") 借助ExecuTorch和KleidiAI提高大語言模型推理性能
借助ExecuTorch和KleidiAI提高大語言模型推理性能
作者:Arm 工程部首席軟件工程師 Gian Marco Iodice 及 Meta 公司 Digant Desai
全球有 2,000 多萬開發(fā)者基于 Arm 架構(gòu)進行開發(fā),而 Arm 也持續(xù)致力于賦能全球開發(fā)者先進的人工智能 (AI) 計算能力。而要實現(xiàn)這一目標,就需要在龐大的軟硬件合作伙伴生態(tài)系統(tǒng)中開展關(guān)鍵的軟件協(xié)作。
去年,Arm 推出了包含一系列開發(fā)者支持技術(shù)和資源的 Arm Kleidi,旨在推動整個機器學習軟件棧的技術(shù)協(xié)作和創(chuàng)新。其中包括提供優(yōu)化軟件例程的 Arm KleidiAI 軟件庫,當將 KleidiAI 集成到如 XNNPACK 等關(guān)鍵框架中時,能夠幫助基于 Arm Cortex-A CPU 的開發(fā)者自動實現(xiàn) AI 加速。而通過 XNNPACK 將 KleidiAI 集成到 ExecuTorch 中,可提升 Arm CPU 在移動端的 AI 工作負載性能。
得益于 Arm 和 Meta 工程團隊的協(xié)作,AI 開發(fā)者可在具有 i8mm ISA 擴展的基于 Armv9 架構(gòu)的 Arm Cortex-A CPU 上部署 Llama 量化模型,運行速度至高可提升 20%。與此同時,ExecuTorch 團隊也已正式上線了測試 (Beta) 版本。
這標志著雙方合作中的一個重要里程碑。在本文中,我們將分享更多細節(jié),包括 ExecuTorch 功能、Meta Llama 3.2 模型、按塊 (per-block) 的 4 位整數(shù)量化,以及在 Arm CPU 上展現(xiàn)出的出色性能。我們在三星 S24+ 設備上運行 Llama 3.2 1B 量化模型,在預填充階段實現(xiàn)了每秒超過 350 個詞元 (token) 的速度,如以下圖所示。
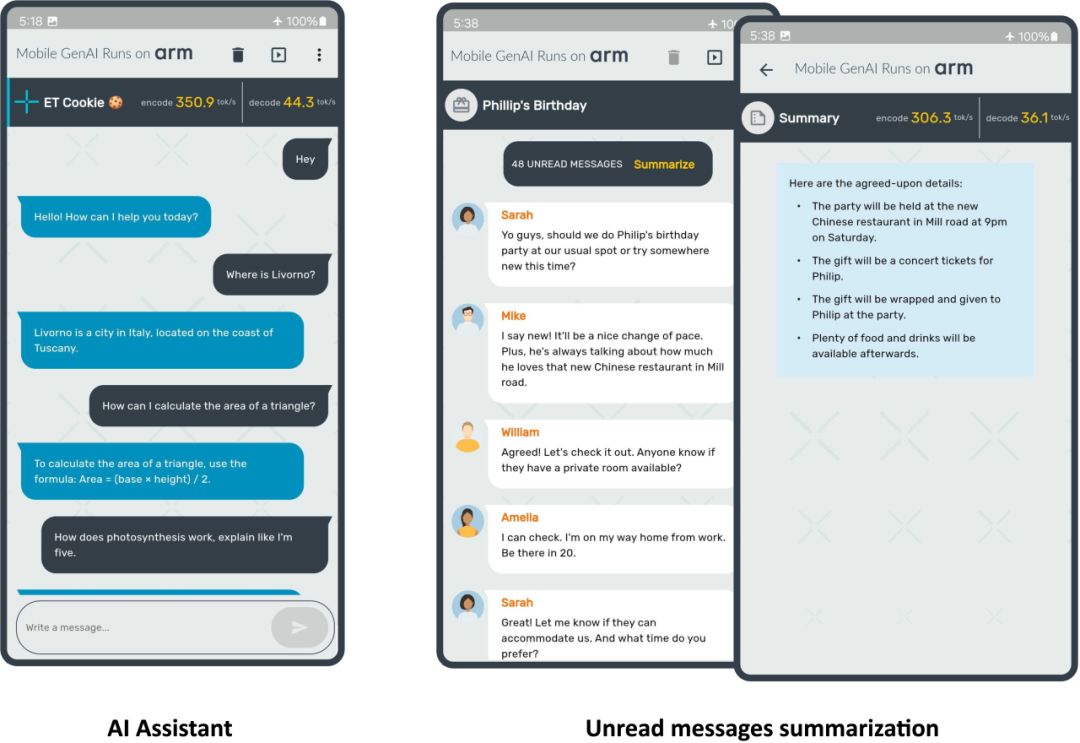
接下來,一起深入了解實現(xiàn)上圖所示演示所需的關(guān)鍵組件。
Meta Llama 3.2
Meta 發(fā)布的首款輕量級 Llama 量化模型能夠在主流的移動設備上運行。Meta 對 Llama 3.2 1B 和 3B 模型采用了兩種量化技術(shù):帶有 LoRA 適配器的量化感知訓練 (QAT) QLoRA 和先進的訓練后量化方法 SpinQuant。這些量化模型在使用 PyTorch 的 ExecuTorch 框架作為推理引擎,并使用 Arm CPU 作為后端的情況下進行評估。這些經(jīng)過指令調(diào)整的模型保留了原始 1B 和 3B 模型的質(zhì)量和安全性,同時與原始 BF16 格式相比,實現(xiàn)了二至四倍的加速,模型大小平均減少了 56%,內(nèi)存占用平均減少了 41%。
ExecuTorch
ExecuTorch 是一種用于在端側(cè)部署 AI 模型的 PyTorch 原生框架,旨在增強隱私性并減少延遲。它支持部署前沿的開源 AI 模型,包括 Llama 模型系列及視覺和語音模型(如 Segment Anything 和 Seamless)。
這為廣泛的邊緣側(cè)設備開辟了新的可能性,例如手機、智能眼鏡、VR 頭顯和智能家居攝像頭等。傳統(tǒng)上,在資源有限的邊緣側(cè)設備上部署 PyTorch 訓練的 AI 模型是一項具有挑戰(zhàn)性且耗時的工作,通常需要轉(zhuǎn)換為其他格式,過程中可能會出現(xiàn)錯誤和性能不理想的情況。此外,硬件和邊緣側(cè)生態(tài)系統(tǒng)中的不同工具鏈也影響了開發(fā)者體驗,使開發(fā)通用解決方案變得不切實際。
為解決這些問題,ExecuTorch 提供了多個可組合的組件,包括核心運行時、算子庫和代理 (delegation) 接口,支持可移植性和可擴展性。模型可以使用 torch.export() 導出,生成與 ExecuTorch 運行時原生兼容的圖表,能夠在大多數(shù)搭載 CPU 的邊緣側(cè)設備上運行,并可擴展到 GPU 和 NPU 等專用硬件以增強性能。
通過與 Arm 合作,ExecuTorch 現(xiàn)可利用 KleidiAI 庫中經(jīng)過優(yōu)化的低比特矩陣乘法內(nèi)核,通過 XNNPACK 提高端側(cè)大語言模型 (LLM) 的推理性能。
為 AI 工作負載提升架構(gòu)
自深度學習浪潮興起以來,Arm 一直致力于投資開源項目并推進新的處理器技術(shù),專注于提高 AI 工作負載的性能和能效。
例如,Arm 從 Armv8.2-A 架構(gòu)開始引入 SDOT 指令,以加速 8 位整數(shù)向量之間的點積運算。目前移動設備上已廣泛具備此特性,顯著加快了 8 位量化模型的計算速度。繼 SDOT 指令之后,Arm 引入了 BF16 數(shù)據(jù)類型和 MMLA 指令,進一步提升 CPU 的浮點和整數(shù)矩陣乘法性能,后來又宣布推出了可伸縮矩陣擴展 (SME),標志著機器學習能力的重大飛躍。
下圖展示了過去十年中 Arm CPU 在 AI 領域持續(xù)創(chuàng)新的部分示例:
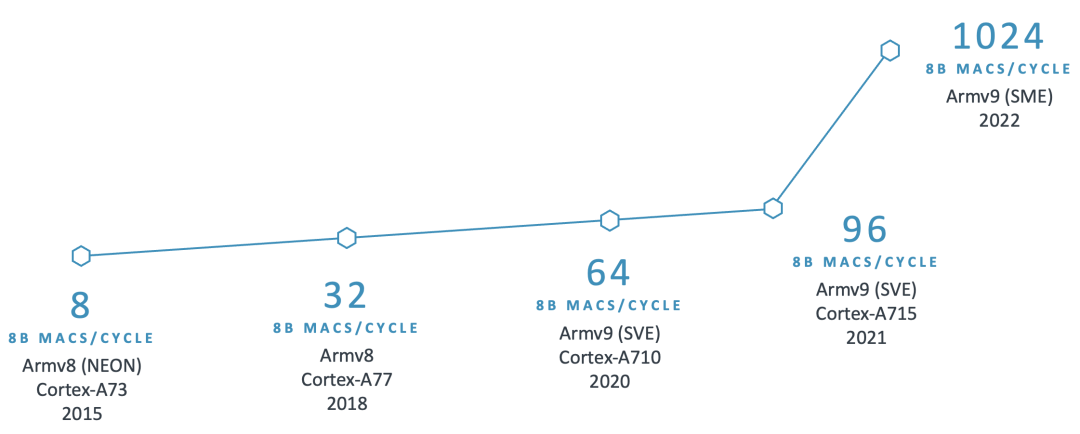
鑒于 Arm CPU 的廣泛應用,AI 框架需要在關(guān)鍵算子中充分利用這些技術(shù),以大幅提高性能。認識到這一點后,我們需要一個開源庫來共享這些經(jīng)過優(yōu)化的軟件例程。然而,我們也注意到將新庫集成到 AI 框架中存在挑戰(zhàn),例如對庫的大小、依賴項和文檔的擔憂,而且需要避免給開發(fā)者增加額外的負擔。因此,我們努力收集合作伙伴的反饋意見,并確保集成過程順利進行,并且不需要 AI 開發(fā)者使用額外的依賴項。這項工作促成了 KleidiAI 的誕生,這是一個開源庫,為針對 Arm CPU 量身定制的 AI 工作負載提供了經(jīng)過優(yōu)化的性能關(guān)鍵例程。
Arm 與 Meta 的 ExecuTorch 團隊合作,為創(chuàng)新的 4 位按塊量化方案提供了軟件優(yōu)化,用于加速 Llama 3.2 量化模型的 Transformer 層的 torch.nn.linear 算子中的矩陣乘法內(nèi)核。ExecuTorch 靈活的 4 位量化方案在針對端側(cè) LLM 的模型準確性和低比特矩陣乘法性能之間取得了平衡。
按塊的 4 位整數(shù)量化
在 KleidiAI 中,我們引入了針對這種新的 4 位整數(shù)量化方案進行優(yōu)化的微內(nèi)核
(matmul_clamp_f32_qai8dxp_qsi4c32p
如下圖所示,對權(quán)重參數(shù)(RHS 矩陣)采用這種 4 位按塊量化策略,并對激活參數(shù)(LHS 矩陣)采用 8 位按行量化:
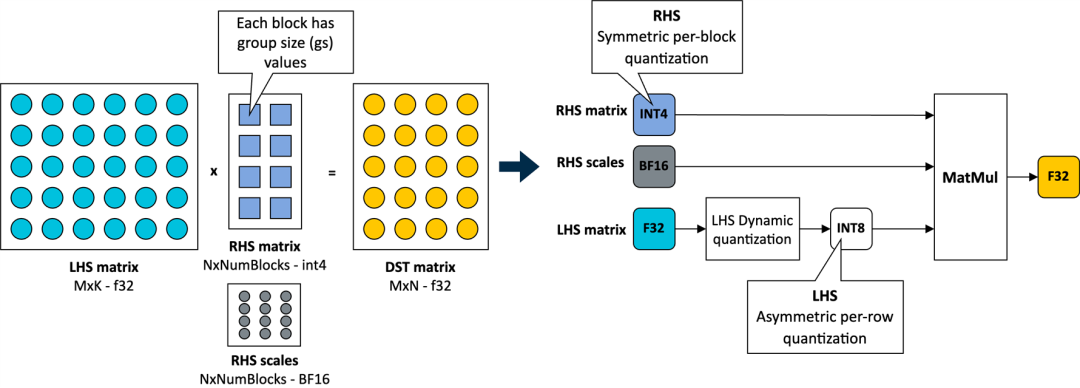
如上圖所示,權(quán)重矩陣中的每個輸出特征圖 (OFM) 被劃分為大小相等的塊(組大小),每個塊都有一個以 BF16 格式存儲的比例因子。BF16 的優(yōu)勢在于它以一半的比特數(shù)維持了 32 位浮點 (FP32) 格式的動態(tài)范圍,并且可以使用簡單的移位運算輕松地與 FP32 進行轉(zhuǎn)換。因而,BF16 非常適合用于節(jié)省模型空間、保持準確性,以及確保向后兼容缺少 BF16 硬件加速的設備。
為保證完整性,這個 4 位量化方案和我們在 KleidiAI 中的實現(xiàn)允許用戶配置線性權(quán)重 (RHS) 的組大小;如果模型由用戶進行量化,則允許用戶在模型大小、模型準確性和模型性能之間進行權(quán)衡。
至此,我們已準備好來展示使用 ExecuTorch 在 Arm CPU 上運行 Llama 3.2 1B 和 Llama 3.2 3B。下面,先來介紹一下用于評估 LLM 推理性能的幾個指標。
LLM 推理指標
通常,用于評估 LLM 推理性能的指標包括:
首詞元延遲 (TTFT):該指標測量的是用戶提供提示詞后生成第一個輸出詞元所花費的時間。這方面的延遲或響應時間對于良好的用戶體驗至關(guān)重要,尤其是在手機上。TTFT 也是提示詞或提示詞詞元長度的函數(shù)。為了使該指標不受提示詞長度的影響,我們在此使用“每秒預填充詞元數(shù)”作為替代指標。它們之間呈反比關(guān)系:TTFT 越低,每秒預填充詞元數(shù)就越高。
解碼性能:該指標是指每秒生成的平均輸出詞元數(shù),因此以“詞元/秒”為單位進行報告。它與生成的詞元總數(shù)無關(guān)。對于端側(cè)推理,重要的是使該指標高于用戶的平均閱讀速度。
峰值運行時內(nèi)存:該指標反映了運行模型時要達到預期性能(使用上述指標來衡量)所需的 RAM 大小。這是端側(cè) LLM 部署的關(guān)鍵指標之一,決定了可在設備上部署的模型類型。
結(jié) 果
Llama 3.2 1B 量化模型(SpinQuant 和 QLoRA)專為在各種 RAM 有限的手機上高效運行而設計。
我們展示的測量數(shù)據(jù)基于運行原生態(tài)安卓系統(tǒng)的三星 S24+ 手機。我們使用 Llama 3.2 1B 參數(shù)模型進行實驗。雖然我們的演示僅使用了 1B 模型,但預計 3B 參數(shù)模型也會有類似的性能提升。實驗設置包括進行一次預熱運行,序列長度為 128,提示詞長度為 64,使用八個可用 CPU 中的六個,并通過 adb 測量結(jié)果。
我們使用來自 GitHub 的 ExecuTorch 主分支,首先用已發(fā)布的檢查點為每個模型生成 ExecuTorch PTE 二進制文件。然后,我們使用相同的代碼倉庫,為 Armv8 生成了 ExecuTorch 運行時二進制文件。我們將使用 KleidiAI 構(gòu)建的二進制文件,比較不同的 1B 量化模型與 BF16 模型的性能。我們還將比較帶有 KleidiAI 的二進制文件和不帶有 KleidiAI 的二進制文件運行量化模型的性能提升幅度,以分析 KleidiAI 產(chǎn)生的影響。
我們的演示結(jié)果顯示,Llama 3.2 1B 量化模型在預填充階段每秒可生成超過 350 個詞元,在解碼階段每秒可生成超過 40 個詞元。這種級別的性能足以僅使用 Arm CPU,就可在端側(cè)實現(xiàn)文本摘要功能,并提供良好的用戶體驗。為便于理解,可以參考的是,平均 50 條未讀消息包含約 600 個詞元。憑借這樣的性能,響應時間(即生成的第一個單詞出現(xiàn)在屏幕上所需的時間)約為兩秒。
量化模型性能
與基線 BF16 模型相比,Llama 3.2 量化模型 SpinQuant 和 QLoRA 在提示詞預填充和文本生成(解碼)方面的性能顯著提升。我們觀察到,解碼性能提高了二倍以上,預填充性能提高了五倍以上。
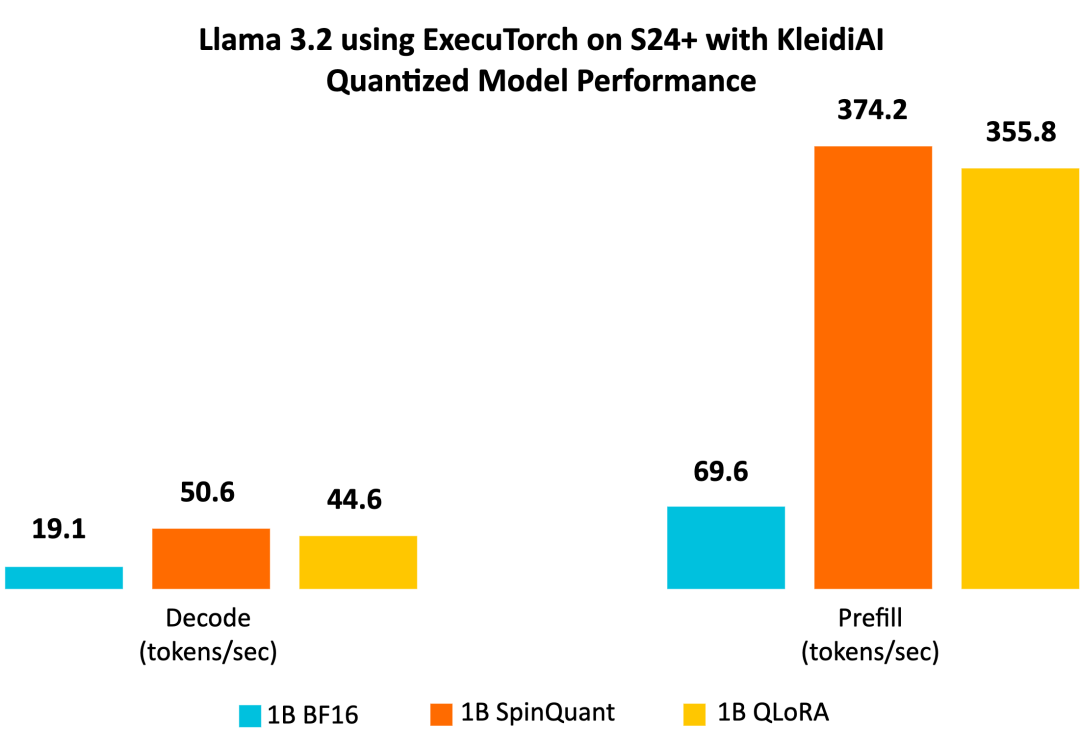
此外,量化模型的大小(以字節(jié)為單位的 PTE 文件大小)不到 BF16 模型的一半,前者為 1.1 GiB,后者為 2.3 GiB。雖然 INT4 的大小是 BF16 的四分之一,但是模型中的某些層是用 INT8 量化的,使得 PTE 文件大小比例增大。我們觀察到,在最大序列長度為 2,048 時,在常駐內(nèi)存集合大小 (RSS) 中測量,與 BF16 模型的 3.1 GiB 相比,SpinQuant 模型的運行時峰值內(nèi)存占用減少近 40%,為 1.9 GiB。
通過全方位的提升,Llama 3.2 量化模型非常適合在 Arm CPU 上進行端側(cè)部署。
KleidiAI 的影響
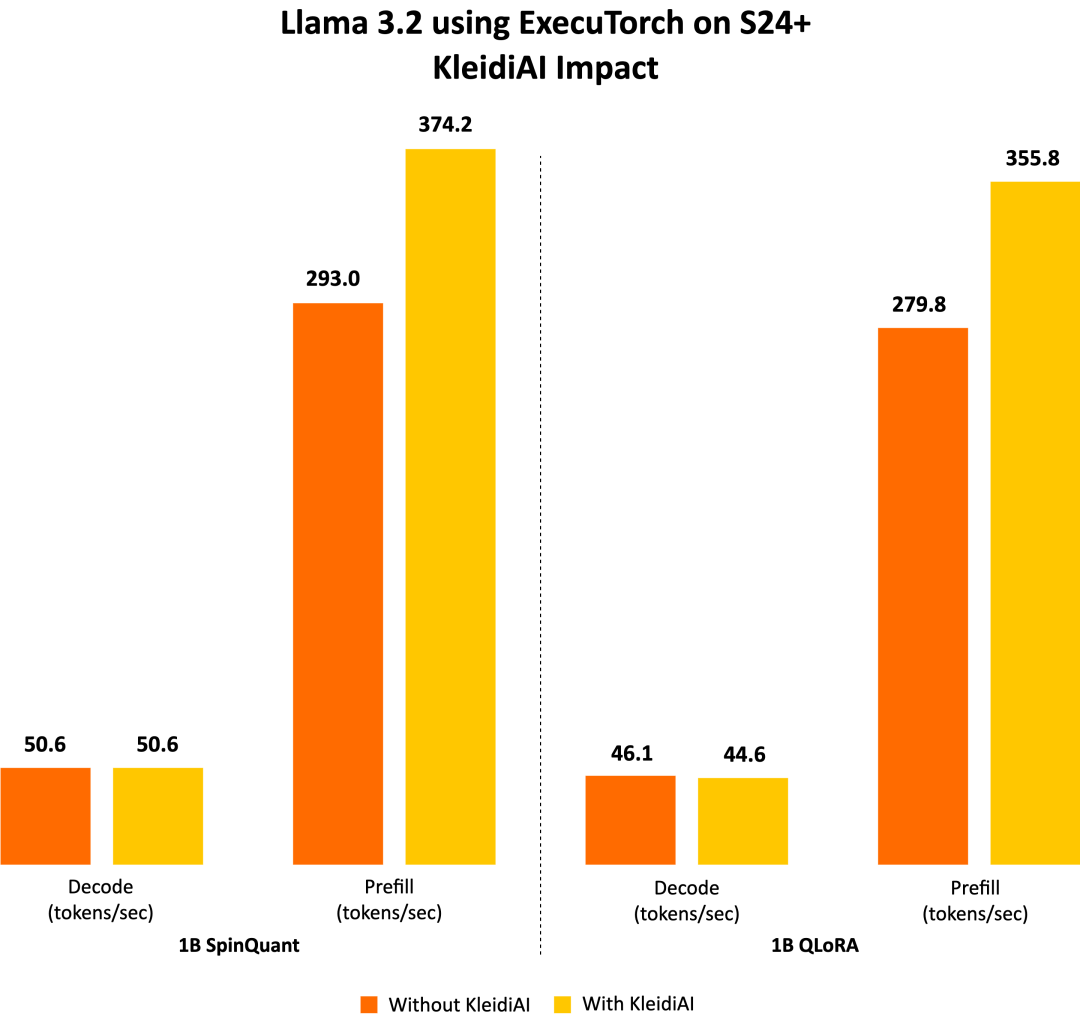
ExecuTorch 借助 KleidiAI 庫,為具有先進 Armv8/Armv9 ISA 特性的新 Arm CPU 提供低比特高性能矩陣乘法內(nèi)核。這些內(nèi)核用于 ExecuTorch 中的端側(cè) Llama 3.2 量化模型推理。
為了評估 Kleidi 產(chǎn)生的影響,我們生成了兩個針對 Cortex-A CPU 的 ExecuTorch 運行時二進制文件,并比較了它們的性能。第一個 ExecuTorch 運行時二進制文件通過 XNNPACK 庫使用 KleidiAI 庫構(gòu)建。第二個二進制文件是在不使用 KleidiAI 庫的情況下構(gòu)建的,使用的是 XNNPACK 庫中的原生內(nèi)核。
如下圖所示,與非 KleidiAI 內(nèi)核相比,ExecuTorch 在 S24+ 上使用 KleidiAI 后,預填充性能平均提升了 20% 以上,同時保持相同的準確度。這種性能優(yōu)勢并不局限于特定的模型或設備,預計所有在 Arm CPU 上使用低比特量化矩陣乘法的 ExecuTorch 模型都將從中受益。
快來動手嘗試吧!
準備好親身體驗性能改進了嗎?在你的項目中試用 ExecuTorch 和 KleidiAI 提供的優(yōu)化!訪問Arm Learning Paths,了解如何通過 ExecuTorch 和 KleidiAI 開發(fā)使用 LLM 的應用。
-
ARM
+關(guān)注
關(guān)注
134文章
9328瀏覽量
375695 -
cpu
+關(guān)注
關(guān)注
68文章
11054瀏覽量
216290 -
模型
+關(guān)注
關(guān)注
1文章
3500瀏覽量
50132 -
工作負載
+關(guān)注
關(guān)注
0文章
11瀏覽量
2031
原文標題:使用 ExecuTorch 和 KleidiAI 運行大語言模型推理,充分釋放移動端 AI 潛力
文章出處:【微信號:Arm社區(qū),微信公眾號:Arm社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
英特爾FPGA 助力Microsoft Azure機器學習提供AI推理性能
NVIDIA擴大AI推理性能領先優(yōu)勢,首次在Arm服務器上取得佳績

NVIDIA打破AI推理性能記錄
【大語言模型:原理與工程實踐】大語言模型的應用
求助,為什么將不同的權(quán)重應用于模型會影響推理性能?
如何提高YOLOv4模型的推理性能?
貝葉斯IP網(wǎng)絡擁塞鏈路推理
英特爾FPGA為人工智能(AI)提供推理性能
最新MLPerf v3.1測試結(jié)果認證,Gaudi2在GPT-J模型上推理性能驚人

Nvidia 通過開源庫提升 LLM 推理性能
用上這個工具包,大模型推理性能加速達40倍
魔搭社區(qū)借助NVIDIA TensorRT-LLM提升LLM推理效率
開箱即用,AISBench測試展示英特爾至強處理器的卓越推理性能

Arm成功將Arm KleidiAI軟件庫集成到騰訊自研的Angel 機器學習框架
使用NVIDIA推理平臺提高AI推理性能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論