 從Shader編成入手了解GPU應用方案
從Shader編成入手了解GPU應用方案
Graphics Processing Unit(GPU),即可編程圖形處理單元, 通常也稱之為可編程圖形硬件。
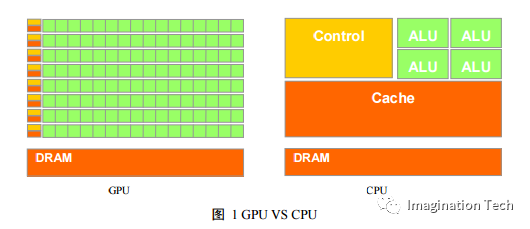
由于GPU有高并行結構(highly parallel structure),所以GPU在處理圖形數據和復雜算法方面擁有比CPU更高的效率。圖 1 GPU VS CPU 展示了 GPU 和 CPU 在結構上的差異,CPU 大部分面積為控制器和寄存器,與之相比,GPU擁有更多的 ALU(Arithmetic Logic Unit,邏輯運算單元)用于數據處理,而非數據高速緩存和流控制,這樣的結構適合對密集型數據進行并行處理。CPU 執行計算任務時,一個時刻只處理一個數據,不存在真正意義上的并行,而 GPU 具有多個處理器核,在一個時刻可以并行處理多個數據。
GPU 采用流式并行計算模式,可對每個數據進行獨立的并行計算,所謂“對 數據進行獨立計算”,即,流內任意元素的計算不依賴于其它同類型數據,例如,計算一個頂點的世界位置坐標,不依賴于其他頂點的位置。而所謂“并行計算” 是指“多個數據可以同時被使用,多個數據并行運算的時間和 1 個數據單獨執行的時間是一樣的”。圖 2 中代碼目的是提取 2D 圖像上每個像素點的顏色值,在 CPU 上運算的 C++代碼通過循環語句依次遍歷像素;而在 GPU 上,則只需要一條語句就足夠。

其一,object space coordinate 就是模型文件中的頂點值,這些值是在模型建模時得到的,例如,用 3DMAX 建 立一個球體模型并導出為.max 文件,這個文件中包含的數據就是 object space coordinate;其二,object space coordinate 與其他物體沒有任何參照關系,注意,這個概念非常重要,它是將 object space coordinate 和 world space coordinate 區分 開來的關鍵。無論在現實世界,還是在計算機的虛擬空間中,物體都必須和一個固定的坐標原點進行參照才能確定自己所在的位置,這是 world space coordinate 的實際意義所在。
從 object space coordinate 到 world space coordinate 的變換過程由一個四階矩陣控制,通常稱之為 world matrix。需要高度注意的是:頂點法向量在模型文件中屬于 object space,在 GPU 的 頂點程序中必須將法向量轉換到 world space 中才能使用,如同必須將頂點坐標從 object space 轉換到 world space 中一樣,但兩者的轉換矩陣是不同的,準確的說,法向量從 object space 到 world space 的轉換矩陣是 world matrix 的轉置矩陣的逆矩陣。
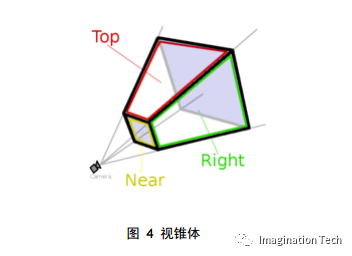
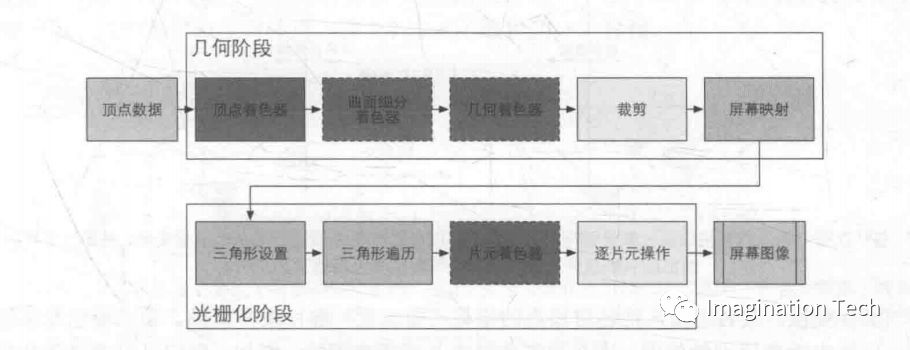
每個人都是從各自的視點出發觀察這個世界,無論是主觀世界還是客觀世界。同樣,在計算機中每次只能從唯一的視角出發渲染物體。在游戲中,都會提供視點漫游的功能,屏幕顯示的內容隨著視點的變化而變化。這是因為 GPU 將 物體頂點坐標從 world space 轉換到了 eye space。 所謂 eye space,即以 camera(視點或相機)為原點,由視線方向、視角和遠近平面,共同組成一個梯形體的三維空間,稱之為 viewing frustum(視錐), 如圖 4 所示。近平面,是梯形體較小的矩形面,作為投影平面,遠平面是梯形體 較大的矩形,在這個梯形體中的所有頂點數據是可見的,而超出這個梯形體之外的場景數據,會被視點去除(Frustum Culling,也稱之為視錐裁剪)。
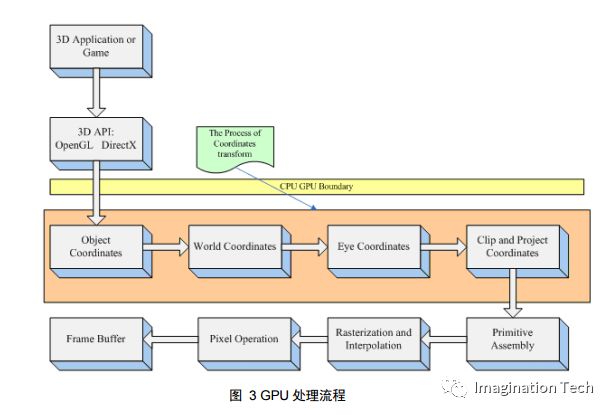
從視點坐標空間到屏幕坐標空間 (screen coordinate space)事實上是由三步組成:
1. 用透視變換矩陣把頂點從視錐體中變換到裁剪空間的 CVV 中;2. 在 CVV 進行圖元裁剪;3. 屏幕映射:將經過前述過程得到的坐標映射到屏幕坐標系上。
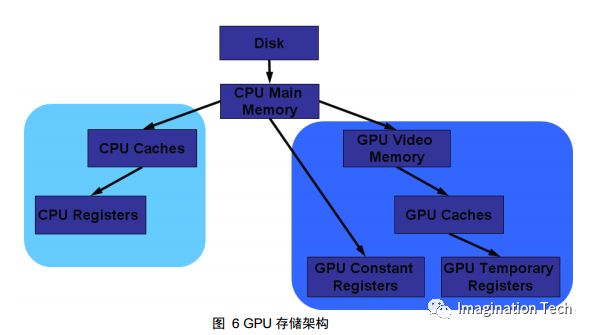
從物理結構而言,寄存器是 cpu 或 gpu 內部的存儲單元,即寄存器是嵌入在 cpu 或者 gpu 中的,而內存則可以獨立存在;
從功能上而言,寄存器是有限存儲 容量的高速存儲部件,用來暫存指令、數據和位址。
Shader 編成是基于計算機圖形硬件的,這其中就包括 GPU 上的寄存器類型,glsl 和 hlsl 的著色虛擬機版本就是基于 GPU 的寄存器和指令集而區分的。
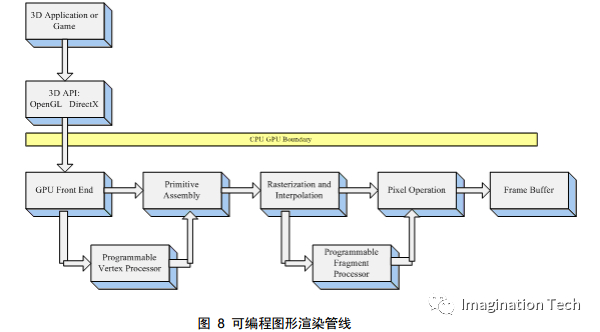
頂點著色器控制頂點坐標 轉換過程;片段著色器控制像素顏色計算過程。這樣就區分出頂點著色程序和片 段著色程序的各自分工:Vertex program 負責頂點坐標變換;Fragment program 負責像素顏色計算;前者的輸出是后者的輸入。
-
寄存器
+關注
關注
31文章
5427瀏覽量
123742 -
gpu
+關注
關注
28文章
4923瀏覽量
130830
原文標題:GPU學習筆記
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
GPU架構深度解析

搭建算力中心,從了解的GPU 特性開始

可以手動構建imx-gpu-viv嗎?
OpenVINO?檢測到GPU,但網絡無法加載到GPU插件,為什么?
從CPU到GPU:渲染技術的演進和趨勢
GPU是如何訓練AI大模型的
PyTorch GPU 加速訓練模型方法
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
【一文看懂】大白話解釋“GPU與GPU算力”
GPU超頻設置技巧
如何選擇適合的GPU
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
GPU云服務器架構解析及應用優勢






 工商網監
工商網監
評論