 數據標注服務—奠定大模型訓練的數據基石
數據標注服務—奠定大模型訓練的數據基石

數據標注是大模型訓練過程中不可或缺的基礎環節,其質量直接影響著模型的性能表現。在大模型訓練中,數據標注承擔著將原始數據轉化為機器可理解、可學習的信息的關鍵任務。這一過程不僅決定了模型學習的起點,也影響著模型能力的上限。隨著大模型技術的快速發展,數據標注服務的重要性愈發凸顯,其面臨的挑戰也日益嚴峻。當前,就標貝科技看來,數據標注服務已從簡單的數據標記,發展成為一門融合了人工智能、質量控制、倫理考量的復雜學科,成為推動大模型技術進步的重要力量。
一、數據標注服務—大模型訓練的基石
在大模型訓練中,數據標注服務是將原始數據轉化為結構化知識的關鍵步驟。通過精確的標注,非結構化的文本、圖像、語音等數據被轉化為機器可理解的標簽和特征,為模型提供明確的學習目標。這一過程直接影響著模型對知識的理解和泛化能力,高質量的標注數據能夠顯著提升模型的性能表現。
數據質量與模型性能呈現顯著的正相關關系。研究表明,在相同模型架構下,使用經過嚴格質量控制的數據集進行訓練,模型在各項任務上的表現可提升30%以上。特別是在少樣本學習場景中,高質量的數據標注能夠幫助模型更好地捕捉數據特征,實現更準確的預測。
數據標注服務面臨的挑戰主要來自規模和質量兩個維度。隨著大模型參數量的指數級增長,所需的數據規模也呈幾何級數增加。同時,確保海量數據的標注質量成為巨大挑戰,需要建立完善的質量控制體系和標準化流程。
二、未來大模型對數據的要求
未來大模型對數據的規模需求將持續擴大。GPT-4等先進模型已經需要處理PB級的數據量,預計下一代大模型的數據需求將達到EB級別。這種規模的增長不僅帶來存儲和處理的挑戰,更對數據標注服務的效率提出了更高要求。
就標貝科技來看,數據多樣性將成為決定模型能力的關鍵因素。多模態、跨領域的數據融合將成為趨勢,要求數據標注能夠處理文本、圖像、視頻、音頻等多種數據類型,并建立統一的標注標準。這種多樣性需求將推動數據標注服務技術向更智能、更靈活的方向發展。
數據質量標準的提升是必然趨勢。未來大模型將要求數據標注達到更高的準確率、一致性和完整性。這需要建立更嚴格的質量控制體系,包括自動化的質量檢測工具、標準化的標注流程和可追溯的質量記錄。
三、訓練數據的發展趨勢
自動化數據標注服務技術正在快速發展。基于預訓練模型的智能標注系統已經能夠實現80%以上的標注自動化率,顯著提高了標注效率。未來,結合強化學習和主動學習的智能標注系統將進一步降低人工干預的需求。
數據合成與增強技術為解決數據稀缺問題提供了新思路。通過生成對抗網絡(GAN)和擴散模型等技術,可以生成高質量的合成數據,補充真實數據的不足。同時,數據增強技術能夠有效提升數據的多樣性和魯棒性。
數據治理與合規性要求日益嚴格。隨著數據隱私保護法規的完善,數據標注服務必須建立完善的合規體系,包括數據脫敏、訪問控制、使用審計等機制。這要求數據標注服務平臺具備更強的安全性和可追溯性。
數據標注服務作為大模型訓練的基礎環節,其重要性將隨著大模型技術的發展而不斷提升。未來,數據標注服務將朝著智能化、標準化、合規化的方向演進,需要技術創新與規范管理的雙重驅動。只有建立高質量、多樣化、合規的數據基礎,才能支撐大模型技術的持續突破和應用創新。在這個過程中,數據標注服務將不僅是技術問題,更是涉及倫理、法律、社會等多個層面的系統工程,需要產學研各界的共同努力和協作。
審核編輯 黃宇
-
大模型
+關注
關注
2文章
3146瀏覽量
4071
發布評論請先 登錄
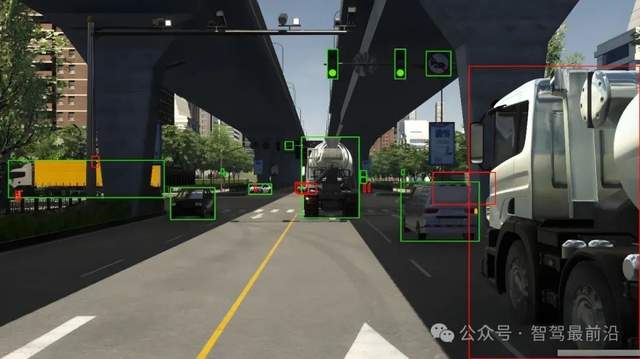
什么是自動駕駛數據標注?如何好做數據標注?
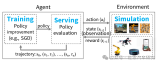
數據標注與大模型的雙向賦能:效率與性能的躍升
海思SD3403邊緣計算AI數據訓練概述
自動化標注技術推動AI數據訓練革新
標貝自動化數據標注平臺推動AI數據訓練革新

AI Cube進行yolov8n模型訓練,創建項目目標檢測時顯示數據集目錄下存在除標注和圖片外的其他目錄如何處理?
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
英偉達推出基石世界模型Cosmos,解決智駕與機器人具身智能訓練數據問題
標貝數據標注在智能駕駛訓練中的落地案例
AI數據服務在智能駕駛訓練中的應用實例
標貝科技:自動駕駛中的數據標注類別分享

標貝科技:自動駕駛中的數據標注類別分享






 工商網監
工商網監
評論