 摩爾線程Round Attention優化AI對話
摩爾線程Round Attention優化AI對話

【編者按】摩爾線程科研團隊發布研究成果《Round Attention:以輪次塊稀疏性開辟多輪對話優化新范式》,該方法端到端延遲低于現在主流的Flash Attention推理引擎,kv-cache 顯存占用節省55%到82% 。
近年來,大型語言模型的進步推動了語言模型服務在日常問題解決任務中的廣泛應用。然而,長時間的交互暴露出兩大顯著挑戰:首先,上下文長度的快速擴張因自注意力機制的平方級復雜度而導致巨大的計算開銷;其次,盡管鍵值( KV )緩存技術能緩解冗余計算,但其顯著增加的 GPU 內存需求導致推理批處理規模受限及 GPU 利用率低下。摩爾線程提出 Round Attention 用于解決這些問題。

01論文主要貢獻
以輪次為分析單元研究 Attention 規律:Round Attention 專為多輪對話場景推理需求設計,以輪次為自然邊界劃分 KV 緩存,研究發現輪次粒度的 Attention 分布存在兩個重要規律。
提出 Round Attention inference pipeline :基于發現的兩個規律提出 Round Attention ,將稀疏性從 Token 級提升至塊級,選取最相關的塊參與 attention 計算,減少 attention 計算耗時,并將不相關的塊 offload 到CPU內存節省顯存占用。該 pipeline 在保持推理精度的情況下,減少了推理耗時,降低了顯存占用。
02核心創新:輪次塊稀疏性的三大優勢
自然邊界的語義完整性
問題洞察:多輪對話中,用戶意圖常以輪次為單位呈現(如“推薦餐廳”→“詢問人均消費”→“確認地址”)。
解決方案:Round Attention 將 KV 緩存按輪次(對)切分為獨立塊,每個塊完整包含一輪對話的提問與回答,確保模型在計算注意力時能直接關聯完整語義單元。
分水嶺層的注意力穩定性
關鍵發現:通過分析 SharedGPT 數據集,發現主流開源模型(如 Qwen2.5B )在特定“分水嶺層”后,各層對歷史輪次的注意力分布高度相似,且同一輪內問題與答案的注意力模式一致。
技術價值:僅需在分水嶺層一次性篩選 Top-K 相關輪次,即可覆蓋后續所有層的計算需求,相比其他工作逐層動態路由,有效減少 Top-K 計算開銷。
端到端的存儲與傳輸優化
存儲設計:將每輪 KV 緩存按分水嶺層拆分為下層塊( b_m )與上層塊( u_m ),以輪次為單位整體存儲于 CPU 內存,減少 GPU 內存占用。
傳輸效率:相比其他 kv cache offload 工作以 Token 級細粒度傳輸, Round Attention 以輪次為單位批量搬運 KV 緩存,單次 H2D 操作即可完成,降低 H2D 操作帶來的延遲。
03效果
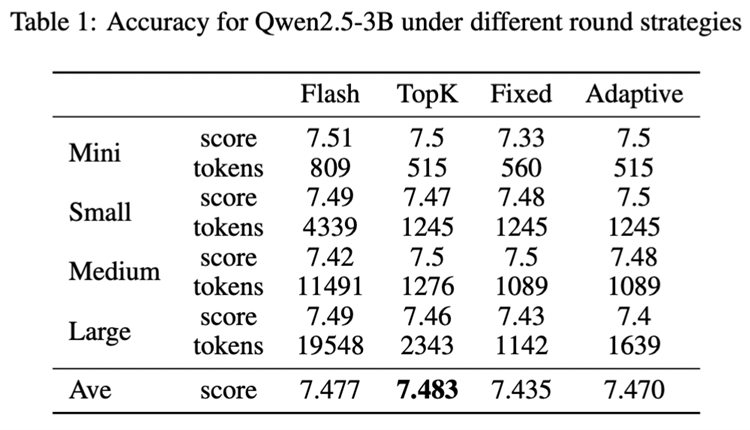
端到端延遲低于現在主流的 Flash Attention 推理引擎, kv-cache 顯存占用節省 55% 到 82% ,并且在主觀評測和客觀評測兩個數據集上模型推理準確率基本未受影響。
04未來展望:開源協作與技術融合
摩爾線程 Round Attention 期待與開源社區深度協同,繼續探索稀疏注意力可能的優化工作,共同攻克 LLM 落地中的效率與成本難題。該論文已發布在 arXiv :
關于摩爾線程
摩爾線程成立于2020年10月,以全功能GPU為核心,致力于向全球提供加速計算的基礎設施和一站式解決方案,為各行各業的數智化轉型提供強大的AI計算支持。
我們的目標是成為具備國際競爭力的GPU領軍企業,為融合人工智能和數字孿生的數智世界打造先進的加速計算平臺。我們的愿景是為美好世界加速。
-
gpu
+關注
關注
28文章
4938瀏覽量
131193 -
內存
+關注
關注
8文章
3121瀏覽量
75238 -
語言模型
+關注
關注
0文章
561瀏覽量
10784 -
摩爾線程
+關注
關注
2文章
234瀏覽量
5349
原文標題:技術研究 | 摩爾線程 Round Attention:以輪次塊稀疏性開辟多輪對話優化新范式
文章出處:【微信號:moorethreads,微信公眾號:摩爾線程】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄

摩爾線程統信軟件戰略合作:共建“完美體驗系統”
摩爾線程正式加入openKylin開源社區
摩爾線程與OpenMMLab戰略合作:推動算法框架與GPU協同發展,共筑AI開發者繁榮生態
摩爾線程計劃本周完成“崗位優化”
國內GPU龍頭!摩爾線程本周人員優化
國產摩爾線程顯卡驅動重磅升級!

摩爾線程與億景智聯戰略合作,共推生成式AI在高校的應用創新

摩爾線程與師者AI攜手完成70億參數教育AI大模型訓練測試
摩爾線程與智譜AI完成大模型性能測試與適配
摩爾線程攜手東華軟件完成AI大模型推理測試與適配
摩爾線程GPU與超圖軟件大模型適配:共筑國產地理空間AI新生態
摩爾線程完成股改,籌備上市
摩爾線程GPU原生FP8計算助力AI訓練






 工商網監
工商網監
評論