 如何從零開始用PyTorch實現Chatbot?
如何從零開始用PyTorch實現Chatbot?
本教程會介紹使用seq2seq模型實現一個chatbot,訓練數據來自Cornell電影對話語料庫。對話系統是目前的研究熱點,它在客服、可穿戴設備和智能家居等場景有廣泛應用。
傳統的對話系統要么基于檢索的方法——提前準備一個問答庫,根據用戶的輸入尋找類似的問題和答案。這更像一個問答系統,它很難進行多輪的交互,而且答案是固定不變的。要么基于預先設置的對話流程,這主要用于slot-filling(Task-Oriented)的任務,比如查詢機票需要用戶提供日期,達到城市等信息。這種方法的缺點是比較死板,如果用戶的意圖在設計的流程之外,那么就無法處理,而且對話的流程也一般比較固定,要支持用戶隨意的話題內跳轉和話題間切換比較困難。
因此目前學術界的研究熱點是根據大量的對話數據,自動的End-to-End的使用Seq2Seq模型學習對話模型。它的好處是不需要人來設計這個對話流程,完全是數據驅動的方法。它的缺點是流程不受人(開發者)控制,在嚴肅的場景(比如客服)下使用會有比較大的風險,而且需要大量的對話數據,這在很多實際應用中是很難得到的。因此目前seq2seq模型的對話系統更多的是用于類似小冰的閑聊機器人上,最近也有不少論文研究把這種方法用于task-oriented的任務,但還不是太成熟,在業界還很少被使用。
效果
本文使用的Cornell電影對話語料庫(https://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html)就是偏向于閑聊的語料庫。
本教程的主要內容參考了PyTorch 官方教程(https://pytorch.org/tutorials/beginner/chatbot_tutorial.html)。
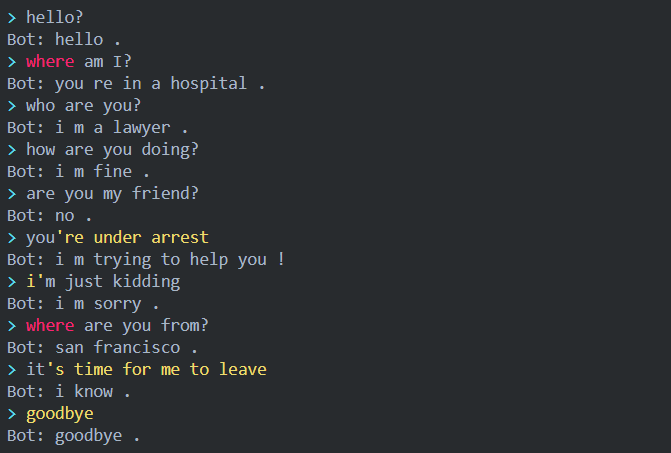
讀者可以(https://github.com/fancyerii/blog-codes)獲取完整代碼。 下面是這個教程實現的對話效果示例:
準備
首先我們通過下載鏈接(http://www.cs.cornell.edu/~cristian/data/cornell_movie_dialogs_corpus.zip)下載訓練語料庫,這是一個zip文件,把它下載后解壓到項目目錄的子目錄data下。接下來我們導入需要用到的模塊,這主要是PyTorch的模塊:
加載和預處理數據
接下來我們需要對原始數據進行變換然后用合適的數據結構加載到內存里。
Cornell電影對話語料庫(https://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html)是電影人物的對話數據,它包括:
10,292對電影人物(一部電影有多個人物,他們兩兩之間可能存在對話)的220,579個對話
617部電影的9,035個人物
總共304,713個utterance(utterance是對話中的語音片段,不一定是完整的句子)
這個數據集是比較大并且多樣的(diverse),語言形式、時代和情感都有很多樣。這樣的數據可以使得我們的chatbot對于不同的輸入更加魯棒(robust)。
首先我們來看一下原始數據長什么樣:
解壓后的目錄有很多文件,我們會用到的文件包括movie_lines.txt。上面的代碼輸出這個文件的前10行,結果如下:
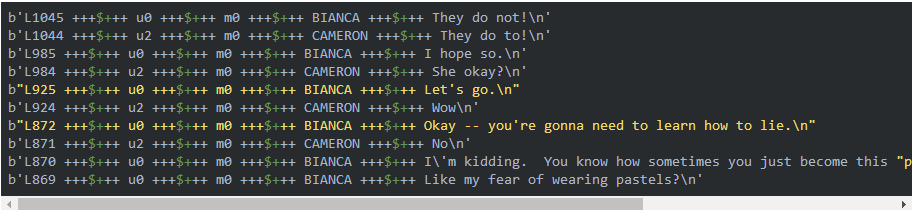
注意:上面的move_lines.txt每行都是一個utterance,但是這個文件看不出哪些utterance是組成一段對話的,這需要movie_conversations.txt文件:
每一行用”+++$+++”分割成4列,第一列表示第一個人物的ID,第二列表示第二個人物的ID,第三列表示電影的ID,第四列表示這兩個人物在這部電影中的一段對話,比如第一行的表示人物u0和u2在電影m0中的一段對話包含ID為L194、L195、L196和L197的4個utterance。注意:兩個人物在一部電影中會有多段對話,中間可能穿插其他人之間的對話,而且即使中間沒有其他人說話,這兩個人物對話的內容從語義上也可能是屬于不同的對話(話題)。所以我們看到第二行還是u0和u2在電影m0中的對話,它包含L198和L199兩個utterance,L198是緊接著L197之后的,但是它們屬于兩個對話(話題)。
數據處理
為了使用方便,我們會把原始數據處理成一個新的文件,這個新文件的每一行都是用TAB分割問題(query)和答案(response)對。為了實現這個目的,我們首先定義一些用于parsing原始文件movie_lines.txt的輔助函數。
loadLines把movie_lines.txt文件切分成 (lineID, characterID, movieID, character, text)
loadConversations把上面的行group成一個個多輪的對話
extractSentencePairs從上面的每個對話中抽取句對
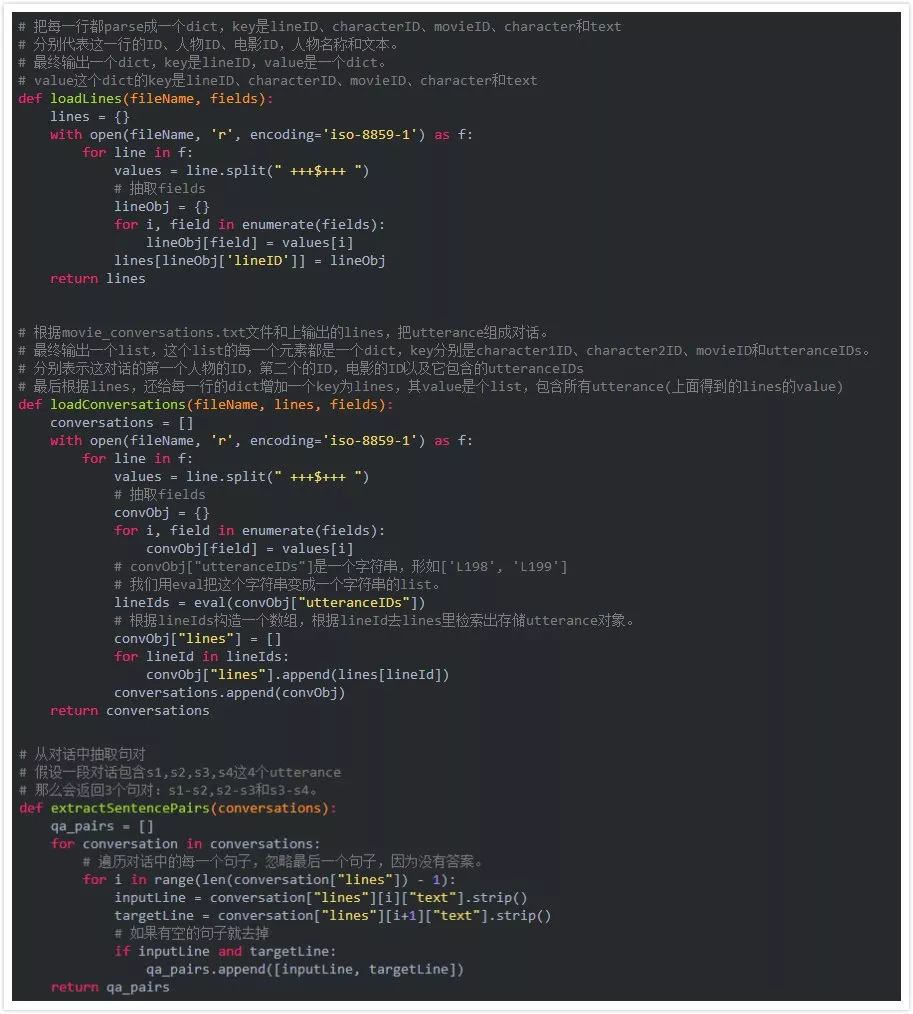
接下來我們利用上面的3個函數對原始數據進行處理,最終得到formatted_movie_lines.txt。
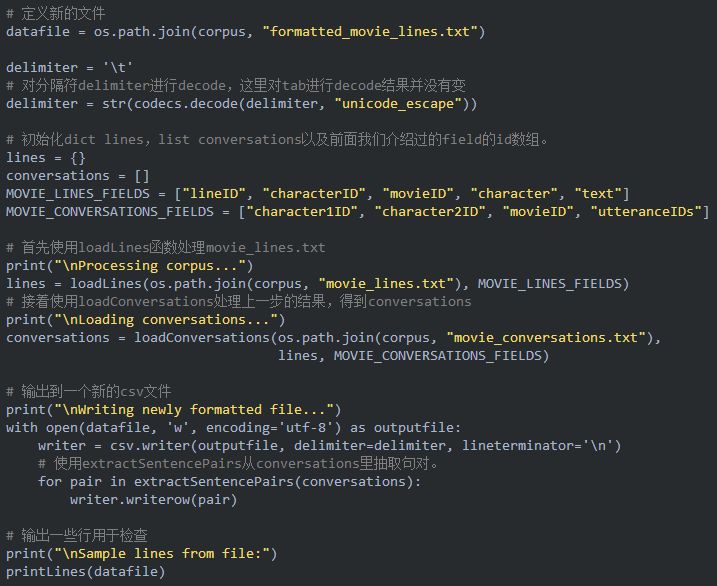
上面的代碼會生成一個新的文件formatted_movie_lines.txt,這文件每一行包含一對句對,用tab分割。下面是前十行:
b"Canwemakethisquick?RoxanneKorrineandAndrewBarrettarehavinganincrediblyhorrendouspublicbreak-uponthequad.Again.\tWell,Ithoughtwe'dstartwithpronunciation,ifthat'sokaywithyou.\n"b"Well,Ithoughtwe'dstartwithpronunciation,ifthat'sokaywithyou.\tNotthehackingandgaggingandspittingpart.Please.\n"b"Notthehackingandgaggingandspittingpart.Please.\tOkay...thenhow'boutwetryoutsomeFrenchcuisine.Saturday?Night?\n"b"You'reaskingmeout.That'ssocute.What'syournameagain?\tForgetit.\n"b"No,no,it'smyfault--wedidn'thaveaproperintroduction---\tCameron.\n"b"Cameron.\tThethingis,Cameron--I'matthemercyofaparticularlyhideousbreedofloser.Mysister.Ican'tdateuntilshedoes.\n"b"Thethingis,Cameron--I'matthemercyofaparticularlyhideousbreedofloser.Mysister.Ican'tdateuntilshedoes.\tSeemslikeshecouldgetadateeasyenough...\n"b'Why?\tUnsolvedmystery.Sheusedtobereallypopularwhenshestartedhighschool,thenitwasjustlikeshegotsickofitorsomething.\n'b"Unsolvedmystery.Sheusedtobereallypopularwhenshestartedhighschool,thenitwasjustlikeshegotsickofitorsomething.\tThat'sashame.\n"b'Gosh,ifonlywecouldfindKataboyfriend...\tLetmeseewhatIcando.\n'
創建詞典
接下來我們需要構建詞典然后把問答句對加載到內存里。
我們的輸入是一個句對,每個句子都是詞的序列,但是機器學習只能處理數值,因此我們需要建立詞到數字ID的映射。
為此,我們會定義一個Voc類,它會保存詞到ID的映射,同時也保存反向的從ID到詞的映射。除此之外,它還記錄每個詞出現的次數,以及總共出現的詞的個數。這個類提供addWord方法來增加一個詞,addSentence方法來增加句子,也提供方法trim來去除低頻的詞。
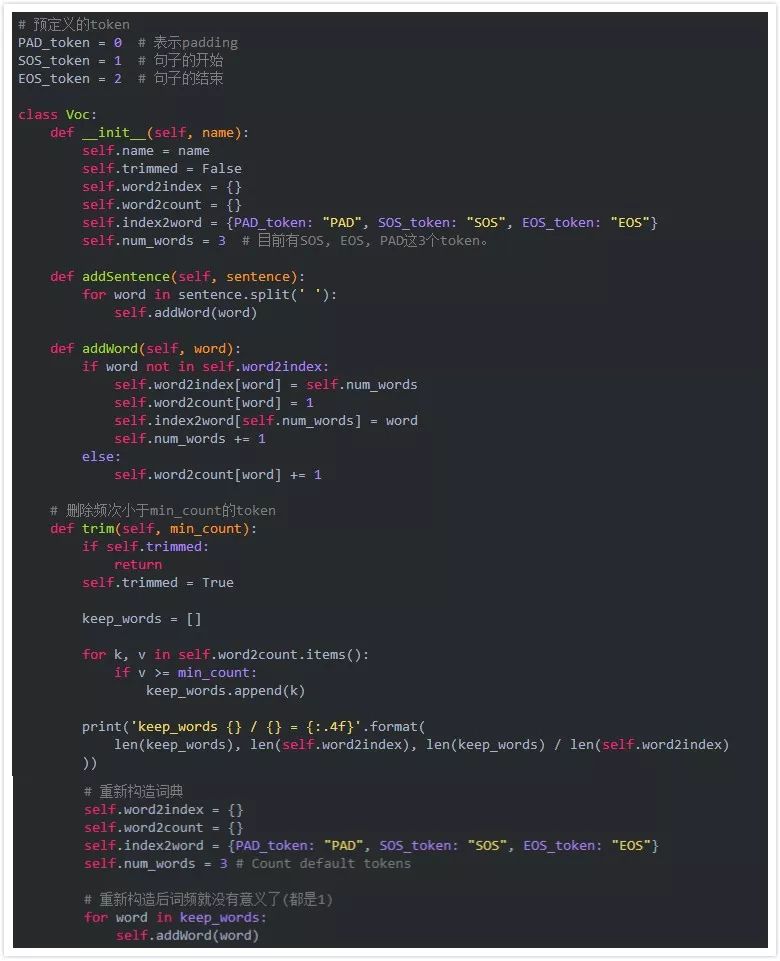
有了上面的Voc類我們就可以通過問答句對來構建詞典了。但是在構建之前我們需要進行一些預處理。
首先我們需要使用函數unicodeToAscii來把unicode字符變成ascii,比如把à變成a。注意,這里的代碼只是用于處理西方文字,如果是中文,這個函數直接會丟棄掉。接下來把所有字母變成小寫同時丟棄掉字母和常見標點(.!?)之外的所有字符。最后為了訓練收斂,我們會用函數filterPairs去掉長度超過MAX_LENGTH的句子(句對)。
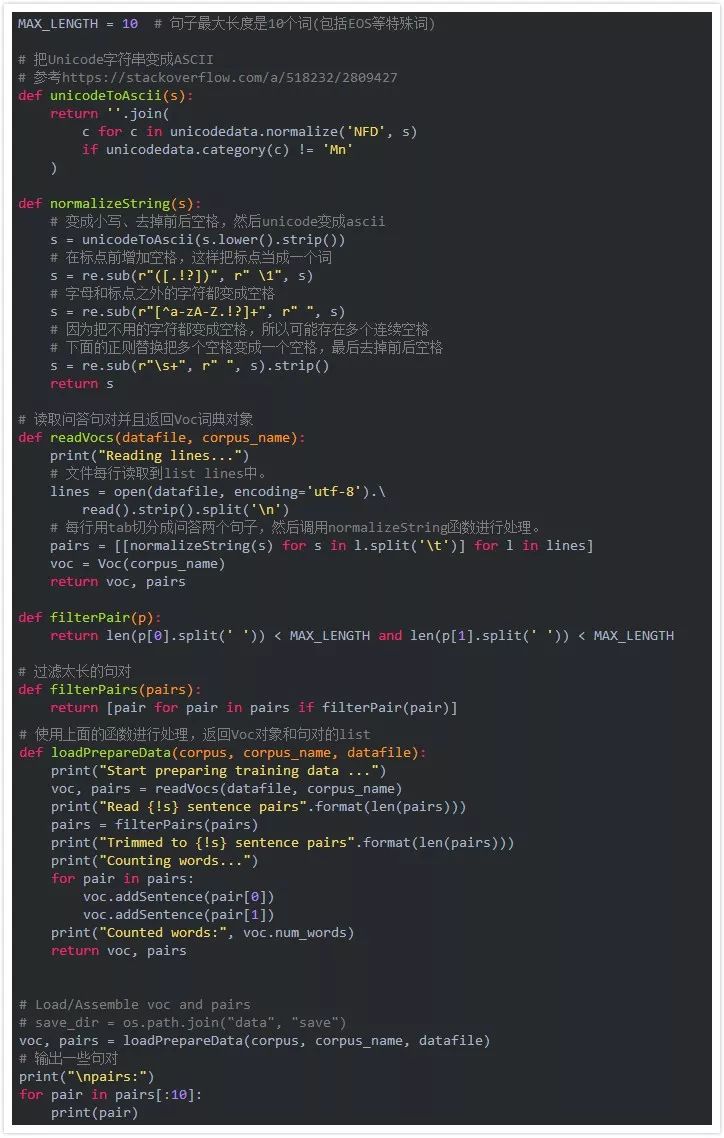
上面的代碼的輸出為:
Startpreparingtrainingdata...Readinglines...Read221282sentencepairsTrimmedto64271sentencepairsCountingwords...Countedwords:18008
我們可以看到,原理共有221282個句對,經過處理后我們值保留了64271個句對。
另外為了收斂更快,我們可以去除掉一些低頻詞。這可以分為兩步:
1) 使用voc.trim函數去掉頻次低于MIN_COUNT的詞。
2) 去掉包含低頻詞的句子(只保留這樣的句子——每一個詞都是高頻的,也就是在voc中出現的)
MIN_COUNT=3#閾值為3deftrimRareWords(voc,pairs,MIN_COUNT):#去掉voc中頻次小于3的詞voc.trim(MIN_COUNT)#保留的句對keep_pairs=[]forpairinpairs:input_sentence=pair[0]output_sentence=pair[1]keep_input=Truekeep_output=True#檢查問題forwordininput_sentence.split(''):ifwordnotinvoc.word2index:keep_input=Falsebreak#檢查答案forwordinoutput_sentence.split(''):ifwordnotinvoc.word2index:keep_output=Falsebreak#如果問題和答案都只包含高頻詞,我們才保留這個句對ifkeep_inputandkeep_output:keep_pairs.append(pair)print("Trimmedfrom{}pairsto{},{:.4f}oftotal".format(len(pairs),len(keep_pairs),len(keep_pairs)/len(pairs)))returnkeep_pairs#實際進行處理pairs=trimRareWords(voc,pairs,MIN_COUNT)
代碼的輸出為:
keep_words7823/18005=0.4345Trimmedfrom64271pairsto53165,0.8272oftotal
18005個詞之中,頻次大于等于3的只有43%,去掉低頻的57%的詞之后,保留的句子為53165,占比為82%。
為模型準備數據
前面我們構建了詞典,并且對訓練數據進行預處理并且濾掉一些句對,但是模型最終用到的是Tensor。最簡單的辦法是一次處理一個句對,那么上面得到的句對直接就可以使用。但是為了加快訓練速度,尤其是重復利用GPU的并行能力,我們需要一次處理一個batch的數據。
對于某些問題,比如圖像來說,輸入可能是固定大小的(或者通過預處理縮放成固定大小),但是對于文本來說,我們很難把一個二十個詞的句子”縮放”成十個詞同時還保持語義不變。但是為了充分利用GPU等計算自由,我們又必須變成固定大小的Tensor,因此我們通常會使用Padding的技巧,把短的句子補充上零使得輸入大小是(batch, max_length),這樣通過一次就能實現一個batch數據的forward或者backward計算。當然padding的部分的結果是沒有意義的,比如某個句子實際長度是5,而max_length是10,那么最終forward的輸出應該是第5個時刻的輸出,后面5個時刻計算是無用功。方向計算梯度的時候也是類似的,我們需要從第5個時刻開始反向計算梯度。為了提高效率,我們通常把長度接近的訓練數據放到一個batch里面,這樣無用的計算是最少的。因此我們通常把全部訓練數據根據長度劃分成一些組,比如長度小于4的一組,長度4到8的一組,長度8到12的一組,…。然后每次隨機的選擇一個組,再隨機的從一組里選擇batch個數據。不過本教程并沒有這么做,而是每次隨機的從所有pair里隨機選擇batch個數據。
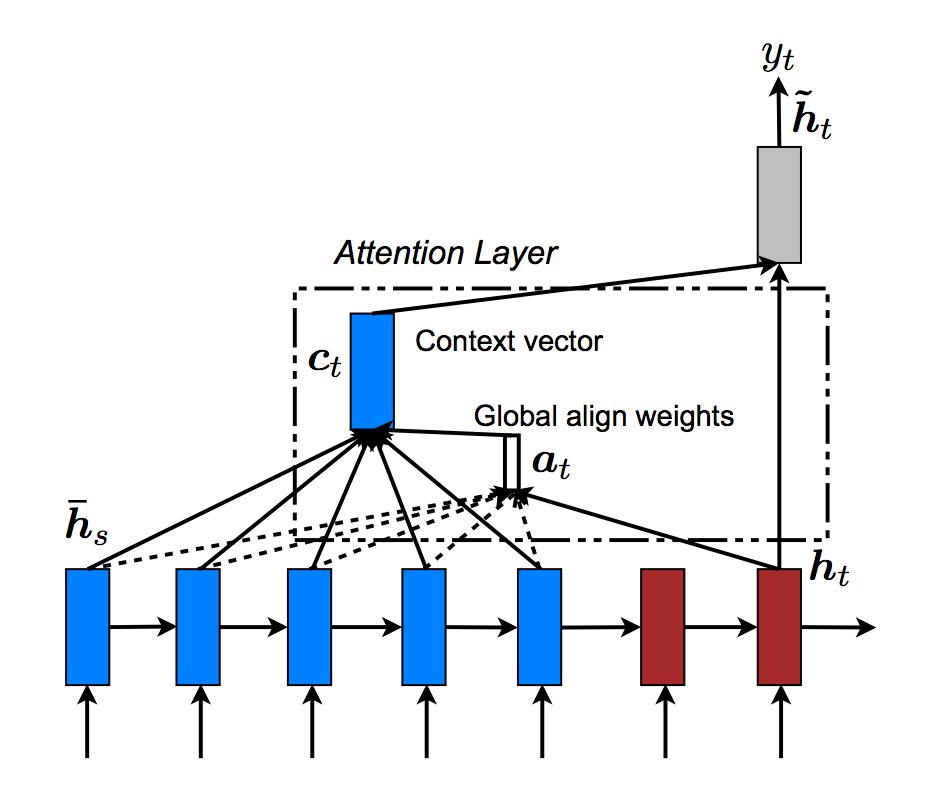
原始的輸入通常是batch個list,表示batch個句子,因此自然的表示方法為(batch, max_length),這種表示方法第一維是batch,每移動一個下標得到的是一個樣本的max_length個詞(包括padding)。因為RNN的依賴關系,我們在計算t+1時刻必須知道t時刻的結果,因此我們無法用多個核同時計算一個樣本的forward。但是不同樣本之間是沒有依賴關系的,因此我們可以在根據t時刻batch樣本的當前狀態計算batch個樣本的輸出和新狀態,然后再計算t+2時刻,…。為了便于GPU一次取出t時刻的batch個數據,我們通常把輸入從(batch, max_length)變成(max_length, batch),這樣使得t時刻的batch個數據在內存(顯存)中是連續的,從而讀取效率更高。這個過程如下圖所示,原始輸入的大小是(batch=6, max_length=4),轉置之后變成(4,6)。這樣某個時刻的6個樣本數據在內存中是連續的。
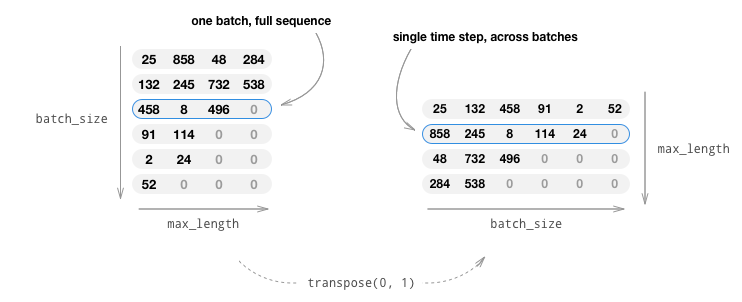
因此我們會用一些工具函數來實現上述處理。
inputVar函數把batch個句子padding后變成一個LongTensor,大小是(max_length, batch),同時會返回一個大小是batch的list lengths,說明每個句子的實際長度,這個參數后面會傳給PyTorch,從而在forward和backward計算的時候使用實際的長度。
outputVar函數和inputVar類似,但是它輸出的第二個參數不是lengths,而是一個大小為(max_length, batch)的mask矩陣(tensor),某位是0表示這個位置是padding,1表示不是padding,這樣做的目的是后面計算方便。當然這兩種表示是等價的,只不過lengths表示更加緊湊,但是計算起來不同方便,而mask矩陣和outputVar直接相乘就可以把padding的位置給mask(變成0)掉,這在計算loss時會非常方便。
batch2TrainData則利用上面的兩個函數把一個batch的句對處理成合適的輸入和輸出Tensor。
#把句子的詞變成IDdefindexesFromSentence(voc,sentence):return[voc.word2index[word]forwordinsentence.split('')]+[EOS_token]#l是多個長度不同句子(list),使用zip_longestpadding成定長,長度為最長句子的長度。defzeroPadding(l,fillvalue=PAD_token):returnlist(itertools.zip_longest(*l,fillvalue=fillvalue))#l是二維的padding后的list#返回m和l的大小一樣,如果某個位置是padding,那么值為0,否則為1defbinaryMatrix(l,value=PAD_token):m=[]fori,seqinenumerate(l):m.append([])fortokeninseq:iftoken==PAD_token:m[i].append(0)else:m[i].append(1)returnm#把輸入句子變成ID,然后再padding,同時返回lengths這個list,標識實際長度。#返回的padVar是一個LongTensor,shape是(batch,max_length),#lengths是一個list,長度為(batch,),表示每個句子的實際長度。definputVar(l,voc):indexes_batch=[indexesFromSentence(voc,sentence)forsentenceinl]lengths=torch.tensor([len(indexes)forindexesinindexes_batch])padList=zeroPadding(indexes_batch)padVar=torch.LongTensor(padList)returnpadVar,lengths#對輸出句子進行padding,然后用binaryMatrix得到每個位置是padding(0)還是非padding,#同時返回最大最長句子的長度(也就是padding后的長度)#返回值padVar是LongTensor,shape是(batch,max_target_length)#mask是ByteTensor,shape也是(batch,max_target_length)defoutputVar(l,voc):indexes_batch=[indexesFromSentence(voc,sentence)forsentenceinl]max_target_len=max([len(indexes)forindexesinindexes_batch])padList=zeroPadding(indexes_batch)mask=binaryMatrix(padList)mask=torch.ByteTensor(mask)padVar=torch.LongTensor(padList)returnpadVar,mask,max_target_len#處理一個batch的pair句對defbatch2TrainData(voc,pair_batch):#按照句子的長度(詞數)排序pair_batch.sort(key=lambdax:len(x[0].split("")),reverse=True)input_batch,output_batch=[],[]forpairinpair_batch:input_batch.append(pair[0])output_batch.append(pair[1])inp,lengths=inputVar(input_batch,voc)output,mask,max_target_len=outputVar(output_batch,voc)returninp,lengths,output,mask,max_target_len#示例small_batch_size=5batches=batch2TrainData(voc,[random.choice(pairs)for_inrange(small_batch_size)])input_variable,lengths,target_variable,mask,max_target_len=batchesprint("input_variable:",input_variable)print("lengths:",lengths)print("target_variable:",target_variable)print("mask:",mask)print("max_target_len:",max_target_len)
示例的輸出為:
input_variable:tensor([[92,101,76,50,34],[7,250,37,6,4],[123,279,628,2,2],[40,75,4,0,0],[359,53,7216,0,0],[2763,217,4,0,0],[637,4,2,0,0],[6,2,0,0,0],[2,0,0,0,0]])lengths:tensor([9,8,7,3,3])target_variable:tensor([[25,34,404,7,25],[283,4,76,24,1464],[25,2,37,4,70],[72,0,7217,2,1465],[829,0,4,0,6],[234,0,2,0,2],[4,0,0,0,0],[2,0,0,0,0]])mask:tensor([[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,0,1,1,1],[1,0,1,0,1],[1,0,1,0,1],[1,0,0,0,0],[1,0,0,0,0]],dtype=torch.uint8)max_target_len:8
我們可以看到input_variable的每一列表示一個樣本,而每一行表示batch(5)個樣本在這個時刻的值。而lengths表示真實的長度。類似的target_variable也是每一列表示一個樣本,而mask的shape和target_variable一樣,如果某個位置是0,則表示padding。
定義模型
Seq2Seq 模型
我們這個chatbot的核心是一個sequence-to-sequence(seq2seq)模型。 seq2seq模型的輸入是一個變長的序列,而輸出也是一個變長的序列。而且這兩個序列的長度并不相同。一般我們使用RNN來處理變長的序列,Sutskever等人的論文發現通過使用兩個RNN可以解決這類問題。這類問題的輸入和輸出都是變長的而且長度不一樣,包括問答系統、機器翻譯、自動摘要等等都可以使用seq2seq模型來解決。
其中一個RNN叫做Encoder,它把變長的輸入序列編碼成一個固定長度的context向量,我們一般可以認為這個向量包含了輸入句子的語義。而第二個RNN叫做Decoder,初始隱狀態是Encoder的輸出context向量,輸入是(表示句子開始的特殊Token),然后用RNN計算第一個時刻的輸出,接著用第一個時刻的輸出和隱狀態計算第二個時刻的輸出和新的隱狀態,...,直到某個時刻輸出特殊的(表示句子結束的特殊Token)或者長度超過一個閾值。Seq2Seq模型如下圖所示。
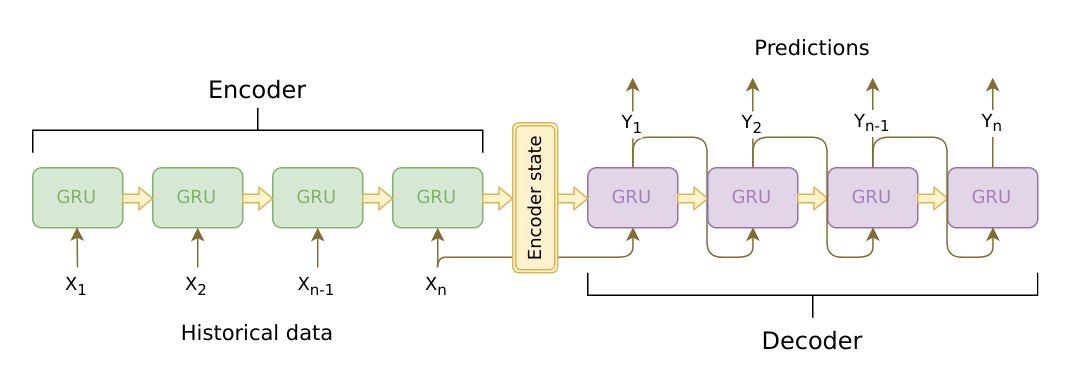
Encoder
Encoder是個RNN,它會遍歷輸入的每一個Token(詞),每個時刻的輸入是上一個時刻的隱狀態和輸入,然后會有一個輸出和新的隱狀態。這個新的隱狀態會作為下一個時刻的輸入隱狀態。每個時刻都有一個輸出,對于seq2seq模型來說,我們通常只保留最后一個時刻的隱狀態,認為它編碼了整個句子的語義,但是后面我們會用到Attention機制,它還會用到Encoder每個時刻的輸出。Encoder處理結束后會把最后一個時刻的隱狀態作為Decoder的初始隱狀態。
實際我們通常使用多層的Gated Recurrent Unit(GRU)或者LSTM來作為Encoder,這里使用GRU,讀者可以參考Cho等人2014年的[論文]。
此外我們會使用雙向的RNN,如下圖所示。
注意在接入RNN之前會有一個embedding層,用來把每一個詞(ID或者one-hot向量)映射成一個連續的稠密的向量,我們可以認為這個向量編碼了一個詞的語義。在我們的模型里,我們把它的大小定義成和RNN的隱狀態大小一樣(但是并不是一定要一樣)。有了Embedding之后,模型會把相似的詞編碼成相似的向量(距離比較近)。
最后,為了把padding的batch數據傳給RNN,我們需要使用下面的兩個函數來進行pack和unpack,后面我們會詳細介紹它們。這兩個函數是:
torch.nn.utils.rnn.pack_padded_sequence
torch.nn.utils.rnn.pad_packed_sequence
計算圖:
1) 把詞的ID通過Embedding層變成向量。
2) 把padding后的數據進行pack。
3) 傳入GRU進行Forward計算。
4) Unpack計算結果
5) 把雙向GRU的結果向量加起來。
6) 返回(所有時刻的)輸出和最后時刻的隱狀態。
輸入:
input_seq: 一個batch的輸入句子,shape是(max_length, batch_size)
input_lengths: 一個長度為batch的list,表示句子的實際長度。
hidden: 初始化隱狀態(通常是零),shape是(n_layers x num_directions, batch_size, hidden_size)
輸出:
outputs: 最后一層GRU的輸出向量(雙向的向量加在了一起),shape(max_length, batch_size, hidden_size)
hidden: 最后一個時刻的隱狀態,shape是(n_layers x num_directions, batch_size, hidden_size)
EncoderRNN代碼如下,請讀者詳細閱讀注釋。
classEncoderRNN(nn.Module):def__init__(self,hidden_size,embedding,n_layers=1,dropout=0):super(EncoderRNN,self).__init__()self.n_layers=n_layersself.hidden_size=hidden_sizeself.embedding=embedding#初始化GRU,這里輸入和hidden大小都是hidden_size,因為我們這里假設embedding層的輸出大小是hidden_size#如果只有一層,那么不進行Dropout,否則使用傳入的參數dropout進行GRU的Dropout。self.gru=nn.GRU(hidden_size,hidden_size,n_layers,dropout=(0ifn_layers==1elsedropout),bidirectional=True)defforward(self,input_seq,input_lengths,hidden=None):#輸入是(max_length,batch),Embedding之后變成(max_length,batch,hidden_size)embedded=self.embedding(input_seq)#PackpaddedbatchofsequencesforRNNmodule#因為RNN(GRU)需要知道實際的長度,所以PyTorch提供了一個函數pack_padded_sequence把輸入向量和長度pack#到一個對象PackedSequence里,這樣便于使用。packed=torch.nn.utils.rnn.pack_padded_sequence(embedded,input_lengths)#通過GRU進行forward計算,需要傳入輸入和隱變量#如果傳入的輸入是一個Tensor(max_length,batch,hidden_size)#那么輸出outputs是(max_length,batch,hidden_size*num_directions)。#第三維是hidden_size和num_directions的混合,它們實際排列順序是num_directions在前面,因此我們可以#使用outputs.view(seq_len,batch,num_directions,hidden_size)得到4維的向量。#其中第三維是方向,第四位是隱狀態。#而如果輸入是PackedSequence對象,那么輸出outputs也是一個PackedSequence對象,我們需要用#函數pad_packed_sequence把它變成一個shape為(max_length,batch,hidden*num_directions)的向量以及#一個list,表示輸出的長度,當然這個list和輸入的input_lengths完全一樣,因此通常我們不需要它。outputs,hidden=self.gru(packed,hidden)#參考前面的注釋,我們得到outputs為(max_length,batch,hidden*num_directions)outputs,_=torch.nn.utils.rnn.pad_packed_sequence(outputs)#我們需要把輸出的num_directions雙向的向量加起來#因為outputs的第三維是先放前向的hidden_size個結果,然后再放后向的hidden_size個結果#所以outputs[:,:,:self.hidden_size]得到前向的結果#outputs[:,:,self.hidden_size:]是后向的結果#注意,如果bidirectional是False,則outputs第三維的大小就是hidden_size,#這時outputs[:,:,self.hidden_size:]是不存在的,因此也不會加上去。#對Pythonslicing不熟的讀者可以看看下面的例子:#>>>a=[1,2,3]#>>>a[:3]#[1,2,3]#>>>a[3:]#[]#>>>a[:3]+a[3:]#[1,2,3]#這樣就不用寫下面的代碼了:#ifbidirectional:#outputs=outputs[:,:,:self.hidden_size]+outputs[:,:,self.hidden_size:]outputs=outputs[:,:,:self.hidden_size]+outputs[:,:,self.hidden_size:]#返回最終的輸出和最后時刻的隱狀態。returnoutputs,hidden
Decoder
Decoder也是一個RNN,它每個時刻輸出一個詞。每個時刻的輸入是上一個時刻的隱狀態和上一個時刻的輸出。一開始的隱狀態是Encoder最后時刻的隱狀態,輸入是特殊的。然后使用RNN計算新的隱狀態和輸出第一個詞,接著用新的隱狀態和第一個詞計算第二個詞,...,直到遇到,結束輸出。普通的RNN Decoder的問題是它只依賴與Encoder最后一個時刻的隱狀態,雖然理論上這個隱狀態(context向量)可以編碼輸入句子的語義,但是實際會比較困難。因此當輸入句子很長的時候,效果會很長。
為了解決這個問題,Bahdanau等人在論文里提出了注意力機制(attention mechanism),在Decoder進行t時刻計算的時候,除了t-1時刻的隱狀態,當前時刻的輸入,注意力機制還可以參考Encoder所有時刻的輸入。拿機器翻譯來說,我們在翻譯以句子的第t個詞的時候會把注意力機制在某個詞上。
當然常見的注意力是一種soft的注意力,假設輸入有5個詞,注意力可能是一個概率,比如(0.6,0.1,0.1,0.1,0.1),表示當前最關注的是輸入的第一個詞。同時我們之前也計算出每個時刻的輸出向量,假設5個時刻分別是$y_1,…,y_5$,那么我們可以用attention概率加權得到當前時刻的context向量$0.6y_1+0.1y_2+…+0.1y_5$。
注意力有很多方法計算,我們這里介紹Luong等人在論文提出的方法。它是用當前時刻的GRU計算出的新的隱狀態來計算注意力得分,首先它用一個score函數計算這個隱狀態和Encoder的輸出的相似度得分,得分越大,說明越應該注意這個詞。然后再用softmax函數把score變成概率。那機器翻譯為例,在t時刻,$h_t$表示t時刻的GRU輸出的新的隱狀態,我們可以認為$h_t$表示當前需要翻譯的語義。通過計算$h_t$與$y_1,…,y_n$的得分,如果$h_t$與$y_1$的得分很高,那么我們可以認為當前主要翻譯詞$x_1$的語義。有很多中score函數的計算方法,如下圖所示:
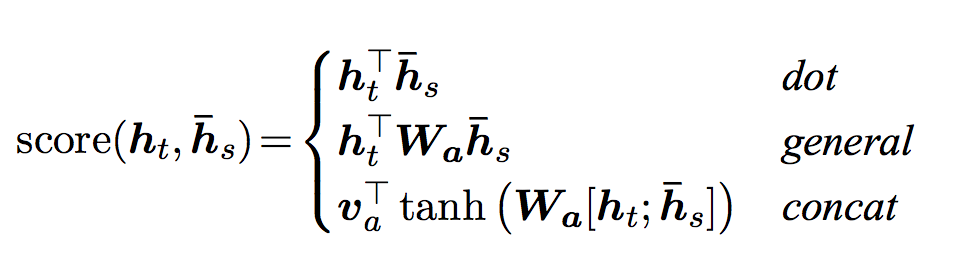
上式中$h_t$表示t時刻的隱狀態,比如第一種計算score的方法,直接計算$h_t$與$h_s$的內積,內積越大,說明這兩個向量越相似,因此注意力也更多的放到這個詞上。第二種方法也類似,只是引入了一個可以學習的矩陣,我們可以認為它先對$h_t$做一個線性變換,然后在與$h_s$計算內積。而第三種方法把它們拼接起來然后用一個全連接網絡來計算score。
注意,我們前面介紹的是分別計算$h_t$和$y_1$的內積、$h_t$和$y_2$的內積,…。但是為了效率,可以一次計算$h_t$與$h_s=[y_1,y_2,…,y_n]$的乘積。 計算過程如下圖所示。
#Luong注意力layerclassAttn(torch.nn.Module):def__init__(self,method,hidden_size):super(Attn,self).__init__()self.method=methodifself.methodnotin['dot','general','concat']:raiseValueError(self.method,"isnotanappropriateattentionmethod.")self.hidden_size=hidden_sizeifself.method=='general':self.attn=torch.nn.Linear(self.hidden_size,hidden_size)elifself.method=='concat':self.attn=torch.nn.Linear(self.hidden_size*2,hidden_size)self.v=torch.nn.Parameter(torch.FloatTensor(hidden_size))defdot_score(self,hidden,encoder_output):#輸入hidden的shape是(1,batch=64,hidden_size=500)#encoder_outputs的shape是(input_lengths=10,batch=64,hidden_size=500)#hidden*encoder_output得到的shape是(10,64,500),然后對第3維求和就可以計算出score。returntorch.sum(hidden*encoder_output,dim=2)defgeneral_score(self,hidden,encoder_output):energy=self.attn(encoder_output)returntorch.sum(hidden*energy,dim=2)defconcat_score(self,hidden,encoder_output):energy=self.attn(torch.cat((hidden.expand(encoder_output.size(0),-1,-1),encoder_output),2)).tanh()returntorch.sum(self.v*energy,dim=2)#輸入是上一個時刻的隱狀態hidden和所有時刻的Encoder的輸出encoder_outputs#輸出是注意力的概率,也就是長度為input_lengths的向量,它的和加起來是1。defforward(self,hidden,encoder_outputs):#計算注意力的score,輸入hidden的shape是(1,batch=64,hidden_size=500),表示t時刻batch數據的隱狀態#encoder_outputs的shape是(input_lengths=10,batch=64,hidden_size=500)ifself.method=='general':attn_energies=self.general_score(hidden,encoder_outputs)elifself.method=='concat':attn_energies=self.concat_score(hidden,encoder_outputs)elifself.method=='dot':#計算內積,參考dot_score函數attn_energies=self.dot_score(hidden,encoder_outputs)#Transposemax_lengthandbatch_sizedimensions#把attn_energies從(max_length=10,batch=64)轉置成(64,10)attn_energies=attn_energies.t()#使用softmax函數把score變成概率,shape仍然是(64,10),然后用unsqueeze(1)變成#(64,1,10)returnF.softmax(attn_energies,dim=1).unsqueeze(1)
上面的代碼實現了dot、general和concat三種score計算方法,分別和前面的三個公式對應,我們這里介紹最簡單的dot方法。代碼里也有一些注釋,只有dot_score函數比較難以理解,我們來分析一下。首先這個函數的輸入輸入hidden的shape是(1, batch=64, hidden_size=500),encoder_outputs的shape是(input_lengths=10, batch=64, hidden_size=500)。
怎么計算hidden和10個encoder輸出向量的內積呢?為了簡便,我們先假設batch是1,這樣可以把第二維(batch維)去掉,因此hidden是(1, 500),而encoder_outputs是(10, 500)。內積的定義是兩個向量對應位相乘然后相加,但是encoder_outputs是10個500維的向量。當然我們可以寫一個for循環來計算,但是效率很低。這里用到一個小的技巧,利用broadcasting,hidden * encoder_outputs可以理解為把hidden從(1,500)復制成(10, 500)(當然實際實現并不會這么做),然后兩個(10, 500)的矩陣進行乘法。注意,這里的乘法不是矩陣乘法,而是所謂的Hadamard乘法,其實就是把對應位置的乘起來,比如下面的例子:
因此hidden * encoder_outputs就可以把hidden向量(500個數)與encoder_outputs的10個向量(500個數)對應的位置相乘。而內積還需要把這500個乘積加起來,因此后面使用torch.sum(hidden * encoder_output, dim=2),把第2維500個乘積加起來,最終得到10個score值。當然我們實際還有一個batch維度,因此最終得到的attn_energies是(10, 64)。接著在forward函數里把attn_energies轉置成(64, 10),然后使用softmax函數把10個score變成概率,shape仍然是(64, 10),為了后面使用方便,我們用unsqueeze(1)把它變成(64, 1, 10)。
有了注意力的子模塊之后,我們就可以實現Decoder了。Encoder可以一次把一個序列輸入GRU,得到整個序列的輸出。但是Decoder t時刻的輸入是t-1時刻的輸出,在t-1時刻計算完成之前是未知的,因此只能一次處理一個時刻的數據。因此Encoder的GRU的輸入是(max_length, batch, hidden_size),而Decoder的輸入是(1, batch, hidden_size)。此外Decoder只能利用前面的信息,所以只能使用單向(而不是雙向)的GRU,而Encoder的GRU是雙向的,如果兩種的hidden_size是一樣的,則Decoder的隱單元個數少了一半,那怎么把Encoder的最后時刻的隱狀態作為Decoder的初始隱狀態呢?這里是把每個時刻雙向結果加起來的,因此它們的大小就能匹配了(請讀者參考前面Encoder雙向相加的部分代碼)。
計算圖:
1) 把詞ID輸入Embedding層
2) 使用單向的GRU繼續Forward進行一個時刻的計算。
3) 使用新的隱狀態計算注意力權重
4) 用注意力權重得到context向量
5) context向量和GRU的輸出拼接起來,然后再進過一個全連接網絡,使得輸出大小仍然是hidden_size
6) 使用一個投影矩陣把輸出從hidden_size變成詞典大小,然后用softmax變成概率 7) 返回輸出和新的隱狀態
輸入:
input_step: shape是(1, batch_size)
last_hidden: 上一個時刻的隱狀態, shape是(n_layers x num_directions, batch_size, hidden_size)
encoder_outputs: encoder的輸出, shape是(max_length, batch_size, hidden_size)
輸出:
output: 當前時刻輸出每個詞的概率,shape是(batch_size, voc.num_words)
hidden: 新的隱狀態,shape是(n_layers x num_directions, batch_size, hidden_size)
classLuongAttnDecoderRNN(nn.Module):def__init__(self,attn_model,embedding,hidden_size,output_size,n_layers=1,dropout=0.1):super(LuongAttnDecoderRNN,self).__init__()#保存到self里,attn_model就是前面定義的Attn類的對象。self.attn_model=attn_modelself.hidden_size=hidden_sizeself.output_size=output_sizeself.n_layers=n_layersself.dropout=dropout#定義Decoder的layersself.embedding=embeddingself.embedding_dropout=nn.Dropout(dropout)self.gru=nn.GRU(hidden_size,hidden_size,n_layers,dropout=(0ifn_layers==1elsedropout))self.concat=nn.Linear(hidden_size*2,hidden_size)self.out=nn.Linear(hidden_size,output_size)self.attn=Attn(attn_model,hidden_size)defforward(self,input_step,last_hidden,encoder_outputs):#注意:decoder每一步只能處理一個時刻的數據,因為t時刻計算完了才能計算t+1時刻。#input_step的shape是(1,64),64是batch,1是當前輸入的詞ID(來自上一個時刻的輸出)#通過embedding層變成(1,64,500),然后進行dropout,shape不變。embedded=self.embedding(input_step)embedded=self.embedding_dropout(embedded)#把embedded傳入GRU進行forward計算#得到rnn_output的shape是(1,64,500)#hidden是(2,64,500),因為是雙向的GRU,所以第一維是2。rnn_output,hidden=self.gru(embedded,last_hidden)#計算注意力權重,根據前面的分析,attn_weights的shape是(64,1,10)attn_weights=self.attn(rnn_output,encoder_outputs)#encoder_outputs是(10,64,500)#encoder_outputs.transpose(0,1)后的shape是(64,10,500)#attn_weights.bmm后是(64,1,500)#bmm是批量的矩陣乘法,第一維是batch,我們可以把attn_weights看成64個(1,10)的矩陣#把encoder_outputs.transpose(0,1)看成64個(10,500)的矩陣#那么bmm就是64個(1,10)矩陣x(10,500)矩陣,最終得到(64,1,500)context=attn_weights.bmm(encoder_outputs.transpose(0,1))#把context向量和GRU的輸出拼接起來#rnn_output從(1,64,500)變成(64,500)rnn_output=rnn_output.squeeze(0)#context從(64,1,500)變成(64,500)context=context.squeeze(1)#拼接得到(64,1000)concat_input=torch.cat((rnn_output,context),1)#self.concat是一個矩陣(1000,500),#self.concat(concat_input)的輸出是(64,500)#然后用tanh把輸出返回變成(-1,1),concat_output的shape是(64,500)concat_output=torch.tanh(self.concat(concat_input))#out是(500,詞典大小=7826)output=self.out(concat_output)#用softmax變成概率,表示當前時刻輸出每個詞的概率。output=F.softmax(output,dim=1)#返回output和新的隱狀態returnoutput,hidden
定義訓練過程
Masked損失
forward實現之后,我們就需要計算loss。seq2seq有兩個RNN,Encoder RNN是沒有直接定義損失函數的,它是通過影響Decoder從而影響最終的輸出以及loss。Decoder輸出一個序列,前面我們介紹的是Decoder在預測時的過程,它的長度是不固定的,只有遇到EOS才結束。給定一個問答句對,我們可以把問題輸入Encoder,然后用Decoder得到一個輸出序列,但是這個輸出序列和”真實”的答案長度并不相同。
而且即使長度相同并且語義相似,也很難直接知道預測的答案和真實的答案是否類似。那么我們怎么計算loss呢?比如輸入是”What is your name?”,訓練數據中的答案是”I am LiLi”。假設模型有兩種預測:”I am fine”和”My name is LiLi”。從語義上顯然第二種答案更好,但是如果字面上比較的話可能第一種更好。
但是讓機器知道”I am LiLi”和”My name is LiLi”的語義很接近這是非常困難的,所以實際上我們通常還是通過字面上里進行比較。我們會限制Decoder的輸出,使得Decoder的輸出長度和”真實”答案一樣,然后逐個時刻比較。Decoder輸出的是每個詞的概率分布,因此可以使用交叉熵損失函數。但是這里還有一個問題,因為是一個batch的數據里有一些是padding的,因此這些位置的預測是沒有必要計算loss的,因此我們需要使用前面的mask矩陣把對應位置的loss去掉,我們可以通過下面的函數來實現計算Masked的loss。
defmaskNLLLoss(inp,target,mask):#計算實際的詞的個數,因為padding是0,非padding是1,因此sum就可以得到詞的個數nTotal=mask.sum()crossEntropy=-torch.log(torch.gather(inp,1,target.view(-1,1)).squeeze(1))loss=crossEntropy.masked_select(mask).mean()loss=loss.to(device)returnloss,nTotal.item()
上面的代碼有幾個需要注意的地方。首先是masked_select函數,我們來看一個例子:
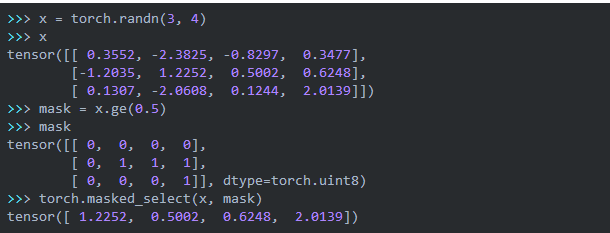
它要求mask和被mask的tensor的shape是一樣的,然后從crossEntropy選出mask值為1的那些值。輸出的維度會減1。
另外為了實現交叉熵這里使用了gather函數,這是一種比較底層的實現方法,更簡便的方法應該使用CrossEntropyLoss或者NLLLoss,其中CrossEntropy等價與LogSoftmax+NLLLoss。
交叉熵的定義為:$H(p,q)=-\sum_xp(x)logq(x)$。其中p和q是兩個隨機變量的概率分布,這里是離散的隨機變量,如果是連續的需要把求和變成積分。在我們這里p是真實的分布,也就是one-hot的,而q是模型預測的softmax的輸出。因為p是one-hot的,所以只需要計算真實分類對應的那個值。
比如假設一個5分類的問題,當前正確分類是2(下標從0-4),而模型的預測是(0.1,0.1,0.4,0.2,0.2),則H=-log(0.4)。用交叉熵作為分類的Loss是比較合理的,正確的分類是2,那么模型在下標為2的地方預測的概率$q_2$越大,則$-logq_2$越小,也就是loss越小。
假設inp是:
0.30.20.40.10.20.10.40.3
也就是batch=2,而分類數(詞典大小)是4,inp是模型預測的分類概率。 而target = [2,3] ,表示第一個樣本的正確分類是第三個類別(概率是0.4),第二個樣本的正確分類是第四個類別(概率是0.3)。因此我們需要計算的是 -log(0.4) - log(0.3)。怎么不用for循環求出來呢?我們可以使用torch.gather函數首先把0.4和0.3選出來:
inp=torch.tensor([[0.3,0.2,0.4,0.1],[0.2,0.1,0.4,0.3]])target=torch.tensor([2,3])selected=torch.gather(inp,1,target.view(-1,1))print(selected)輸出:tensor([[0.4000],[0.3000]])
一次迭代的訓練過程
函數train實現一個batch數據的訓練。前面我們提到過,在訓練的時候我們會限制Decoder的輸出,使得Decoder的輸出長度和”真實”答案一樣長。但是我們在訓練的時候如果讓Decoder自行輸出,那么收斂可能會比較慢,因為Decoder在t時刻的輸入來自t-1時刻的輸出。如果前面預測錯了,那么后面很可能都會錯下去。另外一種方法叫做teacher forcing,它不管模型在t-1時刻做什么預測都把t-1時刻的正確答案作為t時刻的輸入。但是如果只用teacher forcing也有問題,因為在真實的Decoder的是是沒有老師來幫它糾正錯誤的。所以比較好的方法是更加一個teacher_forcing_ratio參數隨機的來確定本次訓練是否teacher forcing。
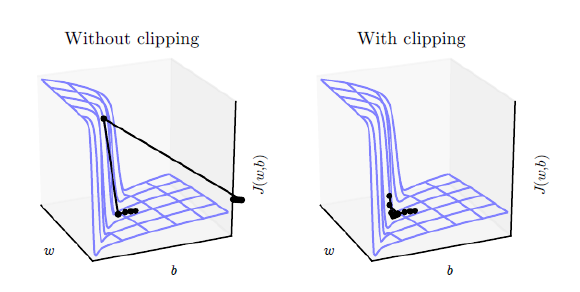
另外使用到的一個技巧是梯度裁剪(gradient clipping)。這個技巧通常是為了防止梯度爆炸(exploding gradient),它把參數限制在一個范圍之內,從而可以避免梯度的梯度過大或者出現NaN等問題。注意:雖然它的名字叫梯度裁剪,但實際它是對模型的參數進行裁剪,它把整個參數看成一個向量,如果這個向量的模大于max_norm,那么就把這個向量除以一個值使得模等于max_norm,因此也等價于把這個向量投影到半徑為max_norm的球上。它的效果如下圖所示。
操作步驟:
1) 把整個batch的輸入傳入encoder
2) 把decoder的輸入設置為特殊的,初始隱狀態設置為encoder最后時刻的隱狀態
3) decoder每次處理一個時刻的forward計算
4) 如果是teacher forcing,把上個時刻的"正確的"詞作為當前輸入,否則用上一個時刻的輸出作為當前時刻的輸入
5) 計算loss
6) 反向計算梯度
7) 對梯度進行裁剪
8) 更新模型(包括encoder和decoder)參數。
注意,PyTorch的RNN模塊(RNN,LSTM,GRU)也可以當成普通的非循環的網絡來使用。在Encoder部分,我們是直接把所有時刻的數據都傳入RNN,讓它一次計算出所有的結果,但是在Decoder的時候(非teacher forcing)后一個時刻的輸入來自前一個時刻的輸出,因此無法一次計算。
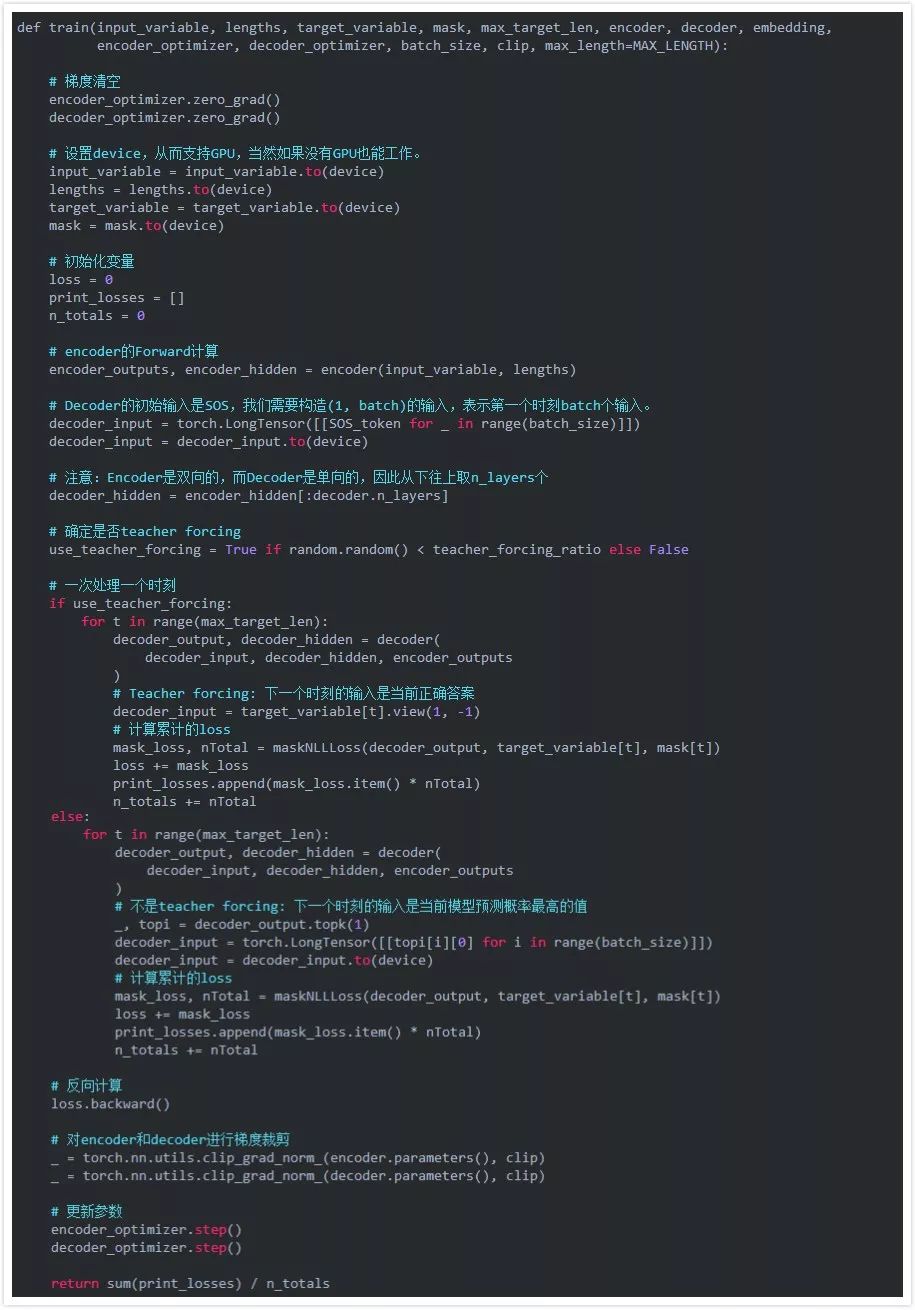
訓練迭代過程
最后是把前面的代碼組合起來進行訓練。函數trainIters用于進行n_iterations次minibatch的訓練。
值得注意的是我們定期會保存模型,我們會保存一個tar包,包括encoder和decoder的state_dicts(參數),優化器(optimizers)的state_dicts, loss和迭代次數。這樣保存模型的好處是從中恢復后我們既可以進行預測也可以進行訓練(因為有優化器的參數和迭代的次數)。
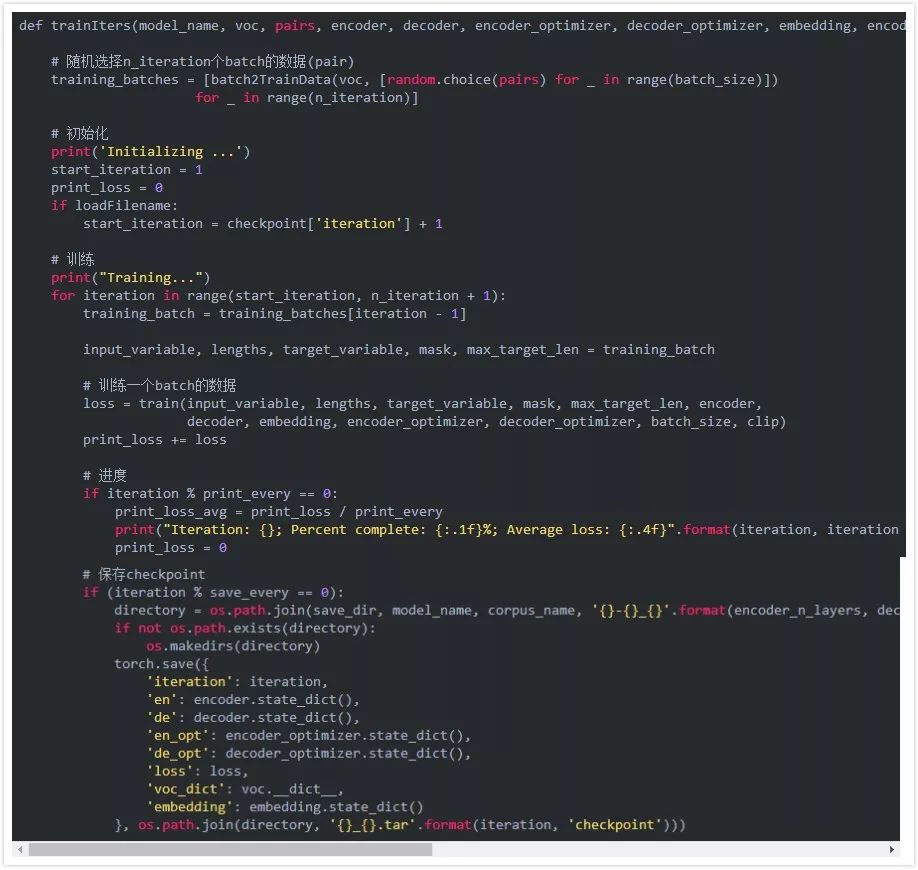
效果測試
模型訓練完成之后,我們需要測試它的效果。最簡單直接的方法就是和chatbot來聊天。因此我們需要用Decoder來生成一個響應。
貪心解碼(Greedy decoding)算法
最簡單的解碼算法是貪心算法,也就是每次都選擇概率最高的那個詞,然后把這個詞作為下一個時刻的輸入,直到遇到EOS結束解碼或者達到一個最大長度。但是貪心算法不一定能得到最優解,因為某個答案可能開始的幾個詞的概率并不太高,但是后來概率會很大。因此除了貪心算法,我們通常也可以使用Beam-Search算法,也就是每個時刻保留概率最高的Top K個結果,然后下一個時刻嘗試把這K個結果輸入(當然需要能恢復RNN的狀態),然后再從中選擇概率最高的K個。
為了實現貪心解碼算法,我們定義一個GreedySearchDecoder類。這個類的forwar的方法需要傳入一個輸入序列(input_seq),其shape是(input_seq length, 1), 輸入長度input_length和最大輸出長度max_length。就是過程如下:
1) 把輸入傳給Encoder,得到所有時刻的輸出和最后一個時刻的隱狀態。
2) 把Encoder最后時刻的隱狀態作為Decoder的初始狀態。
3) Decoder的第一輸入初始化為SOS。
4) 定義保存解碼結果的tensor
5) 循環直到最大解碼長度
a) 把當前輸入傳入Decoder
b) 得到概率最大的詞以及概率
c) 把這個詞和概率保存下來
d) 把當前輸出的詞作為下一個時刻的輸入
6) 返回所有的詞和概率
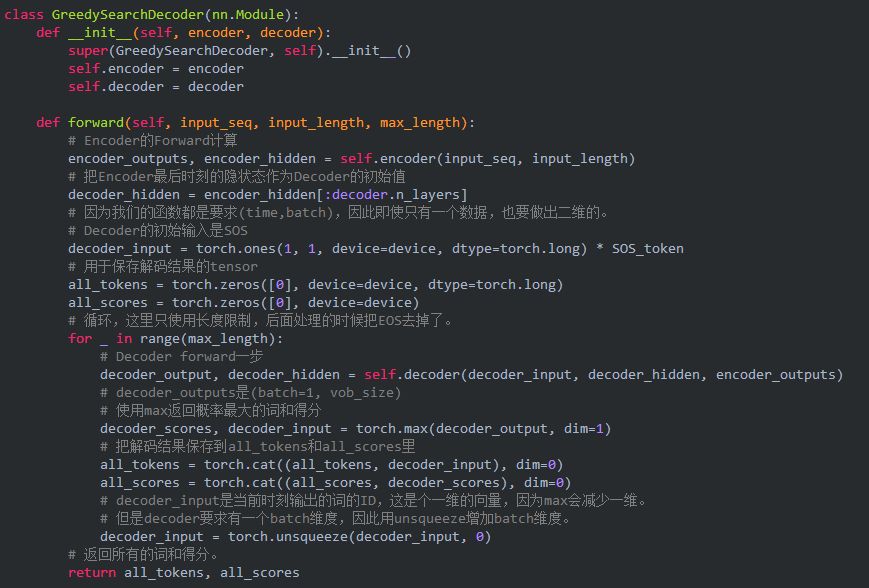
測試對話函數
解碼方法完成后,我們寫一個函數來測試從終端輸入一個句子然后來看看chatbot的回復。我們需要用前面的函數來把句子分詞,然后變成ID傳入解碼器,得到輸出的ID后再轉換成文字。我們會實現一個evaluate函數,由它來完成這些工作。我們需要把一個句子變成輸入需要的格式——shape為(batch, max_length),即使只有一個輸入也需要增加一個batch維度。我們首先把句子分詞,然后變成ID的序列,然后轉置成合適的格式。此外我們還需要創建一個名為lengths的tensor,雖然只有一個,來表示輸入的實際長度。接著我們構造類GreedySearchDecoder的實例searcher,然后用searcher來進行解碼得到輸出的ID,最后我們把這些ID變成詞并且去掉EOS之后的內容。
另外一個evaluateInput函數作為chatbot的用戶接口,當運行它的時候,它會首先提示用戶輸入一個句子,然后使用evaluate來生成回復。然后繼續對話直到用戶輸入”q”或者”quit”。如果用戶輸入的詞不在詞典里,我們會輸出錯誤信息(當然還有一種辦法是忽略這些詞)然后提示用戶重新輸入。
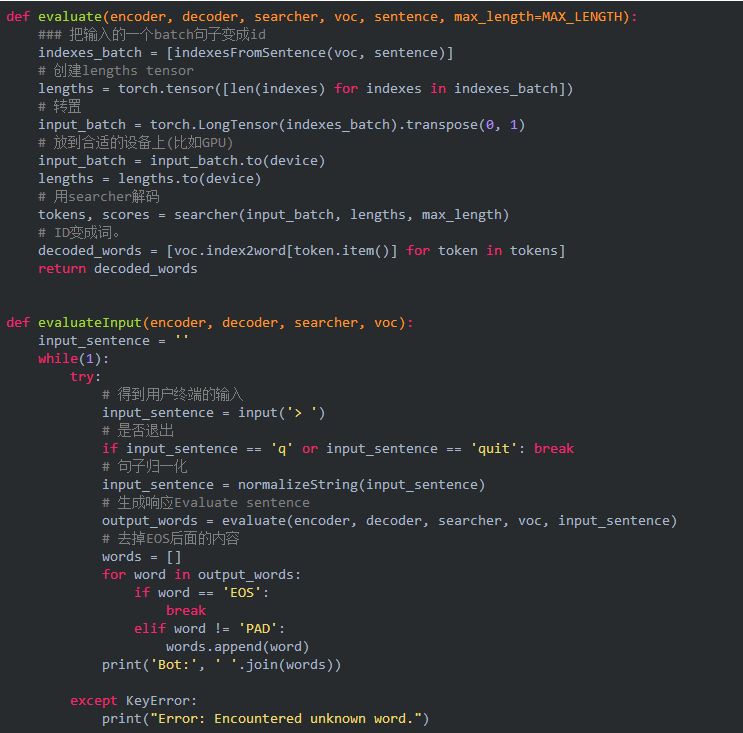
訓練和測試模型
最后我們可以來訓練模型和進行評測了。
不論是我們像訓練模型還是測試對話,我們都需要初始化encoder和decoder模型參數。在下面的代碼,我們從頭開始訓練模型或者從某個checkpoint加載模型。讀者可以嘗試不同的超參數配置來進行調優。
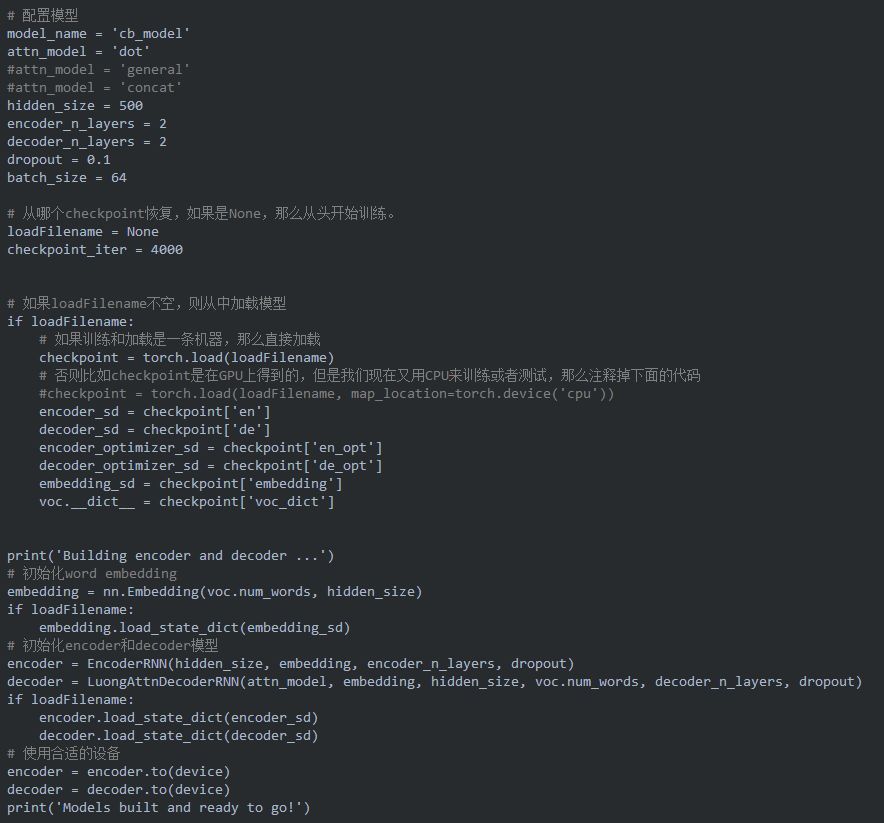
訓練
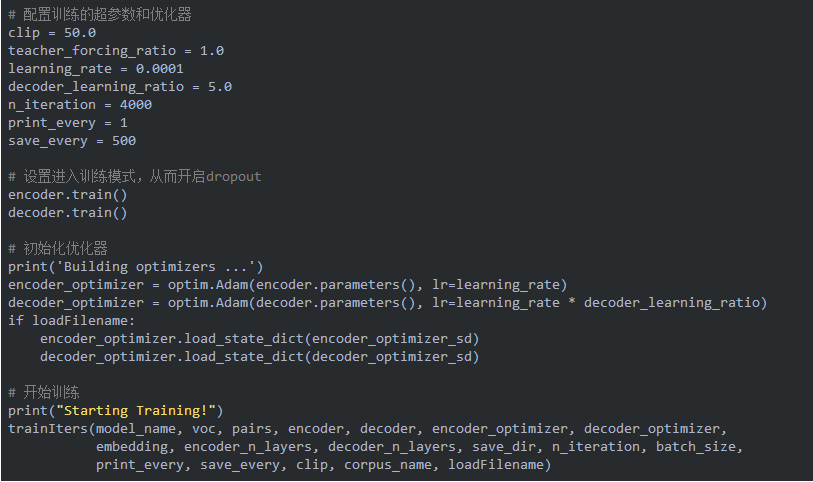
下面的代碼進行訓練,我們需要設置一些訓練的超參數。初始化優化器,最后調用函數trainIters進行訓練。
測試
我們使用下面的代碼進行測試。
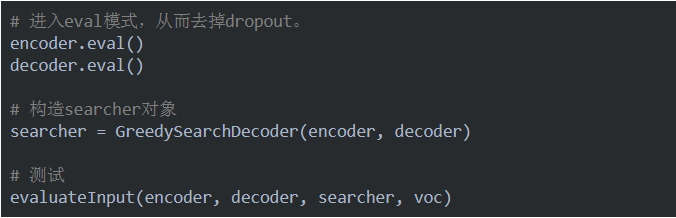
下面是測試的一些例子:

結論
上面介紹了怎么從零開始訓練一個chatbot,讀者可以用自己的數據訓練一個chatbot試試,看看能不能用來解決一些實際業務問題。
-
數據
+關注
關注
8文章
7246瀏覽量
91163 -
pytorch
+關注
關注
2文章
809瀏覽量
13786
原文標題:如何從零開始用PyTorch實現Chatbot?(附完整代碼)
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監
評論