 強化學習的經典基礎性缺陷可能限制它解決很多復雜問題
強化學習的經典基礎性缺陷可能限制它解決很多復雜問題

在上一篇文章里,我們提到了棋盤游戲的比喻和純強化學習技術的缺陷(斯坦福學者冷思考:強化學習存在基礎性缺陷)。在這一部分中,我們會列舉一些添加先驗知識的方法,同時會對深度學習進行介紹,并且展示對最近的成果進行調查。
那么,為什么不跳出純強化學習的圈子呢?
你可能會想:
我們不能越過純強化學習來模仿人類的學習——純強化學習是嚴格制定的方法,我們用來訓練AI智能體的算法是基于此的。盡管從零開始學習不如多提供些信息,但是我們沒有那樣做。
的確,加入先驗知識或任務指導會比嚴格意義上的純強化學習更復雜,但是事實上,我們有一種方法既能保證從零開始學習,又能更接近人類學習的方法。
首先,我們先明確地解釋,人類學習和純強化學習有什么區別。當開始學習一種新技能,我們主要做兩件事:猜想大概的操作方法是什么,或者度說明書。一開始,我們就了解了這一技能要達到的目標和大致使用方法,并且從未從低端的獎勵信號開始反向生成這些東西。
UC Berkeley的研究者最近發現,人類的學習速度比純強化學習在某些時候更快,因為人類用了先驗知識
使用先驗知識和說明書
這種想法在AI研究中有類似的成果:
解決“學習如何學習”的元學習方法:讓強化學習智能體更快速地學會一種新技術已經有類似的技巧了,而學習如何學習正是我們需要利用先驗知識超越純強化學習的方法。
MAML是先進的元學習算法。智能體可以在元學習少次迭代后學會向前和向后跑動
遷移學習:顧名思義,就是將在一種問題上學到的方法應用到另一種潛在問題上。關于遷移學習,DeepMind的CEO是這樣說的。
我認為(遷移學習)是強人工智能的關鍵,而人類可以熟練地使用這種技能。例如,我現在已經玩過很多棋盤類游戲了,如果有人再教我另一種棋類游戲,我可能不會那么陌生,我會把在其他游戲上學到的啟發性方法用到這一游戲上,但是現在機器還做不到……所以我想這是強人工智能所面臨的重大挑戰。
零次學習(Zero-shot learning):它的目的也是掌握新技能,但是卻不用新技能進行任何嘗試,智能體只需從新任務接收“指令”,即使沒有執行過新的任務也能一次性表現的很好。
一次學習(one-shot learning)和少次學習(few-shot learning):這兩類是研究的熱門區域,他們和零次學習不同,因為它們會用到即將學習的技巧做示范,或者只需要少量迭代。
終身學習(life long learning)和自監督學習(self supervised learning):也就是長時間不在人類的指導下學習。
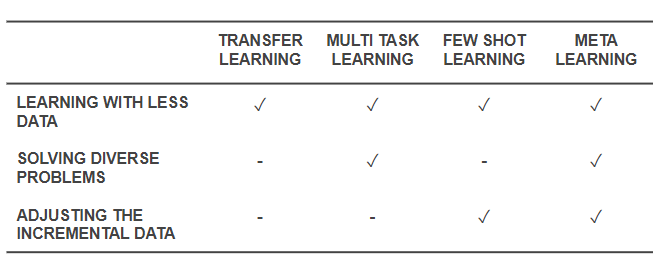
這些都是除了從零學習之外的強化學習方法。特別是元學習和零次學習體現了人在學習一種新技能時更有可能的做法,與純強化學習有差別。一個元學習智能體會利用先驗知識快速學習棋類游戲,盡管它不明白游戲規則。另一方面,一個零次學習智能體會詢問游戲規則,但是不會做任何學習上的嘗試。一次學習和少次學習方法相似,但是只知道如何運用技能,也就是說智能體會觀察其他人如何玩游戲,但不會要求解釋游戲規則。
最近一種混合了一次學習和元學習的方法。來自One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
元學習和零次學習(或少次學習)的一般概念正是棋類游戲中合理的部分,然而更好的是,將零次學習(或少次學習)和元學習結合起來就更接近人類學習的方法了。它們利用先驗經驗、說明指導和試錯形成最初對技能的假設。之后,智能體親自嘗試了這一技巧并且依靠獎勵信號進行測試和微調,從而做出比最初假設更優秀的技能。
這也解釋了為什么純強化學習方法目前仍是主流,針對元學習和零次學習的研究不太受關注。有一部分原因可能是因為強化學習的基礎概念并未經受過多質疑,元學習和零次學習的概念也并沒有大規模應用到基礎原理的實現中。在所有運用了強化學習的代替方法的研究中,也許最符合我們希望的就是DeepMind于2015年提出的Universal Value Function Approximators,其中Richard Sutton提出了“通用價值函數(general value function)”。這篇論文的摘要是這樣寫的:
價值函數是強化學習系統中的核心要素。主要思想就是建立一個單一函數近似器V(s;θ),通過參數θ來估計任意狀態s的長期獎勵。在這篇論文中,我們提出了通用價值函數近似器(UVFAs)V(s, g;θ),不僅能生成狀態s的獎勵值,還能生成目標g的獎勵值。
將UVFA應用到實際中
這種嚴格的數學方法將目標看作是基礎的、必須的輸入。智能體被告知應該做什么,就像在零次學習和人類學習中一樣。
現在距論文發表已經三年,但只有極少數人對論文的結果表示欣喜(作者統計了下只有72人)。據谷歌學術的數據,DeepMind同年發表的Human-level control through deep RL一文已經有了2906次引用;2016年發表的Mastering the game of Go with deep neural networks and tree search已經獲得了2882次引用。
所以,的確有研究者朝著結合元學習和零次學習的方向努力,但是根據引用次數,這一方向仍然不清楚。關鍵問題是:為什么人們不把這種結合的方法看作是默認方法呢?
答案很明顯,因為太難了。AI研究傾向于解決獨立的、定義明確的問題,以更好地做出進步,所以除了純強化學習以及從零學習之外,很少有研究能做到,因為它們難以定義。但是,這一答案似乎還不夠令人滿意:深度學習讓研究人員創造了混合方法,例如包含NLP和CV兩種任務的模型,或者原始AlphaGo加入了深度學習等等。事實上,DeepMind最近的論文Relational inductive biases, deep learning, and graph networks也提到了這一點:
我們認為,通向強人工智能的關鍵方法就是將結合生成作為第一要義,我們支持運用多種方法達到目標。生物學也并不是單純的自然和后期培養相對立,它是將二者結合,創造了更有效的結果。我們也認為,架構和靈活性之間并非對立的,而是互補的。通過最近的一些基于結構的方法和深度學習混合的案例,我們看到了結合技術的巨大前景。
最近元學習(或零次學習)的成果
現在我們可以得出結論:
受上篇棋盤游戲比喻的激勵,以及DeepMind通用價值函數的提出,我們應該重新考慮強化學習的基礎,或者至少更加關注這一領域。
雖然現有成果并未流行,但我們仍能發現一些令人激動的成果:
Hindsight Experience Replay
Zero-shot Task Generalization with Multi-Task Deep Reinforcement Learning
Representation Learning for Grounded Spatial Reasoning
Deep Transfer in Reinforcement Learning by Language Grounding
Cross-Domain Perceptual Reward Functions
Learning Goal-Directed Behaviour
上述論文都是結合了各種方法、或者以目標為導向的方法。而更令人激動的是最近有一些作品研究了本能激勵和好奇心驅使的學習方法:
Kickstarting Deep Reinforcement Learning
Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning
Meta-Reinforcement Learning of Structured Exploration Strategies
Learning Robust Rewards with Adversarial Inverse Reinforcement Learning
Curiosity-driven Exploration by Self-supervised Prediction
Learning by Playing - Solving Sparse Reward Tasks from Scratch
Learning to Play with Intrinsically-Motivated Self-Aware Agents
Unsupervised Predictive Memory in a Goal-Directed Agent
World Models
接著,我們還可以從人類的學習中獲得靈感,也就是直接學習。事實上,過去和現在的神經科學研究直接表明,人類和動物的學習可以用強化學習和元學習共同表示。
Meta-Learning in Reinforcement Learning
Prefrontal cortex as a meta-reinforcement learning system
最后一篇論文的結果和我們的結論相同,論智此前曾報道過這篇:DeepMind論文:多巴胺不只負責快樂,還能幫助強化學習。從根本上講,人們可以認為,人類的智慧正是強化學習和元學習的結合——元強化學習的成果。如果真的是這種情況,我們是否也該對AI做同樣的事呢?
結語
強化學習的經典基礎性缺陷可能限制它解決很多復雜問題,像本文提到的很多論文中都提到,不采用從零學習的方法也不是必須有手工編寫或者嚴格的規則。元強化學習讓智能體通過高水平的指導、經驗、案例更好地學習。
目前的時機已經成熟到可以展開上述工作,將注意力從純強化學習的身上移開,多多關注從人類身上學到的學習方法。但是針對純強化學習的工作不應該立即停止,而是應該作為其他工作的補充。基于元學習、零次學習、少次學習、遷移學習及它們的結合的方法應該成為默認方法,我很愿意為此貢獻自己的力量。
-
智能體
+關注
關注
1文章
291瀏覽量
11028 -
深度學習
+關注
關注
73文章
5557瀏覽量
122666 -
強化學習
+關注
關注
4文章
269瀏覽量
11555
原文標題:面對強化學習的基礎性缺陷,研究重點也許要轉變
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是深度強化學習?深度強化學習算法應用分析

深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
如何深度強化學習 人工智能和深度學習的進階
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?

深度強化學習到底是什么?它的工作原理是怎么樣的
復雜應用中運用人工智能核心 強化學習
一文詳談機器學習的強化學習
DeepMind發布強化學習庫RLax
《自動化學報》—多Agent深度強化學習綜述

什么是強化學習






 工商網監
工商網監
評論