 梯度爆炸問題的介紹和如何解決爆炸問題詳細概述
梯度爆炸問題的介紹和如何解決爆炸問題詳細概述
最近在做一個文本檢測的項目,在訓練的過程中遇到了很嚴重的梯度爆炸情況,今天就來談談梯度爆炸怎么解決。
首先我們要清楚,為什么會產生梯度爆炸。要知道就目前來說,我們一般都認為深層的神經網絡會比淺層的神經網絡的表現要好,所以在處理一些較為復雜的任務的時候,人們往往會使用更深層次的神經網絡,而現在的大部分神經網絡的權重更新都要依靠反向傳播。
那么,問題來了。要知道權重的更新的公式是這樣的:
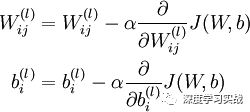
對于每個變量的更新,都要求梯度,也就是求鏈式偏導。假如,我們想象一下,我們的模型處在一個很陡的陡坡上,那么在求梯度的時候,在網絡層上出現了指數型的遞增,也就是說,梯度爆炸了。
那么具體上是怎么樣的呢?我們來看下面這張圖:
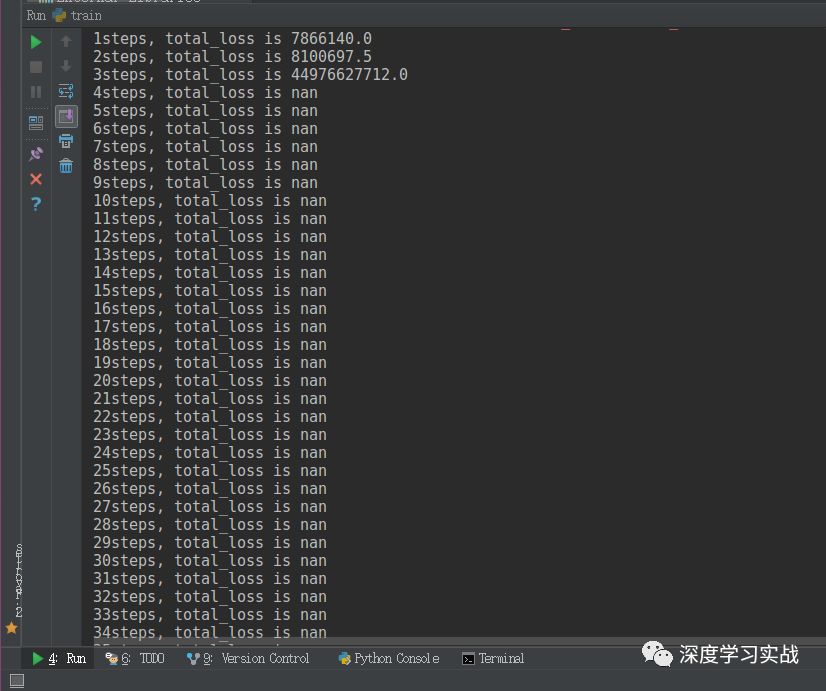
可以看到,上面是我輸出的每一步的損失函數的值,損失值在指數型地增加。nan是not a number的意思,它表示無窮大的數或者無意義的數。遇到這個問題的時候,我第一反應是:是不是我學習率太大了。然后我調小了學習率,發現情況有所改善,但是到最后還是出現的梯度爆炸。然后我又思考,會不會是我網絡結構有問題啊,為了驗證這問題,我把batch size調為了1,固定輸入一張圖片,發現也是收斂到一定程度也出現了梯度爆炸的情況。那么我可以斷定了,是由于網絡層數過多導致的梯度爆炸的問題。
問題找到了,那我面臨了兩個選擇:一是降低網絡層數,二是做梯度裁剪。考慮到了數據的復雜性,我選擇了后者。好,那就來說說梯度裁剪是什么?如何做梯度裁剪。
梯度裁剪
梯度裁剪是指在一個變量計算的梯度過大的情況下,人為地將梯度控制在一定的范圍以內。

那直接來看一下代碼實現。
optimizer = tf.train.GradientDescentOptimizer(learning_rate)params = tf.trainable_variables()gradients = tf.gradients(loss, params)clipped_gradients, norm = tf.clip_by_global_norm(gradients, clip_norm)optimizer_op = optimizer.apply_gradients(zip(clipped_gradients, params), global_step)
你只要設置里面的clip_norm就可以了,那么設置多少合適呢?
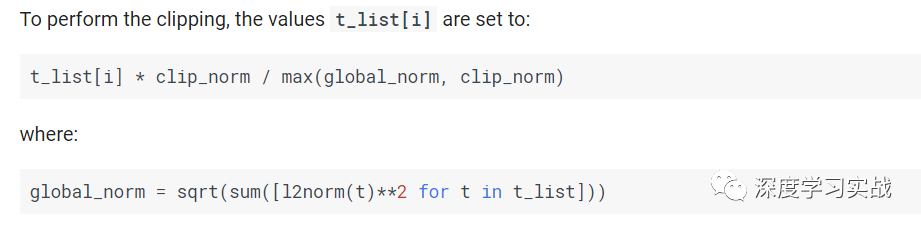
t_list在這里是所有梯度的張量,然后可以看下它是怎么算的。如果global_norm
-
神經網絡
+關注
關注
42文章
4795瀏覽量
102137 -
梯度
+關注
關注
0文章
30瀏覽量
10431
原文標題:項目實戰 | 實戰中如何解決梯度爆炸的問題
文章出處:【微信號:gh_a204797f977b,微信公眾號:深度學習實戰】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電視機顯像管為什么能爆炸傷人
格氏鋰電池爆炸了!!!爆炸了!!!
沖擊、碰撞、爆炸、跌落力測量系統介紹
電解電容爆炸的原因及措施
電解電容爆炸的原因分析
鉛酸電池會爆炸嗎_鉛酸電池爆炸的原因
電動車鋰電池爆炸原因_怎么防止電動車鋰電池爆炸
深度神經網絡的困擾 梯度爆炸與梯度消失






 工商網監
工商網監
評論