 Facebook研究者擴展并增強LASER工具包,并在近期開源這個項目
Facebook研究者擴展并增強LASER工具包,并在近期開源這個項目
為了加速自然語言處理 (NLP) 在更多語言上實現零樣本遷移學習 (zero-shot transfer learning),Facebook 研究者擴展并增強了 LASER (Language-Agnostic Sentence Representations) 工具包,并在近期開源了這個項目。
增強版的 LASER 是首個能夠成功探索大型多語種句子表征的工具包,共包含 90 多種語言,由 28 種不同的字母表編寫。這項龐大的工作也引發了整個 NLP 社區的廣泛關注。該工具包將所有語言聯合嵌入到單個共享空間,而不是為每個語言單獨建立模型。目前,Facebook 官方免費提供多語言編碼器和 PyTorch 代碼(鏈接:https://github.com/facebookresearch/LASER),以及 100 多種語言的多語言測試集方便社區使用。
研究者表示,通過零樣本遷移學習,LASER 能夠將 NLP 模型從一種語言 (如英語) 遷移到其他語言 (包括訓練集中的有限語種)。此外,LASER 工具也是第一個使用單一模型來處理不同語種的自然語言處理庫,包括處理那些稀有語種如卡拜爾語、維吾爾語以及中國的吳語等方言。研究者相信,有朝一日這項工作能夠幫助 Facebook 及其他公司上線特定的 NLP 功能,如用一種語言將電影評論分類為正面或負面,然后再部署到其他 100 多種語言上去。
下面讓我們一睹 LASER 工具包的風采。
性能和功能亮點
在包含 14 種語種的 XNLI 語料庫中,LASER 工具通過零樣本遷移學習,為其中 13 種語言實現跨語種的自然語言處理,并獲得當前最佳的推斷準確率。此外,它還在跨語言文檔分類 (MLDoc 語料庫) 中取得了極有競爭力的結果。在句子嵌入方面,該工具包在并行語料庫挖掘任務中也展現了強大的功能,并在 BUCC 共享任務中為其四種語言對中的三種建立了當前最佳的基準。值得一提的是,BUCC 是 2018 年建立和使用可比較語料庫的研討會,代表了當前該領域的最新進展。
除了 LASER 工具包,研究者還基于 Tatoeba 語料庫共享一組 100 多種全新語言對齊語句的測試集。通過該數據集,在多語言相似性搜索任務上,句子嵌入功能取得了非常優秀的結果,即便是對那些稀有語種也是如此。
此外,LASER 工具包還具有如下一些優點:
極快的性能和極高的處理效率:在 GPU 上每秒處理多達 2000 個句子。
通過 PyTorch 中實現句子編碼器具有最小的外部依賴性。
稀有語種可以從多種語言的聯合訓練中收益。
該模型支持在一個句子中使用多種語言。
隨著新語言的添加,模型性能也會有所提高,因為系統能夠自動學習并識別語言族的特征。
通用的語言無關性句子嵌入
LASER 中的句子向量表征對于輸入語言和 NLP 任務都是通用的。該工具將任何語種的句子映射到高維空間中的一個點,目的是將各語種的語句最終聚合在同一鄰域附近,而這種句子表征可被視為是語義向量空間中的通用語言。如下圖所示,可以看到該空間中的距離與句子語義的接近度是非常相關的。
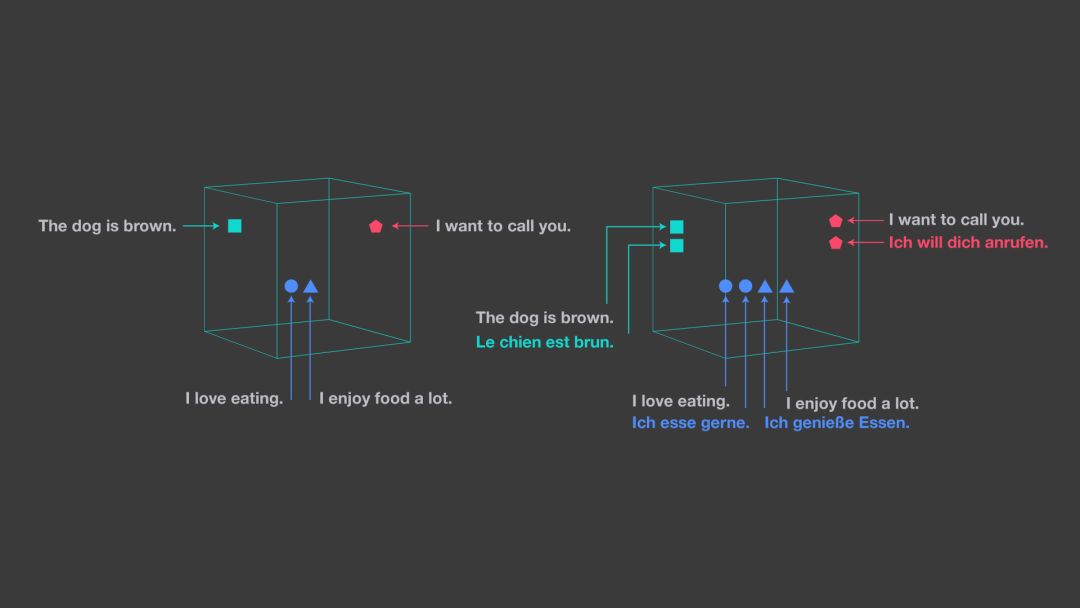
左圖展示的是單個語言的嵌入空間,而右圖顯示的是采用 LASER 工具包方法,它能將所有語言嵌入到同一共享空間中。
LASER 的這種方法是基于神經機器翻譯的基礎技術:即編碼器/*** (encoder/decoder),也稱為序列到序列處理 (sequence-to-sequence)。它為所有的輸入語言設計一個共享編碼器,并使用共享解碼器生成輸出語言。編碼器由五層雙向連接的 LSTM 網絡 (長短期記憶) 組成。
與神經機器翻譯的方法不同的是,LASER 中不引入注意力機制,而是使用 1024 維、固定大小的向量來表示輸入句子。該向量是通過對 BiLSTM 最后狀態進行最大池化操作后得到的,這使我們能夠比較句子表征的差異,并將它們直接輸入到分類器中。
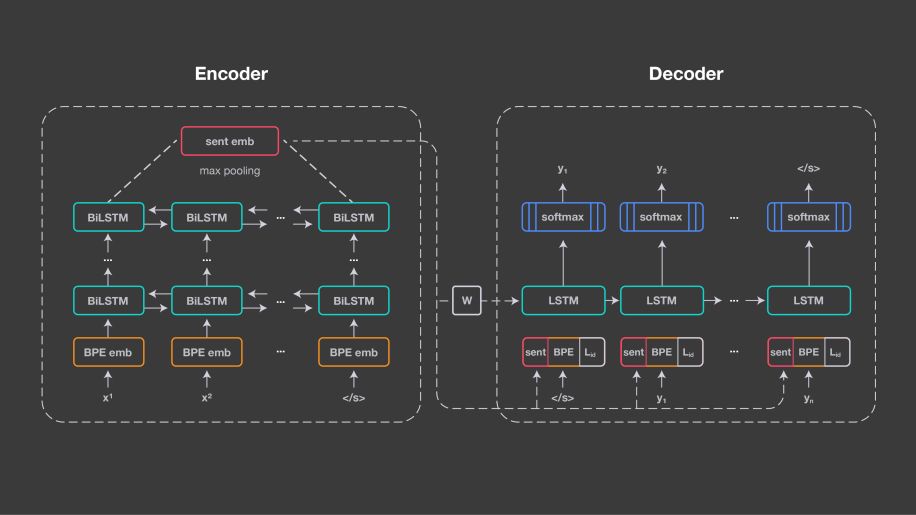
圖中描述了 LASER 的基本架構
這些句子嵌入是通過線性變換的方式初始化解碼器 LSTM,并且還在每個時間步驟與其輸入嵌入相連接。為了通過句子嵌入來捕捉輸入序列的所有相關信息,在架構中編碼器和解碼器之間沒有設置其他連接。
對于解碼器部分,由于它需要一個語言標識嵌入,因此需要清楚地知道需要生成哪種語言,并在每個時間步驟連接輸入及其句子嵌入。研究者使用具有 50000 個操作的聯合字節對編碼詞匯表 (BPE),并在所有訓練語料庫的連接上進行訓練。由于編碼器沒有顯式地指示輸入語言信號,因此該方法鼓勵它學習與語言無關的表征。
不僅如此,研究者還使用英語或西班牙語對公共并行數據中 2.23 億條句子進行了系統的訓練。對于每個小批量,隨機選擇一種輸入語言并訓練模型,使其將句子翻譯成英語或西班牙語中的一種,而不需要讓大多數語言都與目標語言保持一致。
這項工作的開始只是訓練不到 10 種的歐洲語言,所有語言都使用相同的拉丁文字;隨后逐漸增加到 21 種語言,這些都是在 Europarl 語料庫中出現的。
實驗結果表明,隨著所添加的語言數量的增多,多語言間的遷移性能也得到了提高,而該系統也能夠學習到語言族的通用特征。正因為如此,部分稀有語言也能夠受益于同一語言族的一些高頻語言的資源。
通過使用在連接所有語言的數據庫上訓練共享的 BPE 詞匯表,這是完全有可能做到的。對每種語言的 BPE 詞匯表分布之間對稱的 Kullback-Leiber 距離進行分析和聚類結果表明,其與語言家族之間存在幾乎完美的相關性。

圖中顯示了 LASER 能夠自動挖掘各種語言之間的關系,這與語言學家手動定義的語言類別是高度吻合的。
研究者意識到,單個共享的 BiLSTM 編碼器能夠處理多個腳本。他們逐漸擴展到那些可用的并行文本中的所有語言,并將 93 種語言并入到 LASER 工具包中,這些語言包括 subject-verb-object (SVO) order (如英語),SOV order (如孟加拉語和突厥語),VSO order (如塔加路語和柏柏爾語),以及 VOS order (如馬達加斯加語)。
該編碼器能夠推廣到一些未使用的語言,甚至是單語言文本。在訓練階段,可以觀察到它在一些地區語言中展現了突出的能力,包括阿斯圖里亞斯語、法羅語、弗里斯蘭語、卡舒比語、北摩鹿加語馬來語、皮埃蒙特語、斯瓦比亞語和索布語等。這些語言與那些主要語言在不同程度上都有一定的相似之處,但不同語言有其特定的語法或特定詞匯。
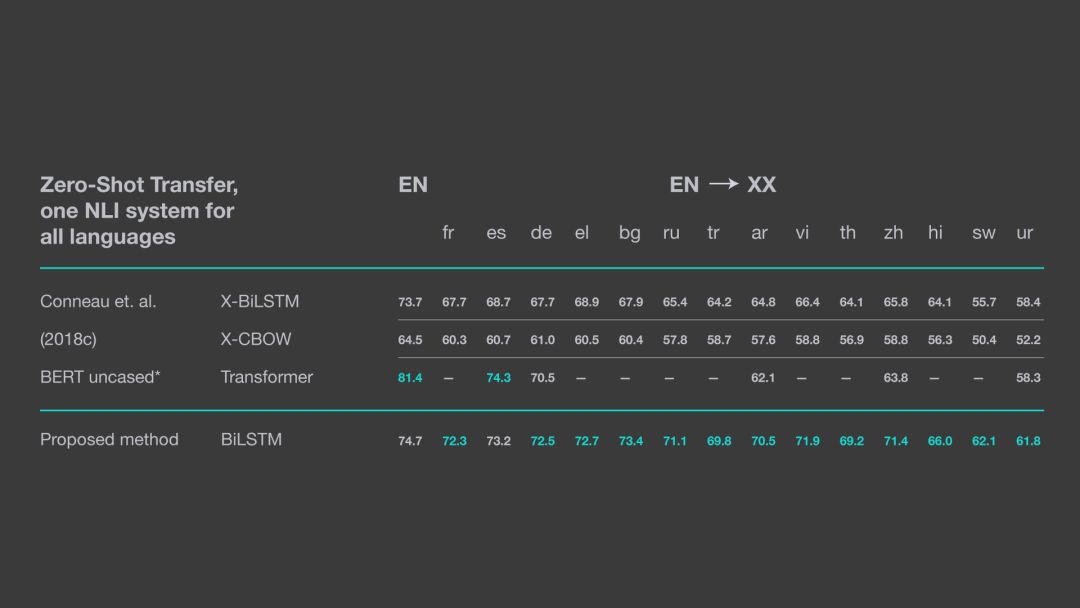
上表展示了 LASER 在 XNLI 語料庫上進行零樣本遷移學習的性能表現。其中,BERT 模型的結果是從其他 github 項目中提取的。值得注意的是,這些結果都是通過 Pytorch1.0 實現的,因此在具體數值方面可能與原論文中的有所不同,論文中使用的是 Pytorch0.4。
零樣本、跨語言的自然語言推理
該模型在跨語言的自然語言推理任務上 (NLI) 取得了優異的成績,表明模型具有極強的句意表征能力。研究者采用零樣本遷移學習的方法,即先在英語上訓練 NLI 分類器,在沒有任何模型微調或其他目標語言數據的情況下,將訓練好的分類器應用于其他目標語言。對于 14 種語言的 8 種,零樣本學習在諸如英語、俄語、中文和越南語等語言上能夠取得 5%以內的表現。
此外,研究者還在斯瓦希里語和烏爾都語等稀有語言上進行試驗,同樣取得了很好的結果。最后,LASER 方法在 14 種語言中有 13 種語言都取得了優于其他零樣本遷移學習方法的表現。
相較于先前研究中至少需要一個英語句子進行學習的方法,LASER 是一種完全跨語種、并支持不同語言間任何組合的自然語言處理方法。
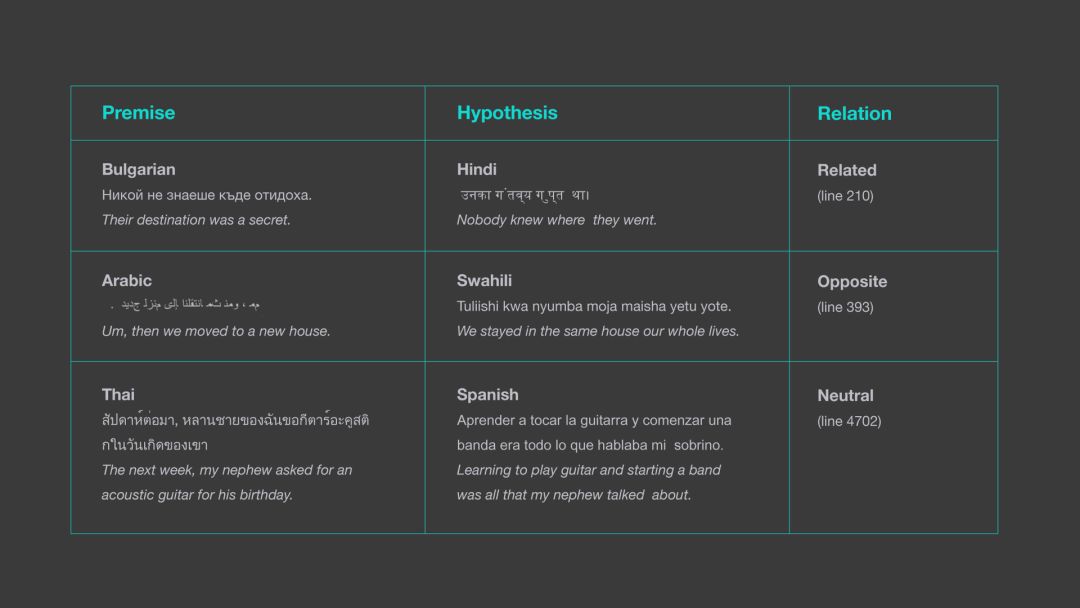
上圖展示了 LASER 是如何確定 XNLI 數據集中不同語言句子間的關系,而先前研究中的方法都只能考慮同一種語言的前提和假設。
此外,LASER 也可用于挖掘大型單語言文本數據集中的并行數據信息。研究表明,只需要計算所有句子對之間的距離并選擇最接近的句子對,就能夠提取文本數據中的數據信息。更進一步地說,通過考慮相近句子及其最近鄰居之間的邊界能夠改進該方法的表現,而通過使用 Facebook 的 FAISS 庫就能夠高效完成這一改進。
在共享 BUCC 任務上,LASER 的表現都遠遠超過當前最佳的技術水平。具體來說,該模型將德語/英語的 F1 得分從 85.5 提高到 96.2,將法語/英語的 F1 得分從 81.5 提高到 93.9,俄語/英語的 F1 得分從 81.3 提高到 93.3,中/英語的表現從 77.5 提高到 92.3。正如這些示例所反映的,該模型在各種語言任務上所取得結果都是高度同質的。
更多詳細的內容介紹可以查看相關的論文:《Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond》(論文鏈接:https://arxiv.org/abs/1812.10464)。
最后,研究者表明,對于任意語言對,都可以通過相同的方法來挖掘 90 多種語言的并行數據。在未來,這將顯著改善許多依賴于并行數據訓練的 NLP 應用程序,包括那些稀有語言的神經機器翻譯應用。
未來的應用
LASER 可以應用于廣泛的自然語言處理任務。例如,多語言語義空間的屬性可用于解析句意或搜索具有相似含義的句子,可以通過使用相同語言或通過 LASER 所支持的其他 93 個語句中的任何一個就能實現。未來,研究人員表示將繼續添加其他的語言支持。
-
Facebook
+關注
關注
3文章
1432瀏覽量
56207 -
Laser
+關注
關注
0文章
22瀏覽量
9392 -
遷移學習
+關注
關注
0文章
74瀏覽量
5688
原文標題:Facebook增強版LASER開源:零樣本遷移學習,支持93種語言
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Facebook開源了增強版的NLP工具包LASER
Facebook推出ReAgent AI強化學習工具包
java開源工具包-Jodd框架
CapSense用這個工具包來處理使用I2C和UART的工具箱?
AUTOSCOPE開發者工具包
微軟在GitHub開源深度學習工具包
開發工具包加速亞千兆赫項目

NVIDIA發布65個全新及更新的軟件開發工具包
NPOI WEG報表工具包簡介





 工商網監
工商網監
評論