") 車載芯片的發(fā)展趨勢(CPU-GPU-FPGA-ASIC)
車載芯片的發(fā)展趨勢(CPU-GPU-FPGA-ASIC)
▌車載芯片的發(fā)展趨勢(CPU-GPU-FPGA-ASIC)
過去汽車電子芯片以與傳感器一一對應的電子控制單元(ECU)為主,主要分布與發(fā)動機等核心部件上。隨著汽車智能化的發(fā)展,汽車傳感器越來越多,傳統(tǒng)的分布式架構逐漸落后,由中心化架構DCU、MDC逐步替代
隨著人工智能發(fā)展,汽車智能化形成趨勢,目前輔助駕駛功能滲透率越來越高,這些功能的實現(xiàn)需借助于攝像頭、雷達等新增的傳感器數(shù)據(jù),其中視頻(多幀圖像)的處理需要大量并行計算,傳統(tǒng)CPU算力不足,這方面性能強大的GPU替代了CPU。再加上輔助駕駛算法需要的訓練過程,GPU+FPGA成為目前主流的解決方案。
著眼未來,自動駕駛也將逐步完善,屆時又會加入激光雷達的點云(三維位置數(shù)據(jù))數(shù)據(jù)以及更多的攝像頭和雷達傳感器,GPU也難以勝任,ASIC性能、能耗和大規(guī)模量產成本均顯著優(yōu)于GPU和FPGA,定制化的ASIC芯片可在相對低水平的能耗下,將車載信息的數(shù)據(jù)處理速度提升更快,隨著自動駕駛的定制化需求提升,ASIC專用芯片將成為主流。本文以如上順序梳理車載芯片發(fā)展歷程,探討未來發(fā)展方向。
▌車載芯片的過去—以CPU為核心的ECU
ECU的核心CPU
ECU(ElectronicControlUnit)是電子控制單元,也稱“行車電腦”,是汽車專用微機控制器。一般ECU由CPU、存儲器(ROM、RAM)、輸入/輸出接口(I/O)、模數(shù)轉換器(A/D)以及整形、驅動等大規(guī)模集成電路組成。
ECU的工作過程就是CPU接收到各個傳感器的信號后轉化為數(shù)據(jù),并由Program區(qū)域的程序對Data區(qū)域的數(shù)據(jù)圖表調用來進行數(shù)據(jù)處理,從而得出具體驅動數(shù)據(jù),并通過CPU針腳傳送到相關驅動芯片,驅動芯片再通過相應的周邊電路產生驅動信號,用來驅動驅動器。
即傳感器信號——傳感器數(shù)據(jù)——驅動數(shù)據(jù)——驅動信號這樣一個完整工作流程。
分布式架構向多域控制器發(fā)展
汽車電子發(fā)展的初期階段,ECU主要是用于控制發(fā)動機工作,只有汽車發(fā)動機的排氣管(氧傳感器)、氣缸(爆震傳感器)、水溫傳感器等核心部件才會放置傳感器,由于傳感器數(shù)量較少,為保證傳感器-ECU-控制器回路的穩(wěn)定性,ECU與傳感器一一對應的分布式架構是汽車電子的典型模式。
后來隨著車輛的電子化程度逐漸提高,ECU占領了整個汽車,從防抱死制動系統(tǒng)、4輪驅動系統(tǒng)、電控自動變速器、主動懸架系統(tǒng)、安全氣囊系統(tǒng),到現(xiàn)在逐漸延伸到了車身各類安全、網(wǎng)絡、娛樂、傳感控制系統(tǒng)等。
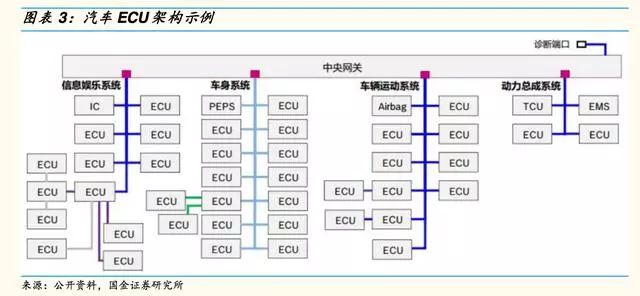
隨著汽車電子化的發(fā)展,車載傳感器數(shù)量越來越多,傳感器與ECU一一對應使得車輛整體性下降,線路復雜性也急劇增加,此時DCU(域控制器)和MDC(多域控制器)等更強大的中心化架構逐步替代了分布式架構。
域控制器(DomainControlUnit)的概念最早是由以博世,大陸,德爾福為首的Tier1提出,是為了解決信息安全,以及ECU瓶頸的問題。
根據(jù)汽車電子部件功能將整車劃分為動力總成,車輛安全,車身電子,智能座艙和智能駕駛等幾個域,利用處理能力更強的多核CPU/GPU芯片相對集中的去控制每個域,以取代目前分布式汽車電子電氣架構。
而進入自動駕駛時代,控制器需要接受、分析、處理的信號大量且復雜,原有的一個功能對應一個ECU的分布式計算架構或者單一分模塊的域控制器已經(jīng)無法適應需求,比如攝像頭、毫米波雷達、激光雷達乃至GPS和輪速傳感器的數(shù)據(jù)都要在一個計算中心內進行處理以保證輸出結果的對整車自動駕駛最優(yōu)。
因此,自動駕駛車輛的各種數(shù)據(jù)聚集、融合處理,從而為自動駕駛的路徑規(guī)劃和駕駛決策提供支持的多域控制器將會是發(fā)展的趨勢,奧迪與德爾福共同開發(fā)的zFAS,即是通過一塊ECU,能夠接入不同傳感器的信號并進行對信號進行分析和處理,最終發(fā)出控制命令。
▌車載芯片的現(xiàn)在—以GPU為核心的智能輔助駕駛芯片
人工智能的發(fā)展也帶動了汽車智能化發(fā)展,過去的以CPU為核心的處理器越來越難以滿足處理視頻、圖片等非結構化數(shù)據(jù)的需求,同時處理器也需要整合雷達、視頻等多路數(shù)據(jù),這些都對車載處理器的并行計算效率提出更高要求,而GPU同時處理大量簡單計算任務的特性在自動駕駛領域取代CPU成為了主流方案。
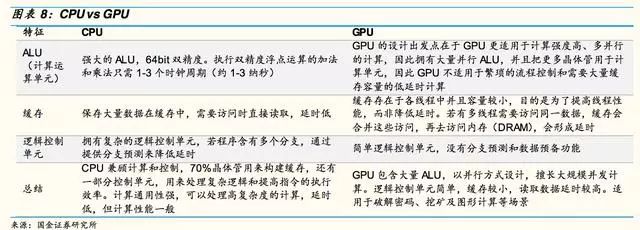
GPUVs.CPU
CPU的核心數(shù)量只有幾個(不超過兩位數(shù)),每個核都有足夠大的緩存和足夠多的數(shù)字和邏輯運算單元,并輔助很多復雜的計算分支。而GPU的運算核心數(shù)量則可以多達上百個(流處理器),每個核擁有的緩存大小相對小,數(shù)字邏輯運算單元也少而簡單。
CPU和GPU最大的區(qū)別是設計結構及不同結構形成的不同功能。CPU的邏輯控制功能強,可以進行復雜的邏輯運算,并且延時低,可以高效處理復雜的運算任務。
而GPU邏輯控制和緩存較少,使得每單個運算單元執(zhí)行的邏輯運算復雜程度有限,但并列大量的計算單元,可以同時進行大量較簡單的運算任務。
GPU占據(jù)現(xiàn)階段自動駕駛芯片主導地位
相比于消費電子產品的芯片,車載的智能駕駛芯片對性能和壽命要求都比較高,主要體現(xiàn)在以下幾方面:
1、耗電每瓦提供的性能;2、生態(tài)系統(tǒng)的構建,如用戶群、易用性等;3、滿足車規(guī)級壽命要求,至少1萬小時穩(wěn)定使用。
目前無論是尚未商業(yè)化生產的自動駕駛AI芯片還是已經(jīng)可以量產使用的輔助駕駛芯片,由于自動駕駛算法還在快速更新迭代,對云端“訓練”部分提出很高要求,既需要大規(guī)模的并行計算,又需要大數(shù)據(jù)的多線程計算,因此以GPU+FPGA解決方案為核心;在終端的“推理”部分,核心需求是大量并行計算,從而以GPU為核心。
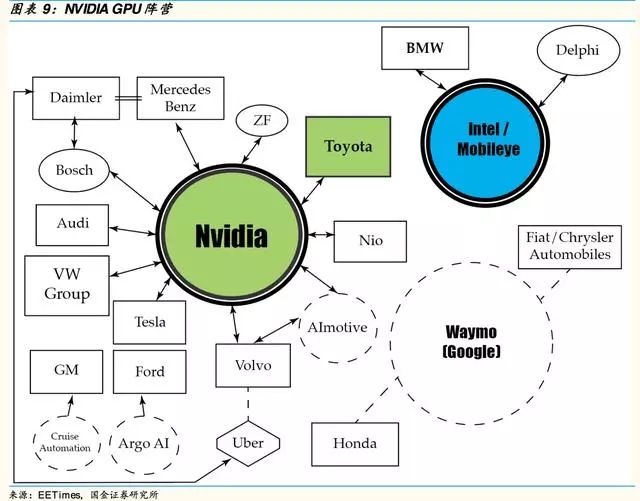
▌相關公司
NVIDIA
NVIDIA在自動駕駛領域的成就正是得益于他們在GPU領域內的深耕,NVIDIAGPU專為并行計算而設計,適合深度學習任務,并且能夠處理在深度學習中普遍存在的向量和矩陣操作。相對于Mobileye專注于視覺處理,NVIDIA的方案重點在于融合不同傳感器。
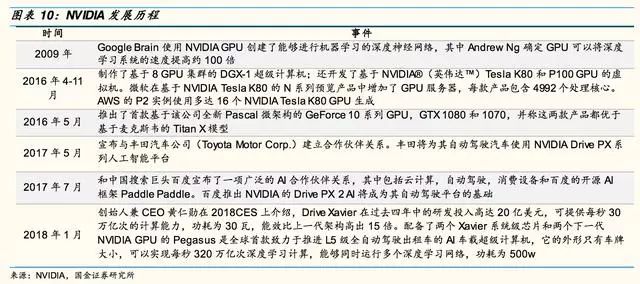
2016年,英偉達在DrivePX2平臺上推出了三款產品,分別是配備單GPU和單攝像頭及雷達輸入端口的DrivePX2Autocruise(自動巡航)芯片(下圖左上)、配備雙GPU及多個攝像頭及雷達輸入端口的DrivePX2AutoChauffeur(自動私人司機)芯片(右上)、配備多個GPU及多個攝像頭及雷達輸入端口的DrivePX2FullyAutonomousDriving(全自動駕駛)芯片(下方)。
以目前的銷售情況,DrivePX2搭載上一代Pascal架構GPU已經(jīng)實現(xiàn)量產,并且已經(jīng)搭載在Tesla的量產車型ModelS以及ModelX上。
目前PX2仍然是NVIDIA自動駕駛平臺出貨的主力,Tesla,Audi和ZF等對外公布DrivePX2應用在量產車上。
Xavier是DrivePX2的進化版本,搭配了最新一代的Volta架構GPU,相較于DrivePX2性能將提升近一倍,2017年年底量產。
由于多家主機廠L3級別以上自動駕駛量產車的計劃在2020年左右,而Xavier的量產計劃將能和自動駕駛車的研發(fā)周期相互配合(一般3年左右),因此Xavier的合作都是有量產車落地計劃的。
而對于較早與NVIDIA達成合作的車廠來說,他們在小批量測試、量產的優(yōu)先級別以及可定制化空間等方面都能獲得一定的優(yōu)勢。
目前,L4及以上的市場基本上被NVIDIA壟斷,CEO黃仁勛稱全球有300余家自動駕駛研發(fā)機構使用DrivePX2。
DrivePX2單價為1.6萬美金,功耗達425瓦,但目前沒有達到車規(guī),按功耗和成本看,只能小規(guī)模測試階段使用。
四維圖新
國內地圖行業(yè)龍頭,向ADAS和自動駕駛進軍。公司成立于2002年,是國內首家獲導航地圖制作資質的企業(yè)(目前僅13家),為領先的數(shù)字地圖內容、車聯(lián)網(wǎng)與動態(tài)交通信息服務、基于位置的大數(shù)據(jù)垂直應用服務的提供商之一。
其拳頭業(yè)務——地圖業(yè)務,以國內60%的份額穩(wěn)居壟斷地位。2017年以來,公司收購杰發(fā)科技、入股中寰衛(wèi)星與禾多科技,“高精度地圖+芯片+算法+軟件”的自動駕駛產業(yè)鏈全方位布局雛形已現(xiàn)。
高精度地圖:代表國內最高水平。
公司以地圖起家,目前國內高精度地圖僅兩家玩家(另一家為高德),公司深度綁定獲得寶馬、大眾、奔馳、通用、沃爾沃、福特、上汽、豐田、日產、現(xiàn)代、標致等主流車企發(fā)展,占絕對優(yōu)勢。2017年公司實現(xiàn)支持L3級別(至少20個城市)的高精度地圖,計劃于2019年覆蓋所有城市,并為L4的推出做準備。
公司地圖編譯能力亮眼,全球首位提供NDS地圖從生產到編譯環(huán)節(jié)。此外,公司在荷蘭、美國硅谷、新加坡等地設立研發(fā)中心和分支機構,合作伙伴涵蓋國際主流車廠、新一代整車企業(yè)以及騰訊、滴滴、搜狗、華為等國內知名企業(yè)。
芯片:收購杰發(fā)科技布局汽車芯片。
杰發(fā)科技(2017年3月完成收購)脫胎于聯(lián)發(fā)科,主攻車載信息娛樂系統(tǒng)芯片。
現(xiàn)階段在國內后裝市場市占率超70%,前裝超30%(主要為吉利、豐田等車企),其車規(guī)級IVI芯片被多家國際主流零部件廠商采用,并計劃推出AMP、MCU及TPMS(胎壓監(jiān)測)芯片等新一代產品。公司通過收購杰發(fā)科技,具備了為車廠提供高性能汽車電子芯片的能力,打通從軟件到硬件的關鍵性關卡,并與蔚來、威馬、愛馳億維等造車新勢力公司達成了合作。
該芯片采用64位QuadA53架構,內置硬件圖像加速引擎,支持雙路高清視頻輸出,和四路高清視頻輸入,能同時支持高級車載影音娛樂系統(tǒng)全部功能和豐富的ADAS功能。
功能包括:360°全景泊車系統(tǒng)、車道偏移警示系統(tǒng)LDW、前方碰撞警示系統(tǒng)FCW、行人碰撞警示系統(tǒng)PCW、交通標志識別系統(tǒng)TSR、車輛盲區(qū)偵測系統(tǒng)BSD、駕駛員疲勞探測系統(tǒng)DFM和后方碰撞預警系統(tǒng)RCW等。
在今年5月的CESAsia,全志科技發(fā)布首款車規(guī)級處理器T7,同時發(fā)布基于T7的多種智能座艙產品形態(tài)。
T7是數(shù)字座艙車規(guī)(AEC-Q100)平臺型處理器,支持Android、Linux、QNX系統(tǒng),集成多路高清影像輸入和輸出,完美支持高清多媒體處理,內置的EVE視覺處理單元可提升輔助駕駛運算效率。
該款芯片雖然是首款通過車規(guī)的國產中控主機芯片,但還處于起步階段,根據(jù)正常汽車電子芯片的生命周期,要規(guī)模應用至少需要兩年時間,而等到形成較多的用戶和良好的生態(tài)還需很多資源投入以及時間的積累。
因此國產車載芯片不論在自動駕駛領域還是中控或輔助駕駛領域,想要真正形成量產與國外老牌巨頭競爭,都還需要大量人力、資本和時間。
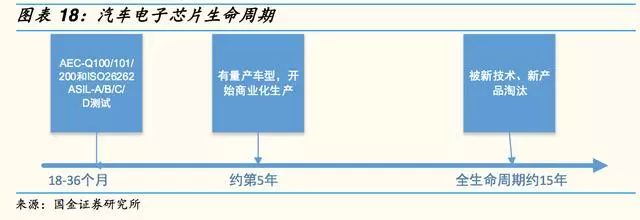
▌車載芯片的未來—以ASIC為核心的自動駕駛芯片
ASICvsGPU+FPGA
GPU適用于單一指令的并行計算,而FPGA與之相反,適用于多指令,單數(shù)據(jù)流,常用于云端的“訓練”階段。
此外與GPU對比,F(xiàn)PGA沒有存取功能,因此速度更快,功耗低,但同時運算量不大。結合兩者優(yōu)勢,形成GPU+FPGA的解決方案。
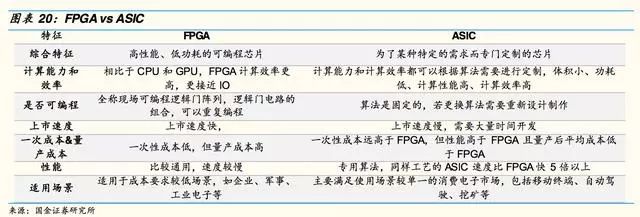
FPGA和ASIC的區(qū)別主要在是否可以編程。FPGA客戶可根據(jù)需求編程,改變用途,但量產成本較高,適用于應用場景較多的企業(yè)、軍事等用戶;而ASIC已經(jīng)制作完成并且只搭載一種算法和形成一種用途,首次“開模”成本高,但量產成本低,適用于場景單一的消費電子、“挖礦”等客戶。
目前自動駕駛算法仍在快速更迭和進化,因此大多自動駕駛芯片使用GPU+FPGA的解決方案。未來算法穩(wěn)定后,ASIC將成為主流。
計算能耗比,ASIC>FPGA>GPU>CPU,究其原因,ASIC和FPGA更接近底層IO,同時FPGA有冗余晶體管和連線用于編程,而ASIC是固定算法最優(yōu)化設計,因此ASIC能耗比最高。
相比前兩者,GPU和CPU屏蔽底層IO,降低了數(shù)據(jù)的遷移和運算效率,能耗比較高。同時GPU的邏輯和緩存功能簡單,以并行計算為主,因此GPU能耗比又高于CPU。
▌ASIC是未來自動駕駛芯片的核心和趨勢
結合ASIC的優(yōu)勢,我們認為長遠看自動駕駛的AI芯片會以ASIC為解決方案,主要有以下幾個原因:

綜上ASIC專用芯片幾乎是自動駕駛量產芯片唯一的解決方案。由于這種芯片僅支持單一算法,對芯片設計者在算法、IC設計上都提出很高要求。
以上并非下定論目前ASIC為核心的芯片一定比GPU+FPGA的芯片強,由于目前自動駕駛算法還在快速迭代和升級過程中,過早以固有算法生產ASIC芯片長期來看不一定是最優(yōu)選擇。
▌相關公司
Mobileye
Intel在ADAS處理器上的布局已經(jīng)完善,包括Mobileye的ADAS視覺處理,利用Altera的FPGA處理,以及英特爾自身的至強等型號的處理器,可以形成自動駕駛整個硬件超級中央控制的解決方案。

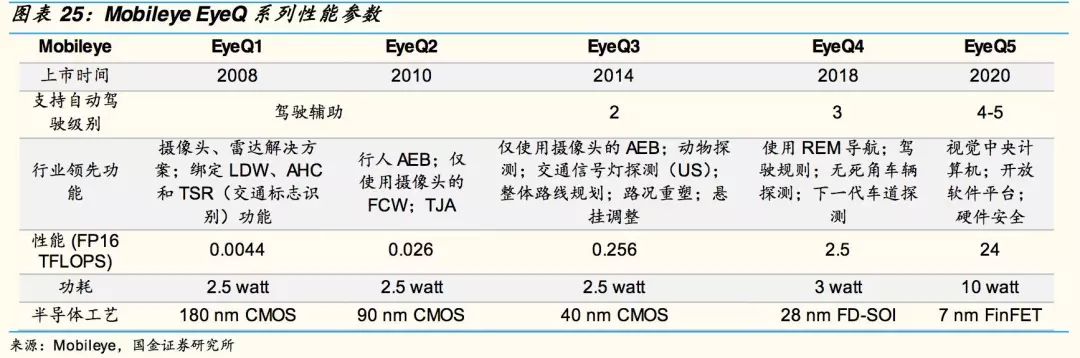
Mobileye具有自主研發(fā)設計的芯片EyeQ系列,由意法半導體公司生產供應。現(xiàn)在已經(jīng)量產的芯片型號有EyeQ1至EyeQ4,EyeQ5正在開發(fā)進行中,計劃2020年面世,對標英偉達DrivePXXavier,并透露EyeQ5的計算性能達到了24TOPS,功耗為10瓦,芯片節(jié)能效率是DriveXavier的2.4倍。
英特爾自動駕駛系統(tǒng)將采用攝像頭為先的方法設計,搭載兩塊EyeQ5系統(tǒng)芯片、一個英特爾凌動C3xx4處理器以及Mobileye軟件,大規(guī)模應用于可擴展的L4/L5自動駕駛汽車。該系列已被奧迪、寶馬、菲亞特、福特、通用等多家汽車制造商使用。
從硬件架構來看,該芯片包括了一組工業(yè)級四核MIPS處理器,以支持多線程技術能更好的進行數(shù)據(jù)的控制和管理(下圖左上)。
多個專用的向量微碼處理器(VMP),用來應對ADAS相關的圖像處理任務(如:縮放和預處理、翹曲、跟蹤、車道標記檢測、道路幾何檢測、濾波和直方圖等,下圖右上)。
一顆軍工級MIPSWarriorCPU位于次級傳輸管理中心,用于處理片內片外的通用數(shù)據(jù)。
此外通過行業(yè)訪談調研等途徑了解到,Mobileye在L1-L3智能駕駛領域具有極大的話語權,對Tire1和OEM非常強勢,其算法和芯片綁定,不允許更改。

5月3日,寒武紀科技在2018產品發(fā)布會上發(fā)布了多個IP產品——采用7nm工藝的終端芯片Cambricon1M、云端智能芯片MLU100等。
其中寒武紀1M芯片是公司第三代IP產品,在TSMC7nm工藝下8位運算的效能比達5Tops/w(每瓦5萬億次運算),同時提供2Tops、4Tops、8Tops三種尺寸的處理器內核,以滿足不同需求。
1M還將支持CNN、RNN、SVM、k-NN等多種深度學習模型與機器學習算法的加速,能夠完成視覺、語音、自然語言處理等任務。通過靈活配置1M處理器,可以實現(xiàn)多線和復雜自動駕駛任務的資源最大化利用。它還支持終端的訓練,以此避免敏感數(shù)據(jù)的傳輸和實現(xiàn)更快的響應。
寒武紀首款云端智能芯片CambriconMLU100同期發(fā)布,同時公布了在R-CNN算法下MLU100與英偉達TeslaV100(2017)和英偉達TeslaP4(2016)的對比,從參數(shù)上看,主要對標TeslaP4。最后說明芯片從設計到落地應用面臨的潛在風險:

地平線
2017年地平線發(fā)布了新一代自動駕駛芯片“征程”和配套軟件平臺方案“雨果”,同時還發(fā)布了應用于智能攝像頭的“旭日”處理器。
“征程”是一款專用AI芯片,采用地平線的第一代BPU架構,可實時處理1080p@30視頻,每幀中可同時對200個目標進行檢測、跟蹤、識別,典型功耗1.5W,每幀延時小于30ms。CEO余凱介紹,地平線的芯片更聚焦在針對不同場景下的具體應用,相比于英偉達的方案,在功耗上低一個數(shù)量級,價格也會有更大的競爭力。
2018年亞洲CES,地平線宣布推出從L2到L4級別全系列的自動駕駛計算平臺。
地平線星云,基于征程1.0芯片,能夠以車規(guī)級標準滿足L1和L2級別的自動駕駛的需求,能同時對行人、機動車、非機動車、車道線、交通標志牌、紅綠燈等多類目標進行精準的實時監(jiān)測與識別;并可滿足車載設備嚴苛的環(huán)境要求,以及復雜環(huán)境下的視覺感知需求,支持L2級別ADAS功能。
地平線Matrix1.0,內置地平線征程2.0處理器架構,最大化嵌入式AI計算性能,是面向L3/L4的自動駕駛解決方案,可滿足自動駕駛場景下高性能和低功耗的需求。
依托地平線公司自主研發(fā)的工具鏈,開發(fā)者和研究人員可以基于Matrix平臺部署神經(jīng)網(wǎng)絡模型,實現(xiàn)開發(fā)、驗證、優(yōu)化和部署。

百度“昆侖”
7月4日百度AI開發(fā)者大會上,李彥宏發(fā)布了由百度自主研發(fā)的中國首款云端全功能AI芯片——“昆侖”。“昆侖”基于百度8年的AI加速器經(jīng)驗的研發(fā),預計將于明年流片。
“昆侖”采用14nm三星工藝,是業(yè)內設計算力最高的AI芯片(100+瓦功耗下提供260Tops性能);512GB/s內存帶寬,由幾萬個小核心構成。
“昆侖”可高效地同時滿足訓練和推斷的需求,除了常用深度學習算法等云端需求,還能適配諸如自然語言處理,大規(guī)模語音識別,自動駕駛,大規(guī)模推薦等具體終端場景的計算需求。
此外可以支持paddle等多個深度學習框架,編程靈活度高。同時也有媒體對該產品提出疑義,主要有以下兩點:

GoogleTPU
GoogleTPU于2016年在GoogleI/O上宣布,當時該公司表示TPU已在其數(shù)據(jù)中心內使用了一年以上。該芯片專為Google的TensorFlow(一個符號數(shù)學庫,用于神經(jīng)網(wǎng)絡等機器學習應用)框架而設計。
GoogleTPU是專用的,并不面向市場,谷歌僅表示“將允許其他公司通過其云計算服務購買這些芯片。”
今年2月,谷歌在其云平臺博客上宣布的TPU服務開放價格大約為每cloudTPU(180TFLOPS和64GB內存)每小時6.50美元。
Google使用TPU開發(fā)圍棋系統(tǒng)AlphaGo和AlphaZero以及進行Google街景視頻文字處理等,能夠在不到五天的時間內找到街景數(shù)據(jù)庫中的所有文字,此外TPU也用于提供Google搜索結果的排序。
TPU與同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。
Xilinx&深鑒科技
Xilinx賽靈思是FPGA的先行者和領導者,1984年,賽靈思發(fā)明了現(xiàn)場可編程門陣列FPGA,作為半定制化的ASIC,順應了計算機需求更專業(yè)的趨勢。
FPGA的好處是可編程以及帶來的靈活配置,同時還可以提高整體系統(tǒng)性能,比單獨開發(fā)芯片整個開發(fā)周期大為縮短,但缺點是價格、尺寸等因素。
在汽車ADAS和自動駕駛解決方案上,賽靈思的FPGA和SOC產品家族衍生出三個模塊:
自動駕駛中央控制器ZynqUltraScale+MPSoC
前置攝像頭Zynq-7000/ZynqUltraScale+MPSoC
多傳感器融合系統(tǒng)ZynqUltraScale+MPSoC
Zynq采用單一芯片即可完成ADAS解決方案的開發(fā),SOC平臺大幅提升了性能,便于各種捆綁式應用,能實現(xiàn)不同產品系列間的可擴展性,可幫助系統(tǒng)廠商加快在環(huán)繞視覺、3D環(huán)繞視覺、后視攝像頭、動態(tài)校準、行人檢測、后視車道偏離警告和盲區(qū)檢測等ADAS應用的開發(fā)時間。并且可以讓OEM和Tier1在平臺上添加自己的IP以及賽靈思自己的擴展。
深鑒科技成立于2016年,其創(chuàng)始團隊有著深厚的清華背景,專注于神經(jīng)網(wǎng)絡剪枝、深度壓縮技術及系統(tǒng)級優(yōu)化。2018年7月17日,賽靈思宣布收購深鑒科技。
自成立以來,深鑒科技就一直基于賽靈思的技術平臺開發(fā)機器學習解決方案,推出的兩個用于深度學習處理器的底層架構—亞里士多德架構和笛卡爾架構的DPU產品,都是基于賽靈思FPGA器件。
對于賽靈思來說,看好深鑒科技基于機器學習的軟件、算法,以及面向云側和端側硬件架構的優(yōu)勢;對于深鑒科技,后期發(fā)展高昂的研發(fā)費用、高成本的芯片設計、流片、試制、認證、投片量產,投靠賽靈思能夠降低隨之而來的風險,進入芯片戰(zhàn)爭的持久戰(zhàn)。
2018年6月,深鑒科技宣布進軍自動駕駛領域,自主研發(fā)的ADAS輔助駕駛系統(tǒng)——DPhiAuto,目前已獲得日本與歐洲一線車企廠商和Tier1的訂單,即將實現(xiàn)量產。
DPhiAuto,基于FPGA,是面向高級輔助駕駛和自動駕駛的嵌入式AI計算平臺,可提供車輛檢測、行人檢測、車道線檢測、語義分割、交通標志識別、可行駛區(qū)域檢測等深度學習算法功能,是一套針對計算機視覺環(huán)境感知的軟硬件協(xié)同產品。
功耗方面,可以在10-20W的功耗范圍內,實現(xiàn)等效性能,能效比指標高于目前主流的CPU、GPU方案。
-
傳感器
+關注
關注
2564文章
52668瀏覽量
764269 -
車載芯片
+關注
關注
0文章
79瀏覽量
15024
原文標題:自動駕駛芯片:GPU 的現(xiàn)在和 ASIC 的未來
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
自動駕駛主流架構方案對比:GPU、FPGA、ASIC
相比CPU、GPU、ASIC,FPGA有什么優(yōu)勢
TPMS技術與發(fā)展趨勢
FPGA和ASIC芯片解密有哪些性能分析
單片機的發(fā)展趨勢
什么是ASIC芯片?與CPU、GPU、FPGA相比如何?
淺析GPU、FPGA、ASIC三種主流AI芯片的區(qū)別
AI芯片的未來發(fā)展趨勢是什么?
FPGA的發(fā)展趨勢
FPGA與CPU、GPU、ASIC的區(qū)別,FPGA在云計算中的應用方案
AI芯片的應用場景和發(fā)展趨勢
ASIC和GPU的原理和優(yōu)勢





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論