") 基于FPGA的SSD目標(biāo)檢測算法設(shè)計(jì)
基于FPGA的SSD目標(biāo)檢測算法設(shè)計(jì)

第一部分 設(shè)計(jì)概述 /Design Introduction
1.1設(shè)計(jì)目的與應(yīng)用
隨著人工智能的發(fā)展,神經(jīng)網(wǎng)絡(luò)正被逐步應(yīng)用于智能安防、自動(dòng)駕駛、醫(yī)療等各行各業(yè)。目標(biāo)識(shí)別作為人工智能的一項(xiàng)重要應(yīng)用也擁有著巨大的前景,隨著深度學(xué)習(xí)的普及和框架的成熟,卷積神經(jīng)網(wǎng)絡(luò)模型的識(shí)別精度越來越高。有名的LeNet-5手寫數(shù)字識(shí)別網(wǎng)絡(luò),精度達(dá)到99%,AlexNet模型和VGG-16模型的提出突破了傳統(tǒng)圖像識(shí)別算法,GooLeNet和ResNet推動(dòng)了卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用。
但是神經(jīng)網(wǎng)絡(luò)的發(fā)展也給我們帶來了更多挑戰(zhàn),權(quán)重參數(shù)越來越多,計(jì)算量越來越大導(dǎo)致了復(fù)雜的模型很難移植到移動(dòng)端或嵌入式設(shè)備中,且嵌入式環(huán)境對(duì)功耗、實(shí)時(shí)性、存儲(chǔ)都有著嚴(yán)格的約束。因此如何將卷積神經(jīng)網(wǎng)絡(luò)部署到嵌入式設(shè)備中是一件非常有意義的事情。目前神經(jīng)網(wǎng)絡(luò)在傳統(tǒng)嵌入式設(shè)備上絕大部分是基于ARM平臺(tái),神經(jīng)網(wǎng)絡(luò)在ARM上部署時(shí)存在的巨大問題是算力的不足。GPU主要應(yīng)用于神經(jīng)網(wǎng)絡(luò)訓(xùn)練階段,對(duì)環(huán)境和庫的依賴性較大,國內(nèi)技術(shù)積累較弱,難以實(shí)現(xiàn)技術(shù)自主可控。ASIC 是為特定需求而專門定制優(yōu)化開發(fā)的架構(gòu),靈活性較差,缺乏統(tǒng)一的軟硬件開發(fā)環(huán)境,開發(fā)周期長且造價(jià)極高所以基于FPGA的硬件加速平臺(tái)是時(shí)候發(fā)揮它的優(yōu)勢了,F(xiàn)PGA由于獨(dú)特的架構(gòu)被廣泛的應(yīng)用與實(shí)時(shí)信號(hào)處理、圖像處理領(lǐng)域,其并行性也為卷積神經(jīng)網(wǎng)絡(luò)提供了巨大算力。
傳統(tǒng)的RTL開發(fā)FPGA流程相比緩慢,不如軟件的開發(fā)效率高,所以HLS運(yùn)營而生,使用高層次語言來進(jìn)行轉(zhuǎn)換為底層的硬件代碼,極大的加快開發(fā)進(jìn)程。因此項(xiàng)目選用HLS工具來實(shí)現(xiàn)算法中的加速IP核,將SSD目標(biāo)檢測網(wǎng)絡(luò)移植到FPGA硬件平臺(tái)上, 對(duì)于硬件加速過程中的算法并行性,在本設(shè)計(jì)中主要采用兩個(gè)方式:對(duì)層內(nèi)的運(yùn)算并行化,將多個(gè)通道的數(shù)據(jù)進(jìn)行分塊,每一塊內(nèi)的通道同時(shí)進(jìn)行運(yùn)算,最后將結(jié)果累加在一起。對(duì)于模塊的運(yùn)算采用HLS并行優(yōu)化,對(duì)數(shù)組核循環(huán)添加優(yōu)化指令進(jìn)行優(yōu)化。整個(gè)系統(tǒng)采用PYNQ的軟件框架來實(shí)現(xiàn),為SSD目標(biāo)檢測算法提供了硬件加速方案,充分發(fā)揮了FPGA的并行性。
1.2 SSD目標(biāo)檢測算法原理
SSD,Single Shot Multi Box Detector,于2016年提出,是經(jīng)典的單階段目標(biāo)檢測模型之一。它的精度可以媲美FasterRcnn雙階段目標(biāo)檢測方法,速度卻達(dá)到了59FPS(512x512,TitanV),單階段目標(biāo)檢測方法的目標(biāo)檢測和分類是同時(shí)完成的,其主要思路是利用CNN提取特征后,均勻地在圖片的不同位置進(jìn)行密集抽樣,抽樣時(shí)可以采用不同尺度和長寬比,物體分類與預(yù)測框的回歸同時(shí)進(jìn)行,整個(gè)過程只需要一步,所以其優(yōu)勢是速度快。
SSD采用的主干網(wǎng)絡(luò)是VGG網(wǎng)絡(luò),VGG是由Simonyan 和Zisserman在文獻(xiàn)《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷積神經(jīng)網(wǎng)絡(luò)模型,其名稱來源于作者所在的牛津大學(xué)視覺幾何組(Visual Geometry Group)的縮寫。該模型參加2014年的 ImageNet圖像分類與定位挑戰(zhàn)賽,取得了優(yōu)異成績:在分類任務(wù)上排名第二,在定位任務(wù)上排名第一。
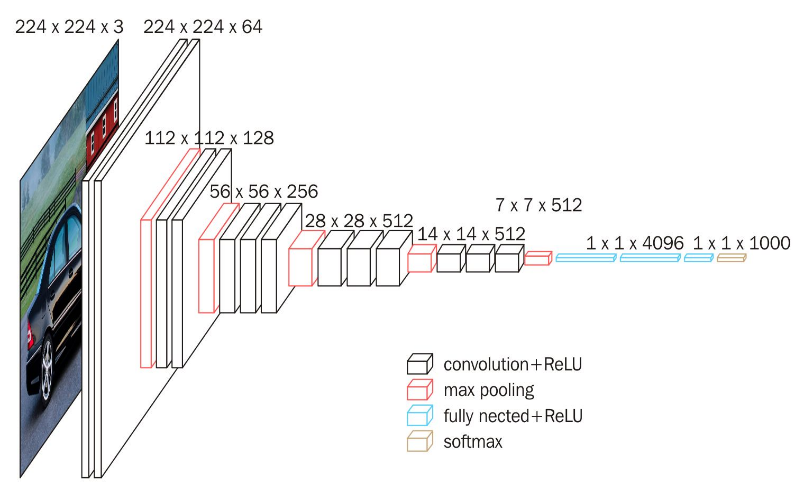
圖1.VGG16網(wǎng)絡(luò)結(jié)構(gòu)
這里的VGG網(wǎng)絡(luò)相比普通的VGG網(wǎng)絡(luò)有一定的修改,主要修改的地方就是:
1、將VGG16的FC6和FC7層轉(zhuǎn)化為卷積層。
2、去掉所有的Dropout層和FC8層;
3、新增了Conv6、Conv7、Conv8、Conv9。
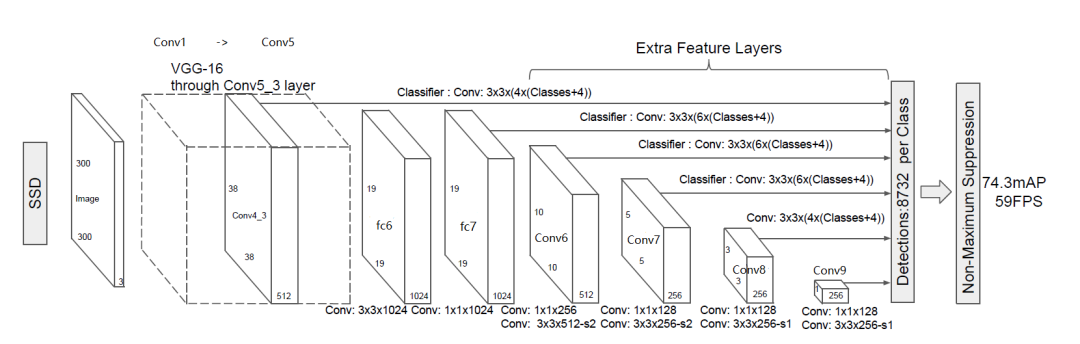
圖2.SSD主干網(wǎng)絡(luò)結(jié)構(gòu)
上圖展示了SSD的主干網(wǎng)絡(luò)結(jié)構(gòu),整個(gè)網(wǎng)絡(luò)為全卷積網(wǎng)絡(luò)結(jié)構(gòu),SSD將VGG16的兩個(gè)全連接層轉(zhuǎn)換成了普通的卷積層,池化層POOL5由原來的stride=2,kernel大小2x2變成stride=1,kernel大小3x3,為了不改變特征圖大小同時(shí)獲得更大的感受野,Conv6改為空洞卷積,diliation=6,輸入的圖片經(jīng)過了改進(jìn)的VGG網(wǎng)絡(luò)(Conv1->fc7)和幾個(gè)另加的卷積層(Conv6->Conv9)進(jìn)行特征提取。
從圖2我們可以看出,SSD將conv4_3、conv7、conv6_2、conv7_2、conv8_2、conv9_2都連接到了最后的檢測分類層做回歸,6個(gè)特征圖分別預(yù)測不同大小和長寬比的邊界框,具體細(xì)節(jié)如圖3。
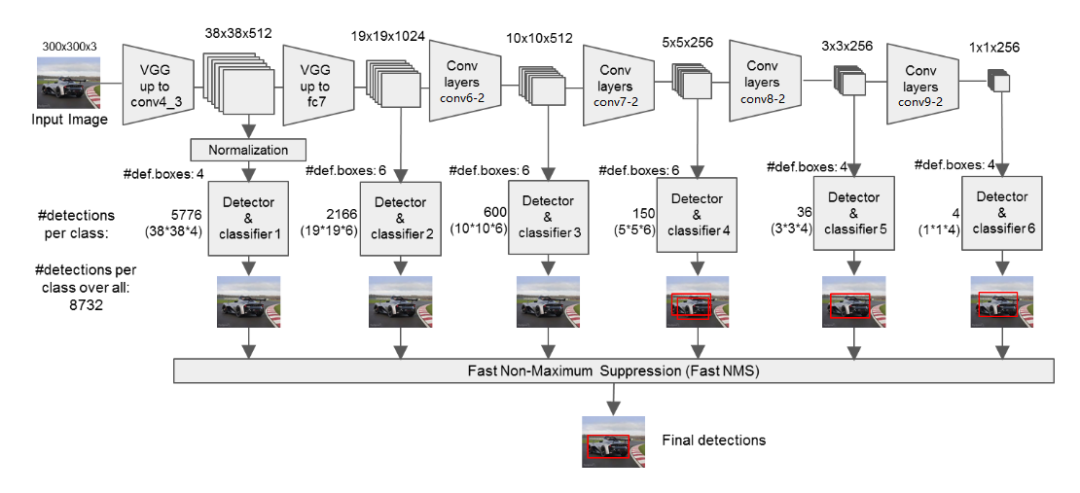
圖3.SSD特征提取網(wǎng)絡(luò)
SSD為每個(gè)檢測層都預(yù)定義了不同大小的先驗(yàn)框(prior boxes),Conv4_3、Conv8_2和Conv9_2分別有4個(gè)先驗(yàn)框,而Conv7、conv7_2和Conv8_2分別有6種先驗(yàn)框,即對(duì)應(yīng)于特征圖上的每個(gè)像素,都會(huì)生成4或6個(gè)prior box.
在淺層的神經(jīng)網(wǎng)絡(luò)里,只能看到圖片的細(xì)節(jié)和紋理信息,就如管中窺豹。隨著網(wǎng)絡(luò)層數(shù)的加深,相當(dāng)于把圖片往后移動(dòng)一段距離。這樣才能夠感知到圖片的整體信息。低層卷積可以捕捉到更多的細(xì)節(jié)信息,高層卷積可以捕捉到更多的抽象信息。低層特性更關(guān)心“在哪里”,但分類準(zhǔn)確度不高,而高層特性更關(guān)心“是什么”,但丟失了物體的位置信息。SSD正是利用不同尺度檢測圖片中不同大小和類別的目標(biāo)物體,獲得了很好的效果。
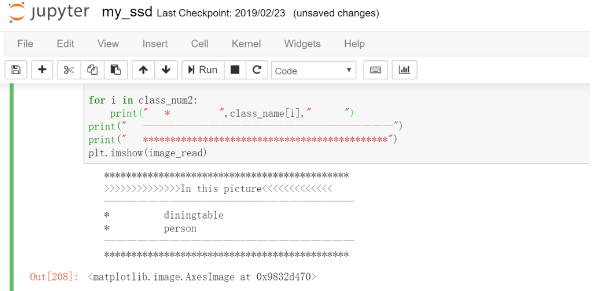
1.3 作品展示



第二部分 系統(tǒng)組成及功能說明 /System Construction & Function Description
2.1 系統(tǒng)功能
實(shí)現(xiàn)了SSD目標(biāo)檢測網(wǎng)絡(luò)在PYNQ平臺(tái)上的移植,能夠?qū)崿F(xiàn)人、自行車、汽車、馬、飛機(jī)等20類目標(biāo)的檢測。輸入任意大小圖像,能夠輸出圖像中所含目標(biāo),并輸出目標(biāo)具體位置。
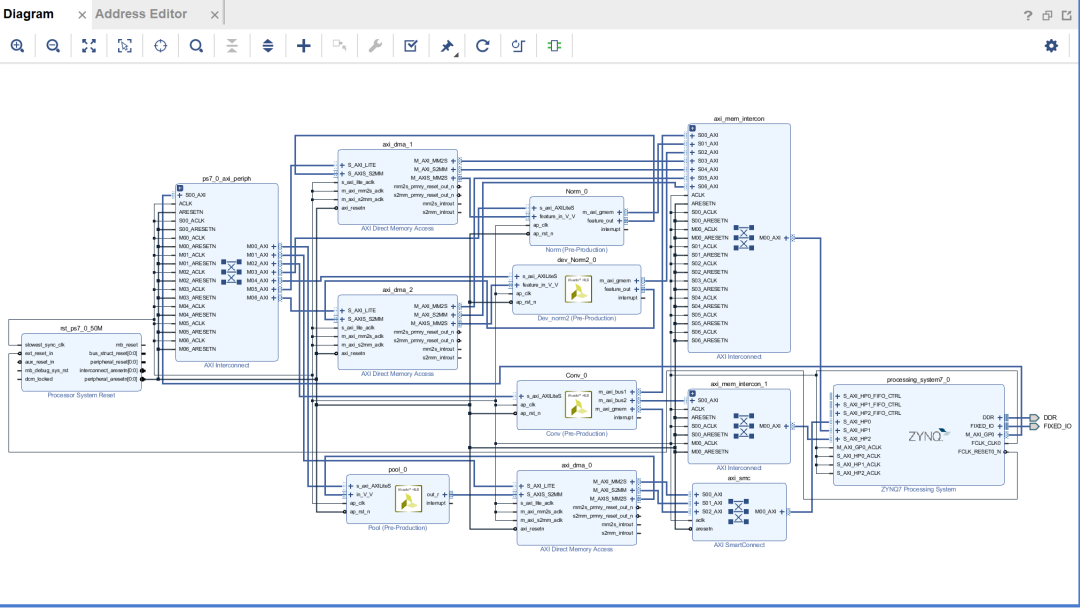
2.2 系統(tǒng)框圖
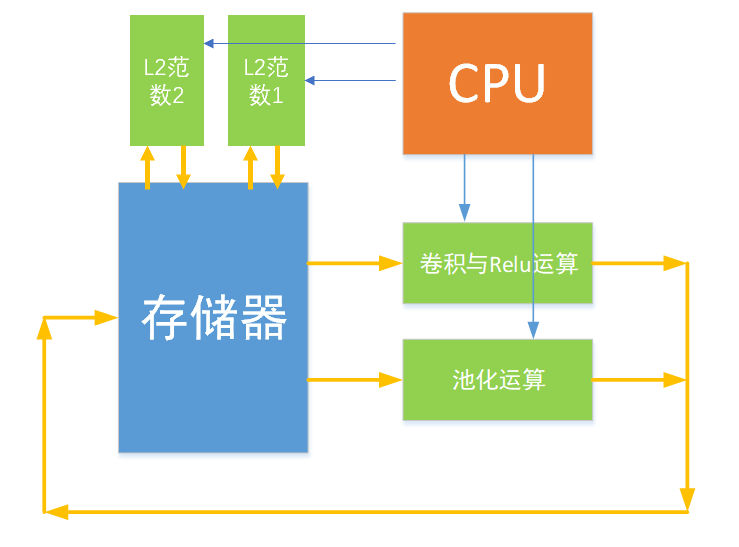
系統(tǒng)框圖如下所示:包含卷積模塊、池化模塊、L2范數(shù)模塊。CPU控制各個(gè)模塊的運(yùn)行,存取地址,通道數(shù)設(shè)置等參數(shù),完成整個(gè)SSD特征提取網(wǎng)絡(luò),并將各個(gè)特征層的數(shù)據(jù)存儲(chǔ)在DDR內(nèi)存中,最后CPU對(duì)輸出結(jié)果進(jìn)行softmax運(yùn)算識(shí)別出圖片中存在的目標(biāo)種類,并根據(jù)輸出計(jì)算出框圖所在的位置。池化模塊和L2范數(shù)模塊是通過AXI-Stream數(shù)據(jù)流的形式對(duì)輸入數(shù)據(jù)進(jìn)行處理,卷積模塊以M_AXI端口同時(shí)讀取特征數(shù)據(jù)和權(quán)重?cái)?shù)據(jù)。
2.3 模塊劃分
卷積模塊:
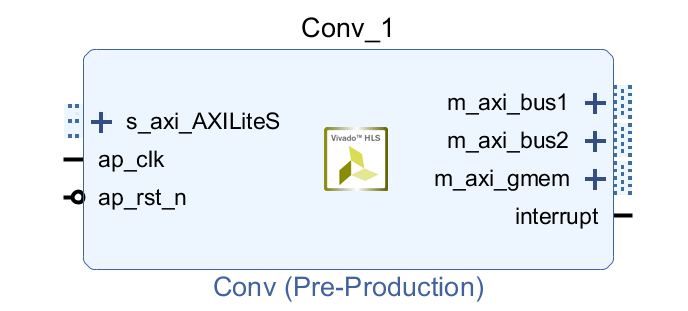
為了提高模塊的通用性,對(duì)模塊的輸入?yún)?shù)約束為AXI_LITE的端口,方便CPU對(duì)模塊進(jìn)行控制,權(quán)重特征及偏置數(shù)據(jù)連接到3個(gè)HP口同時(shí)讀取數(shù)據(jù)。具體的參數(shù)如下
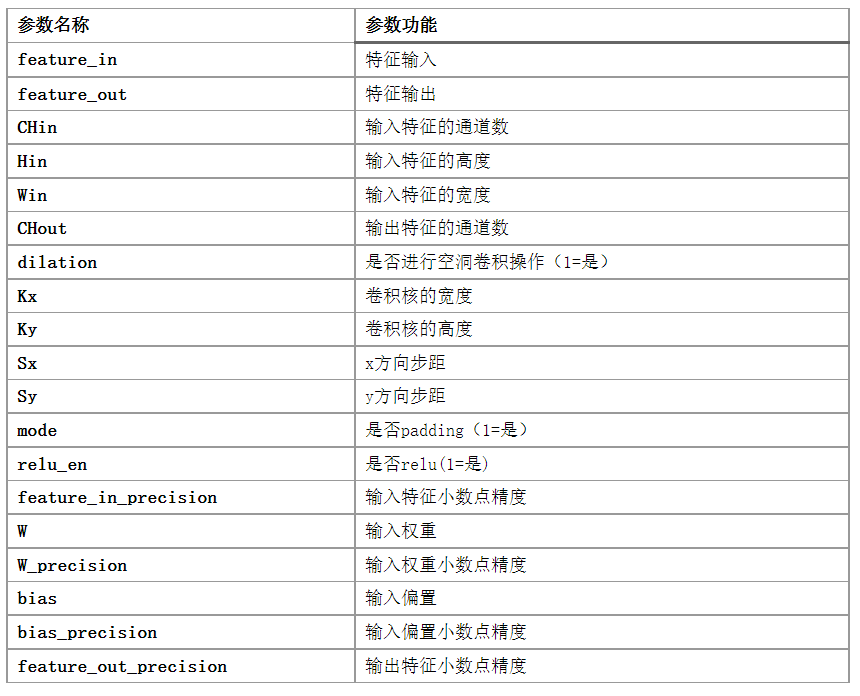
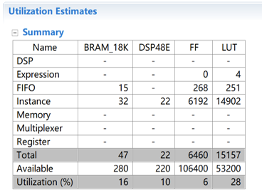
設(shè)置并行數(shù)量K=8時(shí),約束最內(nèi)層循環(huán)II=1,最終得到的資源消耗如下表:

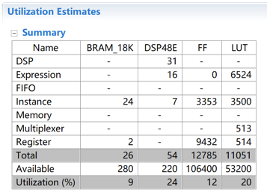
當(dāng)設(shè)置并行數(shù)量K=32時(shí),約束最內(nèi)層循環(huán)II=1,消耗的資源如下表:

考慮到硬件的資源,最終選擇了設(shè)置K=8路并行處理。
池化模塊:

為了實(shí)現(xiàn)流水線的操作,第一步先對(duì)輸入特征進(jìn)行橫向的池化,兩個(gè)兩個(gè)進(jìn)行比較,留下較大的那個(gè)值,第二步再對(duì)縱向池化,縱向池化時(shí)需要第一行的值進(jìn)行緩存,再將第二行的值與其比較,可以使用bram來保存中間值。
L2 范數(shù)模塊

根據(jù)范數(shù)計(jì)算的公式,第一步需要對(duì)每個(gè)通道像素值平方后累加,再開根號(hào)。可以將這個(gè)計(jì)算以流水線的形式對(duì)每個(gè)通道的像素值進(jìn)行累加存放到數(shù)組中,這個(gè)過程同樣可以對(duì)多個(gè)通道同時(shí)操作,增加并行性,等到所有的通道都計(jì)算完成后,將所得到的值存入DDR內(nèi)存地址中,等待下一步使用。
第二步同樣使用流水線的形式取出特征像素和上一步中DDR中存放的數(shù)據(jù),進(jìn)行除法操作,之后再寫回DDR。這樣就完成了整個(gè)L2范數(shù)流水線的計(jì)算。下圖分別為K=16和K=32時(shí)消耗資源的對(duì)比,可以看出當(dāng)K變大時(shí),消耗的LUT資源變得很大,在項(xiàng)目中由于該模塊只使用了一次,因此只將K取為8。
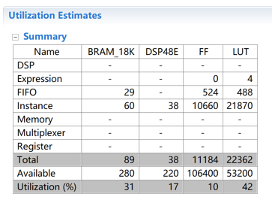
2.4 設(shè)計(jì)優(yōu)化
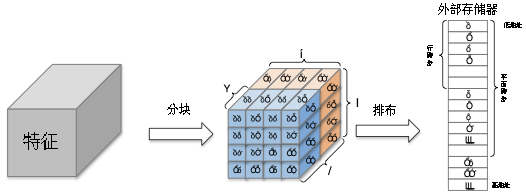
并行設(shè)計(jì):
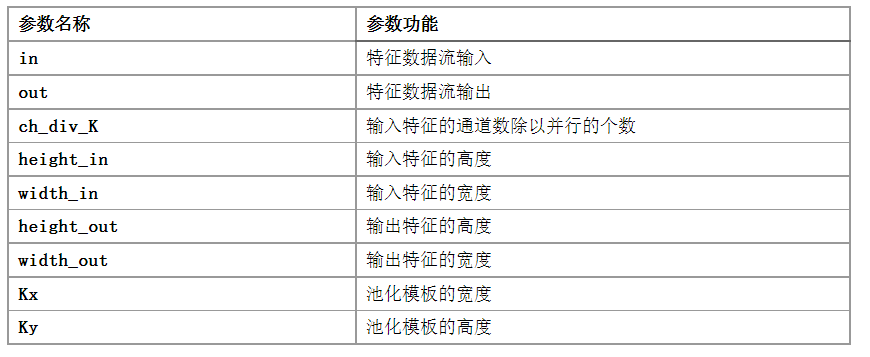
為了提高數(shù)據(jù)的傳輸效率和FPGA的并行特性,我們將特征在內(nèi)存中的排布方式變?yōu)橄聢D的方式,其中一個(gè)長方體子塊代表一個(gè)數(shù)據(jù)子塊,位寬為16*K,K的值可以改變。即每次存取特征數(shù)據(jù)K個(gè)通道的像素值,同時(shí)存取K個(gè)權(quán)重子塊的數(shù)據(jù)進(jìn)行運(yùn)算,
量化設(shè)計(jì)
因?yàn)镕PGA并不比擅長對(duì)浮點(diǎn)數(shù)進(jìn)行運(yùn)算,如果特征和權(quán)重?cái)?shù)據(jù)都使用浮點(diǎn)數(shù)則會(huì)導(dǎo)致資源的消耗特別厲害,因此為了解決這個(gè)問題,采用定點(diǎn)數(shù)的形式對(duì)所有的數(shù)據(jù)進(jìn)行定點(diǎn)化處理。為了獲取權(quán)重及特征的小數(shù)精度,要對(duì)訓(xùn)練好的權(quán)重?cái)?shù)據(jù)進(jìn)行統(tǒng)計(jì),對(duì)于不同層的權(quán)重使用不同精度的定點(diǎn)數(shù),同時(shí)要在前向網(wǎng)絡(luò)時(shí)對(duì)數(shù)據(jù)集中所有數(shù)據(jù)進(jìn)行統(tǒng)計(jì),獲取每一層特征數(shù)據(jù)的精度范圍,將這些精度保留作為卷積模塊的輸入?yún)?shù)。在所有模塊中的計(jì)算都是直接使用定點(diǎn)數(shù)進(jìn)行運(yùn)算。
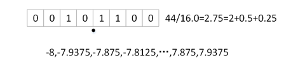
下圖為提取的部分權(quán)重小數(shù)點(diǎn)精度和偏置小數(shù)點(diǎn)精度,可以發(fā)現(xiàn)大部分小數(shù)點(diǎn)的位數(shù)都很高。所以只需要很少的比特去表示整數(shù)位。



2.5 Python 網(wǎng)絡(luò)搭建
第一步.通過PYNQ調(diào)用卷積和池化單元完成主干特征網(wǎng)絡(luò)的實(shí)現(xiàn)
#layer 1
Run_Conv(conv,3,64,3,3,1,1,1,1,0,image,0,vgg1_1w,15,vgg1_1b,14,vgg1_1,5)
Run_Conv(conv,64,64,3,3,1,1,1,1,0,vgg1_1,5,vgg1_2w,15,vgg1_2b,15,vgg1_2,3)
Run_Pool(pool,dma,64,2,2,vgg1_2,vgg1_p)
#layer 2
Run_Conv(conv,64,128,3,3,1,1,1,1,0,vgg1_p,3,vgg2_1w,15,vgg2_1b,15,vgg2_1,2)
Run_Conv(conv,128,128,3,3,1,1,1,1,0,vgg2_1,2,vgg2_2w,15,vgg2_2b,15,vgg2_2,2)
Run_Pool(pool,dma,128,2,2,vgg2_2,vgg2_p)
#layer 3
Run_Conv(conv,128,256,3,3,1,1,1,1,0,vgg2_p,2,vgg3_1w,15,vgg3_1b,15,vgg3_1,2)
Run_Conv(conv,256,256,3,3,1,1,1,1,0,vgg3_1,2,vgg3_2w,15,vgg3_2b,15,vgg3_2,2)
Run_Conv(conv,256,256,3,3,1,1,1,1,0,vgg3_2,2,vgg3_3w,15,vgg3_3b,15,vgg3_3,2)
Run_Pool(pool,dma,256,2,2,vgg3_3,vgg3_cp)
#layer 4
Run_Conv(conv,256,512,3,3,1,1,1,1,0,vgg3_cp,2,vgg4_1w,15,vgg4_1b,15,vgg4_1,2)
Run_Conv(conv,512,512,3,3,1,1,1,1,0,vgg4_1,2,vgg4_2w,15,vgg4_2b,15,vgg4_2,4)
Run_Conv(conv,512,512,3,3,1,1,1,1,0,vgg4_2,4,vgg4_3w,15,vgg4_3b,15,vgg4_3,5)
Run_Pool(pool,dma,512,2,2,vgg4_3,vgg4_p)
#layer 5
Run_Conv(conv,512,512,3,3,1,1,1,1,0,vgg4_p,5,vgg5_1w,15,vgg5_1b,15,vgg5_1,6)
Run_Conv(conv,512,512,3,3,1,1,1,1,0,vgg5_1,6,vgg5_2w,15,vgg5_2b,15,vgg5_2,7)
Run_Conv(conv,512,512,3,3,1,1,1,1,0,vgg5_2,7,vgg5_3w,15,vgg5_3b,12,vgg5_3,7)
Run_Pool_Soft_padding(512,3,3,vgg5_3,vgg5_p)
#exter 1 dilation
Run_Conv(conv,512,1024,3,3,1,1,1,1,1,vgg5_p,7,ex1_1w,15,ex1_1b,15,ex1_1,9)
Run_Conv(conv,1024,1024,1,1,1,1,0,1,0,ex1_1,9,ex1_2w,15,ex1_2b,15,ex1_2,11)
#exter 2
Run_Conv(conv,1024,256,1,1,1,1,0,1,0,ex1_2,11,ex2_1w,15,ex2_1b,15,ex2_1,12)
Run_Conv(conv,256,512,3,3,2,2,1,1,0,ex2_1,12,ex2_2w,15,ex2_2b,15,ex2_2,11)
#exter 3
Run_Conv(conv,512,128,1,1,1,1,0,1,0,ex2_2,11,ex3_1w,15,ex3_1b,15,ex3_1,11)
Run_Conv(conv,128,256,3,3,2,2,1,1,0,ex3_1,11,ex3_2w,15,ex3_2b,15,ex3_2,10)
#exter 4
Run_Conv(conv,256,128,1,1,1,1,0,1,0,ex3_2,10,ex4_1w,15,ex4_1b,15,ex4_1,10)
Run_Conv(conv,128,256,3,3,1,1,0,1,0,ex4_1,10,ex4_2w,15,ex4_2b,15,ex4_2,10)
#exter 5
Run_Conv(conv,256,128,1,1,1,1,0,1,0,ex4_2,10,ex5_1w,15,ex5_1b,15,ex5_1,10)
Run_Conv(conv,128,256,3,3,1,1,0,1,0,ex5_1,10,ex5_2w,15,ex5_2b,15,ex5_2,9)
第二步.對(duì)特定檢測層卷積得到分類預(yù)測和回歸預(yù)測數(shù)據(jù)
#Loc
Run_Conv(conv,1024,24,3,3,1,1,1,0,0,ex1_2,11,l2,15,l2b,15,L2,12)
Run_Conv(conv,512,24,3,3,1,1,1,0,0,ex2_2,11,l3,15,l3b,15,L3,12)
Run_Conv(conv,256,24,3,3,1,1,1,0,0,ex3_2,10,l4,15,l4b,15,L4,12)
Run_Conv(conv,256,16,3,3,1,1,1,0,0,ex4_2,10,l5,15,l5b,15,L5,12)
Run_Conv(conv,256,16,3,3,1,1,1,0,0,ex5_2,9,l6,15,l6b,15,L6,12)
#Conf
Run_Conv(conv,1024,126,3,3,1,1,1,0,0,ex1_2,11,c2,15,c2b,15,C2,10)
Run_Conv(conv,512,126,3,3,1,1,1,0,0,ex2_2,11,c3,15,c3b,15,C3,10)
Run_Conv(conv,256,126,3,3,1,1,1,0,0,ex3_2,10,c4,15,c4b,15,C4,10)
Run_Conv(conv,256,84,3,3,1,1,1,0,0,ex4_2,10,c5,15,c5b,15,C5,10)
Run_Conv(conv,256,84,3,3,1,1,1,0,0,ex5_2,9,c6,15,c6b,15,C6,10)
第三部分 完成情況及性能參數(shù) /Final Design & Performance Parameters
(作品已實(shí)現(xiàn)的功能及性能指標(biāo))
目前作品在功能上已經(jīng)完成了所預(yù)定的功能:實(shí)現(xiàn)SSD目標(biāo)檢測網(wǎng)絡(luò)在PYNQ上的部署,能夠做到輸入一幅圖像,輸出圖中的目標(biāo),并找到目標(biāo)所在的位置。

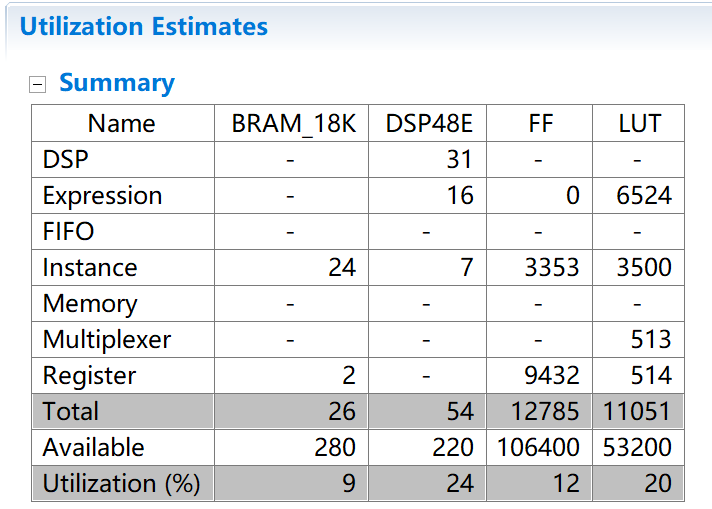

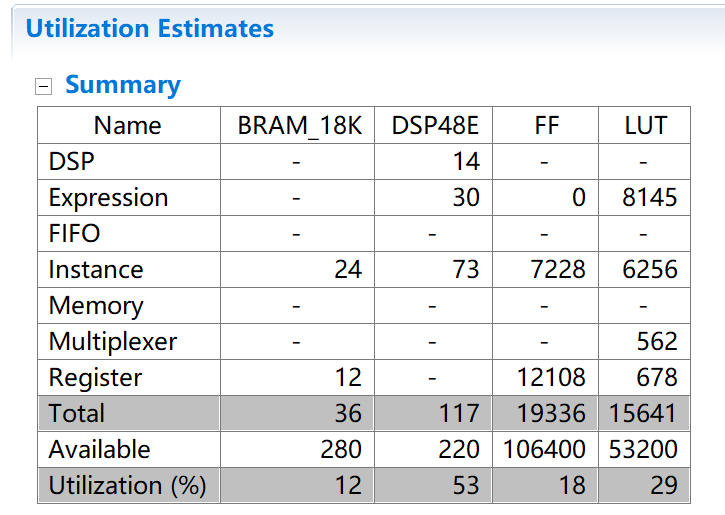
因?yàn)閷?duì)特征權(quán)重?cái)?shù)據(jù)使用了量化的方法,大幅度減少了資源的消耗。下圖對(duì)比了將部分輸入?yún)?shù)改為int類型后消耗的資源情況,可以看到消耗的DSP資源是定點(diǎn)數(shù)的一倍多。
雖然項(xiàng)目達(dá)到了部分預(yù)期的效果,但也存在著一些問題,目前雖然對(duì)FPGA模塊設(shè)計(jì)了并行計(jì)算,但是工作時(shí)鐘頻率卻沒有達(dá)到預(yù)期的100MHz,只使用了50MHz,計(jì)算一幅圖像需要花費(fèi)好幾分鐘的時(shí)間。下一步的工作希望能夠繼續(xù)學(xué)習(xí)如何能夠提高HLS電路的工作頻率,同時(shí)進(jìn)一步提高數(shù)據(jù)并行的數(shù)量,以此來提高目標(biāo)檢測的速度。
-
FPGA
+關(guān)注
關(guān)注
1645文章
22034瀏覽量
617883 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103480 -
目標(biāo)檢測
+關(guān)注
關(guān)注
0文章
224瀏覽量
15999
原文標(biāo)題:基于 FPGA 及神經(jīng)網(wǎng)絡(luò)SSD算法目標(biāo)檢測系統(tǒng)設(shè)計(jì)
文章出處:【微信號(hào):HXSLH1010101010,微信公眾號(hào):FPGA技術(shù)江湖】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
PowerPC小目標(biāo)檢測算法怎么實(shí)現(xiàn)?
基于YOLOX目標(biāo)檢測算法的改進(jìn)
基于碼本模型的運(yùn)動(dòng)目標(biāo)檢測算法

改進(jìn)的ViBe運(yùn)動(dòng)目標(biāo)檢測算法_劉春
基于SSD網(wǎng)絡(luò)模型的多目標(biāo)檢測算法
基于通道注意力機(jī)制的SSD目標(biāo)檢測算法
基于深度學(xué)習(xí)的目標(biāo)檢測算法
一種改進(jìn)的單激發(fā)探測器小目標(biāo)檢測算法
基于多尺度融合SSD的小目標(biāo)檢測算法綜述
基于Grad-CAM與KL損失的SSD目標(biāo)檢測算法
基于SSD算法的小目標(biāo)檢測方法研究
淺談紅外弱小目標(biāo)檢測算法
無Anchor的目標(biāo)檢測算法邊框回歸策略

基于強(qiáng)化學(xué)習(xí)的目標(biāo)檢測算法案例
基于Transformer的目標(biāo)檢測算法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論