") 京東零售數(shù)據(jù)資產(chǎn)能力升級與實(shí)踐
京東零售數(shù)據(jù)資產(chǎn)能力升級與實(shí)踐

作者:京東零售 韓雷鈞
開篇
京東自營和商家自運(yùn)營模式,以及伴隨的多種運(yùn)營視角、多種組合計(jì)算、多種銷售屬性等數(shù)據(jù)維度,相較于行業(yè)同等量級,數(shù)據(jù)處理的難度與復(fù)雜度都顯著增加。如何從海量的數(shù)據(jù)模型與數(shù)據(jù)指標(biāo)中提升檢索數(shù)據(jù)的效率,降低數(shù)據(jù)存算的成本,提供更可信的數(shù)據(jù)內(nèi)容和多種應(yīng)用模式快速支撐業(yè)務(wù)的數(shù)據(jù)決策與分析,是數(shù)據(jù)團(tuán)隊(duì)去年聚焦解決的核心課題。
過程中基于RBO、HBO等多級加速引擎、基于代價(jià)與場景消費(fèi)的智能物化策略、基于One Metric的異構(gòu)融合服務(wù)、基于One Logic語義層的離近在線轉(zhuǎn)換以及基于圖形語法和多端一體的可視化工具,聯(lián)合GPT技術(shù)的智能問答系統(tǒng)chatBI,顯著提升業(yè)務(wù)數(shù)字化決策效率,過程中也沉淀了多篇軟著與多項(xiàng)技術(shù)專利。對于多級加速引擎與智能物化策略,行業(yè)普遍采用cube預(yù)計(jì)算+緩存模式,京東創(chuàng)新性落地了基于主動(dòng)元數(shù)據(jù)的口徑定義以及基于數(shù)據(jù)消費(fèi)場景與消費(fèi)頻次的正負(fù)反饋動(dòng)態(tài)決策,確保整個(gè)數(shù)據(jù)鏈路的存算分配“當(dāng)下最優(yōu)”,同時(shí)相較于粗粒度的物化策略,模型生命周期參考存儲代價(jià)配置,數(shù)據(jù)查詢鏈路根據(jù)RT表現(xiàn)動(dòng)態(tài)尋址,這樣使得數(shù)據(jù)生產(chǎn)與數(shù)據(jù)消費(fèi)形成交互反饋鏈路,決策依據(jù)更加豐富,決策粒度更加精準(zhǔn)。
基于圖形語法和多端一體的可視化能力打造層面,京東JMT數(shù)據(jù)可視化能力可以依托底層指標(biāo)中臺快速進(jìn)行智能診斷與歸因,相較于tableau等頭部解決方案,融入了更多圖形語法同時(shí)可靈活適配多端多場景。
結(jié)合AIGC技術(shù)的智能問答系統(tǒng)chatBI,基于業(yè)務(wù)知識與數(shù)據(jù)資產(chǎn)的Prompt工程,使用本地大模型SFT對實(shí)體進(jìn)行embedding,通過指標(biāo)統(tǒng)一DSL取代了行業(yè)普遍NL2SQL的解決方案,很好解決了人為意識到數(shù)據(jù)語言的轉(zhuǎn)換難題,所消耗芯片規(guī)模也顯著優(yōu)于行業(yè)水平,在數(shù)據(jù)智能分析診斷系統(tǒng)里準(zhǔn)確率大幅領(lǐng)先。
以上核心技術(shù)通過23年的打磨與應(yīng)用,數(shù)據(jù)指標(biāo)開發(fā)與共享效率大幅提升,分析看板搭建時(shí)間從天級別縮短到小時(shí)級別,且業(yè)務(wù)用戶逐漸可以進(jìn)行自交付,解決了集中式研發(fā)的人力瓶頸,日均指標(biāo)消費(fèi)頻次從23年初的百萬級增長到年末的數(shù)千萬;在23年基礎(chǔ)之上,我們未來還將在數(shù)據(jù)加速、智能物化、智能診斷、大模型應(yīng)用等方面持續(xù)深耕,不斷優(yōu)化數(shù)據(jù)存算成本,提升數(shù)據(jù)應(yīng)用的效率、體驗(yàn)。
依托于京東數(shù)據(jù)資產(chǎn)的完備性、數(shù)據(jù)能力的自動(dòng)化與數(shù)據(jù)應(yīng)用的智能化,結(jié)合業(yè)務(wù)場景真實(shí)遇到的痛點(diǎn)問題,我們積累了一些經(jīng)驗(yàn), 本文將通過如下幾個(gè)章節(jié)進(jìn)行分享交流: 1、 數(shù)據(jù)資產(chǎn)篇--資產(chǎn)認(rèn)證與治理 2、 數(shù)據(jù)能力篇--指標(biāo)中臺實(shí)踐 3、 數(shù)據(jù)展現(xiàn)篇--數(shù)據(jù)可視化工具 4、 數(shù)據(jù)智能篇-- 基于大模型的智能化應(yīng)用
1、數(shù)據(jù)資產(chǎn)篇--資產(chǎn)認(rèn)證與治理
背景與挑戰(zhàn)
零售數(shù)據(jù)模型有80+萬張,其中有大量的臨時(shí)表、無效表等,零售數(shù)據(jù)資產(chǎn)用戶(尤其是分析師角色)一直存在找模型、理解模型、使用模型困難的情況,面對業(yè)務(wù)用數(shù)、分析需求,在找模型探數(shù)據(jù)的環(huán)節(jié)經(jīng)常消耗較多的時(shí)間精力,用戶普遍希望可以節(jié)約找、用模型的時(shí)間,提升交付數(shù)據(jù)結(jié)果、分析結(jié)果的效率,而且有些錯(cuò)誤的或重復(fù)的資產(chǎn)在公司部門內(nèi)流通,重復(fù)資產(chǎn)一方面浪費(fèi)成本,另一方面無法保證數(shù)據(jù)的一致性。
為解決用戶訴求,同時(shí)從產(chǎn)研角度希望優(yōu)化數(shù)據(jù)資產(chǎn)的質(zhì)量和標(biāo)準(zhǔn)化程度,從生產(chǎn)到消費(fèi)均進(jìn)行一定程度的優(yōu)化改造,提升端到端的資產(chǎn)建立標(biāo)準(zhǔn)化程度,進(jìn)而提升用戶使用體驗(yàn)。
數(shù)據(jù)統(tǒng)一語言
目標(biāo):如下圖所示,拉齊資產(chǎn)建設(shè)者和資產(chǎn)消費(fèi)者之間的溝通語言,提升找表效率、增強(qiáng)表的可解釋性。
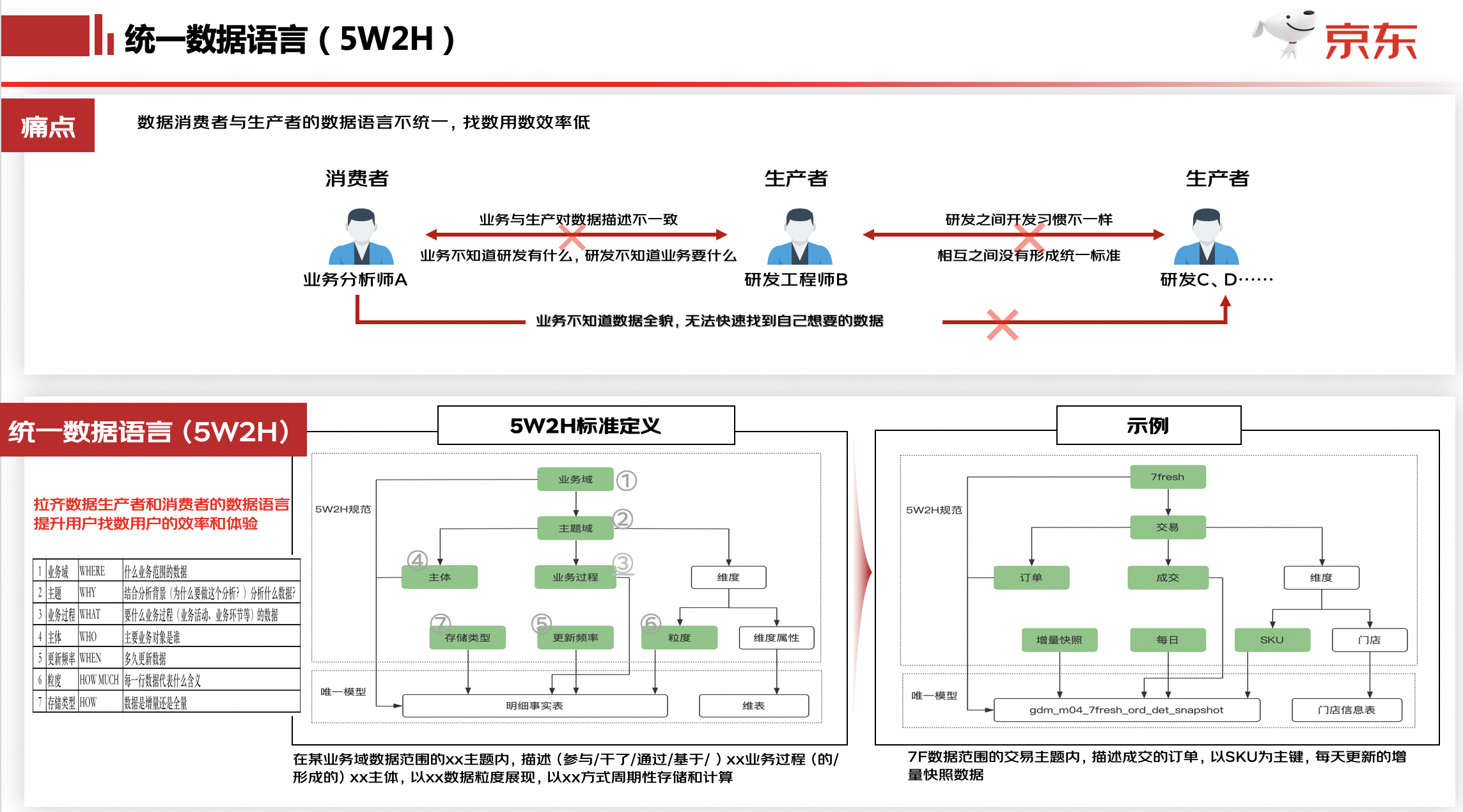
通過數(shù)據(jù)維度建模的三個(gè)階段(概念模型、邏輯模型、物理模型),形成描述模型的標(biāo)準(zhǔn)定義。
總結(jié)為一句話:
業(yè)務(wù)域 & 主題 下,描述了 X1業(yè)務(wù)過程 , X2業(yè)務(wù)過程 的 X主體 表,每 更新頻率 更新 更新周期 數(shù)據(jù)的 存儲方式 表,表主鍵是 數(shù)據(jù)粒度
比如:adm_d04_trade_std_ord_det_snapshot通用域 & 交易 下,描述了 取消,完成,成交,訂單出庫,下單 的 大盤訂單 表,每天更新近1日的增量快照 表,表主鍵是 ord_type+sale_ord_det_id
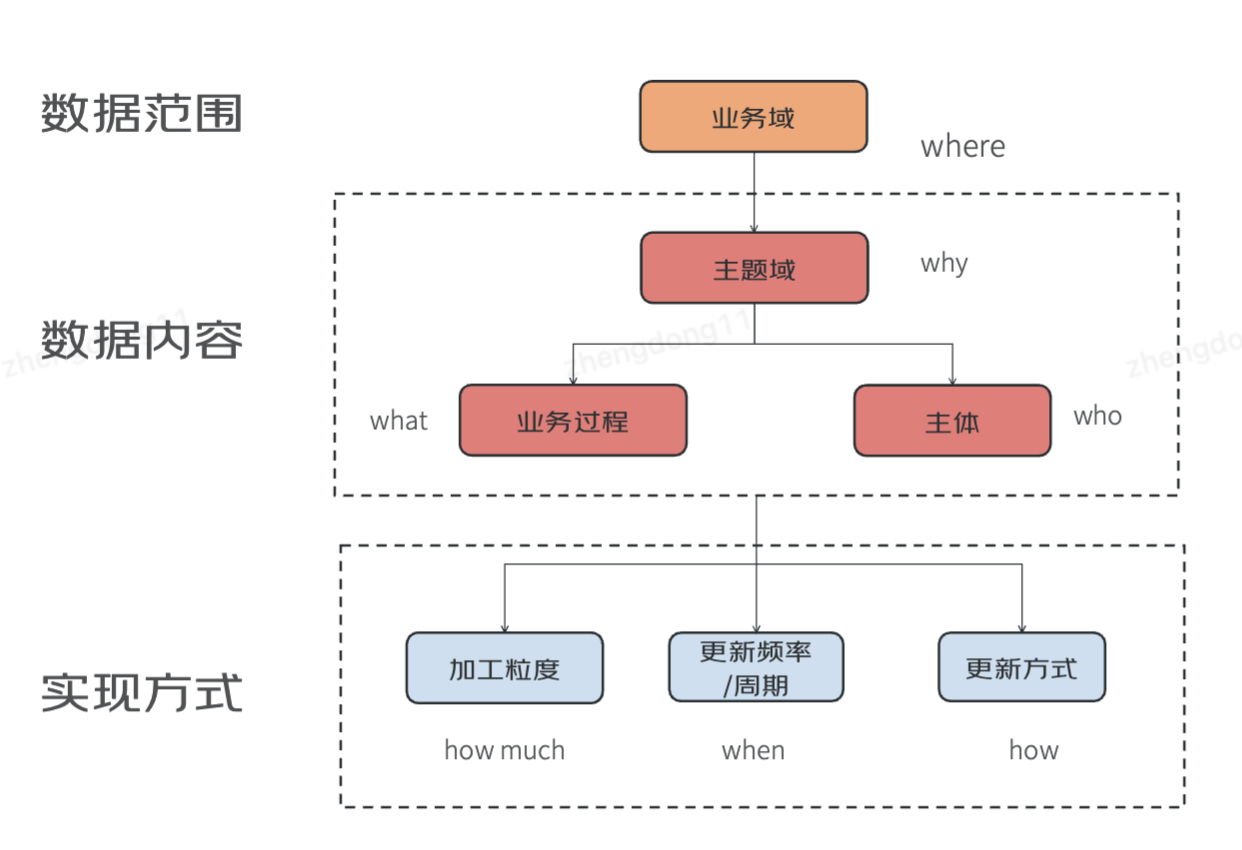
維度建模方法論
3個(gè)階段:概念模型 > 邏輯模型 > 物理模型 (1:N:M )
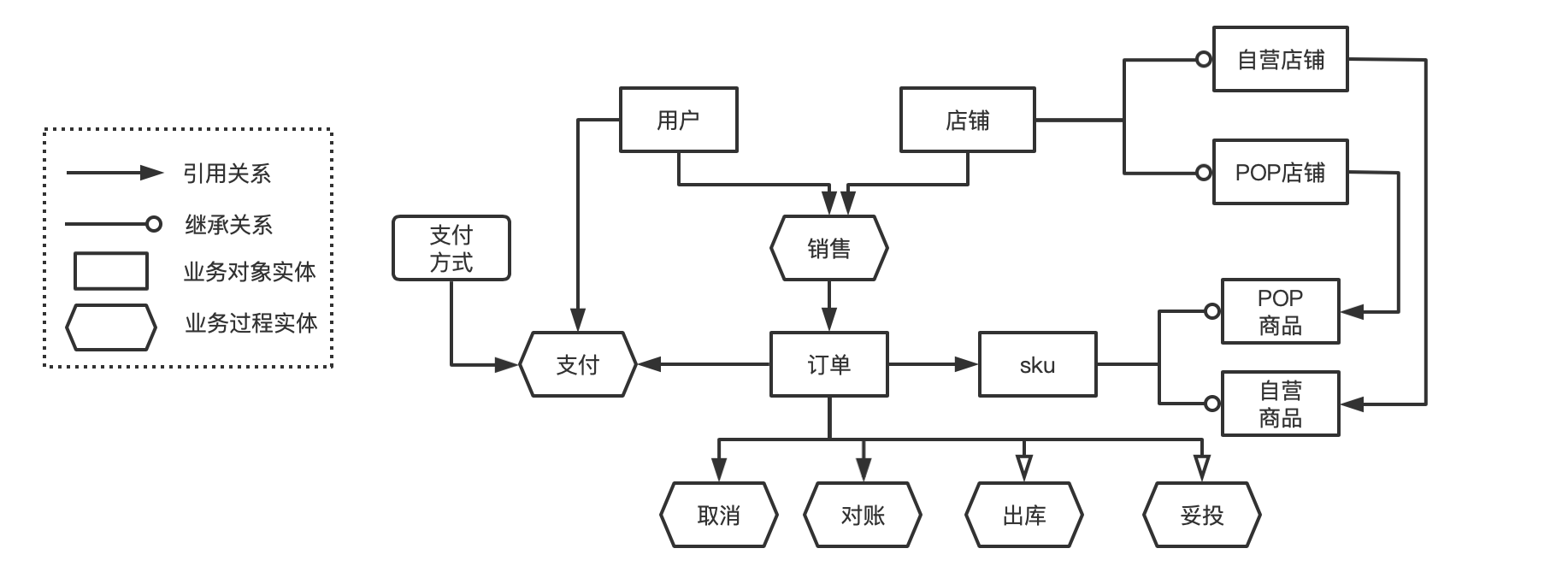
概念模型
在一個(gè)分析領(lǐng)域內(nèi),描述實(shí)體以及實(shí)體之間的關(guān)系,等同于業(yè)務(wù)圖譜。一個(gè)主題下一個(gè)概念模型。
實(shí)體之間的關(guān)系包括引用關(guān)系和繼承關(guān)系,引用關(guān)系:一個(gè)實(shí)體是另外一個(gè)實(shí)體的屬性。繼承關(guān)系:實(shí)體比另外一個(gè)實(shí)體更細(xì)化具體,比如事件和瀏覽。
where [業(yè)務(wù)域]+ why[主題]+who[主體集合] + what [業(yè)務(wù)過程集合]
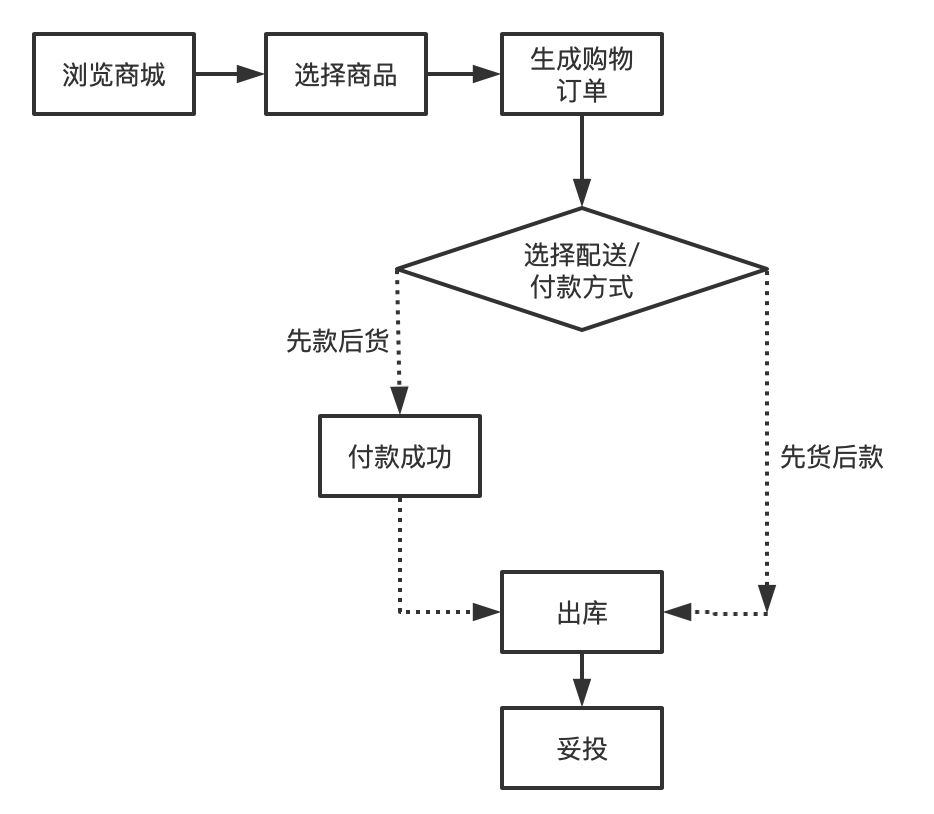
舉例:交易的業(yè)務(wù)流程圖:
將業(yè)務(wù)流程中的實(shí)體(包括業(yè)務(wù)活動(dòng)和業(yè)務(wù)對象)之間的關(guān)系構(gòu)建出來,變成交易主題下的概念模型:
?
邏輯模型
邏輯模型:是將概念模型轉(zhuǎn)化為具體的數(shù)據(jù)模型的過程。一個(gè)概念模型下會(huì)拆分成多個(gè)邏輯模型。拆分原則:根據(jù)主體或者業(yè)務(wù)過程進(jìn)行拆分。
where [業(yè)務(wù)域] + why[主題] +who[主體] + what [業(yè)務(wù)過程]
這里的業(yè)務(wù)過程可以是單個(gè),也可以是多個(gè)。一般根據(jù)業(yè)務(wù)將業(yè)務(wù)相似度高,同粒度的業(yè)務(wù)過程放在一起。
舉例:
where [主站] + why[交易] +who[訂單] + what [下單、支付、出庫、完成] where [主站] + why[交易] +who[訂單] + what [下單、支付] where [主站] + why[交易] +who[移動(dòng)訂單] + what [下單]
物理模型
用技術(shù)手段將邏輯模型通過不同的加工方式和周期頻率等物化形成多個(gè)不同的物理模型。一個(gè)邏輯模型對應(yīng)一個(gè)或者多個(gè)物理模型。更新周期:每次更新多久的數(shù)據(jù)。更新頻率:多久更新一次。加工粒度:描述模型每一行的業(yè)務(wù)含義,也就是主鍵。
where [業(yè)務(wù)域] + why[主題] +who[主體] + what [業(yè)務(wù)過程]
+ when [更新周期+更新頻率]
+ how much [加工粒度]
+ how [更新方式]
舉例:
[主站] + [交易] +[訂單] + [下單、支付、出庫、完成] + [未歸檔/日]+[訂單號] + 增量
[主站] + [交易] +[訂單] + [下單、支付、出庫、完成] +[未歸檔/日]+[銷售訂單明細(xì)編號] + 增量
[主站] + [交易] +[訂單] + [下單、支付、出庫、完成] +[近1日/日]+[銷售訂單明細(xì)編號] + 增量
[主站] + [交易] +[訂單] + [下單、支付、出庫、完成] +[近180日/日]+[銷售訂單明細(xì)編號] + 增量
[主站] + [交易] +[訂單] + [下單、支付] +[近1日/日]+[銷售訂單明細(xì)編號] + 增量
[主站] + [交易] +[移動(dòng)訂單] + [下單] +[近1日/日]+[訂單號] + 增量
資產(chǎn)認(rèn)證
基于數(shù)據(jù)標(biāo)準(zhǔn),推進(jìn)資產(chǎn)認(rèn)證,通過資產(chǎn)完備性、唯一性治理,存量資產(chǎn)關(guān)停并轉(zhuǎn),提升認(rèn)證資產(chǎn)的需求覆蓋率,降本增效。目前,已認(rèn)證模型近3000張,資產(chǎn)需求覆蓋率84%以上,覆蓋零售范圍內(nèi)的交易、用戶、流量、營銷、財(cái)務(wù)等核心主題數(shù)據(jù)資產(chǎn)建設(shè)。
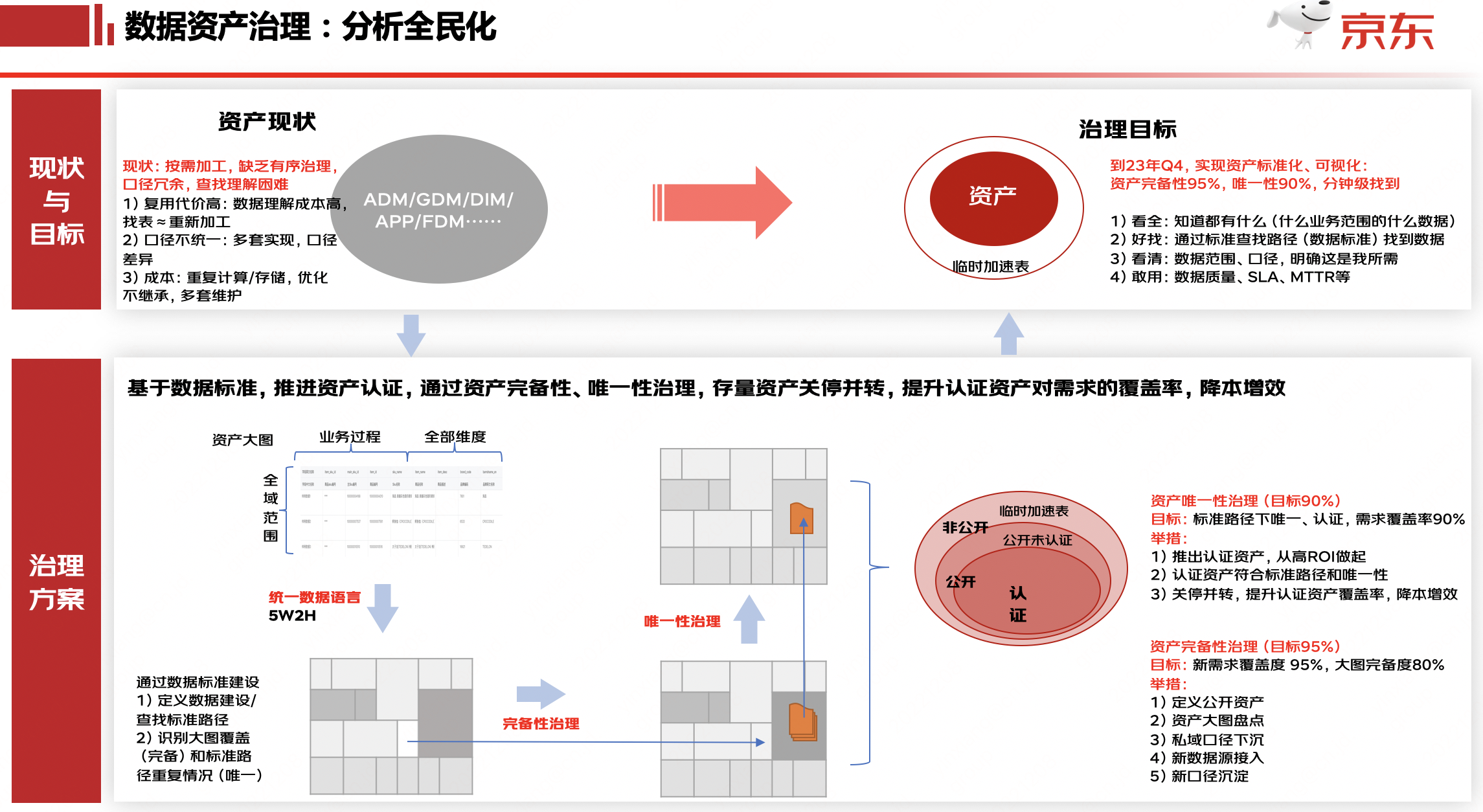
資產(chǎn)可感知
從全局到局部,端到端的全面了解數(shù)據(jù)資產(chǎn),提升資產(chǎn)可感知的能力,包含:
1)推進(jìn)數(shù)據(jù)資產(chǎn)圖譜的自動(dòng)化構(gòu)建能力,從資產(chǎn)全景上快速了解到業(yè)務(wù)流程及業(yè)務(wù)數(shù)據(jù)化的資產(chǎn)模型(數(shù)據(jù)孿生);
2)豐富模型詳情頁,歸一所有信息源,并增加對模型行高、數(shù)據(jù)范圍、常見問題等信息,提升用戶理解模型的效率;
3)標(biāo)準(zhǔn)字段庫,通過對字段標(biāo)準(zhǔn)口徑、業(yè)務(wù)描述、特殊場景、常見問題等信息的補(bǔ)充和完善,提升用戶理解模型、用模型的效率。
未來計(jì)劃
?以用戶反饋問題出發(fā),完善和優(yōu)化數(shù)據(jù)標(biāo)準(zhǔn)5W2H,使其確保數(shù)據(jù)資產(chǎn)清晰易理解的目標(biāo)達(dá)成;
?依據(jù)樣板間的效果反饋,完善樣板間的功能和內(nèi)容,并推廣到其他主題資產(chǎn);
?加強(qiáng)數(shù)據(jù)資產(chǎn)運(yùn)營,擴(kuò)展渠道,提升用戶找數(shù)用數(shù)體驗(yàn)。
?
2、數(shù)據(jù)能力篇--指標(biāo)中臺實(shí)踐
背景與挑戰(zhàn)
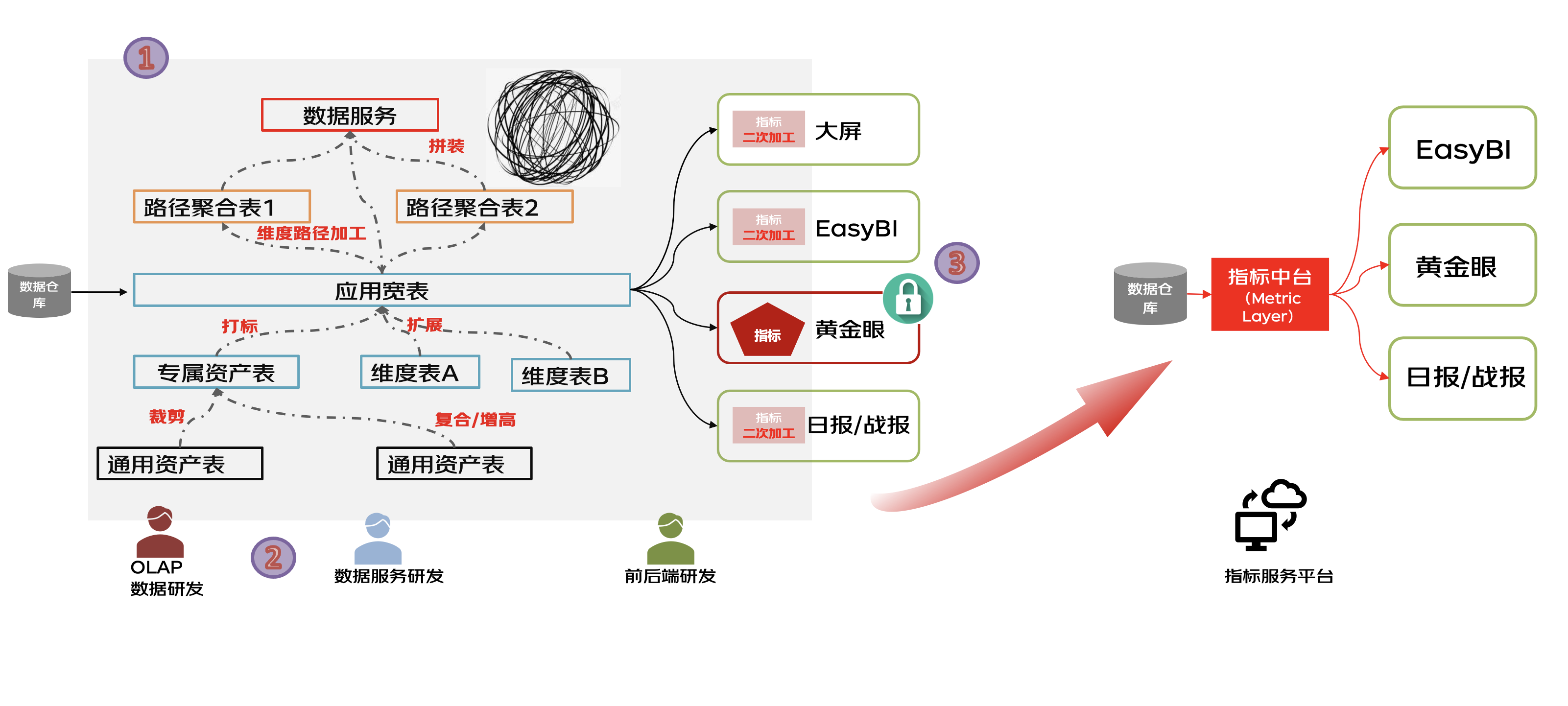
?1、口徑歧義與存算不受控:指標(biāo)通常散落在BI報(bào)表工具、數(shù)據(jù)產(chǎn)品、ETL過程與各種中間表中,看不清,改不動(dòng);如何系統(tǒng)化保障存算資源使用合理?
?2、研發(fā)資源缺口:數(shù)據(jù)BP缺少OLAP數(shù)據(jù)研發(fā)、數(shù)據(jù)服務(wù)研發(fā)、前后端研發(fā),在不擴(kuò)招的情況下如何滿足各業(yè)務(wù)單元的用數(shù)訴求,降低指標(biāo)加工門檻,使少量BP同學(xué)即可完成自交付?
?3、指標(biāo)開放共享難:如何讓原本鎖定在數(shù)據(jù)應(yīng)用產(chǎn)品內(nèi)部的指標(biāo)無需重復(fù)加工即可對外開放共享,讓指標(biāo)流通起來?
技術(shù)先進(jìn)性
縱觀業(yè)界比較成熟的指標(biāo)中臺相關(guān)建設(shè),針對零售場景口徑變化快、用戶類型多且數(shù)量大、數(shù)據(jù)產(chǎn)品形態(tài)豐富等特點(diǎn),我們打造了核心優(yōu)勢項(xiàng)能力:
1.全量的指標(biāo)明細(xì)資產(chǎn)管控能力【指標(biāo)、維度資產(chǎn)】
2.系統(tǒng)原生的拓?fù)淠芰Α局笜?biāo)市場】
3.業(yè)務(wù)公式統(tǒng)一沉淀能力【規(guī)則引擎】
4.指標(biāo)異常主動(dòng)預(yù)警能力【指標(biāo)巡檢】
5.基于邏輯寬表的智能加速和擴(kuò)維能力【定義驅(qū)動(dòng)生產(chǎn)】
結(jié)合以上我們特有的優(yōu)勢項(xiàng)能力,在業(yè)界首次實(shí)現(xiàn)了生產(chǎn)與消費(fèi)聯(lián)動(dòng)互相促進(jìn),打造了數(shù)據(jù)收集、數(shù)據(jù)安全、指標(biāo)計(jì)算、監(jiān)控、分析以及決策支持的指標(biāo)生態(tài),提供一站式的中臺化、服務(wù)化的指標(biāo)服務(wù)平臺,讓用戶可以高效地管理和分析各種業(yè)務(wù)指標(biāo),主要解決用戶在數(shù)據(jù)處理和分析過程中遇到的以下幾個(gè)問題: (1)數(shù)據(jù)孤島:不同的部門或業(yè)務(wù)線可能使用不同的系統(tǒng)來記錄數(shù)據(jù),導(dǎo)致數(shù)據(jù)分散在不同的地方,集中分析變得困難。 (2)數(shù)據(jù)標(biāo)準(zhǔn)一致性:保證整個(gè)組織內(nèi)部使用統(tǒng)一的數(shù)據(jù)指標(biāo)定義和計(jì)算邏輯。 (3)實(shí)時(shí)性:業(yè)務(wù)決策往往需要實(shí)時(shí)或近實(shí)時(shí)的指標(biāo)來支持,一站式指標(biāo)中臺化解決方案可以提供實(shí)時(shí)監(jiān)控和即時(shí)分析。 (4)自助式分析:業(yè)務(wù)人員和分析師可以通過友好的界面進(jìn)行自助式的數(shù)據(jù)探索和分析,而不需要依賴于專業(yè)的數(shù)據(jù)團(tuán)隊(duì)。 (5) 數(shù)據(jù)治理:包括數(shù)據(jù)安全、質(zhì)量管理、合規(guī)性監(jiān)控等多方面確保數(shù)據(jù)的準(zhǔn)確性和可靠性。
總體架構(gòu)設(shè)計(jì)
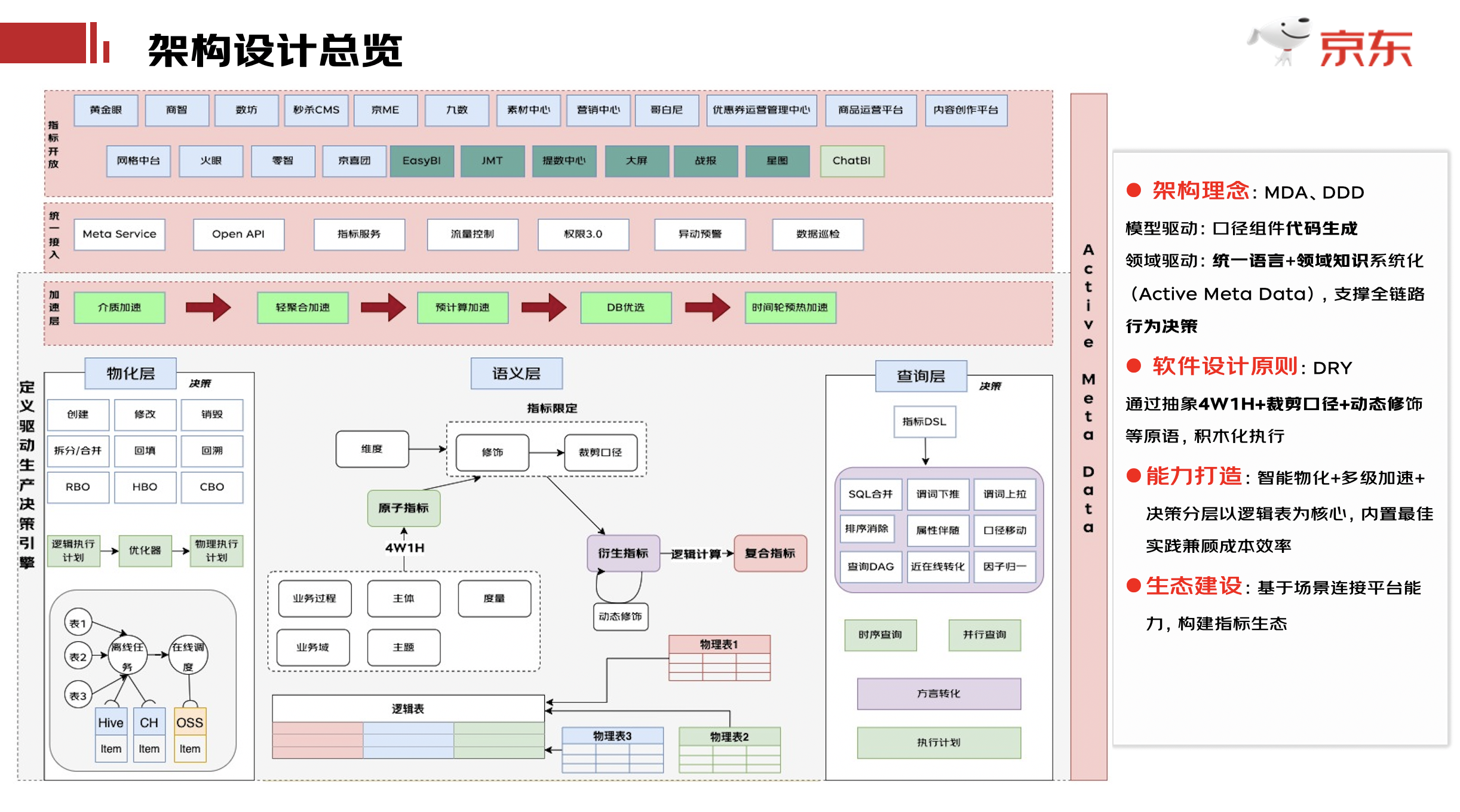
在架構(gòu)設(shè)計(jì)上我們參考了MDA和DDD的思想,希望通過口徑組件實(shí)現(xiàn)自動(dòng)生成代碼并統(tǒng)一查詢語言,支持全鏈路行為決策;通過DRY的原則抽象指標(biāo)定義相關(guān)可積木化執(zhí)行的原語,以便于基于數(shù)據(jù)應(yīng)用的場景連接底層平臺能力;從圖中可以看到整體架構(gòu)分為物化層,語義層,和查詢層。在整個(gè)過程中都會(huì)伴隨數(shù)據(jù)加速,通過統(tǒng)一接入層開放給各個(gè)產(chǎn)品端或可視化工具來使用,物化層用來回答前面的存不存,存多久,存哪里,怎么存的問題;語義層用來通過系統(tǒng)將業(yè)務(wù)語言轉(zhuǎn)化為機(jī)器語言,查詢層用來回答數(shù)據(jù)去哪拿、怎么拿、怎么拿最快的問題,最上面藍(lán)色部分為各個(gè)消費(fèi)指標(biāo)產(chǎn)物的產(chǎn)品端,深綠色是可視化工具,淺綠色是正在孵化階段的基于GPT的數(shù)據(jù)分析工具。
詳細(xì)設(shè)計(jì)展開
查詢層 :統(tǒng)一查詢語言,最佳查詢策略、最優(yōu)查詢性能
統(tǒng)一的DSL
在查詢語言層面,需要將自然語言分析需求轉(zhuǎn)換為結(jié)構(gòu)化的查詢語言從而達(dá)到書同文、車同軌的目的,使得指標(biāo)數(shù)據(jù)所見即所得,開箱即用。我們通過如下案例來說明語言抽象的思路,例如一個(gè)常見的分析需求:
「23年12月21日'小米'品牌在各店鋪'成交金額'排名top5的情況」
如果將該需求進(jìn)行結(jié)構(gòu)化抽取,可以做如下解釋:
聚合條件:【按‘店鋪’聚合】,篩選條件:【時(shí)間范圍 = '2023-12-21'、品牌 = '小米'(id是8557)】 ,要查的指標(biāo) = 【成交金額】,排序 = 【按‘成交金額’降序】, 返回維度屬性 = 【店鋪】,分頁 = 【第一頁-5條】。
通過這樣的結(jié)構(gòu)化思維的理解,則統(tǒng)一的指標(biāo)查詢語言可以由五要素組成:指標(biāo)、聚合條件、篩選條件、排序分頁、返回維度屬性。基于此五要素,設(shè)計(jì)出統(tǒng)一查詢DSL。如下結(jié)構(gòu)體所示,語法規(guī)則設(shè)計(jì)類似Json語法風(fēng)格。
{
"indicators": [
"ge_deal_standard_deal_ord_amt"
],
"attributes": [
"shop"
],
"criteria": {
"criterions": [
{
"propertyName": "main_brand",
"values": "8557",
"type": "string",
"op": "="
},
{
"propertyName": "dt",
"value": "2023-12-21",
"type": "string",
"op": "="
},
...
],
"orders": [
{
"ascending": false,
"propertyName": "ge_deal_standard_deal_ord_amt"
}
],
"maxResults": 5,
"firstResult": 0,
"group": [
"shop"
]
}
}
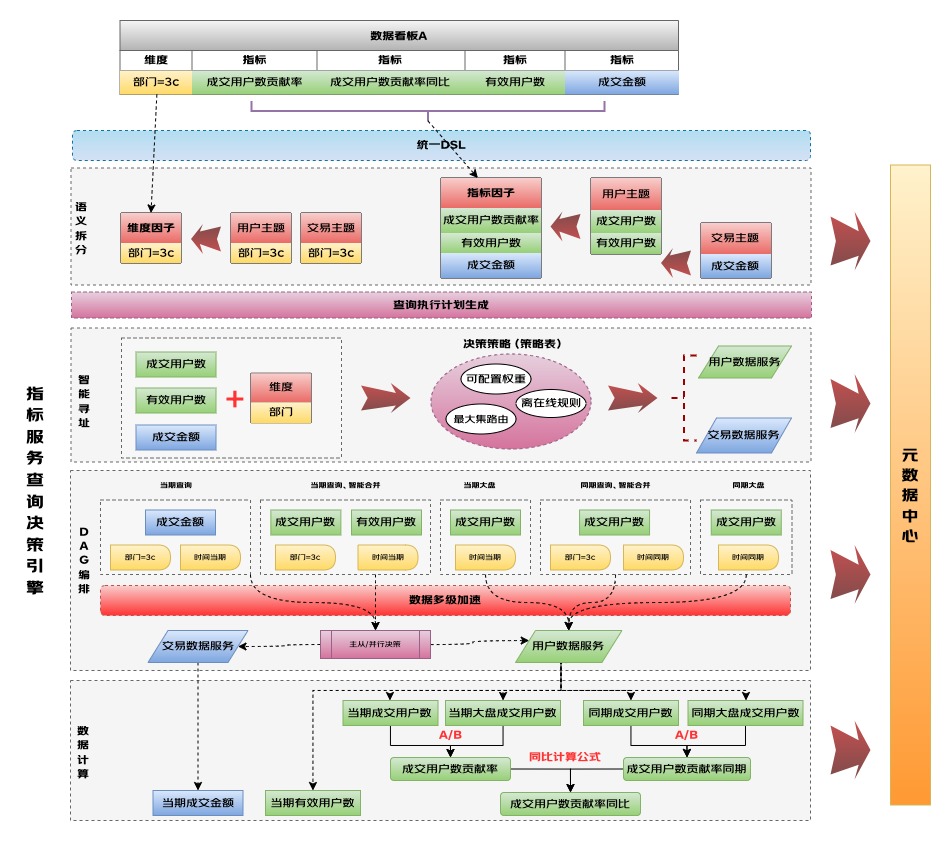
智能尋址拆分
在實(shí)際應(yīng)用情況中,在簡單的五要素基礎(chǔ)上,真實(shí)業(yè)務(wù)場景還存在一些同環(huán)比、復(fù)合指標(biāo)計(jì)算類似的分析及提數(shù)場景,則一次取數(shù)任務(wù)并不是提交一次引擎查詢就可以滿足需求。所以按照實(shí)際場景,查詢引擎在處理一次取數(shù)任務(wù)時(shí),會(huì)生成一個(gè)執(zhí)行計(jì)劃DAG,主要包含兩層拆分原則:
(1)語義拆分:按照查詢引擎提供的DSL語義進(jìn)行第一層拆分,結(jié)合統(tǒng)一的包含“指標(biāo)、維度、數(shù)據(jù)服務(wù)”的基礎(chǔ)元數(shù)據(jù)中心,進(jìn)行尋址物料的歸堆分組,根據(jù)決策策略表進(jìn)行拆分,包含取尋址最大必要集、在線轉(zhuǎn)離線的策略以及可手動(dòng)調(diào)配的權(quán)重等,一個(gè)Job(對應(yīng)用戶一次取數(shù)任務(wù))會(huì)拆分為多個(gè)Task,每個(gè)Task表示一批邏輯的指標(biāo)/維度查詢。
(2)引擎拆分:按照指標(biāo)維度所存在的數(shù)據(jù)服務(wù)(表引擎)進(jìn)行第二層拆分,一個(gè)Task會(huì)拆分多個(gè)Query,每個(gè)Query表示一次面向引擎的查詢,包括上圖里當(dāng)期查詢、同期查詢等并針對Task按照實(shí)際查詢場景進(jìn)行主從/并行的Query決策。
查詢邏輯加速
包含根據(jù)執(zhí)行計(jì)劃發(fā)起的主從/并行和點(diǎn)查/批查的查詢,通過這個(gè)邏輯加速可以減少2/3(整體的統(tǒng)計(jì),一批指標(biāo)越多越明顯)的冗余數(shù)據(jù)查詢,從而提升整體TP99表現(xiàn),同時(shí)在查詢層通過動(dòng)態(tài)獲取集群CPU負(fù)載等情況可以用來進(jìn)行自動(dòng)切流、潮汐滾動(dòng)等加速優(yōu)化,比如在雙流情況下,當(dāng)其中一條流集群CPU負(fù)載超過預(yù)設(shè)的閾值時(shí),啟動(dòng)自動(dòng)切一部分流量到另一個(gè)流從而來前置降低集群負(fù)載避免影響查詢速度。又如在近線的查詢場景中(分頁邏輯異步發(fā)起多次請求,用戶預(yù)期分鐘級響應(yīng)內(nèi)),通過獲取集群CPU、負(fù)載的使用情況來動(dòng)態(tài)調(diào)節(jié)請求的流速,從而通過最大化利用集群資源來實(shí)現(xiàn)查詢提速。當(dāng)然在查詢加速上少不了緩存的介入,通過JIMDB+本地緩存的方式進(jìn)行多級緩存的加速。
語義層:數(shù)據(jù)知識系統(tǒng)化,使資產(chǎn)放心好用、治理有依據(jù)
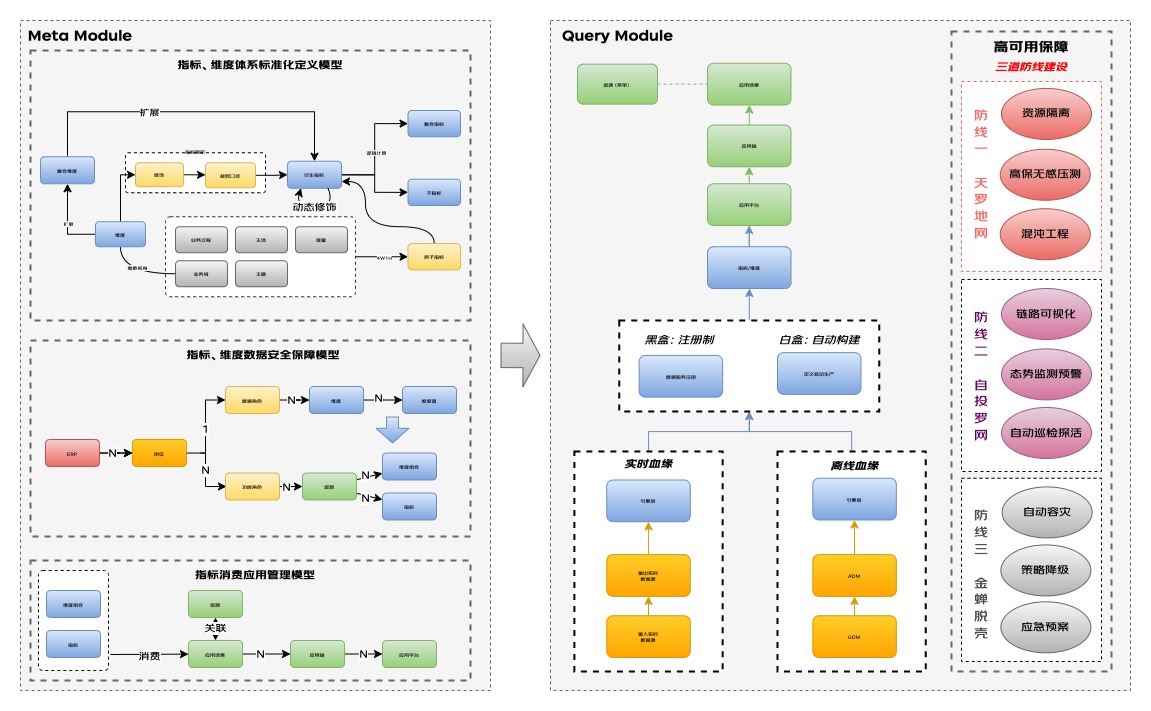
數(shù)據(jù)知識系統(tǒng)化:
在數(shù)據(jù)知識可視化上要做的事兒是如何將業(yè)務(wù)語言轉(zhuǎn)化為機(jī)器語言,并根據(jù)設(shè)定的標(biāo)準(zhǔn)及規(guī)則進(jìn)行執(zhí)行,對此分別從指標(biāo)維度體系化標(biāo)準(zhǔn)定義模型、指標(biāo)維度的數(shù)據(jù)安全保障模型、指標(biāo)消費(fèi)應(yīng)用管理模型三個(gè)層面進(jìn)行了系統(tǒng)化設(shè)計(jì),為自動(dòng)化生產(chǎn)、消費(fèi)及全鏈路血緣可視化做數(shù)據(jù)治理打好基礎(chǔ)。
?指標(biāo)、維度體系化標(biāo)準(zhǔn)定義模型:
通過定義4w1h構(gòu)造原子指標(biāo)并結(jié)合標(biāo)準(zhǔn)維度定義的裁剪口徑進(jìn)行唯一的、標(biāo)準(zhǔn)的衍生指標(biāo)定義。
復(fù)合指標(biāo)指建立在衍生指標(biāo)之上,通過一定運(yùn)算規(guī)則形成的計(jì)算指標(biāo)集合(二次邏輯計(jì)算),如ARPU值、滲透率等;包括比率型、比例型、變化量型、變化率型、統(tǒng)計(jì)行(均值、分位數(shù)),復(fù)合指標(biāo)采用了“積木化+服務(wù)化”雙重解決方案,在既滿足業(yè)務(wù)靈活場景下,又做到了復(fù)合指標(biāo)的資產(chǎn)沉淀。
又如以復(fù)合維度的模型為例在維度模型上結(jié)合較頻繁變動(dòng)的維度(維度的定義會(huì)周期性變動(dòng))調(diào)整項(xiàng)如何統(tǒng)一,對需求進(jìn)行了抽象,設(shè)計(jì)復(fù)合維度模型,進(jìn)一步擴(kuò)充"指標(biāo)-維度-修飾"的概念體系,既保證了維度口徑定義的透明,又保證了邏輯一致且可被系統(tǒng)執(zhí)行;一次定義,多處使用,結(jié)合上面提到的統(tǒng)一查詢的服務(wù)化能力做到了真正的開放(日均調(diào)用量4000w)、共享(可復(fù)用,不用單獨(dú)開發(fā))。
?指標(biāo)、維度數(shù)據(jù)安全保障模型:
對人在數(shù)據(jù)應(yīng)用產(chǎn)品上能看到什么樣的數(shù)據(jù)范圍需要有安全保障,避免數(shù)據(jù)泄露風(fēng)險(xiǎn)。對此通過把看數(shù)視角【維度+維度值】定義到數(shù)據(jù)角色里,可做到數(shù)據(jù)角色被多個(gè)人或者崗位所復(fù)用。在數(shù)據(jù)角色基礎(chǔ)上抽取崗位的模型把人與角色關(guān)聯(lián)起來,保證一個(gè)人可有多個(gè)身份切換不同視角進(jìn)行靈活看數(shù)。在崗位下通過設(shè)計(jì)功能角色把資源(菜單)的權(quán)限進(jìn)行管控,在資源下進(jìn)行具體指標(biāo)和維度組的關(guān)聯(lián),從而達(dá)到在基礎(chǔ)的行列之外,提供了各種“視圖”級別的權(quán)控,而每一個(gè)“視圖”是展示的最小單元。而資源內(nèi)的指標(biāo)維度叉乘關(guān)系是數(shù)據(jù)權(quán)限全集的真子集從而達(dá)到快速分配權(quán)限的目的。
?指標(biāo)消費(fèi)應(yīng)用管理模型:
當(dāng)一個(gè)指標(biāo)被申請消費(fèi)時(shí),需要知道被用在來什么平臺、什么端,應(yīng)用場景是什么樣的,從而來評估是否允許接入、是否需要重保、資源如何分配等。對此構(gòu)建消費(fèi)應(yīng)用管理模型,從指標(biāo)到資源、場景、應(yīng)用端、應(yīng)用平臺的關(guān)系把消費(fèi)血緣需要體現(xiàn)出的具體消費(fèi)情況都能涵蓋。
資產(chǎn)放心好用:
在數(shù)據(jù)知識系統(tǒng)化的前提下,需要大量對外開放,基于三道防線保障了日常和大促的資產(chǎn)放心好用,為系統(tǒng)穩(wěn)定運(yùn)行保駕護(hù)航:
?第一道防線:前置避免故障發(fā)生:
通過資源隔離來進(jìn)行各平臺、端甚至看板級別的隔離保障,保障的是一些非重保看板查詢變慢或者阻塞不影響其他核心業(yè)務(wù);壓測相關(guān)是在平臺層面上基于歷史調(diào)用采集分析對現(xiàn)實(shí)場景的高度還原,進(jìn)行全鏈路節(jié)點(diǎn)高保真壓測,并且針對壓測期間通過動(dòng)態(tài)別名切換技術(shù),來實(shí)現(xiàn)業(yè)務(wù)無損壓測及數(shù)據(jù)產(chǎn)品無感知壓測;在混沌工程演練上將核心的數(shù)據(jù)鏈路注入問題點(diǎn),自動(dòng)識別潛在風(fēng)險(xiǎn),防患于未然。
?
?第二道防線:巡檢與監(jiān)控,主動(dòng)發(fā)現(xiàn)
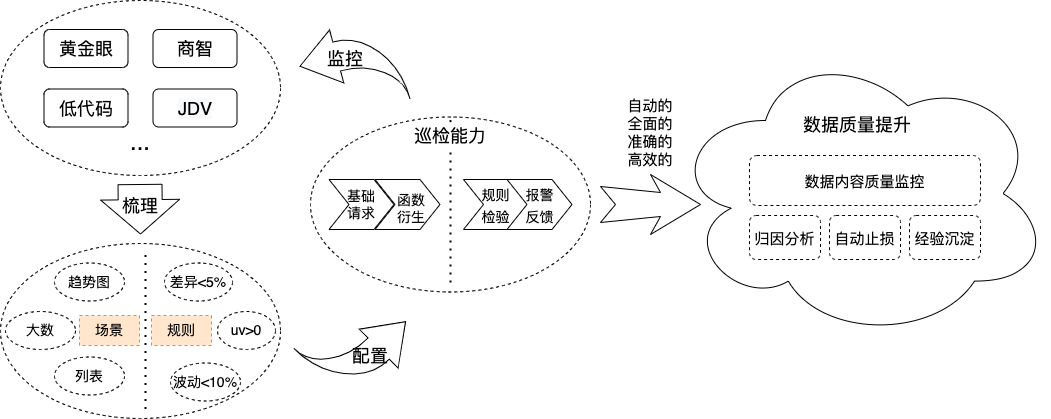
?
在態(tài)勢檢測及預(yù)警上,結(jié)合調(diào)用情況對預(yù)計(jì)算、預(yù)熱命中率等趨勢預(yù)警,防止有些預(yù)計(jì)算未命中或者預(yù)熱未覆蓋到的情況;在數(shù)據(jù)SRE的體系建設(shè)上,對調(diào)用情況通過全鏈路的uuid進(jìn)行串聯(lián),并進(jìn)行可視化展示,提升數(shù)據(jù)可觀測性,打破多系統(tǒng)監(jiān)控?cái)?shù)據(jù)孤島,提升監(jiān)控效率;巡檢能力是通過日常的訪問日志分析及梳理,以及各核心業(yè)務(wù)場景的輸入,如上圖所示,基于統(tǒng)一查詢服務(wù)的巡檢配置場景及對應(yīng)告警規(guī)則,結(jié)合巡檢自動(dòng)化任務(wù),可在任意時(shí)間按任意頻次動(dòng)態(tài)執(zhí)行任務(wù),防止數(shù)據(jù)空窗、跌0、異常波動(dòng)等情況。先于用戶無感的在系統(tǒng)層面發(fā)現(xiàn)問題;從發(fā)現(xiàn)、跟進(jìn)、分析、解決、經(jīng)驗(yàn)沉淀做到全流程自動(dòng)化。在實(shí)戰(zhàn)中巡檢的問題主要分以下幾類:
(1)對于實(shí)時(shí)數(shù)據(jù)異常的巡檢,第一時(shí)間發(fā)現(xiàn)后馬上進(jìn)行數(shù)據(jù)流切換,用戶完全無感知;
(2)BP的戰(zhàn)報(bào)、日報(bào)通過巡檢無需人工確認(rèn),自動(dòng)將結(jié)果發(fā)送給對應(yīng)業(yè)務(wù),可以及時(shí)介入;
(3)大促期間有很多指標(biāo)數(shù)據(jù)有“異常”大波動(dòng)(以23年618期間為例,巡檢發(fā)現(xiàn)16個(gè)線上異常情況),產(chǎn)品研發(fā)收到巡檢結(jié)果后第一時(shí)間進(jìn)行業(yè)務(wù)分析,從經(jīng)營狀態(tài)角度確保數(shù)據(jù)在預(yù)期之內(nèi)。
?第三道防線:應(yīng)急預(yù)案
對于一些已發(fā)生的問題,一定要有應(yīng)急預(yù)案才能真正做到臨危不亂,服務(wù)化對于限流、熔斷實(shí)現(xiàn)了精準(zhǔn)靶向,可做到針對某一個(gè)頁面的某個(gè)主題指標(biāo)進(jìn)行細(xì)粒度限流或者熔斷處理,也可做到整體的看板或者集群粒度的處理,保證容災(zāi)的靈活性。同時(shí)對降級策略有更友好的設(shè)計(jì),在降級后默認(rèn)返回兜底0的基礎(chǔ)上,通過緩存機(jī)制,可返回最后一次請求成功的結(jié)果,增加了系統(tǒng)靈活性及減少業(yè)務(wù)的損失。在應(yīng)急預(yù)案上由于壓力過大導(dǎo)致服務(wù)或容器出現(xiàn)異常時(shí),會(huì)應(yīng)急啟動(dòng)熱備容器,讓子彈飛一會(huì)兒,爭取更多的修復(fù)及問題定位時(shí)間。
存算成本集約化治理:
指標(biāo)體系開放,在生產(chǎn)、消費(fèi)間進(jìn)行系統(tǒng)化流轉(zhuǎn),基于指標(biāo)體系及指標(biāo)消費(fèi)應(yīng)用管理模型首次解決消費(fèi)鏈路可追蹤,結(jié)合指標(biāo)的生產(chǎn)血緣,形成清晰的全鏈路血緣。
打通全鏈路血緣的必要性主要基于以下三大視角:
(1)用戶視角:讓用戶從指標(biāo)展示入口(標(biāo)準(zhǔn)化產(chǎn)品、數(shù)據(jù)工具)到口徑與資產(chǎn)血緣清晰可見,知道數(shù)據(jù)從哪來、怎么來、怎么用。
(2)治理視角:通過數(shù)據(jù)標(biāo)準(zhǔn)消費(fèi)端反向治理,可清晰的知道某些模型或者表在消費(fèi)側(cè)的使用情況如何,訪問少或功能相似的看板做整合,關(guān)停并轉(zhuǎn),實(shí)現(xiàn)了從消費(fèi)價(jià)值來反推資產(chǎn)ROI。
(3)監(jiān)控視角:當(dāng)大促期間發(fā)現(xiàn)某一數(shù)據(jù)任務(wù)延遲或者某一實(shí)時(shí)流積壓時(shí),可通過血緣關(guān)系快速確定應(yīng)用上的影響范圍,從而能快速介入進(jìn)行分析并判斷是否公告用戶。
物化層:基于數(shù)據(jù)消費(fèi)行為(HBO)、系統(tǒng)內(nèi)置規(guī)則(RBO)自動(dòng)加速
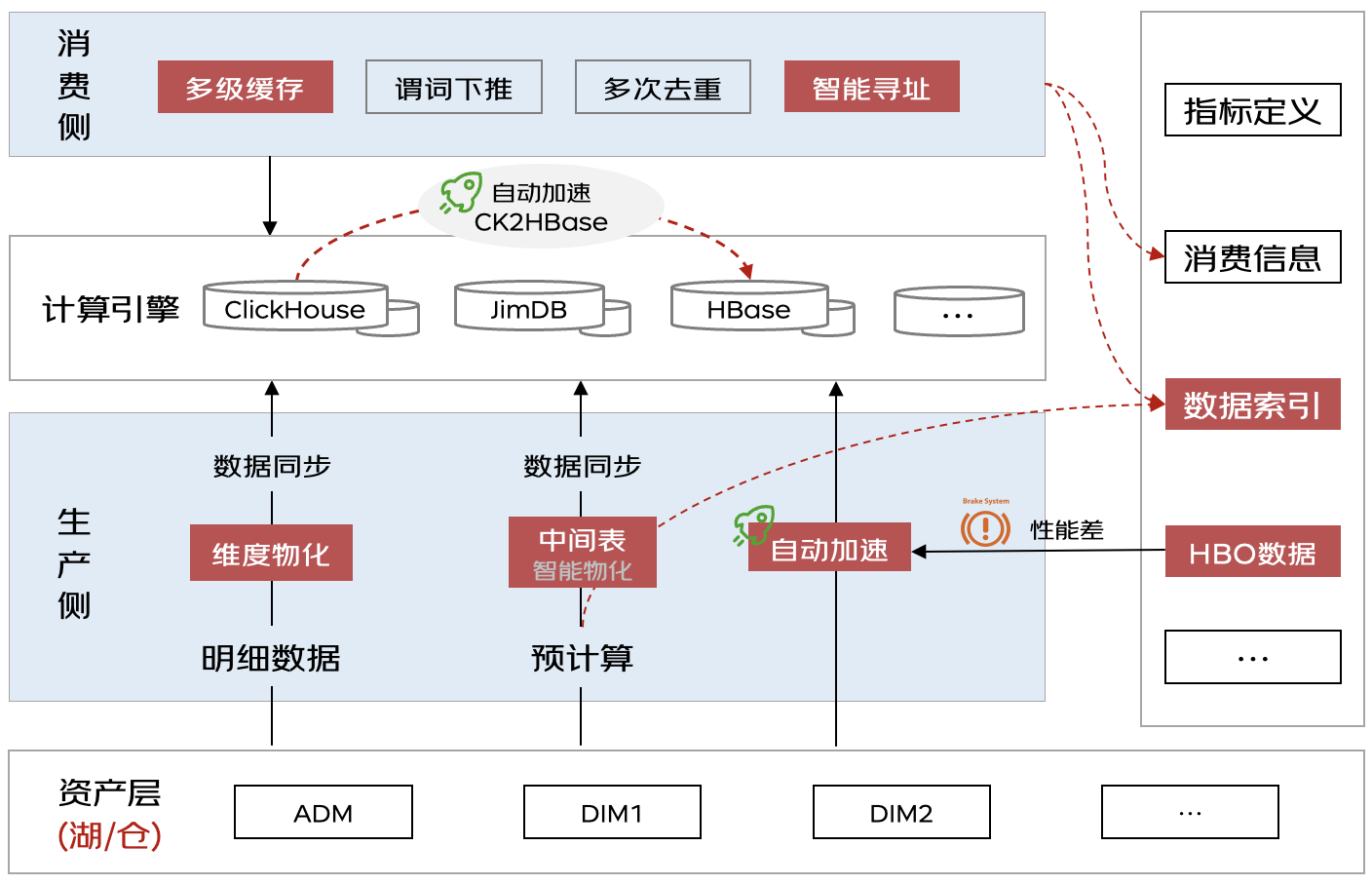
中間結(jié)果物化
大數(shù)據(jù)量預(yù)計(jì)算有著耗資源、易失敗的特點(diǎn),數(shù)據(jù)同步會(huì)因?yàn)榫W(wǎng)絡(luò)抖動(dòng)或集群異常造成同步失敗,整個(gè)鏈路失敗率高、重試成本高。用戶在定義驅(qū)動(dòng)生產(chǎn)只配置基于數(shù)倉做預(yù)計(jì)算,結(jié)果數(shù)據(jù)同步到目標(biāo)數(shù)據(jù)源,中間過程并沒有做配置。為提高任務(wù)穩(wěn)定性,系統(tǒng)內(nèi)置RBO判斷為預(yù)計(jì)算任務(wù)會(huì)自動(dòng)優(yōu)化生產(chǎn)路徑:首先生成預(yù)計(jì)算SQL,之后通過SQL做讀時(shí)建模,在數(shù)倉中自動(dòng)創(chuàng)建模型并將預(yù)計(jì)算結(jié)果數(shù)據(jù)寫入到模型中,模型會(huì)繼承邏輯表5W2H并寫到元數(shù)據(jù)中,避免模型重復(fù)創(chuàng)建。最后基于模型生成數(shù)據(jù)同步任務(wù)。這樣任務(wù)失敗只需要重跑預(yù)計(jì)算或同步任務(wù)即可,無需全鏈路重跑,降低任務(wù)重試成本。更為關(guān)鍵的是,系統(tǒng)會(huì)給中間結(jié)果(包含系統(tǒng)創(chuàng)建模型)配置生命周期,讓數(shù)據(jù)合理生產(chǎn)與消亡,如果不被下游依賴則會(huì)全部清理直至下次使用再創(chuàng)建,避免人工開發(fā)場景只生產(chǎn)不治理的情況。
雙流場景,定義驅(qū)動(dòng)生產(chǎn)內(nèi)配置雙流策略則會(huì)默認(rèn)生成一個(gè)計(jì)算任務(wù),中間結(jié)果物化到臨時(shí)表并基于中間表數(shù)據(jù)生成兩個(gè)同步主備集群的任務(wù)。
數(shù)據(jù)索引增強(qiáng)
多維分析場景中,經(jīng)常使用Groupings Sets將多個(gè)維度組合進(jìn)行計(jì)算,通常每個(gè)維度組合都對應(yīng)唯一編碼(命名為LVL code)供消費(fèi)側(cè)查詢使用。之前人工開發(fā)大多數(shù)據(jù)研發(fā)和服務(wù)研發(fā)共同維護(hù)維度組合與LVL code映射表,在腳本和服務(wù)中通過硬編碼方式實(shí)現(xiàn)雙方聯(lián)動(dòng),維護(hù)成本極高。定義驅(qū)動(dòng)生產(chǎn)判斷預(yù)計(jì)算目標(biāo)源是ClickHouse則自動(dòng)使用Groupings Sets生成輕聚合數(shù)據(jù),生產(chǎn)側(cè)通過調(diào)用生成LVL code函數(shù)獲取維度組合對應(yīng)的LVL code值,并自動(dòng)將二者寫入到"數(shù)據(jù)索引"表中,消費(fèi)側(cè)查詢時(shí)同樣通過"數(shù)據(jù)索引"表獲取編碼值生成SQL,生產(chǎn)、消費(fèi)自動(dòng)聯(lián)動(dòng)。
自動(dòng)加速與引擎優(yōu)選
除用戶手動(dòng)創(chuàng)建加速方式外,系統(tǒng)還支持基于代價(jià)與用戶消費(fèi)行為智能物化。用戶申請指標(biāo)填寫QPS、TP99兩個(gè)信息,用戶可在加速策略模塊選擇高階功能"智能物化",并可配置存儲上限、構(gòu)建頻率、構(gòu)建結(jié)束時(shí)間等信息。系統(tǒng)分析訪問日志,會(huì)對指標(biāo)+維度粒度TP99大于目標(biāo)值進(jìn)行自動(dòng)生成加速策略,默認(rèn)將數(shù)倉數(shù)據(jù)進(jìn)行預(yù)計(jì)算并同步到HBase中,系統(tǒng)判斷邏輯表配置了介質(zhì)加速 如HIVE2ClickHouse,則會(huì)通過引擎優(yōu)選功能判斷基于數(shù)倉和ClickHouse哪個(gè)計(jì)算更快、更省資源,一般會(huì)優(yōu)化為ClickHouse2HBase。
智能物化是整個(gè)系統(tǒng)的核心,解決業(yè)務(wù)敏捷與無序增長的困境,用戶定義完虛擬數(shù)據(jù)模型的業(yè)務(wù)邏輯后,引擎不會(huì)直接將其物化,而是按消費(fèi)端對模型字段的產(chǎn)出時(shí)間和查詢速度的要求,分析全局?jǐn)?shù)據(jù)的查詢情況,選擇性按全局最優(yōu)的策略進(jìn)行物化編排(通過物化視圖實(shí)現(xiàn)),并持續(xù)HBO優(yōu)化。
業(yè)務(wù)貢獻(xiàn)和價(jià)值
覆蓋數(shù)據(jù)中臺內(nèi)所有場景和數(shù)據(jù)團(tuán)隊(duì),零售內(nèi)4個(gè)C-1,及4個(gè)外部子集團(tuán)產(chǎn)研(如CHO、京東健康、京東工業(yè)、京東自由品牌)。日均4000w+次數(shù)據(jù)調(diào)用,支持零售8000+個(gè)指標(biāo),并支持了22個(gè)數(shù)據(jù)產(chǎn)品,覆蓋產(chǎn)研300+人。做到了無OLAP數(shù)據(jù)和服務(wù)端研發(fā)資源使用指標(biāo)服務(wù)平臺交付需求,數(shù)據(jù)整體交付效率由3天縮短到0.8天,提升需求交付效率70%。
3、數(shù)據(jù)展現(xiàn)篇--數(shù)據(jù)可視化工具
背景與挑戰(zhàn)
從行業(yè)來看,未來所有成功的企業(yè)都將是數(shù)字化轉(zhuǎn)型中表現(xiàn)卓越的組織。在數(shù)據(jù)展現(xiàn)能力上,持續(xù)探索數(shù)據(jù)可視化理論、豐富數(shù)據(jù)分析方法和可視化表達(dá),推動(dòng)數(shù)據(jù)可視化自動(dòng)化、場景化、智能化快速落地,助力京東各業(yè)務(wù)單元敏捷作戰(zhàn),激發(fā)個(gè)體創(chuàng)造力,不斷適應(yīng)市場和業(yè)務(wù)需求的變化。
技術(shù)先進(jìn)性
通過持續(xù)建設(shè)系統(tǒng)能力,賦能看板、報(bào)告、大屏、分析、提數(shù)等多個(gè)業(yè)務(wù)場景,同時(shí)從4大方向縱向拉通系統(tǒng)質(zhì)量保障建設(shè),提升系統(tǒng)穩(wěn)定性,最終實(shí)現(xiàn)在復(fù)雜多變的業(yè)務(wù)場景下,通過功能插拔、動(dòng)態(tài)配置,構(gòu)建一站式的解決方案,主要具備以下優(yōu)勢能力:
1.分析可視化組件:引用業(yè)界先進(jìn)的圖形語法理論結(jié)合SVG、D3等技術(shù)沉淀,自研9類可視化分析能力,如杜邦分析、異動(dòng)分析、交叉分析等。相較于行業(yè)方案,更加貼合京東零售業(yè)務(wù)分析思路。
2.低代碼編排:設(shè)計(jì)并實(shí)現(xiàn)了編排技術(shù)方案,包括狀態(tài)管理機(jī)制、可視化編排系統(tǒng)、數(shù)據(jù)集編排系統(tǒng)、代碼生成與注入系統(tǒng),可將萬行代碼的看板完全配置化實(shí)現(xiàn)。
3.PC、移動(dòng)端雙端支持:基于移動(dòng)端組件庫和低代碼平臺高效支持移動(dòng)分析訴求,支持多端、多網(wǎng)絡(luò)、多設(shè)備,交互體驗(yàn)媲美原生App。
4.報(bào)告、洞察等場景化能力:基于底層通用系統(tǒng)能力和能力基座打造。報(bào)告場景下業(yè)內(nèi)首次支持復(fù)雜數(shù)據(jù)PPT報(bào)告的自動(dòng)化輸出,大幅提升分析師效率。洞察場景下基于標(biāo)準(zhǔn)化協(xié)議實(shí)現(xiàn)洞察配置化,并支持快速橫向擴(kuò)展分析能力,高效支持不同業(yè)務(wù)場景下的問題自動(dòng)發(fā)現(xiàn)與診斷歸因。
以上數(shù)據(jù)可視化技術(shù)方案目前在零售內(nèi)得到充分應(yīng)用,有效支撐日常迭代和大促期間復(fù)雜多變的業(yè)務(wù)場景,能夠?qū)崿F(xiàn)降低研發(fā)成本,提升研發(fā)效率,完善用戶體驗(yàn)。
整體架構(gòu)介紹
在數(shù)據(jù)驅(qū)動(dòng)業(yè)務(wù)運(yùn)營的策略下,以高效靈活、場景化、智能化為目標(biāo),整合數(shù)據(jù)資產(chǎn)和工具,以可視化組件和低代碼平臺為核心,打造黃金眼、商智等標(biāo)桿的數(shù)據(jù)應(yīng)用,實(shí)現(xiàn)對不同業(yè)務(wù)場景的快速賦能。我們通過持續(xù)建設(shè)系統(tǒng)能力,賦能看板、報(bào)告、大屏、分析、提數(shù)等多個(gè)業(yè)務(wù)場景,同時(shí)從4大方向縱向拉通系統(tǒng)質(zhì)量保障建設(shè),提升系統(tǒng)穩(wěn)定性,最終實(shí)現(xiàn)在復(fù)雜多變的業(yè)務(wù)場景下,通過功能插拔、動(dòng)態(tài)配置,構(gòu)建一站式的解決方案。
?
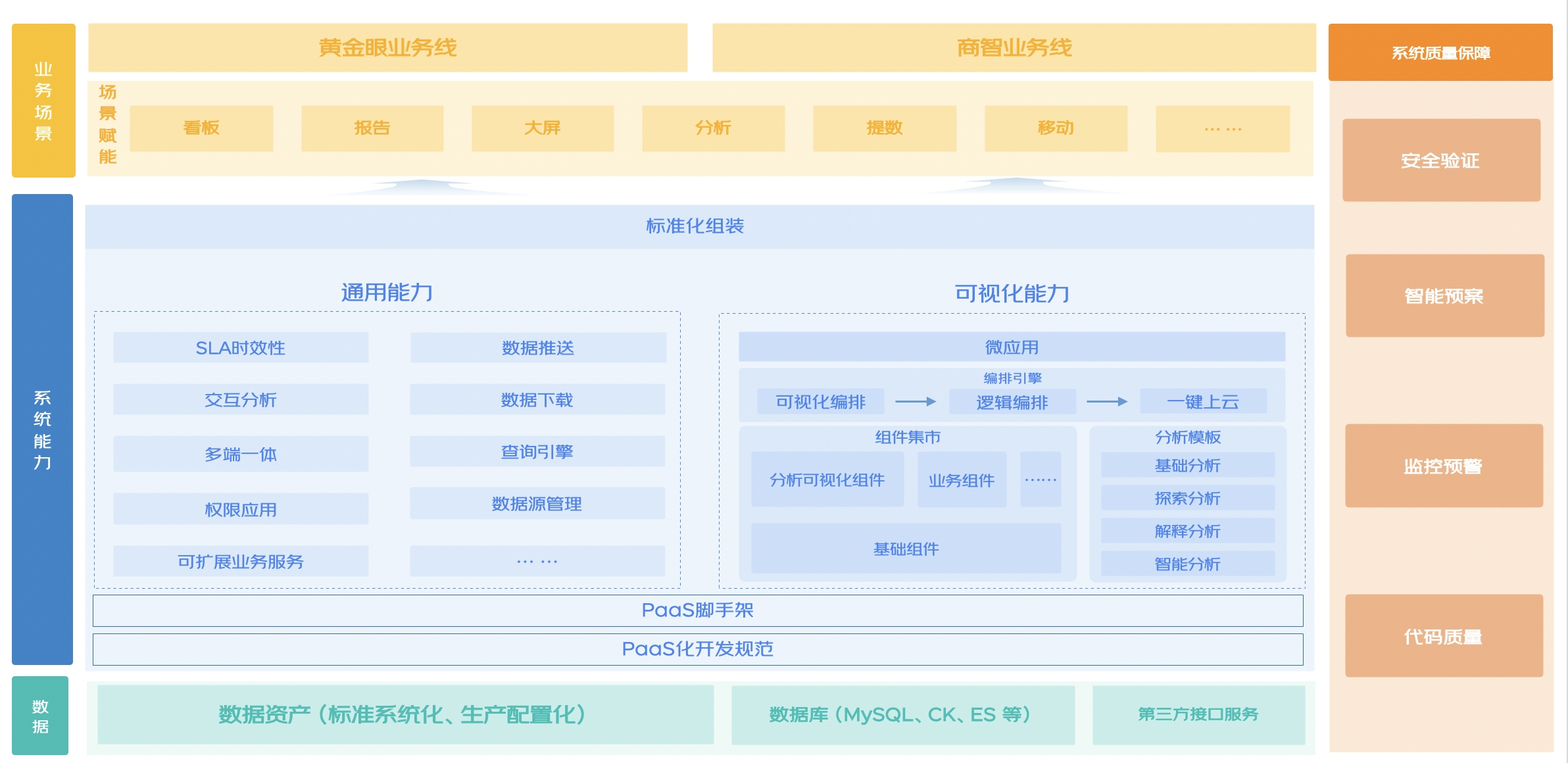
?
整體來看,數(shù)據(jù)分析可視化的能力建設(shè),主要可以分為PC端能力建設(shè)和移動(dòng)端能力建設(shè)兩個(gè)方向,接下來將從PC端的分析可視化組件建設(shè)、低代碼編排、數(shù)據(jù)推送,以及移動(dòng)端能力建設(shè)和多端一體建設(shè)幾個(gè)方向,詳細(xì)介紹數(shù)據(jù)分析可視化的核心技術(shù)方案以及在業(yè)務(wù)中的應(yīng)用。
詳細(xì)設(shè)計(jì)展開
分析可視化組件
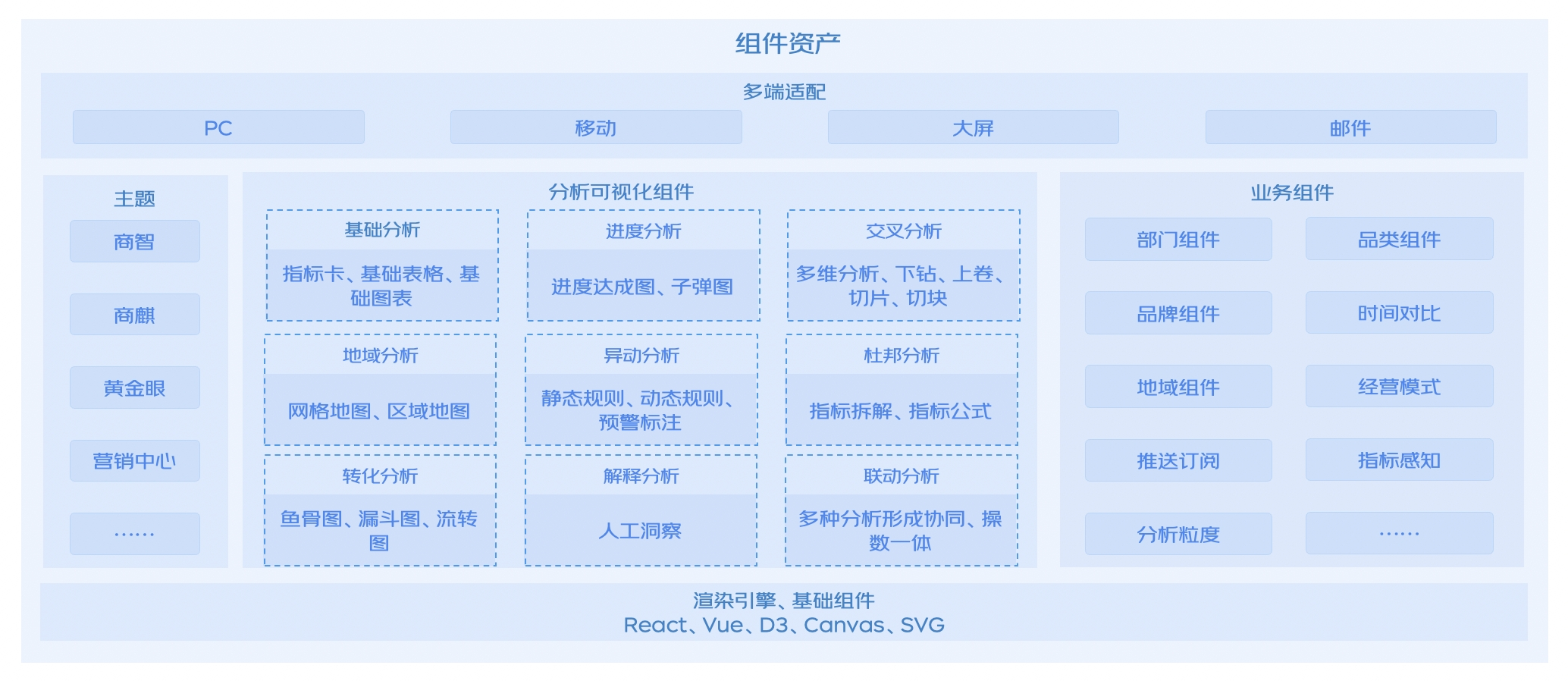
?
圖形語法理論
分析可視化組件底層均采用了業(yè)界先進(jìn)的圖形語法理論。圖形語法是一種將抽象基本元素組合成圖表的規(guī)則。圖形語法深層次地反應(yīng)出統(tǒng)計(jì)圖形的層次結(jié)構(gòu)。在圖形語法學(xué)中,一般統(tǒng)計(jì)圖表的規(guī)格主要包含6個(gè)要素:
?DATA:一組從數(shù)據(jù)集創(chuàng)建變量的數(shù)據(jù)操作
?TRANS:變量轉(zhuǎn)換(如排序)
?SCALE:度量(如對數(shù))
?COORD:一個(gè)坐標(biāo)系統(tǒng)(如極坐標(biāo))
?ELEMENT:圖形及其藝術(shù)審美屬性(如顏色)
?GUIDE:一個(gè)或多個(gè)輔助物(如軸線、圖例)
和傳統(tǒng)枚舉圖表相比,使用圖形語法生成每一個(gè)圖形的過程就是組合不同的基礎(chǔ)圖形語法。故而它的靈活和強(qiáng)大之處就在于,只需要改動(dòng)其中某一步驟,就能得到完全不同的、全新的圖表。
?

?
基于靈活的圖形語法理論基礎(chǔ),沉淀了大量可視化分析能力,接下來將具體介紹幾種特色能力。
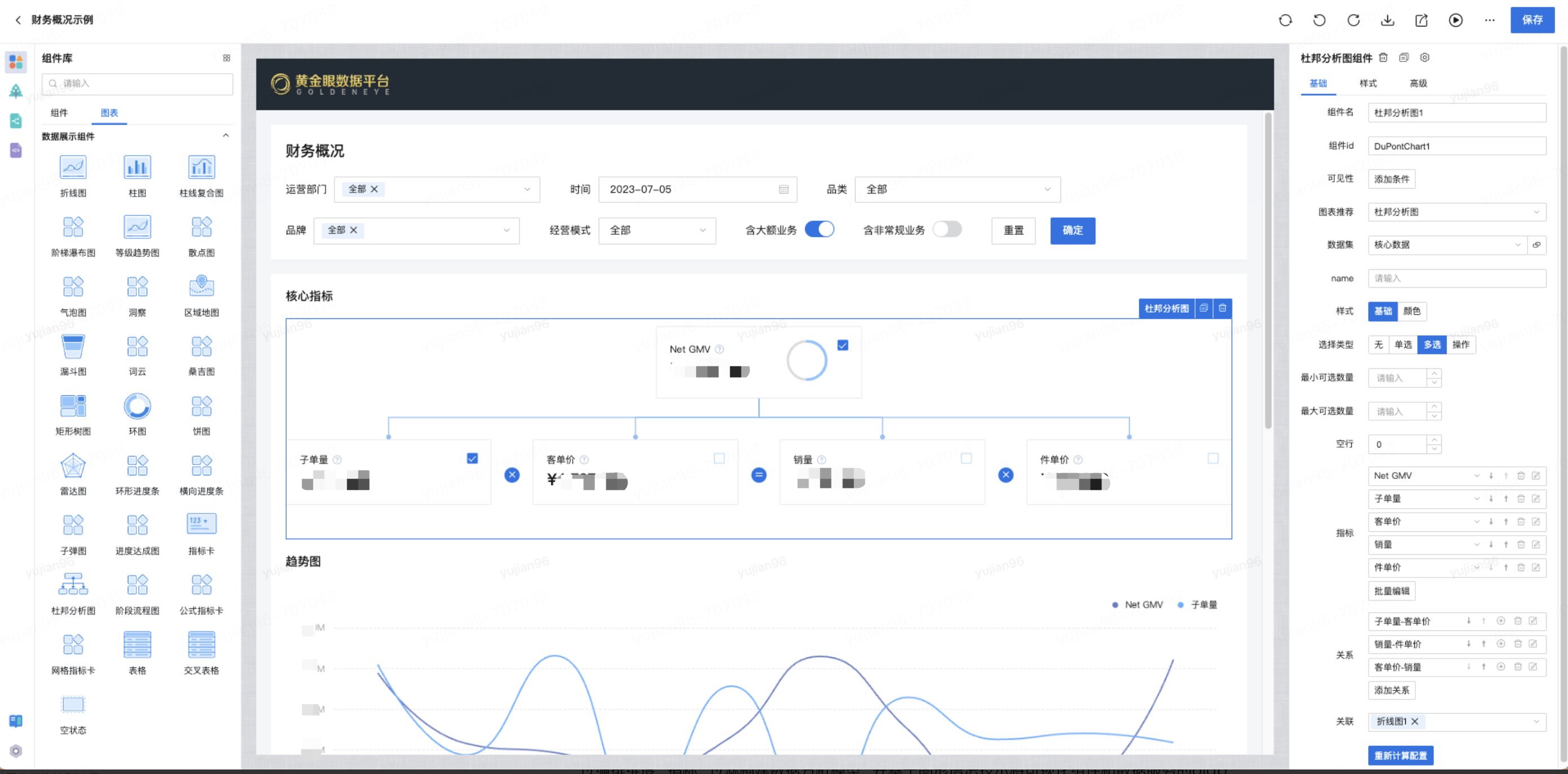
杜邦分析
杜邦分析法(DuPont Analysis)是一種綜合利用多個(gè)財(cái)務(wù)指標(biāo)比率關(guān)系來拆解企業(yè)財(cái)務(wù)狀況的分析方法。其基本思想是將企業(yè)凈資產(chǎn)收益率逐級分解為多項(xiàng)財(cái)務(wù)比率乘積,這樣有助于深入分析、比較企業(yè)的經(jīng)營業(yè)績。由于這種分析方法最早由美國杜邦公司使用,故名杜邦分析法。 使用杜邦分析法可以清晰描述指標(biāo)體系內(nèi)指標(biāo)的層次和指標(biāo)間的關(guān)系。如下圖所示,杜邦分析法通過樹形結(jié)構(gòu)自頂向下的展示了指標(biāo)間的構(gòu)成和層級關(guān)系,同時(shí)通過指標(biāo)之間的運(yùn)算符號清晰展現(xiàn)出指標(biāo)之間的計(jì)算關(guān)系,例如“凈資產(chǎn)收益率=總資產(chǎn)凈利率 * 權(quán)益乘數(shù)”、“總資產(chǎn)凈利率=銷售凈利率 * 總資產(chǎn)周轉(zhuǎn)率”、“銷售凈利率=凈利潤 / 銷售收入”、“總資產(chǎn)周轉(zhuǎn)率=銷售收入 / 資產(chǎn)總額”。采用這一方法,可使財(cái)務(wù)比率分析的層次更清晰、條理更突出,為報(bào)表分析者全面仔細(xì)地了解企業(yè)的經(jīng)營和盈利狀況提供方便。
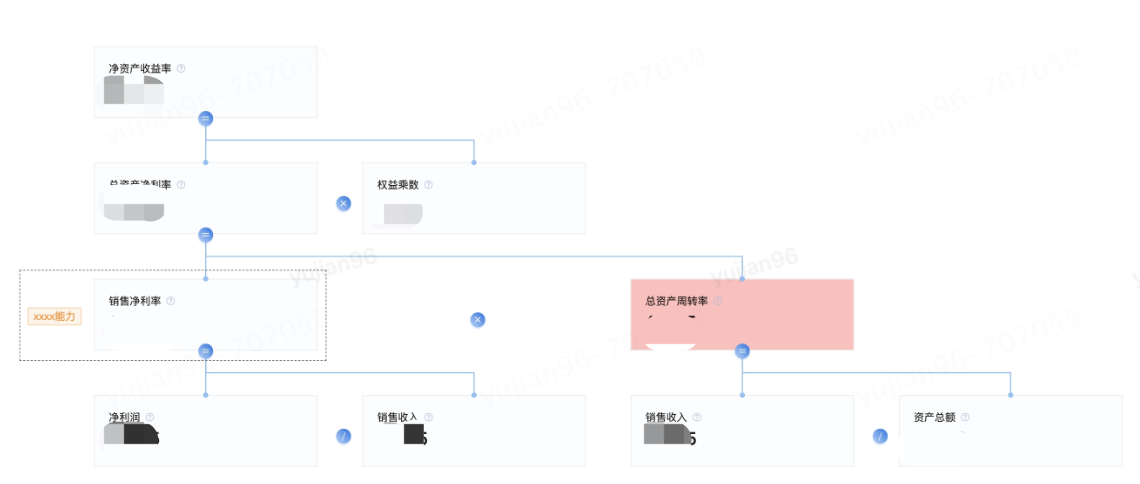
?布局策略:設(shè)計(jì)12種布局方案,分為兩大類:垂直方向(自頂向下、自底向上)、水平方向(自左向右、自右向左),通過d3-hierarchy對層次結(jié)構(gòu)數(shù)據(jù)進(jìn)行布局計(jì)算,實(shí)現(xiàn)node布局。
?節(jié)點(diǎn)關(guān)系:node節(jié)點(diǎn)關(guān)系繪制(父子、兄弟)、node節(jié)點(diǎn)輔助信息繪制(提示、預(yù)警等),實(shí)現(xiàn)關(guān)系ICON位置計(jì)算、輔助信息位置計(jì)算。
?交互:設(shè)計(jì)了收縮展開、縮放能力,支持大數(shù)量圖表的交互,通過viewBox實(shí)現(xiàn)。
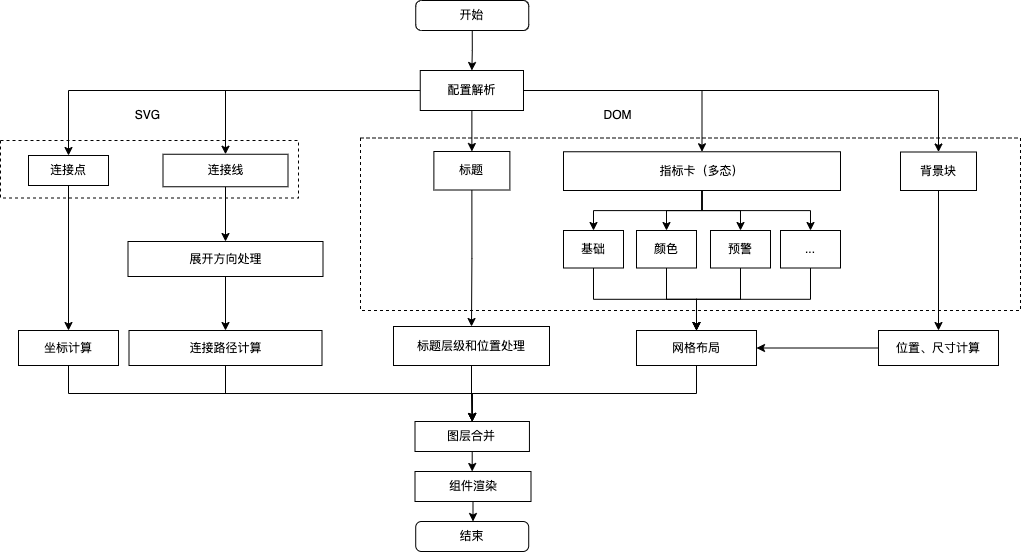
?異動(dòng)分析
在實(shí)際的業(yè)務(wù)場景中,為實(shí)現(xiàn)對全鏈路監(jiān)測部分的可視化展示,沉淀了可復(fù)用的可視化組件:網(wǎng)格指標(biāo)卡。該組件適用于異常監(jiān)控分析、全鏈路轉(zhuǎn)化分析等分析場景,主要包括以下幾部分:
?指標(biāo)卡:集成指標(biāo)卡全部功能,并通過對異常指標(biāo)的特殊標(biāo)識來達(dá)到預(yù)警能力
?流轉(zhuǎn)線:反映指標(biāo)間的轉(zhuǎn)化關(guān)系
?標(biāo)題:業(yè)務(wù)流程的標(biāo)識
主要的實(shí)現(xiàn)流程如下:
?
?
在具體的技術(shù)實(shí)現(xiàn)上,針對點(diǎn)、線、卡片的位置計(jì)算和繪制,采用了類似杜邦分析的技術(shù)思路,前端動(dòng)態(tài)計(jì)算節(jié)點(diǎn)、鏈接關(guān)系位置,并使用svg等前端技術(shù)進(jìn)行渲染。除此之外由于圖表結(jié)構(gòu)和邏輯比較復(fù)雜,如何設(shè)計(jì)該圖表的配置化方案,成為了另一個(gè)技術(shù)難點(diǎn)。為此,針對標(biāo)題部分我們抽離行、列標(biāo)題組,復(fù)用流程標(biāo)簽組件的配置邏輯;針對卡片本身,復(fù)用了原先指標(biāo)卡的配置邏輯;針對指標(biāo)卡的位置和連接關(guān)系,用戶能夠通過行列坐標(biāo)的設(shè)置和關(guān)系綁定來進(jìn)行細(xì)粒度配置,同時(shí)為了節(jié)省用戶的配置成本,組件會(huì)在初始化的時(shí)候進(jìn)行默認(rèn)編排。
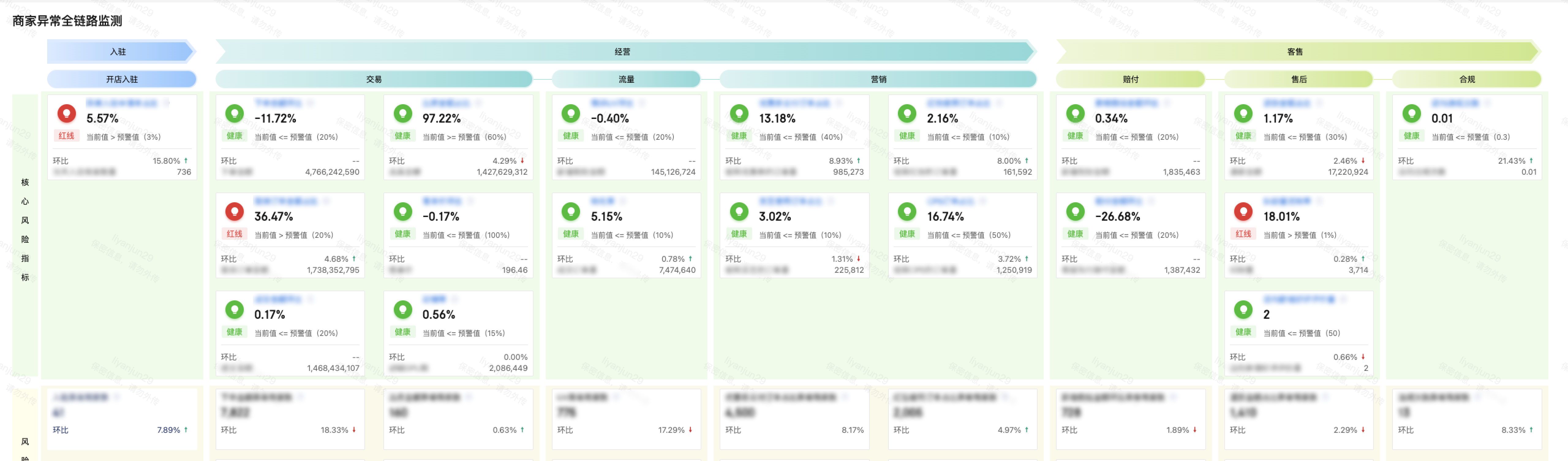
最終在商家異常全鏈路監(jiān)測需求中使用網(wǎng)格指標(biāo)卡組件,針對3個(gè)環(huán)節(jié)、7個(gè)模塊、19類的核心指標(biāo)與異常類型商家數(shù)量,讓用戶能夠從商家經(jīng)營整體環(huán)節(jié)通過預(yù)警功能進(jìn)行風(fēng)險(xiǎn)監(jiān)控和異常定位。
?
交叉分析
為解決復(fù)雜的數(shù)據(jù)分析場景,創(chuàng)建了一種基于React技術(shù)自研的交叉分析表格組件,將常見的表格操作與交叉數(shù)據(jù)分析的思路結(jié)合起來:在傳統(tǒng)可下鉆表格的基礎(chǔ)上,創(chuàng)新地抽取分析動(dòng)作層,能夠類比數(shù)據(jù)分析中的切片、切塊和下鉆思路,進(jìn)行數(shù)據(jù)分析,使用時(shí)允許用戶在多個(gè)合法維度中選擇,形成一條自定義下鉆路徑,成功地實(shí)現(xiàn)多種維度下,在表格中進(jìn)行可下鉆的交叉數(shù)據(jù)分析,滿足了多元復(fù)雜的數(shù)據(jù)分析需求。
?
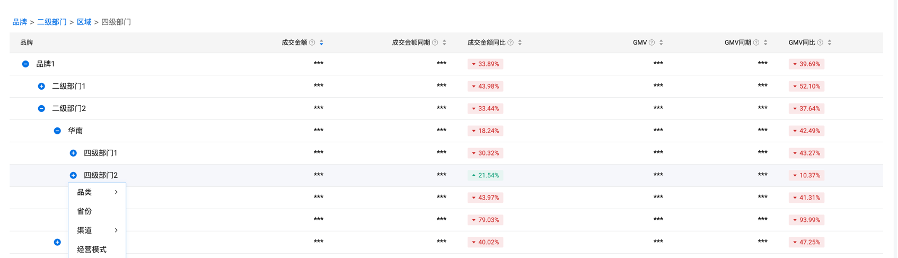
?
具體的實(shí)現(xiàn)原理是將表格的上卷下鉆邏輯與交叉數(shù)據(jù)分析邏輯結(jié)合起來,這里面的重點(diǎn)處理在于對從調(diào)用參數(shù)中過濾條件、維度字段和指標(biāo)字段的進(jìn)行動(dòng)態(tài)處理,從而實(shí)現(xiàn)交叉分析的數(shù)據(jù)獲取查詢。首先,對維度字段和指標(biāo)字段分別進(jìn)行遍歷,能夠獲取到過濾條件、維度字段和指標(biāo)字段這三種參數(shù),對于同一個(gè)表格來說,數(shù)據(jù)查詢的返回字段是一致的,于是在每一次遍歷中,都可以在查詢字段結(jié)果中增加一項(xiàng),用于構(gòu)建最終數(shù)據(jù)查詢的結(jié)果集;接下來,從第一步觸發(fā)下鉆的的動(dòng)作中,獲取到父層級的維度信息和具體的值,設(shè)置為過濾條件,通過這一步,可以查詢出當(dāng)前父級條件下的數(shù)據(jù);接下來,同理如果該維度是子級維度,那么就把該維度條作為聚合維度進(jìn)行操作;最后,將上述封裝好的操作條件,傳遞給后端進(jìn)行查詢,并將獲取到的數(shù)據(jù),根據(jù)父級指標(biāo)的維度值,拼接到該項(xiàng)的子節(jié)點(diǎn)字段中,這樣便語義化的可以了“在父級維度某個(gè)維值的過濾條件下,按子級維度聚合的”數(shù)據(jù),再整體將最新的數(shù)據(jù)拼接到的表格數(shù)據(jù)中,至此便實(shí)現(xiàn)了交叉數(shù)據(jù)分析的分析動(dòng)作。
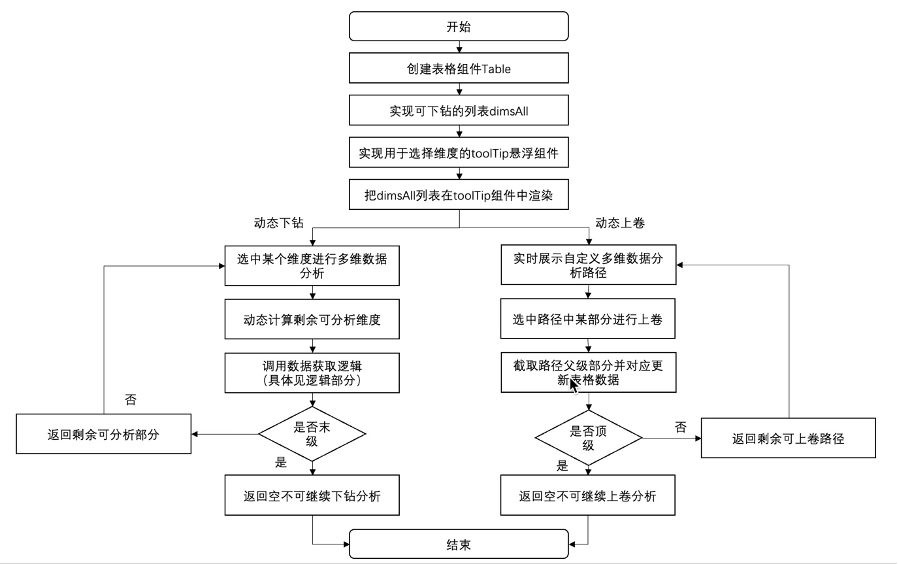
?
自動(dòng)化分析
在沉淀分析可視化組件的同時(shí),也在自動(dòng)化、智能化的數(shù)據(jù)分析方面進(jìn)行探索和建設(shè)。其核心思路是,通過貢獻(xiàn)度和基尼系數(shù)等算法,計(jì)算出最需要關(guān)注的品牌、品類等,并基于增強(qiáng)分析技術(shù),如洞察文案生成技術(shù)和圖表標(biāo)注技術(shù)等,自動(dòng)生成數(shù)據(jù)報(bào)告。
同時(shí),基于自動(dòng)分析結(jié)果,還可以進(jìn)一步通過多因素分析等可視化分析組件進(jìn)行更深入的探查。基于表格組件,通過組件聯(lián)動(dòng)能力,組合多個(gè)表格形成聯(lián)動(dòng)下鉆分析。
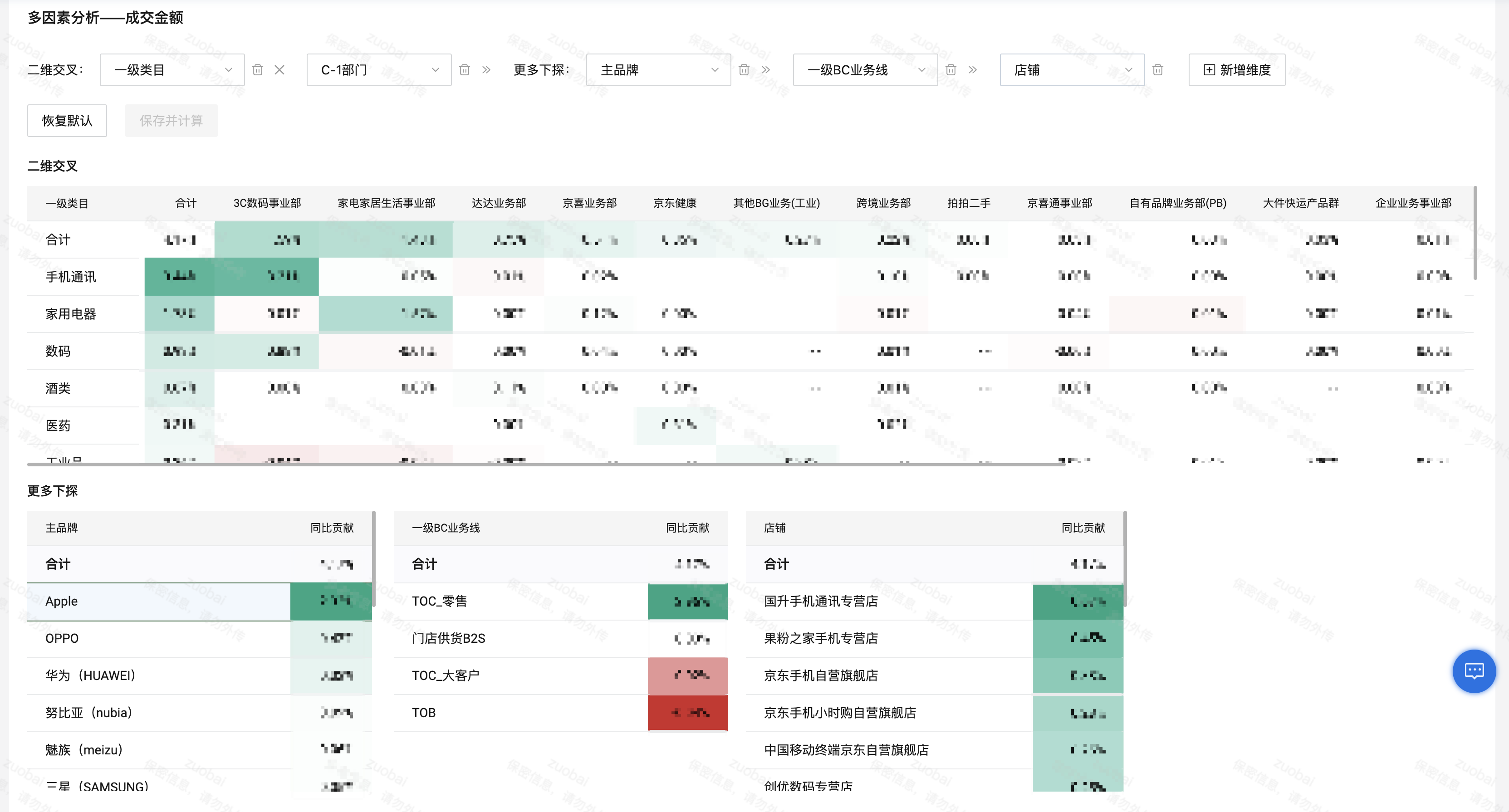
?
低代碼編排
數(shù)據(jù)產(chǎn)品頁面具有復(fù)雜的業(yè)務(wù)邏輯。一方面頁面布局復(fù)雜,一個(gè)頁面可能包含數(shù)十種組件,涵蓋布局、篩選、可視化等多種組件;另一方面組件間存在大量聯(lián)動(dòng)邏輯,如篩選組件間聯(lián)動(dòng)、篩選組件和可視化組件聯(lián)動(dòng)、可視化組件間的聯(lián)動(dòng)以及和外部系統(tǒng)的聯(lián)動(dòng)等;此外,業(yè)務(wù)場景靈活多變,例如在作戰(zhàn)單元模式下,Boss、采、銷、控等角色數(shù)據(jù)分析思路均不一致:這些都對編排能力提出了極大的挑戰(zhàn)。為解決這個(gè)問題,持續(xù)調(diào)研學(xué)習(xí)行業(yè)先進(jìn)的低代碼技術(shù)理論,同時(shí)結(jié)合數(shù)據(jù)產(chǎn)品的特性,設(shè)計(jì)并實(shí)現(xiàn)了一整套編排技術(shù)方案。
首先是自研了基于MVC模型的JMT狀態(tài)管理框架,在redux的基礎(chǔ)上,升級了狀態(tài)的更新和變化響應(yīng)機(jī)制,支持復(fù)雜異步狀態(tài)管理,以一種通用狀態(tài)模型支撐了數(shù)據(jù)產(chǎn)品邏輯的配置化。
?
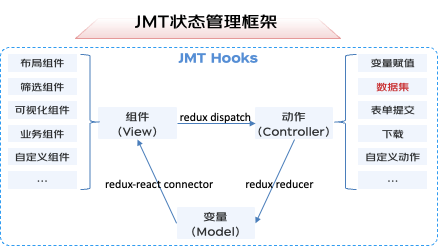
?
其次是基于JMT組件庫自研了可視化編排系統(tǒng),一方面,通過多種靈活的布局組件,支持復(fù)雜頁面布局的編排。另一方面,提供了靈活的組件配置面板,除常規(guī)樣式的編排外,還充分發(fā)揮底層數(shù)據(jù)可視化能力,支持如杜邦分析等指標(biāo)關(guān)系的編排。此外,通過對底層React框架的靈活使用,創(chuàng)新組件嵌套機(jī)制,支持可視化組件互相嵌入形成聯(lián)動(dòng)分析,如在杜邦分析中既展示GMV的拆解,也展示GMV的達(dá)成進(jìn)度等。
?
第三是構(gòu)建數(shù)據(jù)產(chǎn)品特有的數(shù)據(jù)集編排系統(tǒng),支持對數(shù)據(jù)資產(chǎn)、EasyData等多種數(shù)據(jù)源,通過編排維度、指標(biāo)、過濾構(gòu)建數(shù)據(jù)分析模型,并基于圖形語法技術(shù)將可視化組件和數(shù)據(jù)服務(wù)的olap能力做充分打通,實(shí)現(xiàn)數(shù)據(jù)驅(qū)動(dòng)可視化。
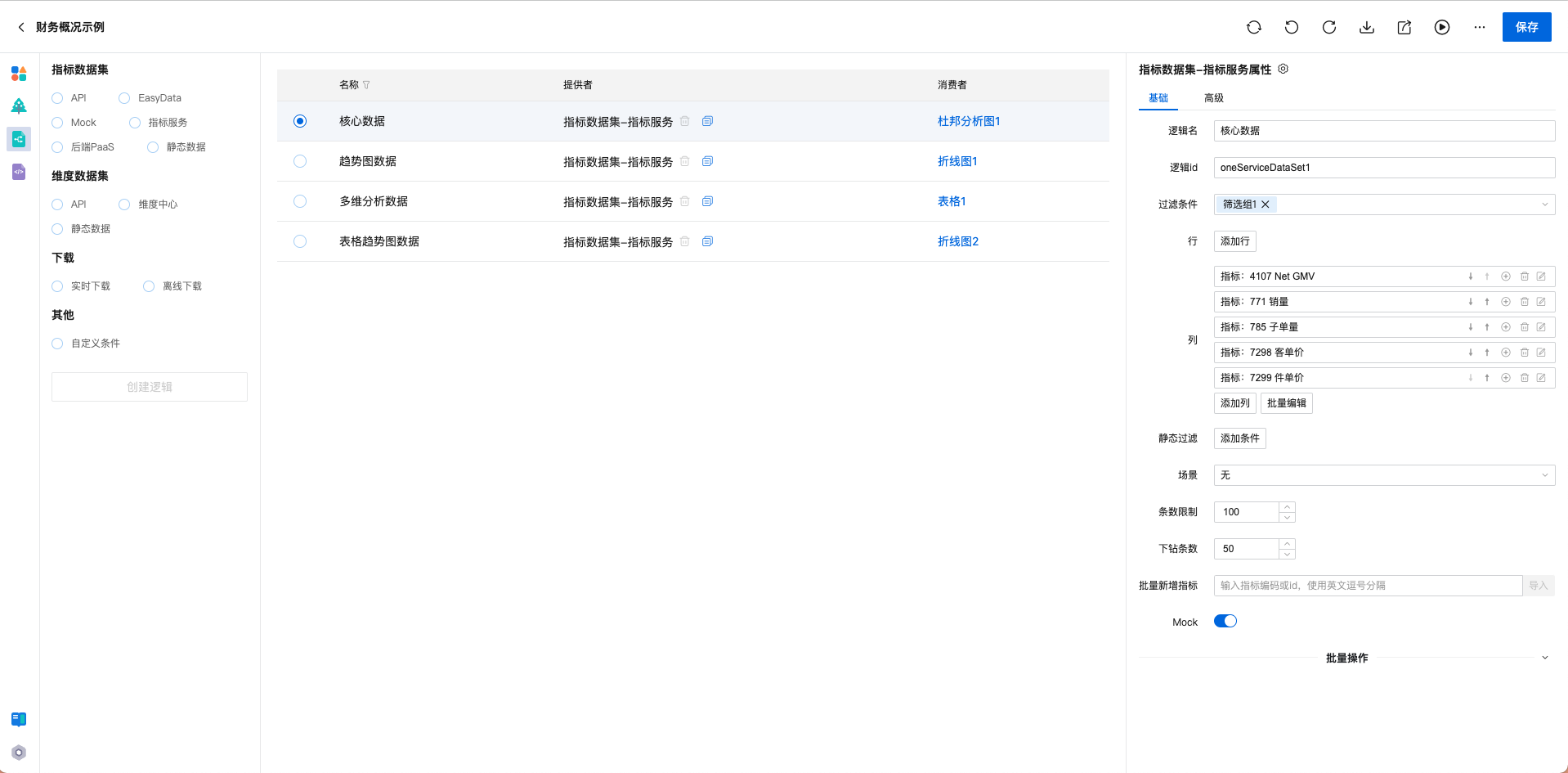
第四是自研了一套代碼生成和注入系統(tǒng)。可視化編排和邏輯編排使用一套標(biāo)準(zhǔn)Schema進(jìn)行驅(qū)動(dòng),在頁面發(fā)布時(shí),會(huì)基于Schema,結(jié)合React和JMT狀態(tài)管理,自動(dòng)生成代碼。此外,對于頁面中的尚未被組件功能覆蓋的個(gè)性化邏輯,可以通過代碼注入,配合JMT函數(shù)庫快速解決。在百億補(bǔ)貼等緊急需求中,代碼注入功能解決了大量個(gè)性化邏輯,在時(shí)間緊任務(wù)重的情況下,保質(zhì)保量交付需求。
?
數(shù)據(jù)推送
郵件作為現(xiàn)有工作模式下一種不可或缺的通信方式,在郵件里查看看板數(shù)據(jù)(定時(shí)匯總為小時(shí)/日/周/月等不同時(shí)間粒度),成為諸多用戶的強(qiáng)烈訴求。
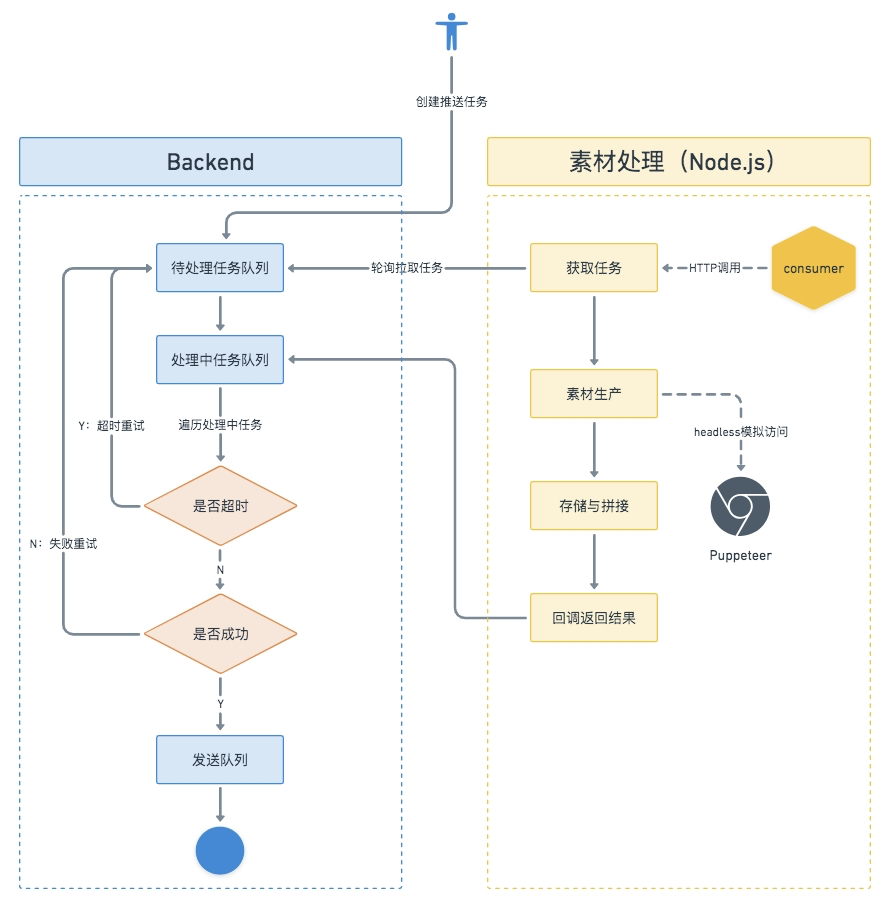
各業(yè)務(wù)服務(wù)調(diào)用統(tǒng)一的后端服務(wù)創(chuàng)建定時(shí)推送任務(wù),任務(wù)通過前置配置項(xiàng)檢查后,被添加到消費(fèi)隊(duì)列中依次處理,處理的產(chǎn)物包括圖片、Email HTML、附件等,最終按照用戶配置的觸發(fā)方式推送出去。
下圖梳理出任務(wù)處理的關(guān)鍵流程:素材處理服務(wù)(Node)主要承擔(dān)推送任務(wù)消費(fèi)及提供獲取素材的HTTP服務(wù)兩大功能。在任務(wù)消費(fèi)過程中,素材處理服務(wù)會(huì)模擬用戶權(quán)限打開瀏覽器去做頁面Canvas圖像轉(zhuǎn)換、看板截圖、PDF生成等操作。如果觸達(dá)方式為郵件,則會(huì)將所有素材填充生成為Email Html文本文件,通過回調(diào)返回給后端,推送給用戶呈現(xiàn)的內(nèi)容是數(shù)據(jù)看板。
?
?
在素材生產(chǎn)過程中,服務(wù)通過捕獲屏幕快照來實(shí)現(xiàn)這一目的。但是某些情況下,比如設(shè)備性能較差或者頁面進(jìn)行縮放而Canvas圖像尺寸沒有隨之調(diào)整時(shí),快照圖片會(huì)變得模糊。為了解決這個(gè)問題,我們直接獲取Canvas對象。通過Chrome DevTools協(xié)議,可以將JS代碼發(fā)送到瀏覽器并在上下文中執(zhí)行,執(zhí)行結(jié)果會(huì)被序列化為JSON格式返回給Node.js環(huán)境,從而達(dá)到Node服務(wù)與chromium上下文通信的目的。
在處理階段,由于Canvas對象是Web API的一部分,只能在瀏覽器環(huán)境中使用。而常用的Node下操作Canvas的工具包幾乎都依賴底層的圖形庫,例如Cairo或Skia等。這對于開發(fā)環(huán)境(MacOS)和部署環(huán)境(CentOS)不一致的研發(fā)來說,調(diào)試難度較大。為了解決這個(gè)問題,通過Node.js環(huán)境提供的Buffer對象承接Canvas對象的Data URL,配合JPEG圖像編解碼器處理。這樣就無需考慮底層圖形庫的兼容性和安裝問題,實(shí)現(xiàn)素材圖片的順利生成。
?

?
依托于數(shù)據(jù)推送和低代碼能力組合的建設(shè),在618大促期間,已將其應(yīng)用到業(yè)務(wù)小時(shí)報(bào)、作戰(zhàn)單元日報(bào)中,快速實(shí)現(xiàn)了基于看板的批量報(bào)告功能,幫助3C、大商超等數(shù)據(jù)BP快速實(shí)現(xiàn)面向作戰(zhàn)單元的日報(bào)和小時(shí)報(bào)推送,為多場景報(bào)告做到了很好的支撐。
移動(dòng)端能力
通過復(fù)用PC端的低代碼編排能力,利用jmtm基礎(chǔ)組件庫和jmtm-charts圖表庫,能夠快速搭建起移動(dòng)端的數(shù)智化分析功能。
?
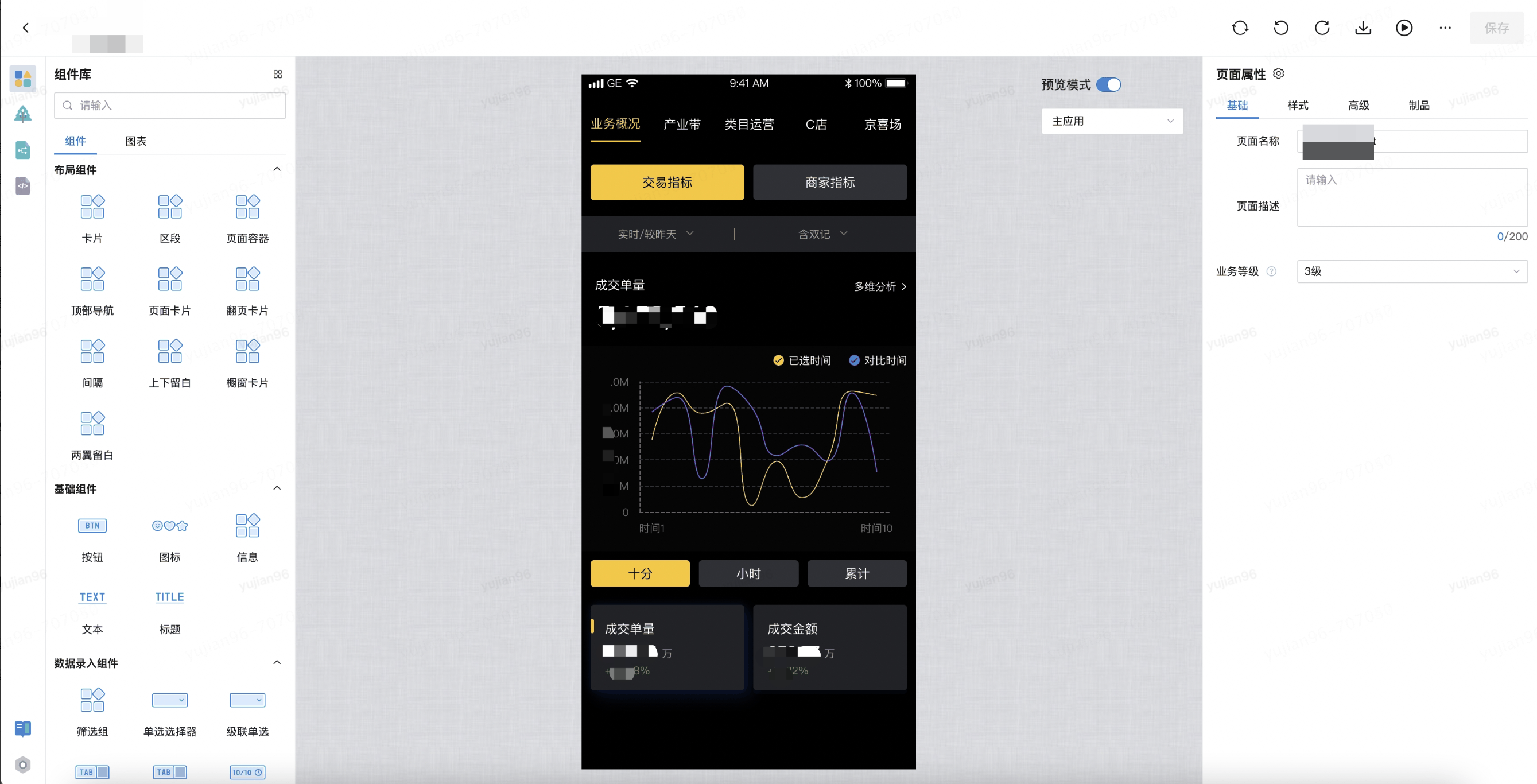
針對移動(dòng)端看數(shù)場景,使用自研的主題配置工具:將組件字號、顏色、圓角、尺寸等樣式變量化,從而可以根據(jù)具體需求進(jìn)行靈活配置。其中色板變量的引入保證了組件庫的底色充足,而公共變量的使用則提高了配置效率。另外我們還引入組件變量,實(shí)現(xiàn)個(gè)性化的定制需求。支持在線預(yù)覽和一鍵發(fā)布等功能:用戶可以通過在線預(yù)覽功能,在配置過程中即時(shí)查看效果;一鍵發(fā)布功能則可以快速將配置好的主題應(yīng)用到移動(dòng)端低代碼平臺中。
針對移動(dòng)端的性能優(yōu)化,通過優(yōu)化動(dòng)效的執(zhí)行時(shí)機(jī),將動(dòng)畫交互與耗時(shí)的DOM渲染分離開來,提高動(dòng)效的流暢度,減少頁面加載時(shí)的卡頓感,確保用戶能夠得到良好的交互體驗(yàn)。
針對移動(dòng)端多頁面交互場景,創(chuàng)造性的采用類似原生多開webview的翻頁卡片機(jī)制并對多個(gè)頁面進(jìn)行緩存處理,使整個(gè)應(yīng)用體驗(yàn)更加接近原生化。基于多人協(xié)作及應(yīng)用的可擴(kuò)展性考慮,我們借鑒業(yè)內(nèi)成熟的微應(yīng)用方案,并結(jié)合自身需求場景,支持微應(yīng)用嵌套微應(yīng)用的方案,為較復(fù)雜應(yīng)用的場景提供了可能。
多端一體建設(shè)
為了提高研發(fā)效率并滿足用戶在不同端的看數(shù)需求,我們在PC端邏輯編排的基礎(chǔ)上引入了hybrid概念,使編排引擎可以發(fā)布到移動(dòng)端的多個(gè)產(chǎn)品線。在頁面打包及部署過程中,使用webpack插件jmtbuild-hybird-plugin,發(fā)布為能適配到多端的js-sdk資源。最后通過前端微服務(wù)平臺在對應(yīng)的容器中加載并展示頁面。
通過低代碼平臺生成的標(biāo)準(zhǔn)頁面需要在不同的業(yè)務(wù)端進(jìn)行展示,在權(quán)限方面,針對嵌入到客戶端的場景進(jìn)行了token校驗(yàn),對于瀏覽器H5,采用cookie解析的方式進(jìn)行登錄校驗(yàn)和數(shù)據(jù)安全保護(hù)。標(biāo)準(zhǔn)頁面默認(rèn)在公司內(nèi)網(wǎng)進(jìn)行訪問,使用colorAdapter適配器函數(shù)可以使接口一鍵轉(zhuǎn)化,接入網(wǎng)關(guān)。網(wǎng)關(guān)統(tǒng)一接入了神盾、反扒、防刷等功能,保障外網(wǎng)訪問的數(shù)據(jù)和網(wǎng)絡(luò)安全。
業(yè)務(wù)貢獻(xiàn)和價(jià)值
在研發(fā)提效方面:在大促期間Boss作戰(zhàn)單元的模式下,在戰(zhàn)報(bào)的應(yīng)用場景上,通過低代碼加數(shù)據(jù)推送能力的快速整合,在兩周內(nèi),支持多個(gè)部門的報(bào)告推送,累計(jì)推送戰(zhàn)報(bào)7220封;此外,在百億補(bǔ)貼重點(diǎn)項(xiàng)目中,面對緊急多變的業(yè)務(wù)場景,協(xié)同業(yè)務(wù)團(tuán)隊(duì)通過低代碼線上配置化+二次開發(fā)的方式,2周內(nèi)交付5個(gè)看板、2個(gè)大屏,80%的需求在24小時(shí)內(nèi)交付。
在創(chuàng)新業(yè)務(wù)支持方面:業(yè)務(wù)對體系化看數(shù)需求強(qiáng)烈,期望使用移動(dòng)端查看業(yè)績達(dá)成情況。通過移動(dòng)端低代碼能力,僅用1個(gè)產(chǎn)品經(jīng)理、4個(gè)數(shù)據(jù)研發(fā)短時(shí)間內(nèi)從0到1打造出一個(gè)基于低代碼的黃金眼移動(dòng)端應(yīng)用,快速解決業(yè)務(wù)移動(dòng)端看數(shù)的訴求。
此外,隨著零售架構(gòu)扁平調(diào)整,Boss單元需要更高效的數(shù)字化決策工具,自動(dòng)化分析能力也得到了充分的應(yīng)用:基于豐富的可視化組件和低代碼編排能力,結(jié)合后端的智能化算法,快速打造零售自動(dòng)化分析看板,應(yīng)用于每日的經(jīng)營過程控制中,將診斷提前至每天的工作中,以提高發(fā)現(xiàn)問題和解決問題時(shí)效。
展望未來,我們會(huì)持續(xù)打磨現(xiàn)有能力,并不斷結(jié)合新的業(yè)務(wù)場景和行業(yè)調(diào)研,沉淀新的數(shù)據(jù)可視化分析能力。首先在智能化方向上,會(huì)基于圖形語法的可視化理論,并整合AI等能力,建設(shè)增強(qiáng)分析能力,打造增強(qiáng)圖表和自動(dòng)化報(bào)表,實(shí)現(xiàn)自動(dòng)洞察數(shù)據(jù)關(guān)聯(lián)、異常及趨勢等,將數(shù)據(jù)分析從描述性分析躍升到預(yù)測性分析和決策性分析;同時(shí)在質(zhì)量體系建設(shè)方面,會(huì)從監(jiān)控預(yù)警、代碼質(zhì)量等方向持續(xù)建設(shè),在不斷提升交付效率的同時(shí)持續(xù)提升交付質(zhì)量:最終期望能夠通過數(shù)據(jù)分析技術(shù)能力的綜合運(yùn)用,降低研發(fā)成本,提升研發(fā)效率,完善用戶體驗(yàn),高效推進(jìn)人人都是分析師的戰(zhàn)略落地。
4、數(shù)據(jù)智能篇-- 基于大模型的智能化應(yīng)用
背景與挑戰(zhàn)
目前,數(shù)據(jù)分析服務(wù)主要通過數(shù)據(jù)產(chǎn)品、BI工具和配備數(shù)據(jù)分析師等方式來支持,在數(shù)據(jù)響應(yīng)效率、分析能力應(yīng)用的廣度、深度和頻率等方面各有不足,但業(yè)務(wù)時(shí)常需要通過數(shù)據(jù)驅(qū)動(dòng)決策,就出現(xiàn)了數(shù)據(jù)獲取難、數(shù)據(jù)分析難等用戶痛點(diǎn)。大模型在數(shù)據(jù)消費(fèi)領(lǐng)域的應(yīng)用,為用戶痛點(diǎn)的解決帶來了新的思路。
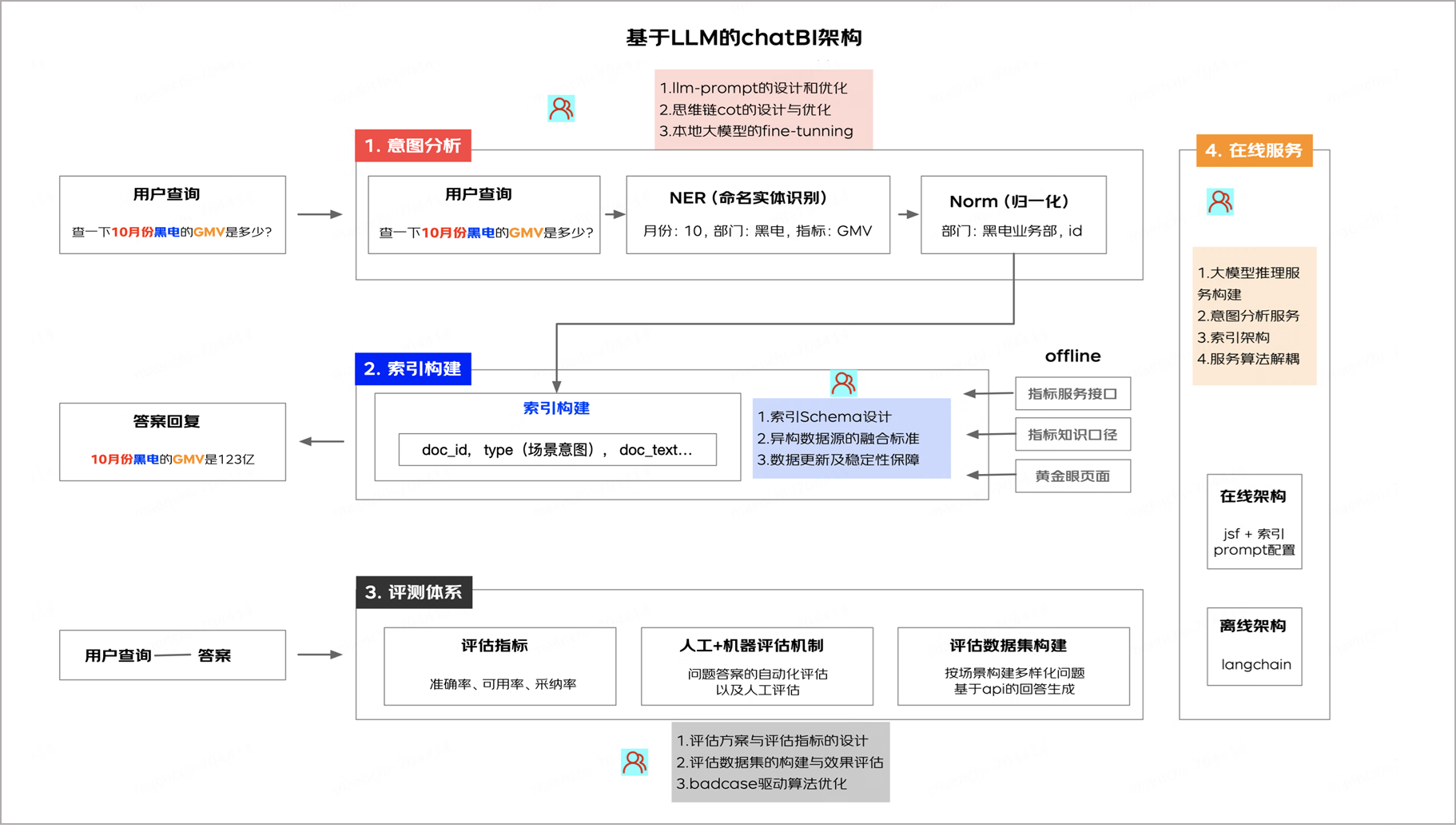
基于LLM的解決方案
對于京東復(fù)雜的業(yè)務(wù)和數(shù)據(jù)體系,大模型在數(shù)據(jù)服務(wù)領(lǐng)域的應(yīng)用很有價(jià)值,同時(shí)也面臨著挑戰(zhàn)。當(dāng)前的架構(gòu)設(shè)計(jì)充分考慮了已具備的底層數(shù)據(jù)服務(wù)能力,結(jié)合LLM實(shí)體識別、上下文推理、決策輔助能力將用戶查詢與復(fù)雜數(shù)據(jù)集的相關(guān)指標(biāo)匹配,實(shí)現(xiàn)快速準(zhǔn)確的數(shù)據(jù)查詢。通過NER識別將用戶的篩選條件、查詢指標(biāo)、聚合方式抽取出來,利用Norm(歸一化)把實(shí)體轉(zhuǎn)換成標(biāo)準(zhǔn)數(shù)據(jù)服務(wù)的調(diào)用參數(shù),并且構(gòu)建索引將歸一化依賴的數(shù)據(jù)資產(chǎn)進(jìn)行存儲,來實(shí)現(xiàn)自然語言查詢準(zhǔn)確數(shù)據(jù)的全鏈路,與此同時(shí),建立完善的評估體系、利用本地模型優(yōu)化等機(jī)制,不斷提升應(yīng)答準(zhǔn)確率,為用戶帶來更優(yōu)質(zhì)的使用體驗(yàn)。
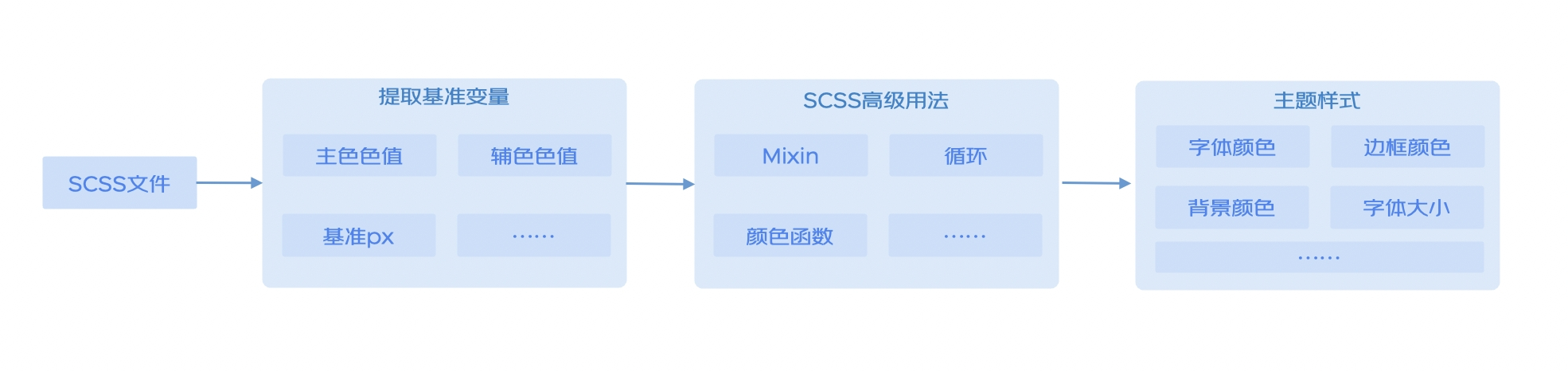
基于業(yè)務(wù)知識和數(shù)據(jù)知識的Prompt工程
Prompt工程建設(shè)
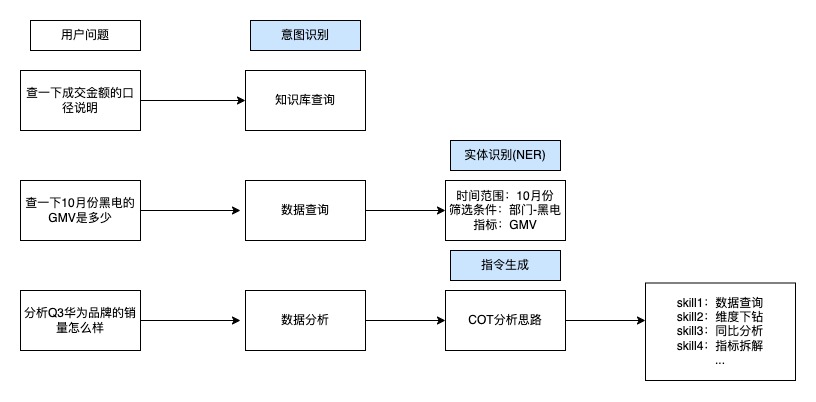
?目標(biāo)確認(rèn):針對用戶對數(shù)據(jù)的訴求,整理用戶問題確定輸入數(shù)據(jù),基于不同任務(wù)目標(biāo)確認(rèn)不同輸出格式,如實(shí)體識別輸出標(biāo)準(zhǔn)格式的{實(shí)體類別:實(shí)體名稱},指令生成輸出標(biāo)準(zhǔn)格式的{分析能力:分析指令}等。
?工程建設(shè):確認(rèn)目標(biāo)后,從環(huán)境預(yù)設(shè)、指令描述、輸出規(guī)范等角度生成規(guī)范Prompt,不斷微調(diào)輸入結(jié)合業(yè)務(wù)知識的個(gè)性化案例。并通過中英互譯、預(yù)設(shè)負(fù)樣本、增設(shè)輸出校驗(yàn)和邊際檢驗(yàn)、動(dòng)態(tài)Prompt生成等方案優(yōu)化,兼顧時(shí)效性的同時(shí),提高輸出結(jié)果的穩(wěn)定性和準(zhǔn)確性。
準(zhǔn)確率提升
模塊歸一化模塊會(huì)把實(shí)體轉(zhuǎn)成數(shù)據(jù)服務(wù)支持的參數(shù)值,難點(diǎn)在于區(qū)分出相同名稱或者相似名稱, 為用戶匹配出最符合用戶需求的結(jié)果,包括指標(biāo)、篩選條件、聚合維度等實(shí)體的轉(zhuǎn)化,具體思路可以拆解成以下步驟:
?精確匹配:入?yún)㈩愋汀⒅笜?biāo)名稱或id、用戶權(quán)限多維度疊加判斷得到精準(zhǔn)結(jié)果;
?相似性匹配,在精準(zhǔn)匹配沒有結(jié)果之后,使用大模型對實(shí)體進(jìn)行embedding操作,從庫里查詢出相似度最高的結(jié)果;
?建立索引:對實(shí)體建立別名層,滿足用戶個(gè)人習(xí)慣,如部門的簡稱、指標(biāo)的別名,來提升識別準(zhǔn)確率;
?用戶行為數(shù)據(jù)輔助:通過用戶在數(shù)據(jù)產(chǎn)品、數(shù)據(jù)工具等系統(tǒng)的行為數(shù)據(jù),生成用戶對指標(biāo)、篩選條件、聚合維度的偏好數(shù)據(jù),輔助提升準(zhǔn)確率。
評測體系
數(shù)據(jù)服務(wù)場景對準(zhǔn)確率要求較高,同時(shí)數(shù)據(jù)指標(biāo)相似度、數(shù)據(jù)口徑復(fù)雜等實(shí)際情況對大模型的準(zhǔn)確率有較高挑戰(zhàn),如何保障回答的準(zhǔn)確性是產(chǎn)品設(shè)計(jì)之初就重點(diǎn)考慮的問題。目前通過周期性大樣本量評測集生成、檢驗(yàn),以及線上監(jiān)控的組合方式來保障。
?樣本設(shè)置:采用人工樣本和大模型生成樣本結(jié)合的方式,快速、多頻次對不同句式、不同場景的問答(1000+)做評測,來保障樣本的多樣性和豐富度。
?準(zhǔn)確率測評:通過批量調(diào)用接口返回大模型結(jié)果,離線代碼支持批量結(jié)果自動(dòng)化比對,從而高效輸出任務(wù)的準(zhǔn)確率、時(shí)效性等指標(biāo),同時(shí)同一批樣本會(huì)多次調(diào)用來評估任務(wù)的穩(wěn)定性。
?構(gòu)建產(chǎn)品功能:用戶可以在答案上點(diǎn)贊或點(diǎn)踩來反饋滿意度,產(chǎn)品側(cè)持續(xù)針對用戶反饋問題進(jìn)行階段性優(yōu)化。
本地大模型SFT
基于LLM對prompt工程輸入token數(shù)量的限制及數(shù)據(jù)隱私安全的考量,我們也選用本地大模型進(jìn)行Fine-tuning。它涉及在一個(gè)預(yù)訓(xùn)練模型的基礎(chǔ)上進(jìn)行額外訓(xùn)練,以使其更好地適應(yīng)特定的任務(wù)場景,實(shí)現(xiàn)準(zhǔn)確率提升和影響時(shí)長降低,具有很好的效果。
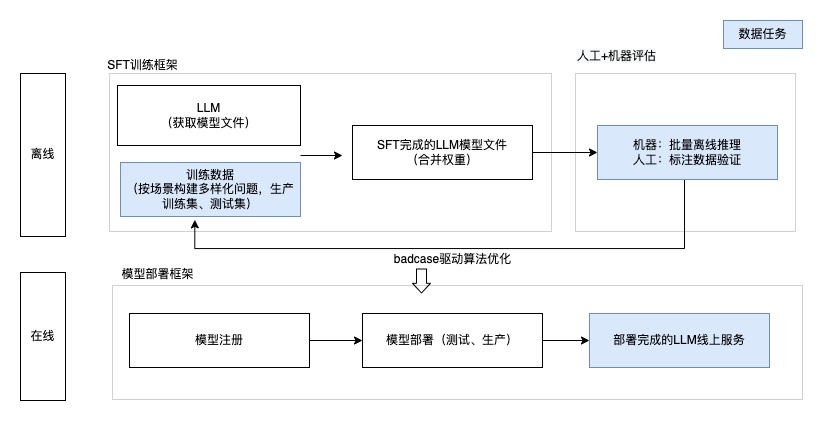
指標(biāo)查詢場景
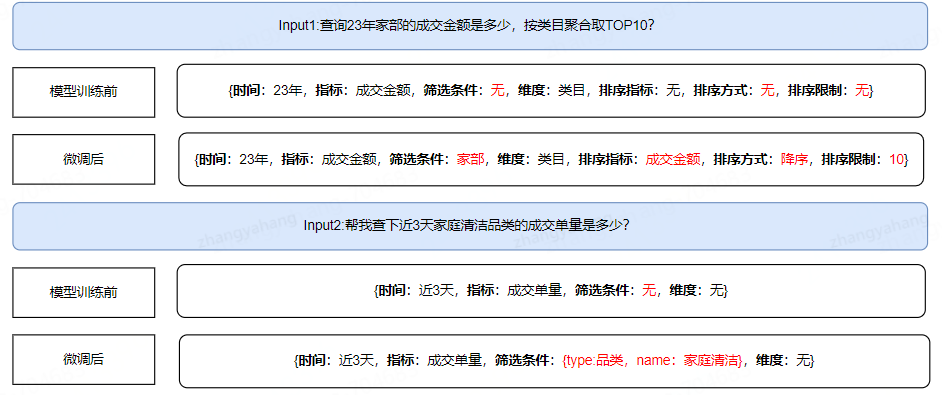
在指標(biāo)查詢場景中,用戶的提問方式具有高度多樣性,同時(shí),影響查詢結(jié)果的關(guān)鍵因素也呈現(xiàn)出復(fù)雜的組合形態(tài)。為了提升查詢效率和準(zhǔn)確性,建立京東專屬的業(yè)務(wù)域知識庫來支持樣本的批量生成
?按場景構(gòu)建多樣化問題庫,如單/多指標(biāo)查詢、分維度查詢、維度id和name查詢、排序查詢等
?按查詢因素構(gòu)建變量知識庫,建立時(shí)間、指標(biāo)、維度、篩選條件知識庫,方便后續(xù)新增場景的快速擴(kuò)充
模型訓(xùn)練前后準(zhǔn)確率對比提升明顯
?
數(shù)據(jù)分析場景
本地大模型可支持?jǐn)?shù)據(jù)交互,解決數(shù)據(jù)在傳輸過程中可能遭遇的安全風(fēng)險(xiǎn)和隱私泄露問題。通過問題引導(dǎo),降低用戶的使用成本,使用戶能夠智能化分析。通過用戶數(shù)據(jù)查詢的當(dāng)前表現(xiàn),由大模型提供"分析線索"引導(dǎo)用戶進(jìn)一步分析下探,線索包括:
?描述性分析,如銷量達(dá)成情況、趨勢分析、摘要總結(jié)
?探索性分析,如維度拆解、相關(guān)性指標(biāo)推薦、異常值識別等
業(yè)務(wù)價(jià)值評估
?數(shù)據(jù)查詢提效:通過自然語言對話,完成快速數(shù)據(jù)指標(biāo)查詢,單次查詢時(shí)效降至7.8秒,大大降低用戶數(shù)據(jù)獲取的時(shí)間,并且很好的支持了用戶個(gè)性化需求的滿足;
?數(shù)據(jù)分析賦能:依托豐富指標(biāo)維度數(shù)據(jù),通過思維鏈實(shí)現(xiàn)自動(dòng)化數(shù)據(jù)分析,并依據(jù)用戶的習(xí)慣喜好等選擇更貼合的數(shù)據(jù)路徑,非“分析師”角色用戶輕松實(shí)現(xiàn)多場景的快速智能分析
?數(shù)據(jù)消費(fèi)拓展:通過產(chǎn)品賦能,為每一個(gè)用戶配置一個(gè)專屬的AI數(shù)據(jù)分析師,可以擴(kuò)大數(shù)據(jù)消費(fèi)用戶的規(guī)模,并且大幅提升數(shù)據(jù)消費(fèi)的能力,支持業(yè)務(wù)應(yīng)用數(shù)據(jù)驅(qū)動(dòng)決策
審核編輯 黃宇
-
邏輯
+關(guān)注
關(guān)注
2文章
834瀏覽量
29789 -
數(shù)據(jù)模型
+關(guān)注
關(guān)注
0文章
52瀏覽量
10180 -
大模型
+關(guān)注
關(guān)注
2文章
3146瀏覽量
4072
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論