 樸素貝葉斯分類算法并實現中文數據集的輿情分析案例
樸素貝葉斯分類算法并實現中文數據集的輿情分析案例
本文主要講述樸素貝葉斯分類算法并實現中文數據集的輿情分析案例,希望這篇文章對大家有所幫助,提供些思路。內容包括:
1.樸素貝葉斯數學原理知識
2.naive_bayes用法及簡單案例
3.中文文本數據集預處理
4.樸素貝葉斯中文文本輿情分析
本篇文章為基礎性文章,希望對你有所幫助,如果文章中存在錯誤或不足之處,還請海涵。同時,推薦大家閱讀我以前的文章了解基礎知識。
▌一. 樸素貝葉斯數學原理知識
該基礎知識部分引用文章"機器學習之樸素貝葉斯(NB)分類算法與Python實現"(https://blog.csdn.net/moxigandashu/article/details/71480251),也強烈推薦大家閱讀博主moxigandashu的文章,寫得很好。同時作者也結合概率論講解,提升下自己較差的數學。
樸素貝葉斯(Naive Bayesian)是基于貝葉斯定理和特征條件獨立假設的分類方法,它通過特征計算分類的概率,選取概率大的情況,是基于概率論的一種機器學習分類(監督學習)方法,被廣泛應用于情感分類領域的分類器。
下面簡單回顧下概率論知識:
1.什么是基于概率論的方法?
通過概率來衡量事件發生的可能性。概率論和統計學是兩個相反的概念,統計學是抽取部分樣本統計來估算總體情況,而概率論是通過總體情況來估計單個事件或部分事情的發生情況。概率論需要已知數據去預測未知的事件。
例如,我們看到天氣烏云密布,電閃雷鳴并陣陣狂風,在這樣的天氣特征(F)下,我們推斷下雨的概率比不下雨的概率大,也就是p(下雨)>p(不下雨),所以認為待會兒會下雨,這個從經驗上看對概率進行判斷。而氣象局通過多年長期積累的數據,經過計算,今天下雨的概率p(下雨)=85%、p(不下雨)=15%,同樣的 p(下雨)>p(不下雨),因此今天的天氣預報肯定預報下雨。這是通過一定的方法計算概率從而對下雨事件進行判斷。
2.條件概率
若Ω是全集,A、B是其中的事件(子集),P表示事件發生的概率,則條件概率表示某個事件發生時另一個事件發生的概率。假設事件B發生后事件A發生的概率為:
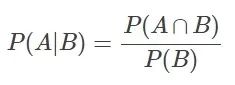
設P(A)>0,則有 P(AB) = P(B|A)P(A) = P(A|B)P(B)。
設A、B、C為事件,且P(AB)>0,則有 P(ABC) = P(A)P(B|A)P(C|AB)。
現在A和B是兩個相互獨立的事件,其相交概率為 P(A∩B) = P(A)P(B)。
3.全概率公式
設Ω為試驗E的樣本空間,A為E的事件,B1、B2、....、Bn為Ω的一個劃分,且P(Bi)>0,其中i=1,2,...,n,則:

P(A) = P(AB1)+P(AB2)+...+P(ABn)
= P(A|B1)P(B1)+P(A|B2)P(B2)+...+P(A|Bn)P(Bn)
全概率公式主要用途在于它可以將一個復雜的概率計算問題,分解為若干個簡單事件的概率計算問題,最后應用概率的可加性求出最終結果。
示例:有一批同一型號的產品,已知其中由一廠生成的占30%,二廠生成的占50%,三長生成的占20%,又知這三個廠的產品次品概率分別為2%、1%、1%,問這批產品中任取一件是次品的概率是多少?
參考百度文庫資料:
https://wenku.baidu.com/view/05d0e30e856a561253d36fdb.html
4.貝葉斯公式
設Ω為試驗E的樣本空間,A為E的事件,如果有k個互斥且有窮個事件,即B1、B2、....、Bk為Ω的一個劃分,且P(B1)+P(B2)+...+P(Bk)=1,P(Bi)>0(i=1,2,...,k),則:
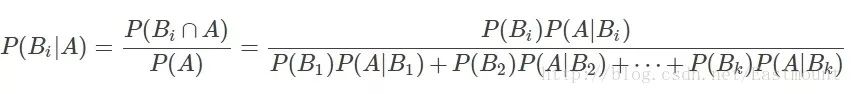
P(A):事件A發生的概率;
P(A∩B):事件A和事件B同時發生的概率;
P(A|B):事件A在時間B發生的條件下發生的概率;
意義:現在已知時間A確實已經發生,若要估計它是由原因Bi所導致的概率,則可用Bayes公式求出。
5.先驗概率和后驗概率
先驗概率是由以往的數據分析得到的概率,泛指一類事物發生的概率,根據歷史資料或主觀判斷未經證實所確定的概率。后驗概率而是在得到信息之后再重新加以修正的概率,是某個特定條件下一個具體事物發生的概率。

6.樸素貝葉斯分類
貝葉斯分類器通過預測一個對象屬于某個類別的概率,再預測其類別,是基于貝葉斯定理而構成出來的。在處理大規模數據集時,貝葉斯分類器表現出較高的分類準確性。
假設存在兩種分類:
1) 如果p1(x,y)>p2(x,y),那么分入類別1
2) 如果p1(x,y)
引入貝葉斯定理即為:
其中,x、y表示特征變量,ci表示分類,p(ci|x,y)表示在特征為x,y的情況下分入類別ci的概率,因此,結合條件概率和貝葉斯定理有:
1) 如果p(c1|x,y)>p(c2,|x,y),那么分類應當屬于類別c1
2) 如果p(c1|x,y)
貝葉斯定理最大的好處是可以用已知的概率去計算未知的概率,而如果僅僅是為了比較p(ci|x,y)和p(cj|x,y)的大小,只需要已知兩個概率即可,分母相同,比較p(x,y|ci)p(ci)和p(x,y|cj)p(cj)即可。
7.示例講解
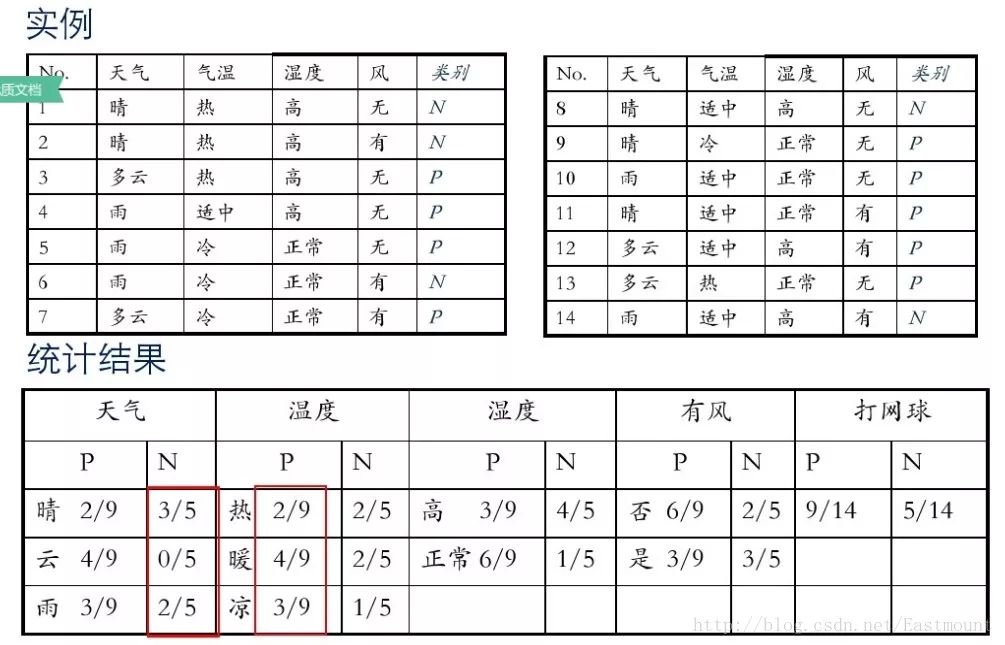
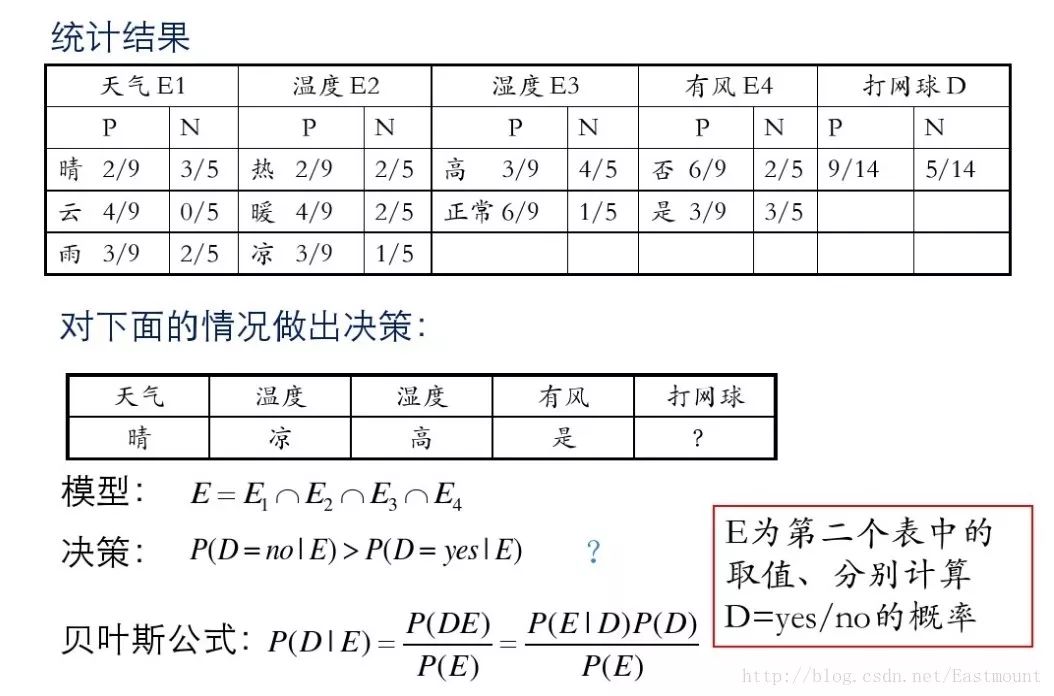
假設存在14天的天氣情況和是否能打網球,包括天氣、氣溫、濕度、風等,現在給出新的一天天氣情況,需要判斷我們這一天可以打網球嗎?首先統計出各種天氣情況下打網球的概率,如下圖所示。
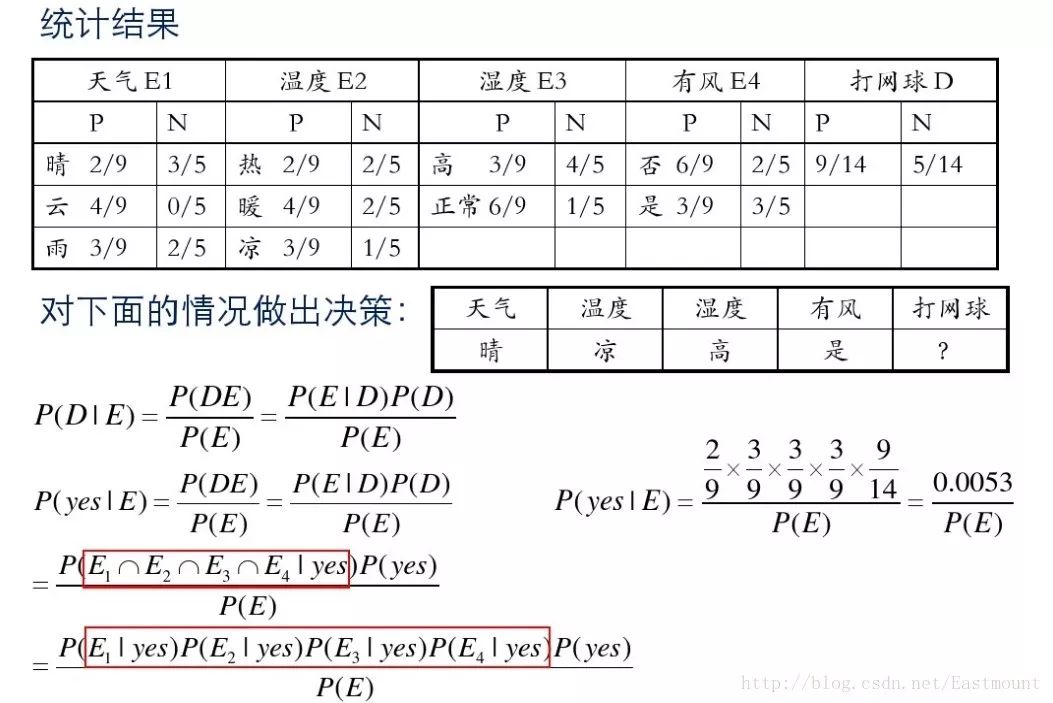
接下來是分析過程,其中包括打網球yse和不打網球no的計算方法。
最后計算結果如下,不去打網球概率為79.5%。
8.優缺點
監督學習,需要確定分類的目標
對缺失數據不敏感,在數據較少的情況下依然可以使用該方法
可以處理多個類別 的分類問題
適用于標稱型數據
對輸入數據的形勢比較敏感
由于用先驗數據去預測分類,因此存在誤差
▌二. naive_bayes用法及簡單案例
scikit-learn機器學習包提供了3個樸素貝葉斯分類算法:
GaussianNB(高斯樸素貝葉斯)
MultinomialNB(多項式樸素貝葉斯)
BernoulliNB(伯努利樸素貝葉斯)
1.高斯樸素貝葉斯
調用方法為:sklearn.naive_bayes.GaussianNB(priors=None)。
下面隨機生成六個坐標點,其中x坐標和y坐標同為正數時對應類標為2,x坐標和y坐標同為負數時對應類標為1。通過高斯樸素貝葉斯分類分析的代碼如下:
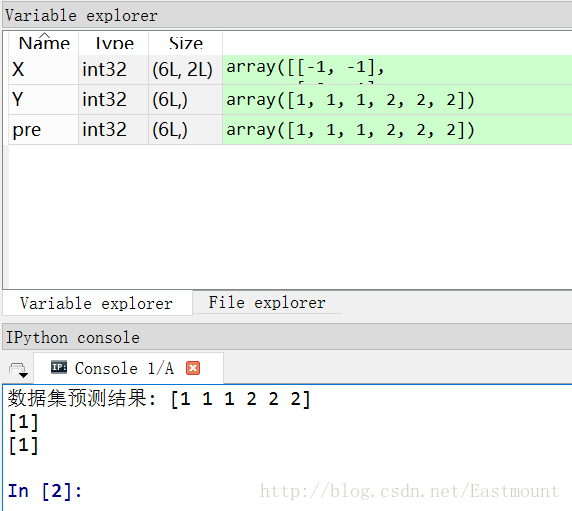
1#-*-coding:utf-8-*- 2importnumpyasnp 3fromsklearn.naive_bayesimportGaussianNB 4X=np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]]) 5Y=np.array([1,1,1,2,2,2]) 6clf=GaussianNB() 7clf.fit(X,Y) 8pre=clf.predict(X) 9printu"數據集預測結果:",pre10printclf.predict([[-0.8,-1]])1112clf_pf=GaussianNB()13clf_pf.partial_fit(X,Y,np.unique(Y))#增加一部分樣本14printclf_pf.predict([[-0.8,-1]])
輸出如下圖所示,可以看到[-0.8, -1]預測結果為1類,即x坐標和y坐標同為負數。
2.多項式樸素貝葉斯
多項式樸素貝葉斯:sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)主要用于離散特征分類,例如文本分類單詞統計,以出現的次數作為特征值。
參數說明:alpha為可選項,默認1.0,添加拉普拉修/Lidstone平滑參數;fit_prior默認True,表示是否學習先驗概率,參數為False表示所有類標記具有相同的先驗概率;class_prior類似數組,數組大小為(n_classes,),默認None,類先驗概率。
3.伯努利樸素貝葉斯
伯努利樸素貝葉斯:sklearn.naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True,class_prior=None)。類似于多項式樸素貝葉斯,也主要用于離散特征分類,和MultinomialNB的區別是:MultinomialNB以出現的次數為特征值,BernoulliNB為二進制或布爾型特性
下面是樸素貝葉斯算法常見的屬性和方法。
1) class_prior_屬性
觀察各類標記對應的先驗概率,主要是class_prior_屬性,返回數組。代碼如下:
1printclf.class_prior_2#[0.50.5]
2) class_count_屬性
獲取各類標記對應的訓練樣本數,代碼如下:
1printclf.class_count_2#[3.3.]
3) theta_屬性
獲取各個類標記在各個特征上的均值,代碼如下:
1printclf.theta_2#[[-2.-1.33333333]3#[2.1.33333333]]
4) sigma_屬性
獲取各個類標記在各個特征上的方差,代碼如下:
1printclf.theta_2#[[-2.-1.33333333]3#[2.1.33333333]]
5) fit(X, y, sample_weight=None)
訓練樣本,X表示特征向量,y類標記,sample_weight表各樣本權重數組。
1#設置樣本不同的權重2clf.fit(X,Y,np.array([0.05,0.05,0.1,0.1,0.1,0.2,0.2,0.2]))3printclf4printclf.theta_5printclf.sigma_
輸出結果如下所示:
1GaussianNB()2[[-2.25-1.5]3[2.251.5]]4[[0.68750.25]5[0.68750.25]]
6) partial_fit(X, y, classes=None, sample_weight=None)
增量式訓練,當訓練數據集數據量非常大,不能一次性全部載入內存時,可以將數據集劃分若干份,重復調用partial_fit在線學習模型參數,在第一次調用partial_fit函數時,必須制定classes參數,在隨后的調用可以忽略。
1importnumpyasnp 2fromsklearn.naive_bayesimportGaussianNB 3X=np.array([[-1,-1],[-2,-2],[-3,-3],[-4,-4],[-5,-5], 4[1,1],[2,2],[3,3]]) 5y=np.array([1,1,1,1,1,2,2,2]) 6clf=GaussianNB() 7clf.partial_fit(X,y,classes=[1,2], 8sample_weight=np.array([0.05,0.05,0.1,0.1,0.1,0.2,0.2,0.2])) 9printclf.class_prior_10printclf.predict([[-6,-6],[4,5],[2,5]])11printclf.predict_proba([[-6,-6],[4,5],[2,5]])
輸出結果如下所示:
1[0.40.6]2[122]3[[1.00000000e+004.21207358e-40]4[1.12585521e-121.00000000e+00]5[8.73474886e-111.00000000e+00]]
可以看到點[-6,-6]預測結果為1,[4,5]預測結果為2,[2,5]預測結果為2。同時,predict_proba(X)輸出測試樣本在各個類標記預測概率值。
7) score(X, y, sample_weight=None)
返回測試樣本映射到指定類標記上的得分或準確率。
1pre=clf.predict([[-6,-6],[4,5],[2,5]])2printclf.score([[-6,-6],[4,5],[2,5]],pre)3#1.0
最后給出一個高斯樸素貝葉斯算法分析小麥數據集案例,代碼如下:
1#-*-coding:utf-8-*- 2#第一部分載入數據集 3importpandasaspd 4X=pd.read_csv("seed_x.csv") 5Y=pd.read_csv("seed_y.csv") 6printX 7printY 8 9#第二部分導入模型10fromsklearn.naive_bayesimportGaussianNB11clf=GaussianNB()12clf.fit(X,Y)13pre=clf.predict(X)14printu"數據集預測結果:",pre1516#第三部分降維處理17fromsklearn.decompositionimportPCA18pca=PCA(n_components=2)19newData=pca.fit_transform(X)20printnewData[:4]2122#第四部分繪制圖形23importmatplotlib.pyplotasplt24L1=[n[0]forninnewData]25L2=[n[1]forninnewData]26plt.scatter(L1,L2,c=pre,s=200)27plt.show()
輸出如下圖所示:
最后對數據集進行評估,主要調用sklearn.metrics類中classification_report函數實現的,代碼如下:
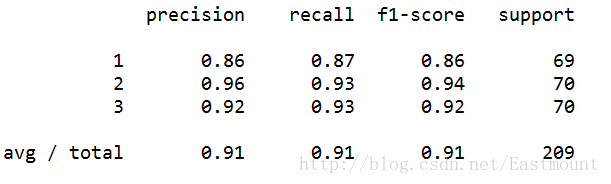
1fromsklearn.metricsimportclassification_report2print(classification_report(Y,pre))
運行結果如下所示,準確率、召回率和F特征為91%。
補充下Sklearn機器學習包常用的擴展類。
1#監督學習 2sklearn.neighbors#近鄰算法 3sklearn.svm#支持向量機 4sklearn.kernel_ridge#核-嶺回歸 5sklearn.discriminant_analysis#判別分析 6sklearn.linear_model#廣義線性模型 7sklearn.ensemble#集成學習 8sklearn.tree#決策樹 9sklearn.naive_bayes#樸素貝葉斯10sklearn.cross_decomposition#交叉分解11sklearn.gaussian_process#高斯過程12sklearn.neural_network#神經網絡13sklearn.calibration#概率校準14sklearn.isotonic#保守回歸15sklearn.feature_selection#特征選擇16sklearn.multiclass#多類多標簽算法1718#無監督學習19sklearn.decomposition#矩陣因子分解sklearn.cluster#聚類20sklearn.manifold#流形學習21sklearn.mixture#高斯混合模型22sklearn.neural_network#無監督神經網絡23sklearn.covariance#協方差估計2425#數據變換26sklearn.feature_extraction#特征提取sklearn.feature_selection#特征選擇27sklearn.preprocessing#預處理28sklearn.random_projection#隨機投影29sklearn.kernel_approximation#核逼近
▌三. 中文文本數據集預處理
假設現在需要判斷一封郵件是不是垃圾郵件,其步驟如下:
數據集拆分成單詞,中文分詞技術
計算句子中總共多少單詞,確定詞向量大小
句子中的單詞轉換成向量,BagofWordsVec
計算P(Ci),P(Ci|w)=P(w|Ci)P(Ci)/P(w),表示w特征出現時,該樣本被分為Ci類的條件概率
判斷P(w[i]C[0])和P(w[i]C[1])概率大小,兩個集合中概率高的為分類類標
下面講解一個具體的實例。
1.數據集讀取
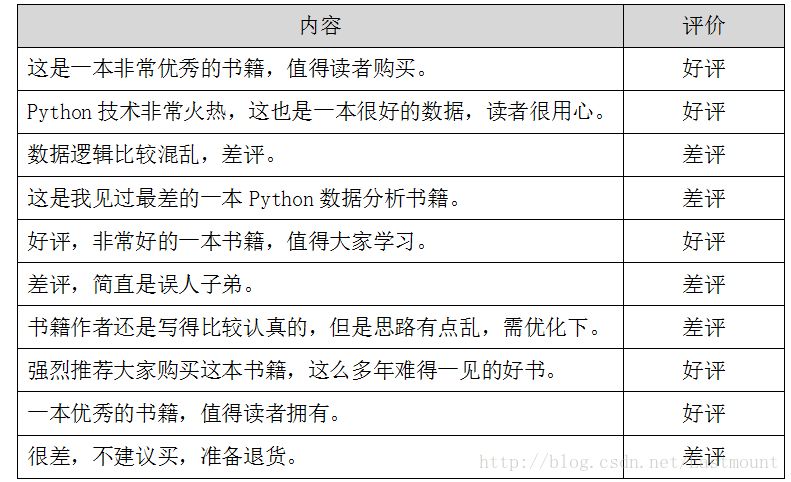
假設存在如下所示10條Python書籍訂單評價信息,每條評價信息對應一個結果(好評和差評),如下圖所示:
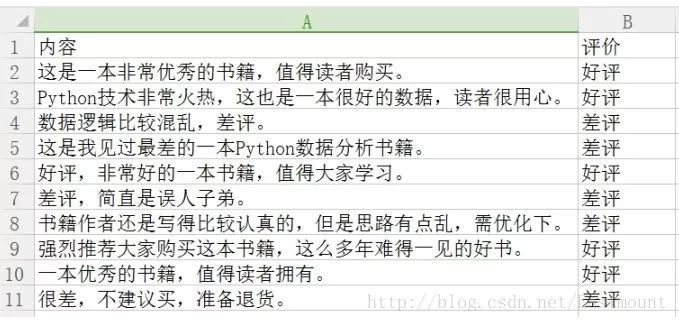
數據存儲至CSV文件中,如下圖所示。
下面采用pandas擴展包讀取數據集。代碼如下所示:
1#-*-coding:utf-8-*- 2importnumpyasnp 3importpandasaspd 4 5data=pd.read_csv("data.csv",encoding='gbk') 6printdata 7 8#取表中的第1列的所有值 9printu"獲取第一列內容"10col=data.iloc[:,0]11#取表中所有值12arrs=col.values13forainarrs:14printa
輸出結果如下圖所示,同時可以通過data.iloc[:,0]獲取第一列的內容。
2.中文分詞及過濾停用詞
接下來作者采用jieba工具進行分詞,并定義了停用詞表,即:
stopwords = {}.fromkeys([',', '。', '!', '這', '我', '非常'])
完整代碼如下所示:
1#-*-coding:utf-8-*- 2importnumpyasnp 3importpandasaspd 4importjieba 5 6data=pd.read_csv("data.csv",encoding='gbk') 7printdata 8 9#取表中的第1列的所有值10printu"獲取第一列內容"11col=data.iloc[:,0]12#取表中所有值13arrs=col.values14#去除停用詞15stopwords={}.fromkeys([',','。','!','這','我','非常'])1617printu"
中文分詞后結果:"18forainarrs:19#printa20seglist=jieba.cut(a,cut_all=False)#精確模式21final=''22forseginseglist:23seg=seg.encode('utf-8')24ifsegnotinstopwords:#不是停用詞的保留25final+=seg26seg_list=jieba.cut(final,cut_all=False)27output=''.join(list(seg_list))#空格拼接28printoutput
然后分詞后的數據如下所示,可以看到標點符號及“這”、“我”等詞已經過濾。
3.詞頻統計
接下來需要將分詞后的語句轉換為向量的形式,這里使用CountVectorizer實現轉換為詞頻。如果需要轉換為TF-IDF值可以使用TfidfTransformer類。詞頻統計完整代碼如下所示:
1#-*-coding:utf-8-*- 2importnumpyasnp 3importpandasaspd 4importjieba 5 6data=pd.read_csv("data.csv",encoding='gbk') 7printdata 8 9#取表中的第1列的所有值10printu"獲取第一列內容"11col=data.iloc[:,0]12#取表中所有值13arrs=col.values14#去除停用詞15stopwords={}.fromkeys([',','。','!','這','我','非常'])1617printu"
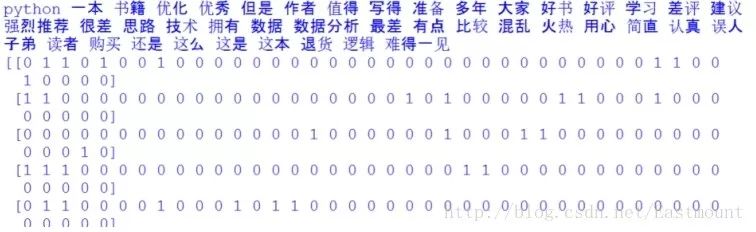
中文分詞后結果:"18corpus=[]19forainarrs:20#printa21seglist=jieba.cut(a,cut_all=False)#精確模式22final=''23forseginseglist:24seg=seg.encode('utf-8')25ifsegnotinstopwords:#不是停用詞的保留26final+=seg27seg_list=jieba.cut(final,cut_all=False)28output=''.join(list(seg_list))#空格拼接29printoutput30corpus.append(output)3132#計算詞頻33fromsklearn.feature_extraction.textimportCountVectorizer34fromsklearn.feature_extraction.textimportTfidfTransformer3536vectorizer=CountVectorizer()#將文本中的詞語轉換為詞頻矩陣37X=vectorizer.fit_transform(corpus)#計算個詞語出現的次數38word=vectorizer.get_feature_names()#獲取詞袋中所有文本關鍵詞39forwinword:#查看詞頻結果40printw,41print''42printX.toarray()
輸出結果如下所示,包括特征詞及對應的10行數據的向量,這就將中文文本數據集轉換為了數學向量的形式,接下來就是對應的數據分析了。
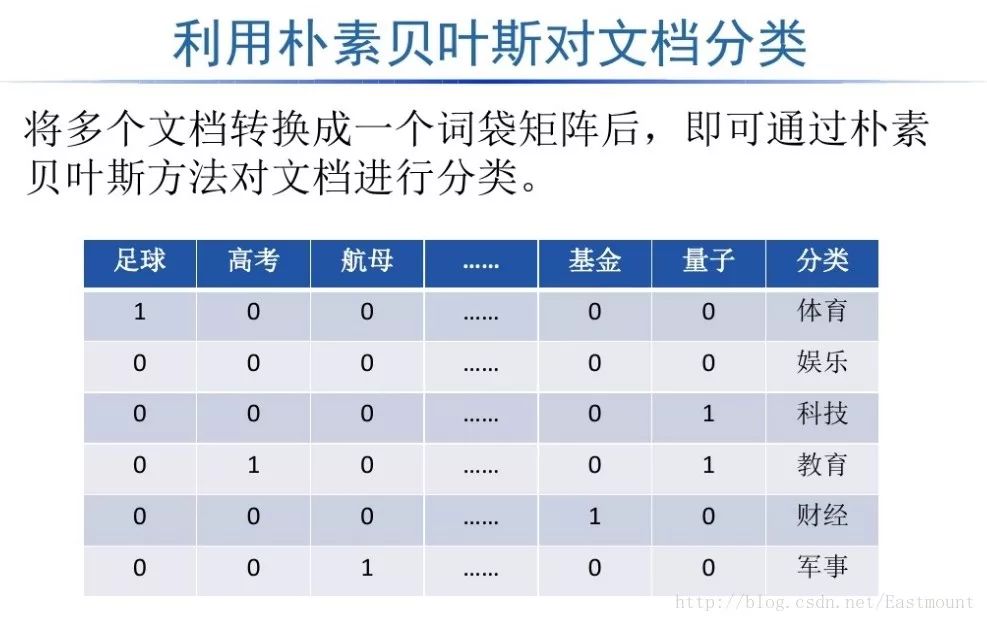
如下所示得到一個詞頻矩陣,每行數據集對應一個分類類標,可以預測新的文檔屬于哪一類。
TF-IDF相關知識推薦我的文章: [python] 使用scikit-learn工具計算文本TF-IDF值(https://blog.csdn.net/eastmount/article/details/50323063)
▌四. 樸素貝葉斯中文文本輿情分析
最后給出樸素貝葉斯分類算法分析中文文本數據集的完整代碼。
1#-*-coding:utf-8-*- 2importnumpyasnp 3importpandasaspd 4importjieba 5 6#http://blog.csdn.net/eastmount/article/details/50323063 7#http://blog.csdn.net/eastmount/article/details/50256163 8#http://blog.csdn.net/lsldd/article/details/41542107 910####################################11#第一步讀取數據及分詞12#13data=pd.read_csv("data.csv",encoding='gbk')14printdata1516#取表中的第1列的所有值17printu"獲取第一列內容"18col=data.iloc[:,0]19#取表中所有值20arrs=col.values2122#去除停用詞23stopwords={}.fromkeys([',','。','!','這','我','非常'])2425printu"
中文分詞后結果:"26corpus=[]27forainarrs:28#printa29seglist=jieba.cut(a,cut_all=False)#精確模式30final=''31forseginseglist:32seg=seg.encode('utf-8')33ifsegnotinstopwords:#不是停用詞的保留34final+=seg35seg_list=jieba.cut(final,cut_all=False)36output=''.join(list(seg_list))#空格拼接37printoutput38corpus.append(output)3940####################################41#第二步計算詞頻42#43fromsklearn.feature_extraction.textimportCountVectorizer44fromsklearn.feature_extraction.textimportTfidfTransformer4546vectorizer=CountVectorizer()#將文本中的詞語轉換為詞頻矩陣47X=vectorizer.fit_transform(corpus)#計算個詞語出現的次數48word=vectorizer.get_feature_names()#獲取詞袋中所有文本關鍵詞49forwinword:#查看詞頻結果50printw,51print''52printX.toarray()535455####################################56#第三步數據分析57#58fromsklearn.naive_bayesimportMultinomialNB59fromsklearn.metricsimportprecision_recall_curve60fromsklearn.metricsimportclassification_report6162#使用前8行數據集進行訓練,最后兩行數據集用于預測63printu"
數據分析:"64X=X.toarray()65x_train=X[:8]66x_test=X[8:]67#1表示好評0表示差評68y_train=[1,1,0,0,1,0,0,1]69y_test=[1,0]7071#調用MultinomialNB分類器72clf=MultinomialNB().fit(x_train,y_train)73pre=clf.predict(x_test)74printu"預測結果:",pre75printu"真實結果:",y_test7677fromsklearn.metricsimportclassification_report78print(classification_report(y_test,pre))
輸出結果如下所示,可以看到預測的兩個值都是正確的。即“一本優秀的書籍,值得讀者擁有。”預測結果為好評(類標1),“很差,不建議買,準備退貨。”結果為差評(類標0)。
1數據分析:2預測結果:[10]3真實結果:[1,0]4precisionrecallf1-scoresupport5601.001.001.001711.001.001.00189avg/total1.001.001.002
但存在一個問題,由于數據量較小不具備代表性,而真實分析中會使用海量數據進行輿情分析,預測結果肯定頁不是100%的正確,但是需要讓實驗結果盡可能的好。最后補充一段降維繪制圖形的代碼,如下:
1#降維繪制圖形 2fromsklearn.decompositionimportPCA 3pca=PCA(n_components=2) 4newData=pca.fit_transform(X) 5printnewData 6 7pre=clf.predict(X) 8Y=[1,1,0,0,1,0,0,1,1,0] 9importmatplotlib.pyplotasplt10L1=[n[0]forninnewData]11L2=[n[1]forninnewData]12plt.scatter(L1,L2,c=pre,s=200)13plt.show()
輸出結果如圖所示,預測結果和真實結果都是一樣的,即[1,1,0,0,1,0,0,1,1,0]。
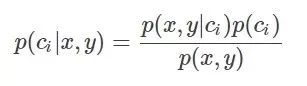




-
數據集
+關注
關注
4文章
1223瀏覽量
25297 -
貝葉斯分類器
+關注
關注
0文章
6瀏覽量
2360
原文標題:樸素貝葉斯分類器詳解及中文文本輿情分析(附代碼實踐)
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
VirtualLab:光柵的優化與分析
貝斯新能源:以科技創新為驅動力 助推鋰電池行業高質量發展
中科曙光旗下中科天璣推出全要素AI輿情系統
大模型訓練:開源數據與算法的機遇與挑戰分析
氣象百葉箱傳感器:全面監測,助力氣候分析與預報
貝斯蘭半導體完成數千萬元天使輪融資
主動學習在圖像分類技術中的應用:當前狀態與未來展望

如何用PCM1808來獲取MIC的音量?最大值能到130分貝嗎?
【飛凌嵌入式OK3576-C開發板體驗】RKNN神經網絡算法開發環境搭建
人員軌跡分析算法有哪些?
基于高光譜數據的典型地物分類識別方法研究






 工商網監
工商網監
評論