 關于有屏設備的語音交互體驗實驗研究
關于有屏設備的語音交互體驗實驗研究

第二屆百度AI開發者大會在北京舉行,百度AI交互設計院在首次舉辦的AI設計分論壇上,分享了《AI時代的人因工程》主題演講,他們認為:在AI時代,全新的設計將會重構我們身邊的工具、生產力、生活甚至心理學。AI時代的人因工程,是關于人的能力、行為、限制的特點,也關于人的社會、文化、心理,是真正以人類為中心的系統工程。他們還將腦電、肌電和眼動等生理測量方法引入了人因工程研究中,將研究方法進行創新迭代,不斷助力百度的AI產品進行“重構”。百度開發者大會剛剛結束,百度AI交互設計院又隨即推出了最新的研究報告《多維對話——走向視聽融合的語音交互新體驗研究》,進一步用扎實的研究彰顯了他們在AI交互設計領域的專業實力。
過去四十年,人與機器的交互方式在不斷進化,幾乎每十年就會有一次重大革新。來到人工智能時代,生活中越來越多的設備開始支持語音交互,語音交互逐漸成為人們傳達意圖和與設備交流的優先選擇(Voice First)。與傳統交互相比,語音交互解放了雙手和雙眼,人們可以低成本與設備互動;而且,語音是多維的,除了言語本身的信息,言語中還蘊含著豐富情感,允許人們與設備進行更充分的互動。
語音交互也有局限性。語音交互是非可視化的,容易增加人們的記憶負擔,設想語音查詢信息的場景,你可能需要集中精力聽,如果不留神就容易錯過一些內容。鑒于此,正如人工智能專家吳恩達提到的,人與機器交流最高效的方式是語言,而機器與人最高效的交流方式是語言加上視覺,即需要在聽覺基礎上融入視覺信息彌補語音交互的不足。從語音向視覺延伸,在語音交互中融入可視化信息,已經是業界探索下一代語音交互范式的重要趨勢。以智能音箱為例,除了無屏音箱以外,市場上開始出現帶屏幕的音箱。
百度人工智能交互設計院本期以有屏智能設備為研究對象,聚焦語音交互反饋和內容輸出環節的體驗。考慮到屏幕尺寸差異可能對反饋和內容輸出體驗的影響,研究選擇了兩種不同屏幕尺寸的設備,分別是智能音箱(7英寸)和智能電視(55英寸)。本期的主要研究問題包括:
1)有屏設備的指令上屏反饋體驗,主要指用戶輸入語音指令后,文本指令上屏的延遲時間以及文本指令在屏幕上呈現的合理時間;
2)有屏設備內容輸出的音量干擾體驗,主要指用戶在特定場景下(如聽音樂/看視頻),插入其它任務后(如查詢百科),不同內容輸出時的音量合理設置。

有屏設備的指令上屏體驗研究
與無屏設備相比,顯示屏的融入使語音交互過程有更豐富的反饋形式。以語音識別階段為例,在無屏設備上,用戶通常無法直接知道輸入指令的識別結果。而有屏設備直接在屏幕上顯示指令的識別結果,用戶可以方便的查看識別結果的正確或錯誤情況,例如上屏后的指令"我要聽周杰倫的青花瓷"。然而,目前很多設備在指令上屏時存在一定程度的延遲現象,本實驗對指令上屏合理的延遲時間和呈現時間進行研究。
1、指令上屏延遲時間實驗
由于市場上的有屏設備多數采用實時上屏方式,即用戶輸入語音指令的同時就開始在屏幕上呈現識別結果,因此,本實驗只研究實時上屏。在實驗中我們使用實時逐字上屏的方式,并以控制首字上屏延遲時間為主要變量(注:首字上屏延遲時間指從用戶開始說到第一個字上屏的時間間隔),我們設置了不同的首字延遲時間,以此獲取用戶對指令上屏速度的滿意度評價(5點量表:1-非常不滿意,2-比較不滿意,3-一般,4-比較滿意,5-非常滿意)。在實驗中,我們分別提供了3種不同長度的指令。
實驗結果表明,首字延遲時間越短,用戶的滿意度越高,不同屏幕尺寸設備的首字延遲時間滿意度略有差異,我們將"4-比較滿意"看做用戶滿意的得分下限,將"3-一般"看做用戶可接受的得分下限,不同設備間用戶滿意和可接受的上屏時間如下:
1)對于有屏音箱,用戶滿意的首字延遲時間下限在500ms左右,可接受的首字延遲時間下限在1500-1600ms左右;
2)對于智能電視,用戶滿意的首字延遲時間下限在600-700ms左右,可接受的首字延遲時間下限在1100-1200ms左右;
結合對市場上其它設備的研究發現,部分設備的首字上屏時間明顯比用戶滿意的時間下限長,少數甚至比可接受的下限還要長。關于指令上屏速度,產品仍有改善和優化的空間,即語音識別ASR(Automatic Speech Recognition)技術除了在不斷提升識別準確率以外,同時也需要關注識別速度指標的提升。
2、指令上屏呈現時間實驗
除了指令上屏時間,我們進一步對指令上屏后合理的呈現時間進行研究,以避免指令呈現時間太短導致用戶無法看清,或者呈現時間太長導致整個交互過程拖沓冗余。在實驗中,我們以文字呈現時間為主要變量(注:文字呈現時間指文本指令最后一個字上屏后到全部指令消失的時間間隔),獲取用戶對不同呈現時間的滿意度評價。由于語音識別涉及語言模型技術,實際的指令上屏并不是逐字的方式,因此,本部分實驗我們也模擬了逐塊上屏的方式,以指令"我想看劉德華2010年以前主演的香港電影"為例,"劉德華"被整體識別后才上屏。在實驗中,我們也分別提供了3種不同長度的指令。
實驗結果表明,存在最優的文字上屏呈現時間,不同屏幕尺寸設備之間,最優的文字上屏呈現時間無顯著差異。不同上屏方式間存在差異,逐字上屏和逐塊上屏的最優呈現時間分別如下:
1)逐字上屏方式下,最優的指令呈現時間為200-500ms的區間;
2)逐塊上屏方式下,最優的指令呈現時間為400-700ms的區間。
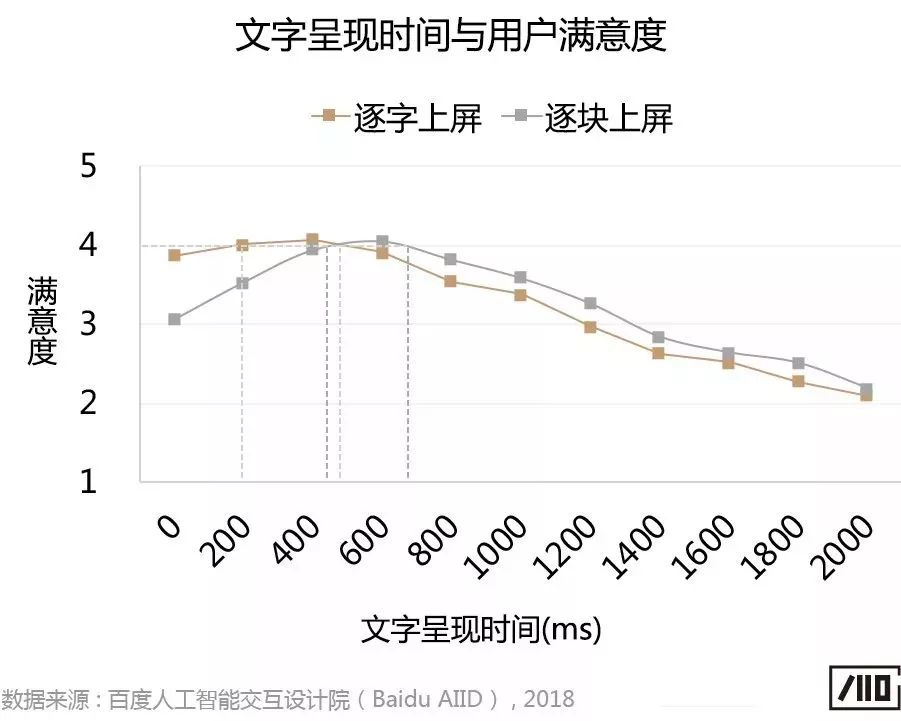
由于逐塊上屏方式更接近真實產品的上屏方式,因此建議主要參考400-700ms的呈現時間。需要說明的是,由于實時上屏的方式允許用戶在輸入語音指令過程中就可以查看已經上屏的文字,這與整體識別后上屏的方式明顯不同,因此,如果產品采用的是整體識別后上屏的方式,不建議參考本部分實驗的結論。
有屏設備的音量干擾體驗研究
有屏設備除了使語音交互有更豐富的反饋以外,屏幕的引入也擴展了設備過去不具備的功能,例如視頻內容消費和視頻通訊能力等。同時設備的使用也在經歷從過去單一任務到多個任務的變化,當看視頻時,你可以隨時插入任務查找信息,例如看電視劇《扶搖》時查詢演員楊冪的信息。本部分實驗主要研究用戶插入任務后,前景內容和背景內容間的音量干擾體驗,如當前景內容正在語音播報信息時,背景視頻或音樂的合理音量范圍,以避免過高的背景音對用戶獲取信息產生干擾。
1、音量干擾實驗
在實驗中,用戶被要求分別在看視頻和聽音樂兩種場景下進行信息查詢。我們設置了兩種初始音量(注:初始音量是用戶看視頻/聽音樂的音量):60和65分貝,用戶查詢人物或百科信息后,通過設置不同的背景音量(注:此時前景內容為語音播報信息,背景內容為視頻或音樂),獲取用戶對背景音量的滿意度評價。同時結合實驗后問卷了解用戶對前景和背景信息展示的態度。由于不同設備間音量刻度范圍存在差異,實驗中對有屏音箱和智能電視的背景音量進行了分別設置。
實驗結果發現,無論背景是視頻還是音樂,用戶都不喜歡背景完全靜音(注:下圖中"0"代表背景完全靜音)。針對有屏音箱和智能電視,當初始音量約為60分貝時,背景音量舒適范圍略有差異,具體結果如下:
1)針對有屏音箱,背景視頻音量下降至36-53分貝范圍,背景音樂音量下降至39-56分貝范圍時,用戶主觀感覺較舒適;
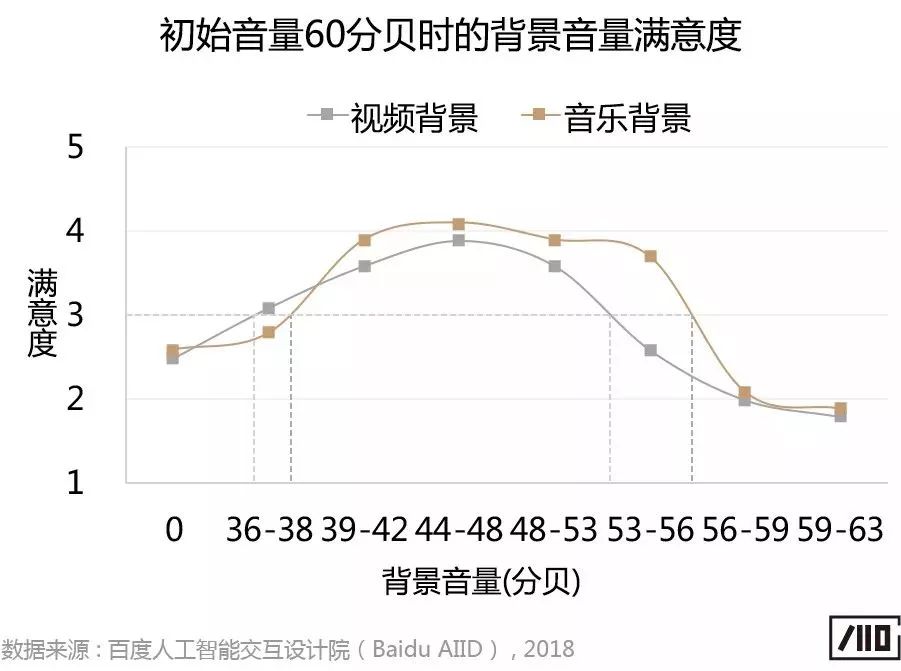
2)針對智能電視,背景視頻音量下降至39-53分貝范圍,背景音樂音量下降至36-53分貝范圍時,用戶主觀感覺較舒適。
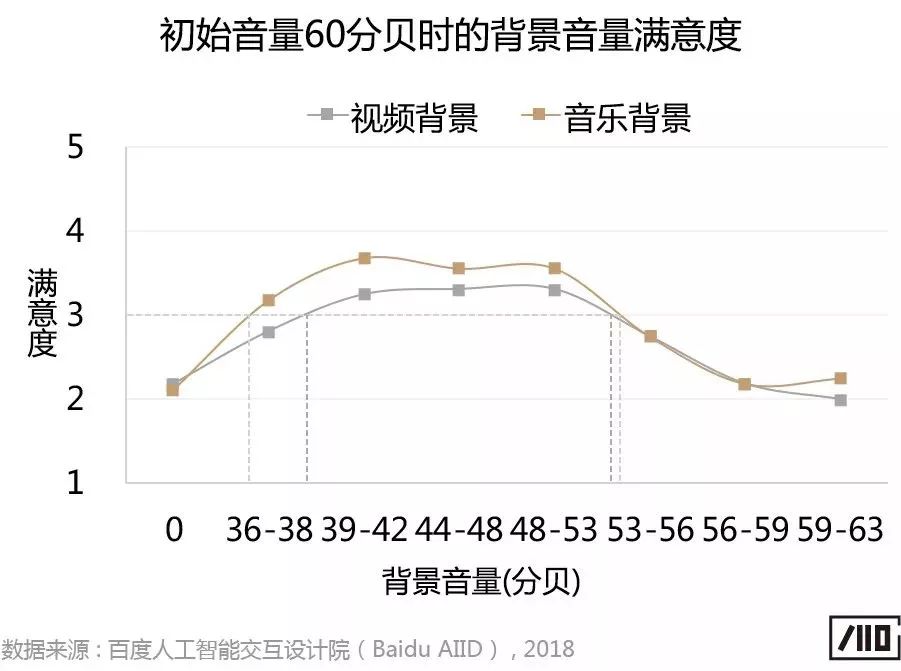
實驗中我們同時研究了初始音量為65分貝時背景音量的舒適范圍,因實驗結果與上述趨勢基本一致,篇幅所限,暫不一一展開。
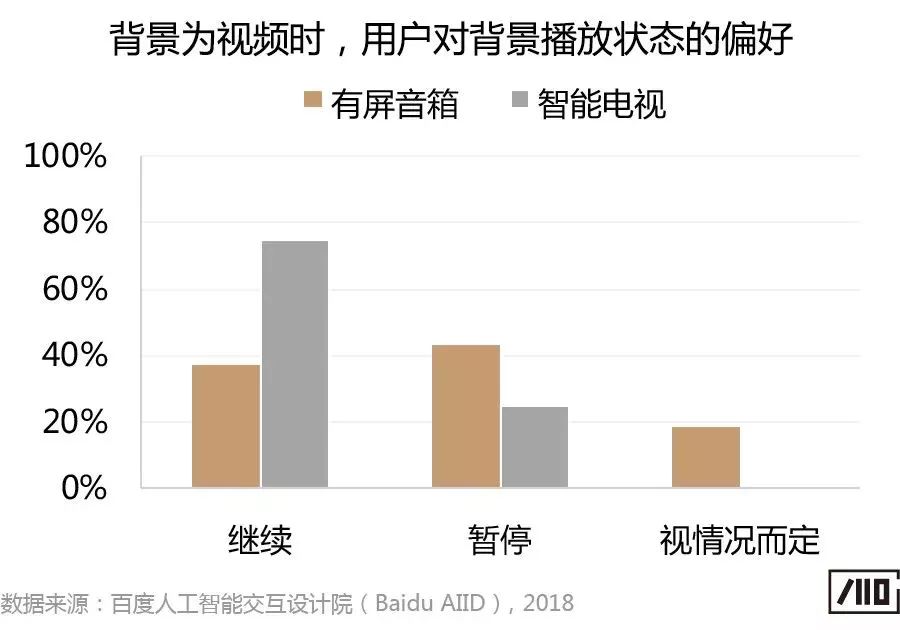
此外,結合實驗后的問卷調研結果發現,關于背景的播放狀態,背景為音樂時用戶更傾向繼續播放,而背景為視頻時有屏音箱端傾向視頻暫停的用戶更多。主要是由于有屏音箱端背景視頻被完全覆蓋,因此,用戶認為背景視頻暫停較好,以避免錯過感興趣的視頻內容。
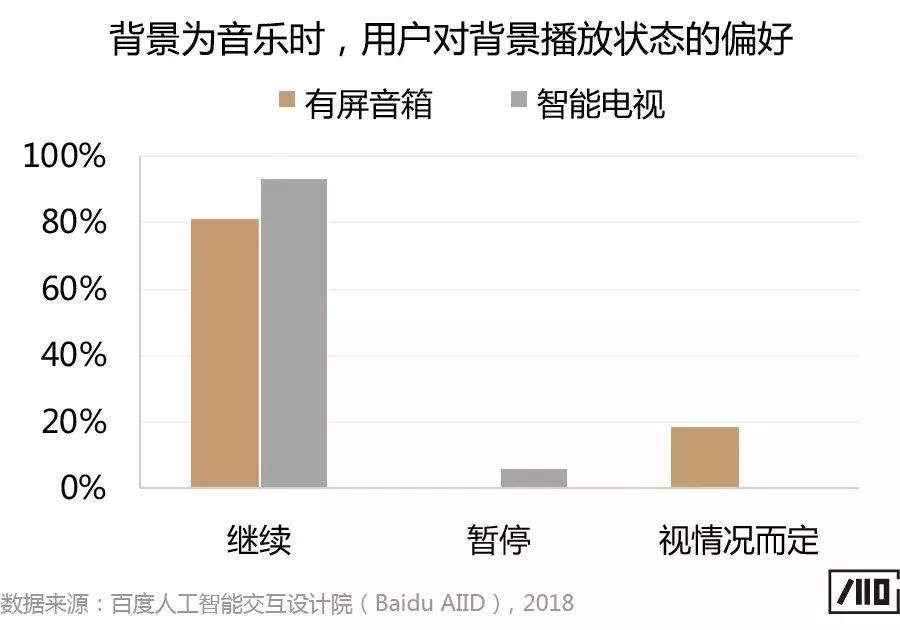
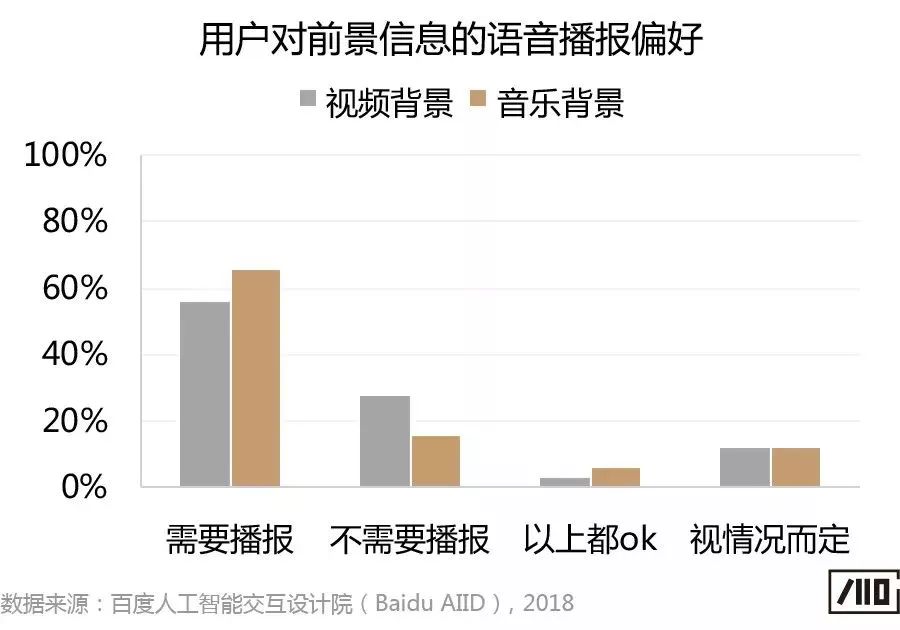
關于前景內容的播放狀態,無論屏幕尺寸差異和背景媒體類型,多數用戶希望能夠對前景信息進行語音播報,而不僅僅是在屏幕上以文字或圖文的形式展示。
本文針對有屏設備的語音交互體驗進行研究,重點探索整合視覺系統后交互反饋和內容輸出環節的體驗問題。對指令上屏的延遲時間和指令呈現時間給出了我們的研究結果和設計建議,以及不同內容輸出時前景和背景的合理音量設置等。
從語音向視覺的延伸,語音交互的邊界和外延仍將不斷變化。語音交互與傳統的交互方式并不是互斥的、非此即彼的關系,未來的人機交互將融入聽覺、視覺、觸覺、味覺、嗅覺等多模態的交互方式。未來的交互范式必然不是這些交互方式的簡單堆砌和羅列,而是在考慮特定場景、人的因素、環境條件等因素后有序的、合理的組合和設計。百度人工智能交互設計院也將會持續的關注多模態交互領域的研究和設計,并不斷輸出我們的研究成果和觀點。
-
AI
+關注
關注
88文章
34666瀏覽量
276589 -
智能電視
+關注
關注
9文章
1392瀏覽量
96573 -
語音交互
+關注
關注
3文章
305瀏覽量
28558 -
智能音箱
+關注
關注
31文章
1787瀏覽量
79643
原文標題:走向視聽融合的語音交互新體驗研究
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
芯資訊|廣州唯創電子WTK6900P語音識別芯片:離線語音交互的革新者

OBOO鷗柏丨AI數字人觸摸屏查詢觸控人臉識別語音交互一體機上市

芯資訊|廣州唯創電子WTV系列語音芯片:以技術創新賦能智能語音交互

智能座艙:車載語音交互測試內容

智能語音交互方案在客服領域的應用
WT3000T8-32N語音合成TTS芯片:小體積、強性能,重塑智能語音交互體驗

重慶大學:研究用于語音識別和交互的機器學習輔助可穿戴傳感系統
WTV380-8S語音芯片:智能清潔設備的“語音助手”,小體積大能量,重塑人機交互體驗

基于WTVxxx語音芯片的智能清潔機器人語音交互系統設計方案介紹

【智能語音交互新標桿】WTK6900HC語音識別芯片:重新定義離線語音控制體驗

RK3568國產處理器實驗平臺:語音識別控制實驗

【「嵌入式系統設計與實現」閱讀體驗】+ 基于語音識別的智能杯墊
基于智能語音交互的智能呼叫中心工作機制






 工商網監
工商網監
評論