 思必馳與上海交大聯合實驗室12篇論文被ICASSP 2025收錄
思必馳與上海交大聯合實驗室12篇論文被ICASSP 2025收錄

2025年度國際聲學語音與信號處理會議——ICASSP在印度海得拉巴舉辦,作為語音領域的國際會議,其憑借權威、廣泛的學界以及工業界影響力,備受各方關注。今年許多學者因故無法前往印度參加會議。考慮到廣大學者的現場交流需求,IEEE信號處理學會特別安排ICASSP 2025在5月23日-25日于蘇州舉辦衛星會議。思必馳-上海交大聯合實驗室團隊將參與本次現場交流。
在本次ICASSP 2025會議上,思必馳-上海交大聯合實驗室共發表了12篇論文,涵蓋了音頻信息處理、語音喚醒識別、語音合成、多模態生成等研究方向,實現了若干針對噪聲環境、低資源、多語種、多模態等場景的技術突破,為思必馳的全鏈路語音語言核心技術實力以及業務創新能力帶來多重增益。下面介紹本次發表的部分典型研究成果:
音頻信息處理
Neural Directed Speech Enhancement with Dual Microphone Array in High Noise Scenario
針對多說話人場景實現了目標語音的靈活增強,僅使用雙麥克風陣列就顯著提高了語音質量和下游任務的性能,尤其是在極低信噪比條件下表現出色。
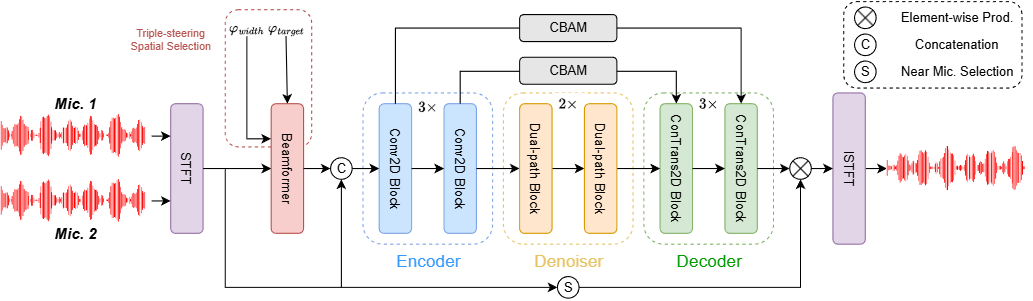
工作簡介:在多說話人場景中,利用空間特征對增強目標語音極為關鍵,但麥克風陣列有限時,構建緊湊的多通道語音增強系統頗具挑戰,極低信噪比下更是難上加難。為此,我們創新提出三導向空間選擇方法,打造靈活框架,用三個導向向量指導增強、界定范圍。具體引入因果導向的U型網絡(CDUNet)模型,以原始多通道語音與期望增強寬度為輸入,據此依目標方向動態調導向向量,結合目標和干擾信號角分離微調增強區域。該模型僅憑雙麥克風陣列,就在語音質量與下游任務表現上十分出色,還具備實時操作、參數少的特性。
語音喚醒識別
NTC-KWS: Noise-aware CTC for Robust Keyword Spotting
針對噪聲環境下的關鍵詞識別提出“NTC-KWS”,強化了在車載、家電等噪音場景下的喚醒和識別精準度,也為資源受限設備帶來高魯棒性的端到端方案。
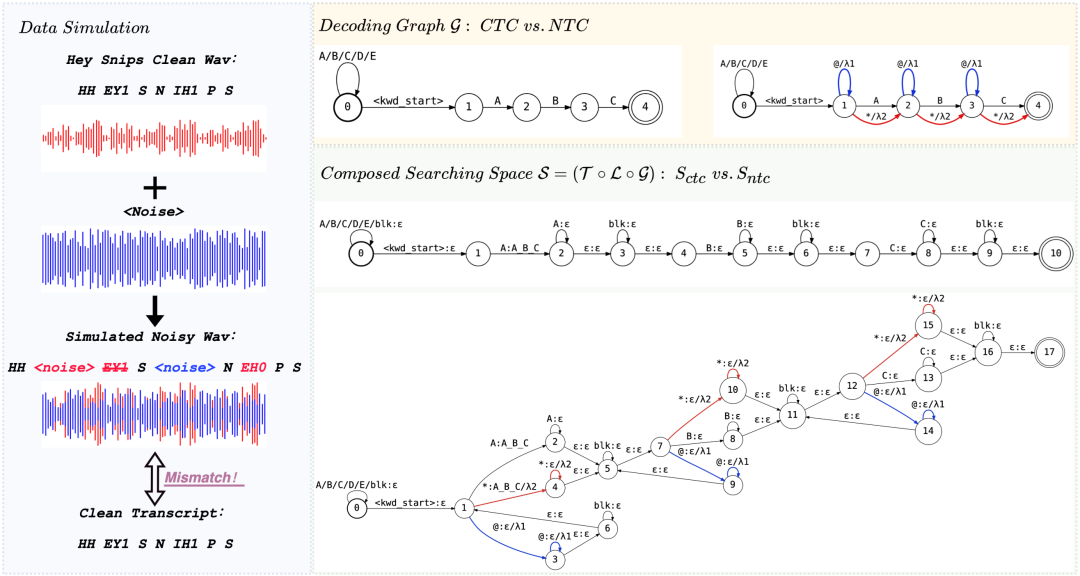
工作簡介:當前基于CTC的小型化關鍵詞識別系統在低資源計算平臺上部署時,因模型尺寸和計算能力限制,面臨噪聲過擬合問題,導致高誤報率,尤其在復雜聲學環境下性能顯著下降。因此,我們在CTC-KWS的框架下提出一種噪聲感知關鍵詞識別系統(NTC-KWS),創新性地引入兩類額外的通配符弧對噪聲進行建模:自環弧處理噪聲導致的插入錯誤,旁路弧應對噪聲過大造成的掩蔽和干擾,旨在提高模型在噪聲環境中的魯棒性。實驗表明,NTC-KWS在各種聲學條件下優于現有端到端系統和CTC-KWS基線,低SNR條件下優勢尤為顯著。該工作為資源受限設備提供了輕量化且高魯棒的關鍵詞識別方案,其噪聲建模機制可擴展至其他端到端語音敏感任務。
語音合成
VALL-T: Decoder-Only Generative Transducer for Robust and Decoding-Controllable Text-to-Speech
針對魯棒、可控語音合成提出“VALL-T”(生成式Transducer模型),進一步提升了思必馳在多語種、多場景高保真TTS方面的性能穩定性。
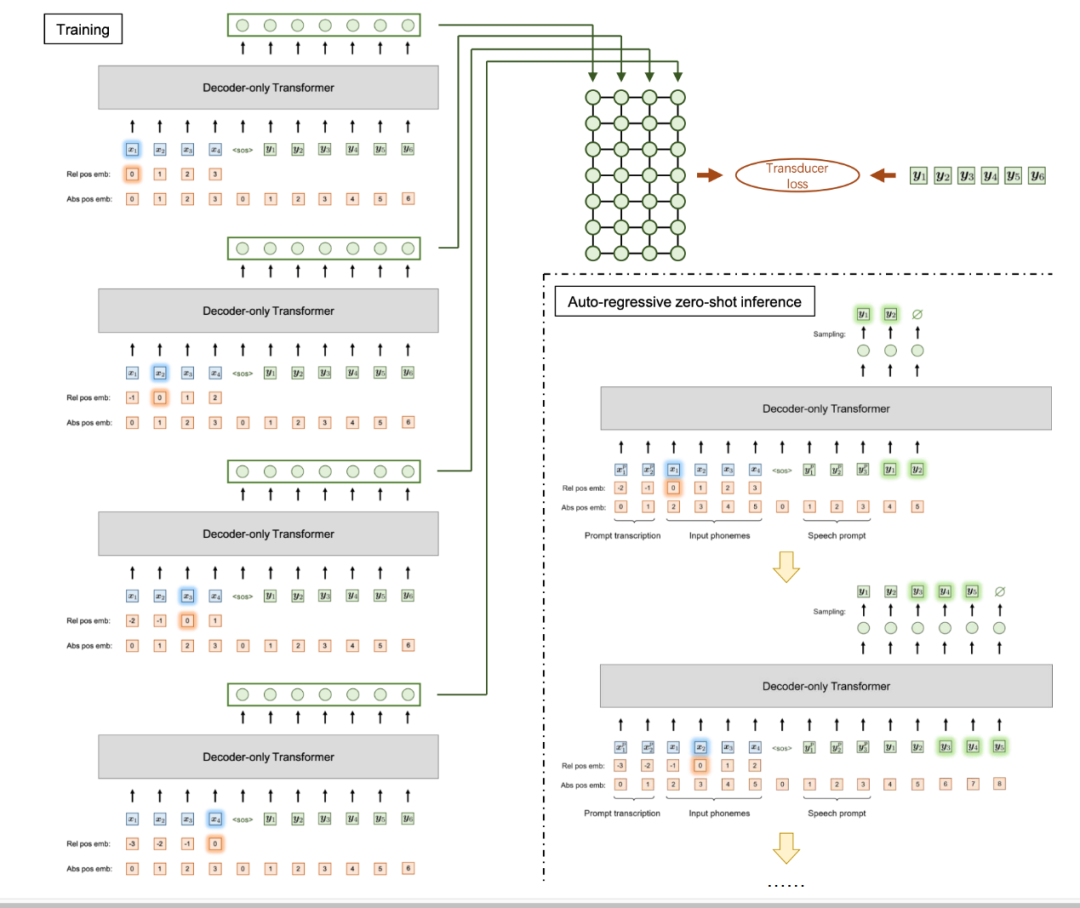
工作簡介:當前基于decoder-only Transformer架構的TTS模型缺乏單調對齊約束,導致發音錯誤、跳詞和難以停止等幻覺問題,嚴重制約其實際應用可靠性。
因此,我們提出了VALL-T,即生成式Transducer模型,它為輸入音素序列引入了移位的相對位置編碼,明確地限制了單調的生成過程,同時保持了decoder-only Transformer的架構。實驗表明,我們的模型對幻覺表現出更好的魯棒性,詞錯誤率相對降低了28.3%。此外,還可以通過對齊的可控性實現跨語言適配和長語音穩定合成。
多模態生成
Smooth-Foley: Creating Continuous Sound for Video-to-Audio Generation Under Semantic Guidance
“Smooth-Foley” 視頻到音頻生成模型,擴展了智能汽車、智能家居、虛擬數字人等垂域解決方案上的產品形態,為思必馳進一步拓展視聽融合交互提供技術儲備。
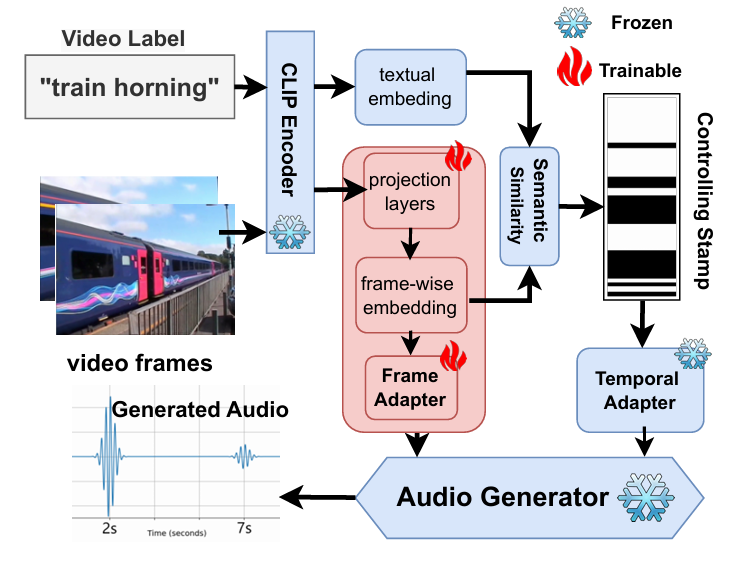
工作簡介:視頻到音頻(V2A)生成任務需同步滿足高精度時間對齊與強語義一致性,但現有方法因低分辨率的語義條件與時間條件不夠精確的限制,難以處理動態物體視頻中的復雜聲景生成。因此,我們提出了Smooth-Foley,一種視頻到音頻的生成模型,不僅在生成過程提供文本標簽的語義引導,以增強音頻的語義和時間對齊;還通過訓練幀適配器和時間適配器以利用預訓練的文本到音頻生成模型。實驗表明,Smooth-Foley在連續聲音場景和一般場景中均優于現有模型。生成的音頻具有更高的質量并更好遵循物理規律。
多模態生成
SLAM-AAC: Enhancing Audio Captioning with Paraphrasing Augmentation and CLAP-Refine through LLMs
“SLAM-AAC”通過高性能模型、創新的數據增強和解碼策略,顯著提升了音頻字幕生成的性能。該項工作是開源項目“SLAM-LLM”的一部分,積極推動多模態大模型技術的創新與發展,促進全球研究者的技術交流與合作。
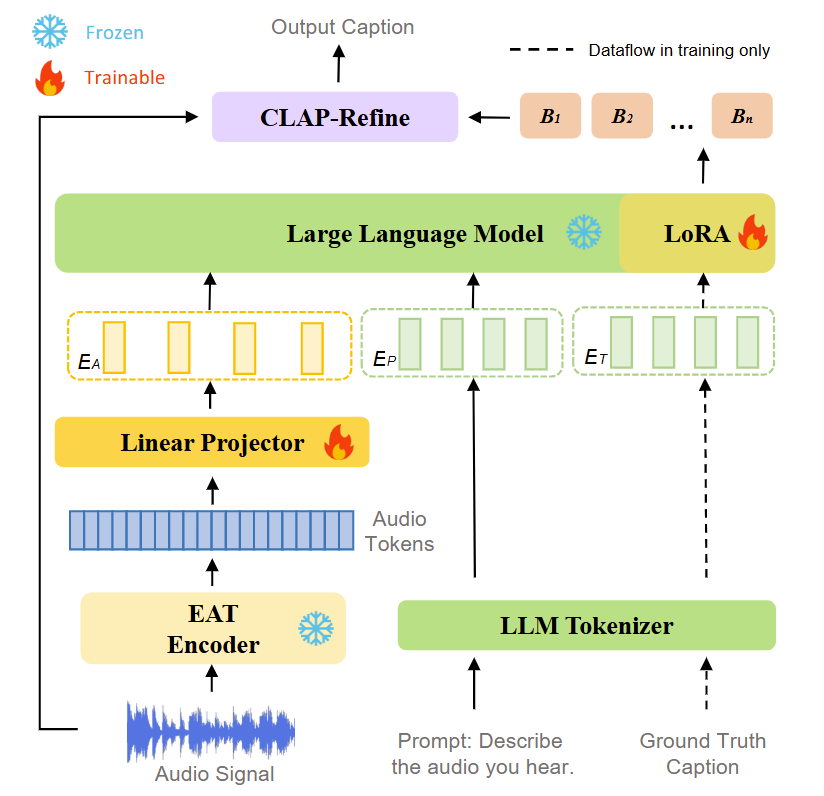
工作簡介:盡管目前音頻預訓練模型與大語言模型(LLMs)的發展為自動音頻描述(AAC)提供了更強的音頻理解和文本生成能力,但如何高效對齊多模態特征并利用有限數據仍是關鍵問題。因此,我們提出SLAM-AAC,通過兩階段創新策略優化AAC:首先,借鑒機器翻譯中的回譯方法,擴展Clotho數據集的文本多樣性,緩解數據稀缺的問題;其次在推理階段引入即插即用的CLAP-Refine方法,從多個束搜索生成的文本描述中選擇與音頻最匹配的描述。實驗表明,SLAM-AAC在Clotho V2和AudioCaps數據集上顯著超越主流模型,該工作為小規模音頻-文本數據下的AAC提供了可擴展解決方案,使其有可能用于其他多模態生成任務。
ICASSP (International Conference on Acoustics, Speech and Signal Processing) 即國際聲學、語音與信號處理會議,是IEEE(電氣與電子工程師協會)主辦的全世界最大的,也是最全面的信號處理及其應用方面的頂級會議,在國際上享有盛譽并具有廣泛的學術影響力。2025年度ICASSP會議主題是 “Celebrating Signal Processing”,旨在慶祝信號處理領域的卓越成就與創新突破。
長期以來,思必馳深度融入國內外學術前沿陣地,在 ICASSP、INTERSPEECH、ACL、EMNLP、AAAI 等頂尖學術大會上屢創佳績,持續輸出高質量科研成果。思必馳-上海交大聯合實驗室通過一系列高水準論文,展現出在人工智能語音語言關鍵技術領域的深度探索與重大突破,為行業發展注入強勁動力。思必馳堅定科研與產業應用密切結合,也將繼續探索科技成果的應用轉化。
作為專業的對話式人工智能平臺型企業,思必馳具有源頭技術創新和應用創新的能力,自2022年7月獲國家科技部批準建設“語言計算國家新一代人工智能開放創新平臺”以來,接連于2023-2024年獲批組建蘇州市、江蘇省、長三角三級創新聯合體,并于2025年攜手上海交通大學、蘇州大學,牽頭組建“江蘇省語言計算及應用重點實驗室”,成為國家人工智能戰略科技力量的重要組成部分。
思必馳承擔了包括國家重點研發計劃、國家發改委“互聯網+”重大工程和人工智能創新發展工程、國家工信部人工智能與實體經濟深度融合項目、長三角科技創新共同體聯合攻關計劃項目等十余項國家級、省部級項目,展現出卓越的科研實力與項目落地能力。
思必馳深耕語音語言領域,憑借自主研發的核心技術多次在國際研究機構評測中奪得冠軍;曾三度斬獲國內人工智能最高獎“吳文俊獎”,榮獲中國專利優秀獎,以及信通院車載智能語音交互系統最高級別認證等重要榮譽。技術創新能力備受全球矚目,被高盛全球人工智能報告列為關鍵參與者,也被Gartner評為東亞五大明星AI公司之一。
截至2024年年底,思必馳擁有近100項全球獨創技術,已授權知識產權1597件,其中已授權發明專利633項,參與了71項國家/行業/團體標準,獲得23項國家級的產品認證。近期,大模型人機對話技術創新與產業賦能發展提速,思必馳堅持自主的大模型技術路線,即“構建可靠性優先的1+N分布式智能體系統:1 個中樞大模型+ N 個垂域模型及全鏈路交互組件組成全功能系統”,以任務型交互為核心,結合智能硬件感知優勢,構建垂域大模型和中樞大模型系統,服務企業客戶。
-
音頻
+關注
關注
29文章
3039瀏覽量
83390 -
信息處理
+關注
關注
0文章
36瀏覽量
10211 -
思必馳
+關注
關注
4文章
337瀏覽量
15311
原文標題:ICASSP2025蘇州衛星會議|思必馳-上海交大聯合實驗室12篇論文將于語音技術頂會現場交流
文章出處:【微信號:思必馳,微信公眾號:思必馳】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
思必馳與上海交大聯合實驗室研究成果入選兩大頂級會議

愛普生與南山電子晶體電路評估聯合測試實驗室成立
思必馳與上海交大聯合實驗室兩篇論文入選ICML 2025





 工商網監
工商網監
評論