 基于語義布局的圖像合成更逼真、效果更好
基于語義布局的圖像合成更逼真、效果更好
編者按:去年,英特爾實驗室視覺組主管Vladlen Koltun和斯坦福大學博士陳啟峰發表論文Photographic Image Synthesis with Cascaded Refinement Networks,用級聯優化網絡生成照片。這種合成的圖片是神經網絡“憑空”生成的,也就是說,世界上根本找不到這樣的場景。他們的算法可以看做一個渲染引擎,輸入一張語義布局,告訴算法哪里有道路、哪里有車、交通燈、行人、樹木,算法就能按照圖中的布局輸出一張逼真的圖像,“好比機器想象出來的畫面”。
在這篇論文中,英特爾實驗室和香港中文大學的研究人員共同創造了一種半參數的圖像合成方法,讓基于語義布局的圖像合成更逼真、效果更好。以下是論智對原論文的編譯。
在古羅馬作家普林尼的作品《自然史》中記述了這樣一則故事:“公元前五世紀,古希臘畫家宙克西斯(Zeuxis)以日常繪畫和對光影的利用而聞名。他畫了一個小男孩舉起葡萄的作品,葡萄非常自然、逼真,竟吸引鳥兒前來啄食。然而宙克西斯并不滿意,因為畫上的男孩舉起葡萄的動作還不夠逼真,沒有嚇跑鳥兒。”技術高超的畫家想做出以假亂真的畫已經很困難了,機器可以實現這個任務嗎?
用深度神經網絡進行現實圖像合成為模擬現實圖像開辟了新方法。在現代數字藝術中,能合成非常逼真的圖像的深層網絡成為一種新工具。通過賦予它們一種視覺想象的形式,證明了它們在AI創造中的有用性。
最近的圖像合成發展大多得益于基于參數的模型驅動,即能代表所有圖像外觀權重所有數據的深層網絡。這與人類寫實畫家的做法完全不同,他們并不是依靠記憶作畫,而是用外部參考當做材料來源,再現目標物體的外觀細節。這也和之前圖像合成的方法不同,傳統的圖像合成方法基于非參數技術,可以在測試時使用大規模數據集。從非參數方法轉變為參數方法,研究人員發現,端到端的訓練有著高度表達的模型。但它在測試時放棄了非參數技術優勢。
在這篇論文中,我們提出了一種半參數的方法(semi-parametric approach),從語義布局中合成近乎真實的圖像,這種方法被稱作“半參數圖像合成(semi-parametric image synthesis,SIMS)”。半參數合成方法結合了參數和非參數技術各自的優勢,在所提出的方法中,非參數部分是指一組與照片相對的語義布局訓練集中繪制的分段數據庫。這些片段用于圖像合成的原始材料,它們通過深度網絡應用在畫布上,之后,畫布會輸出一張圖像。
Chen和Koltun的研究成果與我們的SIMS方法的成果對比。第一行是輸入的語義布局
實驗概覽
我們的目標是基于語義布局L∈{0, 1}h×w×c合成一張逼真的圖像,其中h×w是圖片尺寸,c是語義類別的數量。下圖是圖像合成第一階段的大致過程:
我們的模型在一對對圖片和其對應的語義布局上進行訓練,圖片集是用于生成不同語義類別的圖像片段存儲庫M,其中的每個片段Pi都來源于訓練圖像,并且屬于一個語義類別。圖中的a和b兩部分就是一些片段。
在測試時,我們會得到在訓練時從未見過的語義標簽映射L,這個標簽映射會分解成互相連接的組成部分{Li},對于每個連接部分,我們都會根據形狀、位置和語境,從M中檢索兼容的片段,即上圖b的步驟。而檢索步驟與Li被一個經過訓練的空間變壓器網絡相連接,即圖上的c和d。經過轉換的片段在畫布上進行合成,C∈Rw×h×3,即上圖中的f。由于片段無法與{Li}完美重合,也許會出現重疊的情況。最后e部分用來進行前后排序。
之后,畫布C和輸入的語義布局L一同被輸入合成網絡f中,網絡生成最終的圖像被輸出,過程如下圖所示:
這一過程補全了缺失的區域、調整檢索到的片段、混合邊界、合成陰影,并且基于畫布和目標布局調整圖像外觀。具體架構和訓練過程可查看原論文。
為了將我們的方法應用到較為粗略的語義布局中,我們訓練了一個級聯的精煉網絡,用于將粗糙的布局輸入轉化成密集的像素級輸出。
實驗過程
數據集
本次實驗在三個數據集上進行:Cityscapes、NYU和ADE20K。Cityscapes數據集包含的是城市道路景觀照,其中有3000張帶有精細標記的圖像,20000張粗略標記的、用于訓練的圖像。我們讓模型在這兩種圖像上分別訓練,最終在含有500張圖像的驗證數據集上進行測試。
對于NYU數據集,我們在前1200張圖像上進行訓練,剩下的249張圖像用于測試。而ADE20K數據集是室外圖片,我們中其中1萬張圖像進行訓練,1000張圖像進行測試。
感知測試
我們將提出的方法和pix2pix以及CRN進行了對比,下圖是結果,表中的每一項都顯示,我們的方法(SIMS)都比由pix2pix和CRN合成的圖像更真實:

語義分割準確度
接下來,我們分析了合成圖像的真實性。給定一個語義布局L,我們用一種可評估的方法合成一張圖像I,該圖像之后會被輸入到一個預訓練過的語義分割網絡(這里我們用PSPNet)。這個網絡會生成一個語義布局L?,然后我們將L?和L相比較。理論上來說,二者越接近,圖像的真實程度就越高。比較L和L?有兩種方法:intersection over union(IoU)和總體像素精度。
最終的結果如下:
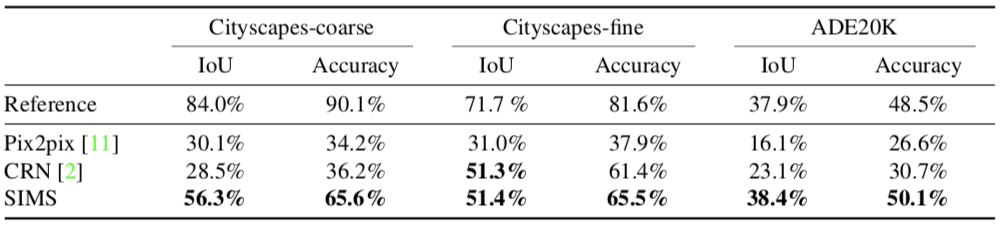
我們的SIMS方法比pix2pix和CRN生成的圖像更合理、更真實。
圖像數據
接著,我們從低級圖像數據方面分析圖像的真實性。我們比較了合成圖像的平均經典譜(power spectrum)以及對應的數據集中的真實圖像。下圖顯示了三種方法合成圖像的平均經典譜:
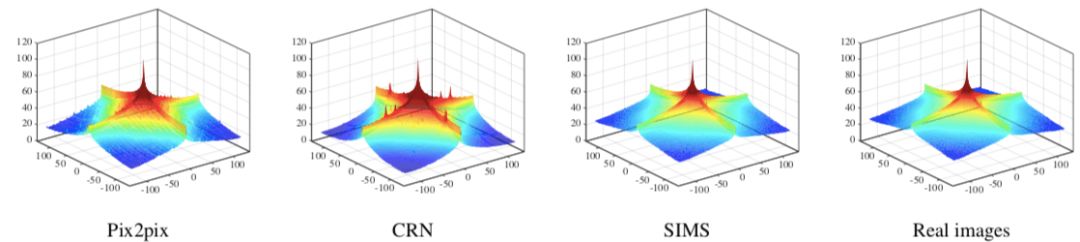
可以看出,我們的方法生成的平均經典譜與真實圖像的平均經典譜非常接近,而其他兩種方法則與真實圖像有差別。
質量結果
從以下兩張圖中可以看出這三種方法的差別。
結語
我們所提出的半參數圖像合成方法(SIMS)可以從語義布局中生成圖像,實驗證明這種方法比完全參數化的技術生成的圖像更真實。但是在這之后仍有一些尚未解決的問題。首先,我們的方法在部署時比完全基于參數的方法慢很多。另外還要開發更高效的數據機構和算法。其次,其他形式的輸入也應該可用,例如語義實例分割或者文本描述。第三,我們所提出的方法并不是端到端訓練的。最后,我們希望這項半參數技術能應用到視頻合成上。
-
神經網絡
+關注
關注
42文章
4785瀏覽量
101266 -
圖像
+關注
關注
2文章
1089瀏覽量
40599 -
數據集
+關注
關注
4文章
1210瀏覽量
24855
原文標題:英特爾實驗室推出半參數圖像合成方法,AI造圖“以假亂真”
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種基于超像素的戶外建筑圖像布局標定方法
3D效果逼真的元件封裝庫網盤下載
基于語義報文的干擾效果評估系統設計
DeepFocus,基于AI實現更逼真的VR圖像
AI工具將低像素的面孔變成逼真的圖像
人體圖像合成制作可信和逼真的人類圖像
分析總結基于深度神經網絡的圖像語義分割方法

基于SEGNET模型的圖像語義分割方法
語義分割標注:從認知到實踐
深度學習圖像語義分割指標介紹

深入理解渲染引擎:打造逼真圖像的關鍵






 工商網監
工商網監
評論