 多智體深度強化學習研究中首次將概率遞歸推理引入AI的學習過程
多智體深度強化學習研究中首次將概率遞歸推理引入AI的學習過程

受人類遞歸推理思維啟發,UCL汪軍教授組在多智體深度強化學習研究中首次將概率遞歸推理引入AI的學習過程,讓智能體在決策前預測其他智能體的反應對自身的影響。這項工作提升了AI群體思考深度,也為MARL研究提供了全新的思路。
開始之前,先來做個游戲。
假設你跟其他正在看這篇文章的讀者一起玩一個游戲,從0到100當中猜出一個數,最后最接近所有人猜的數字平均值的2/3的那個人獲勝,那么作為一個個體,你會說幾?
這個游戲來自著名的博弈論游戲“猜平均數的三分之二”(guess 2/3 of the average-game),嚴格來說,人類玩家之間并沒有一個必勝的策略。但是,通過不斷思考對手可能的決策,這個游戲的眾多答案中就會出現一個唯一的納什均衡,也就是0。
猜平均數的三分之二
0到100的平均值是50, 如果每個個體完全不考慮對手的數字而是隨機選擇一個數字,那么猜的數字的均值就是50.
這時候有人就可以想了,假設其他人都是無腦瞎猜,那么要獲勝,自己就需要多想一步,說出50的三分之二——也就是“50*2/3=33”。
假設其他人都說“33”,又會有人想,要獲勝,自己就需要再多想一步,說出33的2/3——“22”。
這個過程不斷重復下去,最終,就會得到0。實際上,0也是這個問題的納什均衡。
但注意,這是在所有人都完全極度理性的情況下,現實生活中,沒有人是絕對理性的,所以并不會出現所有人都猜到0的情況,一般群體能收斂到“22-33”之間已經很不錯了。
更重要的是,這個游戲充分說明了預測其他人猜的數字對自己將要給出的結果的影響——即使是完全理性的玩家,在這樣的游戲中也不應該猜“0”,除非能夠確認:1)其他玩家也都是理性的,2)每個玩家都知道其他玩家是理性的。
只要上述兩點沒有同時成立,也即存在非理性玩家的情況下,要獲勝至少應該猜大于0的數字。現實生活中,大多數情況下人類的決策都會有非理性的因素。為了對真實的決策過程更好的建模,那么考慮非理性的因素對于多智能體AI的研究來說就是至關重要了。
1981年,Alain Ledoux在他的法國雜志《游戲與策略》(Jeux et Stratégie)中提出了“猜平均數的三分之二”這個游戲,結果分布如下圖。

1981年2898位讀者參與“猜平均數2/3”的結果分布,來源:維基百科
這個游戲也可以用來反映群體的“思維深度”,最終數字越小,說明群體的思考層數(回數)越多。
實驗心理學領域詳細研究了不同職業不同人的思維深度,厲害的國際象棋大師能夠預測未來7個來回甚至更遠的情況,然后根據預測,返回來決定眼下在哪里落子。事實上,人類作為一個整體平均的思維深度是1.5– 2。
絕大多數的人都會在做事前對自己行為的結果進行某種程度上的預估,具體說,人會先預測自己的行為可能對他人影響,然后再進一步預測受了影響的他人將如何反過來影響自己,這是一個遞歸的過程。
認知心理學認為,遞歸推理(recursive reasoning)也即推測他人認為自己在想什么,是人類固有的一種思維模式,在社交生活中對人類行為決策起到重要作用。放在猜數字游戲里,就是“我猜你猜我在想什么”。

人類社交中的遞歸推理過程。圖片來源:Gl?scher Lab
UCL首次將遞歸推理引入多智體深度強化學習
在傳統的多智體學習過程當中,有研究者在對其他智能體建模(也即“對手建模”, opponent modeling)時使用了遞歸推理,但由于算法復雜和計算力所限,目前還尚未有人在多智體深度強化學習(Multi-Agent Deep Reinforcement Learning)的對手建模中使用遞歸推理。
在被深度學習頂會ICLR 2019高分接收的一篇最新論文中,UCL汪軍教授組首次將遞歸推理的思維模式引入多智體深度強化學習。
具體說,他們提出了一個遞歸概率推理框架Probabilistic Recursive Reasoning, 簡稱PR2,讓每個智能體在決策時考慮其他智能體將如何回應自己接下來的行動,然后做出最優的決策。
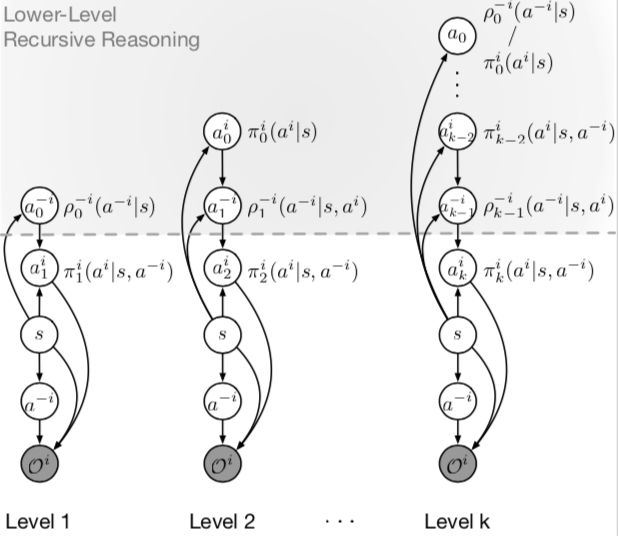
k 階遞歸推理圖模型。a代表思考深度,隱式的對手建模用函數ρ-i逼近。0階模型認為對手完全隨機。上圖灰色區域表示智能體 i 的遞歸推理思考過程。想得更深一級的智能體返回得出當前輪次的最優結果。每一級計算都包含上一級的計算,比如2階包含1階。來源:https://arxiv.org/abs/1901.09216
基于PR2框架,研究人員提出了分別對應連續和離散動作空間的PR2-Q 和 PR2-Actor-Critic算法。有趣的是,這些算法是天生的分布式算法,不需要Centralized Value Function。多次實驗結果表明,PR2有效提升了多智體強化學習中單個智能體的學習效率。
“我們在MARL智能體的遞歸推理中,使用了概率圖模型建模,最后得到了一個soft learning的結果,”參與這項工作的UCL計算機學院博士生Yaodong Yang告訴新智元:“巧妙的是,這和單智能體的最大熵強化學習有相通之處。”
研究人員希望這項工作為MARL的對手建模帶來一個全新的角度。論文的第一作者、UCL計算機學院的博士生溫穎在接受新智元采訪時表示:“在PR2的基礎上,針對更深層的遞歸推理,我們設計了一個特殊的trick,能保證訓練時每一步更深層的推理都比上一次迭代要好,同時不是無限制地計算下去,那樣的話計算資源的消耗太大。”
研究負責人UCL汪軍教授說:“ICLR的工作主要是考慮了1階遞歸思考,也就是考慮別人會怎么想自己,接下來,我們將繼續研究多智體強化學習中AI的遞歸推理,在ICML 2019的投稿中,我們將其推廣到 n 階遞歸思考的過程,從而讓多智能體AI在更加有效有意義的納什均衡,相關理論將在機器人、自動駕駛汽車等應用中都有重要意義。”
-
AI
+關注
關注
88文章
35476瀏覽量
281207 -
智能體
+關注
關注
1文章
318瀏覽量
11124 -
強化學習
+關注
關注
4文章
269瀏覽量
11636
原文標題:ICLR19高分論文:為思想“層次”建模,遞歸推理讓AI更聰明
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是深度強化學習?深度強化學習算法應用分析

將深度學習和強化學習相結合的深度強化學習DRL
薩頓科普了強化學習、深度強化學習,并談到了這項技術的潛力和發展方向
DeepMind發布強化學習庫RLax
機器學習中的無模型強化學習算法及研究綜述

模型化深度強化學習應用研究綜述

基于深度強化學習的路口單交叉信號控制
基于深度強化學習仿真集成的壓邊力控制模型
《自動化學報》—多Agent深度強化學習綜述

語言模型做先驗,統一強化學習智能體,DeepMind選擇走這條通用AI之路






 工商網監
工商網監
評論