") 基于C55x DSP核芯片實(shí)現(xiàn)基帶信號(hào)處理系統(tǒng)的設(shè)計(jì)
基于C55x DSP核芯片實(shí)現(xiàn)基帶信號(hào)處理系統(tǒng)的設(shè)計(jì)
一、 引言
DSP芯片,也稱數(shù)字信號(hào)處理器,是一種特別適合于進(jìn)行數(shù)字信號(hào)處理的微處理器。我們?cè)谶M(jìn)行產(chǎn)品的開(kāi)發(fā)過(guò)程中,往往需要對(duì)信號(hào)進(jìn)行實(shí)時(shí)處理,就是指系統(tǒng)必須在有限的時(shí)間內(nèi)對(duì)外部輸入的信號(hào)完成指定的處理功能,也就是說(shuō)信號(hào)處理速度應(yīng)大于信號(hào)更新的速度,而DSP芯片的處理器結(jié)構(gòu)、指令系統(tǒng)和數(shù)據(jù)流程方式,使其很容易滿足實(shí)時(shí)信號(hào)處理的要求。DSP的應(yīng)用幾乎已遍及電子與信息的每一個(gè)領(lǐng)域,本文沒(méi)有必要對(duì)其應(yīng)用一一羅列,也不打算再花不必要的篇幅來(lái)介紹DSP的結(jié)構(gòu)和原理,因?yàn)檫@方面的書籍和資料也較多。本文結(jié)合作者基于TI公司C5510系列DSP負(fù)責(zé)完成的某國(guó)防科研項(xiàng)目的基帶信號(hào)處理的一點(diǎn)感悟,談?wù)凜55x系列DSP在基帶信號(hào)處理中的應(yīng)用和實(shí)現(xiàn),因?yàn)槟壳敖榻BC54x系列DSP的資料已不少,而介紹C55x系列DSP的書籍和資料卻相對(duì)太少。雖然C55x和C54x都屬于TI的C5000系列的產(chǎn)品,很多書籍往往僅以“C54x與C55x在軟件上完全兼容”來(lái)一筆代過(guò)。但對(duì)于一個(gè)DSP開(kāi)發(fā)者來(lái)說(shuō),卻不是這么簡(jiǎn)單的事,我們考慮的不僅僅是其功能的實(shí)現(xiàn),也好考慮如何去優(yōu)化和利用資源。所以有必要研究一下C55x在C54x基礎(chǔ)上的改進(jìn)功能,探討一下C55x的應(yīng)用問(wèn)題。
二、 C55x與C54x比較
C54x系列是針對(duì)低功耗、高性能的高速實(shí)時(shí)信號(hào)處理而專門設(shè)計(jì)的定點(diǎn)DSP,廣泛應(yīng)用于無(wú)線通信系統(tǒng)中,它的CPU具有下列特征:
⑴ 采用改進(jìn)的哈佛結(jié)構(gòu),一條程序總線(PB)、三條數(shù)據(jù)總線(CB、DB、EB)和四條地址總線(PAB、CAB、DAB、EAB);
⑵ 40bit的算術(shù)邏輯單元(ALU)以及一個(gè)40bit的移位器和兩個(gè)40bit的累加器(A、B),支持32bit或雙16bit的運(yùn)算。
⑶ 17bit×17bit的硬件乘法器和一個(gè)40bit專用加法器的組合(MAC)可以在一個(gè)周期內(nèi)完成乘加運(yùn)算;
⑷ 比較、選擇和存儲(chǔ)等單元能夠加速維特比譯碼的執(zhí)行。
⑸ 專用的指數(shù)編碼器(EXP encoder)能夠在一個(gè)周期內(nèi)完成累加器中40bit數(shù)值的指數(shù)運(yùn)算。
⑹單獨(dú)的數(shù)據(jù)地址產(chǎn)生單元(DAGEN)和程序地址(PAGEN)產(chǎn)生單元,能夠同時(shí)進(jìn)行三個(gè)讀操作和一個(gè)些操作。
C55x通過(guò)增加功能單元,與C54x相比,其綜合性能提高了5倍,而功耗僅為C54x的1/6。C55x采用變長(zhǎng)指令以提高代碼效率,增強(qiáng)并行機(jī)制以提高循環(huán)效率,不僅僅增加了硬件資源,也優(yōu)化了資源的管理,所以性能得到了大大的提高,其處理能力可達(dá)400~800MIPS。C55x在CPU的功能單元方面作了如下擴(kuò)展:
⑴ 總線增加了兩條,一條讀操作線(BB),一條寫操作線(FB);
⑵ 乘加單元(MAC)增加了一個(gè);
⑶ 增加了一個(gè)16bit的ALU;
⑷ 將累加器增至4個(gè),即AC0、AC1、AC2和AC3;
⑸ 臨時(shí)寄存器增至4個(gè),即T0、T2、T2和T3;
由于結(jié)構(gòu)上的變化,我們?cè)谙到y(tǒng)設(shè)計(jì)中必須注意C55x和C54x寄存器的變化關(guān)系,尤其是當(dāng)我們?cè)贑55x設(shè)計(jì)中采用與C54x的兼容模式,而不是增強(qiáng)模式,這更為重要。下表為C54x和C55x的寄存器對(duì)應(yīng)關(guān)系。

C55x雖然也能兼容C54x,在C55x DSP上也能運(yùn)行C54x的指令,但C55x與C54x又是不同的,C55x在指令上作了較大的簡(jiǎn)化。比如,相對(duì)C54x的裝載(LD)與存儲(chǔ)(ST),C55x用更加靈活易用的MOVE操作指令來(lái)實(shí)現(xiàn)裝載和存儲(chǔ),將MOVE操作的范圍擴(kuò)大到數(shù)據(jù)交換、堆棧操作等。另外,在兼容模式中,我們要注意XC、SACCD和ARx+0等情況的使用。
三、 C5510 在基帶信號(hào)處理中的應(yīng)用
下面結(jié)合作者參加的某國(guó)防項(xiàng)目具體談?wù)凜5510在通信系統(tǒng)的基帶信號(hào)處理中的應(yīng)用和實(shí)現(xiàn),由于篇幅所限,僅給出程序流程圖,源代碼略。
1.基帶信號(hào)處理中DSP的任務(wù)
本系統(tǒng)基帶信號(hào)的處理中,DSP主要完成對(duì)數(shù)據(jù)進(jìn)行加擾和解擾、卷積編碼和VITERBI譯碼、交織和解交織、成幀(或子幀)和拆幀等處理。首先,針對(duì)主傳數(shù)據(jù)進(jìn)行隨機(jī)化加擾(采用外同步預(yù)置式,使用n=17級(jí)的m序列),再進(jìn)行(2,1,7)卷積編碼,約束長(zhǎng)度K=7的卷積碼,生成多項(xiàng)式為(用8進(jìn)制表示):1+D+D^2+D^3+D^6=(171),八進(jìn)制g1=171,G1=1+D^2+D^3+D^5+D^6=(133),八進(jìn)制,g2=133,故每次編碼前需加尾比特K-1=6位。編碼后一子幀內(nèi)的比特?cái)?shù)為50(考慮了在一個(gè)大幀范圍內(nèi)對(duì)控制信息比特所占傳輸速率的補(bǔ)償)。再加上每個(gè)子幀的控制信息比特(如子幀數(shù)據(jù)類型比特)后,一個(gè)子幀的有效比特?cái)?shù)為56,然后經(jīng)過(guò)7×8的分組塊交織,加上8比特同步保護(hù)碼,最終成為一個(gè)64bit的子幀,經(jīng)緩存等處理后送給調(diào)制器。
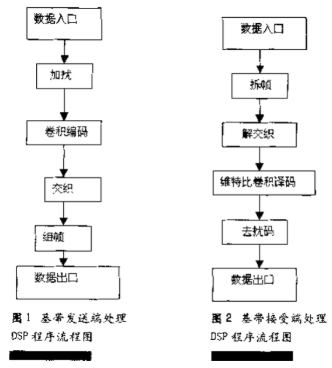
2.基于C5510基帶信號(hào)處理實(shí)現(xiàn)
A.數(shù)據(jù)加擾與解擾
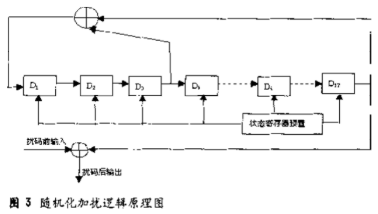
加擾使用n=17級(jí)的m序列來(lái)實(shí)現(xiàn),其生成多項(xiàng)式的8進(jìn)制表示為g=400011,多項(xiàng)式f(x)=x17+x3+1,有三個(gè)反饋抽頭。并采用外同步預(yù)置式,減少誤碼擴(kuò)散。每傳送一個(gè)大幀(含20個(gè)子幀),觸發(fā)預(yù)置式脈沖一次,脈沖預(yù)置可用軟件方式實(shí)現(xiàn)。加擾、解擾邏輯原理如圖3所示,加擾和去擾只需循環(huán)使用C55x的XOR src,dst就可以解決,因而不需詳說(shuō)。
B.卷積編解碼
采用了性能相對(duì)比分組碼好的卷積碼(2,1,7),其限制長(zhǎng)度K=7,生成多項(xiàng)式(8進(jìn)制表示)G0=171,G1=133,自由距離df=10,漸近編碼增益Gh=3.98dB。卷積碼編碼器的原理示意圖如下圖所示。
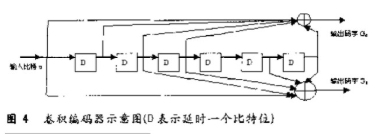
卷積編碼器的輸出序列是G0 G1 G0 G1 G0 G1.。..。.,在DSP C5510編程中,可以采用指令BFXPA來(lái)完成輸出序列的排列這樣就可以在程序中多次調(diào)用這個(gè)宏文件,從而簡(jiǎn)化和縮短源程序,具體實(shí)現(xiàn)時(shí)可以定義一個(gè)宏:
merge .macro src1,src2,temp,dst ;宏定義
BFXPA #5555h,src1,temp ;抽取src1偶數(shù)位置的比特位
BFXPA #0AAAAh,src2,temp ;抽取src2奇數(shù)位置的比特位
XOR temp,dst ;兩者取異或運(yùn)算
SFTL src1,#-8,src1 ;src1右移8位
SFTL src2,#-8,src2 ;src2也右移8位
.endm
卷積碼譯碼采用最大似然譯碼器—維特比譯碼。其流程如圖5所示。
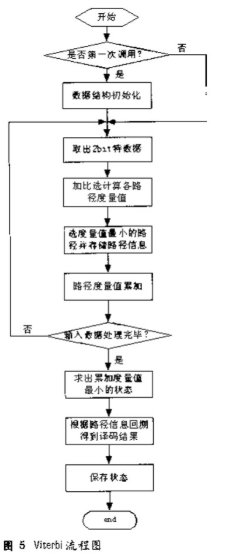
其算法思想是:
① 從時(shí)間單位j=m開(kāi)始,計(jì)算進(jìn)入每一狀態(tài)的單個(gè)路徑的部分量度并存貯量度的路徑及其量度。這樣的路徑稱為幸存路徑。
② j增加1,將進(jìn)入某一狀態(tài)部分分量度與前一時(shí)間單元有關(guān)的幸存路徑的量度相加。計(jì)算進(jìn)入該狀態(tài)所有路徑的部分量度。對(duì)每一狀態(tài)存貯具有最大量度的路徑,即幸存路徑及其量度,刪去所有其他的路徑。
③ 若j《(L+m),重復(fù)步驟②,否則就停止。此處L為碼字長(zhǎng),m=6。
對(duì)分支度量值得計(jì)算采用軟判決,也即歐氏距離,對(duì)于編碼速率為1/2的卷積碼,它的分支度量值為:
T=SD0 G0 (j)+ SD1 G1 (j)
為了計(jì)算的簡(jiǎn)便,Gn (j)用雙極性表示,0用+1表示、1用-1表示,或相反,這樣分支度量值的計(jì)算就可以簡(jiǎn)化為數(shù)據(jù)的加和減。在DSP實(shí)現(xiàn)過(guò)程中就可以分別用寄存器來(lái)表示:
T0: + SD0 + SD1
T1: + SD0 -SD1
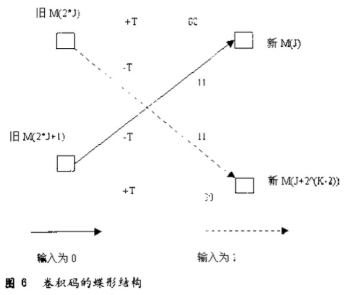
在C55x中可以用特殊應(yīng)用指令ADDSUB、SUBADD和MAXDIFF來(lái)完成各個(gè)狀態(tài)路徑度量值的累加、比較和選擇,而且可以充分運(yùn)用C55x的流水線處理優(yōu)勢(shì)。為了方便調(diào)用,可以將利用流水線處理的維特比蝶形運(yùn)算定義為一個(gè)宏。
C.交織與解交織
一般的糾錯(cuò)編碼是針對(duì)隨機(jī)性錯(cuò)誤的,但在無(wú)線信道中產(chǎn)生的錯(cuò)誤多屬于突發(fā)性差錯(cuò),因此我們使用了交織技術(shù),將突發(fā)性差錯(cuò)離散成隨機(jī)差錯(cuò),實(shí)際上是一種隱分集技術(shù),可獲得抗深度衰落的效果。但交織對(duì)系統(tǒng)會(huì)帶來(lái)時(shí)延上的影響,綜合考慮系統(tǒng)的糾錯(cuò)性能與復(fù)雜性,采用了一個(gè)子幀中56bit進(jìn)行分組塊交織的方式。如用矩陣形式處理,即在發(fā)端以行寫入,收端以列讀出。當(dāng)然也可發(fā)端以列寫入,收端以行讀出。
在C55x中實(shí)現(xiàn)交織時(shí),可以用AR0指向待交織數(shù)據(jù)的輸入緩沖地址,AR1指向交織表,AR2指向完成交織的數(shù)據(jù)的地址。AR1每次加1,對(duì)應(yīng)于AR2所指交織數(shù)據(jù)字的比特位置也加1,指向的內(nèi)容是輸入緩沖區(qū)的地址偏移量,此偏移量指向的比特就是需要交織到AR2指向字的比特位置。程序的重要結(jié)構(gòu)相當(dāng)于有兩層循環(huán),在外層循環(huán)中指針AR2每次加1,對(duì)應(yīng)內(nèi)層循環(huán)執(zhí)行16次。去交織是交織的逆過(guò)程,需要使用相同的的交織表,程序結(jié)構(gòu)也和交織大致相同,但比特搬移方向相反,因而在編程實(shí)現(xiàn)過(guò)程中,只需將交織程序稍加修改就可以。
四、 總結(jié)
隨著DSP技術(shù)的迅猛發(fā)展,芯片集成度的提高也使DSP芯片成本降低,這使DSP的需求上升和應(yīng)用領(lǐng)域的擴(kuò)展,DSP已從軍用轉(zhuǎn)向民用,在整個(gè)電子信息領(lǐng)域得到了廣泛的應(yīng)用,越來(lái)越多的人開(kāi)始或從事DSP的設(shè)計(jì)和研發(fā)。我們知道,現(xiàn)代通信系統(tǒng)中的數(shù)字化、寬帶化、智能化和多媒體化要求都對(duì)信號(hào)的處理提出了很高的要求,一片DSP往往只能進(jìn)行物理層處理,而不能完成處理控制和高層信令,因此DSP有必要與另外的處理器相結(jié)合。TI 公司將C55x DSP核與控制性能強(qiáng)的ARM9微處理器結(jié)合起來(lái),推出了開(kāi)放式多媒體應(yīng)用平臺(tái)(OMAP)。可以預(yù)計(jì),DSP與其它微處理器的結(jié)合是DSP未來(lái)的發(fā)展方向。
責(zé)任編輯:gt
-
dsp
+關(guān)注
關(guān)注
554文章
8059瀏覽量
350447 -
芯片
+關(guān)注
關(guān)注
456文章
51192瀏覽量
427297 -
編碼器
+關(guān)注
關(guān)注
45文章
3669瀏覽量
135251
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于DSP的圖像處理系統(tǒng)的應(yīng)用研究
基于ARM和DSP的3G移動(dòng)終端基帶信號(hào)處理器
基于C55x DSP核芯片實(shí)現(xiàn)基帶信號(hào)處理系統(tǒng)的設(shè)計(jì)方案解析
TMS320C55x DSP是什么?有什么應(yīng)用?
基于DSP和DSP/BIOS的實(shí)時(shí)雷達(dá)信號(hào)采集與處理系統(tǒng)
基帶信號(hào)處理子系統(tǒng)
TDRSS基帶信號(hào)處理系統(tǒng)的FPGA實(shí)現(xiàn)
DSP+FPGA實(shí)現(xiàn)語(yǔ)音基帶處理系統(tǒng)
TMS320C55x DSP并行處理技術(shù)分析
TMS320VC55X的DSP的多通道緩沖串口(MCBSP)的詳細(xì)資料概述

TMS320C55x EMIF號(hào)和DSP與各種類型的必要信號(hào)連接SDRAM的討論

定點(diǎn)DSP C55x音頻專用處理器嵌入式教學(xué)

基于OMAP5910雙核處理器實(shí)現(xiàn)實(shí)時(shí)圖像處理系統(tǒng)的應(yīng)用設(shè)計(jì)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論