 基于雙目視覺的自動駕駛中障礙物識別問題
基于雙目視覺的自動駕駛中障礙物識別問題

基于現實世界是一個三維空間,所以對計算機視覺的研究也應該是在三維空間中進行的。在自動駕駛過程中的首要任務就是道路識別 [1] ,主要是圖像特征法和模型匹配法來進行識別。行駛過程中需要進行障礙物檢測 [2] 和路標路牌識別等,此時車輛上的信息采集便可以運用單目視覺或者多目視覺。
相比之下,運用多目視覺更具優勢,獲取的圖像信息可構建成三維空間,物體運動以及遮擋等問題對其影響較小。目前有很多智能小車的研究都是基于室內環境的研究,本文基于室外環境,采用雙目攝像機模型 [3] ,考慮光照、路面材質等問題,采用分水嶺算法 [4] 對智能車的區域進行定位,以及在行駛區域中采用多閾值 canny 算法來進行障礙物的檢測,進而計算出障礙物大小位置等信息。
分水嶺算法
定義極小值點,本質上的意義就是定義道路和圖像中其他區域的極小值點,使道路與圖像中的其他區域劃分開。 接著對極小值點的相鄰像素按照等級進行逐級劃分,等級是按照極小值點與相鄰像素的距離劃分的,而這里的距離是指兩個像素點之間灰度值的差值。 從定義的極小值點開始逐步擴展形成集水盆。 從最小等級開始,對與集水盆相鄰的像素點進行擴展。 如果當前要擴展的像素點只與一個集水盆相連,則把該點標記為相近集水盆的標記;如果當前要擴展的像素點 2個或多個集水盆相連,則把該點標記為分水線或者分水嶺。 在進行擴展的過程中,只有當前等級的所有像素被劃分完畢后,才能對下一個等級的像素進行劃分。
基于多閾值 canny 的障礙物檢測
由于室外環境下,陰影、光照、雨水等天氣原因都會對圖像的拍攝造成影響,所以采用的是雙目攝像頭模型,可以有效地減輕外界因素對圖像的干擾。
Canny 邊緣檢測 [5] 算法閾值的不同,會導致所獲得的邊緣信息不同,本文中利用 2 個不同的閾值將點分為 3 類:強邊緣點、弱邊緣點、弱紋理點;其中弱邊緣點是利用閾值較小的算子檢測,除去通過閾值較大的算子得到的強邊緣點所剩下的點;剩余的其他像素點則為弱紋理點。 再根據各點特征分配匹配窗口大小,強邊緣點主要是位于邊界和視差不連續點,其支持窗口應該越小越好;而弱紋理點周圍的梯度變化不明顯,窗口應足夠大,包含更多的圖像信息進來;而弱邊緣點特征介于強邊緣點與弱紋理點之間,處于 2 個以上的弱紋理交界處,兼有邊緣與弱紋理的特征,所以窗口介于兩者之間。 在本文算法中,強邊緣點分配的是 1 ×3 窗口,弱邊緣點分配的是 5 ×5 窗口,弱紋理點分配的是 11 ×11 窗口。
分配好所有點的窗口大小后,則需要進行最關鍵的一步———立體匹配 [6] 。 本文采用的是SAD 來作為匹配測度函數,如式(1)。 算法中假設以右圖為參考圖,令為匹配測度,d 為滑動窗口位移量,Wr 為匹配窗口,Ir (x,y)和 Ii(x+d,y) 分別為左圖和右圖中匹配窗口中心像素的灰度值。
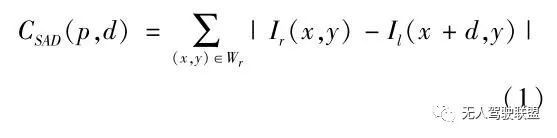
最后可得到一幅初始視差圖,圖像的灰度深淺即表示了前方物體離攝像機的遠近。
障礙物判別
在得到初始視差圖后,需要進一步判別障礙物的遠近及大小,所以這里引入 V-視差和 U-視差理論 [7] 。 V-視差圖是在初始視差圖的基礎上,累加視差圖像每一行上具有相同視差值 dv 的像素個數,以像素的個數作為像素坐標(dv,y)的灰度值,為 0 到 255。 V-視差圖的高度與原圖像是相同的,但是寬度只有 256 [8] 。 同理,U-視差圖是累加視差圖像每一列上具有相同視差值 du 的像素個數,高度為 256。
根據 V-視差圖的原理,每一行中的視差值相同點的個數會被投影成一條直線,所以在 V-視差圖中路面是一條斜線,障礙物是一條看似與斜線垂直的線段,可以通過該線段求出障礙物的高度 。同理,可通過 U-視差圖計算出障礙物的寬度。 根據初始視差圖中包含的視差值,由式(2)可以計算出每個障礙物的距離,其中攝像機的焦距 f 和 2 個攝像機基線距離 b 均是固定并且是已知的。

實驗結果
4.1 道路識別結果該算法基于 VC 平臺實現的,輸入的圖片是由攝像機所拍攝的普通道路圖片,實驗結果如圖1 所示。
4.2 障礙物檢測結果
輸入的原始圖片是由雙目攝像機所拍攝的左右圖像(圖 2)
實驗采用的是平行的攝像機模型,以右攝像機拍攝的圖像為參考圖像進行 Canny 邊緣檢測。 圖 3為對參考圖像進行不同閾值的邊緣檢測。
在求得每個點的最佳視差值之后,用該點的視差值來表示該點的像素值,形成圖像的初始視差圖,并且進行中值濾波后期處理,效果如圖 4。
得到的初始視差圖,利用 V-視差圖和 U-視差圖后根據圖中信息計算障礙物的大小與位置。 輸入 V-視差圖和 U-視差圖后,分別計算出了高度和寬度。 如圖 5 所示。
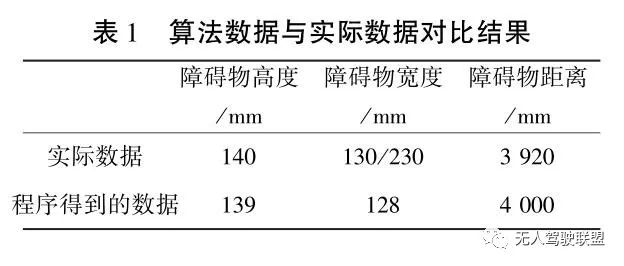
實驗中攝像機的焦距 30 mm,攝像機之間的基線距離為 200 mm,即可計算出障礙物所在位置離攝像機的距離。 算法數據與實際數據對比結果如表 1 所示。
總結
本論文中主要研究了基于雙目視覺的自動駕駛,包括了道路識別算法、基于多閾值 Canny 的障礙物檢測和判別。
算法的處理效果比較理想,運行處理速度在背景復雜的情況下偏慢。 研究了基于雙目視覺的自動駕駛中障礙物識別問題。 該算法實驗效果較好,但由于水平方向的信息較少使得障礙物的寬度檢測結果存在一些誤差。 在后續的深入研究中,應該把動態障礙物檢測加入。
-
計算機視覺
+關注
關注
9文章
1710瀏覽量
46869 -
無人駕駛
+關注
關注
99文章
4182瀏覽量
123856 -
自動駕駛
+關注
關注
790文章
14362瀏覽量
171089
原文標題:基于雙目視覺的無人駕駛算法
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
雙目立體視覺原理大揭秘(一)
自動駕駛真的會來嗎?
基于labview機器視覺的障礙物時別
細說關于自動駕駛那些事兒
基于SoC的雙目視覺ADAS解決方案
激光雷達是自動駕駛不可或缺的傳感器
速騰聚創首次發布LiDAR算法 六大模塊助力自動駕駛
用于ADAS系統和自動駕駛車輛中雷達的毫米波傳感器
LabVIEW開發自動駕駛的雙目測距系統
基于雙目視覺的移動機器人障礙物檢測研究
一種基于圖像處理的雙目視覺校準方法
麻生理工開發出成像技術:可以讓自動駕駛汽車穿過大霧看到障礙物
NVIDIA 自動駕駛實驗室:基于早期網格融合的近距離障礙物感知





 工商網監
工商網監
評論