") 如何理解各層學到了怎樣的信息?通過可視化工具進行探究
如何理解各層學到了怎樣的信息?通過可視化工具進行探究
深度神經(jīng)網(wǎng)絡(luò)的超強有效性一直讓人疑惑。
經(jīng)典論文《可視化與理解CNN》(Visualizing and Understanding Convolutional Networks)解釋了在圖像領(lǐng)域中CNN從低層到高層不斷學習出圖像的邊緣、轉(zhuǎn)角、組合、局部、整體信息的過程,一定層面論證了深度學習的有效性。另一方面,傳統(tǒng)的NLP神經(jīng)網(wǎng)絡(luò)卻并不是那么深,而bert的出現(xiàn)直接將NLP的神經(jīng)網(wǎng)絡(luò)加到12層以上。
那么如何理解各層學到了怎樣的信息?
本文作者Jesse Vig通過可視化工具對此進行了非常有意義的探究。文章分兩部分,第一部分介紹bert中的6種模式,第二部分介紹其底層細節(jié)。
可視化BERT之一
在BERT錯綜復雜的注意力網(wǎng)絡(luò)中,出現(xiàn)了一些直觀的模式。
2018年是自然語言處理領(lǐng)域的轉(zhuǎn)折之年,一系列深度學習模型在智能問答、情感分類等多種NLP任務(wù)上取得了最佳結(jié)果。特別是最近谷歌的BERT,成為了一種“以一當十的模型”,在各種任務(wù)上都取得了的極佳的表現(xiàn)。
BERT主要建立在兩個核心思想上,這兩個思想都包含了NLP最新進展:(1)Transformer的架構(gòu)(2)無監(jiān)督學習預訓練。
Transformer 是一種序列模型,它舍棄了 RNN 的順序結(jié)構(gòu),轉(zhuǎn)而采用了一種完全基于注意力的方法。這在經(jīng)典論文 《Attention Is All You Need》中有具體介紹。
BERT同時也要經(jīng)過預訓練。它的權(quán)重預先通過兩個無監(jiān)督任務(wù)學習到。這兩個任務(wù)是:遮蔽語言模型(masked language model,MLM)和下句一句預測(next sentence prediction)。
因此,對于每個新任務(wù),BERT不需要從頭開始訓練。相反,只要在預訓練的權(quán)重上進行微調(diào)(fine-tuning)就行。有關(guān)BERT的更多詳細信息,可以參考文章《圖解BERT》。
BERT是一只多頭怪
Bert不像傳統(tǒng)的注意力模型那樣只使用一個平坦的注意力機制。相反,BERT使用了多層次的注意力(12或24層,具體取決于模型),并在每一層中包含多個(12或16)注意力“頭”。由于模型權(quán)重不在層之間共享,因此一個BERT模型就能有效地包含多達24 x 16 = 384個不同的注意力機制。
可視化BERT
由于BERT的復雜性,所以很難直觀地了解其內(nèi)部權(quán)重的含義。而且一般來說,深度學習模型也是飽受詬病的黑箱結(jié)構(gòu)。所以大家開發(fā)了各種可視化工具來輔助理解。
可我卻沒有找到一個工具能夠解釋BERT的注意力模式,來告訴我們它到底在學什么。幸運的是,Tensor2Tensor有一個很好的工具,可用于可視化Transformer模型中的注意力模式。因此我修改了一下,直接用在BERT的一個pytorch版本上。修改后的界面如下所示。你可以直接在這個Colab notebook (https://colab.research.google.com/drive/1vlOJ1lhdujVjfH857hvYKIdKPTD9Kid8)里運行,或在Github上找到源碼。(https://github.com/jessevig/bertviz)。
這個工具將注意力看做不同的連線,它們用來連接被更新的位置(左半邊)與被注意的位置(右半邊)。(譯注:可以想象為神經(jīng)網(wǎng)絡(luò)是從右向左正向傳播的。)不同的顏色分別代表相應(yīng)的注意頭,而線條顏色的深淺代表被注意的強度。在這個小工具的頂部,用戶可以選擇觀察模型的第幾層,以及第幾個注意力頭(通過單擊頂部的色塊即可,它們分別代表著12個頭)。
BERT 到底學了什么?
我使用該工具探索了預訓練 BERT 模型各個層和各個頭的注意力模式(用全小寫(uncased)版本的BERT-Base 模型)。雖然我嘗試了不同的輸入句子,但為了方便演示,這里只采用以下例句:
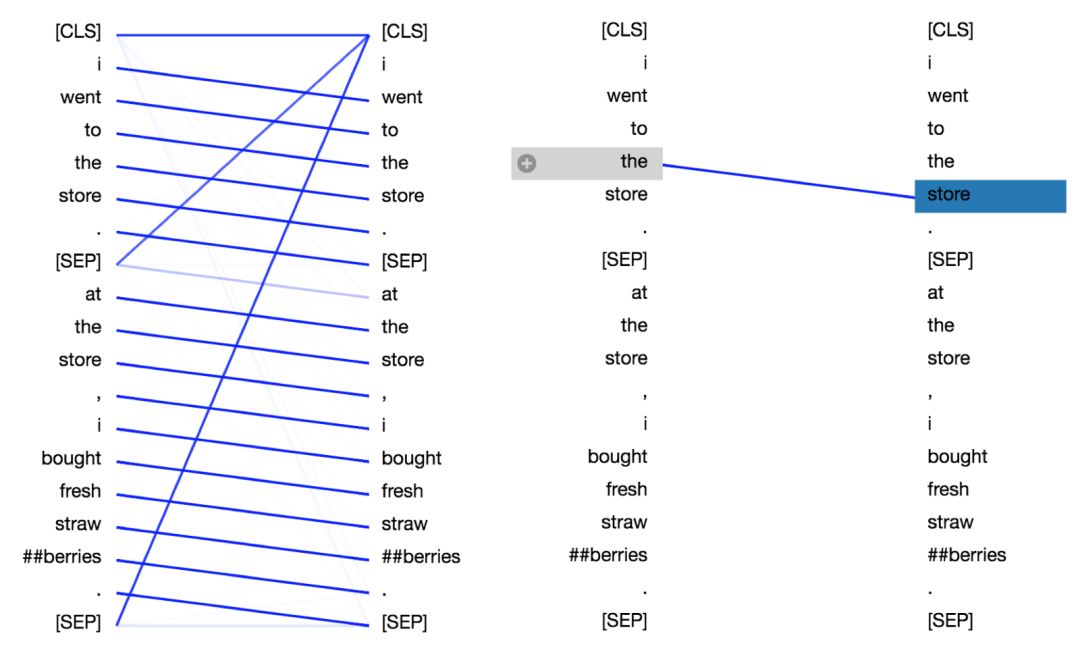
句子A:I went to the store.
句子B:At the store, I bought fresh strawberries.
BERT 用 WordPiece工具來進行分詞,并插入特殊的分離符([CLS],用來分隔樣本)和分隔符([SEP],用來分隔樣本內(nèi)的不同句子)。
因此實際輸入序列為:[CLS] i went to the store . [SEP] at the store , i bought fresh straw ##berries . [SEP]
在探索中,我發(fā)現(xiàn)了一些特別顯著的令人驚訝的注意力模式。下面是我確認的六種關(guān)鍵模式,將產(chǎn)生每一種模式的特定層和頭都進行可視化展示。
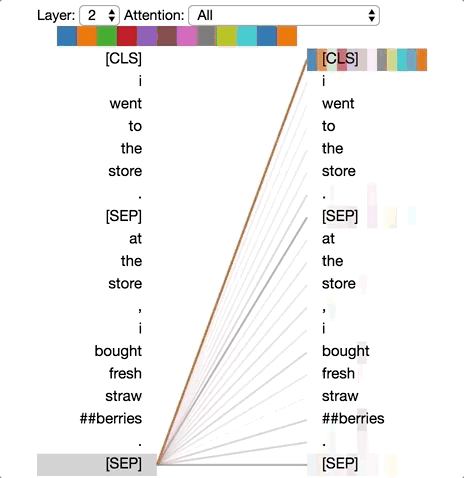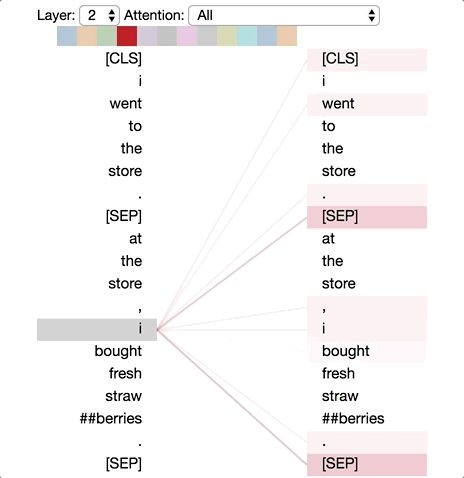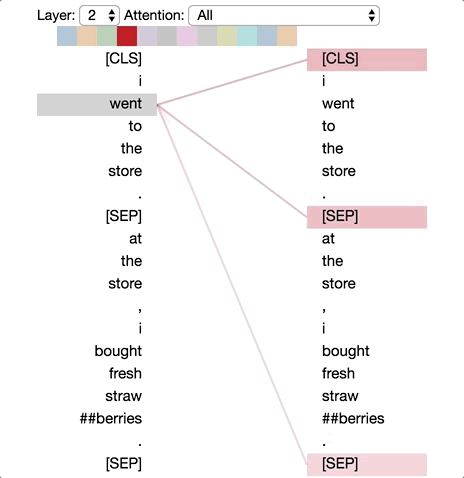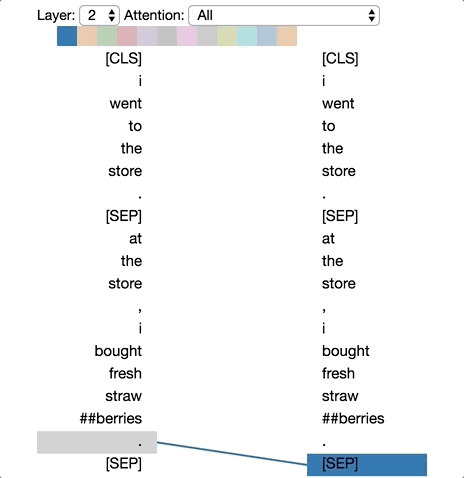
模式1:注意下一個詞
在這種模式中,每個位置主要注意序列中的下一個詞(token)。下面將看到第2層0號頭的一個例子。(所選頭部由頂部顏色條中突出的顯示色塊表示。)
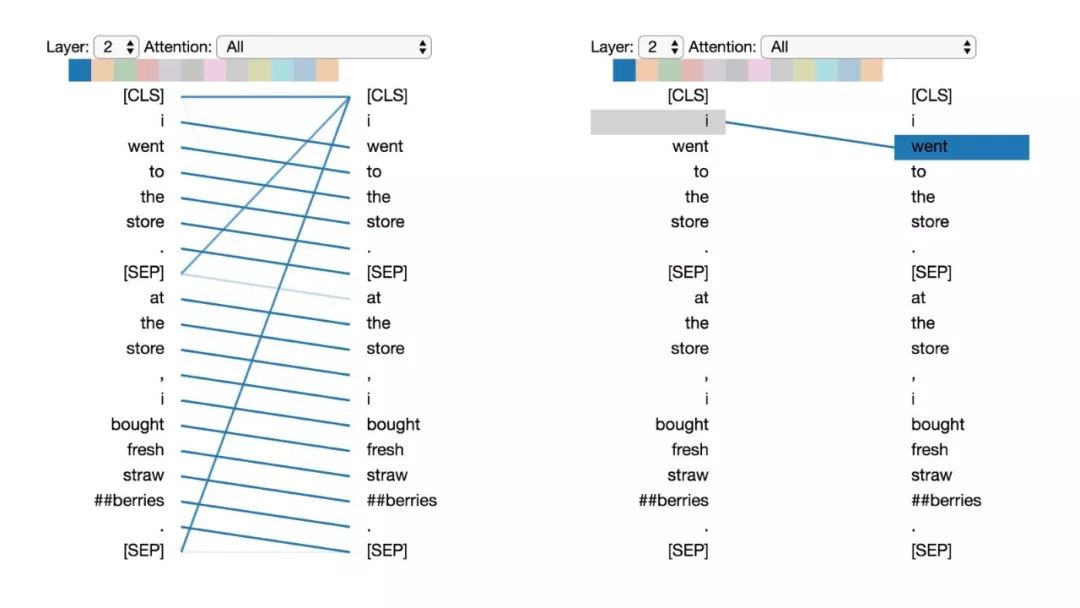
模式1:注意下一個詞。
左:所有詞的注意力。右:所選詞的注意力權(quán)重(“i”)
左邊顯示了所有詞的注意力,而右側(cè)圖顯示一個特定詞(“i”)的注意力。在這個例子中,“i”幾乎所有的注意力都集中在“went”上,即序列中的下一個詞。
在左側(cè),可以看到[SEP]符號不符合這種注意力模式,因為[SEP]的大多數(shù)注意力被引導到了[CLS]上,而不是下一個詞。因此,這種模式似乎主要在每個句子內(nèi)部出現(xiàn)。
該模式與后向RNN有關(guān),其狀態(tài)的更新是從右向左依次進行。模式1出現(xiàn)在模型的多個層中,在某種意義上模擬了RNN的循環(huán)更新。
模式2:注意前一個詞
在這種模式中,大部分注意力都集中在句子的前一個詞上。例如,下圖中“went”的大部分注意力都指向前一個詞“i”。
這個模式不像上一個那樣顯著。有一些注意力也分散到其他詞上了,特別是[SEP]符號。與模式1一樣,這與RNN有些類似,只是這種情況下更像前向RNN。
模式2:注意前一個詞。
左:所有詞的注意力。右:所選詞的注意力權(quán)重(“went”)
模式3:注意相同或相關(guān)的單詞
這種模式注意相同或相關(guān)的單詞,包括其本身。在下面的例子中,第一次出現(xiàn)的“store”的大部分注意力都是針對自身和第二次出現(xiàn)的“store”。這種模式并不像其他一些模式那樣顯著,注意力會分散在許多不同的詞上。
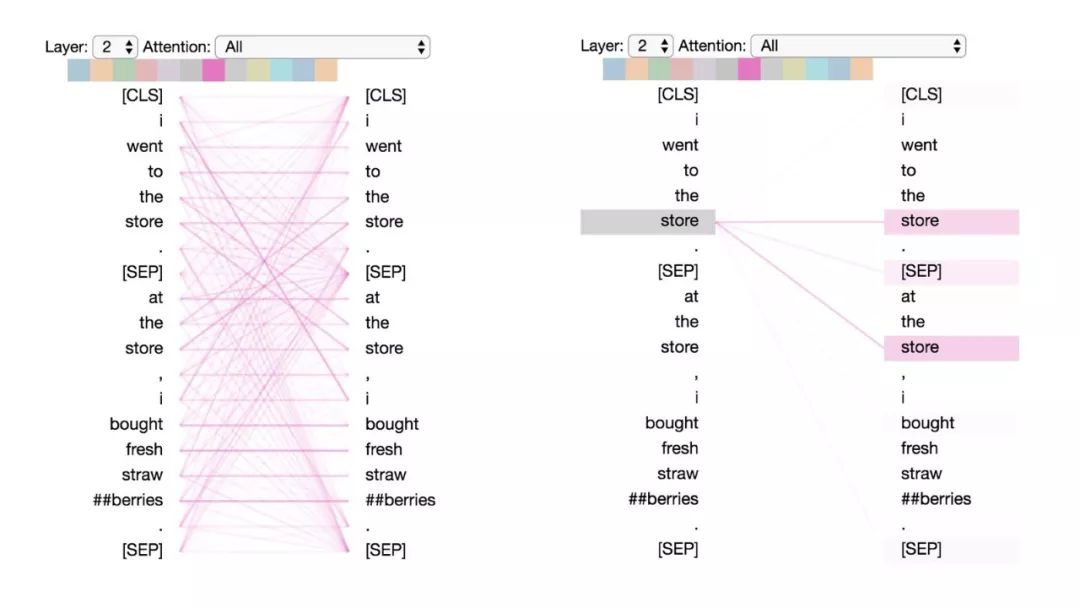
模式3:注意相同/相關(guān)的詞。
左:所有詞的注意力。右:所選詞的注意權(quán)重(“store”)
模式4:注意“其他”句子中相同或相關(guān)詞
這種模式注意另一個句子中相同或相關(guān)的單詞。例如,第二句中“store”的大部分注意力都指向第一句中的“store”。可以想象這對于下句預測任務(wù)(BERT預訓練任務(wù)的一部分)特別有用,因為它有助于識別句子之間的關(guān)系。
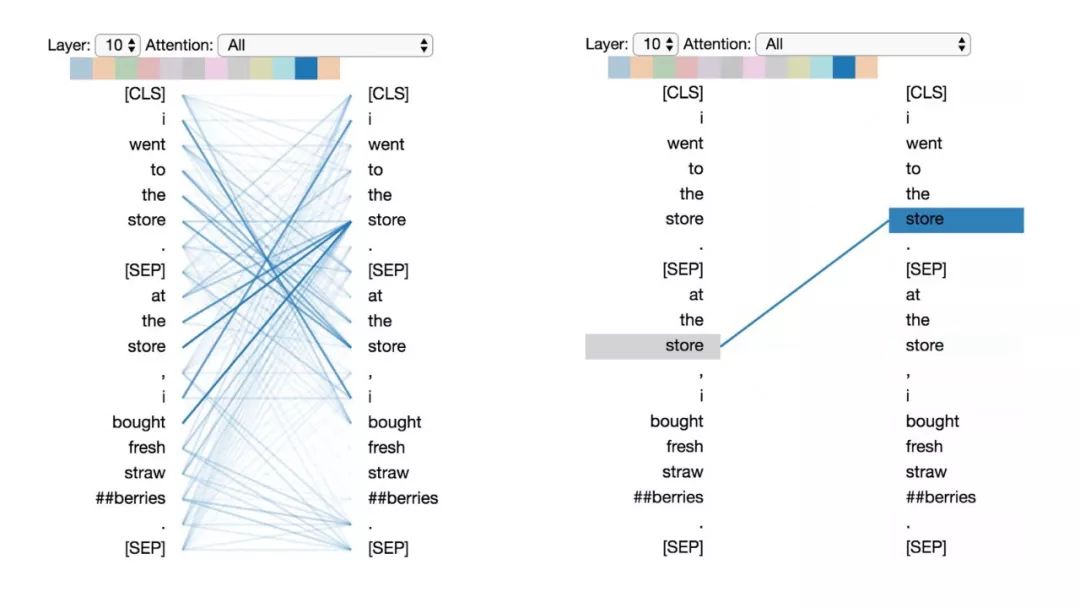
模式4:注意其他句子中相同/相關(guān)的單詞。
左:所有詞的注意力。右:所選詞的注意權(quán)重(“store”)
模式5:注意能預測該詞的其他單詞
這種模式似乎是更注意能預測該詞的詞,而不包括該詞本身。在下面的例子中,“straw”的大部分注意力都集中在“##berries”上(strawberries草莓,因為WordPiece分開了),而“##berries”的大部分注意力也都集中在“straw”上。
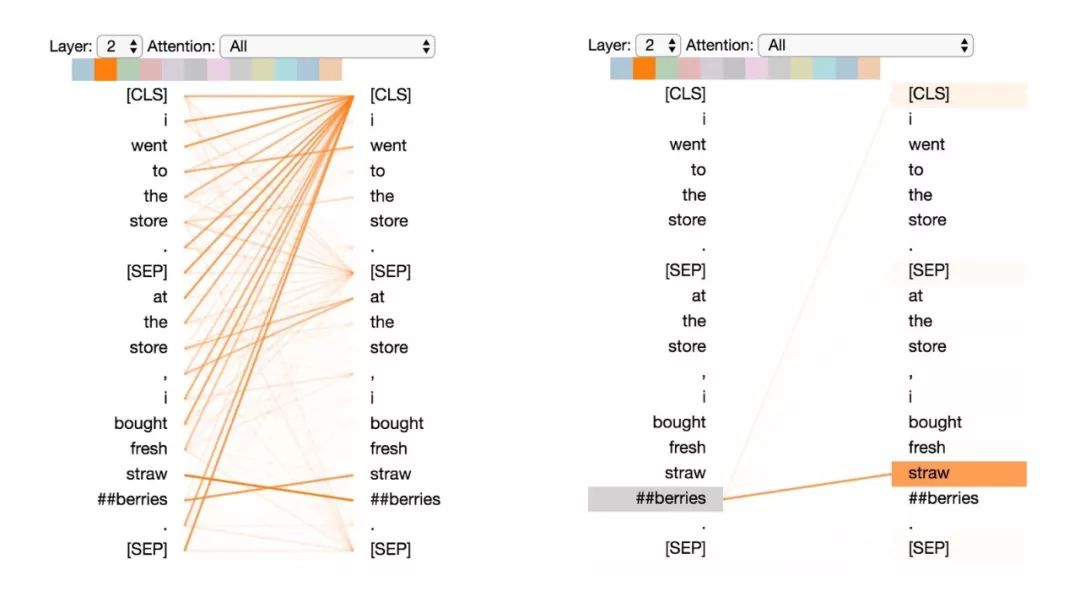
模式5:注意能預測該單詞的其他單詞。
左:所有詞的注意力。右:所選詞的注意力(“## berries”)
這個模式并不像其他模式那樣顯著。例如,詞語的大部分注意力都集中在定界符([CLS])上,而這是下面討論的模式6的特征。
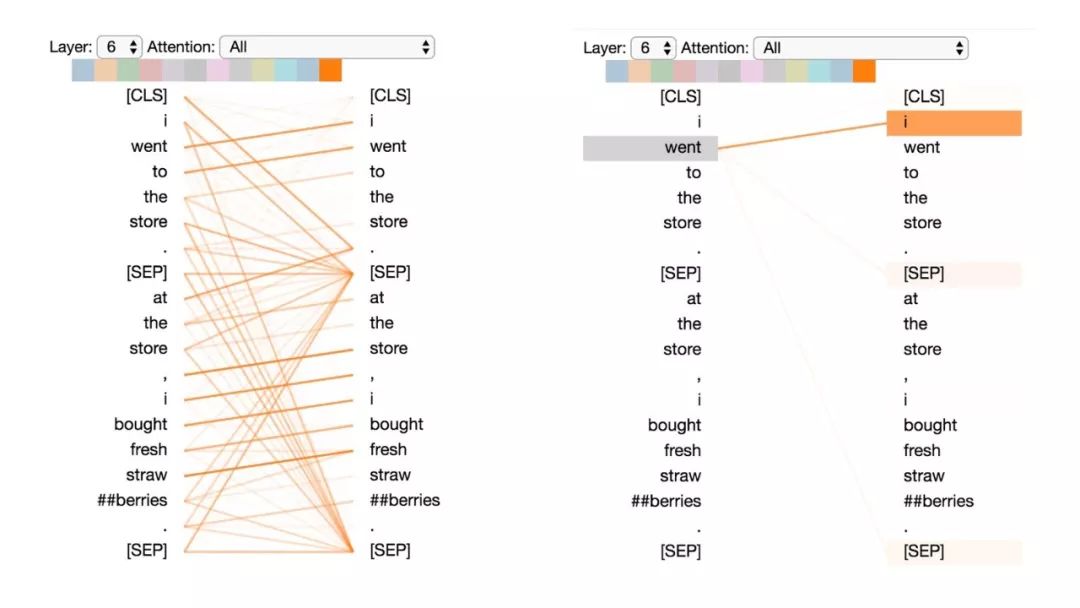
模式6:注意分隔符
在這種模式中,詞語的大部分注意力都集中在分隔符[CLS]或[SEP]上。在下面的示例中,大部分注意力都集中在兩個[SEP]符號上。這可能是模型將句子級狀態(tài)傳播到單個詞語上的一種方式。
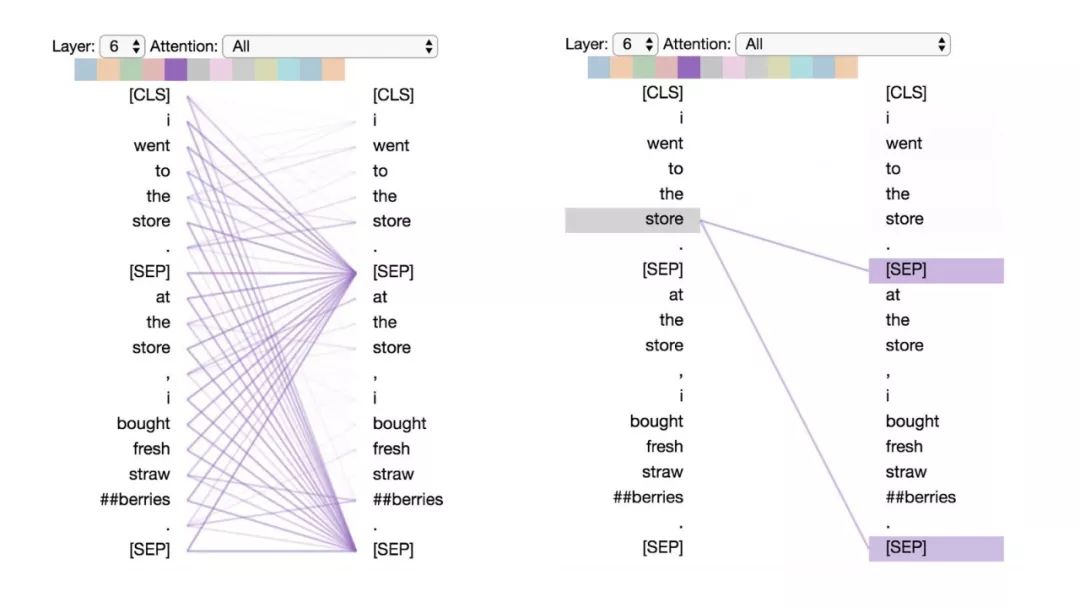
模式6:注意分隔符。左:所有詞的注意力。右:所選詞的注意權(quán)重(“store”)
說明
其實數(shù)據(jù)可視化有點像羅夏墨跡測驗(譯注:這種測驗叫人解釋墨水點繪的圖形以判斷其性格):我們的解釋可能會被我們的主觀信念和期望所影響。雖然上面的一些模式非常顯著,但其他模式卻有點主觀,所以這些解釋只能作為初步觀察。
此外,上述6種模式只是描述了BERT的粗略注意力結(jié)構(gòu),并沒有試圖去描述注意力可能捕獲到的語言學(linguistic)層面的模式。例如,在模式3和4中,其實可以表現(xiàn)為許多其他不同類型的“相關(guān)性”,例如同義關(guān)系、共同指代關(guān)系等。
而且,如果能看到注意力頭是否抓取到不同類型的語義和句法關(guān)系,那將會非常有趣。
可視化BERT之二:探索注意力機制的內(nèi)部細節(jié)一
在這里,一個新的可視化工具將展示BERT如何形成其獨特的注意力模式。
在上文中,我講解了BERT的注意力機制是如何呈現(xiàn)出多種模式的。例如,一個注意力頭會主要注意序列中的下一個詞;而另一個注意力頭會主要注意序列中的前一個詞(具體看下方圖示)。在這兩種情況中,BERT在本質(zhì)上都是學習一種類似RNN的序列更新的模式。之后,我們也將展示BERT是如何建模詞袋模型(Bag-of-Words)的。
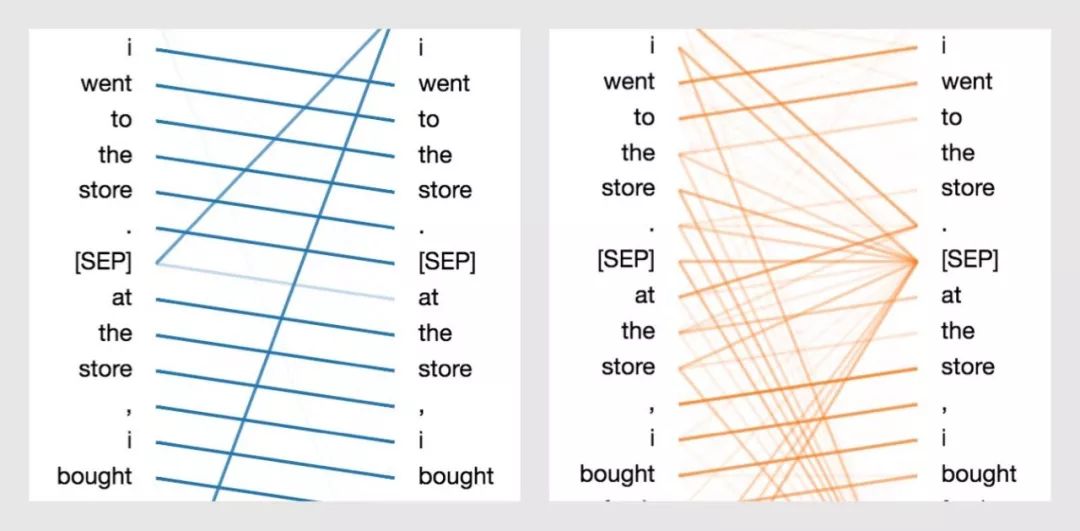
通過BERT學習下一個單詞和上一個單詞的注意力模式
那么BERT是如何學到這些極好的特性呢?為了解決這個問題,我從第一部分擴展了可視化工具來更深入地探索BERT——揭示提供BERT強大建模能力的神經(jīng)元。你可以在這個Colab notebook或者Github上找到這個可視化工具。
最初的可視化工具(基于由Llion Jones出色完成的Tensor2Tensor)嘗試來解釋什么是注意力:也就是說,BERT到底在學習什么樣的注意力結(jié)構(gòu)?那么它是怎樣學到的呢?為了解決這個問題,我添加了一個注意力細節(jié)視圖,來可視化注意力的計算過程。詳細視圖通過點擊⊕圖標按鈕來查看。你可以看到以下的一個demo示例,或直接跳到屏幕截圖。
可視化工具概覽
BERT有點像魯布·戈德堡機(譯注:是一種被設(shè)計得過度復雜的機械組合,以迂回曲折的方法去完成一些其實是非常簡單的工作,例如倒一杯茶,或打一只蛋。),盡管每個組件都非常直觀,但是系統(tǒng)整體很難把握。現(xiàn)在我將通過可視化工具介紹BERT注意力架構(gòu)的各個部分。(想了解有關(guān)BERT的全部教程,推薦《圖解transformer》和《圖解BERT》這兩篇文章。)
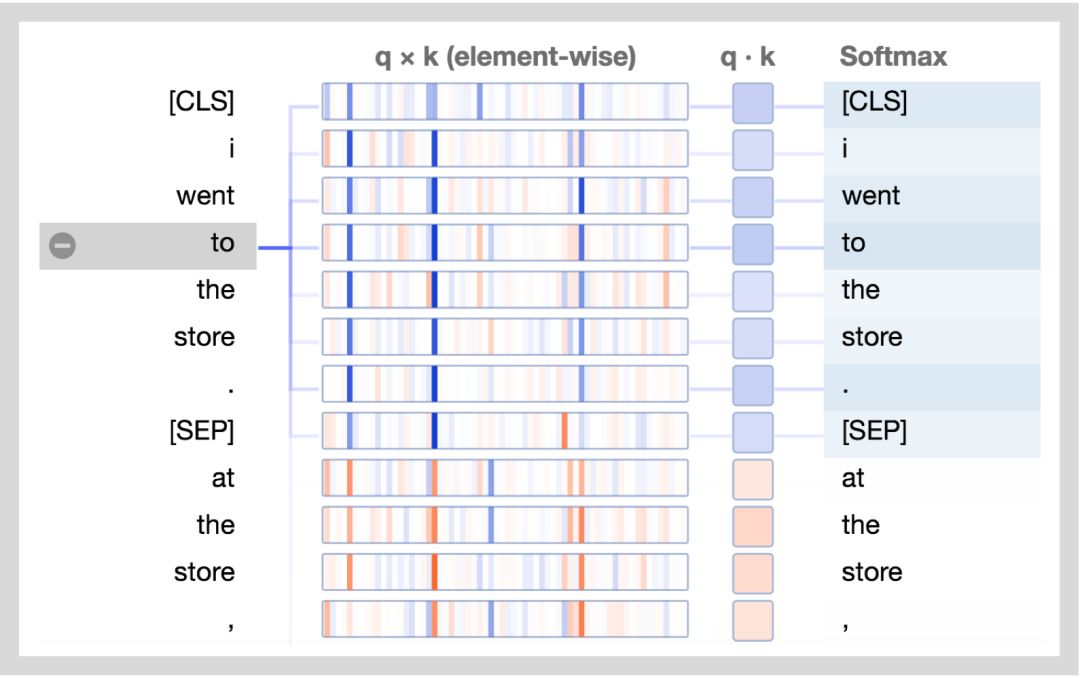
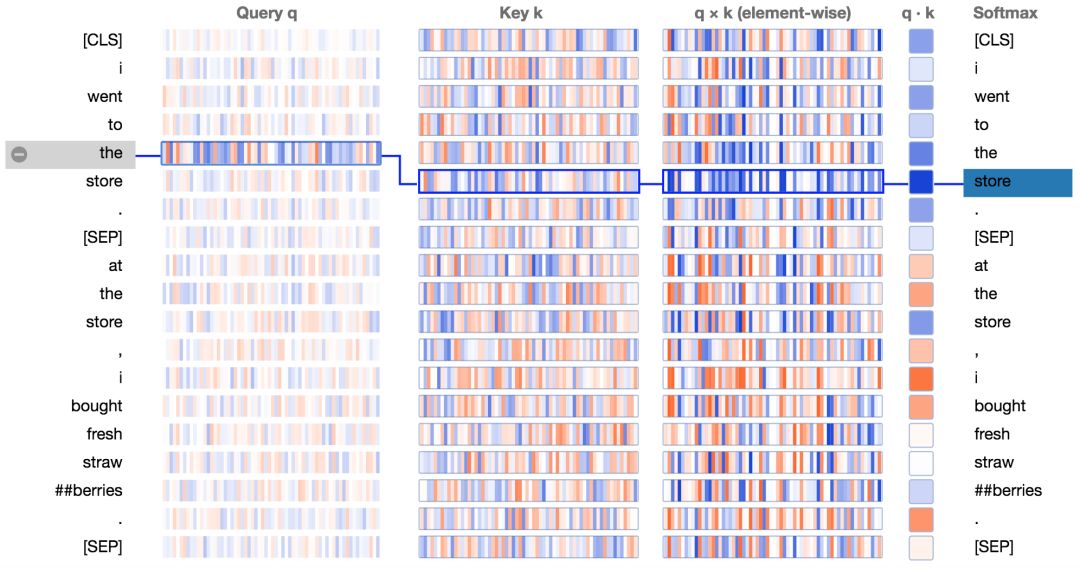
下方展示了新的注意力細節(jié)視圖。圖中正值是藍色的,負值是橙色的,顏色的深淺反映了取值的大小。所有的向量都是64維的,并且作用于某個特定的注意力頭上。和最初的可視化工具類似,連接線顏色的深淺代表了單詞之間的注意力強度。
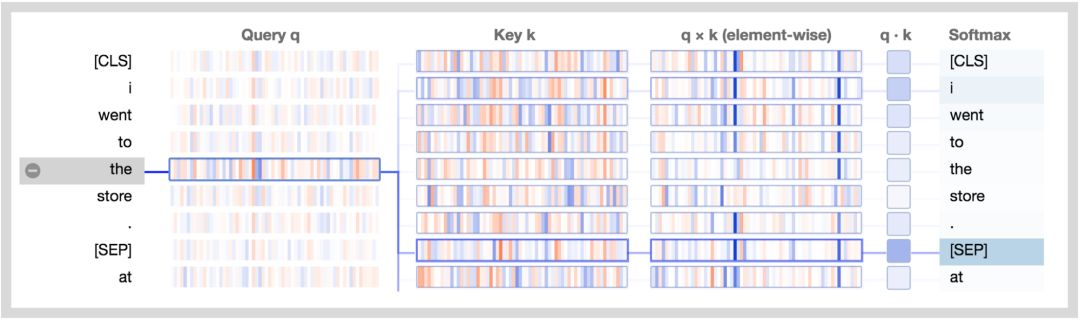
讓我們結(jié)合圖分析一下:
查詢向量q :查詢向量q是左邊正在進行注意力過程的單詞/位置的編碼,也就是說由它來“查詢”其他的單詞/位置。在上述的例子中,“the”(選中的單詞)的查詢向量標注出來了。
鍵向量k:鍵向量k是右邊正在“被注意”的單詞的編碼。如下所述,鍵向量和查詢向量決定了單詞被注意程度的得分。
q×k(element-wise):查詢向量和鍵向量的逐元素積(譯注:element-wise product, 也叫哈達瑪積/Hadamard product)。這個逐元素積是通過選定的查詢向量和每個鍵向量計算得到的。這是點積(逐元素乘積的和)的前導。由于它展示了查詢向量中的單個元素和鍵向量對點積的貢獻,因此將其可視化。選定的查詢向量和每個鍵向量的點積。得到的是非歸一化的注意力得分。
Softmax:所有目標單詞的q·k/ 8的softmax值。這一步實現(xiàn)了注意力得分的歸一化,保證了值為正的且和為1。常量8是向量長度(64)的開方。論文(https://arxiv.org/pdf/1706.03762.pdf)描述了這樣做的原因。
解析BERT的注意力模式
在第一部分文章中,我在BERT的注意力頭的結(jié)構(gòu)中發(fā)現(xiàn)了一些模式。來看看我們是否能使用新的可視化工具來理解BERT是如何形成這些模式的。
注意分隔符
讓我們以一個簡單的例子起手,這個例子中大多數(shù)注意力是聚焦于分隔符[SEP]的(第一部分文章中的模式6)。如第一部分文章中所描述的,這個模式可能是BERT用來將句子級的狀態(tài)傳播到單詞級狀態(tài)的一種方式。

基于BERT預訓練模型的第7層3號頭,聚焦分隔符注意力模式。
所以,BERT是如何直接聚焦于[SEP]符號的呢?來看看可視化工具。下面是上述例子的注意力細節(jié)視圖。
在鍵向量列,兩個出現(xiàn)[SEP]處的鍵向量有顯著的特點:它們都有少量的高正值(藍色)和低負值(橘色)的激活神經(jīng)元,以及非常多的接近0的(淺藍,淺橘或白色)的神經(jīng)元。

第一個分隔符[SEP]的鍵向量。
查詢向量q會通過那些激活神經(jīng)元來匹配[SEP]鍵向量,會使元素內(nèi)積q×k產(chǎn)生較高的值,如下例子所示:
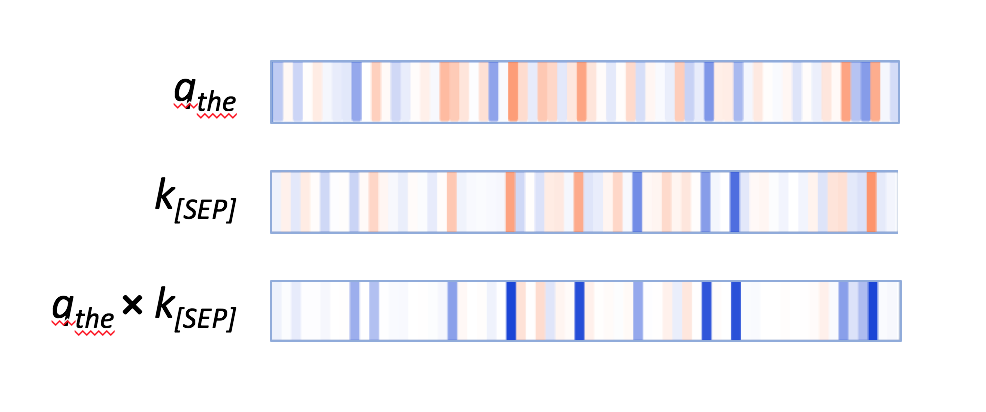
第一個“the”的查詢向量;第一個[SEP]的鍵向量;兩個向量的逐元素積。
其他單詞的查詢向量也遵循相似的模式;它們通過同一組神經(jīng)元來匹配[SEP]鍵向量。因此,BERT似乎指定了一小部分神經(jīng)元作為“[SEP]-匹配神經(jīng)元”,而查詢向量也通過這些相同位置的值來匹配[SEP]鍵向量。這就是注意分隔符[SEP]的注意力模式。
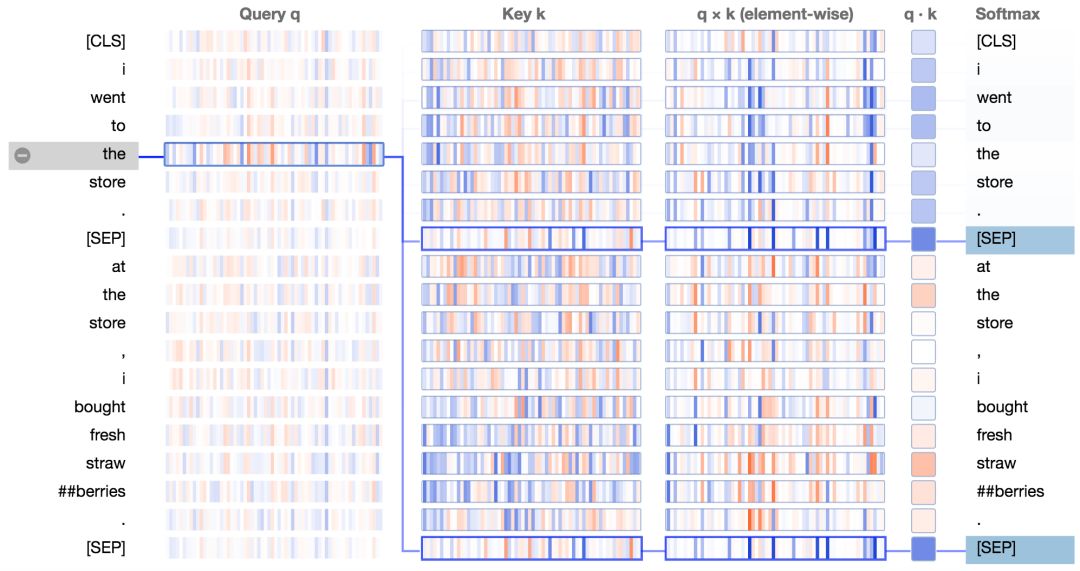
注意句子:詞袋模型(Bag of Words)
這是一個不太常見的模式,在第一部分文章中沒有具體討論。在這種模式中,注意力被平均的分配到句子中的每個單詞上。

基于BERT預訓練模型的第0層0號頭,專注句子的注意力模式
這個模式的作用是將句子級的狀態(tài)分配到單詞級上。BERT在這里本質(zhì)上是通過對所有詞嵌入進行幾乎相等權(quán)重的加權(quán)平均操作來計算一個詞袋模型。詞嵌入就是我們之前提到的值向量。
那么BERT是怎樣處理查詢向量和鍵向量來形成這種注意力模式的呢?讓我們再來看看注意力細節(jié)視圖;
基于BERT預訓練模型的第0層0號頭,專注句子的注意力模式細節(jié)視圖。
在q×k這列,我們能看到一個清晰的模式:少量神經(jīng)元(2-4個)控制著注意力得分的計算。當查詢向量和鍵向量在同個句子中時(上例中第一個句子),這些神經(jīng)元的乘積顯示出較高的值(藍色)。當查詢向量和鍵向量在不同句子中時,在這些相同的位置上,乘積是負的(橘色),如下例子所示:
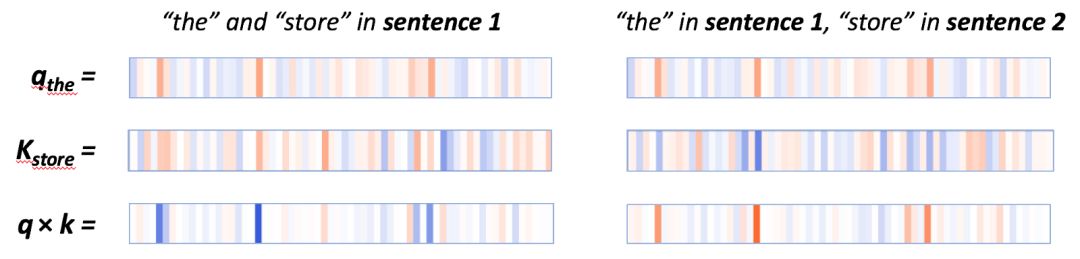
在同個句子中(左邊)q*k的逐元素積很高,在不同句子中(右邊)q*k的逐元素積很低。
當查詢向量和鍵向量都來自第一個句子中時,它們在激活神經(jīng)元上往往有相同的符號,因此會產(chǎn)生一個正積。當查詢向量來自第一個句子中時,鍵向量來自第二個句子時,相同地方的神經(jīng)元會有相反的符號,因此會產(chǎn)生一個負值。
但是BERT是怎么知道“句子”這個概念的?尤其是在神經(jīng)網(wǎng)絡(luò)第一層中,更高的抽象信息還沒有形成的時候。這個答案就是添加到輸入層(見下圖)的句子級嵌入(sentence-level embeddings)。這些句子嵌入的編碼信息傳遞到下層的變量中,即查詢向量和鍵向量,并且使它們能夠獲取到特定句子的值。
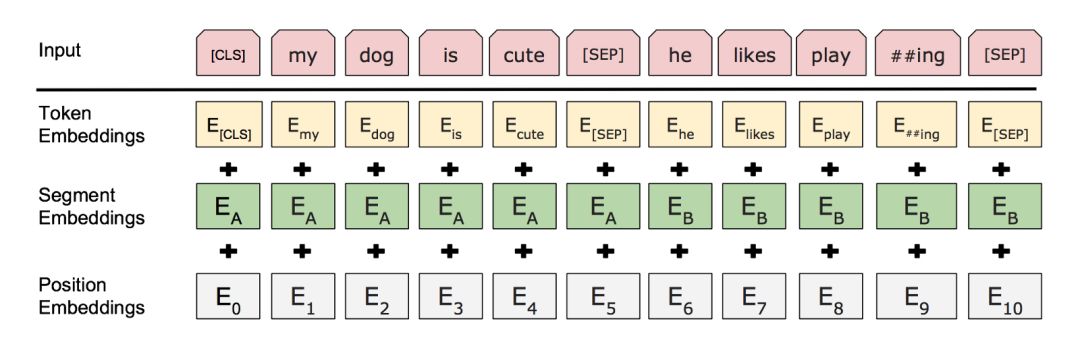
句子A和B的部分嵌入以及位置嵌入被添加到詞嵌入中
(來自BERT論文(https://arxiv.org/pdf/1810.04805.pdf))
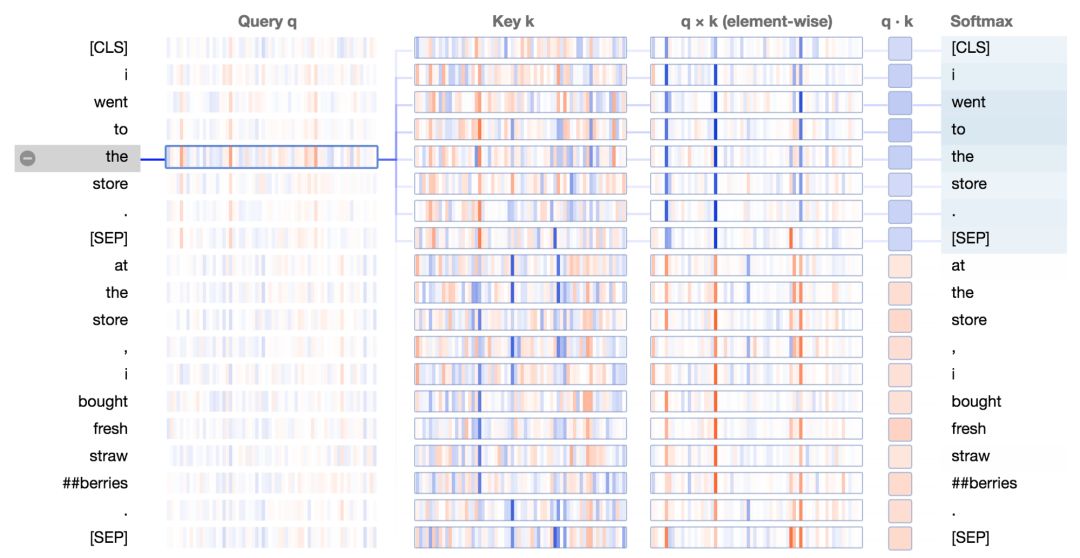
注意下一個詞
在這種注意力模式中,除了分隔符,其他所有的注意力都集中在輸入序列的下個單詞上。
基于BERT預訓練模型的第2層0號頭,注意下一個詞的注意力模式。
這個模式能夠使BERT捕獲序列關(guān)系,如二元語法(bigrams)。我們來查看它的注意力細節(jié)視圖;
我們看到查詢向量“the”和鍵向量“store”(下個單詞)的乘積在大多數(shù)神經(jīng)元中是很高的正值。對于下一個單詞之外的其他單詞,q*k乘積包含著一些正值和負值。最終的結(jié)果是“the”和“store”之間的注意力得分很高。
對于這種注意力模式,大量的神經(jīng)元參與到注意力得分中。而且這些神經(jīng)元根據(jù)詞位置的不同而不同,如下所示:
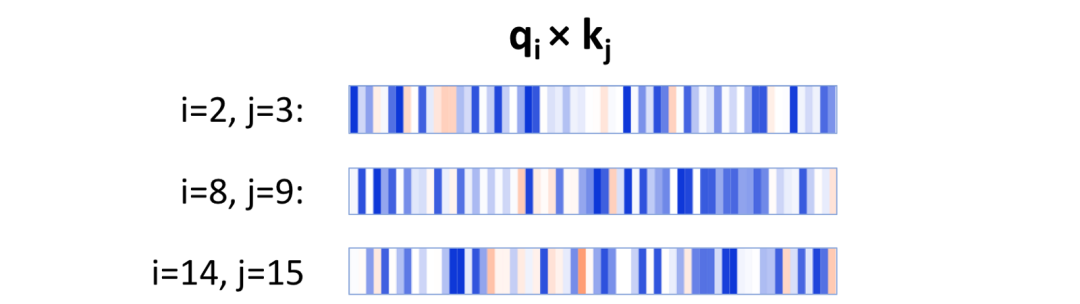
當i取2,4,8的時候,在位置i處的查詢向量和在j = i+1處的鍵向量的逐元素積。注意激活神經(jīng)元在每一個例子中都不同。
這種方式不同于注意分隔符以及注意句子的注意力模式,它們是由少量固定的神經(jīng)元來決定注意力得分的。對于這兩種模式,只有少量的神經(jīng)元是必須的,因此這兩種模式都很簡單,并且在被注意的單詞上都沒多少變化。與它們相反,注意下個單詞的注意力模式需要追蹤512個單詞(譯注:在BERT中每個樣本最多512個單詞。)中到底是哪個是被一個給定的位置注意的,即哪個是下一個單詞。為了實現(xiàn)這個功能,需要產(chǎn)生一系列查詢向量和鍵向量,其中每個查詢向量會有從512個鍵向量有唯一一個匹配。因此使用少量神經(jīng)元很難完成這個任務(wù)。
那么BERT是如何能夠生成這些查詢向量和鍵向量呢?答案就在BERT的位置嵌入(position embeddings),它在輸入層(見圖1)中被添加到詞嵌入(word embeddings)中。BERT在輸入序列中學習512個獨特的位置嵌入,這些指定位置的信息能通過模型流入到鍵向量和查詢向量中。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4783瀏覽量
101240 -
圖像
+關(guān)注
關(guān)注
2文章
1089瀏覽量
40592 -
可視化
+關(guān)注
關(guān)注
1文章
1203瀏覽量
21040
原文標題:用可視化解構(gòu)BERT,我們從上億參數(shù)中提取出了6種直觀模式
文章出處:【微信號:BigDataDigest,微信公眾號:大數(shù)據(jù)文摘】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
七款經(jīng)久不衰的數(shù)據(jù)可視化工具!
從使用效果來看,數(shù)據(jù)可視化工具離不開數(shù)據(jù)中臺嗎?
能做數(shù)據(jù)治理的數(shù)據(jù)可視化工具,又快又靈活
現(xiàn)在做企業(yè)級數(shù)據(jù)分析,離不開秒分析的數(shù)據(jù)可視化工具
這樣選數(shù)據(jù)可視化工具,更能選到適用的
SpeedBI數(shù)據(jù)可視化工具:瀏覽器上做分析
緊跟老板思維,這款數(shù)據(jù)可視化工具神了
mongodb可視化工具如何使用_介紹一款好用 mongodb 可視化工具
建議收藏的20款實用的數(shù)據(jù)可視化工具
數(shù)據(jù)可視化工具的圖表主要分為哪些
怎么挑選合適企業(yè)需求的數(shù)據(jù)可視化工具
幾款好用的可視化工具推薦

一鍵生成可視化圖表/大屏 這13款數(shù)據(jù)可視化工具很強大





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論