 RTC實時語音對話:開啟人機交互新生態,AI大模型智能聯動
RTC實時語音對話:開啟人機交互新生態,AI大模型智能聯動

在當今科技飛速發展的時代,AI大模型技術的爆發讓語音交互成為了人機協同的關鍵入口。就像Gartner預測的那樣,到2028年,15%的日常工作決策將由AI Agent自主完成。但傳統基于Http的語音方案,由于TCP協議的高延遲和回聲干擾等問題,難以滿足實時對話的流暢需求。而RTC(Real-Time Communication)技術,憑借其毫秒級傳輸、抗弱網能力以及多模態支持,成為了AI大模型落地的重要支撐。啟明云端作為樂鑫代理商,今天就帶大家深入了解RTC實時語音對話。
打造實時交互體驗
RTC技術通過端到端優化,實現了語音交互全鏈路的低延遲閉環。在音頻采集與預處理階段,集成了VAD人聲檢測和3A算法(AEC回聲消除、ANS降噪、AGC增益控制)。比如火山引擎RTC結合深度學習算法消除雙講干擾,通過AI降噪屏蔽95%環境噪音。在流式傳輸與弱網對抗方面,采用WebRTC底層框架,結合智能路由(如火山引擎WTN全球節點)、FEC前向糾錯、抗丟包編解碼技術,即便在80%丟包率的情況下,也能保證通話流暢。同時,通過SD-RTN實時網絡同步傳輸語音、文本、視頻數據,支持DeepSeek等大模型進行實時意圖理解與情感表達,實現多模態協同處理。
大模型能力深度集成
在意圖理解層,像豆包、GPT-4o這樣的LLM負責上下文推理,結合RAG技術實現動態知識庫檢索,智能外呼系統就是很好的例子。交互決策層支持打斷檢測,響應延遲低至340ms,還能進行多輪對話管理,TRTC方案就實現了 “類人對話節奏”。語音生成層中,語音大模型TTS(如豆包語音合成模型)支持情緒化表達。
行業應用:多領域開花結果
智能AI外呼系統借助意圖模型+RTC技術,能過濾95%的無效號碼,還能定制多輪話術。TRTC客服解決方案在弱網環境下,端到端延遲保持在300ms,支持多種方言識別,日均處理千萬級會話。
教育娛樂與情感陪伴
火山引擎AI玩具方案集成RTC協議后,延遲降低50%,支持 “眨眼搖尾” 等擬人化交互,在兒童教育場景中復購率提升了40%。DeepSeek語音助手通過650ms全鏈路延遲,能進行詩歌創作、情感安撫,打斷響應速度甚至超越ChatGPT。
企業協作與生產力應用
騰訊會議AI秘書能實時轉錄會議內容并生成摘要,結合RTC實現多語言同聲傳譯,讓跨國協作效率提升30%。醫療問診機器人在復雜噪聲環境中也能準確識別癥狀描述,誤診率較傳統IVR系統降低60%。
挑戰與未來趨勢
目前多模態協同延遲問題較為突出,當前語音-視覺融合方案端到端延遲普遍高于 800ms,離人類無感交互閾值(400ms)還有差距。而且現有TTS的情感表達僅能模擬6種基礎情緒,與真人的細膩度相差2個數量級。
技術演進方向
未來,邊緣AI與RTC融合是一個重要方向,在模組端部署微型大模型,有望將語音識別延遲壓縮至100ms以內。RTC與AI大模型的結合,正在重塑人機交互范式。據IDC預測,2026年全球RTC市場規模將突破320億美元,其中85%的增長來自AI語音場景。啟明云端作為樂鑫代理商,我們將持續關注這一領域的發展,為大家帶來更多優質的產品和解決方案。如果你對RTC實時語音對話技術感興趣,歡迎隨時聯系我們,一起探索智能生態的無限可能!
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
RTC
+關注
關注
2文章
619瀏覽量
68658 -
實時語音
+關注
關注
0文章
4瀏覽量
2134 -
AI大模型
+關注
關注
0文章
372瀏覽量
566
發布評論請先 登錄
相關推薦
熱點推薦
ESP-Brookesia:融合 AI 大模型,全新一代 GUI 開發與管理平臺
語音識別、自然語言對話、擬人化反饋等能力,幫助開發者構建更智能、更具溫度的人機交互體驗。在此基礎上,ESP-Brookesia構建于ESP-IDF和LVGL之上,

聲智科技全球首發新一代人機交互框架
全球人工智能產業正經歷人機交互范式升級。過去兩個月中,以OpenAI、Meta為代表的行業領軍企業加速推進交互技術創新迭代,推動產業進入關鍵變革期。值得關注的是,a16z合伙人Olivia

聲學技術如何重構人機交互生態
人機交互的底層邏輯。隨著非線性聲學計算與強化學習的深度融合,聲音交互正從“聽得見”邁向“聽得懂”,并逐漸成為 AI 時代的重要接口。
芯資訊|WT2605C藍牙語音芯片:AI對話大模型賦能的智能交互新引擎
引言:AI技術驅動智能交互新趨勢在萬物互聯的智能時代,用戶對產品的交互體驗提出了更高要求——從“被動響應”向“主動

單次、多次對話與RTC對話AI交互模式,如何各顯神通?
和RTC對話這三種常見的AI交互模式,各自在不同場景中發揮著關鍵作用,為我們帶來了不同的使用體驗。對話視頻三種
零知開源——ESP32語音交互系統(AI小智)開發教程
小智AI聊天機器人是一個基于嵌入式硬件與人工智能技術深度融合的智能交互系統。該項目以ESP32開發板為核心,結合語音喚醒、自然語言處理、音頻
智能語音交互的突破與應用,啟明云端AI大模型方案應用
熱潮,到文心一言、豆包、deepseek等眾多國內大模型的崛起,AI大模型正以前所未有的速度改變著我們的生活和工作方式。在這股浪潮中,智能語音
移遠通信AI玩具整體解決方案全面升級:融合火山引擎RTC大模型,打造實時交互新體驗
一體,可為玩具的智能化升級提供從硬件、算法到平臺的一站式服務。 移遠通信AI玩具整體解決方案率先支持火山引擎豆包RTC(實時音視頻)大模型,
發表于 02-21 09:50
?366次閱讀

清華牽頭深開鴻參與:混合智能人機交互系統獲批立項
近日,一個由清華大學牽頭、深開鴻重點參與的“面向混合智能的自然人機交互軟硬件系統”研發計劃項目,正式獲得了立項批準。該項目是國家“十四五”重點研發計劃“先進計算與新興軟件”專項中的一項關鍵核心技術
啟英泰倫新推出多意圖自然說,重塑離線人機交互新標準!
智能語音識別技術作為人機交互領域的一場革命性突破,正逐步重塑我們與智能設備的交互方式。近期,啟英泰倫新推出了多意圖自然說技術,進一步增強了

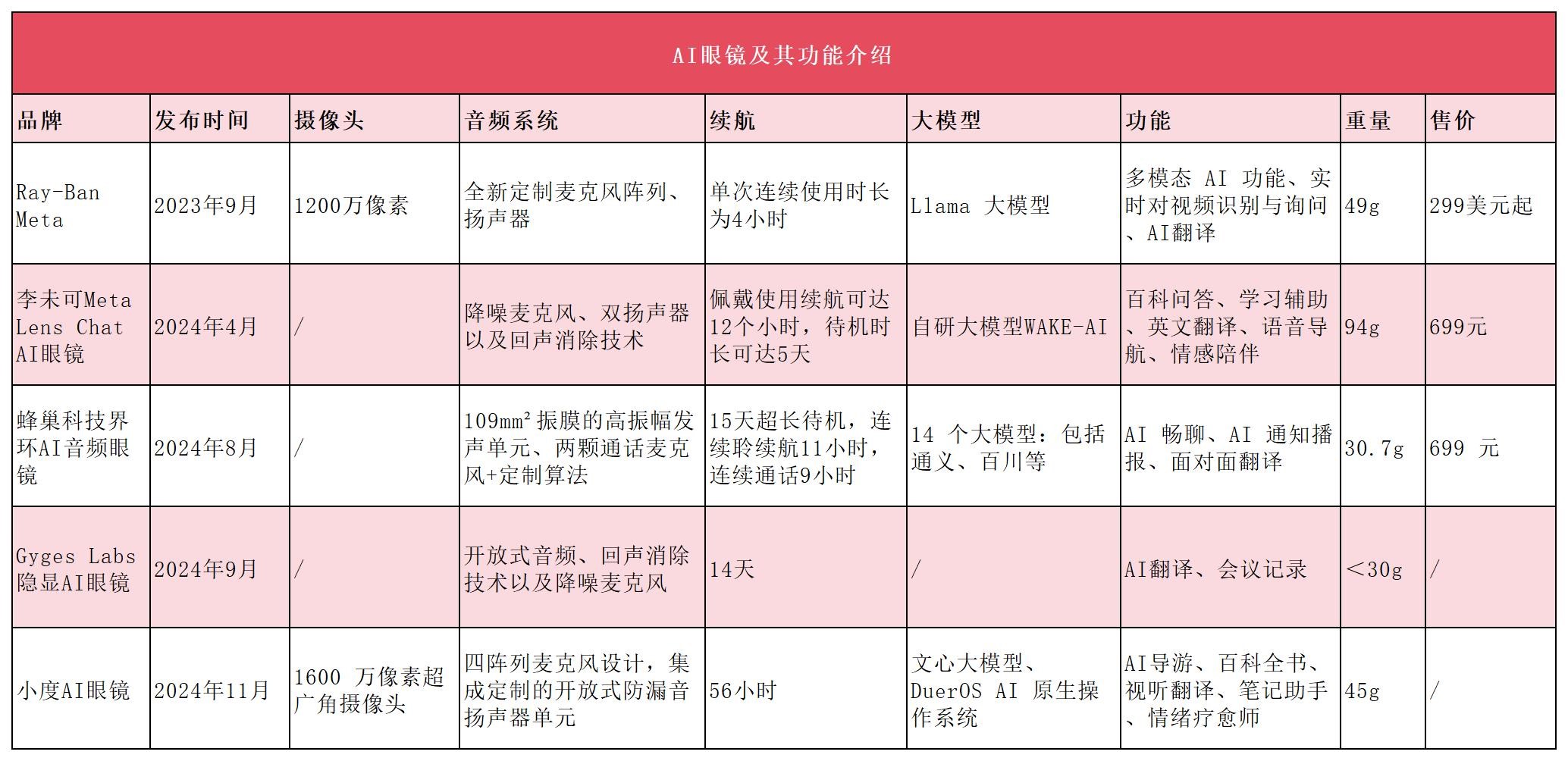
新的人機交互入口?大模型加持、AI眼鏡賽道開啟百鏡大戰
Chat AI眼鏡、蜂巢科技推出的界環AI音頻眼鏡等,不同品牌推出的新品都有其各自的定位。與此同時,在市場需求的帶動下,越來越多企業進入AI眼鏡賽道。 ? ? 全新的人機交互入口已現
具身智能對人機交互的影響
在人工智能的發展歷程中,人機交互一直是研究的核心領域之一。隨著技術的進步,人機交互的方式也在不斷演變。從最初的命令行界面,到圖形用戶界面,再到現在的自然語言處理和語音識別,每一次技術的
科大訊飛發布星火極速超擬人交互,重塑智能對話新體驗
8月19日,科大訊飛震撼宣布了一項關于其明星產品——星火語音大模型的重大革新,即將推出的“星火極速超擬人交互”功能,預示著人機交互的新紀元。該功能定于8月30日正式登陸訊飛星火App,
基于傳感器的人機交互技術
基于傳感器的人機交互技術是現代科技發展的重要領域之一,它極大地推動了人機交互的便捷性、自然性和智能性。本文將詳細探討基于傳感器的人機交互技術,包括其基本原理、關鍵技術、應用領域以及未來





 工商網監
工商網監
評論