 邊緣計算中的機器學習:基于 Linux 系統的實時推理模型部署與工業集成!
邊緣計算中的機器學習:基于 Linux 系統的實時推理模型部署與工業集成!
你好,旅行者!歡迎來到 Medium 的這一角落。在本文中,我們將把一個機器學習模型(神經網絡)部署到邊緣設備上,利用從 Modbus TCP 寄存器獲取的實時數據來預測一臺復古音頻放大器的當前健康狀況。你將學習如何訓練模型、導出模型,并在基于 Linux 的系統上運行實時推理,并通過MQTT 發布結果。這是一個簡單但完整的流程——從工作站上的建模到在邊緣設備上運行工業風格的推理。
雖然需要了解 Linux、基礎網絡、Python 和機器學習包的使用,但本文提供了示例代碼,你可以按自己的節奏逐行學習。
架構
首先,在開始之前我們需要將想法具體化。經過了一次長達 5 分鐘、令人筋疲力盡的頭腦風暴后,我們可能已經有了一個大致的方向。然而,在推進之前,建議先為我們的項目定義一個架構。
無論是出于個人目標、學術實踐還是實際商業案例項目,擁有一個路線圖,明確我們要去哪里、為什么去以及如何去,都是非常有幫助的。
硬件堆棧
有哪些硬件可用?軟件提供了更多的靈活性,通常有不同的選項來做同樣的事情,但是這種額外的好處大部分時間取決于我們的項目可以使用什么樣的硬件。也許我們在家里沒有太多的選擇,只有一些主板,或者在專業環境中,客戶的項目預算可能會定義為確定的解決方案可以購買哪種設備。
我們所需的硬件包括:
筆記本電腦/工作站(這些測試使用 Windows 操作系統,但如果你愿意并知道如何操作,可以在任何 Linux 發行版上使用等效軟件)
樹莓派3,甚至可能是 2
以太網電纜
軟件堆棧
好的,在定義了一個友好且易于訪問的硬件設置后,讓我們來談談軟件。
樹莓派模塊使用 Raspbian 作為其操作系統,實際上它只是 Debian 的一種變體,而 Debian 是一種 Linux 發行版(意味著它使用 Linux 內核)。

有些 Linux 發行版確實非常專注于特定領域的適配,但幸運的是,Debian 和 Raspbian 是最流行且易于訪問的發行版之一。它們之間有很多不同,但要知道著名的 Ubuntu 操作系統也是基于 Debian 的。
這意味著我們可以輕松地從全球社區中找到大量軟件來實現我們的目標(或將其作為構建的工具或自己的工具)。
在本例中,我們將使用:
- Python 3.9+,作為編程語言
- pyModbusTCP,用于通過 ModbusTCP 工業協議進行通信
- paho-mqtt,用于通過 MQTT 發布/訂閱協議進行通信(在物聯網應用中非常流行)
- tensorflow & scikit-learn,用于開發、訓練和導出/導入/使用推理模型
- joblib,幫助我們導入導出的模型
- numpy,幫助我們管理模型中的數值數據結構,是機器學習中非常強大且必不可少的庫
- pandas,用于數據管理和處理,對數據科學和機器學習也非常有用
- matplotlib,用于可視化:生成圖表和繪圖
- Mosquitto Broker,一個可靠的 MQTT 代理,用于發布我們的模型結果
- QModMaster,一個 ModbusTCP 主站模擬器,用于測試我們的主/從通信

先決條件配置和安裝
在繼續之前,最好先準備好一切。你也可以稍后再回顧這一部分,但提前做好準備將有助于你順利地跟隨本文的進度。攜手共進吧。
在筆記本電腦/工作站上:
1.確保系統上已安裝 Python,如果沒有,請從 此處 下載并按照推薦的官方安裝說明進行安裝。
https://www.python.org/downloads/release/python-3100/
2.在 Documents 目錄下啟動一個 shell 或導航到該目錄
cdDocuments
為本項目創建一個目錄并導航到該目錄:
mkdirml_edge_projectcdml_edge_project
創建一個 Python 虛擬環境:
python-m venv .venv
激活虛擬環境:
下載并安裝所需的 Python 庫/包:
pipinstall paho-mqtt pandas numpy scikit-learn tensorflow matplotlib
下載并解壓 QModMaster 桌面應
https://sourceforge.net/projects/qmodmaster/
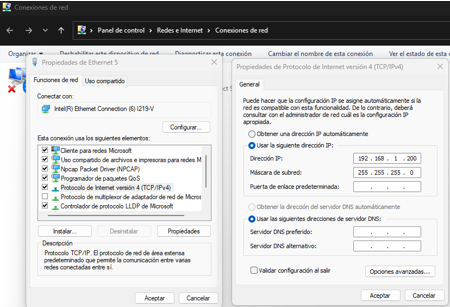
使用靜態 IPv4 地址配置機器的以太網端口。本例中使用 192.168.1.200。
在樹莓派上:
1.確保系統上已安裝 Python,如果沒有,請從 此處 下載并按照推薦的官方安裝說明進行安裝。
https://www.python.org/downloads/release/python-3100/
2.在 Documents 目錄下啟動一個 shell :
cdDocuments
為本項目創建一個目錄并導航到該目錄:
mkdirml_edge_projectcdml_edge_project
創建一個 Python 虛擬環境:
python-m venv .venv
激活虛擬環境:
sourceactivate venv
下載并安裝所需的 Python 庫/包:
pipinstall pyModbusTCP paho-mqtt tensorflow joblib numpy
下載、安裝并啟用 Mosquitto MQTT Broker:
sudo apt update && sudo apt upgradesudo apt install -y mosquitto mosquitto-clientssudo systemctlenablemosquitto.service
驗證 Mosquitto 安裝(打印版本):
mosquitto-v
配置訪問(基本上允許所有訪問,僅用于測試):
sudo nano /etc/mosquitto/mosquitto.conf
在文件末尾插入以下行:
listener1883allow_anonymoustrue
保存并退出。
1.使用靜態 IPv4 地址配置邊緣設備的以太網端口。本例中使用 192.168.1.75。

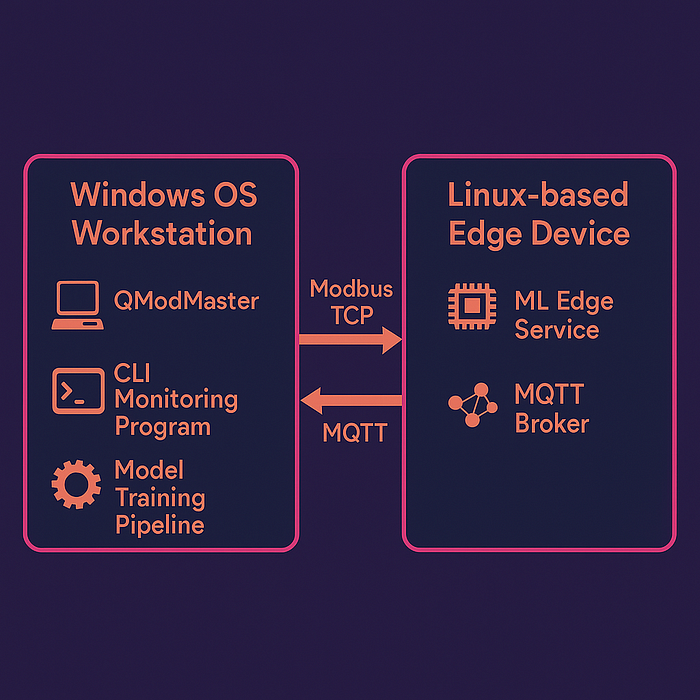
圖表
我們已經有了硬件和軟件列表,現在讓我們以視覺化的方式呈現,以便于后續跟進。
此圖表以更有趣、清晰和高效的方式包含了我們剛才指定的所有內容。
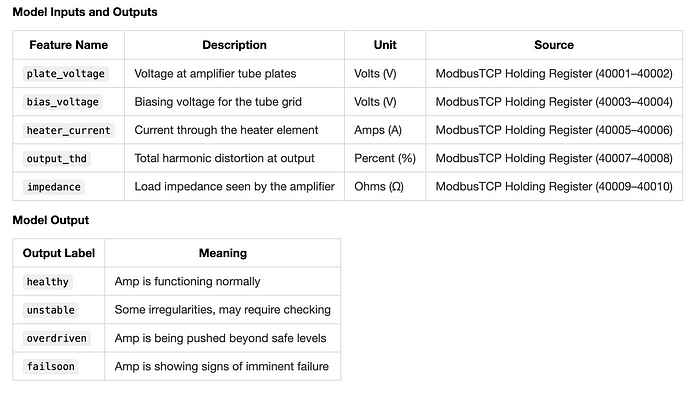
數據映射
任何項目都需要一個數據映射。它可以簡單到一張標注了“輸入和輸出”的餐巾紙,也可以是一張更專業、更美觀的表格/文檔,包含各種列,如名稱、標簽、數據類型、協議、寄存器、源、目標、描述等。
讓我們使用這個用于我們的實踐:
Modbus TCP
我們知道推理服務的輸入數據將來自一個 ModbusTCP 主站(由 QModMaster 模擬),該主站將寫入我們虛擬 ModbusTCP 從站設備的寄存器。然后,我們將循環讀取這些寄存器中的數據,將其從兩個獨立的 16 位寄存器轉換為一個單一的 32 位浮點值,以便我們的模型更容易處理。
在先決條件步驟中,我們已經準備好了環境,現在開始工作。
在工作目錄中,創建一個名為 ml_edge_service.py 的文件,并使用你喜歡的編碼 IDE 或文本編輯器插入以下代碼:
frompyModbusTCP.clientimportModbusClientimportstructimporttime
# Modbus Clientmodbus_client = ModbusClient(host="192.168.1.75", port=502, auto_open=True)# Function to read 32-bit float from 2 Modbus registersdefread_float(start_address): regs = modbus_client.read_holding_registers(start_address,2) ifregs: returnstruct.unpack('>f', struct.pack('>HH', regs[0], regs[1]))[0] returnNone
MQTT
為了使我們的模型推理結果可用,我們可以將它們發布到我們想要的任何 MQTT 主題(只要遵循主題命名和語法規則),但首先我們需要讓 Mosquitto MQTT 代理運行起來。
為此,我們現在修改 ml_edge_service.py,添加 MQTT 發布函數,使其看起來像這樣:
importpaho.mqtt.clientasmqtt
# MQTT Clientmqtt_client= mqtt.Client()mqtt_client.connect("localhost",1883,60)
我們的 ml_edge_service.py 文件已經部分準備好了,它還需要核心部分,即推理模型。我們先保存腳本,然后繼續處理它。
數據
首先,我們獲取實踐項目的數據 data.csv,并將其放在與 ml_edge_service.py 腳本相同的目錄中。此數據已經過清理,但要知道在實際問題中,數據工程過程確實是問題的一部分。數據幾乎從來不會從源頭直接變得干凈。
下載復古放大器健康數據集 >>> [此處]
https://drive.google.com/drive/folders/1wO_uaqUrUKWfm77W35Jeu5Qe64ujZRlE?usp=sharing
對于建模階段,我們將使用 data.csv 文件。
讓我們在工作目錄中創建一個名為 model.py 的新腳本,并開始編寫第一行代碼。添加以下內容:
importpandasaspdimportnumpyasnpfromsklearn.model_selectionimporttrain_test_splitfromsklearn.preprocessingimportLabelEncoder,StandardScalerimportjoblib
# Load and encode datasetdf= pd.read_csv("data.csv")le = LabelEncoder()df['status_encoded'] = le.fit_transform(df['status'])# Features and labelsX = df.drop(['status','status_encoded'], axis=1).valuesy =df['status_encoded'].values# Normalizescaler = StandardScaler()X_scaled = scaler.fit_transform(X)joblib.dump(scaler,"scaler.save")# SplitX_train, X_temp, y_train, y_temp = train_test_split(X_scaled, y, test_size=0.3, random_state=42)X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
構建
現在,是時候定義我們模型的結構了。由于在這個實踐項目中我們處理的是非線性關系和數值輸入,我們將使用一個簡單的神經網絡(順序密集層)。這些網絡通常足以接收連續的傳感器輸入并輸出離散狀態,同時保持復雜性較低。
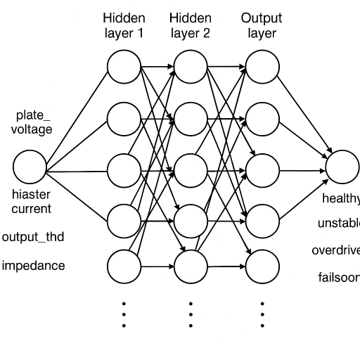
將以下代碼塊插入到 model.py 腳本中:
# MODEL BUILDING STAGE# ---------------------importtensorflowastf
model= tf.keras.Sequential([ tf.keras.layers.Dense(64, activation='relu', input_shape=(5,)), tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(16, activation='relu'), tf.keras.layers.Dense(4, activation='softmax')])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
這個模型架構對于測試目的來說應該足夠了。讓我們繼續添加訓練邏輯。
訓練
為了訓練我們的模型,讓我們添加以下代碼塊:
# TRAINING STAGE# --------------history= model.fit(X_train, y_train, epochs=50, validation_data=(X_val, y_val))
在這里,我們將訓練模型 50 個 epoch(數據是合成的且規模較小,因此學習速度會很快),并存儲指標歷史記錄,然后繪制/分析它們并評估模型的訓練/驗證性能。
測試
訓練后,我們想在未見過的數據(除了驗證數據之外)上測試我們的模型,因此讓我們添加一些代碼:
# TESTING STAGE# -------------
importmatplotlib.pyplotasplt# Evaluate the model on test dataloss, acc = model.evaluate(X_test, y_test)print(f"Test Accuracy:{acc:.2f}")# Plot training historyplt.figure(figsize=(12,5))# Accuracy plotplt.subplot(1,2,1)plt.plot(history.history['accuracy'], label='Train Acc')plt.plot(history.history['val_accuracy'], label='Val Acc')plt.title('Model Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.grid(True)# Loss plotplt.subplot(1,2,2)plt.plot(history.history['loss'], label='Train Loss')plt.plot(history.history['val_loss'], label='Val Loss')plt.title('Model Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)# Save and show the plotplt.tight_layout()plt.savefig("training_history.png")plt.show()
導出
現在,讓我們在測試完成后添加幾行代碼來導出我們的模型,以便我們可以在目標設備(ED-IPC/RasPi)上使用它。
# EXPORTATION STAGE# ------------------model.save("amp_model.h5")
完成的 model.py 腳本
importpandasaspdimportnumpyasnpfromsklearn.model_selectionimporttrain_test_splitfromsklearn.preprocessingimportLabelEncoder,StandardScalerimporttensorflowastfimportjoblibimportmatplotlib.pyplotasplt
# Load datadf= pd.read_csv("data.csv")# Encode targetle = LabelEncoder()df['status_encoded'] = le.fit_transform(df['status'])# Features and labelsX = df.drop(['status','status_encoded'], axis=1).valuesy =df['status_encoded'].values# Normalize featuresscaler = StandardScaler()X_scaled = scaler.fit_transform(X)joblib.dump(scaler,"scaler.save")# Split datasetX_train, X_temp, y_train, y_temp = train_test_split(X_scaled, y, test_size=0.3, random_state=42)X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)# Build modelmodel = tf.keras.Sequential([ tf.keras.layers.Dense(64, activation='relu', input_shape=(5,)), tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(16, activation='relu'), tf.keras.layers.Dense(4, activation='softmax')])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# Train modelhistory= model.fit(X_train, y_train, epochs=50, validation_data=(X_val, y_val))# Evaluate modelloss, acc = model.evaluate(X_test, y_test)print(f"Test Accuracy: {acc:.2f}")# Plot training historyplt.figure(figsize=(12, 5))# Accuracy plotplt.subplot(1, 2, 1)plt.plot(history.history['accuracy'], label='Train Acc')plt.plot(history.history['val_accuracy'], label='Val Acc')plt.title('Model Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.grid(True)# Loss plotplt.subplot(1, 2, 2)plt.plot(history.history['loss'], label='Train Loss')plt.plot(history.history['val_loss'], label='Val Loss')plt.title('Model Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)# Save and show the plotplt.tight_layout()plt.savefig("training_history.png")plt.show()# Export modelmodel.save("amp_model.h5")
太好了。我們的代碼已經準備好運行了!完整的流程應該導入并準備我們的數據集,構建模型,訓練它(同時運行驗證),測試它,給我們一些指標,并將模型保存為文件。
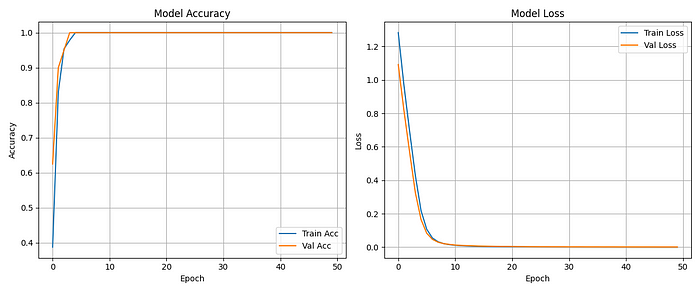
在上面,你可以看到我從這個流程中得到的結果,它足夠好,可以在線測試(將其部署為服務運行),這顯然是因為我們的數據集是合成的。
部署
從 Python 腳本調用導出的模型
好的,讓我們回到 ml_edge_service.py 腳本,并添加幾行缺失的代碼。
這些行將負責加載我們之前導出的模型,并使其隨時可以接收數據并輸出一些推理結果,當然,是作為服務持續運行的。
添加以下內容:
importtensorflowastfimportnumpyasnpimportjoblib
# Load model and scalermodel = tf.keras.models.load_model("amp_model.h5")scaler = joblib.load("scaler.save")labels = ["healthy","unstable","overdriven","failsoon"]while True: plate_voltage = read_float(0) bias_voltage = read_float(2) heater_current = read_float(4) output_thd = read_float(6) impedance = read_float(8) if None not in (plate_voltage, bias_voltage, heater_current, output_thd, impedance): X = np.array([[plate_voltage, bias_voltage, heater_current, output_thd, impedance]]) X_scaled = scaler.transform(X) prediction = model.predict(X_scaled) label = labels[np.argmax(prediction)] mqtt_client.publish("amp/inference", label) time.sleep(1)
完成的 ml_edge_service.py 腳本
這是最終的 ml_edge_service.py 腳本的樣子:
frompyModbusTCP.clientimportModbusClientimporttimeimportstructimporttensorflowastfimportnumpyasnpimportjoblibimportpaho.mqtt.clientasmqtt
# Modbus Clientmodbus_client = ModbusClient(host="192.168.1.75", port=502, auto_open=True)# MQTT Clientmqtt_client = mqtt.Client()mqtt_client.connect("localhost",1883,60)# Load model and scalermodel = tf.keras.models.load_model("amp_model.h5")scaler = joblib.load("scaler.save")# Function to read 32-bit float from 2 Modbus registersdefread_float(start_address): regs = modbus_client.read_holding_registers(start_address,2) ifregs: returnstruct.unpack('>f', struct.pack('>HH', regs[0], regs[1]))[0] returnNonelabels = ["healthy","unstable","overdriven","failsoon"]whileTrue: plate_voltage = read_float(0) bias_voltage = read_float(2) heater_current = read_float(4) output_thd = read_float(6) impedance = read_float(8) ifNonenotin(plate_voltage, bias_voltage, heater_current, output_thd, impedance): X = np.array([[plate_voltage, bias_voltage, heater_current, output_thd, impedance]]) X_scaled = scaler.transform(X) prediction = model.predict(X_scaled) label = labels[np.argmax(prediction)] mqtt_client.publish("amp/inference", label) time.sleep(1)
將 Python 腳本執行設置為系統服務
我們的 ml_edge_service.py 腳本現在已經完成了,不可避免地,現在讓我們將其配置為作為系統服務運行。
為了實現這一點,讓我們在 systemd 目錄中直接創建一個名為 ml_edge_service.service 的服務文件(你可能需要 sudo 權限來執行此操作):
sudo nano/etc/systemd/system/ml_edge_service.service
將以下代碼粘貼到其中:
[Unit]Description= ML Amplifier Health Inference Model ServiceAfter=network.target
[Service]ExecStart=/usr/bin/python3 /home/pi/Documents/ml_edge_project/ml_edge_service.pyWorkingDirectory=/home/pi/Documents/ml_edge_project/Restart=alwaysUser=pi[Install]WantedBy=multi-user.target
保存并退出,現在它位于其他服務所在的位置。你現在可以在打開的系統 shell 中使用以下命令來啟動它:
sudo systemctl daemon-reexecsudo systemctl daemon-reloadsudo systemctlenableml_edge_servicesudo systemctl start ml_edge_service
你可以使用以下命令來監控服務:
sudosystemctl status ml_edge_service
還可以使用以下命令來停止和重啟服務:
sudosystemctl stop ml_edge_servicesudo systemctl restart ml_edge_service
使用 QModMaster 喂養和測試推理模型服務
現在,我們已經在邊緣設備(ED-IPC/RasPi)上啟動并運行了服務,等待一些數據來輸入,讓我們啟動一個 QModMaster 實例,并將其設置為向我們的 ModbusTCP 從站(在邊緣設備上)寫入值。
首先,配置目標從站 IP,并確保設置正確,如下所示。
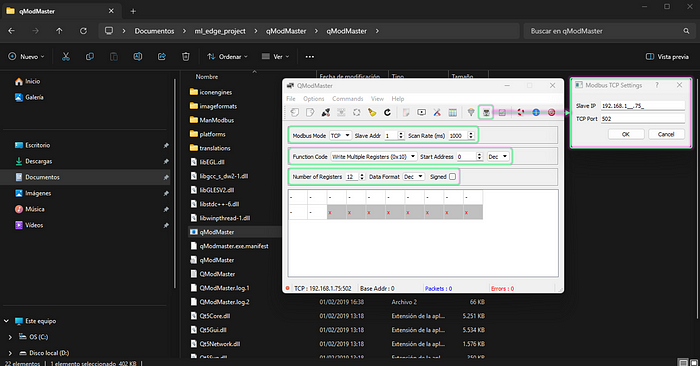
然后繼續連接,并啟用循環更新。之后開始寫入值,使用圖像中的示例作為第一個示例,或使用之前與 data.csv 文件一起提供的 test_samples.csv 文件中的任何示例。
我正在使用下面顯示的示例行。我們預計會收到模型對該輸入數據的推理結果為“healthy”。

服務應該自動讀取并處理 ModbusTCP 從站寄存器中的數據,將其輸入到模型中,并輸出一些結果供我們查看。讓我們找出如何查看它們。
監控
CLI 應用讀取并打印結果
我們知道,現在我們的模型結果正在發布到 amp/inference 主題,并且可以在運行在邊緣設備(ED-IPC/RasPi)上的 Mosquitto MQTT 代理的地址上獲取。因此,讓我們從筆記本電腦/工作站上讀取它們,就像我們是一個試圖獲取并利用這些結果的客戶端一樣。
在你的筆記本電腦/工作站工作目錄中創建一個名為 ml_edge_monitoring.py 的腳本,并插入以下代碼:
importpaho.mqtt.clientasmqtt
def on_message(client, userdata, msg): print(f"[INFERENCE] {msg.payload.decode()}")mqtt_client = mqtt.Client()mqtt_client.connect("192.168.1.75",1883,60)mqtt_client.subscribe("amp/inference")mqtt_client.on_message = on_messagemqtt_client.loop_forever()
現在運行腳本,你應該會看到模型結果定期輸出,實際上幾乎是實時的(不要太認真對待實時部分)。
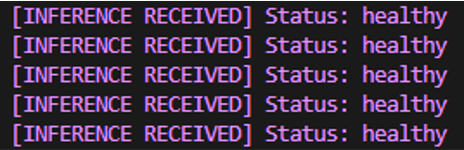
……就這樣,一個完全功能的機器學習推理模型作為服務運行在基于 Linux 的邊緣設備上,供你使用!不過,先別急著賣掉它。還有很多事情要做……
不管如何,恭喜你!我為你達到這一點感到驕傲,冠軍。
機會領域
還有許多其他事情我希望我能在本文中包含。這些可能是未來的主題,但這里有一些,你可以自己探索并打造一個殺手級的機器學習邊緣服務。
OPC UA
集成 OPC UA 客戶端功能,以實現更多工業通信協議兼容性。這是一個非常流行且廣泛用于全球大型企業 OT 網絡的行業標準協議。
使用 Python 的 opcua 庫來利用這一點。
Docker

在不同設備或系統上運行遇到困難?不用擔心,Docker 容器可以幫助你!
它們還可以為更高效的 CI/CD 管道提供方法,這將有利于你的模型部署。
甚至可以使用 Kubernetes 來編排這些容器,使一切穩定且可擴展。
FastAPI

一個聰明的方法是將數據提供給許多不同的應用程序,那就是提供一個 HTTP 服務器,該服務器響應你模型結果或指標的請求。非常適合監控和結果可視化(儀表板?)。
Dashboard

使用 Plotly 或 Grafana 等工具制作一些儀表板,有很多工具可供選擇。每個人都喜歡一個外觀美觀、信息量和細節恰到好處的 UI。
Database

也許可以添加一個地方來存儲你的模型結果和性能指標?數據庫將是一個理想的選擇!
SQLite 適合小型部署,或者你可以使用 PostgreSQL 來構建一個更大、更健壯的平臺。
日志記錄
厭倦了需要關注 CLI 結果和指標流,那就記錄它們,以后再查看!或者甚至捕獲運行時錯誤以供未來調試。
基本的日志文件變得太大,或飽和得太快?使用旋轉日志文件!這些日志文件允許你擁有可覆蓋的日志文件(甚至在達到大小限制時生成自定義數量的備份),它們會自我循環,不會隨著時間的推移占用更多空間,而且永遠不會停止。
在某些情況下,非常適合設置后忘記。
推薦
從一開始就了解你的數據的性質、屬性和質量
本項目只是一個快速而有趣的提案,用于測試在工業環境中如果以適當和健壯的方式實現,可能會使用的各種技術。然而,要實現這種健壯性,最重要的步驟之一是確保你了解你的數據。花一些時間探索它,查看歷史記錄,了解其細微差別。
例如:
為什么我的數據中存在間隙?
為什么每隔一段時間就會出現如此怪異的峰值?
為什么在應該是數值輸入的地方收到了字符串?
還有很多類似(或更糟(或更有趣))的例子
聽起來很可笑,但這種情況比你想象的更常見。即使在專業環境中也是如此。
進行測試并構建健壯的管道(在數據到達你的模型之前)
考慮到最后一個建議,將幫助你意識到項目特定的問題,并因此促使你嘗試(并成功,耶!)從一開始就開發出防錯的管道,因為記住,即使模型正在運行并輸出一些東西,也不意味著它是正確的。
原文地址:
https://medium.com/mcd-unison/machine-learning-on-the-edge-real-time-inference-model-deployment-and-industrial-integration-with-af7f2e5244dehttps://www.makeuseof.com/raspberry-pi-5-overclocking-guide/
-
Linux系統
+關注
關注
4文章
604瀏覽量
28356 -
機器學習
+關注
關注
66文章
8493瀏覽量
134170 -
邊緣計算
+關注
關注
22文章
3291瀏覽量
50616
發布評論請先 登錄
邊緣側部署大模型優勢多!模型量化解決邊緣設備資源限制問題
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
超低功耗FPGA解決方案助力機器學習
好奇~!谷歌的 Edge TPU 專用 ASIC 旨在將機器學習推理能力引入邊緣設備
高性能的機器學習讓邊緣計算更給力-iMX8M Plus為邊緣計算賦能
高性能的機器學習讓邊緣計算更給力-iMX8M Plus為邊緣計算賦能
高性能的機器學習讓邊緣計算更給力-iMX8M Plus為邊緣計算賦能
高性能的機器學習讓邊緣計算更給力
如何用Arm虛擬硬件在Arm Cortex-M上部署PaddlePaddle
一種基于機器學習的流簇大小推理模型

英飛凌攜手SensiML為智能家居、健身和工業應用提供傳感器數據并訓練機器學習模型
智譜GLM-Zero深度推理模型預覽版正式上線
詳解 LLM 推理模型的現狀






 工商網監
工商網監
評論