") 深度強化學習已經(jīng)達到了盡頭?
深度強化學習已經(jīng)達到了盡頭?

近日,Reddit一位網(wǎng)友根據(jù)近期OpenAI Five、AlphaStar的表現(xiàn),提出“深度強化學習是否已經(jīng)到達盡頭”的問題。此問題一出便引起了眾網(wǎng)友的熱烈討論,觀點向一邊倒:根本沒到盡頭!
深度強化學習已經(jīng)達到了盡頭?
前幾日,OpenAI Five擺擂三天,以99%的勝率秒殺人類玩家。但值得注意的是,OpenAI Five是接受了45000年的訓練,而人類只通過一天的時間便找到了戰(zhàn)勝它的策略。
OpenAI Five和AlphaStar都是深度強化學(DRL)最大規(guī)模、最精細的實現(xiàn)方式。但即便是AlphaStar上場,估計結(jié)果都是一樣的。
Reddit網(wǎng)友便針對此現(xiàn)象,拋出了這樣一個問題:
有很多研究正在進行,以使DRL更具數(shù)據(jù)效率,并使深度學習對于分布不均和對抗性的例子更加強大,但與人類的差距是如此極端以至于我懷疑是不是快要達到深度學習的極限了?亦或還是有希望能夠推動范式的發(fā)展?
許多網(wǎng)友比較傾向的觀點是:根本沒有達到所謂的極限,而只是可能到了人們不再用“智能”這樣的詞來談論DRL的地步。
網(wǎng)友hobbesfanclub認為:
我覺得我們才剛剛開始。每天都有很多東西被釋放出來,我甚至都跟不上。幾天前我認為是最先進的技術(shù)突然間就不存在了,因為在這個領域里有大量的工作要做。對于我們這些在這一領域工作的人來說,這些進步仍然是令人難以置信的,在我看來,真正令人印象深刻的是,這些技術(shù)在整體上仍然非常年輕……
網(wǎng)友adventuringraw認為:
這是一個很有趣的問題,關(guān)于深度學習本身也有類似的討論——我們已經(jīng)達到神經(jīng)網(wǎng)絡的極限了嗎?如果沒有根本性的范式轉(zhuǎn)變,是否更不可能?
但是你看,在神經(jīng)網(wǎng)絡上有各種各樣的方法,這些方法在2012年可能會讓一些人大吃一驚。很明顯,GAN、VAE、神經(jīng)風格遷移、深度強化學習本身就屬于神經(jīng)網(wǎng)絡范疇內(nèi),與其說深學習被取代了,不如說它被置于“堆棧”之下了。它是一個組成部分,一個解決問題的策略,一種思考方式。即使是深度網(wǎng)絡自己,也是建立在過去各種進步和見解的基礎上的。
我個人的想法是:這似乎是無模型方法的一個基本問題。你需要在特征空間中進行密集的覆蓋,或者換句話說,你知道在一個已經(jīng)完全探索過的領域里該做什么,但你不一定能夠推斷和推理出新的環(huán)境,你需要一個全局模型來進行推理。
我之前看過基于Google Brain的'SimPLe'模型的RL論文,開始向基于模型的RL過渡并不是一個全新的概念。但是在我們得到一個能夠在空間中進行抽象推理的智能體之前,還有一些嚴重的問題有待解決:
它如何學習空間中相關(guān)的獨立實體、動作、等等?
它能在無人監(jiān)督的情況下完成嗎?
它如何將當前的世界理解壓縮為一個更低的維度表示,從而完美地捕捉到解決當前問題最需要的維度?
它能學會周圍環(huán)境的地圖嗎?
創(chuàng)建分層長期計劃的最佳方法是什么?
......
即使只使用圖像分類,我們?nèi)匀缓茈y提取基于形狀的特征而不是基于紋理的特征。一般來說,局部模式似乎比全局模式更容易獲取,所以我想OpenAI Five更容易利用局部模式所采用的策略,這使得它很容易受到具有正確洞察力的玩家的攻擊。
我一直在讀Judea Pearl的《因果關(guān)系》(Causality),有一些有趣的東西是值得思考的。我不認為他的因果關(guān)系模型是我們需要讓智能體明確地向世界學習什么東西,但是若是讓一個智能體能夠完全適應新環(huán)境并在宏觀規(guī)模上進行規(guī)劃的整體似乎是需要它能夠反事實地推理,并對它自己的世界有一個強有力的理解。
考慮到我們才剛剛開始了解創(chuàng)建一個魯棒的圖像分類器需要什么(即使是在有監(jiān)督的環(huán)境中,更不用說無監(jiān)督的環(huán)境了),我認為在深度強化學習完全成長之前,我們已經(jīng)有了一些基礎理論。
但非常瘋狂的事情是,我們似乎正在逐步消除了這些障礙。而另一方面,卻出現(xiàn) 了一個可以玩Dota2、學會合作、學會對世界進行推理的無監(jiān)督系統(tǒng),這似乎讓人覺得我們快要到達技術(shù)的頂尖了,但實際上并沒有。所以我對于OpenAI沒有到達那個點并不感到驚訝。但對于接下來即將發(fā)生的事情還是抱有很大的期待的。
該問題似乎在reddit的討論熱度很高,但是縱觀網(wǎng)友們的評論,可以很容易看出對這個問題的看法是向一邊傾倒的:
深度強化學習遠未及極限,還有很長的一段路要走。
“寒冬論”四起,榮耀屬于熬過寒冬的人
但其實,人們不僅會對深度強化學習提出“寒冬論”的言論,深度學習亦是如此。
多年來,深度學習一直處于所謂的人工智能革命的最前沿,許多人相信深度學習將帶領我們進入通用AI時代。在2014,2015,2016年,很多事件每每推動人們對 Ai的理解邊界。例如Alpha Go等。特斯拉等公司甚至宣稱:全自動駕駛汽車正在路上。
但是現(xiàn)在,2018年中期,事情開始發(fā)生變化。從表面上看,NIPS會議仍然很火,關(guān)于AI的新聞也很多,Elon Mask仍然看好自動駕駛汽車,而Google CEO不斷重申Andrew Ng的口號,即AI比電力作出了更大的貢獻。但是這些言論已經(jīng)開始出現(xiàn)裂紋。裂紋最明顯的地方是自動駕駛- 這種現(xiàn)實世界中的實際應用。
當ImageNet有了很好的解決方案(注意這并不意味著視覺問題得到已經(jīng)解決),該領域的許多杰出研究人員(甚至包括一直保持低調(diào)的Geoff Hinton)都在積極地接受采訪,在社交媒體上發(fā)布內(nèi)容(例如Yann Lecun,吳恩達,李飛飛等)。他們的話,可以總結(jié)為:世界正處在一場巨大的AI革命中。然而,好幾年已經(jīng)過去了,這些人的Twitter信息變得不那么活躍了,比如 Andrew Ng:
2013年 - 每天0.413推文
2014 年- 每天0.605條推文
2015 -每天0.320條推文
2016 -每天0.802推文
2017 -每天0.668推文
2018 -每天0.263推文(至5月24日)
也許這是因為Andrew 的某些夸張言論,在當下會被進行更詳細的審查,如下面的推文所示:
不可否認,深度學習的熱度已經(jīng)大大下降,贊美深度學習作為AI終極算法的推文少得多了,而且論文正在變得不那么“革命”,現(xiàn)在大家換了個詞,叫:進化。
自從Alpha Zero以來,DeepMind已經(jīng)許久沒有產(chǎn)出令人驚嘆的東西了。OpenAI更是相當?shù)牡驼{(diào),他們最近一次出現(xiàn)在媒體的報道上,是他們做了一個自動打Dota 2的機器人 [我一開始以為,這是跟 Alpha Go 一樣的偉大,然后后來證明,并不是]。
從某些文章來看,貌似Google實際上并不知道如何處理Deepmind,因為他們的結(jié)果顯然不如原先預期的那么實際......至于杰出的研究人員,他們一般都為了funding 在各種政府機構(gòu)間游走,Yann Lecun甚至從 Facebook的AI首席科學家的位置上下臺了。
像這種從富有的大公司向政府資助的研究機構(gòu)的逐漸轉(zhuǎn)變表明,這些公司對這類研究的興趣(我認為是谷歌和Facebook)實際上正在慢慢消失。這些都是早期跡象,沒有人大聲的宣揚,但這些行動就像肢體語言,也能傳達某種意思。
深度學習的一個重要口號是它可以輕松的擴展。我們在2012年擁有60M參數(shù)的AlexNet,現(xiàn)在我們已經(jīng)有至少1000倍的數(shù)量的模型了嗎?好吧,我們可能會這樣做,但問題是 - 這些東西有1000x的能力提升嗎?100倍的能力?openAI的研究派上用場:
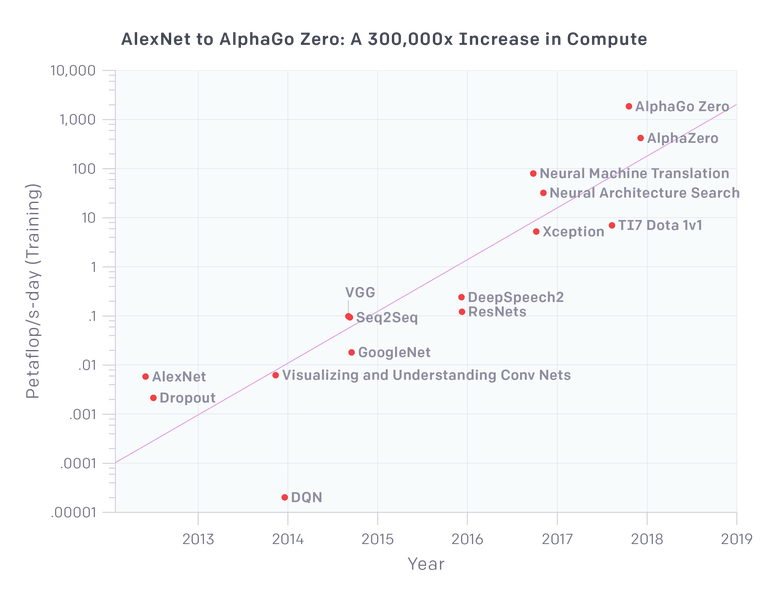
因此,就視覺應用而言,我們看到VGG和Resnets在計算資源應用的一個數(shù)量級上飽和(就參數(shù)數(shù)量而言實際上較少)。Xception是谷歌Inception架構(gòu)的一種變體,實際上它在ImageNet上的表現(xiàn)只是略微優(yōu)于其他模型,因為AlexNet基本上解決了ImageNet。
因此,在比AlexNet計算量提高100倍的情況下,我們在視覺方面已經(jīng)有了近乎飽和的體系結(jié)構(gòu),換句話說,圖像分類的精確已經(jīng)提不動了。
神經(jīng)機器翻譯是所有大型網(wǎng)絡搜索玩家(google, baidu, yahoo 等)的一大努力,難怪它有多少機器就用多少機器(盡管谷歌翻譯仍然很糟糕,雖然已經(jīng)在變得更好了)。
該圖上的最新三點有趣地顯示了Deep Mind和OpenAI應用于游戲的強化學習相關(guān)項目。特別是AlphaGo Zero和稍微更通用的Alpha Zero需要大量計算,但不適用于真實世界的應用程序,因為需要大量計算來模擬和生成這些數(shù)據(jù)來供這些模型使用。
好的,現(xiàn)在我們可以在幾分鐘內(nèi)完成AlexNet的訓練,但是我們可以在幾天內(nèi)訓練一個比AlexNet大1000倍,質(zhì)量更好的模型嗎?顯然不是。
迄今為止,對深度學習的聲譽打擊最大的事件來自自動駕駛領域。一開始人們認為End-to-End的深度學習可以以某種方式解決自動駕駛問題 (Nvidia特別推崇這一理念)。現(xiàn)在我覺得地球上應該沒有人還相信這一點(盡管我可能是錯的)。
看看前年加州車輛管理局DMV給各個廠商的自動駕駛車輛人為干預報告,Nvidia的自動駕駛汽車在缺少人為干預的情況下,連開10英里都做不到。
自2016年以來,特斯拉自動駕駛系統(tǒng)發(fā)生了幾起事故,其中一些事件是致命的。可以說,特斯拉的自動駕駛輔助技術(shù)不應該與自動駕駛混淆起來雖然在核心上它依賴于同一種技術(shù)。
都到今天了,它仍然不能自動停在路口,不能識別交通信號燈,甚至不能通過環(huán)形交叉路口。那是在2018年5月,在承諾特斯拉將自動駕駛從西海岸開到東海岸的幾個月后(盡管傳言是他們已經(jīng)嘗試過但是在小于30次人工干預的情況下無法實現(xiàn))。幾個月前(2018年2月),伊隆馬斯克(Elon Musk)在一次電話會議上被問及海岸到海岸的行駛問題時重復說到:
“我們本可以實現(xiàn)海岸到海岸的駕駛,但它需要太多的專門代碼來有效地進行游戲;或者使代碼變得脆弱一些,這樣它只適用于一個特定的路線,這不是通用的解決方案。
我對神經(jīng)網(wǎng)絡方面取得的進展感到非常興奮。但是看起來并沒有太多的進展。它會覺得這是一個蹩腳的司機。就像…好吧,這是一個非常好的司機。像“Holy Cow!”
因此,有許多人開始對深度學習提出“寒冬論”:
預測人工智能的冬天就像是猜測股市崩盤一樣——不可能精確地知道發(fā)生的時間,但幾乎可以肯定會在某個時刻發(fā)生,就像股市崩盤之前,有跡象表明會發(fā)生危機,但在當時的環(huán)境中,卻很容易被大家忽視。
在我看來,深度學習已經(jīng)出現(xiàn)了明顯的下降跡象。我并不知道這個冬天會有多“深度”,我也不知道接下來會發(fā)生什么,但我可以肯定,這個冬天一定會來臨,并且只會來的比想象的要早。
然而,上個月2018年圖靈獎公布,深度學習三巨頭:Yoshua Bengio、Geoffrey Hinton、Yann LeCun獲獎,三人瓜分100萬美元獎金。
Yann LeCun、Geoffrey Hinton、Yoshua Bengio
去年,”深度學習寒冬論“頻起,三位大神也在多個場合對”寒冬“做出了回應。實際上,三人對“寒冬”早有抗體,在上世紀八十年代,Geoffrey Hinton等人坐了數(shù)年的冷板凳,直到本世紀AI的再度爆發(fā)。
不僅如此,Geoffrey Hinton還提出新的神經(jīng)網(wǎng)絡模型Capsule Network(膠囊網(wǎng)絡),試圖找到解決深度學習缺陷的新方法,這位71歲的老人熬過最冷的AI冬天,并且認定下一個“冬天”不會到來。
事實證明,榮耀是屬于熬過寒冬的人。
-
人工智能
+關(guān)注
關(guān)注
1806文章
49014瀏覽量
249444 -
自動駕駛
+關(guān)注
關(guān)注
789文章
14318瀏覽量
170621 -
強化學習
+關(guān)注
關(guān)注
4文章
269瀏覽量
11600
原文標題:靈魂一問:深度強化學習終到盡頭?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
NVIDIA Isaac Lab可用環(huán)境與強化學習腳本使用指南

18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術(shù)與代碼實現(xiàn)

詳解RAD端到端強化學習后訓練范式

軍事應用中深度學習的挑戰(zhàn)與機遇
淺談適用規(guī)模充電站的深度學習有序充電策略
智譜推出深度推理模型GLM-Zero預覽版
螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
NPU在深度學習中的應用
淺談適用于大規(guī)模充電場站的深度強化學習有序充電策略






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論