 VizWiz數據集:用計算機視覺回答盲人的問題
VizWiz數據集:用計算機視覺回答盲人的問題
計算機視覺的應用可以用來幫助盲人,無論是改善視力缺陷還是打破社交障礙。例如TapTapSee和CamFind等物體識別工具可以讓人們拍攝圖像,并識別目標物體是什么,以及哪里能買到。另外,Facebook和Twitter推出的新功能可以識別和標記圖片中的好友,讓人們與朋友保持聯系。計算機視覺應用的下一個理想目標是讓有視力障礙的人更自然地接收到關于周圍世界的信息。這一目標的出現引起了人們對通用視覺問題解答(visual question answering)的興趣,該問題旨在準確地回答任何有關圖像的問題。
在過去三年里,計算機視覺領域已經涌現出了14種VQA數據集,但他們都是人工創建設置的,并且沒有一個數據集的圖片是來自盲人的或服務于盲人的。然而,可以這么說,盲人能夠產生訓練算法所需的大量數據。近十年來,盲人群體通過拍照詢問他們拍的是什么,并且盲人通常是計算機視覺技術早期的使用者,這項技術將為他們的生活帶來極大的便利。
中國科學技術大學和美國卡內基梅隆大學等高校的研究人員共同提出了第一個由盲人產生的視覺數據庫“VizWiz”,他們通過數據庫創建了一個手機程序,可以讓盲人通過拍照和詢問得到超過七萬個問題的答案。數據集剛開始構建時嚴格對內容進行過濾,消除有可能侵犯個人隱私的視覺問題。之后通過眾包獲取圖像的答案來訓練和評估算法,接著通過實驗對圖像進行特征分類、問題回答,最終發現了VizWiz與其他現有VQA數據集不同的地方。
VizWiz介紹
該VQA數據集由盲人提出的視覺問題組成,在四年時間里積累了72205個問題。表一總結了VizWiz收集數據的過程與其他數據庫的不同,其中明顯的區別是VizWiz包含來自盲人攝影師的圖像,并且提問方式是口頭而非文字。
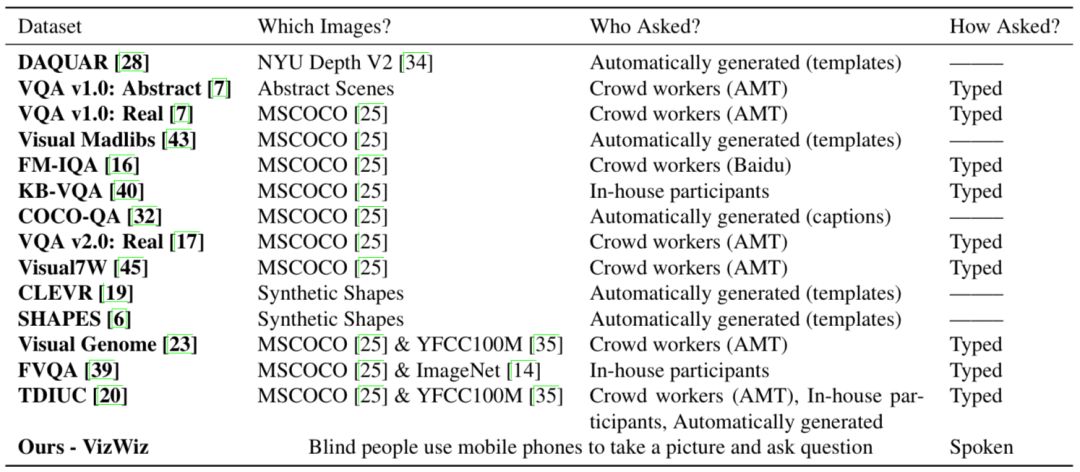
表一
這種圖像質量帶來了一般數據集中沒有的挑戰,例如會有大量的模糊、光線不足、圖像內容缺失等。另外,因為“提問者”也是“拍攝者”,所以有時問題可能與圖像無關,如圖所示。

在對數據集的圖像進行篩選時,研究人員將可能會泄露隱私的圖片分成以下幾類:
暴露個人信息,例如人臉、財務狀況、藥品處方。
某個地點,例如郵箱地址、商業地點。
不雅內容,例如***、褻瀆。
可疑的復雜場景,審查人員懷疑其中可能包括個人信息,但沒有找到明確的地方。
可疑的低質量圖像,審查人員懷疑增強圖像質量可能會暴露個人信息。
最終,研究人員通過IQ引擎、Facebook、Twitter或電子郵件公開接收圖像的答案。
VizWiz數據庫分析
接著,研究人員將對VizWiz中的問題和答案進行可視化,他們分析了自然語言問題的類型、圖像都有哪幾類、答案分為哪幾類以及視覺問題無法回答的情況。
首先,問題的類別如下圖所示:
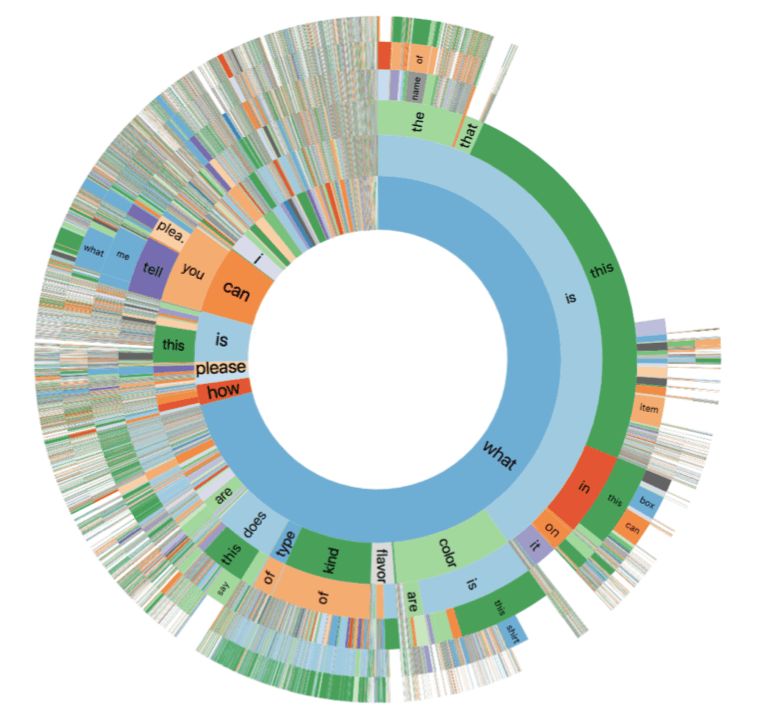
表中統計了所有問題的前六個字母。最內環代表第一個字母,以此類推。可以看出,“這是什么?(What is this)”這個問題是最常見的。
然后,我們來分析數據庫中的圖像多樣性。尤其值得關注的是,我們的數據集中高質量的圖像可以顯示單個標志性的對象,因為在收集時過濾掉了可疑圖像。在之前工作的基礎上,我們首先計算了VizWiz中所有圖像的平均圖像。如下圖所示:
接著,我們來分析答案的多樣性。我們首先用詞匯地圖將不同答案進行可視化,如下圖所示:
文字越大,答案出現的頻率就越高。
VizWiz評估結果
研究人員用現有算法測試了VizWiz數據集的難度。首先是用現代VQA算法預測VizWiz數據集中視覺問題的答案,結果如下表所示:
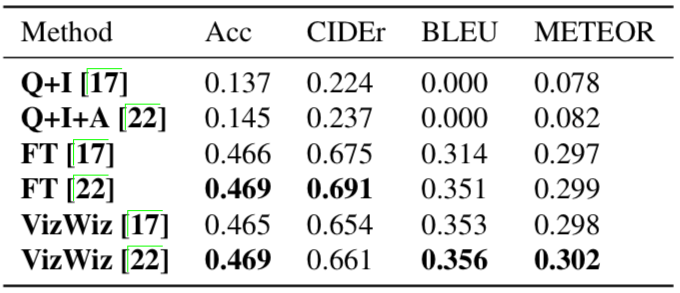
可以看出前兩行的表現非常糟糕,而VizWiz的表現還是不錯的。
接著他們測試了算法是夠能區分某一問題是否可答的精確度,結果如下圖所示:
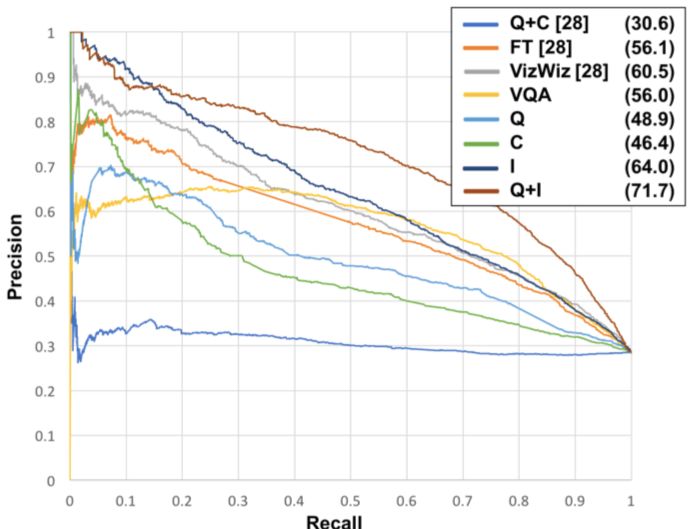
結果可見,研究人員提出的方法比現有方法的精確度提高了至少25%。
結語
在這篇論文中,研究人員介紹了一種VQA數據集——VizWiz,與一般數據集不同的是,其中的內容都來自盲人拍攝的圖片,并由盲人對內容進行提問。通過對數據集的分析,研究人員對計算機視覺以及自然語言處理又有了新的認識。更重要的一點是,VizWiz的出現能讓更多人關注針對盲人的技術需求,為開發專門的技術提供了新機會。
-
數據
+關注
關注
8文章
7249瀏覽量
91384 -
人工智能
+關注
關注
1805文章
48843瀏覽量
247449
原文標題:VizWiz數據集:用計算機視覺回答盲人的問題
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄







 工商網監
工商網監
評論