 思必馳與上海交大聯合實驗室研究成果入選兩大頂級會議
思必馳與上海交大聯合實驗室研究成果入選兩大頂級會議

近日,計算語言學與自然語言處理領域全球頂級會議ACL 2025及語音研究領域旗艦會議INTERSPEECH 2025相繼公布論文錄用結果。思必馳-上海交大聯合實驗室表現亮眼,共有13篇論文被兩大會議收錄!
ACL是中國計算機學會(CCF)推薦的A類頂級國際學術會議,代表著計算語言學和自然語言處理領域的最高水平。INTERSPEECH由國際語音通信協會(ISCA)主辦,是全球最大、最綜合性的語音信號處理領域科技盛會。
本次收錄的論文成果涵蓋了大模型檢索增強生成、語音編解碼與表示學習、低延遲語音合成、低資源語音識別、可靠音頻語言模型等前沿方向,在多模態檢索增強生成、說話人解耦低比特率編碼、高效非自回歸語音合成、大規模低資源語料庫構建與自訓練、模型可靠性增強等關鍵技術上取得重要突破。這些研究共同推動高效、可靠、低資源友好的智能語音語言技術發展,為思必馳的全鏈路語音語言核心技術實力以及業務創新能力帶來多重增益。以下為部分成果介紹:
面向長文檔問答的大模型可靠檢索
NeuSym-RAG: Hybrid Neural Symbolic Retrieval with Multiview Structuring for PDF Question Answering
NeuSym-RAG在自建數據集AIRQA-Real上以17.3%絕對優勢超越經典RAG,通過神經與符號檢索協同、多視角結構化解析,讓企業級大模型在處理海量半結構化文檔時保持高可靠性與可擴展性,同時兼具成本可控能力。
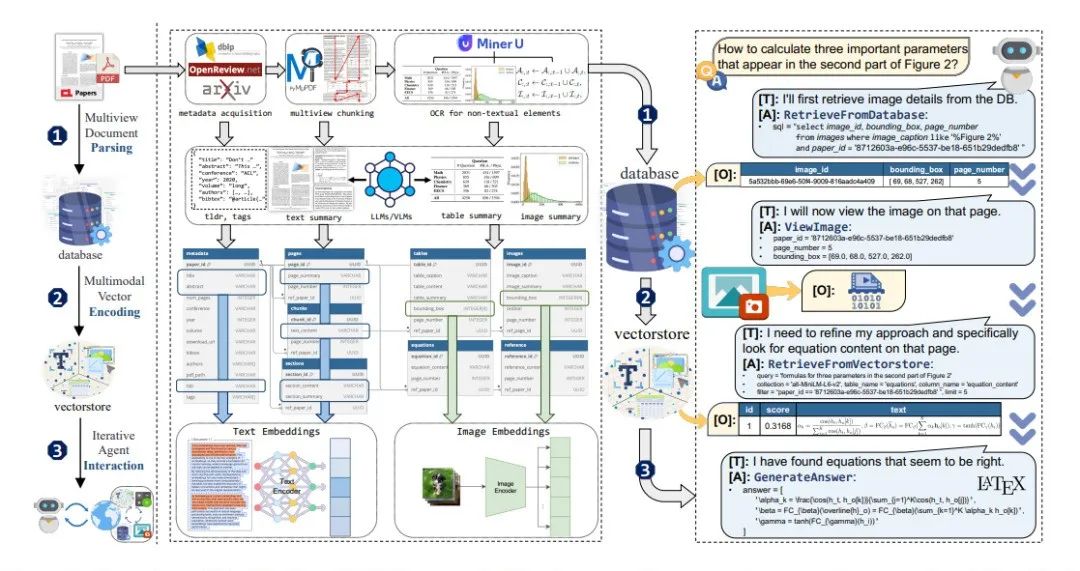
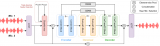
論文簡介:基于大語言模型(LLM)的檢索增強生成(RAG)技術在自動問答任務中展現出廣闊前景,但現有方法往往將神經檢索與符號檢索割裂處理,未能充分發揮二者的互補優勢。此外,傳統的單視角文本切分方式忽略了PDF文檔中豐富的結構與版面信息,如章節、表格等。為此,本文提出NeuSym-RAG,一種神經-符號融合的混合式檢索框架,在智能體與知識庫的交互中結合兩種檢索范式。該方法通過多視角元素切分與基于數據庫模式的解析,將半結構化PDF中的內容同時組織進關系型數據庫與向量庫中,使得大模型智能體能夠迭代式地檢索上下文,直至獲取足夠信息以生成答案。在三個基于完整 PDF 的問答數據集(包括一個自建的學術問答集 AIRQA-REAL)上的實驗表明,NeuSym-RAG 穩定優于僅基于向量的RAG方法和多種結構化基線,證明了其在統一檢索機制與多視角利用方面的優勢。
低碼率語音傳輸
LSCodec: Low-Bitrate and Speaker-Decoupled Discrete Speech Codec
LSCodec 提出了一種超低比特率且說話人解耦的離散語音編解碼器,在保證聽感的前提下顯著壓縮語音編碼,并把說話人信息與內容徹底分離,讓云端或邊緣設備都能以更低帶寬、更小模型安全傳輸和生成高品質語音。
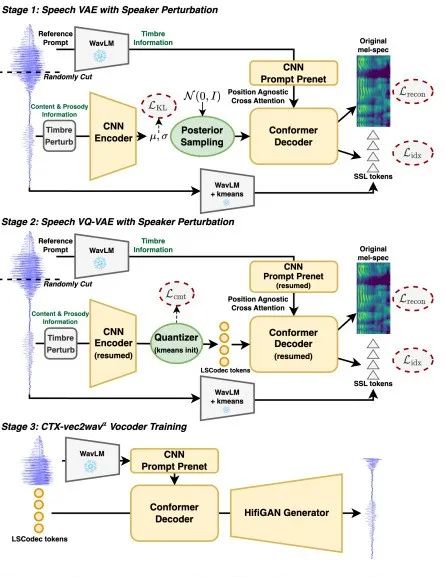
論文簡介:盡管離散語音標記在基于語言模型的語音生成方面展現出強大潛力,但其高比特率和冗余的音色信息限制了此類模型的發展。在這項工作中,我們提出了LSCodec,一種兼具低比特率和說話人解耦能力的離散語音編解碼器。LSCodec采用多階段無監督訓練框架并結合說話人擾動技術。首先建立一個連續信息瓶頸,然后通過向量量化生成一個離散的說話人解耦空間。最后,一個離散標記聲碼器從LSCodec中細化聲學細節。通過重建評估,LSCodec在僅使用單個碼本和比基線更小的詞匯量的情況下,展現出卓越的可懂度和音頻質量。語音轉換和說話人探測實驗證明了LSCodec出色的說話人解耦能力,消融研究驗證了所提出訓練框架的有效性。
低延遲語音合成
Unlocking Temporal Flexibility: Neural Speech Codec with Variable Frame Rate
提出TFC(時序靈活編碼)技術,首次將可變幀率(VFR)引入神經語音編解碼器,讓語音編碼“按需給幀”,在保持音質的同時顯著縮短傳輸/推理序列,實現實時語音服務的更快響應和更低云成本。
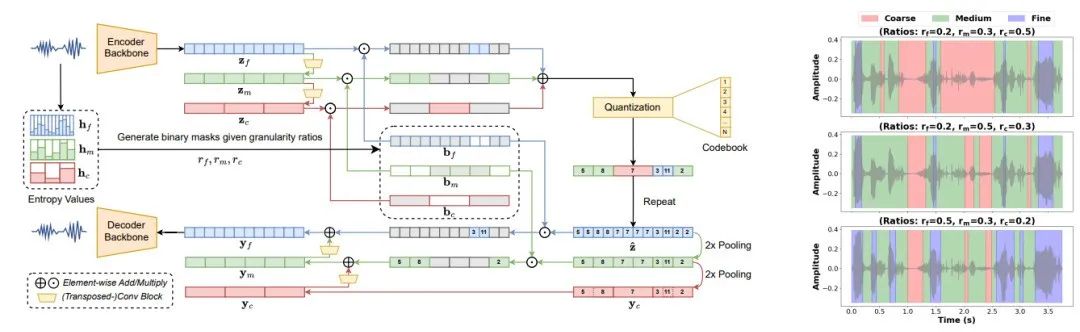
論文簡介:大多數神經語音編解碼器通過幀內機制(例如碼本丟棄)在恒定幀率(CFR)下實現比特率調整。然而,語音段本身具有時變的信息密度(例如靜音區間與有聲段)。這一特性使得CFR在比特率和詞元序列長度方面并非最優,影響了實時應用的效率。在本工作中,我們提出了一種時序靈活編碼(Temporally Flexible Coding, TFC)技術,首次將可變幀率(VFR)引入神經語音編解碼器。TFC支持無縫調整平均幀率,并基于時序熵動態分配幀率。實驗結果表明,采用TFC的編解碼器能以高度靈活性實現最優重建質量,并在較低幀率下保持競爭力。該方法有望與其他低幀率神經語音編解碼技術結合,為下游任務提供更高效的解決方案。
長期以來,思必馳深度參與國內外學術前沿研究,在ICASSP、INTERSPEECH、ACL、EMNLP、AAAI、ICML等頂級學術會議上屢獲佳績,持續產出高質量科研成果。思必馳-上海交大聯合實驗室憑借一系列高水平論文,彰顯了在人工智能語音語言關鍵技術領域的深度探索和重大突破,為行業的發展注入了強大動力。思必馳秉持科研與產業應用緊密結合的理念,未來也將持續探索科技成果的應用轉化。
作為專業的對話式人工智能平臺型企業,思必馳具有源頭技術創新和應用創新的能力,自2022年7月獲國家科技部批準建設“語言計算國家新一代人工智能開放創新平臺”以來,接連于2023-2024年獲批組建蘇州市、江蘇省、長三角三級創新聯合體,并于2025年攜手上海交通大學、蘇州大學,牽頭組建“江蘇省語言計算及應用重點實驗室”,成為國家人工智能戰略科技力量的重要組成部分。
思必馳承擔了包括國家重點研發計劃、國家發改委“互聯網+”重大工程和人工智能創新發展工程、國家工信部人工智能與實體經濟深度融合項目、長三角科技創新共同體聯合攻關計劃項目等十余項國家級、省部級項目,展現出卓越的科研實力與項目落地能力。
思必馳深耕語音語言領域,憑借自主研發的核心技術多次在國際研究機構評測中奪得冠軍;曾三度斬獲國內人工智能最高獎“吳文俊獎”,榮獲中國專利優秀獎,以及信通院車載智能語音交互系統最高級別認證等重要榮譽。技術創新能力備受全球矚目,被高盛全球人工智能報告列為關鍵參與者,也被Gartner評為東亞五大明星AI公司之一。
截至2024年年底,思必馳擁有近100項全球獨創技術,已授權知識產權1597件,其中已授權發明專利633項,參與了71項國家/行業/團體標準,獲得23項國家級的產品認證。近期,大模型人機對話技術創新與產業賦能發展提速,思必馳堅持自主的大模型技術路線,即“構建可靠性優先的1+N分布式智能體系統:1 個中樞大模型+ N 個垂域模型及全鏈路交互組件組成全功能系統”,以任務型交互為核心,結合智能硬件感知優勢,構建垂域大模型和中樞大模型系統,服務企業客戶。
-
人工智能
+關注
關注
1806文章
48987瀏覽量
249054 -
思必馳
+關注
關注
4文章
337瀏覽量
15309 -
自然語言
+關注
關注
1文章
292瀏覽量
13652 -
大模型
+關注
關注
2文章
3132瀏覽量
4047
原文標題:ACL2025 + INTERSPEECH2025|思必馳-上海交大聯合實驗室13篇論文被收錄
文章出處:【微信號:思必馳,微信公眾號:思必馳】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
思必馳宣布,再獲新一輪融資
思必馳與上海交大聯合實驗室兩篇論文入選ICML 2025
思必馳與上海交大聯合實驗室12篇論文被ICASSP 2025收錄





 工商網監
工商網監
評論