 一文快速了解機器學習任務中的重要成分和結構
一文快速了解機器學習任務中的重要成分和結構
??▌基本概念
我們從一個實例來了解機器學習的基本概念。假設我們現在面臨這樣一個任務(Task),任務的內容是識別手寫體的數字。對于計算機而言,這些手寫數字是一張張圖片,如下所示:

對人來說,識別這些手寫數字是非常簡單的,但是對于計算機而言,這種任務很難通過固定的編程來完成,即使我們把我們已經知道的所有手寫數字都存儲到數據庫中,一旦出現一個全新的手寫數字(從未出現在數據庫中),固定的程序就很難識別出這個數字來。所以,在這里,我們的任務指的就是這類很難通過固定編程解決的任務。
要解決這類任務,我們的計算機需要有一定的“智能”,但是在我們的認知中,只有人類才具備這種“高級智能”(某些靈長類動物雖然具備一定的運用工具的能力,但我們認為那距離我們所說的智能還有很遠的距離),所以如果我們想讓計算機具備這種“智能”,由于這是人造的事物,我們稱這種智能為人工智能(Artificial Intelligence, AI)。
正式地講,人工智能,是指由人制造出來的機器所表現出來的智能。通常人工智能是指通過普通計算機程序的手段實現的類人智能技術。機器學習可以幫助我們解決這類任務,所以我們說,機器學習是一種人工智能技術。
那么機器學習是怎么解決這類任務的呢?
機器學習(Machine learning)是一類基于數據或者既往的經驗,優化計算機程序的性能標準的方法。這是機器學習的定義,看起來可能難以理解,我們對它進行分解:
1、首先,對于手寫數字識別這個任務來說,數據或者既往的經驗就是我們已經收集到的手寫數字,我們要讓我們的程序從這些數據中學習到一種能力/智能,這種能力就是:通過學習,這個程序能夠像人一樣識別手寫數字。
2、性能標準,就是指衡量我們的程序的這種能力高低的指標了。在識別任務中,這個指標就是識別的精度。給定100個手寫數字,有99個數字被我們的“智能”程序識別正確,那么精度就是99%。
3、優化,就是指我們基于既往的經驗或者數據,讓我們的“智能”程序變得越來越聰明,甚至比人類更加聰明。
機器學習,就是能夠從經驗中不斷“學習進步”的算法,在很多情況下,我們將這些經驗用數值描述,因此,經驗=數據,這些收集在一起的數據被成為數據集(Dataset),在這些已有的數據集上學習的過程我們稱之為訓練(Train),因此,這個數據集又被稱為訓練集。
很顯然,我們真正關心的并不是機器學習算法在訓練集上的表現,我們希望我們的“智能”程序對從未見過的手寫字也能夠正確的識別,這種在新的樣本(數據)上的性能我們稱之為泛化能力(generalization ability),對于一個任務而言,泛化能力越強,這個機器學習算法就越成功。
根據數據集的不同,機器學習可以分成如下三類:
監督學習(Supervised learning):數據集既包含樣本(手寫字圖片),還包含其對應的標簽(每張手寫字圖片對應的是那個數字)
無監督學習(Unsupervised learning):與監督學習相對,數據集僅包含樣本,不包含樣本對應的標簽,機器學習算法需要自行確定樣本的類別歸屬
強化學習(Reinforcement learning):又稱為增強學習,是一種半監督學習,強調如何基于環境而行動,以取得最大化的預期利益。
當前大熱的神經網絡,深度學習等等都是監督學習,隨著大數據時代的到來以及GPU帶來的計算能力的提升,監督學習已經在諸如圖像識別,目標檢測和跟蹤,機器翻譯,語音識別,自然語言處理的大量領域取得了突破性的進展。
然而,當前在無監督學習領域并沒有取得像監督學習那樣的突破性進展。由于在無人駕駛領域主要應用的機器學習技術仍然是監督學習,本文將重點講監督學習的相關內容。
在本文中,為了便于理解,我們使用手寫數字識別來描述處理的任務,實際上,機器學習算法能夠處理的任務還有很多,例如:分類,回歸,轉錄,機器翻譯,結構化輸出,異常檢測,合成與采樣, 缺失值填補等等。這些任務看似不同,卻有著一個共性,那就是很難通過人為設計的確定性程序來解決。
▌監督學習
經驗風險最小化
監督學習,本質上就是在給定一個集合(X,Y)的基礎上去學得一個函數:
y=f(x)
在 MNIST 問題中,X就表示我們收集到的所有的手寫數字圖片的集合,Y表示這些圖片對應的真實的數字,函數f則表示輸入一張手寫字圖片,輸出這張圖片表示的數值這樣的一個映射關系。
很顯然,這樣的映射關系中的x有著一個極其巨大的取值域(甚至有無限種可能取值), 所以我們可以把我們已有的樣本集合(X,Y)理解為從某個更大甚至是無限的母體中,根據某種未知的概率分布p,以獨立同分布隨機變量方式來取樣。現在,我們假定存在一個損失函數(Loss function)L,這個損失函數可以表述為:
L(f(x),y)
這個損失函數描述的是我們學得的函數f(x)的輸出和x樣本對應的真實值y之間的距離,很顯然,這個損失越小,表示我們學得的函數f更貼近于真實映射g。以損失函數為基礎,我們定義風險:
函數f的風險,就是損失函數的期望值。由于我們以手寫字分類為例,所以這里各個樣本的概率分布p是離散的,我們可以用如下公式定義風險:
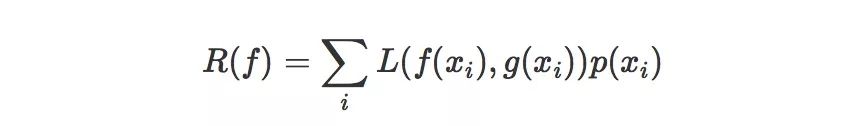
如果是連續的,則可以使用定積分和概率密度函數來表示。這里的xi是指整個樣本空間的所有可能取值,所以,現在的目標就變成了:在很多可能的函數中,去尋找一個f,使得風險R(f)最小。
然而,真實的風險是建立在對整個樣本空間進行考量的,我們并不能獲得整個樣本空間,我們有的只是一個從我們要解決的任務的樣本空間中使用獨立同分布的方法隨機采樣得到的子集(X,Y),那么,在這個子集上,我們可以求出這個真實分布的近似值,比如說經驗風險:
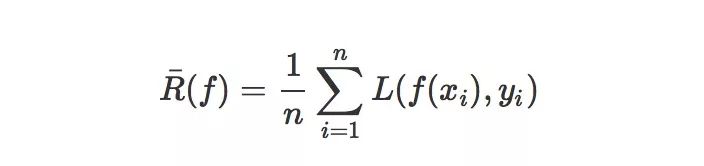
其中(xi,yi)是我們已有的數據集中的樣本,所以,我們選擇能夠最小化經驗風險的函數f這樣的一個策略就被稱之為經驗風險最小化原則。
很顯然,當訓練數據集足夠大的時候,經驗風險最小化這一策略能夠保證很好的學習效果——這也就是我們當代深度神經網絡取得很多方面的成功的一個重要原因。專業的說,我們把我們已有的數據集的大小稱之為樣本容量。不論是什么應用領域,規范的大數據集合,就意味著我們的機器學習任務已經成功了一半。
模型,過擬合,欠擬合
那么學習這個f需要一個載體, 這個載體的作用就是,用它我們可以表述各種各樣的函數f這樣我們就可以通過調整這個載體去選擇一個最優的f,這個最優的f能夠使經驗風險最小化,這個載體我們專業地說,就是機器學習中的模型(model), 單純地說模型的抽象概念可能讓人難以理解,我們選取一種模型的實例來看。
我們以人工神經網絡(artificial neural network,ANN)為例來討論。首先,我們知道我們現在需要的是一個模型,這個模型具有能夠描述各種各樣的函數的能力,下圖是一個神經網絡:
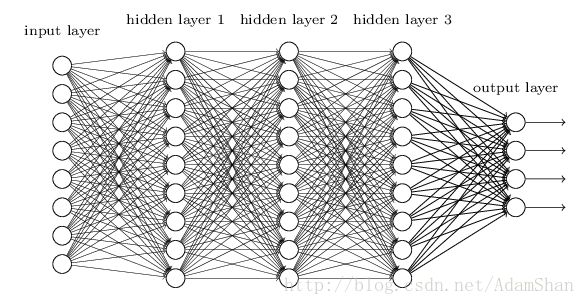
它看起來很復雜,讓人費解,那么我們把它簡化,如下圖:
我們把這個模型理解成一個黑箱,這個黑箱里有很多參數:(w1,w2,w3,...,wn),我們用W來描述這個黑箱中的參數,這些參數叫模型參數,即使模型內部的結構不變,僅僅修改這些參數,模型也能表現出不同的本領。
具體來說:對于手寫字識別任務,我們在手寫字數據集上通過一定的算法調整神經網絡的參數,使得神經網絡擬合出一個函數f,這個f是經驗風險最小化的函數,那么我們訓練出來的這個“黑箱”就可以用于手寫字識別了;另一方面,對于車輛識別來說,假設我們有車輛數據集,相同的思路,我們可以訓練出一個黑箱來最做車輛識別。如下圖所示:

在前文中我們知道,考量一個機器學習模型的關鍵在于其泛化能力,一個考量泛化能力的重要指標就是模型的訓練誤差和測試誤差的情況:
訓練誤差:模型在訓練集上的誤差
測試誤差:模型在從未“見過的”測試集上的誤差
這兩個誤差,分別對應了機器學習任務中需要解決的兩個問題:欠擬合和過擬合。當訓練誤差過高時,模型學到的函數并沒有滿足經驗風險最小化,對手寫字識別來說,模型即使在我們的訓練集中識別的精度也很差,我們稱這種情況為欠擬合。
當訓練誤差低但是測試誤差高,即訓練誤差和測試誤差的差距過大時,我們稱之為過擬合,此時模型學到了訓練集上的一些“多余的規律”,表現為在訓練數據集上識別精度很高,在測試數據集(未被用于訓練,或者說未被用于調整模型參數的數據集合)上識別精度不高。
模型的容量(capacity)決定了模型是否傾向于過擬合還是欠擬合。模型的容量指的是模型擬合各種函數的能力,很顯然,越復雜的模型就能夠表述越復雜的函數(或者說規律,或者說模式)。那么對于一個特定的任務(比如說手寫字識別),如何去選擇合適的模型容量來擬合相應的函數呢?這里就引入了奧卡姆剃刀原則:
奧卡姆剃刀原則:在同樣能夠解釋已知觀測現象的假設中,我們應該挑選”最簡單”的那一個。
這可以理解為一個簡約設計原則,在處理一個任務是,我們應當使用盡可能簡單的模型結構。
“一定的算法”–>梯度下降算法
前面我們說到我們可以通過一定的算法調整神經網絡的參數,這里我們就來介紹一下這個定向(朝著經驗風險最小化的方向)調整模型參數的算法——梯度下降算法。
要最小化經驗風險Rˉ(f),等同于最小化損失函數,在機器學習中,損失函數可以寫成每個樣本的損失函數的總和:
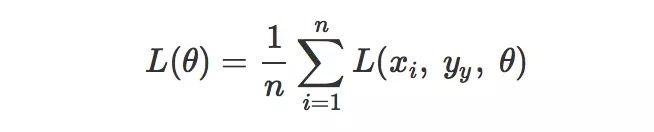
其中θ表示模型中的所有參數,現在我們要最小化L(θ),我們首先想到的是求解導數,我們把這個L對θ的導數記作L′(θ)或者dLdθ, 導數L′(θ)就代表了函數L(θ)在θ處的斜率,我們可以把函數的輸入輸出關聯性用斜率來描述:
L(θ+α)≈L(θ)+αL′(θ)
其中,α是一個變化量,利用這個公式,我們就可以利用導數來逐漸使L變小,具體來說,我們只要讓α的符號和導數的符號相反,即:
sign(α)=?sign(L′(θ))
這樣,L(θ+α)就會比原來的L(θ)更小:
L(θ+α)=L(θ)?|αL′(θ)|
這種通過向導數的反方向移動一小步來最小化目標函數(在我們機器學習中,也就是損失函數)的方法,我們稱之為梯度下降(gradient descent)。
對于神經網絡這種復雜的模型來說,模型包含了很多參數,所以這里的θ就表示一個參數集合,或者說參數向量, 所以我們要求的導數就變成了包含所有參數的偏導數的向量▽θL(θ)。
這里的α就可以理解為我們進行梯度下降的過程中的步長了,我們將學習的步長稱為學習率(learning rate), 它描述了梯度下降的速度。
▌小結
在本文中,我們沒有介紹任何一種具體的機器學習算法和模型,但是我們快速的了解了機器學習任務中的重要成分和結構,以下我們來進行一個小的總結:
首先,機器學習是用來完成特定的任務的:比如說手寫字識別,行人檢測,房價預測等等。這個任務必須要有一定的性能度量,比如說識別精度,預測誤差等等。
然后,為了處理這個任務,我們需要設計模型,這個模型能夠從數據中基于一定的策略(比如說經驗風險最小化原則) 和一定的算法(比如說梯度下降算法) 去學習一個函數。
最后,這個函數要能夠處理這個任務中的各種各樣的情況(包括沒有出現在訓練集中的情況),這個模型要有很好的泛化能力,這樣,我們的機器學習任務就成功了。
-
人工智能
+關注
關注
1797文章
47867瀏覽量
240779 -
機器學習
+關注
關注
66文章
8453瀏覽量
133152 -
數據集
+關注
關注
4文章
1210瀏覽量
24861
原文標題:機器學習入門概覽
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論