") 谷歌提出對加速智能體的學(xué)習(xí)過程
谷歌提出對加速智能體的學(xué)習(xí)過程

在強化學(xué)習(xí)問題中,關(guān)于任務(wù)目標(biāo)的制定,往往需要開發(fā)人員花費很多的精力,在本文中,谷歌大腦聯(lián)合佐治亞理工學(xué)院提出了正向-反向強化學(xué)習(xí)(Forward-Backward Reinforcement Learning,F(xiàn)BRL),它既能從開始位置正向進(jìn)行探索,也可以從目標(biāo)開始進(jìn)行反向探索,從而加速智能體的學(xué)習(xí)過程。
一般來說,強化學(xué)習(xí)問題的目標(biāo)通常是通過手動指定的獎勵來定義的。為了設(shè)計這些問題,學(xué)習(xí)算法的開發(fā)人員必須從本質(zhì)上了解任務(wù)的目標(biāo)是什么。然而我們卻經(jīng)常要求智能體在沒有任何監(jiān)督的情況下,在這些稀疏獎勵之外,獨自發(fā)現(xiàn)這些任務(wù)目標(biāo)。雖然強化學(xué)習(xí)的很多力量來自于這樣一種概念,即智能體可以在很少的指導(dǎo)下進(jìn)行學(xué)習(xí),但這一要求對訓(xùn)練過程造成了極大的負(fù)擔(dān)。
如果我們放松這一限制,并賦予智能體關(guān)于獎勵函數(shù)的知識,尤其是目標(biāo),那么我們就可以利用反向歸納法(backwards induction)來加速訓(xùn)練過程。為了達(dá)到這個目的,我們提出訓(xùn)練一個模型,學(xué)習(xí)從已知的目標(biāo)狀態(tài)中想象出反向步驟。
我們的方法不是專門訓(xùn)練一個智能體以決策該如何在前進(jìn)的同時到達(dá)一個目標(biāo),而是反向而行,共同預(yù)測我們是如何到達(dá)目標(biāo)的。我們在Gridworld和漢諾塔(Towers of Hanoi)中對我們的研究進(jìn)行了評估,并通過經(jīng)驗證明了,它的性能比標(biāo)準(zhǔn)的深度雙Q學(xué)習(xí)(Deep Double Q-Learning,DDQN)更好。
強化學(xué)習(xí)(Reinforcement Learning,RL)問題通常是由智能體在對環(huán)境的任務(wù)獎勵盲然無知的情況下規(guī)劃的。然而,對于許多稀疏獎勵問題,包括點對點導(dǎo)航、拾取和放置操縱、裝配等等目標(biāo)導(dǎo)向的任務(wù),賦予該智能體以獎勵函數(shù)的知識,對于學(xué)習(xí)可泛化行為來說,既可行又實用。
通常,這些問題的開發(fā)人員通常知道任務(wù)目標(biāo)是什么,但不一定知道如何解決這些問題。在本文中,我們將介紹我們?nèi)绾卫脤δ繕?biāo)的知識,使我們甚至能夠在智能體到達(dá)這些領(lǐng)域之前學(xué)習(xí)這些領(lǐng)域中的行為。相比于那些從一開始就將學(xué)習(xí)初始化的方法,這種規(guī)劃性方案可能更容易解決。
例如,如果我們知道所需的位置、姿勢或任務(wù)配置,那么我們就可以逆轉(zhuǎn)那些將我們帶到那里的操作,而不是迫使智能體獨自通過隨機發(fā)現(xiàn)來解決這些難題。
Gridworld和漢諾塔環(huán)境
本文中,我們介紹了正向-反向強化學(xué)習(xí)(Forward-Backward Reinforcement Learning,F(xiàn)BRL),它引入反向歸納,使我們的智能體能夠及時進(jìn)行逆向推理。通過一個迭代過程,我們既從開始位置正向進(jìn)行了探索,也從目標(biāo)開始進(jìn)行了反向探索。
為了實現(xiàn)這一點,我們引入了一個已學(xué)習(xí)的反向動態(tài)模型,以從已知的的目標(biāo)狀態(tài)開始進(jìn)行反向探索,并在這個局部領(lǐng)域中更新值。這就產(chǎn)生了“展開”稀疏獎勵的效果,從而使它們更容易發(fā)現(xiàn),并因此加速了學(xué)習(xí)過程。
標(biāo)準(zhǔn)的基于模型的方法旨在通過正向想象步驟并使用這些產(chǎn)生幻覺的事件來增加訓(xùn)練數(shù)據(jù),從而減少學(xué)習(xí)優(yōu)秀策略所必需的經(jīng)驗的數(shù)量。然而,并不能保證預(yù)期的狀態(tài)會通向目標(biāo),所以這些轉(zhuǎn)出結(jié)果可能是不充分的。
預(yù)測一個行為的結(jié)果的能力并不一定能提供指導(dǎo),告訴我們哪些行為會通向目標(biāo)。與此相反,F(xiàn)BRL采用了一種更有指導(dǎo)性的方法,它給定了一個精確的模型,我們相信,每一個處于反向步驟中的狀態(tài)都有通向目標(biāo)的路徑。
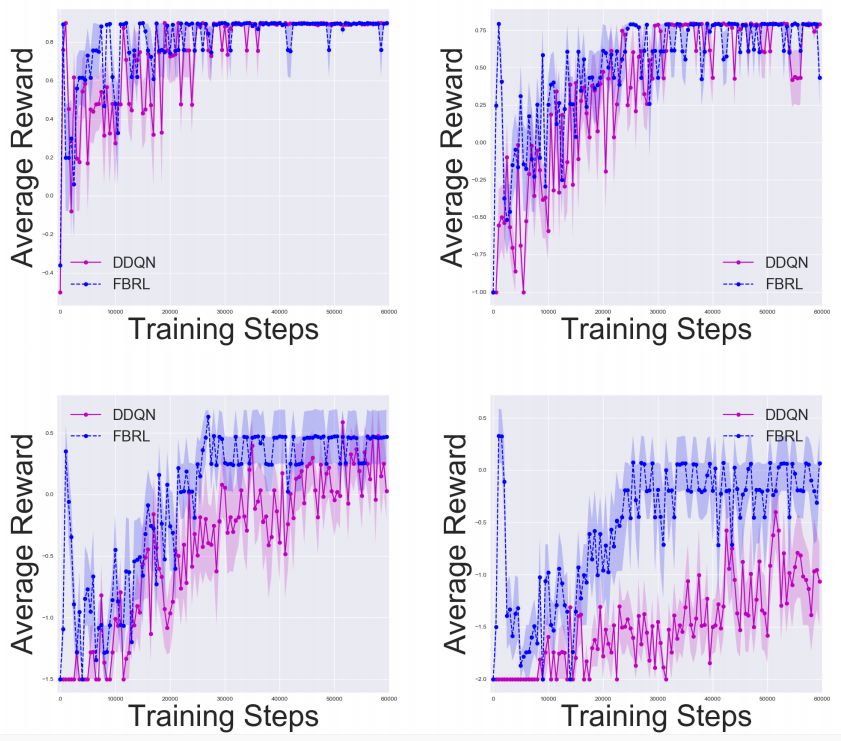
Gridworld中的實驗結(jié)果,其中n =5、10、15、20。我們分別使用50、100、150、200步的固定水平,結(jié)果是10次實驗的平均值。
相關(guān)研究
當(dāng)我們訪問真正的動態(tài)模型時,可以使用純粹基于模型的方法(如動態(tài)編程)來計算所有狀態(tài)的值(Sutton和Barto于1998年提出),盡管當(dāng)狀態(tài)空間較大或連續(xù)時,難以在整個狀態(tài)空間中進(jìn)行迭代。Q-Learning是一種無模型方法,它通過直接訪問狀態(tài)以在線方式更新值,而函數(shù)逼近技術(shù)(如Deep Q-Learning)可以泛化到未見的數(shù)據(jù)中(Mnih等人于2015年提出)。
基于模型和無模型信息的混合方法也可以使用。例如,DYNA-Q(Sutton于1990年提出)是一種早期的方法,它使用想象的轉(zhuǎn)出出來更新Q值,就如同在真實環(huán)境中經(jīng)歷過一樣。最近出現(xiàn)了更多方法,例如NAF(Gu等人于2016年提出)和I2A(Weber等人于2017年提出)。但這些方法只使用正向的想象力。
與我們自己的方法相似的方法是反向的值迭代(Zang等人于2007年提出),但這是一種純粹基于模型的方法,并且它不學(xué)習(xí)反向模型。一個相關(guān)的方法從一開始就實現(xiàn)雙向搜索和目標(biāo)(Baldassarre于2003年提出),但這項研究只是學(xué)習(xí)值,而我們的目標(biāo)是學(xué)習(xí)行動和值。
另一項相似的研究是通過使用接近目標(biāo)狀態(tài)的反向課程來解決問題(Florensa等人于2017年提出)。但是,該方法假設(shè)智能體可以在目標(biāo)附近得以初始化。我們不做這個假設(shè),因為了解目標(biāo)狀態(tài)并不意味著我們知道該如何達(dá)到這一狀態(tài)。
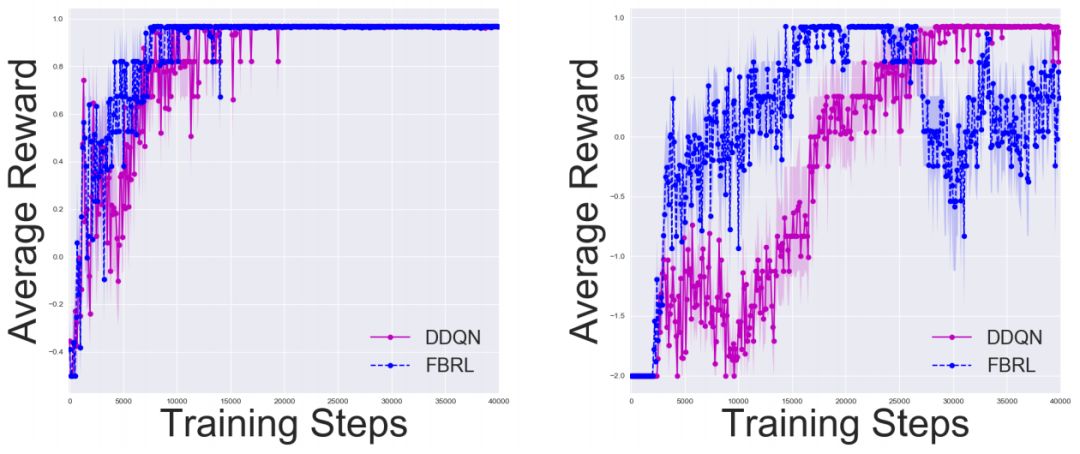
漢諾塔中的實驗結(jié)果,其中n = 2、3。我們分別使用50、100步的固定水平。 結(jié)果是10次試驗的平均值。
許多研究通過使用域知識來幫助加速學(xué)習(xí),例如獎勵塑造(Ng等人于1999年提出)。另一種方法是更有效地利用回放緩沖區(qū)中的經(jīng)驗。優(yōu)先經(jīng)驗復(fù)現(xiàn)(Schaul等人于2015年提出)旨在回放具有高TD誤差的樣本。事后經(jīng)驗回放(Hindsight experience replay)將環(huán)境中的每個狀態(tài)視為一個潛在目標(biāo),這樣即使系統(tǒng)無法達(dá)到所需的目標(biāo),也可以進(jìn)行學(xué)習(xí)。
使用反向動力學(xué)的概念類似于動力學(xué)逆過程(Agrawal等人于2016年,Pathak等人于2017年提出)。在這些方法中,系統(tǒng)預(yù)測在兩個狀態(tài)之間產(chǎn)生轉(zhuǎn)換的動態(tài)。我們的方法是利用狀態(tài)和動作來預(yù)測前一個狀態(tài)。此函數(shù)的目的是進(jìn)行反向操作,并使用此分解來學(xué)習(xí)靠近目標(biāo)的值。
本文中,我們介紹了一種加速學(xué)習(xí)具有稀缺獎勵問題的方法。我們介紹了FBRL,它從目標(biāo)的反向過程中得到了想象步驟。我們證明了該方法在Gridworld和諾塔中的性能表現(xiàn)優(yōu)于DDQN。這項研究有多個擴(kuò)展方向。
我們對于評估一個反向計劃方法很感興趣,但我們也可以運用正向和反向的想象力進(jìn)行訓(xùn)練。另一項進(jìn)步是改善規(guī)劃策略。我們使用了一種具有探索性和貪婪性的方法,但沒有評估如何在兩者之間進(jìn)行權(quán)衡。我們可以使用優(yōu)先掃描(Moore和Atkeson等人于1993年提出),它選擇那些能夠?qū)е戮哂懈逿D誤差狀態(tài)的行為。
-
谷歌
+關(guān)注
關(guān)注
27文章
6231瀏覽量
108113 -
智能
+關(guān)注
關(guān)注
8文章
1733瀏覽量
120132
原文標(biāo)題:谷歌大腦提出對智能體進(jìn)行「正向-反向」強化學(xué)習(xí)訓(xùn)練,加速訓(xùn)練過程
文章出處:【微信號:AItists,微信公眾號:人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
IBM推動AI智能體應(yīng)用加速普及
什么是AI智能體






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論