") 使用TensorFlow框架演示了卷積神經(jīng)網(wǎng)絡(luò)在MNIST數(shù)據(jù)集上的應(yīng)用
使用TensorFlow框架演示了卷積神經(jīng)網(wǎng)絡(luò)在MNIST數(shù)據(jù)集上的應(yīng)用
Google產(chǎn)品分析Zlatan Kremonic介紹了卷積神經(jīng)網(wǎng)絡(luò)的機(jī)制,并使用TensorFlow框架演示了卷積神經(jīng)網(wǎng)絡(luò)在MNIST數(shù)據(jù)集上的應(yīng)用。
卷積神經(jīng)網(wǎng)絡(luò)(CNN)是一種前饋人工神經(jīng)網(wǎng)絡(luò),其神經(jīng)元連接模擬了動物的視皮層。在圖像分類之類的計(jì)算機(jī)視覺任務(wù)中,CNN特別有用;不過,CNN也可以應(yīng)用于其他機(jī)器學(xué)習(xí)任務(wù),只要該任務(wù)中至少一維上的屬性的順序?qū)Ψ诸惗允潜夭豢缮俚摹@纾珻NN也用于自然語言處理和音頻分析。
CNN的主要組成部分是卷積層(convolutional layer)、池化層(pooling layer)、ReLU層(ReLU layer)、全連接層(fully connected layer)。
圖片來源:learnopencv.com
卷積層
卷積層從原輸入的三維版本開始,一般是包括色彩、寬度、高度三維的圖像。接著,圖像被分解為過濾器(核)的子集,每個(gè)過濾器的感受野均小于圖像總體。這些過濾器接著沿著輸入量的寬高應(yīng)用卷積,計(jì)算過濾器項(xiàng)和輸入的點(diǎn)積,并生成過濾器的二維激活映射。這使得網(wǎng)絡(luò)學(xué)習(xí)因?yàn)閭蓽y到輸入的空間位置上特定種類的特征而激活的過濾器。過濾器沿著整個(gè)圖像進(jìn)行“掃描”,這讓CNN具有平移不變性,也就是說,CNN可以處理位于圖像不同部分的物體。
接著疊加激活函數(shù),這構(gòu)成卷積層輸出的深度。輸出量中的每一項(xiàng)因此可以視作查看輸入的一小部分的神經(jīng)元的輸出,同一激活映射中的神經(jīng)元共享參數(shù)。
卷積層的一個(gè)關(guān)鍵概念是局部連通性,每個(gè)神經(jīng)元僅僅連接到輸入量中的一小部分。過濾器的尺寸,也稱為感受野,是決定連通程度的關(guān)鍵因素。
其他關(guān)鍵參數(shù)是深度、步長、補(bǔ)齊。深度表示創(chuàng)建的特征映射數(shù)目。步長控制每個(gè)卷積核在圖像上移動的步幅。一般將步長設(shè)為1,從而導(dǎo)向高度重疊的感受野和較大的輸出量。補(bǔ)齊讓我們可以控制輸出量的空間大小。如果我們用零補(bǔ)齊(zero-padding),它能提供和輸入量等高等寬的輸出。
圖片來源:gabormelli.com
池化層
池化是一種非線性下采樣的形式,讓我們可以在保留最重要的特征的同時(shí)削減卷積輸出。最常見的池化方法是最大池化,將輸入圖像(這里是卷積層的激活映射)分區(qū)(無重疊的矩形),然后每區(qū)取最大值。
池化的關(guān)鍵優(yōu)勢之一是降低參數(shù)數(shù)量和網(wǎng)絡(luò)的計(jì)算量,從而緩解過擬合。此外,由于池化去除了特定特征的精確位置的信息,但保留了該特征相對其他特征的位置信息,結(jié)果也提供了平移不變性。
最常見的池化大小是2 x 2(步長2),也就是從輸入映射中去除75%的激活。
圖片來源:Leonardo Araujo dos Santos
ReLU層
修正線性單元(Rectifier Linear Unit)層應(yīng)用如下激活函數(shù)
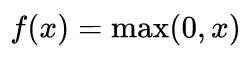
至池化層的輸出。它在不影響卷積層的感受野的前提下增加了整個(gè)網(wǎng)絡(luò)的非線性。當(dāng)然,我們也可以應(yīng)用其他標(biāo)準(zhǔn)的非線性激活函數(shù),例如tanh和sigmoid。
圖片來源:hashrocket.com
全連接層
獲取ReLU層的輸出,將其扁平化為單一向量,以便調(diào)節(jié)權(quán)重。

圖片來源:machinethink.net
使用TensorFlow在MNIST數(shù)據(jù)集上訓(xùn)練CNN
下面我們將展示如何在MNIST數(shù)據(jù)集上使用TensorFlow訓(xùn)練CNN,并達(dá)到接近99%的精確度。
首先導(dǎo)入需要的庫:
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import pandas as pd
import os
from datetime import datetime
from sklearn.utils import shuffle
編寫提供錯(cuò)誤率和預(yù)測響應(yīng)矩陣的基本輔助函數(shù):
def y2indicator(y):
N = len(y)
y = y.astype(np.int32)
ind = np.zeros((N, 10))
for i in range(N):
ind[i, y[i]] = 1
return ind
def error_rate(p, t):
return np.mean(p != t)
接下來,我們加載數(shù)據(jù),歸一化并重整數(shù)據(jù),并生成訓(xùn)練集和測試集。
data = pd.read_csv(os.path.join('Data', 'train.csv'))
def get_normalized_data(data):
data = data.as_matrix().astype(np.float32)
np.random.shuffle(data)
X = data[:, 1:]
mu = X.mean(axis=0)
std = X.std(axis=0)
np.place(std, std == 0, 1)
X = (X - mu) / std
Y = data[:, 0]
return X, Y
X, Y = get_normalized_data(data)
X = X.reshape(len(X), 28, 28, 1)
X = X.astype(np.float32)
Xtrain = X[:-1000,]
Ytrain = Y[:-1000]
Xtest = X[-1000:,]
Ytest = Y[-1000:]
Ytrain_ind = y2indicator(Ytrain)
Ytest_ind = y2indicator(Ytest)
在我們的卷積函數(shù)中,我們?nèi)〔介L為一,并通過設(shè)定padding為SAME確保卷積輸出的維度和輸入的維度相等。下采樣系數(shù)為二,在輸出上應(yīng)用ReLU激活函數(shù):
def convpool(X, W, b):
conv_out = tf.nn.conv2d(X, W, strides=[1, 1, 1, 1], padding='SAME')
conv_out = tf.nn.bias_add(conv_out, b)
pool_out = tf.nn.max_pool(conv_out, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
return tf.nn.relu(pool_out)
初始化權(quán)重的方式是隨機(jī)正態(tài)分布取樣/sqrt(扇入+扇出)。這里的關(guān)鍵是隨機(jī)權(quán)重的方差受限于數(shù)據(jù)集大小。
def init_filter(shape, poolsz):
w = np.random.randn(*shape) / np.sqrt(np.prod(shape[:-1]) + shape[-1]*np.prod(shape[:-2] / np.prod(poolsz)))
return w.astype(np.float32)
我們定義梯度下降參數(shù),包括迭代數(shù),batch尺寸,隱藏層數(shù)量,分類數(shù)量,池尺寸。
max_iter = 6
print_period = 10
N = Xtrain.shape[0]
batch_sz = 500
n_batches = N / batch_sz
M = 500
K = 10
poolsz = (2, 2)
初始化過濾器,注意TensorFlow的維度順序。
W1_shape = (5, 5, 1, 20) # (filter_width, filter_height, num_color_channels, num_feature_maps)
W1_init = init_filter(W1_shape, poolsz)
b1_init = np.zeros(W1_shape[-1], dtype=np.float32) # one bias per output feature map
W2_shape = (5, 5, 20, 50) # (filter_width, filter_height, old_num_feature_maps, num_feature_maps)
W2_init = init_filter(W2_shape, poolsz)
b2_init = np.zeros(W2_shape[-1], dtype=np.float32)
W3_init = np.random.randn(W2_shape[-1]*7*7, M) / np.sqrt(W2_shape[-1]*7*7 + M)
b3_init = np.zeros(M, dtype=np.float32)
W4_init = np.random.randn(M, K) / np.sqrt(M + K)
b4_init = np.zeros(K, dtype=np.float32)
接著,我們定義輸入變量和目標(biāo)變量,以及將在訓(xùn)練過程中更新的變量:
X = tf.placeholder(tf.float32, shape=(batch_sz, 28, 28, 1), name='X')
T = tf.placeholder(tf.float32, shape=(batch_sz, K), name='T')
W1 = tf.Variable(W1_init.astype(np.float32))
b1 = tf.Variable(b1_init.astype(np.float32))
W2 = tf.Variable(W2_init.astype(np.float32))
b2 = tf.Variable(b2_init.astype(np.float32))
W3 = tf.Variable(W3_init.astype(np.float32))
b3 = tf.Variable(b3_init.astype(np.float32))
W4 = tf.Variable(W4_init.astype(np.float32))
b4 = tf.Variable(b4_init.astype(np.float32))
定義前向傳播過程,然后使用RMSProp加速梯度下降過程。
Z1 = convpool(X, W1, b1)
Z2 = convpool(Z1, W2, b2)
Z2_shape = Z2.get_shape().as_list()
Z2r = tf.reshape(Z2, [Z2_shape[0], np.prod(Z2_shape[1:])])
Z3 = tf.nn.relu( tf.matmul(Z2r, W3) + b3 )
Yish = tf.matmul(Z3, W4) + b4
cost = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits = Yish, labels = T))
train_op = tf.train.RMSPropOptimizer(0.0001, decay=0.99, momentum=0.9).minimize(cost)
# 用于計(jì)算錯(cuò)誤率
predict_op = tf.argmax(Yish, 1)
我們使用標(biāo)準(zhǔn)的訓(xùn)練過程,不過,當(dāng)在測試集上做出預(yù)測時(shí),由于RAM限制我們需要固定輸入尺寸;因此,我們加入的計(jì)算總代價(jià)和預(yù)測的函數(shù)稍微有點(diǎn)復(fù)雜。
t0 = datetime.now()
LL = []
init = tf.initialize_all_variables()
with tf.Session() as session:
session.run(init)
for i in range(int(max_iter)):
for j in range(int(n_batches)):
Xbatch = Xtrain[j*batch_sz:(j*batch_sz + batch_sz),]
Ybatch = Ytrain_ind[j*batch_sz:(j*batch_sz + batch_sz),]
if len(Xbatch) == batch_sz:
session.run(train_op, feed_dict={X: Xbatch, T: Ybatch})
if j % print_period == 0:
test_cost = 0
prediction = np.zeros(len(Xtest))
for k in range(int(len(Xtest) / batch_sz)):
Xtestbatch = Xtest[k*batch_sz:(k*batch_sz + batch_sz),]
Ytestbatch = Ytest_ind[k*batch_sz:(k*batch_sz + batch_sz),]
test_cost += session.run(cost, feed_dict={X: Xtestbatch, T: Ytestbatch})
prediction[k*batch_sz:(k*batch_sz + batch_sz)] = session.run(
predict_op, feed_dict={X: Xtestbatch})
err = error_rate(prediction, Ytest)
if j == 0:
print("Cost / err at iteration i=%d, j=%d: %.3f / %.3f" % (i, j, test_cost, err))
LL.append(test_cost)
print("Elapsed time:", (datetime.now() - t0))
plt.plot(LL)
plt.show()
輸出:
Cost / err at iteration i=0, j=0: 2243.417 / 0.805
Cost / err at iteration i=1, j=0: 116.821 / 0.035
Cost / err at iteration i=2, j=0: 78.144 / 0.029
Cost / err at iteration i=3, j=0: 57.462 / 0.018
Cost / err at iteration i=4, j=0: 52.477 / 0.015
Cost / err at iteration i=5, j=0: 48.527 / 0.018
Elapsed time: 0:09:16.157494
結(jié)語
如我們所見,模型在測試集上的表現(xiàn)在98%到99%之間。在這個(gè)練習(xí)中,我們沒有進(jìn)行任何超參數(shù)調(diào)整,但這是很自然的下一步。我們也可以增加正則化、動量、dropout。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102985 -
圖像分類
+關(guān)注
關(guān)注
0文章
96瀏覽量
12120 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25309
原文標(biāo)題:卷積神經(jīng)網(wǎng)絡(luò)簡明教程
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論