 數據庫高可用容災方案設計和實現
數據庫高可用容災方案設計和實現
現如今已經進入大數據時代,各種系統、應用、活動所產生的數據浩如煙海,數據不再僅僅是企業存儲的信息,而是成為可以從中獲取巨大商業價值的企業戰略資產。這樣背景下,如何存儲海量復雜的數據、從紛繁錯綜的數據中找到真正有價值的數據,是大數據時代企業面臨的難題。
8月18日的“UCan下午茶”杭州站,來自UCloud、網易、華為的五位技術專家,從數據庫高可用容災方案設計和實現、新一代公有云分布式數據庫、基于Impala平臺打造交互查詢系統等不同維度出發,分享了他們在大數據查詢、分析、存儲開發過程中遇到的“困惑”與解決方案。
數據庫高可用容災方案設計和實現
高可用容災是搭建數據庫服務的一個重要考量特性,搭建高可用數據庫服務需要解決諸多問題,保證最終的容災效果。UCloud云數據庫產品UDB在研發演進過程中,根據用戶的需要不斷完善和演進,形成了一套完善的高可用架構體系。
UCloud資深存儲研發工程師丁順從高可用數據庫概述、典型的高可用架構分析以及高可用數據庫自動化運維等角度,講述了如何設計和運營一套完善的數據庫高可用架構,保證在出現異常時能夠及時恢復數據庫服務。
高可用數據庫由一系列的數據庫構成了總的系統,在任何時刻至少有一個節點可以接受客戶端請求,提供數據庫服務。大多數的高可用架構有一個主節點處理主要請求,還有若干備用節點,當主節點不能提供服務時,備節點成為主節點繼續提供服務,這樣可以保證整個系統的可用和穩定。
業界典型的高可用架構可以劃分為四種:第一種,共享存儲方案;第二種,操作系統實時數據塊復制;第三種,數據庫級別的主從復制;第三,高可用數據庫集群。每種數據同步方式可以衍生出不同的架構。
第一種,共享存儲。共享存儲是指若干DB服務使用同一份存儲,一個主DB,其他的為備用DB,若主服務崩潰,則系統啟動備用DB,成為新的主DB,繼續提供服務。一般共享存儲采用比較多的是SAN/NAS方案,這種方案的優點是沒有數據同步的問題,缺點是對網絡性能要求比較高。
第二種,操作系統實時數據塊復制。這種方案的典型場景是DRBD。如下圖所示,左邊數據庫寫入數據以后立即同步到右邊的存儲設備當中。如果左邊數據庫崩潰,系統直接將右邊的數據庫存儲設備激活,完成數據庫的容災切換。這個方案同樣有一些問題,如系統只能有一個數據副本提供服務,無法實現讀寫分離;另外,系統崩潰后需要的容災恢復時間較長。
第三種,數據庫主從復制。這種方案是較經典的數據同步模式,系統采用一個主庫和多個從庫,主庫同步數據庫日志到各個從庫,從庫各自回放日志。它的好處是一個主庫可以連接多個從庫,能很方便地實現讀寫分離,同時,因為每個備庫都在啟動當中,所以備庫當中的數據基本上都是熱數據,容災切換也非常快。
第四種,數據庫高可用集群。前面三種是通過復制日志的模式實現高可用,第四種方案是基于一致性算法來做數據同步。數據庫提供一種多節點的一致性同步機制,然后利用該機制構建多節點同步集群,這是業界近年來比較流行的高可用集群的方案。
UCloud綜合了原生MySQL兼容,不同版本、不同應用場的覆蓋等多種因素,最終選擇采用基于數據庫主從復制的方式實現高可用架構,并在原架構基礎上,使用雙主架構、半同步復制、采用GTID等措施進行系列優化,保證數據一致性的同時,實現日志的自動尋址。
自動化運維是高可用數據庫當中的難點,UDB在日常例行巡檢之外,也會定期做容災演練,查看在不同場景下數據是否丟失、是否保持一致性等,同時設置記錄日志、告警系統等等,以便于第一時間發現問題,并追溯問題的根源,找出最佳解決方案。
新一代公有云分布式數據庫UCloud Exodus
公有云2.0時代,云數據庫新產品不斷涌現。諸如AWS Aurora、阿里云PolarDB等,UCloud在采用最新軟硬件和分布式技術改造傳統數據庫的工作中,也在思考除了分布式數據庫所要求的更大和更快之外,是否還有其他更重要的用戶價值?UCloud資深數據庫研發工程師劉堅君,現場講解了UCloud對于新一代公有云分布式數據庫的思考與設計。
劉堅君首先從1.0時代存在的問題入手,他認為1.0時代云數據庫帶來了三方面價值:彈性、故障救援、知識復用。但它同樣面臨三大難以解決的問題:容量和性能、租用成本、運營成本。
到2.0時代,解決上述三個問題的思路是計算和讀寫分離。通過計算和讀寫分離,將傳統數據庫的計算層和存儲層拆開,各自獨立擴展和演進。這樣做的好處是:1.提供更大的容量和讀寫性能;2.按需擴容和付費;3.優化運營成本并降低運營風險。業界已推出的2.0云數據庫(如Aurora、PolarDB等),均采用計算和存儲分離的架構。
UCloud Exodus的產品和技術理念則更進一步:計算和存儲分離后,存儲層將完全復用云平臺的高性能分布式存儲(如UCloud UDisk、阿里云盤古等),而Exodus則專注于構建一款數據庫內核,去適配主流公有云和私有云廠商發布的高性能分布式存儲產品。Exodus的這種產品架構,稱之為Shared-ALL-DISK架構。
Shared-ALL-DISK架構的優點明顯,在提供云數據庫2.0創新功能的同時,賦予用戶業務自由遷徙的能力,不被某個云平臺綁架,同時能夠連接上下游的軟硬件廠商,共建Exodus數據庫生態。
更為重要的是,Exodus將最終將開源,UCloud會將核心系統的每一行源碼開放,賦予用戶深入了解和優化Exodus的能力。并建設開源社區,吸收全行業的優化成果,共同改進和完善Exodus。
基于Impala平臺打造交互查詢系統
在數據分析當中,因為數據基數龐大、關系模型復雜、響應時間要求高等特性,數據之間的交互查詢就顯得尤為重要。來自網易的大數據技術專家蔣鴻翔現場從交互式查詢特點著手,深入淺出講解了Impala架構、原理,以及網易對Impala的改進思路和使用場景。
Impala是Cloudera公司主導開發的新型查詢系統,它提供SQL語義,能查詢存儲在Hadoop的HDFS和HBase中的PB級大數據。已有的Hive系統雖然也提供了SQL語義,但由于Hive底層執行使用的是MapReduce引擎,仍然是一個批處理過程,難以滿足查詢的交互性。相比之下,Impala能夠很快速的實現數據查詢。下圖是一個Impala的架構圖。
Impala擁有元數據緩存、MPP并行計算、支持LLVM與JIT以及支持HDFS本地讀、算子下推等特性。但它也有一些缺陷,如服務單點、Web信息無法持久化、資源隔離并不精確、負載均衡需要外部支持等。
網易針對上述不足之處,在原有的Impala查詢系統下,進行了系列改進優化:
基于ZK的Loadbalance。原始的Impala負載均衡需要外部支持,為此網易基于ZK做了一個Loadbalance方案;
管理服務器。主要為了解決當某一個節點掛掉時數據丟失的問題,管理服務器會將所有的狀態信息搜集進來,后續如果做分析都可以通過關聯的服務器查詢;
細粒度權限和代理;
Json格式;
兼容Ranger權限管理;
批量元數據刷新;
元數據同步;
元數據過濾;
對接ElasticSearch查詢。
據蔣鴻翔介紹,改造后的交互查詢系統,已經成功應用于網易數據科學中心的一站式大數據平臺自助查詢系統上。同時,數據分析中心的一站式報表系統底層,也搭載在Impala上。相信未來,基于Impala的查詢系統將會應用于更多不同的場景。
UCloud分布式KV存儲系統
分布式KV存儲系統在互聯網公司中扮演著重要角色,各類上層業務對于KV存儲系統的高可用性、可擴展性和數據一致性都有著很高的要求。UCloud存儲部門在迭代升級分布式Redis架構的同時,也一直致力于研發基于硬盤存儲的大容量分布式KV系統。來自UCloud的技術專家王仆,著重介紹了UCloud在大容量分布式KV系統設計方面的經驗,以及應對線上業務高性能、高容量要求的系統架構設計思路。
下圖為UCloud分布式KV存儲系統架構,底層為多個Storage,每一個Storage有三個節點,這三個節點需要放在不同的物理機上,防止一臺機器宕機后系統不可用;標紅框的屬于Master節點,Master節點通過日志同步的方式,同步到層節點,整個數據的請求從Proxy進入。
整個系統是有中心節點的系統,路由管理由Master來管理,Master通過每個機器上的Host管理Storage節點,由Zookeeper確定誰是主誰是從,因此,一些管理方面的請求都是直接連接到Master上的,包括創建、刪除和控制臺方面的功能等。
在測試過程中也發現了一些性能方面的問題,如采用的部分Raft協議是單Raft,設計之初并沒有實現并行Raft功能,因此數據同步較慢;其次,請求是通過代理的方式實現,代理的延遲會比直接訪問的延遲更高,后期,會考慮提供一些客戶端的SDK,讓請求可以跳過代理,減少一次網絡交互。
在KV系統的后續優化上,王仆介紹到,為了能夠將存儲系統應用于更多不同的業務場景,未來會考慮更高的通用性,適配多種的存儲引擎;另外,因為Redis比較流行,系統設計之初主要是支持Redis,但是業界還有一些其他協議,這時候需要特殊的轉化流程,未來希望做成一個支持各種協議的通用結構化存儲系統,適配其他不同協議。
實時流計算技術及其應用
隨著Flink/Spark Streaming的大受歡迎,實時流計算開始為人熟知,進入大眾視野。流計算在物聯網行業、車聯網、智慧城市等行業快速落地,亦創造出越來越多的價值。來自華為的架構師時金魁,現場分享了實時流計算的一些技術方案和落地應用。
在傳統的數據處理流程中,總是先收集數據,然后將數據放到DB中。當人們需要的時候通過DB對數據做query,得到答案或進行相關的處理。這個流程看起來雖然合理,但是結果卻非常的緊湊,尤其是對于一些實時搜索應用環境中的某些具體問題,類似于MapReduce方式的離線處理并不能很好地解決問題。這就引出了一種新的數據計算結構---流計算方式。它可以很好地對大規模流動數據在不斷變化的運動過程中實時地進行分析,捕捉到可能有用的信息,并把結果發送到下一計算節點。
目前,業界開源的流計算框架很多,最早有Storm、Heron,后來還有Akka,Beam,以及現在的Kafka等等。在諸多的開源框架中,時金魁認為,Flink是最恰當的流計算框架,Spark Streaming則是最有潛力的流計算框架,但這兩個框架在落地應用中都有各自的優缺點。
華為根據Flink與Spark框架各自的特點,摒棄其劣勢,設計開發出一款全新的實時流計算服務Cloud Stream Service(簡稱CS)。CS采用Apache Flink的Dataflow模型,實現完全的實時計算,同時,采用在線SQL編輯平臺編寫Stream SQL,定義數據流入、數據處理、數據流出,用戶無需關心計算集群, 無需學習編程技能,降低流數據分析門檻。下圖為華為的實時流計算服務概覽圖。
據介紹,CS聚焦于互聯網和物聯網場景,適用于實時性要求高、吞吐量大的業務場景。主要應用在互聯網行業中小企業、物聯網、車聯網、金融反欺詐等多種行業應用場景,如互聯網汽車、日志在線分析、在線機器學習、在線圖計算、在線推薦算法應用等。
總結
雖然說開源軟件因為其強大的成本優勢而擁有極其強大的力量,數據庫、云計算廠商仍會嘗試推出性能、穩定性、維護服務等指標上更加強大的產品與之進行差異化競爭,并同時參與開源社區,借力開源軟件來豐富自己的產品線、提升自己的競爭力,并通過更多的高附加值服務來滿足部分消費者需求。
總的來看,未來的大數據分析技術、存儲將會變得越來越成熟、越來越便宜、越來越易用,相應的,用戶將會更容易、更方便地從自己的大數據中挖掘出有價值的商業信息。
-
數據庫
+關注
關注
7文章
3904瀏覽量
65826 -
大數據
+關注
關注
64文章
8952瀏覽量
139599
原文標題:企業該如何做大數據的分析挖掘?這里有一份參考指南
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
介紹三種常見的MySQL高可用方案
SQLSERVER數據庫是什么
MySQL數據庫是什么
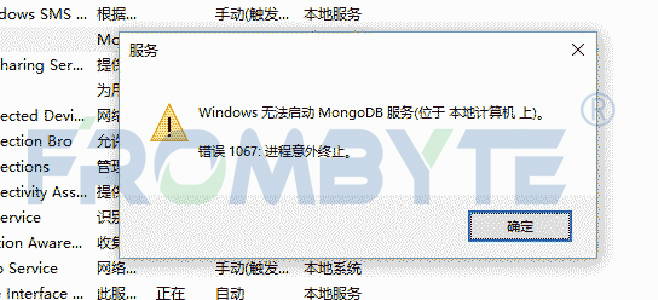
數據庫數據恢復——MongoDB數據庫文件拷貝后服務無法啟動的數據恢復
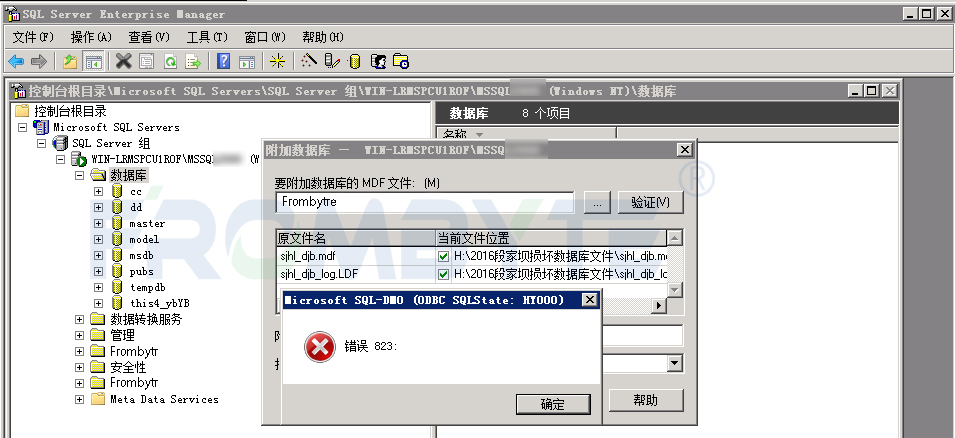
數據庫數據恢復—SQL Server附加數據庫提示“錯誤 823”的數據恢復案例
Oracle推出創新數據庫服務
MySQL數據庫的安裝
云數據庫是哪種數據庫類型?
數據庫數據恢復—Mysql數據庫表記錄丟失的數據恢復流程

數據庫數據恢復—MYSQL數據庫ibdata1文件損壞的數據恢復案例
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

云數據庫可以租用嗎?完整租用流程來了
一文講清什么是分布式云化數據庫!
Oracle數據恢復—異常斷電后Oracle數據庫啟庫報錯的數據恢復案例
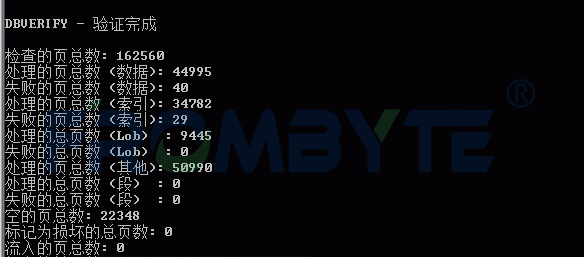
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例






 工商網監
工商網監
評論