 數據挖掘與機器學習項目特征工程實戰
數據挖掘與機器學習項目特征工程實戰
找特征這件事,Andrew Ng在深度學習網課中提到過,原課件見第3課結構化機器學習項目中的2.9和2.10兩節,筆記整理如下:
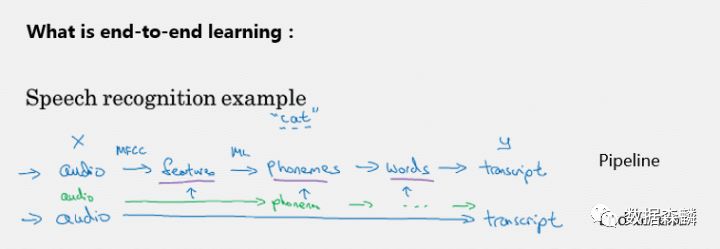

Andrew以Speech Recognition的場景為例,比較了pipeline和end-to-end兩種建模方式中特征工程的差異。
其中pipeline的搭建依賴于人工設計的特征,需要依賴于人類可以理解的音節,將一段音頻轉化為文字;而end-to-end模型基于大量的音頻素材,自動找出語音和文字間的關系,不依賴于音節而自動翻譯成文字。
總而言之,除去語音和圖像等特定場景,對于大部分生活中的機器學習項目,由于沒有足夠的訓練數據支撐,我們還無法完全信任算法自動生成的特征,因而基于人工經驗的特征工程依然是目前的主流。
人工經驗這件事比較虛,加之許多業界的項目由于隱私性的考慮,很少會透露底層的入模特征和計算邏輯,使得目前網絡上關于特征工程細節的文章少之又少。答主在這里結合自己這幾年在金融領域的建模經驗,介紹一些常見的數據源類型和特征計算方法,希望可以幫助剛入行或者想入行的從業者們開開腦洞。
(1)支付流水:通常包括支付賬戶、時間、金額、地點、目的、狀態等字段,可以反映出客戶的經濟實力和消費習慣。其中特別的,賬戶間的復雜交易關系和異常金額時間地點的支付行為,都可以在反欺詐場景中應用,視為團伙作案或者反洗錢的重要指標。
(2)財富管理:基金理財類產品的申購歷史記錄,體現出客戶的資金儲備和購買偏好。對于風險偏好較低的客戶,我們可以推薦小金庫這類收益穩定、波動較小的債券類產品;對于追求高收益的客戶,我們可以推薦在京東金融app上代銷的各類基金,以及智能投顧產品。
(3)貸款信息:伴隨著近幾年國內現金貸以及場景貸市場的迅速發展,國家也在大力推動各家資方信貸數據的治理與共享。基于一個客戶在各個平臺上的貸款申請、提現、還款信息,可以刻畫出這個客戶的還款意愿和征信表現,從而為其下一次的信貸申請決策提供建議。常見的,多個平臺申請和在貸以及當前有貸款發生90天以上逾期的用戶,都會被其他平臺列入自動拒絕的名單。
(4)App登錄:從SDK埋點獲取的各類app登錄數據中,我們可以分析出用戶在每個app上的停留時間,從而側面了解這個用戶的興趣愛好,甚至預測用戶的年齡和性別。例如京東、阿里等電商app登錄較頻繁的用戶,通常以女性居多,并且消費能力較強;而抖音、快手等小視頻app停留時間較長的,一般為年輕人群體。
(5)電商流水:從電商公司豐富的訂單流水數據中,可以挖掘出較為完整的客戶畫像。客戶Alice近一年內購買頻繁,但是平均單筆訂單金額較低,通常集中在生活用品以及水果生鮮,可以推斷出Alice應該是一位家庭婦女;而客戶Ben消費總金額較高,購買過車飾類產品,收貨地址集中在辦公場所,則大概率Ben是有車一族的白領青年。
(6)收貨地址:在信貸風控場景中,通常近一年內地址數量較少、地址穩定性高的用戶,貸款逾期風險更低;而對于地址變動頻繁或者涉黑的用戶,建議貸前申請直接拒絕,或者把這些收貨地址運用到貸后催收之中。
(7)運營商信息:數據市場上比較常見的第三方數據源,可以用作各個場景下的身份證、姓名、手機號的三要素核驗,以及利用在網時長和在網狀態判斷一個用戶是否有欺詐風險。
除去上面整理的簡單底層特征,在實際工作中數據分析師和算法工程師們還需要針對不同的業務場景,利用規則和模型構造一些復雜特征。
舉兩個實際的例子:
第一個例子,為了計算用戶的年收入,可以利用近一年內支付總金額+理財總余額-信貸總負債的大公式,通過線性回歸擬合出三個指標的系數,來得到每個用戶預測的收入水平;
第二個例子,給自己在做的模型打個小廣告,京東金融金融科技業務部基于京東集團商城、金融和物流三大自有數據源以及海量外部數據源,利用XGBoost、LightGBM、CatBoost等復雜集成樹類算法,計算得到玉衡分特征,用來衡量京東客戶在現金貸場景的信用等級,幫助服務的銀行和小貸公司搭建信貸智能決策系統。
-
機器學習
+關注
關注
66文章
8478瀏覽量
133810
原文標題:在機器學習的項目中,特征是如何被找出來的
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《AI Agent 應用與項目實戰》----- 學習如何開發視頻應用
《AI Agent 應用與項目實戰》第1-2章閱讀心得——理解Agent框架與Coze平臺的應用
數據準備指南:10種基礎特征工程方法的實戰教程

特征工程實施步驟
【全新課程資料】正點原子《基于GD32 ARM32單片機項目實戰入門》培訓課程資料上線!
【全新課程資料】正點原子《ESP32基礎及項目實戰入門》培訓課程資料上線!
【全新課程資料】正點原子《ESP32物聯網項目實戰》培訓課程資料上線!
【「時間序列與機器學習」閱讀體驗】時間序列的信息提取
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
機器學習中的數據預處理與特征工程
通過強化學習策略進行特征選擇





 工商網監
工商網監
評論