 開源大模型DeepSeek的開放內容詳析
開源大模型DeepSeek的開放內容詳析
當大家討論為什么 DeepSeek 能夠形成全球刷屏之勢,讓所有廠商、平臺都集成之時,「開源」成為了最大的關鍵詞之一,圖靈獎得主 Yann LeCun 稱其是「開源的勝利」。模型開源一直備受關注,從代碼、數據到模型的完全開源是人們渴求的方向。那么 DeepSeek 的開源究竟開放了什么?開放到了何種程度?本文作者——資深程序員+資深律師,一起為大家拆解 DeepSeek 的開源之道。
【寫在前面】DeepSeek 是目前可以和閉源大模型媲美的開源大模型,DeepSeek 許可證是負責任的人工智能許可證。按照 Linux 基金會的模型開放架構,DeepSeek 的開放層級尚未完全達到第三級。使用或者分發 DeepSeek 大模型應當遵從 DeepSeek 許可證,包括對于使用場景的限制等。美中不足的是 DeepSeek 可能自己也沒有完全遵守其應當遵守的開源許可證。

DeepSeek 到底有多牛?
DeepSeek 的演進包括了 V2、V2.5、V3、R1-Zero、R1 等版本。其中,用于評估 V3 模型的基準測試包括 MMLU、MMLU-Redux、MMLU-Pro、C-Eval、CMMLU、IFEval、FRAMES、GPQA Diamond、SimpleQA、C-SimpleQA、SWE-Bench Verified、Aider、LiveCodeBench、Codeforces、中國全國中學生數學奧林匹克競賽(CMO),以及美國數學邀請賽(AIME)。V3 的測試比對結果顯示 V3 是性能最佳的開源模型,并且與前沿閉源模型相比也表現出了競爭力。測試對比結果如下[1]:
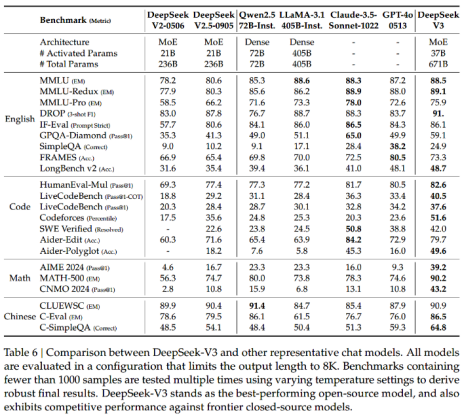
圖 1 DeepSeek-V3 模型測試對比結果
R1 里程碑式的貢獻在于其主要采用強化學習(Reinforcement Learning,RL)而非監督微調(Supervised Fine-Tuning,SFT)提升了大模型的能力。R1 的測試結果在某些測試項的表現優于 OpenAI 的 o1。R1 的測試比對結果如下[2]:
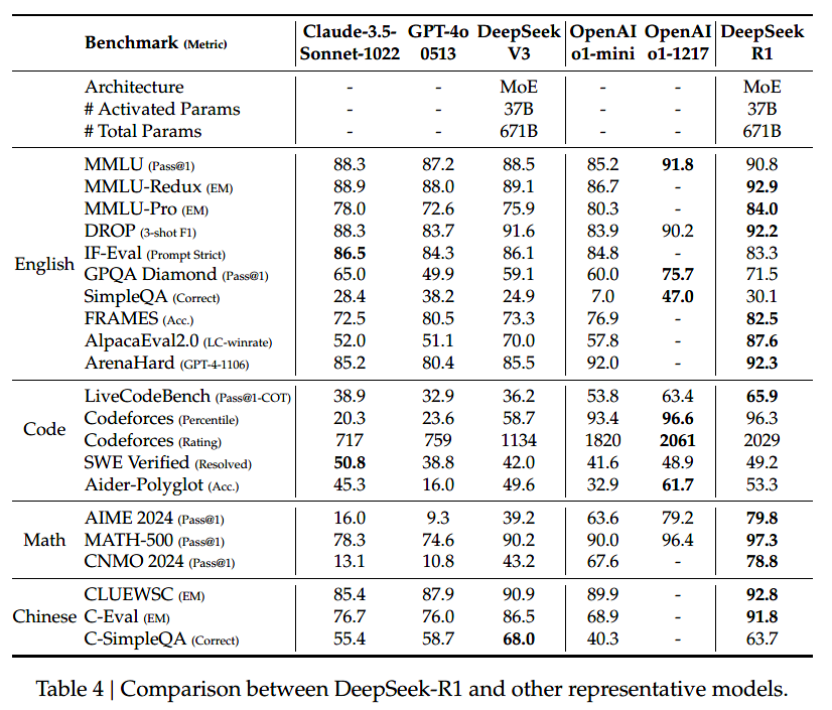
圖 2 DeepSeek-R1 模型測試對比結果
就在看似閉源 OpenAI 遙遙領先之時,DeepSeek 開源大模型的出圈又帶來了巨大的不確定性。對于開源我們仍然滿懷期待,就像 PC 時代的 Linux,移動終端時代的 Android,人類期待 AI 時代的「待定」(可參見《萬字長文!深入大模型版權歸屬問題》一文)。

DeepSeek 是什么開源許可證?
DeepSeek 在 Hugging Face 上一共開放了 68 個模型以及一個數據集[3]。DeepSeek-R1、DeepSeek-R1-Zero 模型的代碼和模型權重都采用的是 MIT 許可證。其余的模型采用的是 DeepSeek 許可證,但代碼采用的是 MIT 許可證。各模型采用的開放許可證如下:
表 1 DeepSeek 模型許可證

注:序號按照 Hugging Face 上的時間順序,序號越小時間越在前。
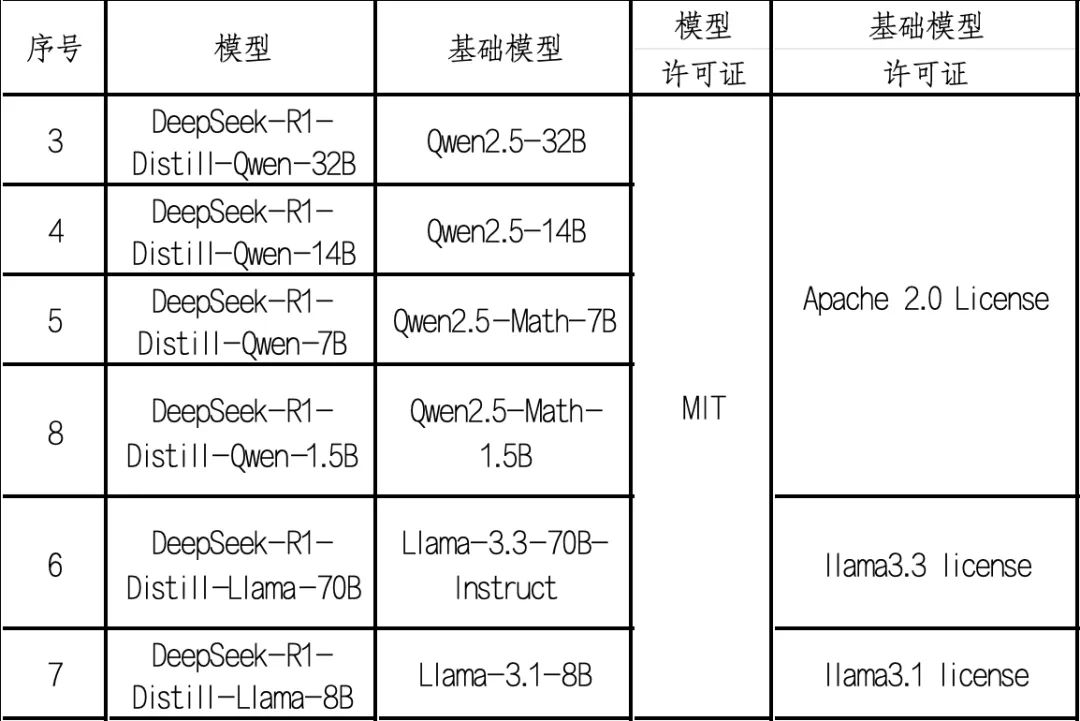
除了以上大模型之外,DeepSeek 還從 Qwen 和 Llama 蒸餾了 6 個模型,蒸餾模型的許可證為 MIT 許可證,Qwen 基礎模型許可證為 Apache 2.0,而 Llama 的許可證為 llama 許可證。
表 2 蒸餾模型許可證

DeepSeek 的開源/開放到了什么層級?
根據 LF AI&Data 基金會引入的模型開放框架(Model Openness Framework,MOF),大模型的開放分為以下三個層次[4]:
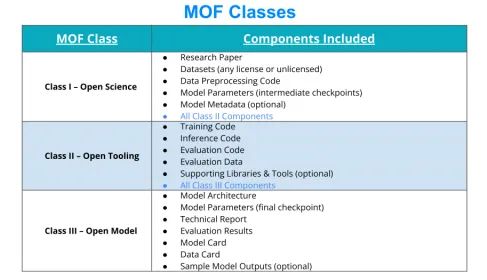
圖 3 模型開放框架
以 DeepSeek-R1 和 DeepSeek-V3 為例,筆者理解的 DeepSeek 開放層級如下:
表 3 DeepSeek 模型開放層級
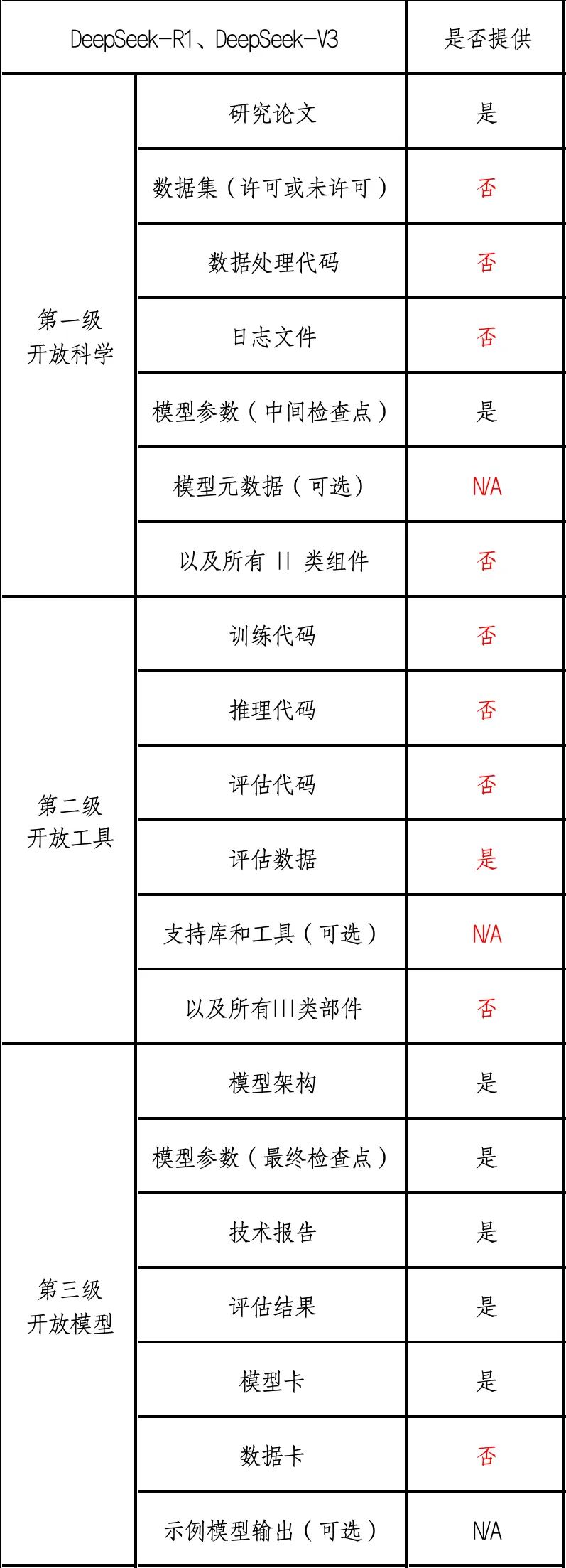
由上表可知,DeepSeek 開放了模型架構、模型卡、模型參數、技術報告、評估結果等,因此,DeepSeek 的開放層次至多屬于第三級。DeepSeek 并未開放訓練代碼、推理代碼、評估代碼、數據集等更為重要的組件。

使用及分發 DeepSeek 大模型有哪些限制及條件?
除了 R1 系列模型之外的其他 DeepSeek 模型都采用 DeepSeek 許可證。
正如前文所述,DeepSeek 幾乎沒有開放任何數據。“數據”是指從模型使用的用于訓練、預訓練或以其他方式評估模型的數據集中提取的信息和/或內容的集合。因此,DeepSeek 許可證中也明確寫明數據未根據該許可證獲得許可。
DeepSeek 模型許可證的原型是負責任的人工智能許可證(Responsible AI License,RAIL)的模型許可證[5]。當然 RAIL 的原型應該是 Apache 2.0 許可證[6]。
(一)使用限制
RAIL 旨在防止不負責任和有害的應用程序。為此,在 RAIL 許可證中加入了使用限制條款,具體而言,采用 DeepSeek 許可證的模型不得用于以下情形:
以任何方式違反任何適用的國家或國際法律或法規或侵犯任何第三方的合法權益;
以任何方式用于軍事用途;
以任何方式剝削、傷害或試圖剝削或傷害未成年人;
生成或傳播可驗證的虛假信息和/或內容,以傷害他人為目的;
根據適用的監管要求生成或傳播不適當內容;
未經授權或者不合理使用而生成或傳播個人身份信息;
誹謗、貶損或以其他方式騷擾他人;
對于完全自動化的決策,對個人的合法權利產生不利影響或以其他方式產生或修改具有約束力、可執行的義務;
任何基于線上或線下社交行為或已知或預測的個人或性格特征,旨在或具有歧視或傷害個人或團體的效果的使用;
利用特定群體基于其年齡、社會、身體或精神特征的任何弱點,以實質性扭曲該群體成員的行為,從而造成或可能造成該人或他人身體或心理傷害;
對于任何旨在或具有基于受法律保護的特征或類別歧視個人或群體的效果的使用。
R1 模型采用的 MIT 許可證沒有列出任何限制。雖然看起來 DeepSeek 許可證比 MIT 許可證增加了很多限制,但是具有實質意義的限制大概只有“以任何方式用于軍事用途”這一條,其他限制,無論是否列出,根據現代國家的法律,基本上都是不符合法律規定的。
除了以上的限制情形,使用者可以使用 DeepSeek 模型創建任何內容、微調、更新、運行、訓練、評估和/或重新參數化模型。
(二)知識產權許可
DeepSeek 針對模型、模型衍生品和補充材料授予的許可包括版權許可和專利許可。許可條款如下:
2.授予版權許可。根據本許可的條款和條件,DeepSeek 特此授予您永久、全球、非排他、免費、免版稅、不可撤銷的版權許可,以復制、準備、公開展示、公開表演、再授權和分發補充材料、模型和模型的衍生品。
3.授予專利許可。根據本許可的條款和條件以及適用情況, DeepSeek 在此授予您永久、全球、非排他、免費、免版稅、不可撤銷(本段所述情況除外)的專利許可,以制作、委托制作、使用、提供銷售、銷售、進口和以其他方式傳遞模型和補充材料,但此類許可僅適用于 DeepSeek 可授權且因其貢獻而必然被侵權的專利權利要求。如果您對任何實體提起專利訴訟(包括訴訟中的交叉訴訟或反訴),聲稱模型和/或補充材料構成直接或共同專利侵權,則根據本許可授予您的模型和/或作品的任何專利許可應在該訴訟主張或提交之日起終止。
授予版權和專利權的條款和最常見的 Apache 2.0 許可證的許可條款幾無二致。
(三)分發和再分發的條件
如果想把 DeepSeek 模型為第三方遠程訪問目的(例如 SaaS)而托管、復制和分發模型或其衍生品的副本(無論是否經過修改),分發者或者再分發者(統稱“傳播方”)必須滿足以下條件:
a. 傳播方必須將以上使用限制作為可執行條款納入任何類型的法律協議(例如許可證)中,以管理模型或模型衍生品的使用和/或分發,并且應當通知第三方接收者,模型或模型衍生品均受使用限制的約束。該條件不適用于補充材料的使用。“補充材料”是指用于定義、運行、加載、基準測試或評估模型的隨附源代碼和腳本,以及用于準備用于訓練或評估的數據(如有),包括任何隨附文檔、教程、示例等(如有)。
b. 傳播方必須向模型或模型衍生品的任何第三方接收者提供 DeepSeek 許可證的副本;
c. 傳播方如果又進行了修改,則必須在任何修改過的文件上附加顯著的聲明,說明更改了這些文件;
d. 傳播方必須保留所有版權、專利、商標和歸屬聲明,但不包括與模型、模型衍生品的任何部分無關的聲明。
e. 傳播方如果進行了修改,傳播方可以在修改中添加自己的版權聲明,并且為使用、復制或分發其修改部分,或整體上為修改后的模型衍生品,提供額外的或不同的許可條款和條件(前提是符合 a 項的使用限制),前提是傳播方對 DeepSeek 模型的使用、復制和分發符合 DeepSeek 許可證中規定的條件。
如果傳播方在分發或者再分發時沒有滿足這些條件,那么傳播方就會構成違約(對 DeepSeek 許可證這一合同的違反)或者侵權(侵犯了 DeepSeek 許可證中授予的著作權以及專利權)。根據各國法律普遍面臨著停止侵權、賠償損失的法律責任。

使用及分發蒸餾模型有哪些進一步的限制及條件?
DeepSeek 分別基于 Qwen 以及 Llama 模型得出了蒸餾模型。如果需要使用或分發這些蒸餾模型,除了需要滿足蒸餾模型本身的 MIT 許可證的要求外,還需要滿足基礎模型的許可證要求。Qwen 模型的許可證為 Apache 2.0 許可證,而 Llama 模型為 Llama 許可證。對于傳統的 MIT 和 Apache 2.0 許可證的許可條件此處不再贅述。以 Llama 3.3 許可證為例,許可證第 1 條對于使用和分發的限制包括:
i.如果您分發或提供 Llama 材料(或其任何衍生作品)或包含其中任何內容的產品或服務(包括另一個 AI 模型),您應 (A) 隨任何此類 Llama 材料提供本協議的副本;以及(B)在相關網站、用戶界面、博客文章、關于頁面或產品文檔上突出顯示“使用 Llama 構建” 。如果您使用 Llama 材料或 Llama 材料的任何輸出或結果來創建、訓練、微調或以其他方式改進已分發或提供的 AI 模型,您還應在任何此類 AI 模型名稱的開頭包含“Llama”。
ii. 如果您從被許可方處收到 Llama 材料或其任何衍生作品作為集成最終用戶產品的一部分,則本許可證第 2 條不適用于您。
iii. 您必須在分發的所有 Llama 材料副本中保留以下歸屬聲明,這些聲明應在作為此類副本的一部分而分發的“聲明”文本文件中發布:“Llama 3.3 已根據 Llama 3.3 社區許可獲得許可,版權所有 Meta Platforms, Inc.保留所有權利。”
iv. 您對 Llama 材料的使用必須遵守適用法律和法規(包括貿易合規法律和法規),并遵守 Llama 材料的可接受使用政策(可在 https://www.llama.com/llama3_3/use-policy 上找到),該政策特此通過引用納入本協議。
該許可證的第 2 條為附加商業條款,即對于商業使用施加的限制:
如果在 Llama 3.3 版本發布之日,由被許可方或被許可方的關聯方提供的產品或服務的月活躍用戶數在前一個日歷月超過 7 億月活躍用戶數,則您必須向 Meta 申請許可,Meta 可自行決定是否授予您許可,并且您無權行使本協議項下的任何權利,除非或直到 Meta 明確授予您此類權利。

DeepSeek 自己是否完全遵守了開源許可證?
DeepSeek-V3 和 DeepSeek-R1 的模型代碼文件 modeling_deepseek.py[7]文件來自 EleutherAI 的 GPT-NeoX 庫以及庫中的 GPT-NeoX 和 OPT 實現,且原始形式上進行了修改,以適應與訓練該模型的 Meta AI 團隊使用的 GPT-NeoX 和 OPT 相比細微的架構差異。在 modeling_deepseek.py 文件中,也有多處類似于“# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->DeepseekV3”的注釋。EleutherAI 的 GPT-NeoX 庫采用 Apache 2.0 許可證[8]。
因此,如果 DeepSeek 集成了按照 Apache2.0 許可證分發的模型材料,也應當遵守 Apache 2.0 許可證的規定;如果 DeepSeek 集成了按照 Llama 許可證分發的模型材料,也應當遵守 Llama 許可證的規定。
DeepSeek 對 Qwen 大模型以及 Llama 大模型進行蒸餾,顯然也應當遵守 Qwen 大模型所采用的 Apache 2.0 許可證以及 Llama 大模型采用的 Llama 許可證。
按照 Llama 許可證(以 Llama 3.1 為例)的規定,對于作為分發者的 DeepSeek,還應當(A)附隨 Llama 材料提供 Llama 許可證副本;并且(B)在相關網站、用戶界面、博客文章、關于頁面、或產品文檔上突出顯示“使用 Llama 構建”。從 Llama 模型蒸餾毫無疑問使用了 Llama 模型材料,因此還應在任何此類蒸餾模型名稱的開頭包含“Llama”。此外,還應當在聲明文本文件中保留以下署名聲明:“Llama 3.1 是根據 Llama 3.1 社區許可證授權,版權所有 Meta Platforms, Inc.,保留所有權利。”
根據以上的分析,DeepSeek 并未完全遵循開源許可證,主要表現在沒有在相應的大模型分發材料中附隨分發許可證副本,沒有突出顯示“使用 Llama 構建”,也沒有保留署名聲明。

總結
盡管 DeepSeek 自己本身可能也并未完全遵守開源許可證。但是,白璧微瑕,DeepSeek 驚人的表現又讓世界對于開源大模型有了更高的期待。這也并不代表著其他人在使用和分發 DeepSeek 大模型時就可以有樣學樣。恰恰相反,使用者或者分發者更應該本著不讓雷鋒吃虧的精神,認真遵循開源許可證中規定的使用限制條件和分發條件,構建負責任的人工智能世界。
-
開源
+關注
關注
3文章
3624瀏覽量
43536 -
大模型
+關注
關注
2文章
3046瀏覽量
3862 -
DeepSeek
+關注
關注
1文章
783瀏覽量
1426
原文標題:開源大模型 DeepSeek 到底開放了什么?
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【書籍評測活動NO.62】一本書讀懂 DeepSeek 全家桶核心技術:DeepSeek 核心技術揭秘
如何使用OpenVINO運行DeepSeek-R1蒸餾模型

HarmonyOS NEXT開發實戰:DevEco Studio中DeepSeek的使用
聆思CSK6大模型語音開發板接入DeepSeek資料匯總(包含深度求索/火山引擎/硅基流動華為昇騰滿血版)
RK3588開發板上部署DeepSeek-R1大模型的完整指南
DeepSeek扔的第二枚開源王炸是什么






 工商網監
工商網監
評論