 如何利用深度學習修復醫療影像數據集
如何利用深度學習修復醫療影像數據集
醫學圖像數據很難處理,經常包含旋轉倒置的圖像。這篇文章介紹如何利用深度學習以最小的工作量來修復醫療影像數據集,緩解目前構建醫療 AI 系統中收集和清洗數據成本大的問題。
在醫學成像中,數據存儲檔案是基于臨床假設的。不幸的是,這意味著當你想要提取一個圖像時,比如一個正面的胸部x光片,你通常會獲得一個存儲了許多其他圖像的文件夾,并且沒有簡單的方法來對它們加以區分。
圖1:這些圖片來自于相同的文件夾是有道理的,因為在放射學中我們記錄的是病例而非圖像。這是病人受傷后,同時掃描的所有身體部位。
根據機構的不同,你可能會得到水平或垂直翻轉的圖像。它們可能包含反向像素值。他們可能會旋轉。問題是,當處理一個巨大的數據集,比如5萬到十萬個圖像時,你怎么能在沒有醫生指導的情況下發現這些畸變呢?
您可以嘗試編寫一些優雅的解決方案,比如:因為大多數胸部X光高度都比寬度高,因此在X光的兩側有黑色的邊界,所以如果底部有超過50個黑色的像素行,那么它可能旋轉了90度。
但和往常一樣,我們的經驗失敗了。
圖2:這里只有中間的圖像有經典的“黑色邊框”
這些脆弱的規則不能解決上述問題。
進入software 2.0,我們使用機器學習來構建我們無法自行編碼的解決方案。像旋轉的圖像這樣的問題是embarrassingly learnable。這意味著機器可以像人類一樣完美地實現這些任務。
因此,顯而易見的解決辦法是使用深度學習來為我們修復數據集。在這篇文章中,我將向您展示這些技術的可應用領域,如何用最少的努力做到這一點,并展示一些使用方法的示例。舉個例子,我將使用Wang等人開發的CXR14數據集,它看起來是經過精心策劃的,但有時仍然包含一些糟糕的圖片。如果你使用CXR14數據集,我們甚至可以給你包含430個新標簽的數據集,這樣你就不用擔心那些糟糕的圖片了!
如此尷尬的問題
我們真正需要問的第一個問題是現在的問題是embarrassingly learnable么?
考慮到大多數的研究都是正常的,你需要一個非常高的精確度來防止排除那些“好“的研究。我們應該瞄準99.9%的目標。
很酷的一點是,對于視覺上可以識別的問題,它很簡單,我們也可以很好地解決。一個很好的問題是“你能想象一個單一的視覺規則來解決這個問題嗎?”“ImageNet數據集的主要目的就是區分區分狗和貓,而解決辦法也肯定不是這樣。
有太多的變化,有太多的相似之處。我經常在演講中使用這個例子:我甚至無法想象如何編寫規則來直觀地區分這兩種類型的動物。這并不是令人embarrassingly learnable。
但在醫學數據中,許多問題其實很簡單。因為醫學圖像的變化是很小的。解剖學、角度、光線、距離和背景都很穩定。為了說明這一點,讓我們看一個來自CXR14的簡單示例。在數據集中的普通胸部x光中,有一些是旋轉的(這在標簽中沒有被識別,所以我們不知道是哪一個)。它們可以旋轉90度左右,或180度的上下顛倒。
這是embarrassingly learnable么?
圖3:旋轉和垂直的胸部x光的區別真的非常簡單
答案是肯定的。從視覺上看,異常的研究與正常的研究完全不同。你可以使用一個簡單的視覺規則,比如“肩膀應該高于心臟”,你會在所有的樣例上得到驗證。鑒于解剖學是非常穩定的,而且所有人都有肩膀和心臟,這應該是一個可學習的卷積神經網絡規則。
“嗷嗷待哺”的數據
我們要問的第二個問題是:我們有足夠的訓練數據嗎?
在旋轉圖像的情況下,我們當然有足夠的數據,我們可以進行數據生成。我們所需要的只是幾千個普通的胸部x光片,然后隨機旋轉。例如,如果你使用的是numpy數組,你可能會使用這樣的函數:
def rotate(image):
rotated_image = np.rot90(image, k = np.random.choice(range(1,4)), axes = (1,2))
return rotated_image
這只是在順時針方向旋轉90 ,180度或270度。在這種情況下通常繞著第二和第三個軸旋轉,因為第一個軸是通道的數量(根據theano矩陣維度的約定)。
注意:在這種情況下,CXR14數據集中幾乎沒有旋轉的圖像,所以不小心地“糾正”了已經旋轉的圖像的幾率非常小。我們可以假設數據中沒有旋轉圖像,這樣有利于模型的學習。如果大量的不正常圖像,那么你最好同時選擇正常和不正常的圖像。因為像旋轉這樣的問題很容易被識別的,我發現我可以在一個小時內給出幾千個標簽,所以這并不需要花費太多的精力。由于這些問題很簡單,我經常發現我只需要幾百個例子來“解決”這個挑戰。
所以我們建立了一個正常圖像的數據集,旋轉其中的一半,并相應地標記它們。在我的例子中,我選擇了4000個訓練用例,其中2000個是旋轉的,2000個驗證集案例中有1000個是經過旋轉處理的。這似乎是一個相當數量的數據(記住,根據經驗法則,在將誤差考慮在范圍之內,1000個例子可能是好的,而且它適合于RAM,所以很容易在我的家用電腦上進行訓練。
為了在機器學習中有一個有趣的變化,我不需要一個單獨的測試集。證明在Pudding中可見:我將在整個數據集上運行這個模型,并通過對數據進行檢查來獲得測試結果。
總的來說,進行這類工作可以使我們的生活變得輕松。我縮小圖像到256 x 256像素,因為旋轉檢測看起來不需要高分辨率,我使用一個經過預先訓練的resnet50,它以keras作為基礎網絡。對于使用預先訓練的網絡,并沒有一個明確的理由,因為幾乎所有你使用的網絡都會在一個簡單的解決方案上得到收斂,但是它很簡單,并且不會導致任何速度的減慢,因為無論如何訓練時間都是快的。我使用了一組默認的參數,因為我不為這個簡單的任務需要做任何調優。
您可以使用手邊的任何網絡和編碼。一個VGG-net就行。一個densenet也可以。實際上,任何網絡都是可以實現這個任務的。
在幾十輪的迭代后,我在驗證集上得到了我期待的結果:
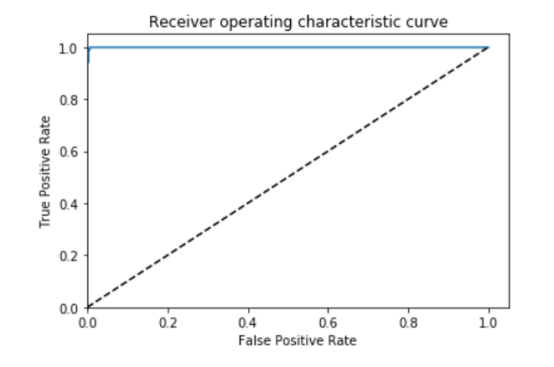
圖4:AUC = 0.999, ACC = 0.996, PREC = 0.998, REC = 0.994 ?
很好,如果這是一項embarrassingly learnable任務,我發現的正是我所期待的。
結果檢驗
就像我之前說過的,在醫學圖像分析中,我們總是需要檢查我們的結果。通過對照圖片,確保模型或過程實現了你的目標。
因此,最后一步是在整個數據集上運行模型,進行預測,然后排除旋轉的研究。因為在數據中幾乎沒有旋轉的研究,盡管我知道這樣做以后,召回率會非常高,我可以簡單地看一下所有被預測旋轉的圖像。
如果這是一個有大量異常圖像的問題,比方說包括了超過5%的異常數據,那么收集幾百個隨機的案例并手工標記一個測試集就會更有效率,然后你就可以跟蹤你的模型在適當的指標上的精確度。
我特別關心的是任何被認為是旋轉過的正常研究(假陽性),因為我不想失去有價值的訓練案例。這實際上一個超出你想象的擔憂,因為這個模型很可能會過度調用特定類型的病例(可能是那些病人懶散和傾斜時記錄的病例),如果我們排除這些規則,我們將引入偏差數據,不再有“真實世界”的代表數據集。這顯然對醫療數據很重要,因為我們的目標是構建能夠在真正的診所工作的系統。
該模型總共將171個案例識別為“旋轉”的圖像。有趣的是,它實際上是一個“異常”探測器,識別出許多實際上并沒有旋轉的異常情況。這是有道理的,因為它可能是在學習解剖學上的里程碑。任何不正常的東西,比如旋轉的電影或其他身體部位的x光,相比較于這場模型都被標記了不同的標簽。所以我們得到的結果比找到不正常旋轉的圖像要多得多。
在171個被選中的預測中,51個是被旋轉過的前胸x光片。鑒于患病率低得離譜(120,000個中有51個),這已經是一個非常低的假正率了。
圖5:旋轉胸片的例子
在剩下的120個病例中,56個不是正面的胸片。主要是側面照和腹部x光片。不管怎樣,我還是想把這些都去掉。
其余的呢?有一種混合的研究,就是圖像包含大量黑色或白色的邊界,淘汰性研究,也就是說整個圖像都是灰色的,反向像素水平的研究,等等。
總的來說,有大約10個研究,我稱之為“假陽性”(意思是挑出的圖像是我可能想要保存的正面x射線)。值得慶幸的是,即使你想把它們重新加起來,只有171個預測,因此容易進行人工管理。
所以旋轉檢測器看起來像是部分地解決了一些其他的問題(比如像素值的反轉)。要知道它有多好,我們需要檢查它是否漏掉了其他壞的情況。我們可以測試這個,因為像素值的反轉很容易生成數據(對于圖像中的x,x=max-x)。
此處需要再一次提及embarrassingly learnable問題。在這種情況下,在沒有機器學習的情況下,可能有一些方法可以做到這一點(柱狀圖應該看起來很不一樣),但這也很簡單。
那么,這個特定的探測器是否發現了比旋轉探測器更多的逆序呢?是的。旋轉探測器在整個數據集中發現了4個,而反演探測器發現了38個反向研究。所以旋轉探測器只發現了部分差的研究。
書歸正傳:訓練單個模型來解決每個問題是正確的方法。
所以,我們需要特定的模型來完成額外的數據清洗任務。
滴水穿石
為了證明少量的標簽數據是有用的,我使用旋轉檢測器(n=56)拍攝了橫向和不良區域的影片,并在它們上面訓練了一個新模型。由于我沒有很多數據,我決定用HOGwild,并且不使用驗證集。由于這些任務是embarrassingly learnable,一旦它接近100%,它的泛化能力會有很好的表現。顯然這里有過度訓練的風險,但我仍然選擇冒險。
實驗證明結果非常好!我還發現了另外幾百個側面圖像,腹部圖像和一些骨盆的圖像。
顯然,如果我從頭開始構建這個數據集,它解決這個問題會更容易,因為我可以獲得很多相關的非正面胸部圖像。對我來說,要比現在做得更好,我需要從我當地的醫院檔案中提取出一系列的圖像,這超出了這篇文章的論述范圍。所以我不能確定我取得了大部分的成就,但是從這樣一個小的數據集里,這是一個相當不錯的努力。
除了關于CXR14的數據外,我注意到的一件事是,我的模型在兒童的圖像上的表現很差。這些兒科圖像在外觀上與成人圖像是不同的,它們被旋轉探測器、倒置探測器和bad-部分探測器識別為“異常”。我建議他們應該被忽略,但是隨著病人年齡被包含在標簽中,這樣就可以在沒有深入學習的情況下完成。考慮到在5歲以下的數據集中,只有286個病人,我個人會把所有的病人排除在外,除非我特別想要研究那個年齡段的病人并且真正知道我在做什么,從醫學成像的角度來看。實際上,我可能會把所有10歲以下的人排除在外,因為這是一個合理的年齡,可以考慮到體型和病理特征更“成熟”。在10歲以下的人群中,約有1400例,約占1%。
書歸正傳:
小兒胸部X光與成人非常不同。考慮到低于10歲的數據只占大約1%的數據,除非有很好的理由,否則應該排除它們。
糟糕的定位和放大的圖像可能會成為一個問題,但這是取決任務的,武斷地定義一個“壞圖像”對于所有任務來說都是不可能的,這不是我想做的。還有一件事是特定于任務的。
總的來說,使用深度學習來解決簡單的數據清理問題效果很好。 經過大約一個小時的時間,我已經清理了數據集中大部分旋轉和倒置的圖像。我可能已經確定了很大一部分的橫向圖像和其他身體部位的圖像,雖然我確信我需要為他們建立特定的探測器。如果沒有原始數據,這對于這篇簡單博客來說太長了。
從更廣泛的角度來看CXR14數據,它沒有太多的圖像錯誤。美國國家衛生研究院的團隊很好地整理了他們的數據。然而在醫療數據集里,情況并非總是如此,如果你想要建立高性能的醫療人工智能系統,就一定需要利用臨床基礎設施來處理研究任務的噪音。
進一步考慮
到目前為止,我們已經解決了一些非常簡單的挑戰,但并不是我們在醫學成像中遇到的所有問題都這么簡單。
我們的團隊在構建大型髖部骨折數據集時應用了這些技術。我們排除了來自其他身體區域的圖像,我們排除了植入金屬的病例,如髖關節置換,我們還放大了臀部區域,刪除了與我們的問題無關的圖像區域,如髖部骨折不發生在臀部的情況。
我們是通過一個自動文本挖掘過程來實現金屬排除的問題的,這些假肢幾乎總是在出現的同時被發現,所以我發現了與植入物有關的關鍵字。這些標簽是在10分鐘左右被創建的。
在身體部分的錯誤檢測和錯誤的邊界框預測的情況下,我們沒有辦法自動生成標簽。所以直接進行手工處理。即使是像邊界框預測這樣復雜的東西(這確實是一個解剖學上的里程碑式的鑒定任務),我們只需要大約750個案例,每個數據集只花了一個小時左右的時間。
在這種情況下,我們使用人工標記的測試集來對結果進行量化。從我們的一篇論文中:
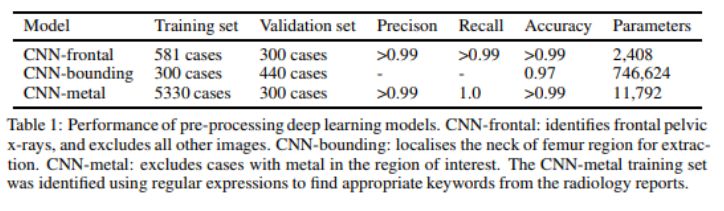
考慮到對骨折問題的標記需要幾個月的時間,花費額外的一個或兩個小時來獲得一個干凈的數據集是一個很小的代價。而且該系統現在可以接受任何臨床圖像,并且通過利用我們的知識可以自動排除無關或低質量的圖像。這正是一個醫學人工智能系統如何在現實應用的案例,除非你想雇一個人來為你處理模型所分析的所有圖像。
總結
我們都認為深度神經網絡和人類解決視覺問題一樣好,只要有足夠的數據。然而,“足夠的數據”在很大程度上取決于任務的難度。
對于醫學圖像分析問題的一個分支,它是我們在構建醫學數據集時經常需要解決的問題,任務非常簡單,這使得問題很容易用少量的數據來解決。通常,模型只需要不到一個小時的時間來識別圖像,而醫生卻需要花費幾個小時的時間來對每個數據集進行人工處理。
作為該方法的證明并用于感謝閱讀我博客的讀者,我已經提供了一組約430張不良圖像的標簽,以排除CXR14數據集,并建議排除約1400名10歲以下兒童,除非你真的知道你為什么要保留這些數據。這不會改變任何論文的結果,但這些數據集的圖像清晰度越高越好。
我在這里所展示的結論沒有任何技術上的創新,這就是為什么我不寫一篇相關的正式論文的原因。但對于我們這些正在構建新數據集的人,特別是那些沒有深度學習經驗的醫生,我希望這可能會引發一些關于軟件2.0如何能夠以數量級的方式解決您的數據問題的想法,因為它比手動方法更省力。目前構建令人驚嘆的醫療AI系統的主要障礙是收集和清理數據的巨大成本,在這種情況下,深度神經網絡確實沒太大的用處。
我在Windows文件資源管理器中檢查了我所有的圖像!
我在這個博客文章的結尾附加了我的地址,我在我的空間中進行旋轉探測器的預測。
我只是將我想要看到的案例轉移到一個新文件夾,然后打開文件夾(使用“超大圖標”的視圖模式)。這種尺寸的圖像大約是屏幕高度的四分之一,而且在大多數屏幕上都大到可以檢測到旋轉等大的異常。當我用大的異常標記圖像時,我只是按下ctrl鍵點擊文件夾中的所有例子,然后將它們剪切/粘貼到一個新文件夾中。這就是我如何做到每小時1000個數據處理的的秘密。
就像這個系統的janky一樣,它比我從網上的repos或自己編寫的大多數東西都要好得多。
用于移動文件的python代碼非常簡單,但在構建數據時是我最常用的代碼,所以我想我應該包括它:
pos = rotation_labs[rotation_labs[‘Preds’] > 0.5]
在這種情況下,rotationlabs是一個panda的dataframe,它存儲圖像索引/文件名和該案例的模型預測。我把它的子集變成了一個只有正例的dataframe。
for i in pos[‘Index’]:
fname = “F:/cxr8/chest xrays/images/” + i
shutil.copy(fname, “F:/cxr8/data building/rotation/”)
所有這些都是將相關的圖像復制到我所做的一個名為“rotation”的文件夾中。
然后我就可以去那個文件夾看一看。如果我做了一些手工管理,想要把這些圖像重新讀出來,那么它就很簡單了:
new_list = os.listdir(“F:/cxr8/data building/rotation/”)
-
醫療影像
+關注
關注
1文章
92瀏覽量
19449 -
深度學習
+關注
關注
73文章
5547瀏覽量
122313
原文標題:實用:用深度學習方法修復醫學圖像數據集
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺/深度學習領域常用數據集匯總
深度學習中開發集和測試集的定義
如何利用FPGA實現醫療影像設計?
怎么利用FPGA實現醫療影像?
如何開發醫療影像的算法?
醫療影像的算法有哪些?
谷歌FHIR標準協議利用深度學習預測醫療事件發生

基于深度學習的圖像修復模型及實驗對比






 工商網監
工商網監
評論