 Deepmind“好奇心學習”新機制:讓智能體不再偷懶
Deepmind“好奇心學習”新機制:讓智能體不再偷懶
Google、Deepmind和蘇黎世聯邦理工學院的研究人員提出“好奇心學習”新方法,改變了智能體“好奇心”的生成方式和獎勵機制,獎勵機制不再基于智能體的“意外”,而是其記憶和所在情景。研究人員稱,新方法可以有效降低智能體“原地兜圈子”、“拖延”等不良行為,有效提升模型性能。
強化學習是機器學習中最活躍的研究領域之一,在該領域的研究環境下,人工智能體(agent)做到正確的事情時會獲得積極的獎勵,否則獲得負面的獎勵。
這種“胡蘿卜加大棒”的方法簡單而通用,DeepMind教授利用DQN算法來玩Atari游戲和AlphaGoZero下圍棋,都是利用強化學習模型。OpenAI團隊利用OpenAI-Five算法來打Dota,Google如何教機器人手臂來握住新目標,也是利用強化學習實現的。不過,盡管強化學習取得了如此大的成功,但想使其成為一種有效的技術,仍然存在許多挑戰。
標準的強化學習算法在對智能體反饋信息很少的環境中表現不佳。至關重要的是,這類環境在現實世界中是很常見的。舉個例子,如何在一個大型的迷宮式超市中學習如何找到自己喜歡的奶酪。你找了又找,但找不到賣奶酪的貨架。
如果做完了某一步動作,既沒有“胡蘿卜”,也沒有“大棒”,那智能體便無法判斷是否正朝著正確的方向前進。在沒有獎勵的情況下,怎樣才能避免原地兜圈子?也只有好奇心了,好奇心會激勵目標進入一個似乎不熟悉的區域,到那里去找奶酪。
在Google Brain團隊、DeepMind和蘇黎世聯邦理工學院的合作研究中,提出了一種新的基于情景記憶的模型,它可以提供與好奇心類似的獎勵,可以用于探索周圍環境。
研究團隊希望,智能體不僅要能探索環境,而且還要解決原始任務,因此將模型提供的獎勵加入原始的反饋信息稀疏的任務的獎勵中。合并后的獎勵不再稀疏,使用標準強化學習算法就可以從中學習。因此,該團隊提出的好奇心方法擴展了可用強化學習解決的任務集。研究論文題為《Episodic Curiosity through Reachability》
基于情景的好奇心模型:觀察結果被添加到智能體的記憶中,獎勵基于智能體當前的觀察結果與記憶中最相似的結果的差異來計算的。智能體會因為看到記憶中尚不存在的觀察結果而獲得更多獎勵。
這一方法的關鍵是,將智能體對環境的觀察結果存儲在情景記憶中,同時對智能體觀察到的“記憶中尚不存在”的結果也進行獎勵。“記憶中不存在”是這一方法中新的定義,智能體去尋求這種觀察結果,意味著去尋求不熟悉的東西。尋求陌生事物的驅動力會讓智能體到達新的位置,防止其在原地兜圈子,并最終幫助其找到目標。下文還將談到,這種方法不會像其他一些方法那樣,讓智能體出現一些不希望出現的行為,比如類似人類的“拖延”行為。
過去的好奇心學習機制:基于“意外”的好奇心
盡管在過去有許多嘗試來形成好奇心,但本文關注的是一種自然且非常流行的方法:基于“意外”的好奇心機制。最近一篇題為“Curiosity-driven Exploration bySelf-supervised Prediction”的論文中探討了這個問題。此方法一般稱為ICM方法。為了說明意外是如何引發好奇心的,這里再次以超市中尋找奶酪的比喻為例。
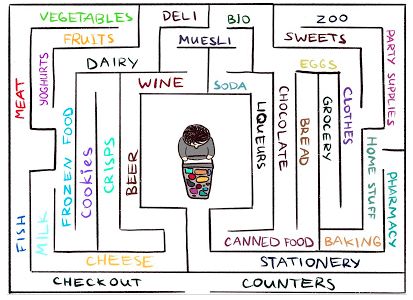
想象一下當你在逛市場時,其實會嘗試著預測未來(“現在我在賣肉攤位處,所以我認為拐角處應該是賣魚的,超市連鎖店中這兩個部分一般是相鄰的”)。如果你的預測錯了,你會感到意外(“啊,原來是賣菜的。我沒想到!”)因而得到一個回報。這使你更有動力將來更加關注拐角處,探索新的地方,看看自己對它們的預測是否符合現實(也是希望能夠找到奶酪)。
與此類似,ICM方法也建立了關于世界動態的預測模型,并在模型未能做出良好預測時對智能體給予獎勵,這種獎勵標志著“意外”或“新東西”。注意,探索沒去過的地方,并不是ICM好奇心機制的直接組成部分。
對于ICM方法而言,這只是獲得更多“意外”的一種方式,目的是讓獲得的總體獎勵最大化。事實證明,在某些環境中可能存在其他方式造成“自我意外”,從而導致無法預料的結果。
基于“意外”好奇心的智能體會一直卡在電視前,不去執行任務
基于“意外好奇心“的智能體易產生“拖延行為”
在 《Large-Scale Study of Curiosity-Driven Learning》一文中,ICM方法的作者和OpenAI的研究人員表明,基于“意外最大化”的強化學習方法可能存在潛在的風險:智能體可以學會放縱和拖延的行為,不去做任何有用的事情來完成當前任務。
為了了解其中的原因,請看一個常見的思想實驗,實驗名為“嘈雜的電視問題”,在實驗中,智能體被置于一個迷宮中,任務是尋找一個非常有價值的項目(與本文之前的超市例子中的“奶酪”類似)。
測試環境中還放了一臺電視,智能體有電視的遙控器。電視頻道數量有限(每個頻道放映不同的節目),每次按鍵都會切換到隨機頻道。智能體在這樣的環境中會如何表現?
對基于意外的好奇心的方法而言,改變頻道會產生巨大的回報,因為每次頻道變化都是不可預測和意外的。重要的是,即使在所有可用頻道的節目都循環出現一次之后,由于頻道放映的內容是隨機的,所以每一個新變化仍然屬于意外,因為智能體一直預測改變頻道后會放什么節目,這個預測很可能會出錯,導致意外的產生。
即使智能體已經看過每個頻道的每個節目,這種隨機變化仍然是不可預測的。因此,不斷收獲意外的好奇心智能體,最終將永遠留在電視機前,不會去尋找那個非常有價值的物品,這類似于一種“拖延”行為。那么,如何定義“好奇心”才能避免產生這種拖延行為呢?
基于“情境”的好奇心模型
在《Episodic Curiositythrough Reachability》一文中,我們探索了一種基于記憶的“情境好奇心”模型,結果證明,這種模型不太容易產生“自我放縱”的即時滿足感。為什么呢?
這里仍以上文的實驗為例,智能體在不斷變換電視頻道一段時間后,所有的節目最終都會出現在記憶中。因此,電視將不再具有吸引力:即使屏幕上出現的節目順序是隨機且不可預測的,但所有這些節目已經在記憶中了。
這是本方法與前文的“基于意外”的方法的主要區別:我們的方法甚至沒有去預測未來。與此相反,智能體會檢查過去的信息,了解自己是否已經看到過與當前的觀察結果。因此,我們的智能體不會被嘈雜的電視所提供的“即時滿足感”所吸引。它必須去電視之外世界進行探索,才能獲得更多獎勵。
如何判斷智能體是否看到與現有記憶中相同的東西?檢查二者是否完全匹配可能是毫無意義的:因為在現實環境中,很少出現完全相同的場景。比如,即使智能體返回了一間完全相同的房間內,其觀察角度也會與之前的記憶場景不同。
我們不會檢查智能體記憶中的是否存在精確匹配,而是用訓練后的深度神經網絡來衡量兩種體驗的相似度。為了訓練該網絡,我們會猜測前后兩個觀察結果在時間上是否相距很近。如果二者在時間上很接近,很可能就應該被視為智能體同一段體驗中的不同部分。
是新是舊可由“可達性”圖決定。在實際應用中,此圖無法獲取,我們通過訓練神經網絡估計器,在觀察結果之間估計一系列步驟。
實驗結果與未來展望
為了比較不同方法的表現,我們在兩個視覺元素豐富的3D環境中進行了測試:分別為ViZDoom和DMLab。在這些環境中,智能體的任務是處理各種問題,比如在迷宮中搜索目標,或者收集“好目標”,同時避開“壞目標”。
DMLab環境恰好能為智能體提供很炫酷的工具。此前的研究中,關于DMLab的標準設置就是為智能體配備適用所有任務的小工具,如果代理不需要特定任務的小工具,那么也可以不用。
有趣的是,在類似于上文的嘈雜的電視實驗中,基于意外的ICM方法實際上使用了這個小工具,即使它對于當前任務并無用處!智能體的任務是在迷宮中搜尋高回報的目標,但它卻更喜歡花時間對墻壁進行標記,因為這會產生很多“意外”獎勵。
從理論上講,預測標記的結果是可能的,但實際上太難實現了,因為智能體顯然不具備預測這些結果所需的更深入的物理知識。
基于“意外”的ICM方法,智能體一直在標記墻壁,而不是探索迷宮
而我們的方法則在相同的條件下學習合理的探索行為。智能體沒有試圖預測其行為的結果,而是尋求從已在情景記憶中存在的那些“更難”實現目標的觀察結果。換句話說,智能體會根據記憶,去尋求更難實現的目標,而不僅僅進行標記操作。
在我們的“情景記憶”方法中,智能體會進行合理的探索
有趣的是,我們的方法所實施的獎勵機制,會懲罰在原地兜圈子的智能體。這是因為在完成一次內容循環后,智能體之后的觀察結果都已存在于記憶中了,因此不會得到任何獎勵:
對我們的方法獎勵機制的可視化:紅色表示負面獎勵,綠色表示正面獎勵。從左到右分別為:使用獎勵的映射,使用當前記憶位置的映射,第一人稱視圖
我們希望我們的研究有助于引領對新的探索方法的討論。有關我們方法的深入分析,請查看我們的研究論文的預印本。
-
機器人
+關注
關注
213文章
29537瀏覽量
211772 -
智能體
+關注
關注
1文章
274瀏覽量
10979
原文標題:Deepmind“好奇心”強化學習新突破!改變獎勵機制,讓智能體不再“兜圈子”
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
TC275HSM能支持SecOC中的密鑰刷新機制嗎?
南灣街道探索電動車管理新機制,首批智能充電樁投入使用
Microchip Technology的好奇心板的新設計
求大神分享一種基于bootloader的嵌入式軟件自動更新機制
Android系統固件更新機制設計資料分享
一種基于嵌入式系統的遠程程序更新機制
ADO_NET數據集更新機制及并發控制策略
嵌入式系統自更新機制的設計與應用
適用動態存儲的自適應刷新機制算法設計
強化學習“好奇心”模型:訓練無需外部獎勵,全靠自己
人工智能要想更快更好 好奇心必不可少
機器人擁有好奇心會讓機器人變得更加聰明
語言模型做先驗,統一強化學習智能體,DeepMind選擇走這條通用AI之路

石墨烯之父——安德烈·海姆,好奇心驅使下的幽默大師和創新者






 工商網監
工商網監
評論