 電子發燒友App
電子發燒友App


?
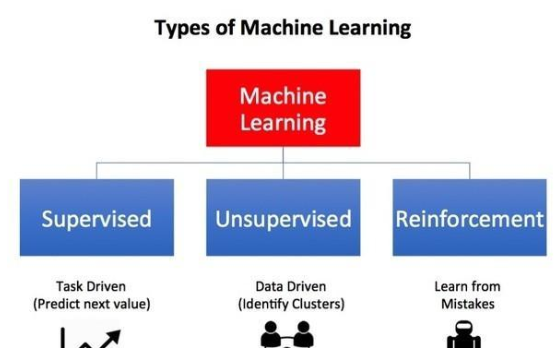
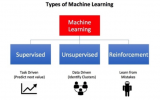
如今,機器學習(Machine Learning,ML)和人工智能(Artificial Intelligence,AI)的相關算法越來越深度地融合到了我們的社會與生活中,并且在金融科技、醫療保健、以及交通運輸等各個方面起到了關鍵性的驅動與促進作用。如果說20世紀下半葉,人類得益于以互聯網為基礎架構的計算力和連通性總體進步的話,那么人類在21世紀正在逐步走向由智能計算和智能機器的迭代。其中,以深度學習(Deep Learning,DL)為首的此類新型的計算范式通常屬于“監督學習(supervised learning)”的范疇。其對應的應用--深度神經網絡(Deep Neural Networks,DNN),在疾病分類、圖像分割、以及語音識別等高科技系統和應用方面,都取得了令人興奮進步和驚人的成功。
不過,深度神經網絡系統往往需要大量的訓練數據,以及已知答案的帶標簽樣本,才能正常地工作。并且,它們目前尚無法完全模仿人類學習和運用智慧的方式。幾乎所有的AI專家都認為:僅僅增加基于深度神經網絡系統的規模和速度,是永遠不會產生真正的“類人(human-like)”AI系統的。 因此,人們開始轉向那些“監督學習”以外的ML和AI計算范式和算法,試圖順應人類的學習過程曲線。該領域研究的最廣泛的當屬--強化學習(Reinforcement Learning,RL)。在本文中,我們通過相關知識和算法的介紹,和您簡要地討論了如何將深度學習和強化學習融合在一起,產生所謂深度強化學習(Deep Reinforcement Learning,DRL),這一強大的AI系統。
什么是深度強化學習? 眾所周知,人類擅長解決各種挑戰性的問題,從低級的運動控制(如:步行、跑步、打網球)到高級的認知任務(如:做數學題、寫詩、交談)。而強化學習則旨在使用軟、硬件之類的代理(具體含義請見下文),通過明確的定義、合理的設計等相關算法,來模仿人類的此類行為。也就是說,這種學習范式的目標不是以簡單的輸入/輸出方式(如:獨立的深度學習系統),來映射帶有標簽的示例,而是要建立一種策略,通過幫助智能化的代理,以某種順序進行動作(具體含義請見下文),從而實現某項最終目標。
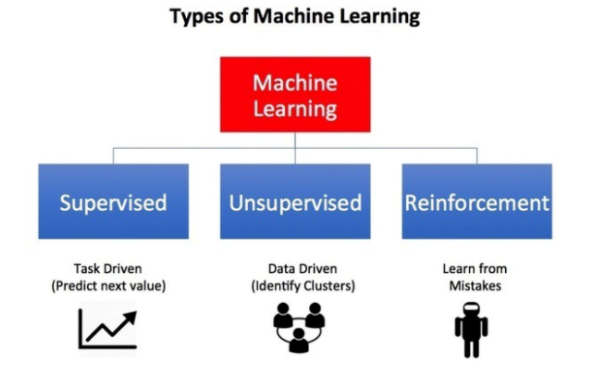
圖片來源:《機器學習有哪些類型》(請參見-- https://towardsdatascience.com/what-are-the-types-of-machine-learning-e2b9e5d1756f)
其實,強化學習是一些面向目標(goal-oriented)的算法,它們能夠學習如何實現復雜的目標,或通過多個步驟沿著某個特定維度來實現目標的最大化。下面是強化學習在實際應用中的三種示例:
讓一個棋盤游戲的獲勝率最大化。
讓財務模擬某筆交易的最大收益。
在復雜的環境中,保障機器人在移動過程中的錯誤行徑最小。
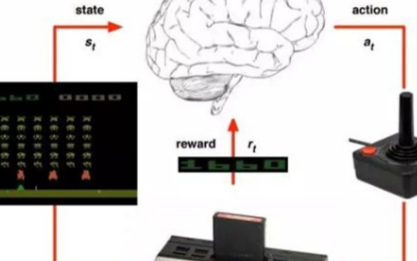
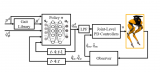
如下圖所示,其基本想法是:代理通過傳感器接收來自所處環境中的輸入數據,使用強化學習的算法對其進行處理,然后采取相應的行動以達到預定的目標。可見,這與人類在日常生活中的行為非常相似。
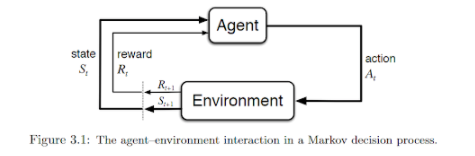
資料來源:《強化學習的簡介》(請參見--http://incompleteideas.net/book/bookdraft2017nov5.pdf) 深度強化學習中的基本定義 我們在開展后續討論之前,了解強化學習中所涉及和使用到的各種關鍵術語是非常實用的。其中包括:
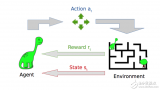
代理(Agent):一種軟、硬件機制。它通過與周圍環境的交互,來采取相應的措施。例如:一架正在送貨的無人機,或是視頻游戲中引導超級瑪麗前進的程序。當然,算法本身也屬于代理。
動作(Action):代理可以采取的各種可能性動作。雖然動作本身具有一定的不言自明性(self-explanatory),但是我們仍需要讓代理能夠從一系列離散的、且可能的動作中予以選擇。
環境(Environment):外界環境與代理之間存在著相互作用,以及做出響應的關系。環境將代理當前的狀態和動作作為輸入,并將代理的獎勵(具體含義請見下文)和下一個狀態作為輸出。
狀態(State):狀態是代理自行發現的、具體且直接的情況,包括:特定的地點、時刻、以及將代理與其他重要事物相關聯的瞬時配置。例如:一個棋盤在某個特定時刻的棋子布局。
獎勵(Reward):獎勵是一種反饋,我們可以據此衡量代理在給定狀態下各種動作的成敗。例如:在下棋游戲中,吃掉對手的象這一重要的動作會得到某種獎勵,而贏得整個游戲則會獲得更大的獎勵。負獎勵(Negative rewards)有著相反的含義,例如:下輸了一盤棋。
折扣因子(Discount factor):折扣因子是一個乘數。由代理發現的未來獎勵乘以該因子,以減弱此類獎勵針對代理當前動作選擇的累積影響。這是強化學習的核心,也就是通過逐漸降低未來獎勵的值,以便對最近的動作給予更多的權值。這對于基于“延遲動作(delayed action)”原理的范式而言,是至關重要的。
策略(Policy):它是代理用來根據當前狀態確定下一步動作的策略。它能夠將不同的狀態映射到各種動作上,以承諾最高的獎勵。
值(Value):它被定義為在特定的策略下,當前狀態帶有折扣的長期預期獎勵(并非短期獎勵)。
Q值(Q-value)或動作值(action-value):與“值”的不同之處在于,Q值需要一個額外的參數,也就是當前的動作。它是指一個動作在特定的策略下,由當前狀態產生的長期獎勵。
常見的數學(算法)框架 在解決強化學習的相關問題時,我們經常會用到如下的數學框架: 馬爾可夫決策過程(Markov Decision Process,MDP):幾乎所有的強化學習問題都可以被構造為MDP。MDP中的所有狀態都具有“馬爾可夫”屬性,即:未來僅取決于當前狀態,而非狀態的歷史,這一事實。 Bellman方程(Bellman Equations):它是一組將值函數分解為即時獎勵加上折扣未來值的方程。 動態編程(Dynamic Programming,DP):如果當系統模型(代理+環境)完全已知時,根據Bellman方程,我們就可以使用動態編程,來迭代評估值函數,并改進相應的策略。

值迭代(Value iteration):這是一種算法,它通過迭代式地改進對于值的估計,以計算出具有最佳狀態值的函數。該算法先將值函數初始化為任意隨機值,然后重復更新Q值和值函數的各個值,直到它們收斂為止。

策略迭代(Policy iteration):由于代理僅關注尋找最優的策略,而最優策略有時會在價值函數之前就已經收斂了。因此,策略迭代不應該重復地改進值函數的估算,而需要在每一步上重新定義策略,并根據新的策略去計算出值來,直到策略收斂為止。 Q學習(Q-learning):作為一種無模型(model-free)學習算法的示例,它并不會假定代理對于狀態的轉換和獎勵模型已經了如指掌,而是“認為”代理將通過反復的試驗,來發現正確的動作。因此,Q學習的基本思想是:在代理與環境交互過程中,通過觀察Q值函數的樣本,以接近“狀態-動作對(state-action pairs)”的Q函數。這種方法也被稱為時分學習(Time-Difference Learning)。
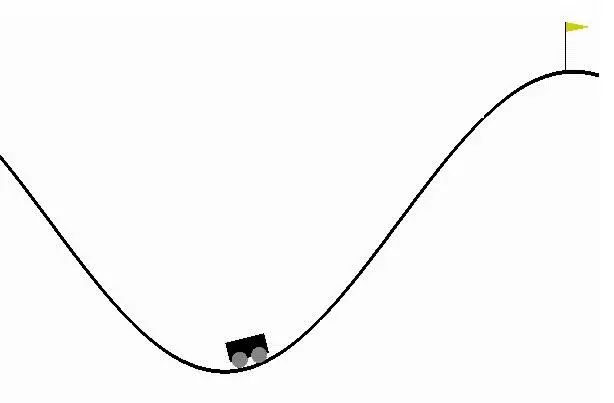
上圖是一個通過Q學習(即:嘗試和錯誤觀察),來解決強化學習問題的示例(請參見-- https://gym.openai.com/envs/MountainCar-v0)。在示例所處環境中,動力學和模型,即運動的整體物理原理,都是未知的。 Q學習所存在的問題 Q學習是解決強化學習相關問題的一種簡單而強大的方法。
從理論上講,我們可以在不引入其他數學復雜性的情況下,將其延伸到各種大而復雜的問題上。其實,Q學習可以借助遞歸方程來完成,其中: Q(s,a):Q值函數 s:狀態 s',s'':未來狀態 a:動作 γ:折現率 對于小的問題,我們可以從對所有的Q值(Q-values)做出任意假設開始,通過反復的試驗,Q表(Q-table)不斷得以更新,進而讓政策逐漸趨于一致。由于更新和選擇動作是隨機執行的,因此最優的策略可能并不代表全局最優,但它可以被用于所有實際的目的。 不過,隨著問題規模的增加,針對某個大問題所構造并存儲一組Q表,將很快成為一個計算性的難題。例如:在象棋或圍棋之類的游戲中,可能的狀態數(即移動的順序)與玩家需要提前計算的步數,成指數式的增長。因此:
保存和更新該表所需的內存量,將隨著狀態數的增加而增多。
探索每個狀態,進而創建Q表所需的時間,將變得無法預知。
針對上述問題,我們需要用到諸如深度Q學習(Deep-Q learning)之類的技術,并使用機器學習來試著解決。 深度Q學習 顧名思義,深度Q學習不再維護一張大型的Q值表,而是利用神經網絡從給定的動作和狀態輸入中去接近Q值函數。在一些公式中,作為輸入的狀態已經被給出,而所有可能的動作Q值都作為輸出被產生。此處的神經網絡被稱為Deep-Q–Network(DQN),其基本思想如下圖所示:
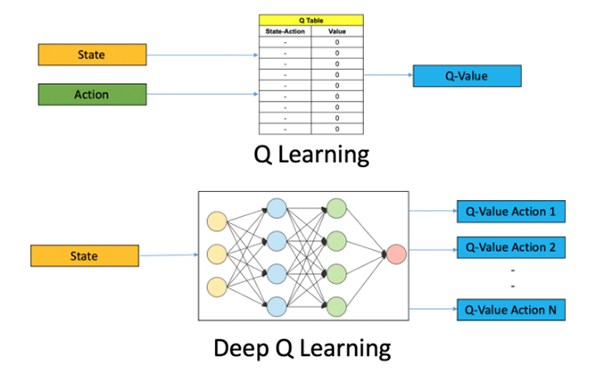
圖片來源:在Python中使用OpenAI Gym進行深度Q學習的入門(請參見--https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/)
不過DQN在使用的時候有一定的難度。而在傳統的深度學習算法中,由于我們對輸入樣本進行了隨機化處理,因此輸入的類別在各種訓練批次之間,都是非常均衡且穩定的。在強化學習中,搜索會在探索階段(exploration phase)不斷被改進,進而不斷地更改輸入和動作的空間。此外,隨著系統逐漸加深對于環境的了解,Q的目標值也會自動被更新。簡而言之,對于簡單的DQN系統而言,輸入和輸出都是經常變化的。
為了解決該問題,DQN引入了體驗重播(experience replay)和目標網絡(target network)的概念來減緩變化,進而以受控且穩定的方式逐步學習Q表。 其中,體驗重播在特定的緩沖區中存儲一定量的狀態動作獎勵值(例如,最后有一百萬個)。而對于Q函數的訓練,它使用來自緩沖區的隨機樣本的小批量來完成。因此,訓練樣本不但是隨機的,并且能夠表現得更接近傳統深度學習中監督學習的典型情況。這有點類似于系統具有高效的短期記憶,我們在探索未知環境時可以用到它。 此外,DQN通常使用兩個網絡來存儲Q值。
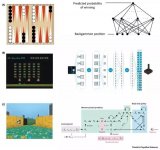
一個網絡不斷被更新,而另一個網絡(即:目標網絡)與第一個網絡以固定的間隔進行同步。我們使用目標網絡來檢索Q值,以保證目標值的變化波動較小。 深度強化學習的實際應用 進行Atari游戲 成立于2010年的DeepMind(請參見--https://deepmind.com/)是一家位于倫敦的初創公司。該公司于2014年被Google的母公司Alphabet所收購,并成功地將卷積神經網絡(CNN)和Q學習結合起來用于訓練。它為深度強化學習領域做出了開拓性貢獻。例如:某個代理可以通過原始像素的輸入(如某些感知信號),來進行Atari游戲。欲知詳情,請參見--https://deepmind.com/research/publications/playing-atari-deep-reinforcement-learning)

圖片來源:DeepMind在arXiV上有關Atari的文章(2013年)(請參見--https://arxiv.org/pdf/1312.5602v1.pdf)。
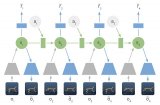
Alpha Go和Alpha Go Zero 3000多年前起源于中國的圍棋,憑借著其復雜性,被稱為AI最具挑戰性的經典游戲。標準的AI處理方法是:使用搜索樹(search tree)來測試所有可能的移動和位置。但是,AI無法處理大量棋子的可能性移動,或評估每個可能性棋盤位置的強度。 借助深度強化學習的技術和新穎的搜索算法,DeepMind開發了AlphaGo,這是第一個擊敗了人類職業圍棋選手的計算機程序,第一個擊敗了圍棋世界冠軍的程序,也可以說是歷史上最強的圍棋選手。
Alpha Go的升級版本被稱為Alpha Go Zero。該系統源于一個對圍棋規則一無所知的神經網絡。該神經網絡通過與功能強大的搜索算法相結合,不斷和自己下棋,與自己進行對抗。在重復進行游戲的過程中,神經網絡會通過持續調整和更新,來預測下棋的步驟,并最終成為游戲的贏家。通過不斷的迭代,升級后的神經網絡與搜索算法重新組合,以提升系統的性能,并不斷提高與自己對弈的水平。
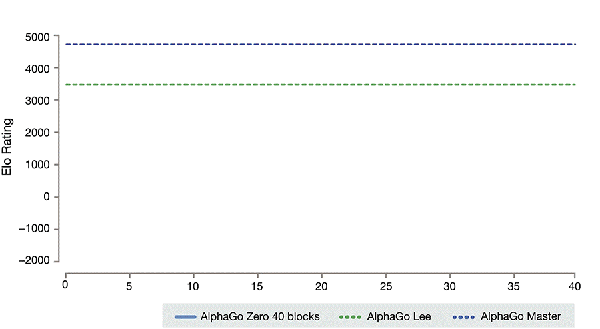
圖片來源:從零開始的Alpha Go Zero(請參見--https://deepmind.com/blog/article/alphago-zero-starting-scratch)
在石油和天然氣行業中的應用 荷蘭皇家殼牌公司一直在其勘探和鉆探工作中通過強化學習的部署,以降低高昂的天然氣開采成本,并改善整個供應鏈中的多個環節。那些經過了歷史鉆探數據訓練的深度學習算法,以及基于物理學的高級模擬技術,讓天然氣鉆頭在穿過地表后,能夠智能地移動。深度強化學習技術還能夠實時地利用來自鉆頭的機械數據(如:壓力和鉆頭的溫度),以及地表下的地震勘測數據。自動駕駛 雖然不是主流應用,但是深度強化學習在自動駕駛汽車的各種挑戰性問題上,也發揮著巨大的潛力。其中包括:
車輛控制
坡道合并
個人駕駛風格的感知
針對安全超車的多目標強化學習
總結 深度增強學習是真正可擴展的通用人工智能(Artificial general intelligence,AGI),是AI系統的最終發展方向。在實際應用中,它催生了諸如Alpha Go之類的智能代理,實現了自行從零開始學習游戲規則(也就是人們常說的:外部世界的法則),而無需進行明確的訓練和基于規則的編程。我們樂觀地認為,深度增強學習的未來和前景將是一片光明。
編輯:黃飛
?



















 工商網監
工商網監
評論