") 學(xué)會使用頂級算法的秘訣是什么?如何找到合適的學(xué)習(xí)率?
學(xué)會使用頂級算法的秘訣是什么?如何找到合適的學(xué)習(xí)率?
編者按:此前,論智曾寫過一篇Kaggle競賽方案分享:如何分辨雜草和植物幼苗,介紹了當(dāng)時排名第五的開發(fā)者Kumar Shridhar的實戰(zhàn)思路。同樣是這個競賽,自參賽起,fast.ai聯(lián)合創(chuàng)始人Jeremy Howard的名次卻經(jīng)歷連連暴跌,最后止步第105名。那么這位明星數(shù)據(jù)科學(xué)家究竟遭遇了何方狙擊?沒錯,就是他自己的學(xué)生,而這些新手最后也成功霸榜Kaggle。
當(dāng)我離開你時,我只是求學(xué)者,但現(xiàn)在,我才是王者
隨著互聯(lián)網(wǎng)和知識傳播的深度結(jié)合,現(xiàn)在在線課程對許多人來說已經(jīng)不是新鮮事物,在深度學(xué)習(xí)領(lǐng)域,最受學(xué)生歡迎的MOOC課程平臺有三個:Fast.ai、deeplearning.ai /Coursera和Udacity。其中,因為Jeremy Howard化繁為簡、實戰(zhàn)為上的獨特授課風(fēng)格,F(xiàn)ast.ai給人的印象一直很“接地氣”,而植物幼苗分類賽的結(jié)果也證實了課程的教學(xué)效果。
那么這些新手在短短幾周內(nèi)就學(xué)會使用頂級算法的秘訣是什么?是什么讓他們能在競賽中擊敗擁有大量GPU的資深深度學(xué)習(xí)專家?下文是你想知道的所有答案。
如果你已經(jīng)上手深度學(xué)習(xí),并希望快速了解Fast.ai課程中使用的強大技術(shù),請繼續(xù)閱讀。 如果你已經(jīng)完成Fast.ai課程,并希望回顧所學(xué)內(nèi)容,請繼續(xù)閱讀。 如果你正準(zhǔn)備入門深度學(xué)習(xí),并希望了解Fast.ai對初學(xué)者的幫助和這個行業(yè)的未來發(fā)展,請繼續(xù)閱讀。
首先,在正式開始前,我們都應(yīng)該知道,如果要有效學(xué)習(xí)Fast.ai的課程內(nèi)容,云GPU必不可少。這里我們先介紹一個好用的工具——FloydHub,對于初學(xué)者來說,這是訓(xùn)練深度學(xué)習(xí)模型最好的、也是最簡單的方法。法國的Ecole 42非常喜愛這個工具,我們也可以借此為接觸更多有趣實現(xiàn)做準(zhǔn)備,如:
如何用100行神經(jīng)網(wǎng)絡(luò)代碼為黑白圖片著色
如何用深度學(xué)習(xí)做“前端”:基于設(shè)計模型圖片生成HTML和CSS代碼
下面,讓我們正式開始!
1. 使用Fast.ai庫
from fast.ai import *
Fast.ai庫不僅是讓新手快速構(gòu)建深度學(xué)習(xí)實現(xiàn)的工具包,它也是提供最佳實踐的一個強大而便捷的資源。每當(dāng)Fast.ai團(tuán)隊(包括AI研究人員和合作者網(wǎng)絡(luò))發(fā)現(xiàn)一篇特別有趣的論文,他們就會在各種數(shù)據(jù)集上測試,然后找出調(diào)整優(yōu)化方法。如果這些成果確實是有效的,它們會陸續(xù)出現(xiàn)在庫中,以便用戶快速接觸新技術(shù)。
這樣做的結(jié)果是Fast.ai庫現(xiàn)在已經(jīng)成為一個功能強大的工具箱,比如去年學(xué)界公認(rèn)的深度學(xué)習(xí)年度進(jìn)展:SGDR、循環(huán)學(xué)習(xí),現(xiàn)在所有Fast.ai用戶都可以快速訪問,并把它們用于自己的實現(xiàn)。
這個庫基于PyTorch構(gòu)建,使用流暢,用戶體驗很好。
2. 使用多個學(xué)習(xí)率,而不是一個
使用不同的學(xué)習(xí)率意味著在訓(xùn)練期間,神經(jīng)網(wǎng)絡(luò)前幾層的變化比后幾層更多。在計算機視覺任務(wù)中,現(xiàn)在通行的一種做法是直接在現(xiàn)有架構(gòu)上構(gòu)建深度學(xué)習(xí)模型,實踐證明這樣做模型的性能更好。
而大多數(shù)架構(gòu),如Resnet、VGG、inception等都是在ImageNet上經(jīng)過預(yù)訓(xùn)練的,如果要使用它們,我們必須考量手頭數(shù)據(jù)集和ImageNet圖像的相似程度,并以此對權(quán)重做或多或少的調(diào)整。在修改權(quán)重時,模型的最后幾層調(diào)整幅度更大,而用于檢測基礎(chǔ)特征的層(比如邊緣和輪廓)則只需極少調(diào)整。
下面是一些代碼示例,首先,我們從Fast.ai庫里獲得預(yù)訓(xùn)練模型:
from fastai.conv_learner import *
# 導(dǎo)入用于創(chuàng)建卷積學(xué)習(xí)對象的庫 #選擇VVG16
# 將模型分配給resnet、vgg,甚至是你自己的自定義模型
PATH = './folder_containing_images'
data = ImageClassifierData.from_paths(PATH)
# 創(chuàng)建fast ai數(shù)據(jù)對象,這里我們用from_paths
# 其中PATH將每個圖像類分成不同的文件夾
learn = ConvLearner.pretrained(model, data, precompute=True)
# 創(chuàng)建一個學(xué)習(xí)對象,以便快速調(diào)用Fast.ai庫里的state of art算法
通過創(chuàng)建好的學(xué)習(xí)對象,我們可以凍結(jié)最后一層以前的所有層,單獨調(diào)整最后一層的參數(shù):
learn.freeze()
# 凍結(jié)最后一層之前的所有層,保持它們的參數(shù)不變
learning_rate = 0.1
learn.fit(learning_rate, epochs=3)
# 只訓(xùn)練最后一層幾個epoch
如果調(diào)參結(jié)果不錯,我們就可以在不同層使用不同的學(xué)習(xí)率,比如中間幾層參數(shù)變化幅度沒最后幾層那么大,所以它的學(xué)習(xí)率可以是后者的1/10。
learn.unfreeze()
# 將所有圖層的requires_grads設(shè)置為True,以便進(jìn)行更新
learning_rate = [0.001, 0.01, 0.1]
# first layer的學(xué)習(xí)率是0.001,middle layer的是0.01,final layer則是0.1.
learn.fit(learning_rate, epochs=3)
# 用不同學(xué)習(xí)率訓(xùn)練模型三個epoch
3. 如何找到合適的學(xué)習(xí)率
學(xué)習(xí)率是訓(xùn)練神經(jīng)網(wǎng)絡(luò)最重要的一個超參數(shù),但直到最近,許多人才發(fā)現(xiàn)以前設(shè)置學(xué)習(xí)率的方式非常不當(dāng)。去年,Leslie N. Smith在arXiv上提交了一個預(yù)印本:Cyclical Learning Rates for Training Neural Networks。他在文中提出一種確定學(xué)習(xí)率的新方法:循環(huán)學(xué)習(xí)率,即不使用固定值,而是用一個在合理閾值內(nèi)循環(huán)變化的數(shù)值,實驗證明它可以減少迭代次數(shù),提高模型分類準(zhǔn)確率。文章一經(jīng)發(fā)布,F(xiàn)ast.ai就立馬推廣了這種方法。
對于這種方法,我們可以從一個較低的學(xué)習(xí)率開始訓(xùn)練神經(jīng)網(wǎng)絡(luò),然后隨著迭代進(jìn)行,逐漸對學(xué)習(xí)率做指數(shù)增加。以下是示例代碼:
learn.lr_find()
# 隨著學(xué)習(xí)率呈指數(shù)增長,訓(xùn)練學(xué)習(xí)對象
learn.sched.plot_lr()
# 繪制學(xué)習(xí)率和迭代的進(jìn)展圖
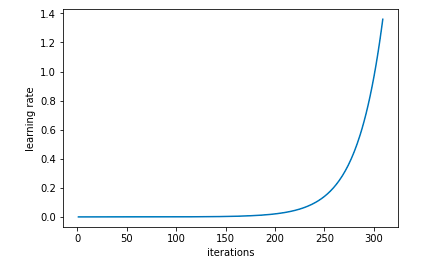
學(xué)習(xí)率隨迭代呈指數(shù)上升
同時,記錄不同學(xué)習(xí)率時每個值的損失,并繪制相關(guān)圖像:
learn.sched.plot()
# 學(xué)習(xí)率和損失的關(guān)系圖
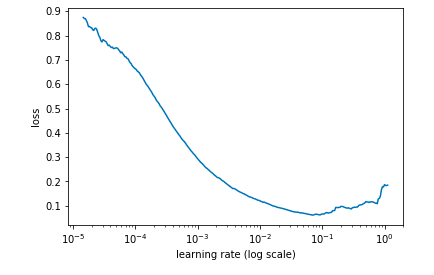
損失一直在減少,還沒有穩(wěn)定
在上圖情況下,我們可以確定的最佳學(xué)習(xí)率是0.01。
4. 余弦退火
隨著每個batch隨機梯度下降(SGD)的進(jìn)行,神經(jīng)網(wǎng)絡(luò)的損失會逐漸接近全局最小值,相應(yīng)的,學(xué)習(xí)率也應(yīng)該變得更小,防止算法超調(diào)。余弦退火是一種將學(xué)習(xí)率設(shè)置為隨模型迭代輪數(shù)不斷改變的方法,因為更新學(xué)習(xí)率用的是cos(),所以稱余弦。如下圖所示:
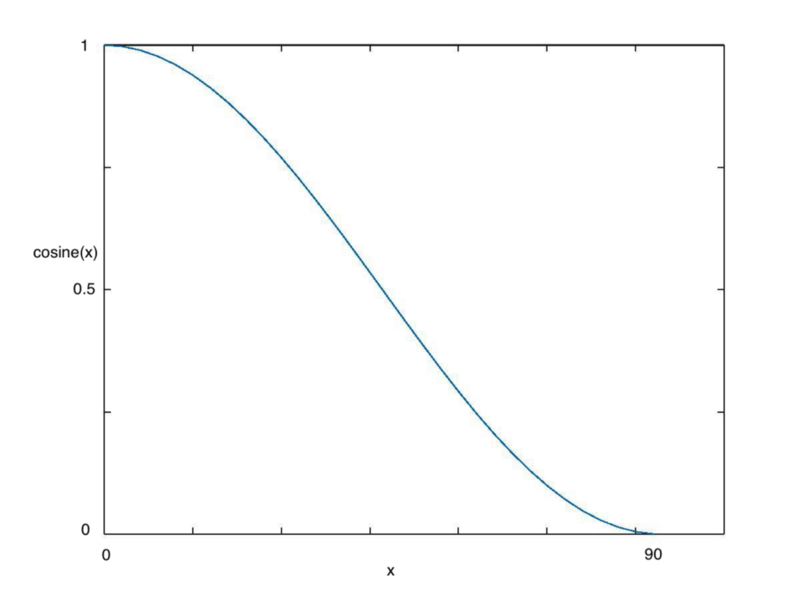
隨著x增加,cos(x)會不斷縮小
當(dāng)我們不斷增加x時,cos(x)的變化是一個先緩慢后急劇再緩慢的過程,這種下降趨勢十分符合學(xué)習(xí)率,因此也可以提高模型性能。
learn.fit(0.1, 1)
# 在Fast.ai庫中調(diào)用learn.fit函數(shù)可以直接使用余弦退火
5. SGDR
在訓(xùn)練期間,梯度下降可能會陷入局部最小值而不是全局最小值。

梯度下降可能會陷入局部最小值
這時,通過突然提高學(xué)習(xí)率,梯度下降可以“跳出”局部最小值,重新回歸尋找全局最小值的正軌。這種方法被稱為熱重啟隨機梯度下降(SGDR),它首次出現(xiàn)在德國弗萊堡大學(xué)的論文SGDR: Stochastic Grandient Descent with warm Restarted中,這也是ICLR 2017的重磅成果。
現(xiàn)在,SGDR已經(jīng)加入Fast.ai庫,當(dāng)用戶調(diào)用learn.fit(learning_rate, epochs)時,每個epoch的學(xué)習(xí)率會被重新設(shè)置成原始超參數(shù),然后在用余弦退火逐漸縮小。
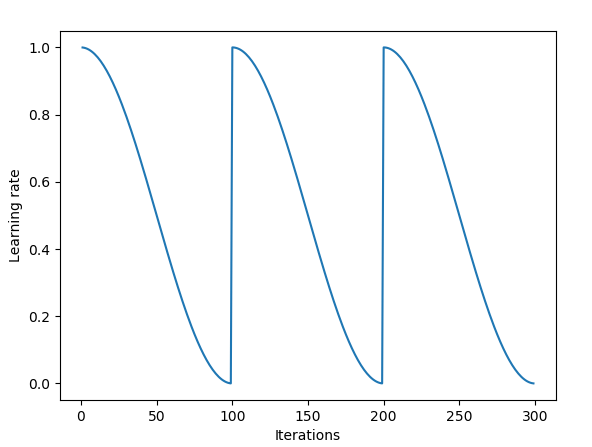
每個epoch的學(xué)習(xí)率回歸原始值
每次學(xué)習(xí)率下降到最低點,我們就稱之為一個循環(huán)。
cycle_len = 1
# 決定學(xué)習(xí)率降到最低要幾個epoch
# 在這種情況下,1個epoch
cycle_mult=2
# 在每個循環(huán)結(jié)束時,將cycle_len值乘以2
learn.fit(0.1, 3, cycle_len=2, cycle_mult=2)
# 在這種情況下,將重啟3次
# 第一次的cycle_len為1,所以我們用1個epoch完成循環(huán)
# cycle_mult=2,所以下個循環(huán)是2個epoch
# 然后是4個epoch,以此類推

每個循環(huán)所需epoch是上個循環(huán)的兩倍
使用這種方法可以幫助開發(fā)者在圖像分類問題中占據(jù)先機。
6. 把激活函數(shù)想象成人
Softmax是一個專一的家伙,只喜歡挑選一個目標(biāo);Sigmoid只想知道你在-1和1之間的位置,如果超出了閾值,他才不管你的死活;Relu是一名稱職的夜店門衛(wèi),如果顏值為負(fù),你就別想過這道門。
以上述方式看待激活函數(shù)縱然有點蠢,但至少它區(qū)分了三種函數(shù)的不同,可以有效防止誤用。Jeremy Howard曾表示,他在許多學(xué)術(shù)論文中都看到過把Softmax用于多元分類,而文章、博客中的激活函數(shù)濫用更不鮮見。
7. 遷移學(xué)習(xí)對NLP任務(wù)非常有用
眾所周知,遷移學(xué)習(xí)在計算機視覺中的效果非常出色,而隨著研究人員的不斷探索,如今越來越多線索開始指向另一個現(xiàn)實:自然語言處理(NLP)模型同樣能從遷移學(xué)習(xí)中收益頗多。
在fast.ai的第4課中,Jeremy Howard構(gòu)建了一個用于分類IMDB電影評論消極與否的模型,他把遷移學(xué)習(xí)思想引入模型,發(fā)現(xiàn)模型的準(zhǔn)確率遠(yuǎn)超Bradbury等人的最先進(jìn)成果,效果立竿見影。
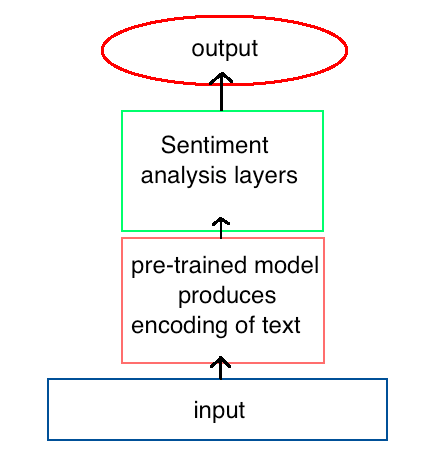
他加入了一個預(yù)訓(xùn)練模型
而這個做法的成功秘訣是先訓(xùn)練一個模型,讓它對語言產(chǎn)生基礎(chǔ)理解,然后再把這個預(yù)訓(xùn)練模型作為模型的一部分用于情感分析。為了構(gòu)建這第一個模型,我們需要讓RNN學(xué)會預(yù)測文本序列中的下一個詞,也就是語言建模。一旦模型訓(xùn)練完畢,性能很好,第二個新模型就能利用它對每個次的編碼分析影評是積極的還是消極的。
雖然課程示例是個情感分析模型,但我們也可以把它用到其他NLP和計算機視覺任務(wù)中。
8. 用深度學(xué)習(xí)處理結(jié)構(gòu)化數(shù)據(jù)
在介紹機器學(xué)習(xí)和深度學(xué)習(xí)優(yōu)勢時,我們一般會夸它們可以處理非結(jié)構(gòu)化數(shù)據(jù),認(rèn)為這是統(tǒng)計學(xué)無法做到的,但Fast.ai反其道而行之,他們用深度學(xué)習(xí)實現(xiàn)了在結(jié)構(gòu)化數(shù)據(jù)上快速生成出色結(jié)果,而無需借助特征工程和應(yīng)用領(lǐng)域的特定知識。
他們的庫充分利用了PyTorch的嵌入功能,允許將分類變量快速轉(zhuǎn)換為嵌入矩陣。當(dāng)然,課程中展示的技術(shù)相對較簡單,只是將分類變量轉(zhuǎn)換為數(shù)字,然后為每個值分配嵌入向量:
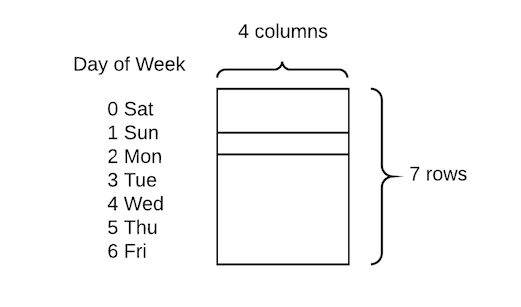
為一周中的每一天嵌入4個值
與創(chuàng)建虛擬變量(one-hot編碼)的傳統(tǒng)方法相比,這樣做的好處是對于每一天,我們可以用4個值代替一個值,從而創(chuàng)建維度更高、更豐富的矩陣。
9. 競賽致勝關(guān)鍵:擴大圖像尺寸、Dropout和TTA
4月30日,在斯坦福大學(xué)舉辦的DAWNBench中,fast.ai團(tuán)隊一舉贏得Imagenet和CIFAR10分類競賽,之后Jeremy Howard寫了一篇獲勝感言,他把競賽結(jié)果歸功于fast.ai庫中的一些獨特工具。
兩年前Geoffrey Hinton提出的Dropout是其中之一。盡管論文發(fā)布之初,學(xué)界對這個概念十分追捧,但它在計算機視覺領(lǐng)域卻一直不受重視。幸好,現(xiàn)在有了PyTorch,如果我們用PyTorch實現(xiàn)Dropout,它會變得異常簡單,而如果用了fast.ai庫,整個過程就更簡單了。
空格表示Dropout函數(shù)激活的區(qū)域
Dropout可以很好地防止模型過擬合,這對于在CIFAR10這樣的小型數(shù)據(jù)集上構(gòu)建分類器是非常重要的。在創(chuàng)建學(xué)習(xí)對象時,fast.ai會自動執(zhí)行Dropout,但它可以自定義修改:
learn = ConvLearner.pretrained(model, data, ps=0.5, precompute=True)
# 在測試集上創(chuàng)建0.5的Dropout(激活的一半)
# 驗證集會自動關(guān)閉此功能
除此之外,他們采用的另一種方法是先在較小的圖像上訓(xùn)練,然后擴大圖像尺寸,在用相同的模型在上面訓(xùn)練。這樣做可以有效防止過擬合,同時提高模型性能。
# create a data object with images of sz * sz pixels
def get_data(sz):
tmfs = tfms_from_model(model, sz)
# tells what size images should be, additional transformations such
# image flips and zooms can easily be added here too
data = ImageClassifierData.from_paths(PATH, tfms=tfms)
# creates fastai data object of create size
return data
learn.set_data(get_data(299))
# changes the data in the learn object to be images of size 299
# without changing the model.
learn.fit(0.1, 3)
# train for a few epochs on larger versions of images, avoiding overfitting
最后一種方法則是測試時數(shù)據(jù)增強(TTA),也就是把測試集里的原始圖像做裁剪、縮放,轉(zhuǎn)換成一系列不同的圖像,然后用于圖像測試。這之后,我們計算不同版本的平均輸出,并將其作為圖像的最終分?jǐn)?shù),這可以通過調(diào)用learn.TTA()直接實現(xiàn):
preds, target = learn.TTA()
10. 創(chuàng)造力是關(guān)鍵
fast.ai團(tuán)隊不僅在DAWNBench競賽中贏得了訓(xùn)練速度最快獎(3小時),也把成本壓縮到25美元,堪稱奇跡。這里我們可以學(xué)到的經(jīng)驗是,創(chuàng)建一個成功的深度學(xué)習(xí)模型并不意味著投入更多GPU,創(chuàng)造力、想法和創(chuàng)新可以為我們打開另一扇窗。
本文提到的大多數(shù)學(xué)術(shù)突破也是創(chuàng)造力的一個佐證,當(dāng)別人用千篇一律的做法解決問題時,這些學(xué)者想到了不同的方法,而且這些創(chuàng)新確實有效。雖然硅谷的大公司擁有海量GPU,這是常人不敢奢望的,但我們要勇于發(fā)起挑戰(zhàn),創(chuàng)造出屬于自己的特殊的、新的東西。
有時候,現(xiàn)實的擠壓也是一種機遇,畢竟必要性是成功之母。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4795瀏覽量
102147 -
算法
+關(guān)注
關(guān)注
23文章
4677瀏覽量
94271 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5542瀏覽量
122265
原文標(biāo)題:從fast.ai學(xué)到的十大技巧:如何在幾周內(nèi)上手頂級算法
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
機器學(xué)習(xí)算法概念介紹及選用建議

Protel制版教程 【讓新手立刻學(xué)會使用】 ppt 相當(dāng)詳細(xì)
錯誤:無法找到核心的頂級HDL源文件:vdma
學(xué)會使用A4988驅(qū)動電機有什么幫助
如何幫你的回歸問題選擇最合適的機器學(xué)習(xí)算法
機器學(xué)習(xí)和深度學(xué)習(xí)算法流程
17個機器學(xué)習(xí)的常用算法
機器學(xué)習(xí)有哪些算法?機器學(xué)習(xí)分類算法有哪些?機器學(xué)習(xí)預(yù)判有哪些算法?
一步一步學(xué)會使用Channel Analysis






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論