 AlexNet主要使用到的新技術
AlexNet主要使用到的新技術
AlexNet
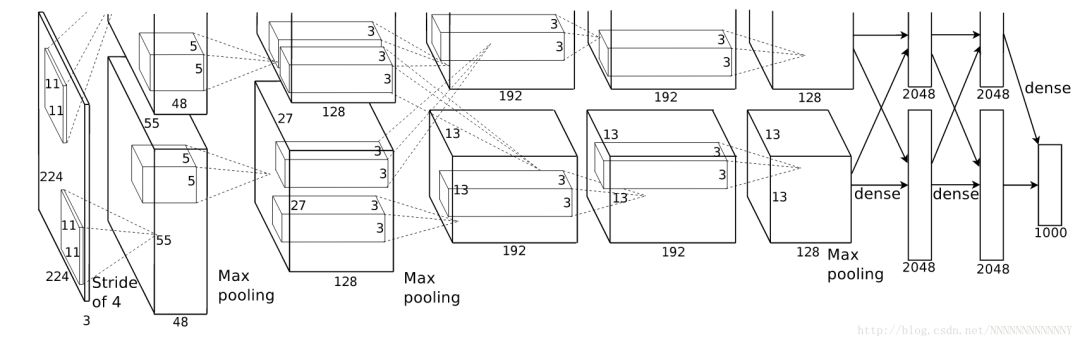
2012年,Hinton的學生Alex Krizhevsky提出了深度卷積神經網絡模型AlexNet,獲得當年ILSVRC(Image Large Scale Visual Recognition Challenge)比賽分類項目的冠軍。
AlexNet主要使用到的新技術如下:
a) 成功使用ReLU作為CNN的激活函數,并驗證了其在較深網絡中的有效性,解決了Sigmod在網絡較深時的梯度彌散問題。b) 訓練時在最后幾個全連接層使用Dropout隨機忽略一部分神經元以避免模型過擬合,c) 使用重疊的最大池化。AlexNet全部使用最大池化,避免平均池化的模糊效果;并提出讓步長比池化核的尺寸小,這樣池化層的輸出之間會有重疊覆蓋,特升了特征的豐富性。d) 提出LRN(Local Response Normalization,局部響應歸一化)層,如今已很少使用。e) 使用CUDA加速深度卷積神經網絡的訓練。當初用的還是兩塊GRX 580 GPU,發展的好快呀。f)數據增強,隨機從256*256的原始圖像中截取224*224大小的區域作為網絡輸入。
整個AlexNet有5個卷積層和3個全連接層。
其參數圖如下:
關于計算params和FLOPs的方法,參看Deep Learning for Computer Vision: Memory usage and computational considerations
使用tensorflow實現AlexNet
參考網址:https://github.com/tensorflow/models/tree/master/tutorials/image/alexnet
VGGNet
VGGNet結構非常簡潔,其特點如下:
a) 通過反復堆疊3*3的小型卷積核和2*2的最大池化層構建。b) VGGNet擁有5段卷積,每一段卷積網絡都會將圖像的邊長縮小一半,但將卷積通道數翻倍:64 —>128 —>256 —>512 —>512 。這樣圖像的面積縮小到1/4,輸出通道數變為2倍,輸出tensor的總尺寸每次縮小一半。c) 經常多個完全一樣的3*3的卷積層堆疊在一起。這其實是非常有用的設計:3個3*3的卷積層串聯相當于1個7*7的卷積層,即一個像素會跟周圍7*7的像素產生關聯,可以說感受野大小是7*7。而且前者擁有比后者更少的參數量,3×3×37×7=55%3×3×37×7=55%。更重要的是,3個3*3的卷積層擁有比1個7*7的卷積層更多的線性變換(前者可以使用三次ReLU激活函數),使得CNN對特征的學習能力更強。
d) 訓練時有個小技巧:先訓練級別A的簡單網絡,再復用A網絡的權重初始化后幾個復雜模型,這樣訓練收斂的速度更快。
使用tensorflow實現VGGNet
參考網址:https://github.com/machrisaa/tensorflow-vgg
Google Inception Net
具有如下特點:
a)在控制了計算量和參數量的同時,獲得了非常好的分類性能。Inception V1有22層深,但其計算量只有15億次浮點運算,同時只有500萬的參數量,即為AlexNet參數量(6000萬)的1/12。為什么要降低參數量?第一,參數越多模型越龐大,(同樣深度下)需要供模型學習的數據量就越大,而目前高質量的數據又很貴;第二,參數越多,耗費的計算資源也越大。Inception V1參數少但效果好的原因之一就在于其模型參數更深、表達能力更強。b)去除了最后的全連接層,使用1*1的卷積層來替代,這樣是模型訓練更快并減輕了過擬合。關于這方面可參見:為什么使用卷積層替代CNN末尾的全連接層c)精心設計的Inception Module(Network In Network的思想)有選擇地保留不同層次的高階特征,最大程度地豐富網絡的表達能力。一般來說卷積層要提升表達能力,主要依靠增加輸出通道數(副作用是計算量大和過擬合)。因為每一個輸出通道對應一個濾波器,同一個濾波器共享參數只能提取一類特征,因此一個輸出通道只能做一種特征處理。Inception Module一般情況下有4個分支:第一個分支為1*1卷積(性價比很高,低成本(計算量小)的跨通道特征變換,同時可以對輸出通道升維和降維),第二個分支為1個1*1卷積再接分解后(factorized)的1*n和n*1卷積 (Factorization into small convolutions的思想),第三個分支和第二個類似但一般更深一些,第四個分支為最大池化(增加了網絡對不同尺度的適應性,Multi-Scale的思想)。因此Inception Module通過比較簡單的特征抽象(分支1)、比較復雜的特征抽象(分支2和分支3)和一個簡化結構的池化層(分支4)有選擇地保留不同層次的高階特征,這樣可以最大程度地豐富網絡的表達能力。
d) Inception V2提出了著名的Batch Normalization方法。BN用于神經網絡某層時,會對每一個mini-batch數據內部進行標準化(normalization)處理,是輸出規范化到N(0, 1)的正態分布,減少了Internal Covariate shift。關于這方面可參見:為什么會出現Batch Normalization層e) Inception V3引入了Factorization into small convolutions的思想,將一個較大的二維卷積拆成兩個較小的一維卷積。比如,將7*7卷積拆成1*7和7*1兩個卷積。這樣做節約了大量參數,加速運算并減輕了過擬合(比將7*7卷積拆成3個3*3卷積更節約參數);并且論文指出這種非對稱的卷積結構拆分比對稱地拆分為幾個相同的小卷積核效果更明顯,可以處理更多、更豐富的空間特征,增加特征多樣性。
使用tensorflow實現inception_v3
參考網址:https://github.com/tensorflow/models/blob/master/slim/nets/inception_v3.py
ResNet
這是一種新的網絡思想,說一下我自己的理解。
為什么會出現Residual Learning
人們觀察到一個典型現象:當網絡一直加深時,準確率會趨于峰值,然后再加深網絡準確率反而會下降(在訓練集和測試集上均是如此,這顯然就不是過擬合了)。ResNet作者把這種現象稱為degradation problem。
然后大家開始想,前向傳播過程中信息量越來越少是不錯,但也不至于逼近效果越來越差呀。聰明的小伙子(嚴肅來講應該是大神)He提出:把新增加的層變為恒等映射(identity mappings),這樣至少效果不會越來越差吧。既然網絡能擬合函數H(x),是不是也能同樣擬合H(x)-x。說干就干,實驗是檢驗真理的唯一標準。于是得出結論“擬合H(x)-x比直接擬合H(x)更簡單”(當然理論上他也有一套自己的解釋:如果我們想要得到的最優結果是x,擬合前者顯然更簡單,權重直接為0即可;雖然現實中我們想要的并非x,但我們想要的更應該接近x而非接近0吧)。哈哈,深度殘差網絡就這樣誕生了。
ResNet單元模塊
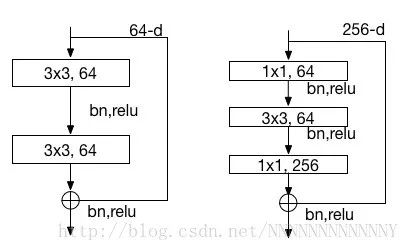
如上圖所示為兩種類型的block,block定義如下:
y=F(x,Wi)+xy=F(x,Wi)+x
對于block里只有兩個卷積的情況,
F=W2σ(W1x)F=W2σ(W1x)
上述公式里兩者相加存在一個問題:1. 各個維度相同,直接相加即可2. 維度不同(在第一張圖網絡的虛線處,feature map尺寸大小和通道數均發生變化),論文中說給x加個WsWs的映射。我的理解是對x加個池化(stride=2)即可滿足尺寸變化,然后再利用1*1小卷積升維即可。
ResNet網絡特點
a) 網絡較瘦,控制了參數數量;b) 存在明顯層級,特征圖個數逐層遞進,保證輸出特征表達能力;c)沒有使用Dropout,利用BN和全局平均池化進行正則化,加快了訓練速度;d) 層數較高時減少了3x3卷積個數,并用1x1卷積控制了3x3卷積的輸入輸出特征圖數量,稱這種結構為“瓶頸”(bottleneck)。參考:https://zhuanlan.zhihu.com/p/22447440
使用tensorflow實現Resnet_v2
參考網址:https://github.com/tensorflow/models/blob/master/slim/nets/resnet_v2.py
參考:1.以上相關模型的論文,這里就不貼了2.書籍《Tensorflow實戰》
-
神經網絡
+關注
關注
42文章
4811瀏覽量
103065 -
函數
+關注
關注
3文章
4374瀏覽量
64426
原文標題:幾種經典卷積神經網絡介紹
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
從AlexNet到ResNet的網絡架構進步

如何高效學習一門新技術
納米防水技術特點介紹(新技術)
手機的新技術盤點
PyTorch教程8.1之深度卷積神經網絡(AlexNet)


哪些材料需要使用到雙85恒溫恒濕試驗箱做測試






 工商網監
工商網監
評論