 Deepseek R1大模型離線部署教程
Deepseek R1大模型離線部署教程
1. Deepseek簡介
DeepSeek-R1,是幻方量化旗下AI公司深度求索(DeepSeek)研發的推理模型。DeepSeek-R1采用強化學習進行后訓練,旨在提升推理能力,尤其擅長數學、代碼和自然語言推理等復雜任務。作為國產AI大數據模型的代表,憑借其卓越的推理能力和高效的文本生成技術,在全球人工智能領域引發廣泛關注。 本文主要說明DeepSeek-R1如何離線運行在EASY-EAI-Orin-Nano(RK3576)硬件上, RK3576 具有優異的端側AI能效比與極高的性價比,是AI落地的不二之選。
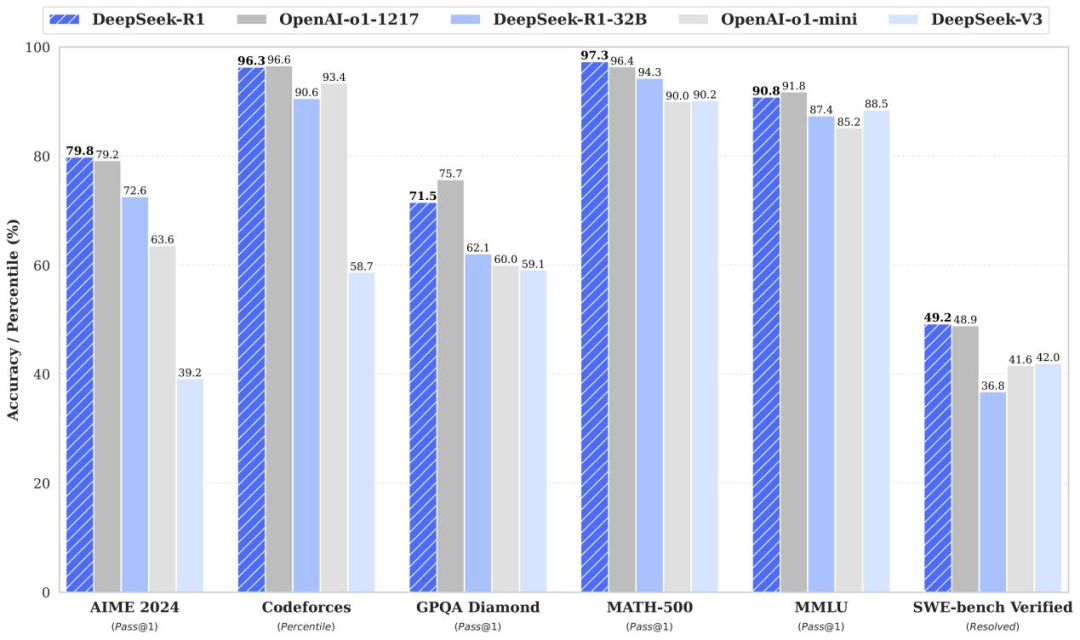

2. 開發環境搭建
2.1RKLLM-Toolkit安裝
本節主要說明如何通過 pip 方式來安裝 RKLLM-Toolkit,用戶可以參考以下的具體流程說明完成 RKLLM-Toolkit 工具鏈的安裝。
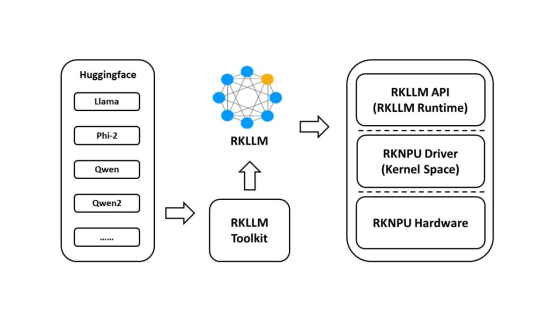
2.1.1安裝miniforge3工具
為防止系統對多個不同版本的 Python 環境的需求,建議使用 miniforge3 管理 Python 環境。檢查是否安裝 miniforge3 和 conda 版本信息,若已安裝則可省略此小節步驟。
下載 miniforge3 安裝包:
wget -c https://mirrors.bfsu.edu.cn/github-release/conda-forge/miniforge/LatestRelease/Miniforge3-Linux-x86_64.sh
安裝miniforge3:
chmod 777 Miniforge3-Linux-x86_64.sh bash Miniforge3-Linux-x86_64.sh2.1.2創建 RKLLM-Toolkit Conda 環境
進入 Conda base 環境:
source ~/miniforge3/bin/activate創建一個 Python3.8 版本(建議版本)名為 RKLLM-Toolkit 的 Conda 環境:
conda create -n RKLLM-Toolkit python=3.8
進入 RKLLM-Toolkit Conda 環境:
conda activate RKLLM-Toolkit

2.1.3安裝RKLLM-Toolkit
在 RKLLM-Toolkit Conda 環境下使用 pip 工具直接安裝所提供的工具鏈 whl 包,在安裝過程 中,安裝工具會自動下載 RKLLM-Toolkit 工具所需要的相關依賴包。
pip3 install nvidia_cublas_cu12-12.1.3.1-py3-none-manylinux1_x86_64.whl pip3 install torch-2.1.0-cp38-cp38-manylinux1_x86_64.whl pip3 install rkllm_toolkit-1.1.4-cp38-cp38-linux_x86_64.whl
若在安裝的過程中,某些文件安裝很慢,可以登錄python官網單獨下載:
https://pypi.org/
執行以下命令沒有報錯,則安裝成功。
3.Deepseek-R1模型轉換
本章主要說明如何實現Deepseek-R1大語言模型如何轉換為RKLLM模型。
3.1模型與腳本下載
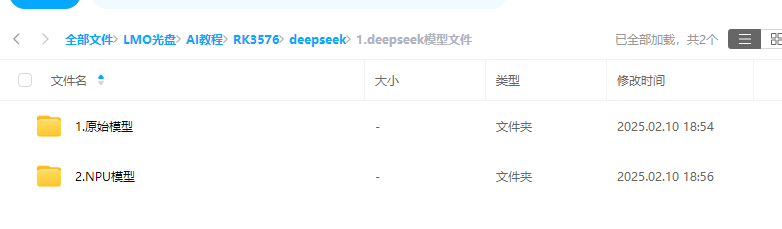
本節提供兩種大模型文件,Hugging face的原始模型和轉換完成的NPU模型。
還有用于模型轉換的腳本:
3.2模型轉換
下載完成后模型和腳本放到同一個目錄:
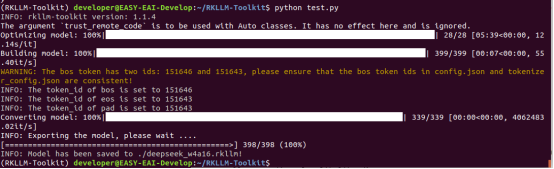
在RKLLM-Toolkit環境,執行以下指令進行模型轉換:
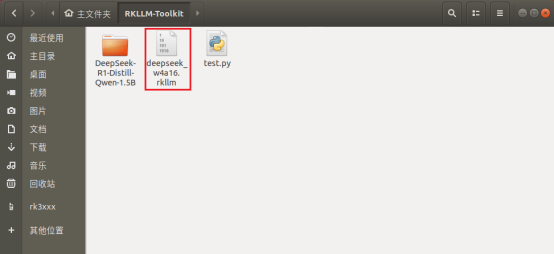
至此模型轉換成功,生成deepseek_w4a16.rkllm NPU化的大模型文件:
test.py轉換腳本如下所示, 用于轉換deepseek-r1模型:
from rkllm.api import RKLLM from datasets import load_dataset from transformers import AutoTokenizer from tqdm import tqdm import torch from torch import nn import os # os.environ['CUDA_VISIBLE_DEVICES']='1' modelpath = '/home/developer/RKLLM-Toolkit/DeepSeek-R1-Distill-Qwen-1.5B' llm = RKLLM() # Load model # Use 'export CUDA_VISIBLE_DEVICES=2' to specify GPU device # options ['cpu', 'cuda'] ret = llm.load_huggingface(model=modelpath, model_lora = None, device='cpu') # ret = llm.load_gguf(model = modelpath) if ret != 0: print('Load model failed!') exit(ret) # Build model dataset = "./data_quant.json" # Json file format, please note to add prompt in the input,like this: # [{"input":"Human: 你好! Assistant: ", "target": "你好!我是人工智能助手KK!"},...] qparams = None # qparams = 'gdq.qparams' # Use extra_qparams ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w4a16', quantized_algorithm='normal', target_platform='rk3576', num_npu_core=2, extra_qparams=qparams, dataset=None) if ret != 0: print('Build model failed!') exit(ret) # Chat with model messages = "<|im_start|>system You are a helpful assistant.<|im_end|><|im_start|>user你好! <|im_end|><|im_start|>assistant" kwargs = {"max_length": 128, "top_k": 1, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1} # print(llm.chat_model(messages, kwargs)) # Export rkllm model ret = llm.export_rkllm("./deepseek_r1_rk3576_w4a16.rkllm") if ret != 0: print('Export model failed!')4.Deepseek-R1模型部署
本章主要說明RKLLM格式的NPU模型如何運行在EASY-EAI-Orin-Nano硬件上。

然后把例程【復制粘貼】到nfs掛載目錄中。(不清楚目錄如何構建的,可以參考《入門指南/開發環境準備/nfs服務搭建與掛載》)。
特別注意:源碼目錄和模型最好cp到板子上,如/userdata,否則在nfs目錄執行大模型會導致模型初始化過慢。
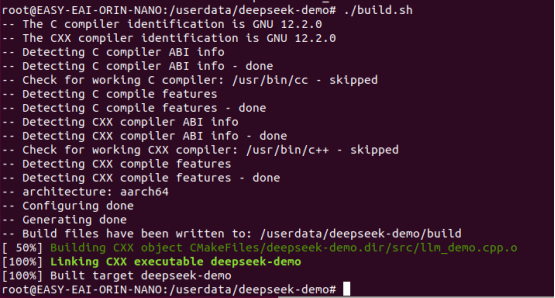
進入到開發板對應的例程目錄執行編譯操作,具體命令如下所示:
cd /userdata/deepseek-demo/ ./build.sh
4.1例程運行及效果
進入例程的deepseek-demo/deepseek-demo_release目錄,執行下方命令,運行示例程序:
cd deepseek-demo_release/ulimit -HSn 102400 ./deepseek-demo deepseek_w4a16.rkllm 256 512

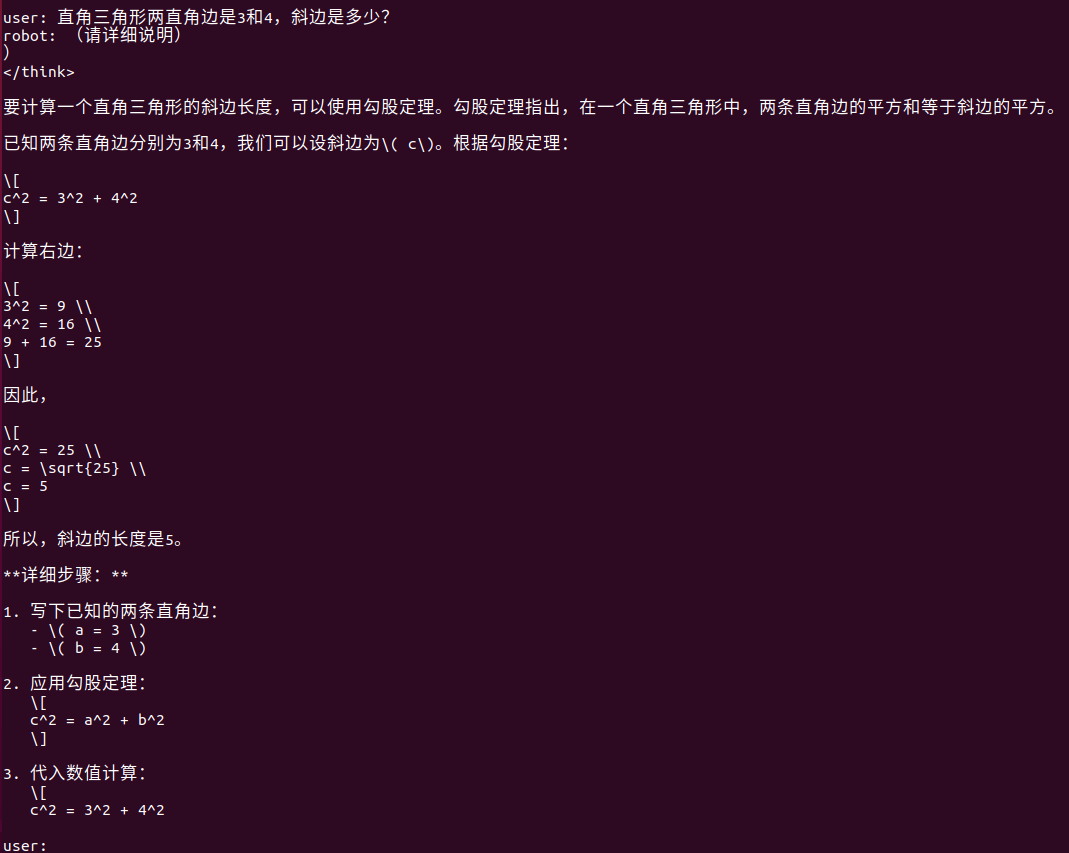
至此可以進行對話測試了,試著輸入“直角三角形兩直角邊是3和4,斜邊是多少?”。回答如下所示:
4.2RKLLM算法例程
例程目錄為rkllm-demo/src/main.cpp,操作流程如下。
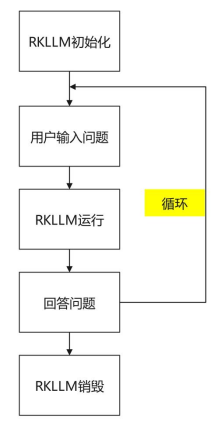
具體代碼如下所示:
#include#include #include #include "rkllm.h" #include #include #include #include #define PROMPT_TEXT_PREFIX "<|im_start|>system You are a helpful assistant. <|im_end|> <|im_start|>user" #define PROMPT_TEXT_POSTFIX "<|im_end|><|im_start|>assistant" using namespace std; LLMHandle llmHandle = nullptr; void exit_handler(int signal) { if (llmHandle != nullptr) { { cout << "程序即將退出" << endl; LLMHandle _tmp = llmHandle; llmHandle = nullptr; rkllm_destroy(_tmp); } } exit(signal); } void callback(RKLLMResult *result, void *userdata, LLMCallState state) { if (state == RKLLM_RUN_FINISH) { printf(" "); } else if (state == RKLLM_RUN_ERROR) { printf("\run error "); } else if (state == RKLLM_RUN_GET_LAST_HIDDEN_LAYER) { /* ================================================================================================================ 若使用GET_LAST_HIDDEN_LAYER功能,callback接口會回傳內存指針:last_hidden_layer,token數量:num_tokens與隱藏層大小:embd_size 通過這三個參數可以取得last_hidden_layer中的數據 注:需要在當前callback中獲取,若未及時獲取,下一次callback會將該指針釋放 ===============================================================================================================*/ if (result->last_hidden_layer.embd_size != 0 && result->last_hidden_layer.num_tokens != 0) { int data_size = result->last_hidden_layer.embd_size * result->last_hidden_layer.num_tokens * sizeof(float); printf(" data_size:%d",data_size); std::ofstream outFile("last_hidden_layer.bin", std::binary); if (outFile.is_open()) { outFile.write(reinterpret_cast (result->last_hidden_layer.hidden_states), data_size); outFile.close(); std::cout << "Data saved to output.bin successfully!" << std::endl; } else { std::cerr << "Failed to open the file for writing!" << std::endl; } } } else if (state == RKLLM_RUN_NORMAL) { printf("%s", result->text); } } int main(int argc, char **argv) { if (argc < 4) { std::cerr << "Usage: " << argv[0] << " model_path max_new_tokens max_context_len "; return 1; } signal(SIGINT, exit_handler); printf("rkllm init start "); //設置參數及初始化 RKLLMParam param = rkllm_createDefaultParam(); param.model_path = argv[1]; //設置采樣參數 param.top_k = 1; param.top_p = 0.95; param.temperature = 0.8; param.repeat_penalty = 1.1; param.frequency_penalty = 0.0; param.presence_penalty = 0.0; param.max_new_tokens = std::atoi(argv[2]); param.max_context_len = std::atoi(argv[3]); param.skip_special_token = true; param.extend_param.base_domain_id = 0; int ret = rkllm_init(&llmHandle, ¶m, callback); if (ret == 0){ printf("rkllm init success "); } else { printf("rkllm init failed "); exit_handler(-1); } string text; RKLLMInput rkllm_input; // 初始化 infer 參數結構體 RKLLMInferParam rkllm_infer_params; memset(&rkllm_infer_params, 0, sizeof(RKLLMInferParam)); // 將所有內容初始化為 0 // 1. 初始化并設置 LoRA 參數(如果需要使用 LoRA) // RKLLMLoraAdapter lora_adapter; // memset(&lora_adapter, 0, sizeof(RKLLMLoraAdapter)); // lora_adapter.lora_adapter_path = "qwen0.5b_fp16_lora.rkllm"; // lora_adapter.lora_adapter_name = "test"; // lora_adapter.scale = 1.0; // ret = rkllm_load_lora(llmHandle, &lora_adapter); // if (ret != 0) { // printf(" load lora failed "); // } // 加載第二個lora // lora_adapter.lora_adapter_path = "Qwen2-0.5B-Instruct-all-rank8-F16-LoRA.gguf"; // lora_adapter.lora_adapter_name = "knowledge_old"; // lora_adapter.scale = 1.0; // ret = rkllm_load_lora(llmHandle, &lora_adapter); // if (ret != 0) { // printf(" load lora failed "); // } // RKLLMLoraParam lora_params; // lora_params.lora_adapter_name = "test"; // 指定用于推理的 lora 名稱 // rkllm_infer_params.lora_params = &lora_params; // 2. 初始化并設置 Prompt Cache 參數(如果需要使用 prompt cache) // RKLLMPromptCacheParam prompt_cache_params; // prompt_cache_params.save_prompt_cache = true; // 是否保存 prompt cache // prompt_cache_params.prompt_cache_path = "./prompt_cache.bin"; // 若需要保存prompt cache, 指定 cache 文件路徑 // rkllm_infer_params.prompt_cache_params = &prompt_cache_params; // rkllm_load_prompt_cache(llmHandle, "./prompt_cache.bin"); // 加載緩存的cache rkllm_infer_params.mode = RKLLM_INFER_GENERATE; while (true) { std::string input_str; printf(" "); printf("user: "); std::getline(std::cin, input_str); if (input_str == "exit") { break; } for (int i = 0; i < (int)pre_input.size(); i++) { if (input_str == to_string(i)) { input_str = pre_input[i]; cout << input_str << endl; } } //text = PROMPT_TEXT_PREFIX + input_str + PROMPT_TEXT_POSTFIX; text = input_str; rkllm_input.input_type = RKLLM_INPUT_PROMPT; rkllm_input.prompt_input = (char *)text.c_str(); printf("robot: "); // 若要使用普通推理功能,則配置rkllm_infer_mode為RKLLM_INFER_GENERATE或不配置參數 rkllm_run(llmHandle, &rkllm_input, &rkllm_infer_params, NULL); } rkllm_destroy(llmHandle); return 0; }
-
人工智能
+關注
關注
1804文章
48820瀏覽量
247270 -
大模型
+關注
關注
2文章
3058瀏覽量
3888 -
rk3576
+關注
關注
1文章
154瀏覽量
607 -
DeepSeek
+關注
關注
1文章
784瀏覽量
1460
原文標題:速看!EASY-EAI教你離線部署Deepseek R1大模型
文章出處:【微信號:easy-eai-AIoT,微信公眾號:EASY EAI靈眸科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
部署DeepSeek R1于AX650N與AX630C平臺
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
RK3588開發板上部署DeepSeek-R1大模型的完整指南
云天勵飛上線DeepSeek R1系列模型

扣子平臺支持DeepSeek R1與V3模型
Gitee AI 聯合沐曦首發全套 DeepSeek R1 千問蒸餾模型,全免費體驗!
超星未來驚蟄R1芯片適配DeepSeek-R1模型
IBM在watsonx.ai平臺推出DeepSeek R1蒸餾模型
研華邊緣AI Box MIC-ATL3S部署Deepseek R1模型







 工商網監
工商網監
評論