") 邊緣AI新突破:MemryX AI加速卡與RK3588打造高效多路物體檢測方案
邊緣AI新突破:MemryX AI加速卡與RK3588打造高效多路物體檢測方案
信息革命的浪潮正快速推進(jìn)!隨著科技日新月異的發(fā)展,人工智能(AI) 的應(yīng)用已悄然融入人們的日常生活,無論是 Google 的搜索引擎、Facebook 的推薦系統(tǒng),還是電商平臺的銷售排行,AI 技術(shù)正潛移默化地改變著我們的生活方式。這些科技成果的普及,使得低成本、高效能的解決方案成為當(dāng)下的關(guān)鍵需求。
同時,視覺相關(guān)的AI應(yīng)用正以驚人的速度改變著我們的世界。無論是在汽車、工業(yè)還是醫(yī)療領(lǐng)域,其獨特價值都得到了充分展現(xiàn)。展望未來,隨著視覺AI技術(shù)的不斷進(jìn)步,更多創(chuàng)新應(yīng)用將逐步落地,深刻影響并重塑我們的日常生活和工作方式。以下是視覺AI在各領(lǐng)域的典型應(yīng)用:
◆ 智能監(jiān)控:通過實時目標(biāo)檢測、行為分析和入侵預(yù)警,為智慧城市的安全管理提供有力支持。
◆ 智慧零售:借助顧客行為分析和智能貨架管理,優(yōu)化購物體驗,同時提升銷售效率和運營效益。
◆ 醫(yī)療影像分析:輔助醫(yī)生進(jìn)行精準(zhǔn)診斷,例如腫瘤檢測與分析,從而提高醫(yī)療效率和診斷準(zhǔn)確性。
◆ 工業(yè)質(zhì)檢:利用視覺AI快速識別產(chǎn)品缺陷,確保生產(chǎn)質(zhì)量的穩(wěn)定性,并顯著提升生產(chǎn)效率。
◆ 自動駕駛:車載AI通過視覺處理技術(shù)分析道路環(huán)境、行人及障礙物,實時做出決策,大幅提升駕駛的安全性與可靠性。
邊緣計算(Edge Computing)將成為推動該技術(shù)發(fā)展的關(guān)鍵因素。隨著神經(jīng)處理單元(Neural Processing Unit, NPU)的問世,計算性能實現(xiàn)了指數(shù)級提升,使機器學(xué)習(xí)和人工智能應(yīng)用得以廣泛應(yīng)用于移動設(shè)備、傳感器等多種硬件中,從而讓智能計算更加貼近人們的日常生活。為此,MemryX 推出了 MX3 AI 芯片,該芯片能夠提供每瓦高達(dá) 5 TOPS 的算力性能,并支持浮點數(shù)(Brain Floating Point)運算,以確保用戶模塊的計算精度。每顆芯片內(nèi)置 10.5 MB 的靜態(tài)隨機存取存儲器(SRAM),用于模塊訪問,不會占用主系統(tǒng)資源。此外,最多可串聯(lián) 16 顆芯片以進(jìn)一步擴展性能。

圖1 MemryX AI芯片規(guī)格示意圖
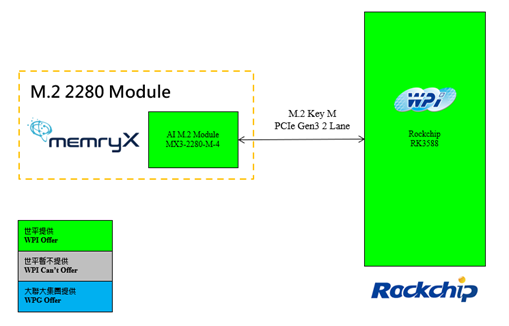
2024年,MemryX 重磅推出外掛式 MemryX MX3 AI 推理加速卡,采用 PCIe Gen3 M.2 M-Key 接口,具備高達(dá) 20 TOPS 的卓越計算性能,為各類工業(yè)電腦帶來即插即用的便捷體驗。該解決方案以“平臺升級,迎接AI智能時代”為設(shè)計理念助力企業(yè)與開發(fā)者輕松邁向人工智能領(lǐng)域。本方案特別結(jié)合了 Orange Pi 5 Plus (Rockchip RK3588) 與 MemryX AI 加速卡,構(gòu)建出一套高性價比的智能解決方案。憑借 MemryX 提供的豐富軟件資源及對主流深度學(xué)習(xí)框架 (如 TensorFlow、PyTorch、ONNX) 的支持,即便是新手也能快速上手,輕松部署 AI 模型,實現(xiàn)智能應(yīng)用開發(fā)。
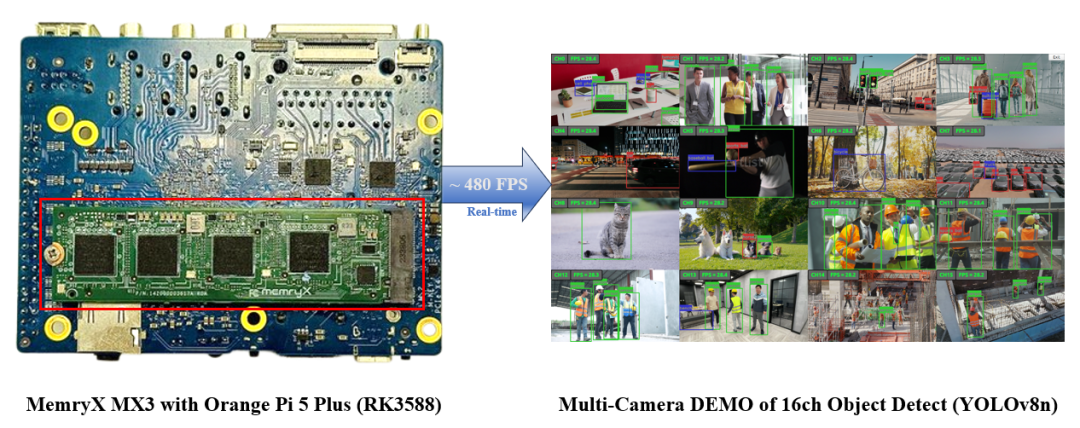
圖2 基于 MemryX AI 加速卡結(jié)合 Rockchip RK3588 多路物體檢測解決方案優(yōu)勢示意圖
憑借 MemryX 的強大運算能力,能夠輕松實現(xiàn)多路(Multi-Streamer) 的物體檢測(Object Detection)應(yīng)用。只需要使用普通的USB攝像頭或通過網(wǎng)絡(luò)來源串聯(lián),即可適用于市面上常見的停車場管理系統(tǒng)、智慧停車柱、智慧交通監(jiān)控、商場人流檢測、居家無死角意外檢測等應(yīng)用。現(xiàn)在就加入我們,體驗人工智能的無限魅力!讓 AI 助力您的創(chuàng)新,開創(chuàng)屬于您的智能應(yīng)用時代!
搭配 MemryX 所構(gòu)建的開發(fā)環(huán)境 Developer Hub,開發(fā)者能夠簡單且快速地上手將 TensorFlow Lite、ONNX、Pytorch、Keras 等熱門深度學(xué)習(xí)框架的模塊轉(zhuǎn)換為 MemryX MX3+ 芯片所需的 DFP 框架。并通過原廠豐富的示例應(yīng)用與公共工具,即可一步步實現(xiàn) AI 應(yīng)用。
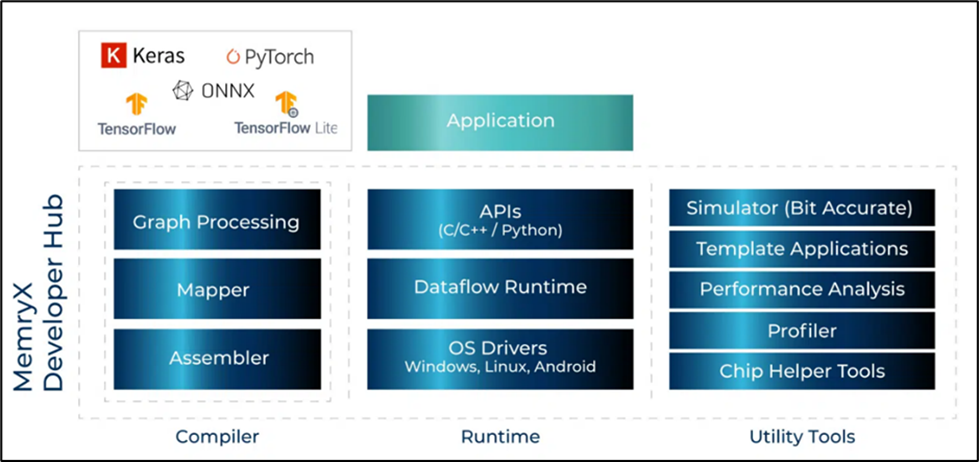
圖4 MemryX 開發(fā)環(huán)境示意圖
▼ 編譯器(Compiler)
神經(jīng)編譯器提供多種功能,如多模型整合(Multi-Model)、模型剪枝(Model Cropping)、多路流輸入單一應(yīng)用(Multiple Input Streams)、單路流輸入多個應(yīng)用(Shared Input Stream)、混合精度權(quán)重(Mixed-Precision Weights)、模塊資源使用情況顯示(Resources Utilization)。通過簡單的命令行指令,能夠幫助開發(fā)者。快速轉(zhuǎn)換模塊將 Pytorch、Keras、Tensorflow、Tensorflow Lite、ONNX 等模型轉(zhuǎn)換為 MemryX DFP 模組格式。
▼ 運行時(Runtime)
提供優(yōu)化的用戶體驗,利用 Benchmark 搭配模型庫能夠幫助開發(fā)者快速評估其硬件性能與準(zhǔn)確度,并且提供多種開源示例 DEMO (MemryX_Example) 與簡潔有力的 API 能夠幫助開發(fā)者快速實現(xiàn)與部署AI應(yīng)用。
加速器 API(Python,C/C++)
▼ 公用工具(Utility Tools)
模擬器 (Simulator):為 MemryX 提供一套軟件,以解決手頭沒有 MX3 芯片的開發(fā)者進(jìn)行性能評估的問題。
可視化工具(Viewer):為 MemryX 提供的 GUI 界面,包含上述編譯器、模擬器、加速器。
檢查器(DFP Inspect):為 MemryX 提供的一套檢查 DFP 文件的工具。
如下圖所示,展示了更多實際的應(yīng)用,如物體檢測、語義分割、車輛識別、深度估算、肢體識別、虛擬畫筆、人臉識別、車牌識別、表情檢測、圍欄警示等。都可以通過你的想象力與創(chuàng)造力,開發(fā)出更具潛力的殺手級應(yīng)用!這里還提供了實際應(yīng)用數(shù)據(jù),大多數(shù)應(yīng)用都能輕松達(dá)到每秒 30 幀以上的推理速度!并主打浮點數(shù)運算 (BF16),確保模型的準(zhǔn)確性!潛力無限!
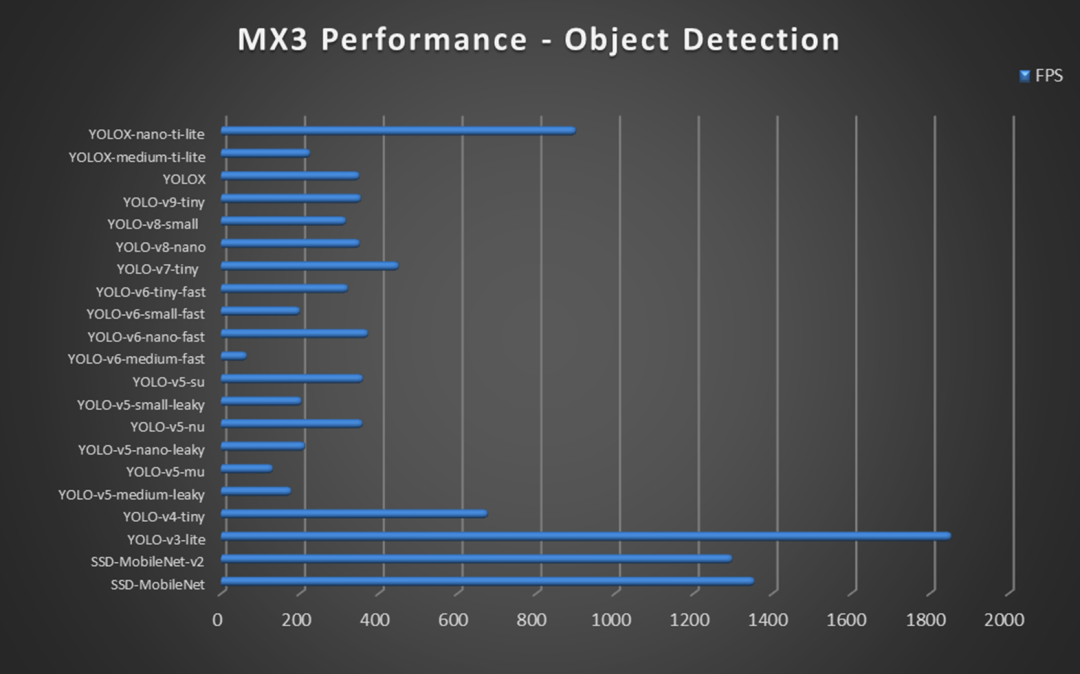
圖6 MemryX M3+ 芯片性能數(shù)據(jù)表
?場景應(yīng)用圖
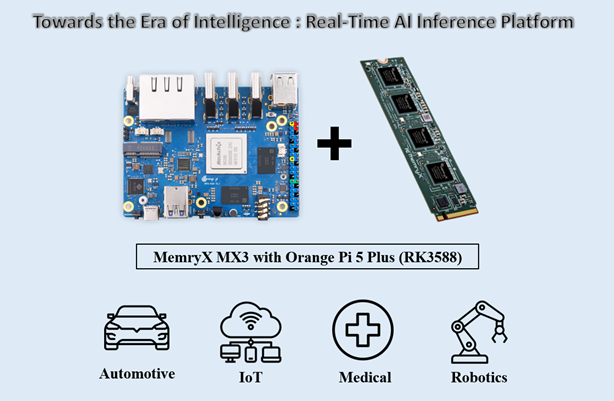
?展示板照片

?方案方塊圖
?核心技術(shù)優(yōu)勢
◆ 采用浮點數(shù) BF16 進(jìn)行計算,確保模塊準(zhǔn)確度:
模塊設(shè)計以 BF16(Brain Floating Point 16)為基礎(chǔ)進(jìn)行運算,相較于傳統(tǒng)的浮點數(shù)格式,BF16 能夠在大幅減少內(nèi)存使用量的同時,仍然提供接近 FP32 的計算準(zhǔn)確度。這使其特別適合用于人工智能和深度學(xué)習(xí)模型的推理與訓(xùn)練場景,確保結(jié)果的精確性。
◆ 不占用系統(tǒng)內(nèi)存:
模塊運行時采用了獨立內(nèi)存的架構(gòu),無需占用主系統(tǒng)的 RAM 資源,有效降低對系統(tǒng)整體性能的影響。這種設(shè)計特性確保模塊在高效運行的同時,仍然能為其他應(yīng)用程序預(yù)留足夠的系統(tǒng)資源。
◆ 高度可擴展性:
支持連接多達(dá) 16 個模塊,通過模塊化設(shè)計實現(xiàn)高擴展性。這使得系統(tǒng)能夠根據(jù)需求靈活擴展計算能力,以應(yīng)對不同場景的計算需求,例如需要更高性能的數(shù)據(jù)中心或邊緣計算。
◆ 最佳數(shù)據(jù)流優(yōu)化,最大限度減少數(shù)據(jù)移動:
模塊內(nèi)部針對數(shù)據(jù)流進(jìn)行了高度優(yōu)化設(shè)計,通過智能路由和緩存機制,能夠最大程度地減少數(shù)據(jù)在運行過程中的移動頻率,從而提升處理性能并降低延遲。此外,這樣的設(shè)計也有助于降低能耗,進(jìn)一步增強系統(tǒng)的運行效率。
◆ 高性價比與低功耗解決方案:
將主平臺 Orange Pi 5 Plus 搭配 MemryX MX+ 的 AI 芯片,即可無痛升級為更高階的 AI 平臺,每秒能夠運行約 480 幀(YOLOv8)的物體檢測;且 MX3+ 擁有 5 TOPS/W 的性能表現(xiàn),整套多路物體檢測解決方案僅耗電約 14 W。
◆ 多路應(yīng)用的新概念:
相較于近年來興起的邊緣計算,將其概念套用到區(qū)域性場景或許是一個新穎且能夠大幅降低成本的解決方案。利用輕松易得的攝像頭,再搭配一臺智能工業(yè)主機,即可實現(xiàn)許多應(yīng)用,并且能夠?qū)η岸说臄z像頭進(jìn)行任意更換與配置。
?方案規(guī)格
◆ 主平臺開發(fā)板采用 RockChip RK3588 平臺為基礎(chǔ),搭載四顆 Cortex-A76 處理器與四顆 Cortex-A55 處理器,并提供高性能圖像處理器 Arm Mali-G610 與神經(jīng)運算處理器 NPU 等強大核心架構(gòu)。
◆ I/O Board 開發(fā)板提供強大的周邊配置,如 Gigabit Ethernet 千兆以太網(wǎng)、USB Type A/C 3.0 通用串行總線接口、HDMI 高清多媒體接口、M.2 E-Key 傳輸接口、M.2 M-Key 傳輸接口,并能夠通過擴展的 40 pin 針腳來模擬常用的 UART、I2C、SPI、CAN 等信號。
◆ MemryX MX3+ 芯片提供強大的 AI 運算能力(20 TOPS),以 PCIe Gen3 M.2 2280 M-Key 接口為主,其 M.2 加速卡搭載四顆 MX3+ 芯片,每顆芯片能夠提供 5 TOPS/W 的性能,并內(nèi)置 10.5 MB 的靜態(tài)隨機存取存儲器用于存取模塊。支持 Linux 與 Windows 兩大操作系統(tǒng),并提供豐富的軟件資源供開發(fā)者使用,能夠直接移植 Tensorflow、ONNX、Pytorch、Keras 等熱門的深度學(xué)習(xí)框架。
本文作者 大大通博主:ATU 伊布小編 (一部)
了解MPU技術(shù)整合、深度學(xué)習(xí)、電腦視覺技術(shù)與人工智能(AI)的發(fā)展等更多相關(guān)內(nèi)容!
登錄大大通網(wǎng)站,向作者提問,下載方案技術(shù)文檔,了解更多資訊!
-
Rockchip
+關(guān)注
關(guān)注
0文章
80瀏覽量
19049 -
NPU
+關(guān)注
關(guān)注
2文章
325瀏覽量
19575
發(fā)布評論請先 登錄
RK3576 vs RK3588:為何越來越多的開發(fā)者轉(zhuǎn)向RK3576?
輕松上手邊緣AI:MemryX MX3+結(jié)合Orange Pi 5 Plus的C/C++實戰(zhàn)指南

RK3588參數(shù)與主要特性 RK3588數(shù)據(jù)手冊解讀

邊緣AI運算革新 DeepX DX-M1 AI加速卡結(jié)合Rockchip RK3588多路物體檢測解決方案

6TOPS算力NPU加持!RK3588如何重塑8K顯示的邊緣計算新邊界
RK3588核心板在邊緣AI計算中的顛覆性優(yōu)勢與場景落地
《RK3588核心板:AIoT邊緣計算的革命性引擎,能否解鎖智能物聯(lián)新范式?》
有獎直播 | @4/8 輕松部署,強大擴展邊緣運算 AI 新世代

添越智創(chuàng)基于 RK3588 開發(fā)板部署測試 DeepSeek 模型全攻略
EPSON差分晶振SG3225VEN頻點312.5mhz應(yīng)用于AI加速卡
基于迅為RK3568/RK3588開發(fā)板的AI圖像識別方案
基于迅為RK3588開發(fā)板的AI圖像識別方案
淺談邊緣計算AI攝像頭嵌入式主板方案,基于東勝物聯(lián)RK3588核心板







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論