 常識知識有助于開放域對話系統中語言的理解與生成
常識知識有助于開放域對話系統中語言的理解與生成

▌AI 科技大本營按:2018 年 7月 13 日——19 日,ICJAI 2018 在瑞典首都斯德哥爾摩順利召開。IJCAI(International Joint Conference on Artificial Intelligence)人工智能領域頂級學術會議之一,涵蓋領域包括機器學習、圖像識別、語音技術、自然語言處理、視頻技術等,對全球人工智能行業有著巨大的影響力。
IJCAI 的評審歷來都很嚴格,今年投稿數量更是達到了 3470 篇,接收論文 710 篇,接收率只有 20.5%(同比 2017 年, 2540 篇投稿,接收 660 篇,約26%的接收率);而來自國內的論文更是近達半數之多,可見國內研究的活躍。與往年不同,今年 IJCAI 沒有評選出 Best Paper,但是選出了 7 篇 Distinguished Paper ,其中有 4 篇都是來自國內的研究成果。
今天 AI 科技大本營為大家采訪到了本次 IJCAI 大會 Distinguished Paper 《Commonsense Knowledge Aware Conversation Generation with Graph Attention》(具有圖注意力的常識知識感知會話生成系統)的第一作者——來自清華大學的博士研究生周昊,和大家分享其中更多的故事。
其實在去年,周昊和所在的課題組就有一項研究成果——Emotional Chatting Machine(情緒聊天機)獲得了國內外的高度關注,MIT 科技評論、衛報和 NIVIDIA 就相繼進行了追蹤和報道。

(來源于 MIT Technology Review)

(此節選部分內容來源于 MIT Technology Review)
計算機無法衡量對話內容的情感,對話人的情緒,也就無法和人進行共情。而一個沒有情商的聊天機器人反而會成為一個話題終結者。周昊和他所在的課題組就開發了一個能夠評估對話內容情感并作出相應回應的聊天機器人,這項工作打開了通往具有情感意識的新一代聊天機器人的大門。

他們在研究中所提出的情緒聊天機(ECM),不僅可以在內容上給出適當的反應,而且能在情感上給出適當的反應(情緒一致)。這項工作已經在 TensorFlow 中實現.

摘要
常識知識對于自然語言處理來說至關重要。在本文中,我們提出了一種新的開放域對話的生成模型,以此來展現大規模的常識知識庫是如何提升語言理解與生成的。若輸入一個問題,模型會從知識庫中檢索相關的知識圖,然后基于靜態圖注意力機制對其進行編碼,圖注意力機制有助于提升語義信息,從而幫助系統更好地理解問題。接下來,在語句的生成過程中,模型會逐個讀取檢索到的知識圖以及每個圖中的知識三元組,并通過動態的圖注意力機制來優化語句的生成。我們首次嘗試了在對話生成中使用大規模的常識知識庫。此外,現有的模型都是將知識三元組分開使用的,而我們的模型將每個知識圖作為完整的個體,從而獲得結構更清晰,語義也更連貫的編碼信息。實驗顯示,與當前的最高水平相比,我們提出的模型所生成的對話更為合理,信息量也更大。
簡介
在許多自然語言處理工作中,尤其在處理常識知識和客觀現象時,語義的理解顯得尤為重要,毋庸置疑,它是一個成功的對話系統的關鍵要素,因為對話互動是一個基于“語義”的過程。在開放域對話系統中,常識知識對于建立有效的互動是很重要的,這是因為社會共享的常識知識是大眾樂于了解并在談話中使用的信息。
最近,在對話生成方面有很多神經模型被提出。但這些模型往往給出比較籠統的回復,大多數情況下,無法生成合適且信息豐富的答案,因為若不對用戶的輸入信息、背景知識和對話內容進行深度理解,是很難從對話數據中獲取語義交互信息的。當一個模型能夠連接并充分利用大規模的常識知識庫,它才能更好地理解對話內容,并給出更合理的回復。舉個例子,假如模型要理解這樣一對語句,“Don’t order drinks at the restaurant , ask for free water”和“Not in Germany. Water cost more than beer. Bring your own water bottle”,我們需要的常識知識可以包括(water,AtLocation,restaurant),(free, RelatedTo, cost)等。
在此之前,有些研究已經在對話生成中引入了外部知識。這些模型所用到的知識是非結構化的文本或特定領域的知識三元組,但存在兩個問題,第一,它們高度依賴非結構化文本的質量,受限于小規模的、領域特定的知識庫。第二,它們通常將知識三元組分開使用,而不是將其作為每個圖的完整個體。因此,這類模型不能基于互相關聯的實體和它們之間的關系來給出圖的語義信息。
為解決這兩個問題,我們提出了常識知識感知對話模型(Commonsense Knowledge Aware Conversational Model, CCM),以優化語言理解和開放域對話系統的對話生成。我們使用大規模的常識知識來幫助理解問題的背景信息,從而基于此類知識來優化生成的答案。該模型為每個提出的問題檢索相應的知識圖,然后基于這些圖給出富有信息量又合適的回復,如圖1所示。為了優化圖檢索的過程,我們設計了兩種新的圖注意力機制。靜態圖注意力機制對檢索到的圖進行編碼,來提升問題的語義,幫助系統充分理解問題。動態圖注意機制會讀取每個知識圖及其中的三元組,然后利用圖和三元組的語義信息來生成更合理的回復。
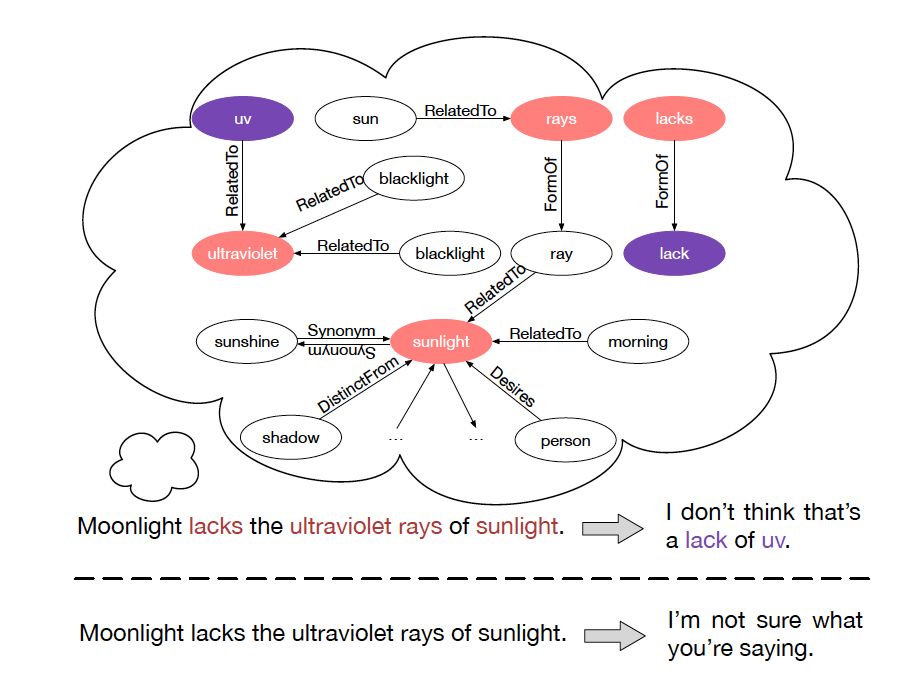
圖 1:兩種模型的對比。第一行回復由我們的模型(引入常識知識)生成,
第二行回復由 Seq2Seq 模型(未引入常識知識)生成。
總地來說,本文主要做出了以下突破:
該項目是首次在對話生成神經系統中,嘗試使用大規模常識知識。有了這些知識的支撐,我們的模型能夠更好地理解對話,從而給出更合適、信息量更大的回復。
代替過去將知識三元組分開使用的方法,我們設計了靜態和動態圖注意力機制,把知識三元組看作一個圖,基于與其相鄰實體和它們之間的關系,我們可以更好地解讀所研究實體的語義。
常識對話模型
▌2.1 背景:Encoder - Decoder 模型
首先,我們介紹一下基于 seq2seq 的 Encoder-Decoder 模型。編碼器表示一個問題序列
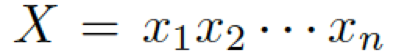
,其隱藏層可表示為 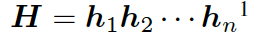 ,可以簡單寫作如下形式:
,可以簡單寫作如下形式:
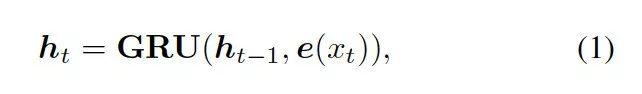
這里的 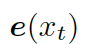 是
是 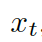 的詞嵌入結果,GRU (Gated Recurrent Unit) 是門控循環單元。
的詞嵌入結果,GRU (Gated Recurrent Unit) 是門控循環單元。
解碼器將上下文向量 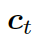 和
和 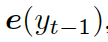 的詞嵌入結果作為輸入,同時使用另一個 GRU(門控循環單元)來更新其狀態
的詞嵌入結果作為輸入,同時使用另一個 GRU(門控循環單元)來更新其狀態 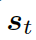 :
:
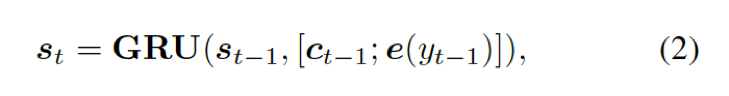
這里的
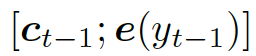
結合兩個向量,共同作為 GRU 網絡的輸入。上下文向量 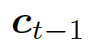 是?H?的詞嵌入結果,也就是編碼器隱藏狀態的權重和:
是?H?的詞嵌入結果,也就是編碼器隱藏狀態的權重和:
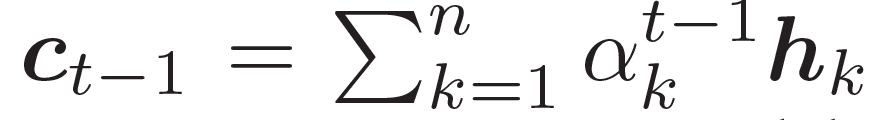
, 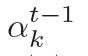 估量了狀態
估量了狀態 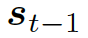 和隱藏狀態
和隱藏狀態 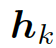 中間的相關度。
中間的相關度。
從輸出的可能性分布中抽取樣本,解碼器會產生一個 token,可能性的計算如下:
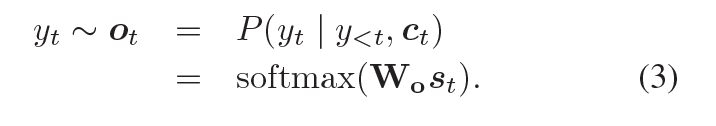
此處
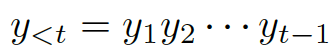
,這些詞便生成了。
譯者注:Seq2Seq 模型與經典模型有所不同的是,經典的 N vs N 循環神經網絡要求序列要等長,但我們在做對話生成時,問題和回復長度往往不同。因此 Encoder-Decoder 結構通過 Encoder 將輸入數據編碼成一個上下文向量,再通過 Decoder 對這個上下文向量進行解碼,這里的 Encoder 和 Decoder 都是 RNN 網絡實現的。
▌2.2 任務定義與概述
我們的問題描述如下:給定一個問題
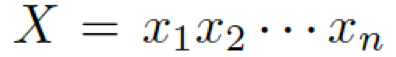
和一些常識知識的圖 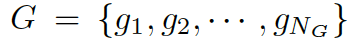 ,目標是生成合理的回復
,目標是生成合理的回復
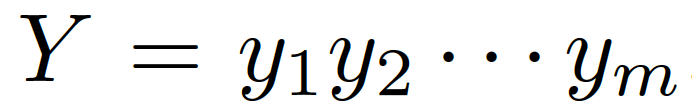
。本質上來看,該模型估計了概率:
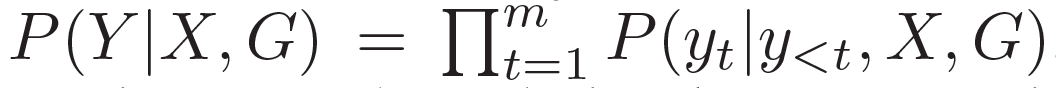
。基于問題從知識庫中檢索圖,每個單詞對應G中的一個圖。每個圖包含一個三元組的集合
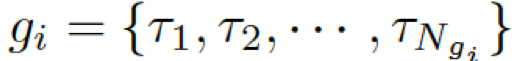
,每個三元組(頭實體、關系、尾實體)可表示為
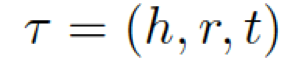
。
為了把知識庫與非結構化的對話本文相關聯,我們采用了 MLP 模型:一個知識三元組 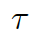 可以表示為k= (h,?r,?t) =?MLP(TransE(h,r,?t)),這里的h?/?r?/?t?是經過 TransE 模型分別轉化處理過的?h / r / t.
可以表示為k= (h,?r,?t) =?MLP(TransE(h,r,?t)),這里的h?/?r?/?t?是經過 TransE 模型分別轉化處理過的?h / r / t.
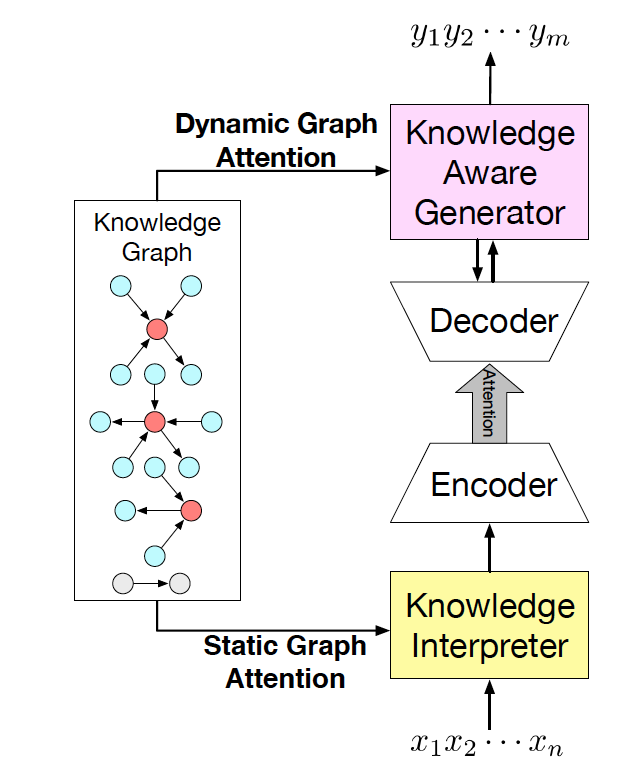
圖 2:CCM 結構圖
我們的常識對話模型(Commonsense Conversational Model, CCM)的概覽如圖 2 所示。知識解析器 (Knowledge Interpreter) 將問題
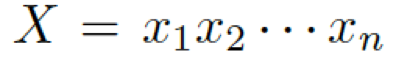
和檢索得到的知識圖 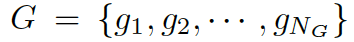 作為輸入,通過把單詞向量和與其對應的知識圖向量相結合,來獲得對每個單詞的知識感知。通過靜態圖注意力機制,知識圖向量包含了問題?X中對應每個單詞的知識圖。基于我們的動態圖注意力機制,知識感知生成器 (Knowledge Aware Generator) 生成了回復
作為輸入,通過把單詞向量和與其對應的知識圖向量相結合,來獲得對每個單詞的知識感知。通過靜態圖注意力機制,知識圖向量包含了問題?X中對應每個單詞的知識圖。基于我們的動態圖注意力機制,知識感知生成器 (Knowledge Aware Generator) 生成了回復 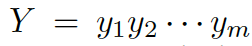 。在每個解碼環節,它讀取檢索到的圖和每個圖中的實體,然后在詞匯表中生成通用詞匯,或在知識圖中生成實體。
。在每個解碼環節,它讀取檢索到的圖和每個圖中的實體,然后在詞匯表中生成通用詞匯,或在知識圖中生成實體。
▌2.3 知識解析器
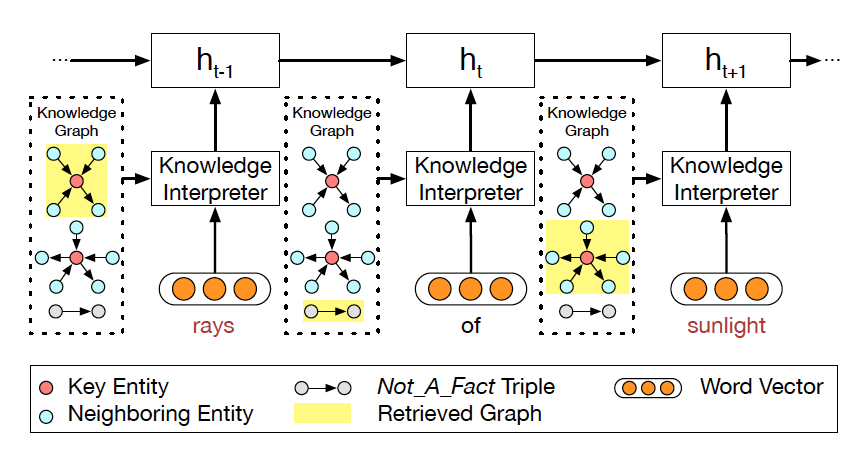
圖 3:知識解析器把單詞向量和圖向量相結合。
在該例子中,單詞 rays 對應第一個圖,sunlight 對應第二個圖。
每個圖都用圖向量表示。關鍵實體 (Key Entity) 表示當前問題中的實體。
知識解析器 (Knowledge Interpreter) 旨在優化問題理解這一環節。它通過引入每個單詞對應的圖向量,來增強單詞的語義,如圖 3 所示。知識解析器把問題中的每個單詞 xt 作為關鍵實體,從整個常識知識庫中檢索圖
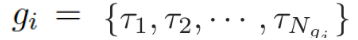 (圖中黃色部分)。每個檢索到的圖包含一個關鍵實體(圖中紅色圓點),與其相鄰的實體(圖中藍色圓點)以及實體之間的關系。對一些常用詞匯(如:of)來說,常識知識圖中沒有與其匹配的圖,這類詞匯用一個帶有特殊標志 Not_A_Fact(圖中灰色圓點)的圖來表示。接下來,知識解析器會基于靜態圖注意力機制,來計算檢索到的圖的圖向量
(圖中黃色部分)。每個檢索到的圖包含一個關鍵實體(圖中紅色圓點),與其相鄰的實體(圖中藍色圓點)以及實體之間的關系。對一些常用詞匯(如:of)來說,常識知識圖中沒有與其匹配的圖,這類詞匯用一個帶有特殊標志 Not_A_Fact(圖中灰色圓點)的圖來表示。接下來,知識解析器會基于靜態圖注意力機制,來計算檢索到的圖的圖向量  。把單詞向量
。把單詞向量 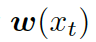 和知識圖向量
和知識圖向量 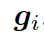 相結合,就得到了向量
相結合,就得到了向量
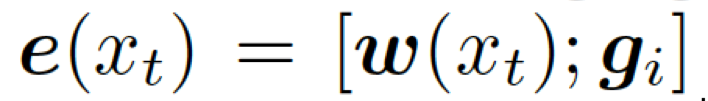
,然后把它喂給編碼器中的 GRU(門控循環單元,見圖 1)。
靜態圖注意力
靜態圖注意力機制的設計旨在為檢索到的知識圖提供一個表現形式,我們設計的機制不僅考慮到圖中的所有節點,也同時考慮節點之間的關系,因此編碼的語義信息更加結構化。
靜態圖注意力機制會為每個圖生成一個靜態的表現形式,因而有助于加強問題中每個單詞的語義。
形式上,靜態圖注意力把圖??中的知識三元組向量 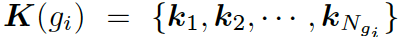 作為輸入,來生成如下的圖向量
作為輸入,來生成如下的圖向量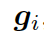
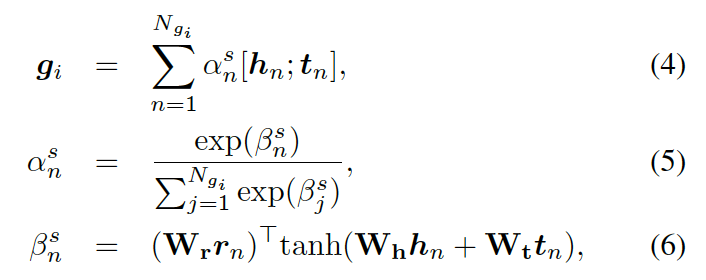
這里的 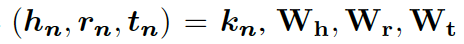 分別是頭實體、關系、尾實體的權重矩陣。注意力的權重估量了“實體間關系”
分別是頭實體、關系、尾實體的權重矩陣。注意力的權重估量了“實體間關系” 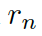 和“頭實體”
和“頭實體” 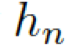 以及“尾實體”
以及“尾實體” 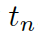 之間的關聯度。
之間的關聯度。
本質上來說,圖向量 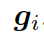
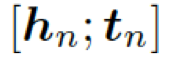 的權重和。
的權重和。
▌2.4 知識感知生成器
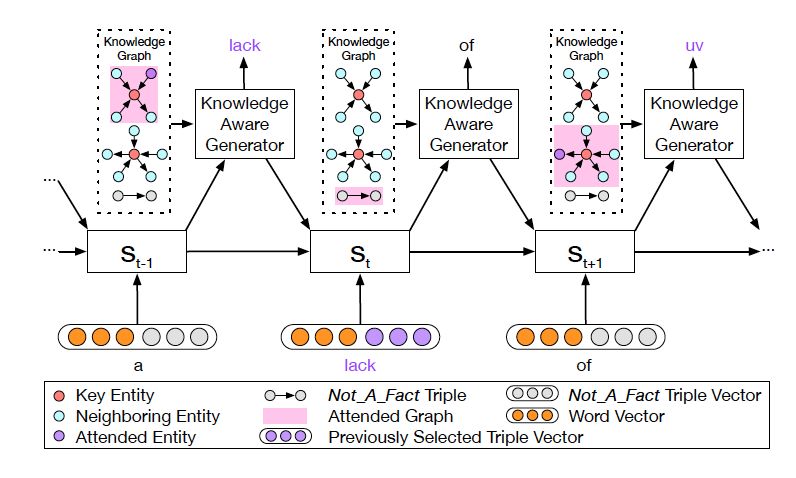
圖 4: 知識感知生成器動態地處理著圖
知識感知生成器 (Knowledge Aware Generator) 旨在通過充分利用檢索到的圖,來生成相應的回復,如圖 4 所示。知識感知生成器扮演了兩個角色:1) 讀取所有檢索到的圖,來獲取一個圖感知上下文向量,并用這個向量來更新解碼器的狀態;2) 自適應地從檢索到的圖中,選擇通用詞匯或實體來生成詞語。形式上來看,解碼器通過如下過程來更新狀態:
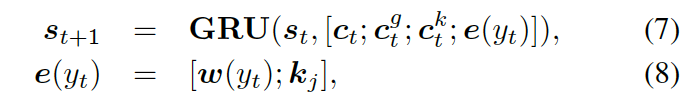
這里  是單詞向量
是單詞向量  和前一個知識三元組向量
和前一個知識三元組向量 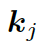 的結合,其來自上一個所選單詞
的結合,其來自上一個所選單詞 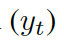 。
。
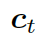 是式 2 中的上下文向量,
是式 2 中的上下文向量, 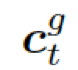 和
和 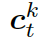 分別是作用于知識圖向量
分別是作用于知識圖向量
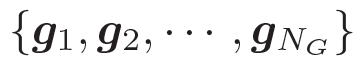
和知識三元組向量
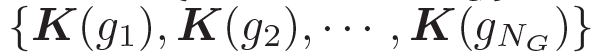
的上下文向量。
動態圖注意力
動態圖注意力機制是一個分層的、自上而下的過程。首先,它讀取所有的知識圖和每個圖中的所有三元組,用來生成最終的回復。若給定一個解碼器的狀態 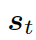 , 它首先作用于知識圖向量
, 它首先作用于知識圖向量
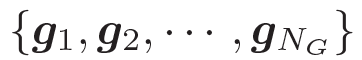
,以計算使用每個圖的概率,如下:
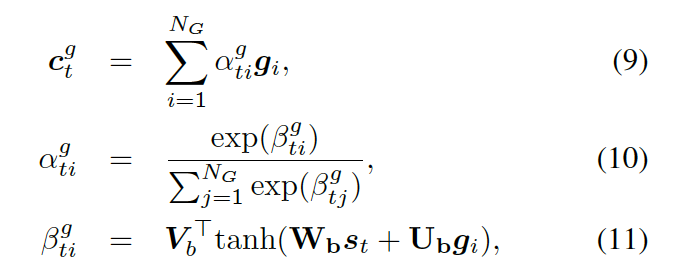
這里
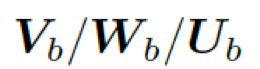
都是參數, 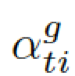 是處于第 t 步時選擇知識圖
是處于第 t 步時選擇知識圖 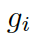 的概率。圖的上下文向量
的概率。圖的上下文向量 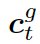 是圖向量的權重和,這個權重估量了解碼器的狀態
是圖向量的權重和,這個權重估量了解碼器的狀態 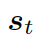
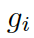
接下來,該模型用每個圖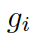
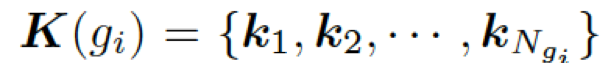
,來計算選擇某個三元組來生成答案的概率,過程如下:
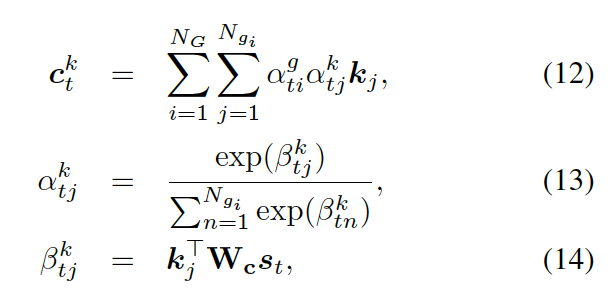
這里 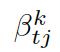 可被看作每個知識三元組向量
可被看作每個知識三元組向量 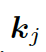 和解碼器狀態
和解碼器狀態 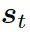 的相似度,
的相似度,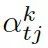
是處于第 t 步時從圖 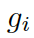 的所有三元組中選擇
的所有三元組中選擇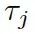 的概率。
的概率。
最后,知識感知生成器選取通用詞匯或實體詞匯,基于如下概率分布:
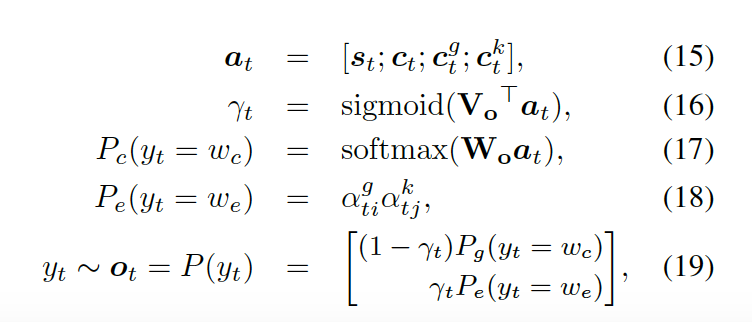
這里 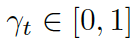 是用來平衡實體詞匯
是用來平衡實體詞匯 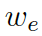 和通用詞匯
和通用詞匯 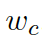 之間選擇的標量,
之間選擇的標量, 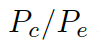 分別是通用詞匯和實體詞匯的概率。最終的概率
分別是通用詞匯和實體詞匯的概率。最終的概率 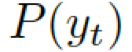 由兩種概率結合所得。
由兩種概率結合所得。
譯者注:在語言生成過程中,引入動態圖注意力機制,模型可以通過當前解碼器的狀態,注意到最合適的知識圖以及對應的知識三元組,再基于此來選擇合適的常識與詞匯來生成回復,從而使對話的信息量更大,內容更加連貫合理。與很多動態優化算法相類似,狀態不斷地更新與反饋,隨之自適應地調整下一步決策,在對話生成系統中引入該機制有效地改善了生成結果。
實驗
▌3.1 數據集
常識知識庫
我們使用語義網絡 (ConceptNet) 作為常識知識庫。語義網絡不僅包括客觀事實,如“巴黎是法國的首都”這樣確鑿的信息,也包括未成文但大家都知道的常識,如“狗是一種寵物”。這一點對我們的實驗很關鍵,因為在建立開放域對話系統過程中,能識別常見概念之間是否有未成文但真實存在的關聯是必需的。
常識對話數據集
我們使用了來自 reddit 上一問一答形式的對話數據,數據集大小約為 10M。由于我們的目標是用常識知識優化語言理解和生成,所以我們濾出帶有知識三元組的原始語料數據。若一對問答數據與任何三元組(即一個實體出現在問題中,另一個在答復中)都沒有關聯,那么這一對數據就會被剔除掉。具體數據概況可見表 1。
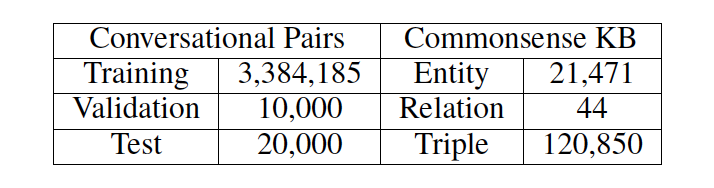
表 1: 數據集與知識庫概況
▌3.2 實驗細節
我們的模型是在 Tensorflow 下運行的。編碼器與解碼器均有兩層 GRU 結構,每層有 512 個隱藏單元,它們之間不會共享參數。詞嵌入時的長度設置為 300。詞匯表大小限制在 30000。
我們采用了 Adam 優化器,學習率設置為 0.0001。具體代碼已共享在 github上,文末附有地址。
▌3.3 對比模型
我們選取了幾種合適的模型作為標準來進行對比:
Seq2Seq,一種 seq2seq 模型,它被廣泛應用于各種開放域對話系統中。
MemNet,一個基于知識的模型,其中記憶單元用來存儲知識三元組經 TransE 嵌入處理后的數據。
CopyNet,一種拷貝網絡模型,它會從知識三元組中拷貝單詞或由詞匯表生成單詞。
▌3.4 自動評估
指標:我們采用復雜度 (perplexity)來評估模型生成的內容。我們也計算了每條回復中的實體個數,來估量模型從常識知識庫中挑選概念的能力,這項指標記為 entity score.
結果:如表 2 所示,CCM 獲得了最低的復雜度,說明 CCM 可以更好地理解用戶的問題,從而給出語義上更合理的回復。而且與其他模型相比,在對話生成中,CCM 從常識知識中選取的實體最多,這也可以說明常識知識可以在真正意義上優化回復的生成。
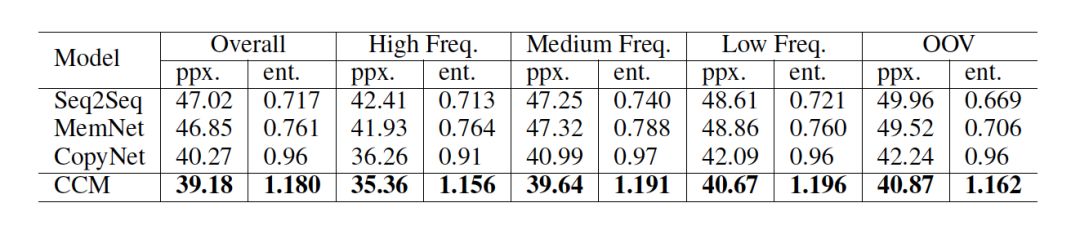
表 2: 基于 perplexity 和 entity score 的模型自動評估
▌3.5 人工評估
我們借助于眾包服務 Amazon Mechanical Turk,從人工標記過的數據中隨機采集 400 條數據。我們基于此來將 CCM 和另外幾個模型對同一問題生成的回復進行對比。我們有三個對比模型,總計 1200 個問答數據對。
指標:我們定義了兩項指標:appropriateness 在內容質量上進行評估(基于語法、主題和邏輯);informativeness 在知識層面進行評估(基于生成的答復是否針對問題提供了新的信息和知識)。
結果:如表 3 所示,CCM 在兩項指標下都比另外幾個模型表現更為突出。其中 CopyNet 是將知識三元組分開單獨使用的,這也證明了圖注意力機制的有效性。
很明顯,在 OOV(out-of-vocabulary)數據集的表現上, CCM 比 Seq2Seq 突出得多。這也進一步說明常識知識在理解生僻概念上很有效,而 Seq2Seq 并沒有這個能力。對于 MemNet 和 CopyNet,我們未發現在這一點上的差別,是因為這兩個模型都或多或少引入使用了常識知識。

表 3: 基于 appropriateness (app.) 和 informativeness (inf.) 的人工評估
▌3.6 案例研究
如表 4 所示,這是一個對話示例。問題中的紅色單詞 "breakable" 是知識庫里的一個單詞實體,同時對于所有模型來說,也是一個詞匯表以外的單詞。由于沒有使用常識知識,且 "breakable" 是詞匯表之外的單詞,所以 Seq2Seq 模型無法理解問題,從而給出含有OOV的回復。MemNet 因為讀取了記憶中嵌入的三元組,可以生成若干有意義的詞匯,但輸出中仍包含OOV。CopyNet 可以從知識三元組中讀取和復制詞匯。然而,CopyNet 生成的實體單詞個數比我們的少(如表 2 所示),這是因為 CopyNet 將知識三元組分開使用了。相比之下,CCM 將知識圖作為一個整體,通過相連的實體和它們之間的關系,與信息關聯起來,使解碼更加結構化。通過這個簡單的例子,可以證明相比于其他幾個模型,CCM 可以生成更為合理、信息也更豐富的回復。

表 4: 對于同一問題,所有模型生成的回復
總結和未來的工作
在本文中,我們提出了一個常識知識感知對話模型 (CCM),演示了常識知識有助于開放域對話系統中語言的理解與生成。自動評估與人工評估皆證明了,與當前最先進的模型相比,CCM 能夠生成更合理、信息量更豐富的回復。圖注意力機制的表現,鼓舞了我們在未來的其他項目中也將使用常識知識。
-
編碼器
+關注
關注
45文章
3793瀏覽量
137978 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14149
發布評論請先 登錄
RF功率測量及控制有助于確保系統安全、高效地運行
介紹一些與變量相關的存儲屬性與作用域
有助于提高FPGA調試效率的技術與問題分析
智能電網的發展有助于智能家居的應用普及

NLP中基于聯合知識的任務導向型對話系統HyKnow
基于知識的對話生成任務
相位噪聲曲線有助于系統測試





 工商網監
工商網監
評論