 網絡爬蟲的作用是什么
網絡爬蟲的作用是什么
網絡爬蟲的作用是什么
網絡爬蟲又被稱為網頁蜘蛛,聚焦爬蟲,網絡機器人,在FOAF社區中間,更經常的稱為網頁追逐者,是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本。另外一些不常使用的名字還有螞蟻、自動索引、模擬程序或者蠕蟲。
網絡爬蟲是一個自動提取網頁的程序,它為搜索引擎從萬維網上下載網頁,是搜索引擎的重要組成。傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入隊列,直到滿足系統的一定停止條件。聚焦爬蟲的工作流程較為復雜,需要根據一定的網頁分析算法過濾與主題無關的鏈接,保留有用的鏈接并將其放入等待抓取的URL隊列。然后,它將根據一定的搜索策略從隊列中選擇下一步要抓取的網頁URL,并重復上述過程,直到達到系統的某一條件時停止。另外,所有被爬蟲抓取的網頁將會被系統存貯,進行一定的分析、過濾,并建立索引,以便之后的查詢和檢索;對于聚焦爬蟲來說,這一過程所得到的分析結果還可能對以后的抓取過程給出反饋和指導。
網絡爬蟲的具體作用是什么
說白了就是網絡黃牛利用爬蟲軟件24小時監控某個系統,比如說蘋果官網的維修預約就很難預約到,這時候就可以24小時監控他們的官網一有預約號出來立刻就用軟件搶了,然后再賣出去。
python網絡爬蟲的作用
1、做為通用搜索引擎網頁收集器。
2、做垂直搜索引擎。
3、科學研究:在線人類行為,在線社群演化,人類動力學研究,計量社會學,復雜網絡,數據挖掘,等領域的實證研究都需要大量數據,網絡爬蟲是收集相關數據的利器。
4、偷窺,hacking,發垃圾郵件。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
網絡爬蟲
+關注
關注
1文章
52瀏覽量
8888 -
爬蟲
+關注
關注
0文章
83瀏覽量
7375
發布評論請先 登錄
相關推薦
熱點推薦
IP地址數據信息和爬蟲攔截的關聯
IP地址數據信息和爬蟲攔截的關聯主要涉及到兩方面的內容,也就是數據信息和爬蟲。IP 地址數據信息的內容豐富,包括所屬地域、所屬網絡運營商、訪問時間序列、訪問頻率等。 從IP地址信息中可以窺見
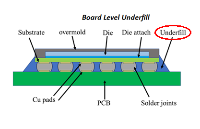
underfill膠水的作用是什么?
underfill膠水的作用是什么?Underfill膠水,也稱為底部填充膠,在電子半導體封裝技術工藝中扮演著至關重要的角色。其作用主要體現在以下幾個方面:加固與保護加固芯片連接:Underfill
大帶寬服務器的作用是什么
大帶寬服務器在現代互聯網應用中扮演著至關重要的角色,其作用主要體現在以下幾個方面,rak小編為您整理發布大帶寬服務器的作用是什么。
詳細解讀爬蟲多開代理IP的用途,以及如何配置!
爬蟲多開代理IP是一種在爬蟲開發中常用的技術策略,主要用于提高數據采集效率、避免IP被封禁以及獲取地域特定的數據。
電容的濾波作用是什么原理
電容的濾波作用是電子電路中非常常見的一種功能,其基本原理是通過電容對交流信號進行充電和放電,從而實現對信號的濾波。 一、電容濾波的基本原理 電容的基本特性 電容是一種能夠存儲電荷的電子元件,其
網絡濾波器的作用是什么
網絡濾波器是一種在通信系統中廣泛應用的設備,其主要作用是對信號進行濾波處理,以提高信號的質量和性能。濾波器的設計和應用涉及到許多方面,包括信號處理、電路設計、電磁兼容等。 一、網絡濾波器的作用
振蕩電路中選頻網絡的作用是什么
振蕩電路是電子電路中的一種重要類型,廣泛應用于通信、信號處理、時鐘同步等領域。在振蕩電路中,選頻網絡起著至關重要的作用。 一、選頻網絡的作用 頻率選擇性 選頻
神經網絡三層結構的作用是什么
的三層結構是最基本的神經網絡結構,包括輸入層、隱藏層和輸出層。下面介紹神經網絡三層結構的作用。 輸入層 輸入層是神經網絡的第一層,負責接收外部輸入信號。輸入層的神經元數量與輸入信號的維
卷積神經網絡激活函數的作用
起著至關重要的作用,它們可以增加網絡的非線性,提高網絡的表達能力,使網絡能夠學習到更加復雜的特征。本文將詳細介紹卷積神經網絡中激活函數的
pi調節器的作用是什么
的基本概念 比例(P)調節:比例調節是PI調節器的基礎,其作用是將輸入信號與設定值之間的偏差進行比例放大,從而產生控制信號。比例調節的特點是響應速度快,但存在穩態誤差。 積分(I)調節:積分調節的作用是消除比例調節中的穩態誤差。通過將
開關穩壓電源的作用是什么
開關穩壓電源的作用是什么 開關穩壓電源是一種廣泛應用于電子設備中的電源設備,其主要作用是將輸入的交流電或直流電轉換為穩定、連續的直流電輸出,以滿足電子設備對電源的特定需求。 一、開關穩壓電源的作用





 工商網監
工商網監
評論