 未來實例分割中更具挑戰性的一個問題 將單個對象進行細分
未來實例分割中更具挑戰性的一個問題 將單個對象進行細分
近日,Yann LeCun 等人發表了一篇針對未來實例分割預測的論文。該論文提出了一種預測模型,可通過預測卷積特征來對未來實例分割進行預測。該算法有以下幾大優勢:
可以處理模型輸出大小不固定的情況,如對象檢測和實例分割;
不需要使用帶有標記的視頻序列進行訓練,可以直接從未標記的數據中計算出中間的 CNN 特征映射圖;
支持可生成多個場景解釋的模型,如曲面法線、對象邊界框和人體部分標簽,而不需要針對這些任務設計合適的編碼器和損失函數。

▌簡介
預測未來事件是實現智能行為的一個重要的先決條件,而視頻預測就是其中一項任務。最近的研究表明,在對未來幀進行語義分割時,在語義層面上的預測,比先預測 RGB 幀,然后將其分段更加有效。本文考慮了未來實例分割中更具挑戰性的一個問題——將單個對象進行細分。為了處理各圖像中不同數量的輸出標簽,我們在 Mask R-CNN 實例分割模型的固定尺寸卷積特征空間中開發了一個預測模型。
我們將 Mask R-CNN 框架的“探測頭(detection head)”應用于預測特征,以產生未來幀的實例分割。實驗表明,與基于光流(optical flow)的基線相比,該算法在性能上有顯著提升。
圖 1:預測未來 0.5 秒。 光流基線 (a) 和本文算法 (b) 的實例分割比較。來自文獻 [8] 的算法 (c) 和本文的實例語義分割算法 (d) 的語義分割比較。實例建模顯著提高了單個行人的分割精度。
我們的貢獻如下:
引入未來實例預測這一新任務,在語義上比之前研究的預期識別任務更為豐富。
基于預測未來幀的高維卷積神經網絡特征的自監督算法,支持多種預期識別任務。
實驗結果表明我們的特征學習算法相對于強光流基線有所改進。
預測未來實例分割的特征
本節簡要回顧了 Mask R-CNN 框架實例分割框架,然后介紹了如何通過預測未來幀的內部 CNN 特征,將該框架用于預期識別(anticipated recognition)。
使用 Mask R-CNN 進行實例分割
Mask R-CNN 模型主要由三個主要階段組成。首先,使用一個 CNN 主干框架結構提取高層特征映射圖。其次,候選區域生成網絡 (RPN) 利用這些特征以包含實例邊界框坐標的形式產生興趣區域(ROI)。候選邊界框用作興趣區域層的輸入,通過在每個邊界框中插入高級特征,為每個邊界框獲取固定大小的表示(不管大小)。 將每個興趣區域的特征輸入到檢測分支,并產生精確的邊界框坐標、類別預測以及用于預測類別的固定二進制掩碼。最后,在預測的邊界框內將掩碼插入到圖像分辨率中,并報告為預測類的一個實例分割。
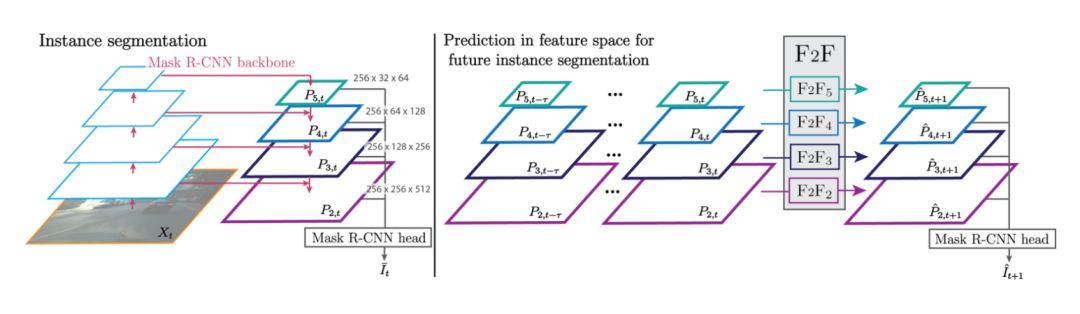
圖2 :左,自上而下的特征采樣結合相同分辨率吧的自下而上的特征,從而獲得的 FPN(feature pyramid network) 算法主干框架中的特征。右,為了得到未來實例分割,我們從 t-τ 到 t 幀提取 FPN 特征,并預測 t + 1 幀的 FPN 特征。
預測卷積特征
對處于不同 FPN 層級的特征進行訓練,并將其作為共享“探測頭(detection head)”的輸入。然而,由于分辨率在不同層級上會發生改變,每層上的“空間-時間”動態特性也會不同。 因此,我們提出了一種多尺度算法,對每一級采用單獨的網絡進行預測。每級網絡都經過訓練,彼此完全獨立地工作。對于每一級,我們關注的是特征維度輸入序列的特征。
實驗評估
我們使用的是 Cityscapes 數據集,數據來自于汽車在駕駛過程中錄制的城市環境視頻,每個視頻片段時長 1.8 秒,一共分為 2,975 個訓練集,500 個驗證集和 1,525 個測試集。
我們使用在 MS-COCO 數據集上預先訓練好的的 Mask R-CNN 模型,并在 Cityscapes 數據集上以端到端的形式對其進行微調。
未來實例分割:表1為未來特征預測算法 (F2F) 的實例分割結果,并將其與 Oracle、Copy 和光流基線的性能做比較。由表可知,F2F 算法效果最好,比最佳的中期基線提高了 74% 以上。
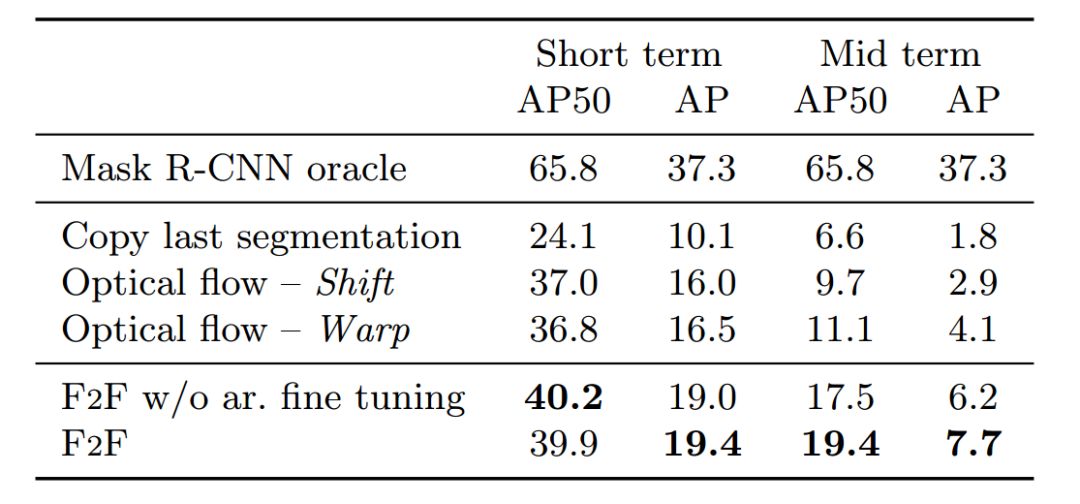
表1:Cityscapes val.數據集上實例分割的精確度
未來語義分割:我們發現,F2F 算法在 IoU 方面比所有的短期分割方法都有明顯的改進,以61.2 %的成績排名第一。
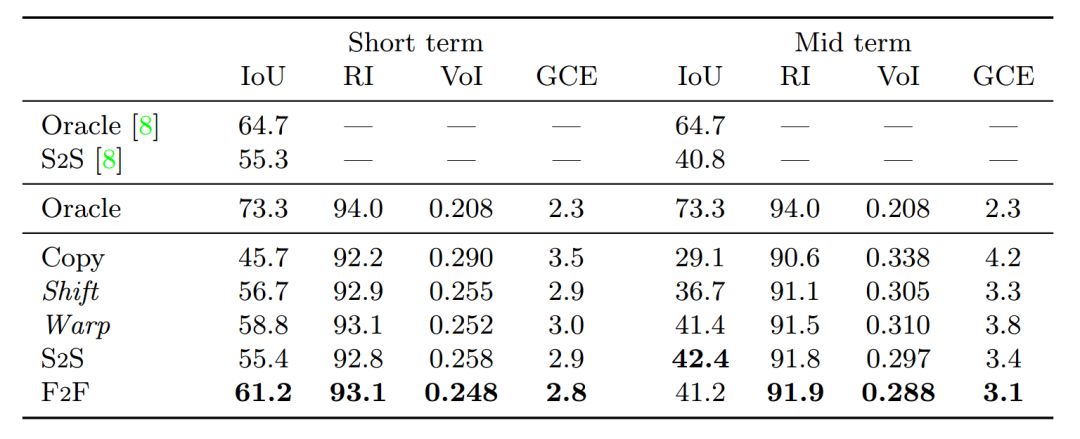
表2: 不同算法在 Cityscapes val. 數據集上的移動對象( 8 類)短期和中期語義分割表現。
圖4顯示,與 Warp 基線相比, F2F 算法能夠與對象的實際布局更好地對齊,這表明該算法已經學會了對場景和對象的動態建模,且效果比基線好。如預期所示,預測的掩碼也比那些 S2S 算法更加精確。
圖4:對三個序列的中期預測(未來 0.5 秒)。
通過圖5展示的示例,我們可以更好地理解,為什么在語義分割度量標準方面,F2F 和 Warp 基線之間的差異比實例分割度量標準要小很多。
圖5:用 Warp 基線和 F2F 模型獲得的中期預測的實例和語義分割。不準確的實例分割會導致精確的語義分割區域,請看圖中的橙色矩形高光部分。
失敗案例討論
在圖6(a) 的第一個例子中,由于前面的所有模型認為白色轎車完全被另一輛車遮擋,因此沒有檢測到。這是不可避免的一種情況,除非對象在較早的幀中可見,在這種情況下,長期記憶機制可能會避免不必要的錯誤。
在圖 6(b) 中,卡車和行人的預測掩碼在形狀和位置上都不連貫。用明確建模遮擋機制或許可以獲得更一致的預測。
最后,由于對象本身比較模糊,某些運動和形狀轉換很難得到準確的預測,如圖 6(c)中的行人的腿部,對于這種情況,確切的姿勢存在高度的不確定性。
-
編碼器
+關注
關注
45文章
3780瀏覽量
137300 -
圖像
+關注
關注
2文章
1094瀏覽量
41059 -
人工智能
+關注
關注
1804文章
48788瀏覽量
246927
原文標題:Yann LeCun等最新研究:如何對未來實例分割進行預測?
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何選擇LTE系統測試方法,存在哪些挑戰?
設計了一個定制形狀的圣誕樹
如何使用Wemos D1 mini制作一款簡單但具有挑戰性的游戲?
音頻設計:比你所想象的更富挑戰性
聚焦語義分割任務,如何用卷積神經網絡處理語義圖像分割?
Facebook AI使用單一神經網絡架構來同時完成實例分割和語義分割

深度學習在視頻對象分割中的應用及相關研究


點云分割相較圖像分割的優勢是啥?

康謀分享 | 在基于場景的AD/ADAS驗證過程中,識別挑戰性場景!






 工商網監
工商網監
評論