") 網(wǎng)絡(luò)在線發(fā)布的BAT機器學(xué)習(xí)面試1000題系列
網(wǎng)絡(luò)在線發(fā)布的BAT機器學(xué)習(xí)面試1000題系列
刷題,是面試前的必備環(huán)節(jié)。本文作者便總結(jié)了往年BAT機器學(xué)習(xí)面試題,干貨滿滿,值得收藏。
想要入職大廠可謂是千軍萬馬過獨木橋。
為了通過層層考驗,刷題肯定是必不可少的。本文作者根據(jù)網(wǎng)絡(luò)在線發(fā)布的BAT機器學(xué)習(xí)面試1000題系列,整理了一份面試刷題寶典。
1.請簡要介紹下SVM。
SVM,全稱是support vector machine,中文名叫支持向量機。SVM是一個面向數(shù)據(jù)的分類算法,它的目標(biāo)是為確定一個分類超平面,從而將不同的數(shù)據(jù)分隔開。
擴展:
支持向量機學(xué)習(xí)方法包括構(gòu)建由簡至繁的模型:線性可分支持向量機、線性支持向量機及非線性支持向量機。當(dāng)訓(xùn)練數(shù)據(jù)線性可分時,通過硬間隔最大化,學(xué)習(xí)一個線性的分類器,即線性可分支持向量機,又稱為硬間隔支持向量機;當(dāng)訓(xùn)練數(shù)據(jù)近似線性可分時,通過軟間隔最大化,也學(xué)習(xí)一個線性的分類器,即線性支持向量機,又稱為軟間隔支持向量機;當(dāng)訓(xùn)練數(shù)據(jù)線性不可分時,通過使用核技巧及軟間隔最大化,學(xué)習(xí)非線性支持向量機。
支持向量機通俗導(dǎo)論(理解SVM的三層境界)
https://www.cnblogs.com/v-July-v/archive/2012/06/01/2539022.html
機器學(xué)習(xí)之深入理解SVM
http://blog.csdn.net/sinat_35512245/article/details/54984251
2.請簡要介紹下Tensorflow的計算圖。
@寒小陽:Tensorflow是一個通過計算圖的形式來表述計算的編程系統(tǒng),計算圖也叫數(shù)據(jù)流圖,可以把計算圖看做是一種有向圖,Tensorflow中的每一個計算都是計算圖上的一個節(jié)點,而節(jié)點之間的邊描述了計算之間的依賴關(guān)系。
3.請問GBDT和XGBoost的區(qū)別是什么?
@Xijun LI:XGBoost類似于GBDT的優(yōu)化版,不論是精度還是效率上都有了提升。與GBDT相比,具體的優(yōu)點有:
損失函數(shù)是用泰勒展式二項逼近,而不是像GBDT里的就是一階導(dǎo)數(shù);
對樹的結(jié)構(gòu)進行了正則化約束,防止模型過度復(fù)雜,降低了過擬合的可能性;
節(jié)點分裂的方式不同,GBDT是用的基尼系數(shù),XGBoost是經(jīng)過優(yōu)化推導(dǎo)后的。
知識點鏈接:集成學(xué)習(xí)的總結(jié)
https://xijunlee.github.io/2017/06/03/%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93/
4.在k-means或kNN,我們是用歐氏距離來計算最近的鄰居之間的距離。為什么不用曼哈頓距離?
曼哈頓距離只計算水平或垂直距離,有維度的限制。另一方面,歐氏距離可用于任何空間的距離計算問題。因為,數(shù)據(jù)點可以存在于任何空間,歐氏距離是更可行的選擇。例如:想象一下國際象棋棋盤,象或車所做的移動是由曼哈頓距離計算的,因為它們是在各自的水平和垂直方向做的運動。
5.百度2015校招機器學(xué)習(xí)筆試題。
知識點鏈接:百度2015校招機器學(xué)習(xí)筆試題
http://www.itmian4.com/thread-7042-1-1.html
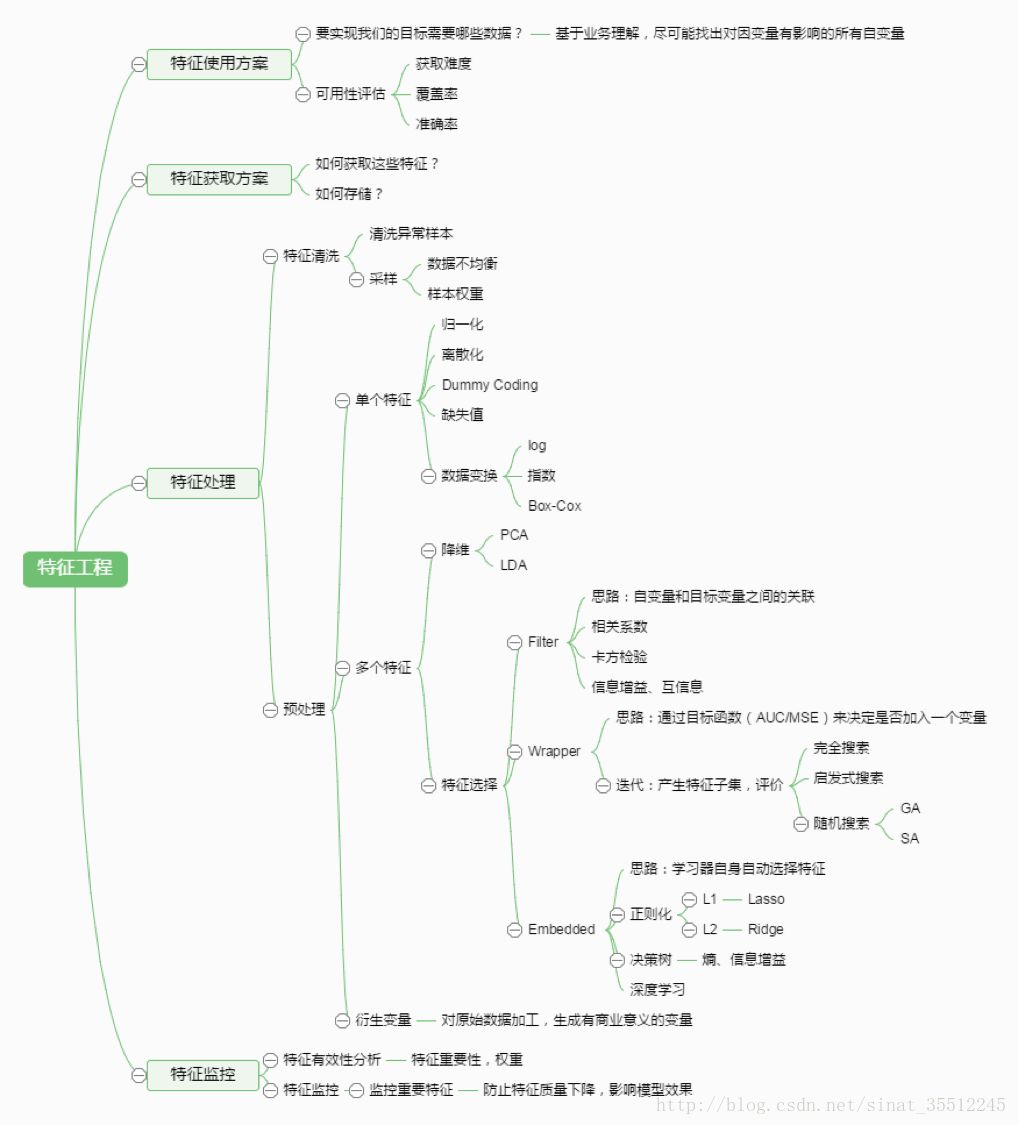
6.簡單說說特征工程。

7.關(guān)于LR。
@rickjin:把LR從頭到腳都給講一遍。建模,現(xiàn)場數(shù)學(xué)推導(dǎo),每種解法的原理,正則化,LR和maxent模型啥關(guān)系,LR為啥比線性回歸好。有不少會背答案的人,問邏輯細節(jié)就糊涂了。原理都會? 那就問工程,并行化怎么做,有幾種并行化方式,讀過哪些開源的實現(xiàn)。還會,那就準(zhǔn)備收了吧,順便逼問LR模型發(fā)展歷史。

知識點鏈接:機器學(xué)習(xí)之Logistic回歸(邏輯蒂斯回歸)
http://blog.csdn.net/sinat_35512245/article/details/54881672
8.overfitting怎么解決?
dropout、regularization、batch normalizatin
9.LR和SVM的聯(lián)系與區(qū)別?
@朝陽在望,聯(lián)系:
1、LR和SVM都可以處理分類問題,且一般都用于處理線性二分類問題(在改進的情況下可以處理多分類問題)
2、兩個方法都可以增加不同的正則化項,如L1、L2等等。所以在很多實驗中,兩種算法的結(jié)果是很接近的。
區(qū)別:
1、LR是參數(shù)模型,SVM是非參數(shù)模型。
2、從目標(biāo)函數(shù)來看,區(qū)別在于邏輯回歸采用的是Logistical Loss,SVM采用的是hinge loss.這兩個損失函數(shù)的目的都是增加對分類影響較大的數(shù)據(jù)點的權(quán)重,減少與分類關(guān)系較小的數(shù)據(jù)點的權(quán)重。
3、SVM的處理方法是只考慮Support Vectors,也就是和分類最相關(guān)的少數(shù)點,去學(xué)習(xí)分類器。而邏輯回歸通過非線性映射,大大減小了離分類平面較遠的點的權(quán)重,相對提升了與分類最相關(guān)的數(shù)據(jù)點的權(quán)重。
4、邏輯回歸相對來說模型更簡單,好理解,特別是大規(guī)模線性分類時比較方便。而SVM的理解和優(yōu)化相對來說復(fù)雜一些,SVM轉(zhuǎn)化為對偶問題后,分類只需要計算與少數(shù)幾個支持向量的距離,這個在進行復(fù)雜核函數(shù)計算時優(yōu)勢很明顯,能夠大大簡化模型和計算。
5、Logic 能做的 SVM能做,但可能在準(zhǔn)確率上有問題,SVM能做的Logic有的做不了。
答案來源:機器學(xué)習(xí)常見面試問題(一)
http://blog.csdn.net/timcompp/article/details/62237986
10.LR與線性回歸的區(qū)別與聯(lián)系?
@nishizhen
個人感覺邏輯回歸和線性回歸首先都是廣義的線性回歸,
其次經(jīng)典線性模型的優(yōu)化目標(biāo)函數(shù)是最小二乘,而邏輯回歸則是似然函數(shù),
另外線性回歸在整個實數(shù)域范圍內(nèi)進行預(yù)測,敏感度一致,而分類范圍,需要在[0,1]。邏輯回歸就是一種減小預(yù)測范圍,將預(yù)測值限定為[0,1]間的一種回歸模型,因而對于這類問題來說,邏輯回歸的魯棒性比線性回歸的要好。
@乖乖癩皮狗:邏輯回歸的模型本質(zhì)上是一個線性回歸模型,邏輯回歸都是以線性回歸為理論支持的。但線性回歸模型無法做到sigmoid的非線性形式,sigmoid可以輕松處理0/1分類問題。
11.為什么XGBoost要用泰勒展開,優(yōu)勢在哪里?
@AntZ:XGBoost使用了一階和二階偏導(dǎo), 二階導(dǎo)數(shù)有利于梯度下降的更快更準(zhǔn). 使用泰勒展開取得二階倒數(shù)形式, 可以在不選定損失函數(shù)具體形式的情況下用于算法優(yōu)化分析.本質(zhì)上也就把損失函數(shù)的選取和模型算法優(yōu)化/參數(shù)選擇分開了. 這種去耦合增加了XGBoost的適用性。
12.XGBoost如何尋找最優(yōu)特征?是又放回還是無放回的呢?
@AntZ:XGBoost在訓(xùn)練的過程中給出各個特征的評分,從而表明每個特征對模型訓(xùn)練的重要性.。XGBoost利用梯度優(yōu)化模型算法, 樣本是不放回的(想象一個樣本連續(xù)重復(fù)抽出,梯度來回踏步會不會高興)。但XGBoost支持子采樣, 也就是每輪計算可以不使用全部樣本。
13.談?wù)勁袆e式模型和生成式模型?
判別方法:由數(shù)據(jù)直接學(xué)習(xí)決策函數(shù) Y = f(X),或者由條件分布概率 P(Y|X)作為預(yù)測模型,即判別模型。
生成方法:由數(shù)據(jù)學(xué)習(xí)聯(lián)合概率密度分布函數(shù) P(X,Y),然后求出條件概率分布P(Y|X)作為預(yù)測的模型,即生成模型。
由生成模型可以得到判別模型,但由判別模型得不到生成模型。
常見的判別模型有:K近鄰、SVM、決策樹、感知機、線性判別分析(LDA)、線性回歸、傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)、邏輯斯蒂回歸、boosting、條件隨機場
常見的生成模型有:樸素貝葉斯、隱馬爾可夫模型、高斯混合模型、文檔主題生成模型(LDA)、限制玻爾茲曼機
14.L1和L2的區(qū)別。
L1范數(shù)(L1 norm)是指向量中各個元素絕對值之和,也有個美稱叫“稀疏規(guī)則算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范數(shù)為 |1|+|-1|+|3|.
簡單總結(jié)一下就是:
L1范數(shù): 為x向量各個元素絕對值之和。
L2范數(shù): 為x向量各個元素平方和的1/2次方,L2范數(shù)又稱Euclidean范數(shù)或Frobenius范數(shù)
Lp范數(shù): 為x向量各個元素絕對值p次方和的1/p次方.
在支持向量機學(xué)習(xí)過程中,L1范數(shù)實際是一種對于成本函數(shù)求解最優(yōu)的過程,因此,L1范數(shù)正則化通過向成本函數(shù)中添加L1范數(shù),使得學(xué)習(xí)得到的結(jié)果滿足稀疏化,從而方便人類提取特征。
L1范數(shù)可以使權(quán)值稀疏,方便特征提取。
L2范數(shù)可以防止過擬合,提升模型的泛化能力。
15.L1和L2正則先驗分別服從什么分布 ?
@齊同學(xué):面試中遇到的,L1和L2正則先驗分別服從什么分布,L1是拉普拉斯分布,L2是高斯分布。
16.CNN最成功的應(yīng)用是在CV,那為什么NLP和Speech的很多問題也可以用CNN解出來?為什么AlphaGo里也用了CNN?這幾個不相關(guān)的問題的相似性在哪里?CNN通過什么手段抓住了這個共性?
@許韓
知識點鏈接(答案解析):深度學(xué)習(xí)崗位面試問題整理筆記
https://zhuanlan.zhihu.com/p/25005808
17.說一下Adaboost,權(quán)值更新公式。當(dāng)弱分類器是Gm時,每個樣本的的權(quán)重是w1,w2…,請寫出最終的決策公式。
答案解析
http://www.360doc.com/content/14/1109/12/20290918_423780183.shtml
18.LSTM結(jié)構(gòu)推導(dǎo),為什么比RNN好?
推導(dǎo)forget gate,input gate,cell state, hidden information等的變化;因為LSTM有進有出且當(dāng)前的cell informaton是通過input gate控制之后疊加的,RNN是疊乘,因此LSTM可以防止梯度消失或者爆炸。
19.經(jīng)常在網(wǎng)上搜索東西的朋友知道,當(dāng)你不小心輸入一個不存在的單詞時,搜索引擎會提示你是不是要輸入某一個正確的單詞,比如當(dāng)你在Google中輸入“Julw”時,系統(tǒng)會猜測你的意圖:是不是要搜索“July”,如下圖所示:
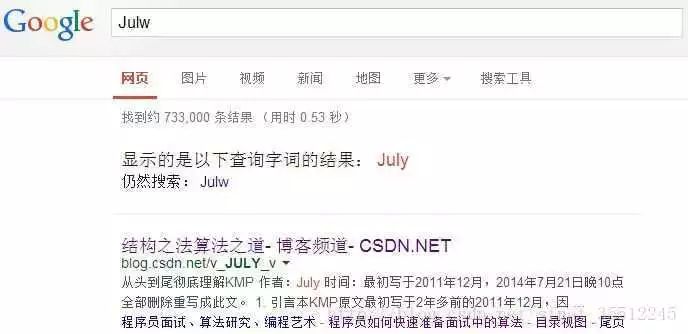
這叫做拼寫檢查。根據(jù)谷歌一員工寫的文章How to Write a Spelling Corrector顯示,Google的拼寫檢查基于貝葉斯方法。請說說的你的理解,具體Google是怎么利用貝葉斯方法,實現(xiàn)”拼寫檢查”的功能。
用戶輸入一個單詞時,可能拼寫正確,也可能拼寫錯誤。如果把拼寫正確的情況記做c(代表correct),拼寫錯誤的情況記做w(代表wrong),那么”拼寫檢查”要做的事情就是:在發(fā)生w的情況下,試圖推斷出c。換言之:已知w,然后在若干個備選方案中,找出可能性最大的那個c,也就是求P(c|w)P(c|w)的最大值。而根據(jù)貝葉斯定理,有:
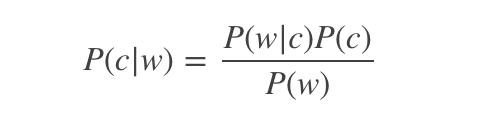
由于對于所有備選的c來說,對應(yīng)的都是同一個w,所以它們的P(w)是相同的,因此我們只要最大化P(w|c)P(c)即可。其中:
P(c)表示某個正確的詞的出現(xiàn)”概率”,它可以用”頻率”代替。如果我們有一個足夠大的文本庫,那么這個文本庫中每個單詞的出現(xiàn)頻率,就相當(dāng)于它的發(fā)生概率。某個詞的出現(xiàn)頻率越高,P(c)就越大。比如在你輸入一個錯誤的詞“Julw”時,系統(tǒng)更傾向于去猜測你可能想輸入的詞是“July”,而不是“Jult”,因為“July”更常見。
P(w|c)表示在試圖拼寫c的情況下,出現(xiàn)拼寫錯誤w的概率。為了簡化問題,假定兩個單詞在字形上越接近,就有越可能拼錯,P(w|c)就越大。舉例來說,相差一個字母的拼法,就比相差兩個字母的拼法,發(fā)生概率更高。你想拼寫單詞July,那么錯誤拼成Julw(相差一個字母)的可能性,就比拼成Jullw高(相差兩個字母)。值得一提的是,一般把這種問題稱為“編輯距離”,參見程序員編程藝術(shù)第二十八~二十九章:最大連續(xù)乘積子串、字符串編輯距離。
http://blog.csdn.net/v_july_v/article/details/8701148#t4
所以,我們比較所有拼寫相近的詞在文本庫中的出現(xiàn)頻率,再從中挑出出現(xiàn)頻率最高的一個,即是用戶最想輸入的那個詞。具體的計算過程及此方法的缺陷請參見How to Write a Spelling Corrector。
http://norvig.com/spell-correct.html
20.為什么樸素貝葉斯如此“樸素”?
因為它假定所有的特征在數(shù)據(jù)集中的作用是同樣重要和獨立的。正如我們所知,這個假設(shè)在現(xiàn)實世界中是很不真實的,因此,說樸素貝葉斯真的很“樸素”。
21.機器學(xué)習(xí)中,為何要經(jīng)常對數(shù)據(jù)做歸一化?
@zhanlijun
本題解析來源:為什么一些機器學(xué)習(xí)模型需要對數(shù)據(jù)進行歸一化?
http://www.cnblogs.com/LBSer/p/4440590.html
22.談?wù)勆疃葘W(xué)習(xí)中的歸一化問題。
詳情參見此視頻:深度學(xué)習(xí)中的歸一化
http://www.julyedu.com/video/play/69/686
23.請簡要說說一個完整機器學(xué)習(xí)項目的流程。
1 抽象成數(shù)學(xué)問題
明確問題是進行機器學(xué)習(xí)的第一步。機器學(xué)習(xí)的訓(xùn)練過程通常都是一件非常耗時的事情,胡亂嘗試時間成本是非常高的。
這里的抽象成數(shù)學(xué)問題,指的我們明確我們可以獲得什么樣的數(shù)據(jù),目標(biāo)是一個分類還是回歸或者是聚類的問題,如果都不是的話,如果劃歸為其中的某類問題。
2 獲取數(shù)據(jù)
數(shù)據(jù)決定了機器學(xué)習(xí)結(jié)果的上限,而算法只是盡可能逼近這個上限。
數(shù)據(jù)要有代表性,否則必然會過擬合。
而且對于分類問題,數(shù)據(jù)偏斜不能過于嚴(yán)重,不同類別的數(shù)據(jù)數(shù)量不要有數(shù)個數(shù)量級的差距。
而且還要對數(shù)據(jù)的量級有一個評估,多少個樣本,多少個特征,可以估算出其對內(nèi)存的消耗程度,判斷訓(xùn)練過程中內(nèi)存是否能夠放得下。如果放不下就得考慮改進算法或者使用一些降維的技巧了。如果數(shù)據(jù)量實在太大,那就要考慮分布式了。
3 特征預(yù)處理與特征選擇
良好的數(shù)據(jù)要能夠提取出良好的特征才能真正發(fā)揮效力。
特征預(yù)處理、數(shù)據(jù)清洗是很關(guān)鍵的步驟,往往能夠使得算法的效果和性能得到顯著提高。歸一化、離散化、因子化、缺失值處理、去除共線性等,數(shù)據(jù)挖掘過程中很多時間就花在它們上面。這些工作簡單可復(fù)制,收益穩(wěn)定可預(yù)期,是機器學(xué)習(xí)的基礎(chǔ)必備步驟。
篩選出顯著特征、摒棄非顯著特征,需要機器學(xué)習(xí)工程師反復(fù)理解業(yè)務(wù)。這對很多結(jié)果有決定性的影響。特征選擇好了,非常簡單的算法也能得出良好、穩(wěn)定的結(jié)果。這需要運用特征有效性分析的相關(guān)技術(shù),如相關(guān)系數(shù)、卡方檢驗、平均互信息、條件熵、后驗概率、邏輯回歸權(quán)重等方法。
4 訓(xùn)練模型與調(diào)優(yōu)
直到這一步才用到我們上面說的算法進行訓(xùn)練。現(xiàn)在很多算法都能夠封裝成黑盒供人使用。但是真正考驗水平的是調(diào)整這些算法的(超)參數(shù),使得結(jié)果變得更加優(yōu)良。這需要我們對算法的原理有深入的理解。理解越深入,就越能發(fā)現(xiàn)問題的癥結(jié),提出良好的調(diào)優(yōu)方案。
5 模型診斷
如何確定模型調(diào)優(yōu)的方向與思路呢?這就需要對模型進行診斷的技術(shù)。
過擬合、欠擬合 判斷是模型診斷中至關(guān)重要的一步。常見的方法如交叉驗證,繪制學(xué)習(xí)曲線等。過擬合的基本調(diào)優(yōu)思路是增加數(shù)據(jù)量,降低模型復(fù)雜度。欠擬合的基本調(diào)優(yōu)思路是提高特征數(shù)量和質(zhì)量,增加模型復(fù)雜度。
誤差分析 也是機器學(xué)習(xí)至關(guān)重要的步驟。通過觀察誤差樣本,全面分析誤差產(chǎn)生誤差的原因:是參數(shù)的問題還是算法選擇的問題,是特征的問題還是數(shù)據(jù)本身的問題……
診斷后的模型需要進行調(diào)優(yōu),調(diào)優(yōu)后的新模型需要重新進行診斷,這是一個反復(fù)迭代不斷逼近的過程,需要不斷地嘗試, 進而達到最優(yōu)狀態(tài)。
6 模型融合
一般來說,模型融合后都能使得效果有一定提升。而且效果很好。
工程上,主要提升算法準(zhǔn)確度的方法是分別在模型的前端(特征清洗和預(yù)處理,不同的采樣模式)與后端(模型融合)上下功夫。因為他們比較標(biāo)準(zhǔn)可復(fù)制,效果比較穩(wěn)定。而直接調(diào)參的工作不會很多,畢竟大量數(shù)據(jù)訓(xùn)練起來太慢了,而且效果難以保證。
7 上線運行
這一部分內(nèi)容主要跟工程實現(xiàn)的相關(guān)性比較大。工程上是結(jié)果導(dǎo)向,模型在線上運行的效果直接決定模型的成敗。 不單純包括其準(zhǔn)確程度、誤差等情況,還包括其運行的速度(時間復(fù)雜度)、資源消耗程度(空間復(fù)雜度)、穩(wěn)定性是否可接受。
這些工作流程主要是工程實踐上總結(jié)出的一些經(jīng)驗。并不是每個項目都包含完整的一個流程。這里的部分只是一個指導(dǎo)性的說明,只有大家自己多實踐,多積累項目經(jīng)驗,才會有自己更深刻的認識。
故,基于此,七月在線每一期ML算法班都特此增加特征工程、模型調(diào)優(yōu)等相關(guān)課。比如,這里有個公開課視頻《特征處理與特征選擇》。
24.new 和 malloc的區(qū)別?
知識點鏈接:new 和 malloc的區(qū)別
https://www.cnblogs.com/fly1988happy/archive/2012/04/26/2470542.html
25.hash 沖突及解決辦法?
@Sommer_Xia
關(guān)鍵字值不同的元素可能會映象到哈希表的同一地址上就會發(fā)生哈希沖突。解決辦法:
1)開放定址法:當(dāng)沖突發(fā)生時,使用某種探查(亦稱探測)技術(shù)在散列表中形成一個探查(測)序列。沿此序列逐個單元地查找,直到找到給定 的關(guān)鍵字,或者碰到一個開放的地址(即該地址單元為空)為止(若要插入,在探查到開放的地址,則可將待插入的新結(jié)點存人該地址單元)。查找時探查到開放的 地址則表明表中無待查的關(guān)鍵字,即查找失敗。
2) 再哈希法:同時構(gòu)造多個不同的哈希函數(shù)。
3)鏈地址法:將所有哈希地址為i的元素構(gòu)成一個稱為同義詞鏈的單鏈表,并將單鏈表的頭指針存在哈希表的第i個單元中,因而查找、插入和刪除主要在同義詞鏈中進行。鏈地址法適用于經(jīng)常進行插入和刪除的情況。
4)建立公共溢出區(qū):將哈希表分為基本表和溢出表兩部分,凡是和基本表發(fā)生沖突的元素,一律填入溢出表。
26.如何解決梯度消失和梯度膨脹?
(1)梯度消失:
根據(jù)鏈?zhǔn)椒▌t,如果每一層神經(jīng)元對上一層的輸出的偏導(dǎo)乘上權(quán)重結(jié)果都小于1的話,那么即使這個結(jié)果是0.99,在經(jīng)過足夠多層傳播之后,誤差對輸入層的偏導(dǎo)會趨于0。
可以采用ReLU激活函數(shù)有效的解決梯度消失的情況。
(2)梯度膨脹:
根據(jù)鏈?zhǔn)椒▌t,如果每一層神經(jīng)元對上一層的輸出的偏導(dǎo)乘上權(quán)重結(jié)果都大于1的話,在經(jīng)過足夠多層傳播之后,誤差對輸入層的偏導(dǎo)會趨于無窮大。
可以通過激活函數(shù)來解決。
27.下列哪個不屬于CRF模型對于HMM和MEMM模型的優(yōu)勢( )
A. 特征靈活
B. 速度快
C. 可容納較多上下文信息
D. 全局最優(yōu)
解答:首先,CRF,HMM(隱馬模型),MEMM(最大熵隱馬模型)都常用來做序列標(biāo)注的建模。
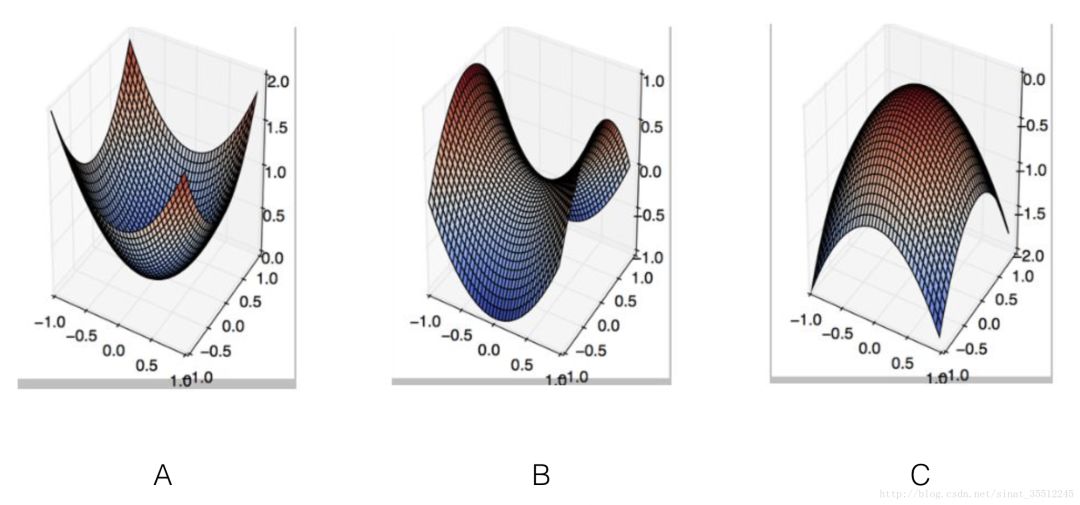
隱馬模型一個最大的缺點就是由于其輸出獨立性假設(shè),導(dǎo)致其不能考慮上下文的特征,限制了特征的選擇。
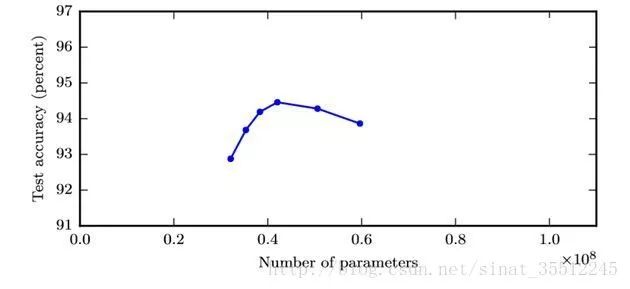
最大熵隱馬模型則解決了隱馬的問題,可以任意選擇特征,但由于其在每一節(jié)點都要進行歸一化,所以只能找到局部的最優(yōu)值,同時也帶來了標(biāo)記偏見的問題,即凡是訓(xùn)練語料中未出現(xiàn)的情況全都忽略掉。
條件隨機場則很好的解決了這一問題,他并不在每一個節(jié)點進行歸一化,而是所有特征進行全局歸一化,因此可以求得全局的最優(yōu)值。
答案為B。
28.簡單說下有監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)的區(qū)別?
有監(jiān)督學(xué)習(xí):對具有標(biāo)記的訓(xùn)練樣本進行學(xué)習(xí),以盡可能對訓(xùn)練樣本集外的數(shù)據(jù)進行分類預(yù)測。(LR,SVM,BP,RF,GBDT)
無監(jiān)督學(xué)習(xí):對未標(biāo)記的樣本進行訓(xùn)練學(xué)習(xí),比發(fā)現(xiàn)這些樣本中的結(jié)構(gòu)知識。(KMeans,DL)
29.了解正則化么?
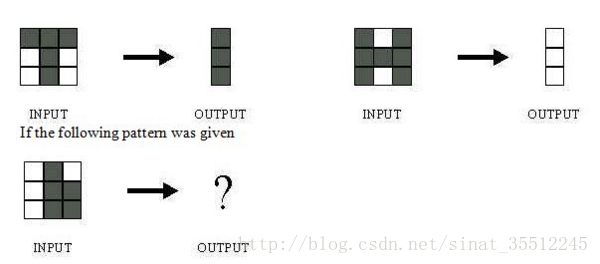
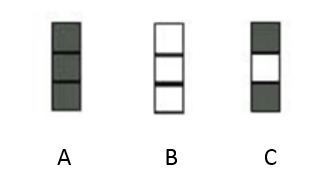
正則化是針對過擬合而提出的,以為在求解模型最優(yōu)的是一般優(yōu)化最小的經(jīng)驗風(fēng)險,現(xiàn)在在該經(jīng)驗風(fēng)險上加入模型復(fù)雜度這一項(正則化項是模型參數(shù)向量的范數(shù)),并使用一個rate比率來權(quán)衡模型復(fù)雜度與以往經(jīng)驗風(fēng)險的權(quán)重,如果模型復(fù)雜度越高,結(jié)構(gòu)化的經(jīng)驗風(fēng)險會越大,現(xiàn)在的目標(biāo)就變?yōu)榱私Y(jié)構(gòu)經(jīng)驗風(fēng)險的最優(yōu)化,可以防止模型訓(xùn)練過度復(fù)雜,有效的降低過擬合的風(fēng)險。
奧卡姆剃刀原理,能夠很好的解釋已知數(shù)據(jù)并且十分簡單才是最好的模型。
30.協(xié)方差和相關(guān)性有什么區(qū)別?
相關(guān)性是協(xié)方差的標(biāo)準(zhǔn)化格式。協(xié)方差本身很難做比較。例如:如果我們計算工資($)和年齡(歲)的協(xié)方差,因為這兩個變量有不同的度量,所以我們會得到不能做比較的不同的協(xié)方差。為了解決這個問題,我們計算相關(guān)性來得到一個介于-1和1之間的值,就可以忽略它們各自不同的度量。
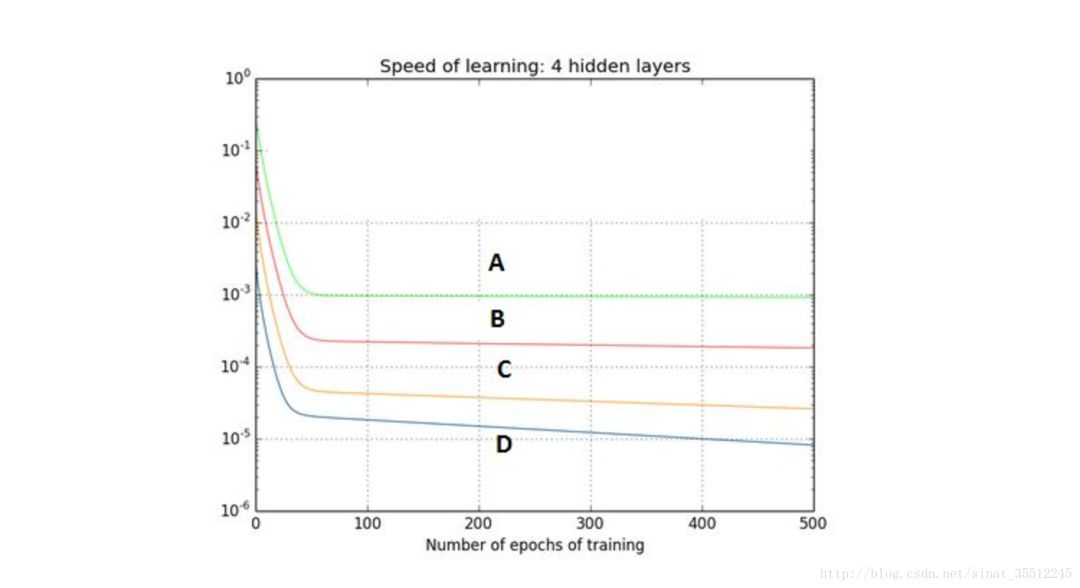
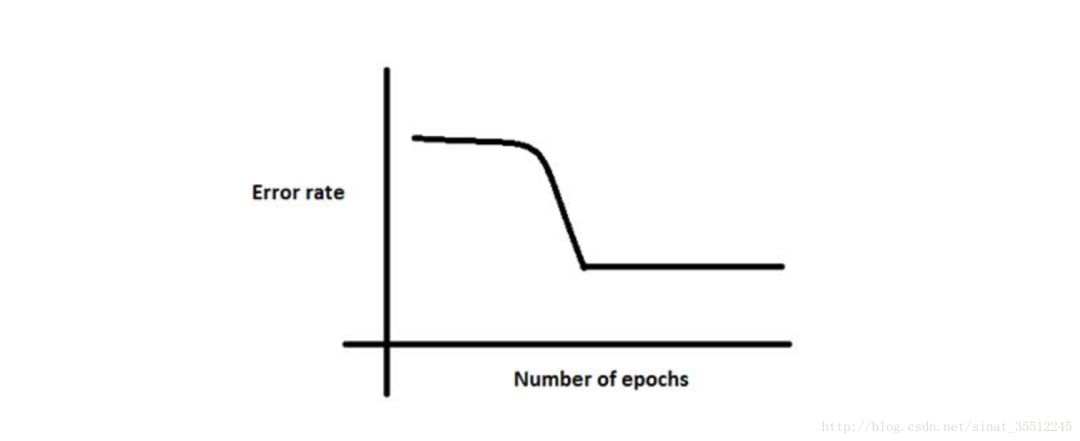
31.線性分類器與非線性分類器的區(qū)別以及優(yōu)劣。
如果模型是參數(shù)的線性函數(shù),并且存在線性分類面,那么就是線性分類器,否則不是。
常見的線性分類器有:LR,貝葉斯分類,單層感知機、線性回歸。
常見的非線性分類器:決策樹、RF、GBDT、多層感知機。
SVM兩種都有(看線性核還是高斯核)。
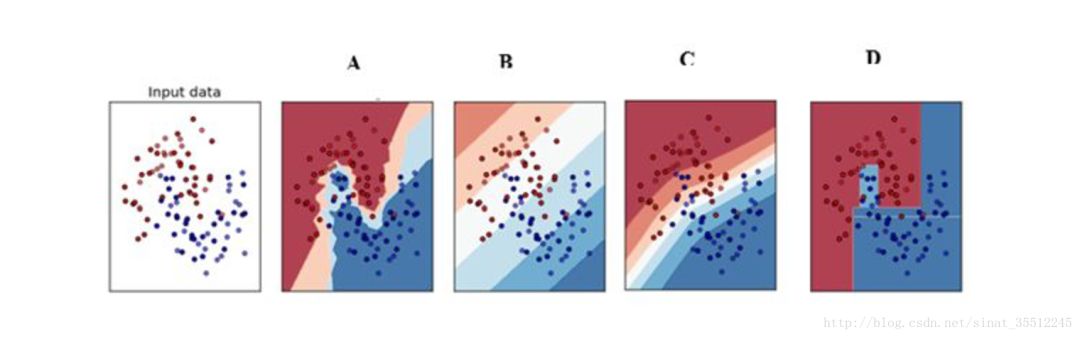
線性分類器速度快、編程方便,但是可能擬合效果不會很好。
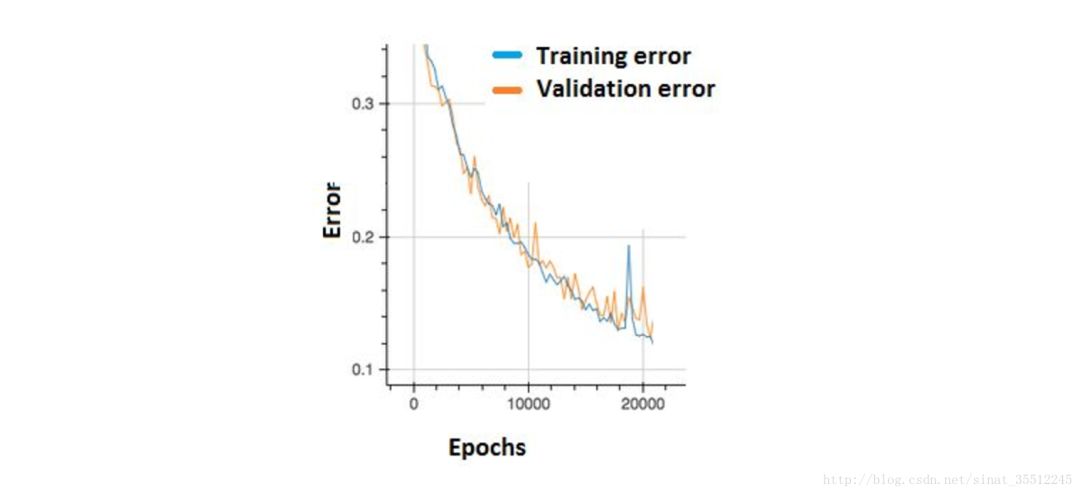
非線性分類器編程復(fù)雜,但是效果擬合能力強。
32.數(shù)據(jù)的邏輯存儲結(jié)構(gòu)(如數(shù)組,隊列,樹等)對于軟件開發(fā)具有十分重要的影響,試對你所了解的各種存儲結(jié)構(gòu)從運行速度、存儲效率和適用場合等方面進行簡要地分析。

33.什么是分布式數(shù)據(jù)庫?
分布式數(shù)據(jù)庫系統(tǒng)是在集中式數(shù)據(jù)庫系統(tǒng)成熟技術(shù)的基礎(chǔ)上發(fā)展起來的,但不是簡單地把集中式數(shù)據(jù)庫分散地實現(xiàn),它具有自己的性質(zhì)和特征。集中式數(shù)據(jù)庫系統(tǒng)的許多概念和技術(shù),如數(shù)據(jù)獨立性、數(shù)據(jù)共享和減少冗余度、并發(fā)控制、完整性、安全性和恢復(fù)等在分布式數(shù)據(jù)庫系統(tǒng)中都有了不同的、更加豐富的內(nèi)容。
34.簡單說說貝葉斯定理。
在引出貝葉斯定理之前,先學(xué)習(xí)幾個定義:
條件概率(又稱后驗概率)就是事件A在另外一個事件B已經(jīng)發(fā)生條件下的發(fā)生概率。條件概率表示為P(A|B),讀作“在B條件下A的概率”。
比如,在同一個樣本空間Ω中的事件或者子集A與B,如果隨機從Ω中選出的一個元素屬于B,那么這個隨機選擇的元素還屬于A的概率就定義為在B的前提下A的條件概率,所以:P(A|B) = |A∩B|/|B|,接著分子、分母都除以|Ω|得到:
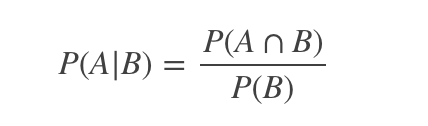
聯(lián)合概率表示兩個事件共同發(fā)生的概率。A與B的聯(lián)合概率表示為P(A∩B)或者P(A,B)。
邊緣概率(又稱先驗概率)是某個事件發(fā)生的概率。邊緣概率是這樣得到的:在聯(lián)合概率中,把最終結(jié)果中那些不需要的事件通過合并成它們的全概率,而消去它們(對離散隨機變量用求和得全概率,對連續(xù)隨機變量用積分得全概率),這稱為邊緣化(marginalization),比如A的邊緣概率表示為P(A),B的邊緣概率表示為P(B)。
接著,考慮一個問題:P(A|B)是在B發(fā)生的情況下A發(fā)生的可能性。
1)首先,事件B發(fā)生之前,我們對事件A的發(fā)生有一個基本的概率判斷,稱為A的先驗概率,用P(A)表示;
2)其次,事件B發(fā)生之后,我們對事件A的發(fā)生概率重新評估,稱為A的后驗概率,用P(A|B)表示;
3)類似的,事件A發(fā)生之前,我們對事件B的發(fā)生有一個基本的概率判斷,稱為B的先驗概率,用P(B)表示;
4)同樣,事件A發(fā)生之后,我們對事件B的發(fā)生概率重新評估,稱為B的后驗概率,用P(B|A)表示。
貝葉斯定理的公式表達式:
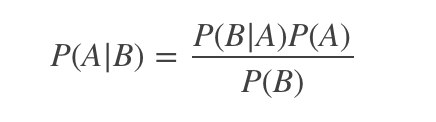
35.#include
知識點鏈接:#include
http://blog.csdn.net/u010339647/article/details/77825788
36.某超市研究銷售紀(jì)錄數(shù)據(jù)后發(fā)現(xiàn),買啤酒的人很大概率也會購買尿布,這種屬于數(shù)據(jù)挖掘的哪類問題?(A)
A. 關(guān)聯(lián)規(guī)則發(fā)現(xiàn) B. 聚類 C. 分類 D. 自然語言處理
37.將原始數(shù)據(jù)進行集成、變換、維度規(guī)約、數(shù)值規(guī)約是在以下哪個步驟的任務(wù)?(C)
A. 頻繁模式挖掘 B. 分類和預(yù)測 C. 數(shù)據(jù)預(yù)處理 D. 數(shù)據(jù)流挖掘
38.下面哪種不屬于數(shù)據(jù)預(yù)處理的方法?(D)
A變量代換 B離散化 C 聚集 D 估計遺漏值
39.什么是KDD?(A)
A. 數(shù)據(jù)挖掘與知識發(fā)現(xiàn) B. 領(lǐng)域知識發(fā)現(xiàn)C. 文檔知識發(fā)現(xiàn) D. 動態(tài)知識發(fā)現(xiàn)
40.當(dāng)不知道數(shù)據(jù)所帶標(biāo)簽時,可以使用哪種技術(shù)促使帶同類標(biāo)簽的數(shù)據(jù)與帶其他標(biāo)簽的數(shù)據(jù)相分離?(B)
A. 分類 B. 聚類 C. 關(guān)聯(lián)分析 D. 隱馬爾可夫鏈
41.建立一個模型,通過這個模型根據(jù)已知的變量值來預(yù)測其他某個變量值屬于數(shù)據(jù)挖掘的哪一類任務(wù)?(C)
A. 根據(jù)內(nèi)容檢索 B. 建模描述
C. 預(yù)測建模 D. 尋找模式和規(guī)則
42.以下哪種方法不屬于特征選擇的標(biāo)準(zhǔn)方法?(D)
A嵌入 B 過濾 C 包裝 D 抽樣
43.請用python編寫函數(shù)find_string,從文本中搜索并打印內(nèi)容,要求支持通配符星號和問號。
1find_string('hello\nworld\n','wor') 2['wor'] 3find_string('hello\nworld\n','l*d') 4['ld'] 5find_string('hello\nworld\n','o.') 6['or'] 7答案 8deffind_string(str,pat): 9importre10returnre.findall(pat,str,re.I)11---------------------12作者:qinjianhuang13來源:CSDN14原文:https://huangqinjian.blog.csdn.net/article/details/7879632815版權(quán)聲明:本文為博主原創(chuàng)文章,轉(zhuǎn)載請附上博文鏈接!
44.說下紅黑樹的五個性質(zhì)。
教你初步了解紅黑樹
http://blog.csdn.net/v_july_v/article/details/6105630
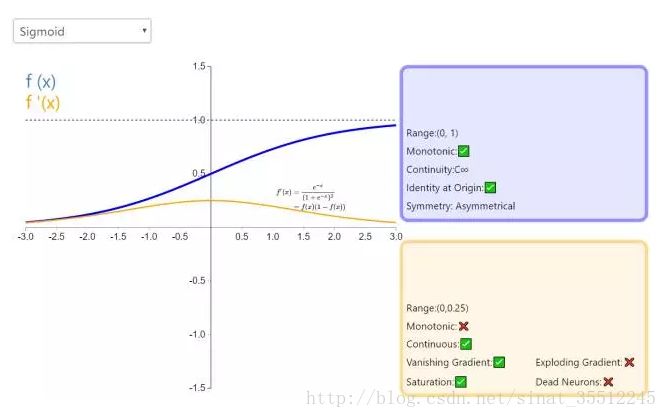
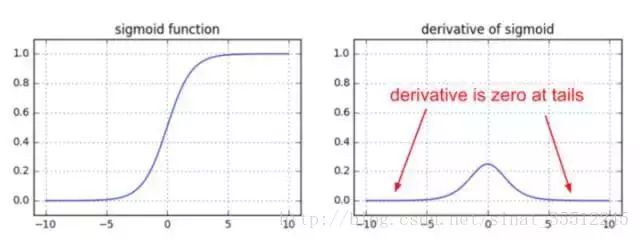
45.簡單說下sigmoid激活函數(shù)。
常用的非線性激活函數(shù)有sigmoid、tanh、relu等等,前兩者sigmoid/tanh比較常見于全連接層,后者relu常見于卷積層。這里先簡要介紹下最基礎(chǔ)的sigmoid函數(shù)(btw,在本博客中SVM那篇文章開頭有提過)。
Sigmoid的函數(shù)表達式如下:
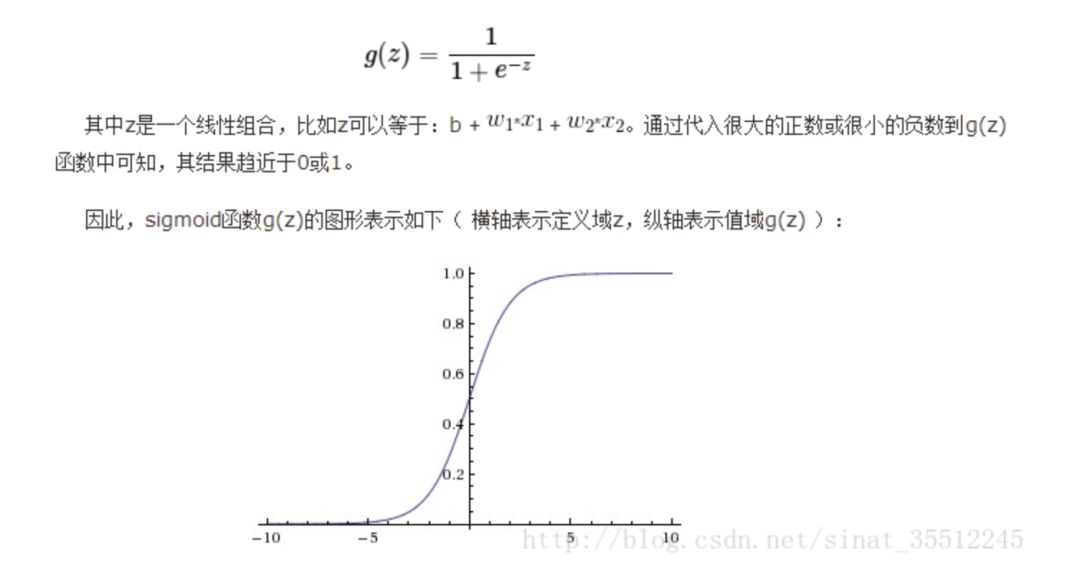
也就是說,Sigmoid函數(shù)的功能是相當(dāng)于把一個實數(shù)壓縮至0到1之間。當(dāng)z是非常大的正數(shù)時,g(z)會趨近于1,而z是非常小的負數(shù)時,則g(z)會趨近于0。
壓縮至0到1有何用處呢?用處是這樣一來便可以把激活函數(shù)看作一種“分類的概率”,比如激活函數(shù)的輸出為0.9的話便可以解釋為90%的概率為正樣本。
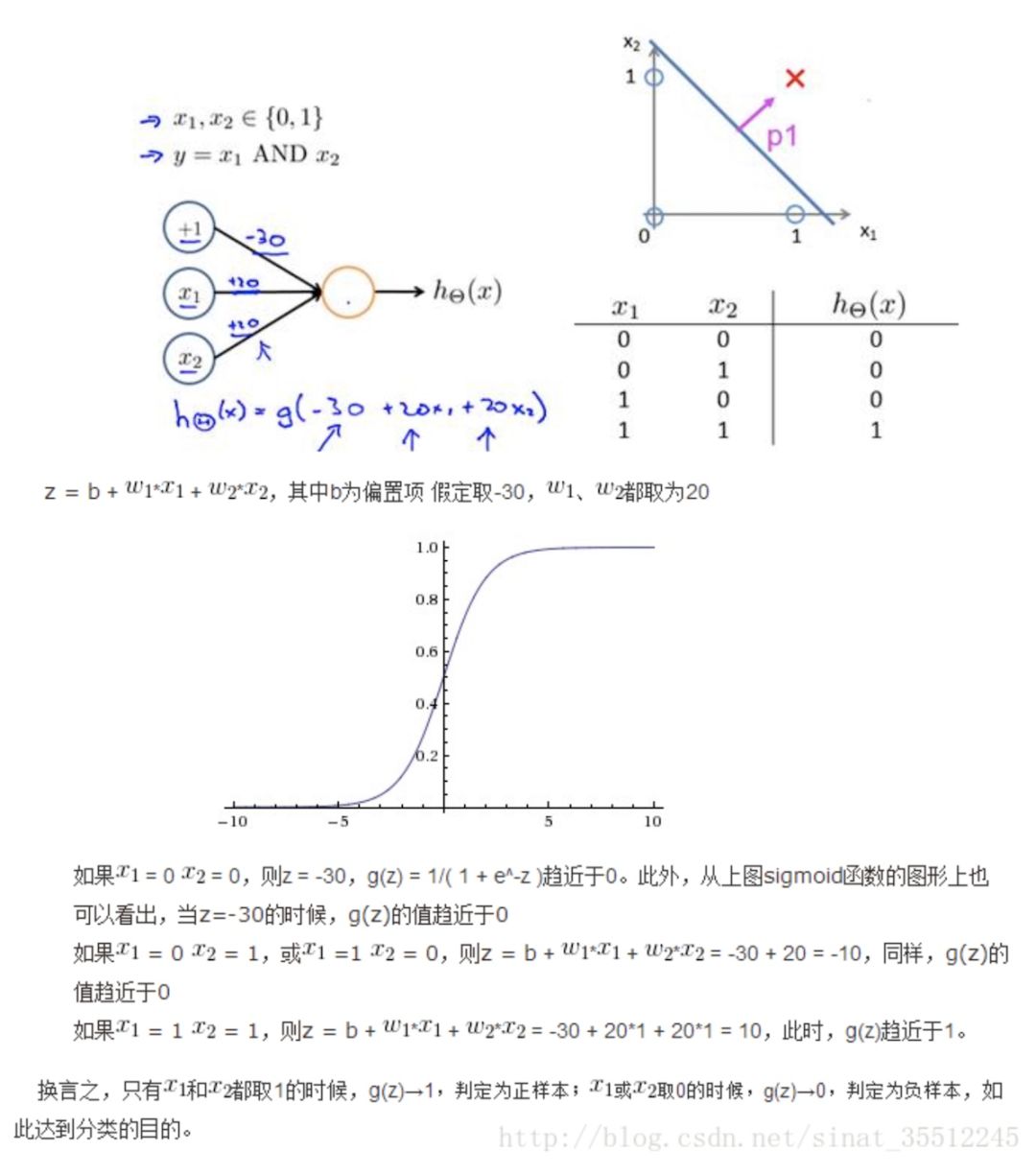
舉個例子,如下圖(圖引自Stanford機器學(xué)習(xí)公開課):
46.什么是卷積?
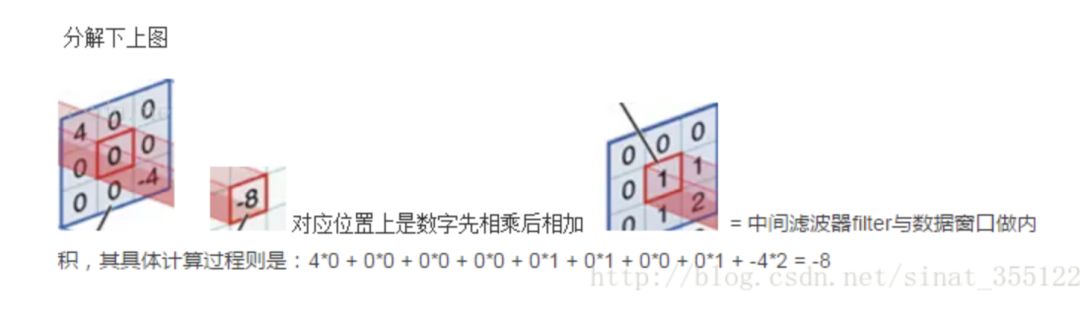
對圖像(不同的數(shù)據(jù)窗口數(shù)據(jù))和濾波矩陣(一組固定的權(quán)重:因為每個神經(jīng)元的多個權(quán)重固定,所以又可以看做一個恒定的濾波器filter)做內(nèi)積(逐個元素相乘再求和)的操作就是所謂的『卷積』操作,也是卷積神經(jīng)網(wǎng)絡(luò)的名字來源。
非嚴(yán)格意義上來講,下圖中紅框框起來的部分便可以理解為一個濾波器,即帶著一組固定權(quán)重的神經(jīng)元。多個濾波器疊加便成了卷積層。
OK,舉個具體的例子。比如下圖中,圖中左邊部分是原始輸入數(shù)據(jù),圖中中間部分是濾波器filter,圖中右邊是輸出的新的二維數(shù)據(jù)。
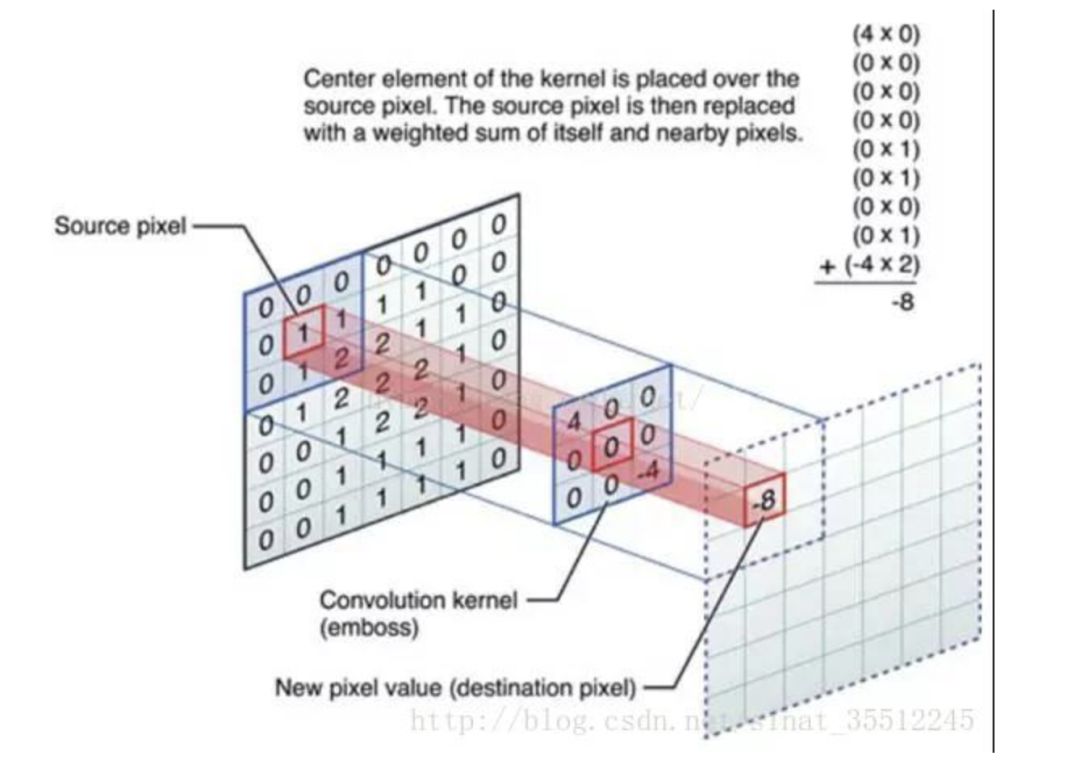
分解下上圖
47.什么是CNN的池化pool層?
池化,簡言之,即取區(qū)域平均或最大,如下圖所示(圖引自cs231n):
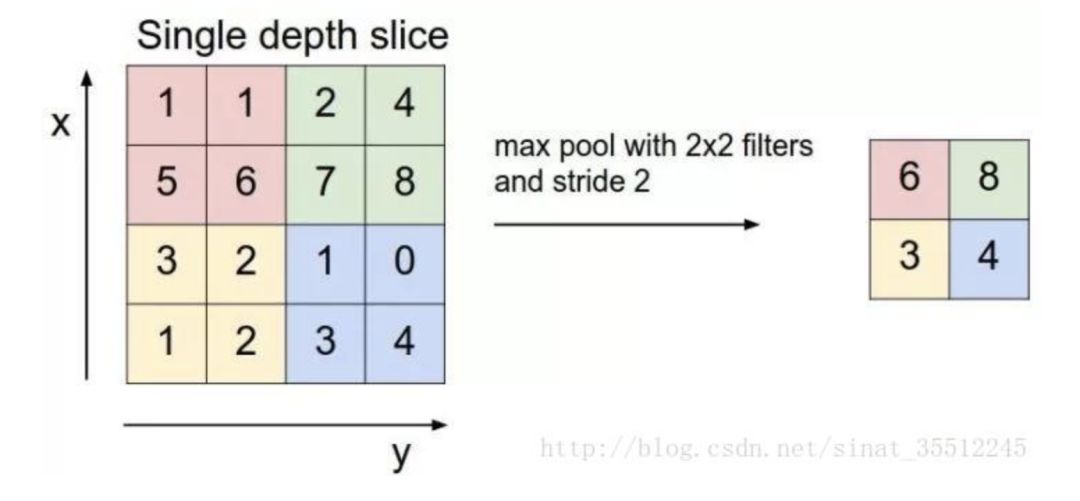
上圖所展示的是取區(qū)域最大,即上圖左邊部分中 左上角2x2的矩陣中6最大,右上角2x2的矩陣中8最大,左下角2x2的矩陣中3最大,右下角2x2的矩陣中4最大,所以得到上圖右邊部分的結(jié)果:6 8 3 4。很簡單不是?
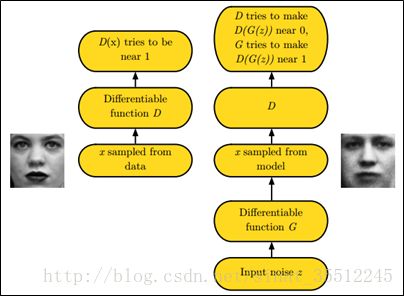
48.簡述下什么是生成對抗網(wǎng)絡(luò)。
GAN之所以是對抗的,是因為GAN的內(nèi)部是競爭關(guān)系,一方叫g(shù)enerator,它的主要工作是生成圖片,并且盡量使得其看上去是來自于訓(xùn)練樣本的。另一方是discriminator,其目標(biāo)是判斷輸入圖片是否屬于真實訓(xùn)練樣本。
更直白的講,將generator想象成假幣制造商,而discriminator是警察。generator目的是盡可能把假幣造的跟真的一樣,從而能夠騙過discriminator,即生成樣本并使它看上去好像來自于真實訓(xùn)練樣本一樣。

如下圖中的左右兩個場景:
更多請參見此課程:生成對抗網(wǎng)絡(luò)
https://www.julyedu.com/course/getDetail/83
49.學(xué)梵高作畫的原理是啥?
這里有篇如何做梵高風(fēng)格畫的實驗教程 教你從頭到尾利用DL學(xué)梵高作畫:GTX 1070 cuda 8.0 tensorflow gpu版,至于其原理請看這個視頻:NeuralStyle藝術(shù)化圖片(學(xué)梵高作畫背后的原理)。
http://blog.csdn.net/v_july_v/article/details/52658965
http://www.julyedu.com/video/play/42/523
50.現(xiàn)在有 a 到 z 26 個元素, 編寫程序打印 a 到 z 中任取 3 個元素的組合(比如 打印 a b c ,d y z等)。
一道百度機器學(xué)習(xí)工程師職位的面試題
http://blog.csdn.net/lvonve/article/details/53320680
51.哪些機器學(xué)習(xí)算法不需要做歸一化處理?
概率模型不需要歸一化,因為它們不關(guān)心變量的值,而是關(guān)心變量的分布和變量之間的條件概率,如決策樹、RF。而像Adaboost、GBDT、XGBoost、SVM、LR、KNN、KMeans之類的最優(yōu)化問題就需要歸一化。
52.說說梯度下降法。
@LeftNotEasy
機器學(xué)習(xí)中的數(shù)學(xué)(1)-回歸(regression)、梯度下降(gradient descent)
http://www.cnblogs.com/LeftNotEasy/archive/2010/12/05/mathmatic_in_machine_learning_1_regression_and_gradient_descent.html
53.梯度下降法找到的一定是下降最快的方向么?
梯度下降法并不是下降最快的方向,它只是目標(biāo)函數(shù)在當(dāng)前的點的切平面(當(dāng)然高維問題不能叫平面)上下降最快的方向。在Practical Implementation中,牛頓方向(考慮海森矩陣)才一般被認為是下降最快的方向,可以達到Superlinear的收斂速度。梯度下降類的算法的收斂速度一般是Linear甚至Sublinear的(在某些帶復(fù)雜約束的問題)。
知識點鏈接:一文清晰講解機器學(xué)習(xí)中梯度下降算法(包括其變式算法)
http://blog.csdn.net/wemedia/details.html?id=45460
54.牛頓法和梯度下降法有什么不同?
@wtq1993
知識點鏈接:機器學(xué)習(xí)中常見的最優(yōu)化算法
http://blog.csdn.net/wtq1993/article/details/51607040
55.什么是擬牛頓法(Quasi-Newton Methods)?
@wtq1993
機器學(xué)習(xí)中常見的最優(yōu)化算法
56.請說說隨機梯度下降法的問題和挑戰(zhàn)?



57.說說共軛梯度法?
@wtq1993
機器學(xué)習(xí)中常見的最優(yōu)化算法
http://blog.csdn.net/wtq1993/article/details/51607040
58.對所有優(yōu)化問題來說, 有沒有可能找到比現(xiàn)在已知算法更好的算法?
答案鏈接
https://www.zhihu.com/question/41233373/answer/145404190
59、什么最小二乘法?
我們口頭中經(jīng)常說:一般來說,平均來說。如平均來說,不吸煙的健康優(yōu)于吸煙者,之所以要加“平均”二字,是因為凡事皆有例外,總存在某個特別的人他吸煙但由于經(jīng)常鍛煉所以他的健康狀況可能會優(yōu)于他身邊不吸煙的朋友。而最小二乘法的一個最簡單的例子便是算術(shù)平均。
最小二乘法(又稱最小平方法)是一種數(shù)學(xué)優(yōu)化技術(shù)。它通過最小化誤差的平方和尋找數(shù)據(jù)的最佳函數(shù)匹配。利用最小二乘法可以簡便地求得未知的數(shù)據(jù),并使得這些求得的數(shù)據(jù)與實際數(shù)據(jù)之間誤差的平方和為最小。用函數(shù)表示為:

由于算術(shù)平均是一個歷經(jīng)考驗的方法,而以上的推理說明,算術(shù)平均是最小二乘的一個特例,所以從另一個角度說明了最小二乘方法的優(yōu)良性,使我們對最小二乘法更加有信心。
最小二乘法發(fā)表之后很快得到了大家的認可接受,并迅速的在數(shù)據(jù)分析實踐中被廣泛使用。不過歷史上又有人把最小二乘法的發(fā)明歸功于高斯,這又是怎么一回事呢。高斯在1809年也發(fā)表了最小二乘法,并且聲稱自己已經(jīng)使用這個方法多年。高斯發(fā)明了小行星定位的數(shù)學(xué)方法,并在數(shù)據(jù)分析中使用最小二乘方法進行計算,準(zhǔn)確的預(yù)測了谷神星的位置。
對了,最小二乘法跟SVM有什么聯(lián)系呢?請參見支持向量機通俗導(dǎo)論(理解SVM的三層境界)。
http://blog.csdn.net/v_july_v/article/details/7624837
60、看你T恤上印著:人生苦短,我用Python,你可否說說Python到底是什么樣的語言?你可以比較其他技術(shù)或者語言來回答你的問題。
15個重要Python面試題 測測你適不適合做Python?
http://nooverfit.com/wp/15%E4%B8%AA%E9%87%8D%E8%A6%81python%E9%9D%A2%E8%AF%95%E9%A2%98-%E6%B5%8B%E6%B5%8B%E4%BD%A0%E9%80%82%E4%B8%8D%E9%80%82%E5%90%88%E5%81%9Apython%EF%BC%9F/
61.Python是如何進行內(nèi)存管理的?
2017 Python最新面試題及答案16道題
http://www.cnblogs.com/tom-gao/p/6645859.html
62.請寫出一段Python代碼實現(xiàn)刪除一個list里面的重復(fù)元素。
1、使用set函數(shù),set(list);
2、使用字典函數(shù):
1a=[1,2,4,2,4,5,6,5,7,8,9,0]2b={}3b=b.fromkeys(a)4c=list(b.keys())5c
63.編程用sort進行排序,然后從最后一個元素開始判斷。
1a=[1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]23a.sort()4last=a[-1]5foriinrange(len(a)-2,-1,-1):6iflast==a[i]:7dela[i]8else:last=a[i]9print(a)
64.Python里面如何生成隨機數(shù)?
@Tom_junsong
random模塊
隨機整數(shù):random.randint(a,b):返回隨機整數(shù)x,a<=x<=b?
random.randrange(start,stop,[,step]):返回一個范圍在(start,stop,step)之間的隨機整數(shù),不包括結(jié)束值。
隨機實數(shù):random.random( ):返回0到1之間的浮點數(shù)
random.uniform(a,b):返回指定范圍內(nèi)的浮點數(shù)。
65.說說常見的損失函數(shù)。
對于給定的輸入X,由f(X)給出相應(yīng)的輸出Y,這個輸出的預(yù)測值f(X)與真實值Y可能一致也可能不一致(要知道,有時損失或誤差是不可避免的),用一個損失函數(shù)來度量預(yù)測錯誤的程度。損失函數(shù)記為L(Y, f(X))。
常用的損失函數(shù)有以下幾種(基本引用自《統(tǒng)計學(xué)習(xí)方法》):
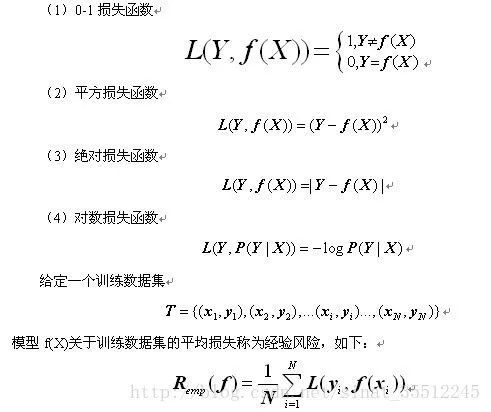
66.簡單介紹下Logistics回歸。
Logistic回歸目的是從特征學(xué)習(xí)出一個0/1分類模型,而這個模型是將特性的線性組合作為自變量,由于自變量的取值范圍是負無窮到正無窮。因此,使用logistic函數(shù)(或稱作sigmoid函數(shù))將自變量映射到(0,1)上,映射后的值被認為是屬于y=1的概率。
假設(shè)函數(shù):
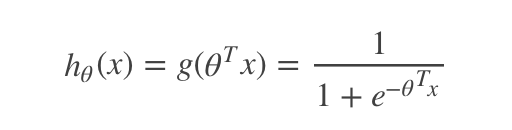
其中x是n維特征向量,函數(shù)g就是Logistic函數(shù)。而:g(z)=11+e?zg(z)=11+e?z的圖像是:
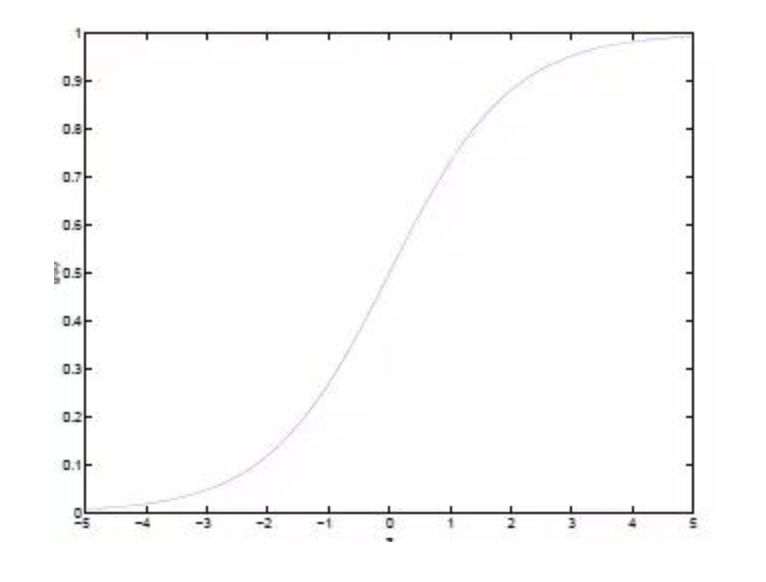
可以看到,將無窮映射到了(0,1)。而假設(shè)函數(shù)就是特征屬于y=1的概率。
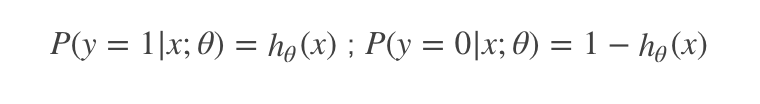

67.看你是搞視覺的,熟悉哪些CV框架,順帶聊聊CV最近五年的發(fā)展史如何?
答案解析https://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2651986617&idx=1&sn=fddebd0f2968d66b7f424d6a435c84af&scene=0#wechat_redirect
68.深度學(xué)習(xí)在視覺領(lǐng)域有何前沿進展?
@元峰
本題解析來源:深度學(xué)習(xí)在計算機視覺領(lǐng)域的前沿進展
https://zhuanlan.zhihu.com/p/24699780
69.HashMap與HashTable區(qū)別?
HashMap與Hashtable的區(qū)別
http://oznyang.iteye.com/blog/30690
70.在分類問題中,我們經(jīng)常會遇到正負樣本數(shù)據(jù)量不等的情況,比如正樣本為10w條數(shù)據(jù),負樣本只有1w條數(shù)據(jù),以下最合適的處理方法是( )
A、將負樣本重復(fù)10次,生成10w樣本量,打亂順序參與分類
B、直接進行分類,可以最大限度利用數(shù)據(jù)
C、從10w正樣本中隨機抽取1w參與分類
D、將負樣本每個權(quán)重設(shè)置為10,正樣本權(quán)重為1,參與訓(xùn)練過程
@管博士:準(zhǔn)確的說,其實選項中的這些方法各有優(yōu)缺點,需要具體問題具體分析,有篇文章對各種方法的優(yōu)缺點進行了分析,講的不錯 感興趣的同學(xué)可以參考一下:
How to handle Imbalanced Classification Problems in machine learning?
https://www.analyticsvidhya.com/blog/2017/03/imbalanced-classification-problem/
71.深度學(xué)習(xí)是當(dāng)前很熱門的機器學(xué)習(xí)算法,在深度學(xué)習(xí)中,涉及到大量的矩陣相乘,現(xiàn)在需要計算三個稠密矩陣A,B,C的乘積ABC,假90設(shè)三個矩陣的尺寸分別為m?n,n?p,p?q,且m
A.(AB)C
B.AC(B)
C.A(BC)
D.所以效率都相同
正確答案:A
@BlackEyes_SGC: m*n*p
72.Nave Bayes是一種特殊的Bayes分類器,特征變量是X,類別標(biāo)簽是C,它的一個假定是:( C )
A.各類別的先驗概率P(C)是相等的
B.以0為均值,sqr(2)/2為標(biāo)準(zhǔn)差的正態(tài)分布
C.特征變量X的各個維度是類別條件獨立隨機變量
D.P(X|C)是高斯分布
正確答案:C
@BlackEyes_SGC:樸素貝葉斯的條件就是每個變量相互獨立。
73.關(guān)于支持向量機SVM,下列說法錯誤的是(C)
A.L2正則項,作用是最大化分類間隔,使得分類器擁有更強的泛化能力
B.Hinge 損失函數(shù),作用是最小化經(jīng)驗分類錯誤
C.分類間隔為1||w||1||w||,||w||代表向量的模
D.當(dāng)參數(shù)C越小時,分類間隔越大,分類錯誤越多,趨于欠學(xué)習(xí)
正確答案:C
@BlackEyes_SGC:
A正確。考慮加入正則化項的原因:想象一個完美的數(shù)據(jù)集,y>1是正類,y<-1是負類,決策面y=0,加入一個y=-30的正類噪聲樣本,那么決策面將會變“歪”很多,分類間隔變小,泛化能力減小。加入正則項之后,對噪聲樣本的容錯能力增強,前面提到的例子里面,決策面就會沒那么“歪”了,使得分類間隔變大,提高了泛化能力。?
B正確。
C錯誤。間隔應(yīng)該是2||w||2||w||才對,后半句應(yīng)該沒錯,向量的模通常指的就是其二范數(shù)。
D正確。考慮軟間隔的時候,C對優(yōu)化問題的影響就在于把a的范圍從[0,+inf]限制到了[0,C]。C越小,那么a就會越小,目標(biāo)函數(shù)拉格朗日函數(shù)導(dǎo)數(shù)為0可以求出w=∑iai?yi?xiw=∑iai?yi?xi,a變小使得w變小,因此間隔2||w||2||w||變大
74.在HMM中,如果已知觀察序列和產(chǎn)生觀察序列的狀態(tài)序列,那么可用以下哪種方法直接進行參數(shù)估計( D )
A.EM算法
B.維特比算法
C.前向后向算法
D.極大似然估計
正確答案:D
@BlackEyes_SGC:
EM算法: 只有觀測序列,無狀態(tài)序列時來學(xué)習(xí)模型參數(shù),即Baum-Welch算法
維特比算法: 用動態(tài)規(guī)劃解決HMM的預(yù)測問題,不是參數(shù)估計
前向后向算法:用來算概率
極大似然估計:即觀測序列和相應(yīng)的狀態(tài)序列都存在時的監(jiān)督學(xué)習(xí)算法,用來估計參數(shù)
注意的是在給定觀測序列和對應(yīng)的狀態(tài)序列估計模型參數(shù),可以利用極大似然發(fā)估計。如果給定觀測序列,沒有對應(yīng)的狀態(tài)序列,才用EM,將狀態(tài)序列看不不可測的隱數(shù)據(jù)。
75.假定某同學(xué)使用Naive Bayesian(NB)分類模型時,不小心將訓(xùn)練數(shù)據(jù)的兩個維度搞重復(fù)了,那么關(guān)于NB的說法中正確的是:(BD)
A.這個被重復(fù)的特征在模型中的決定作用會被加強
B.模型效果相比無重復(fù)特征的情況下精確度會降低
C.如果所有特征都被重復(fù)一遍,得到的模型預(yù)測結(jié)果相對于不重復(fù)的情況下的模型預(yù)測結(jié)果一樣。
D.當(dāng)兩列特征高度相關(guān)時,無法用兩列特征相同時所得到的結(jié)論來分析問題
E.NB可以用來做最小二乘回歸
F.以上說法都不正確
正確答案:BD
@BlackEyes_SGC:NB的核心在于它假設(shè)向量的所有分量之間是獨立的。在貝葉斯理論系統(tǒng)中,都有一個重要的條件獨立性假設(shè):假設(shè)所有特征之間相互獨立,這樣才能將聯(lián)合概率拆分。
76.以下哪些方法不可以直接來對文本分類?(A)
A、Kmeans
B、決策樹
C、支持向量機
D、KNN
正確答案: A分類不同于聚類。
@BlackEyes_SGC:A:Kmeans是聚類方法,典型的無監(jiān)督學(xué)習(xí)方法。分類是監(jiān)督學(xué)習(xí)方法,BCD都是常見的分類方法。
77.已知一組數(shù)據(jù)的協(xié)方差矩陣P,下面關(guān)于主分量說法錯誤的是( C )
A、主分量分析的最佳準(zhǔn)則是對一組數(shù)據(jù)進行按一組正交基分解, 在只取相同數(shù)量分量的條件下,以均方誤差計算截尾誤差最小
B、在經(jīng)主分量分解后,協(xié)方差矩陣成為對角矩陣
C、主分量分析就是K-L變換
D、主分量是通過求協(xié)方差矩陣的特征值得到
正確答案: C
@BlackEyes_SGC:K-L變換與PCA變換是不同的概念,PCA的變換矩陣是協(xié)方差矩陣,K-L變換的變換矩陣可以有很多種(二階矩陣、協(xié)方差矩陣、總類內(nèi)離散度矩陣等等)。當(dāng)K-L變換矩陣為協(xié)方差矩陣時,等同于PCA。
78.Kmeans的復(fù)雜度?
時間復(fù)雜度:O(tKmn),其中,t為迭代次數(shù),K為簇的數(shù)目,m為記錄數(shù),n為維數(shù)空間復(fù)雜度:O((m+K)n),其中,K為簇的數(shù)目,m為記錄數(shù),n為維數(shù)。
具體參考:機器學(xué)習(xí)之深入理解K-means、與KNN算法區(qū)別及其代碼實現(xiàn)
http://blog.csdn.net/sinat_35512245/article/details/55051306
79.關(guān)于Logit 回歸和SVM 不正確的是(A)
A. Logit回歸本質(zhì)上是一種根據(jù)樣本對權(quán)值進行極大似然估計的方法,而后驗概率正比于先驗概率和似然函數(shù)的乘積。logit僅僅是最大化似然函數(shù),并沒有最大化后驗概率,更談不上最小化后驗概率。A錯誤
B. Logit回歸的輸出就是樣本屬于正類別的幾率,可以計算出概率,正確
C. SVM的目標(biāo)是找到使得訓(xùn)練數(shù)據(jù)盡可能分開且分類間隔最大的超平面,應(yīng)該屬于結(jié)構(gòu)風(fēng)險最小化。
D. SVM可以通過正則化系數(shù)控制模型的復(fù)雜度,避免過擬合。
@BlackEyes_SGC:Logit回歸目標(biāo)函數(shù)是最小化后驗概率,Logit回歸可以用于預(yù)測事件發(fā)生概率的大小,SVM目標(biāo)是結(jié)構(gòu)風(fēng)險最小化,SVM可以有效避免模型過擬合。
80.輸入圖片大小為200×200,依次經(jīng)過一層卷積(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一層卷積(kernel size 3×3,padding 1,stride 1)之后,輸出特征圖大小為:()
正確答案:97
@BlackEyes_SGC:計算尺寸不被整除只在GoogLeNet中遇到過。卷積向下取整,池化向上取整。
本題 (200-5+2*1)/2+1 為99.5,取99
(99-3)/1+1 為97
(97-3+2*1)/1+1 為97
研究過網(wǎng)絡(luò)的話看到stride為1的時候,當(dāng)kernel為 3 padding為1或者kernel為5 padding為2 一看就是卷積前后尺寸不變。計算GoogLeNet全過程的尺寸也一樣。
81.影響聚類算法結(jié)果的主要因素有(BCD )
A.已知類別的樣本質(zhì)量;
B.分類準(zhǔn)則;
C.特征選取;
D.模式相似性測度
82.模式識別中,馬式距離較之于歐式距離的優(yōu)點是(CD)
A. 平移不變性;
B. 旋轉(zhuǎn)不變性;
C. 尺度不變性;
D. 考慮了模式的分布
83.影響基本K-均值算法的主要因素有(ABD)
A. 樣本輸入順序;
B. 模式相似性測度;
C. 聚類準(zhǔn)則;
D. 初始類中心的選取
84.在統(tǒng)計模式分類問題中,當(dāng)先驗概率未知時,可以使用(BD)
A. 最小損失準(zhǔn)則;
B. 最小最大損失準(zhǔn)則;
C. 最小誤判概率準(zhǔn)則;
D. N-P判決
85.如果以特征向量的相關(guān)系數(shù)作為模式相似性測度,則影響聚類算法結(jié)果的主要因素有(BC)
A. 已知類別樣本質(zhì)量;
B. 分類準(zhǔn)則;
C. 特征選取;
D. 量綱
86.歐式距離具有(AB );馬式距離具有(ABCD )。
A. 平移不變性;
B. 旋轉(zhuǎn)不變性;
C. 尺度縮放不變性;
D. 不受量綱影響的特性
87.你有哪些Deep Learning(RNN,CNN)調(diào)參的經(jīng)驗?
答案解析,來自知乎
https://www.zhihu.com/question/41631631
88.簡單說說RNN的原理。
我們升學(xué)到高三準(zhǔn)備高考時,此時的知識是由高二及高二之前所學(xué)的知識加上高三所學(xué)的知識合成得來,即我們的知識是由前序鋪墊,是有記憶的,好比當(dāng)電影字幕上出現(xiàn):“我是”時,你會很自然的聯(lián)想到:“我是中國人”。
89.什么是RNN?
@一只鳥的天空,本題解析來源:
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN, Recurrent Neural Networks)介紹
http://blog.csdn.net/heyongluoyao8/article/details/48636251
90.RNN是怎么從單層網(wǎng)絡(luò)一步一步構(gòu)造的的?
@何之源,本題解析來源:
完全圖解RNN、RNN變體、Seq2Seq、Attention機制
https://zhuanlan.zhihu.com/p/28054589
101.深度學(xué)習(xí)(CNN RNN Attention)解決大規(guī)模文本分類問題。
用深度學(xué)習(xí)(CNN RNN Attention)解決大規(guī)模文本分類問題 - 綜述和實踐
https://zhuanlan.zhihu.com/p/25928551
102.如何解決RNN梯度爆炸和彌散的問題的?
深度學(xué)習(xí)與自然語言處理(7)_斯坦福cs224d 語言模型,RNN,LSTM與GRU
http://blog.csdn.net/han_xiaoyang/article/details/51932536
103.如何提高深度學(xué)習(xí)的性能?
機器學(xué)習(xí)系列(10)_如何提高深度學(xué)習(xí)(和機器學(xué)習(xí))的性能
http://blog.csdn.net/han_xiaoyang/article/details/52654879
104.RNN、LSTM、GRU區(qū)別?
@我愛大泡泡,本題解析來源:
面試筆試整理3:深度學(xué)習(xí)機器學(xué)習(xí)面試問題準(zhǔn)備(必會)
http://blog.csdn.net/woaidapaopao/article/details/77806273
105.當(dāng)機器學(xué)習(xí)性能遭遇瓶頸時,你會如何優(yōu)化的?
可以從這4個方面進行嘗試:基于數(shù)據(jù)、借助算法、用算法調(diào)參、借助模型融合。當(dāng)然能談多細多深入就看你的經(jīng)驗心得了。
這里有一份參考清單:機器學(xué)習(xí)系列(20)_機器學(xué)習(xí)性能改善備忘單
http://blog.csdn.net/han_xiaoyang/article/details/53453145
106.做過什么樣的機器學(xué)習(xí)項目?比如如何從零構(gòu)建一個推薦系統(tǒng)?
推薦系統(tǒng)的公開課http://www.julyedu.com/video/play/18/148,另,再推薦一個課程:機器學(xué)習(xí)項目班 [10次純項目講解,100%純實戰(zhàn)](https://www.julyedu.com/course/getDetail/48)。
107.什么樣的資料集不適合用深度學(xué)習(xí)?
@抽象猴,來源:
知乎解答
https://www.zhihu.com/question/41233373
108.廣義線性模型是怎被應(yīng)用在深度學(xué)習(xí)中?
@許韓,來源:
知乎解答
https://huangqinjian.blog.csdn.net/article/details/%E5%A6%82%E6%9E%9C%E4%BD%A0%E6%98%AF%E9%9D%A2%E8%AF%95%E5%AE%98%EF%BC%8C%E4%BD%A0%E6%80%8E%E4%B9%88%E5%8E%BB%E5%88%A4%E6%96%AD%E4%B8%80%E4%B8%AA%E9%9D%A2%E8%AF%95%E8%80%85%E7%9A%84%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%B0%B4%E5%B9%B3%EF%BC%9F%20-%20%E8%AE%B8%E9%9F%A9%E7%9A%84%E5%9B%9E%E7%AD%94%20-%20%E7%9F%A5%E4%B9%8E%20https://www.zhihu.com/question/41233373/answer/145404190
109.準(zhǔn)備機器學(xué)習(xí)面試應(yīng)該了解哪些理論知識?
知乎解答
https://www.zhihu.com/question/62482926
110.標(biāo)準(zhǔn)化與歸一化的區(qū)別?
簡單來說,標(biāo)準(zhǔn)化是依照特征矩陣的列處理數(shù)據(jù),其通過求z-score的方法,將樣本的特征值轉(zhuǎn)換到同一量綱下。歸一化是依照特征矩陣的行處理數(shù)據(jù),其目的在于樣本向量在點乘運算或其他核函數(shù)計算相似性時,擁有統(tǒng)一的標(biāo)準(zhǔn),也就是說都轉(zhuǎn)化為“單位向量”。規(guī)則為L2的歸一化公式如下:
特征向量的缺失值處理:
1.缺失值較多.直接將該特征舍棄掉,否則可能反倒會帶入較大的noise,對結(jié)果造成不良影響。
2.缺失值較少,其余的特征缺失值都在10%以內(nèi),我們可以采取很多的方式來處理:
1) 把NaN直接作為一個特征,假設(shè)用0表示;
2) 用均值填充;
3) 用隨機森林等算法預(yù)測填充
111.隨機森林如何處理缺失值。
方法一(na.roughfix)簡單粗暴,對于訓(xùn)練集,同一個class下的數(shù)據(jù),如果是分類變量缺失,用眾數(shù)補上,如果是連續(xù)型變量缺失,用中位數(shù)補。
方法二(rfImpute)這個方法計算量大,至于比方法一好壞?不好判斷。先用na.roughfix補上缺失值,然后構(gòu)建森林并計算proximity matrix,再回頭看缺失值,如果是分類變量,則用沒有陣進行加權(quán)平均的方法補缺失值。然后迭代4-6次,這個補缺失值的思想和KNN有些類似1缺失的觀測實例的proximity中的權(quán)重進行投票。如果是連續(xù)型變量,則用proximity矩2。
112.隨機森林如何評估特征重要性。
衡量變量重要性的方法有兩種,Decrease GINI 和 Decrease Accuracy:
1) Decrease GINI: 對于回歸問題,直接使用argmax(VarVarLeftVarRight)作為評判標(biāo)準(zhǔn),即當(dāng)前節(jié)點訓(xùn)練集的方差Var減去左節(jié)點的方差VarLeft和右節(jié)點的方差VarRight。
2) Decrease Accuracy:對于一棵樹Tb(x),我們用OOB樣本可以得到測試誤差1;然后隨機改變OOB樣本的第j列:保持其他列不變,對第j列進行隨機的上下置換,得到誤差2。至此,我們可以用誤差1-誤差2來刻畫變量j的重要性。基本思想就是,如果一個變量j足夠重要,那么改變它會極大的增加測試誤差;反之,如果改變它測試誤差沒有增大,則說明該變量不是那么的重要。
113.優(yōu)化Kmeans。
使用Kd樹或者Ball Tree
將所有的觀測實例構(gòu)建成一顆kd樹,之前每個聚類中心都是需要和每個觀測點做依次距離計算,現(xiàn)在這些聚類中心根據(jù)kd樹只需要計算附近的一個局部區(qū)域即可。
114.KMeans初始類簇中心點的選取。
K-means++算法選擇初始seeds的基本思想就是:初始的聚類中心之間的相互距離要盡可能的遠。
1.從輸入的數(shù)據(jù)點集合中隨機選擇一個點作為第一個聚類中心
2.對于數(shù)據(jù)集中的每一個點x,計算它與最近聚類中心(指已選擇的聚類中心)的距離D(x)
3.選擇一個新的數(shù)據(jù)點作為新的聚類中心,選擇的原則是:D(x)較大的點,被選取作為聚類中心的概率較大
4.重復(fù)2和3直到k個聚類中心被選出來
5.利用這k個初始的聚類中心來運行標(biāo)準(zhǔn)的k-means算法
115.解釋對偶的概念。
一個優(yōu)化問題可以從兩個角度進行考察,一個是primal 問題,一個是dual 問題,就是對偶問題,一般情況下對偶問題給出主問題最優(yōu)值的下界,在強對偶性成立的情況下由對偶問題可以得到主問題的最優(yōu)下界,對偶問題是凸優(yōu)化問題,可以進行較好的求解,SVM中就是將Primal問題轉(zhuǎn)換為dual問題進行求解,從而進一步引入核函數(shù)的思想。
116.如何進行特征選擇?
特征選擇是一個重要的數(shù)據(jù)預(yù)處理過程,主要有兩個原因:一是減少特征數(shù)量、降維,使模型泛化能力更強,減少過擬合;二是增強對特征和特征值之間的理解。
常見的特征選擇方式:
1.去除方差較小的特征。
2.正則化。1正則化能夠生成稀疏的模型。L2正則化的表現(xiàn)更加穩(wěn)定,由于有用的特征往往對應(yīng)系數(shù)非零。
3.隨機森林,對于分類問題,通常采用基尼不純度或者信息增益,對于回歸問題,通常采用的是方差或者最小二乘擬合。一般不需要feature engineering、調(diào)參等繁瑣的步驟。它的兩個主要問題,1是重要的特征有可能得分很低(關(guān)聯(lián)特征問題),2是這種方法對特征變量類別多的特征越有利(偏向問題)。
4.穩(wěn)定性選擇。是一種基于二次抽樣和選擇算法相結(jié)合較新的方法,選擇算法可以是回歸、SVM或其他類似的方法。它的主要思想是在不同的數(shù)據(jù)子集和特征子集上運行特征選擇算法,不斷的重復(fù),最終匯總特征選擇結(jié)果,比如可以統(tǒng)計某個特征被認為是重要特征的頻率(被選為重要特征的次數(shù)除以它所在的子集被測試的次數(shù))。理想情況下,重要特征的得分會接近100%。稍微弱一點的特征得分會是非0的數(shù),而最無用的特征得分將會接近于0。
117.數(shù)據(jù)預(yù)處理。
1.缺失值,填充缺失值fillna:
i. 離散:None,
ii. 連續(xù):均值。
iii. 缺失值太多,則直接去除該列
2.連續(xù)值:離散化。有的模型(如決策樹)需要離散值
3.對定量特征二值化。核心在于設(shè)定一個閾值,大于閾值的賦值為1,小于等于閾值的賦值為0。如圖像操作
4.皮爾遜相關(guān)系數(shù),去除高度相關(guān)的列
118.簡單說說特征工程。
119.你知道有哪些數(shù)據(jù)處理和特征工程的處理?
120.請對比下Sigmoid、Tanh、ReLu這三個激活函數(shù)?
121.Sigmoid、Tanh、ReLu這三個激活函數(shù)有什么缺點或不足,有沒改進的激活函數(shù)?
@我愛大泡泡,來源:
面試筆試整理3:深度學(xué)習(xí)機器學(xué)習(xí)面試問題準(zhǔn)備(必會)
http://blog.csdn.net/woaidapaopao/article/details/77806273
122.怎么理解決策樹、xgboost能處理缺失值?而有的模型(svm)對缺失值比較敏感?
知乎解答
https://www.zhihu.com/question/58230411
123.為什么引入非線性激勵函數(shù)?
@Begin Again,來源:
知乎解答
https://www.zhihu.com/question/29021768
如果不用激勵函數(shù)(其實相當(dāng)于激勵函數(shù)是f(x) = x),在這種情況下你每一層輸出都是上層輸入的線性函數(shù),很容易驗證,無論你神經(jīng)網(wǎng)絡(luò)有多少層,輸出都是輸入的線性組合,與沒有隱藏層效果相當(dāng),這種情況就是最原始的感知機(Perceptron)了。
正因為上面的原因,我們決定引入非線性函數(shù)作為激勵函數(shù),這樣深層神經(jīng)網(wǎng)絡(luò)就有意義了(不再是輸入的線性組合,可以逼近任意函數(shù))。最早的想法是Sigmoid函數(shù)或者Tanh函數(shù),輸出有界,很容易充當(dāng)下一層輸入(以及一些人的生物解釋)。
124.請問人工神經(jīng)網(wǎng)絡(luò)中為什么ReLu要好過于Tanh和Sigmoid function?
@Begin Again,來源:
知乎解答
https://www.zhihu.com/question/29021768
125.為什么LSTM模型中既存在Sigmoid又存在Tanh兩種激活函數(shù)?
本題解析來源:知乎解答
https://www.zhihu.com/question/46197687
@beanfrog:二者目的不一樣:sigmoid 用在了各種gate上,產(chǎn)生0~1之間的值,這個一般只有sigmoid最直接了。tanh 用在了狀態(tài)和輸出上,是對數(shù)據(jù)的處理,這個用其他激活函數(shù)或許也可以。
@hhhh:另可參見A Critical Review of Recurrent Neural Networks for Sequence Learning的section4.1,說了那兩個tanh都可以替換成別的。
126.衡量分類器的好壞。
@我愛大泡泡,來源:
答案解析
http://blog.csdn.net/woaidapaopao/article/details/77806273
這里首先要知道TP、FN(真的判成假的)、FP(假的判成真)、TN四種(可以畫一個表格)。
幾種常用的指標(biāo):
精度precision = TP/(TP+FP) = TP/~P (~p為預(yù)測為真的數(shù)量)
召回率 recall = TP/(TP+FN) = TP/ P
F1值: 2/F1 = 1/recall + 1/precision
ROC曲線:ROC空間是一個以偽陽性率(FPR,false positive rate)為X軸,真陽性率(TPR, true positive rate)為Y軸的二維坐標(biāo)系所代表的平面。其中真陽率TPR = TP / P = recall, 偽陽率FPR = FP / N
127.機器學(xué)習(xí)和統(tǒng)計里面的auc的物理意義是什么?
詳情參見機器學(xué)習(xí)和統(tǒng)計里面的auc怎么理解?
https://www.zhihu.com/question/39840928
128.觀察增益gain, alpha和gamma越大,增益越小?
@AntZ:XGBoost尋找分割點的標(biāo)準(zhǔn)是最大化gain. 考慮傳統(tǒng)的枚舉每個特征的所有可能分割點的貪心法效率太低,XGBoost實現(xiàn)了一種近似的算法。大致的思想是根據(jù)百分位法列舉幾個可能成為分割點的候選者,然后從候選者中計算Gain按最大值找出最佳的分割點。它的計算公式分為四項, 可以由正則化項參數(shù)調(diào)整(lamda為葉子權(quán)重平方和的系數(shù), gama為葉子數(shù)量):
第一項是假設(shè)分割的左孩子的權(quán)重分?jǐn)?shù), 第二項為右孩子, 第三項為不分割總體分?jǐn)?shù), 最后一項為引入一個節(jié)點的復(fù)雜度損失。
由公式可知, gama越大gain越小, lamda越大, gain可能小也可能大。
原問題是alpha而不是lambda, 這里paper上沒有提到, XGBoost實現(xiàn)上有這個參數(shù). 上面是我從paper上理解的答案,下面是搜索到的:
如何對XGBoost模型進行參數(shù)調(diào)優(yōu)
https://zhidao.baidu.com/question/2121727290086699747.html?fr=iks&word=xgboost%20lamda&ie=gbk
129.什么造成梯度消失問題? 推導(dǎo)一下。
@許韓,來源:
神經(jīng)網(wǎng)絡(luò)的訓(xùn)練中,通過改變神經(jīng)元的權(quán)重,使網(wǎng)絡(luò)的輸出值盡可能逼近標(biāo)簽以降低誤差值,訓(xùn)練普遍使用BP算法,核心思想是,計算出輸出與標(biāo)簽間的損失函數(shù)值,然后計算其相對于每個神經(jīng)元的梯度,進行權(quán)值的迭代。
梯度消失會造成權(quán)值更新緩慢,模型訓(xùn)練難度增加。造成梯度消失的一個原因是,許多激活函數(shù)將輸出值擠壓在很小的區(qū)間內(nèi),在激活函數(shù)兩端較大范圍的定義域內(nèi)梯度為0,造成學(xué)習(xí)停止。
130.什么是梯度消失和梯度爆炸?
@寒小陽,反向傳播中鏈?zhǔn)椒▌t帶來的連乘,如果有數(shù)很小趨于0,結(jié)果就會特別小(梯度消失);如果數(shù)都比較大,可能結(jié)果會很大(梯度爆炸)。
@單車
神經(jīng)網(wǎng)絡(luò)訓(xùn)練中的梯度消失與梯度爆炸
https://zhuanlan.zhihu.com/p/25631496
131.如何解決梯度消失和梯度膨脹?
(1)梯度消失:
根據(jù)鏈?zhǔn)椒▌t,如果每一層神經(jīng)元對上一層的輸出的偏導(dǎo)乘上權(quán)重結(jié)果都小于1的話,那么即使這個結(jié)果是0.99,在經(jīng)過足夠多層傳播之后,誤差對輸入層的偏導(dǎo)會趨于0,可以采用ReLU激活函數(shù)有效的解決梯度消失的情況。
(2)梯度膨脹
根據(jù)鏈?zhǔn)椒▌t,如果每一層神經(jīng)元對上一層的輸出的偏導(dǎo)乘上權(quán)重結(jié)果都大于1的話,在經(jīng)過足夠多層傳播之后,誤差對輸入層的偏導(dǎo)會趨于無窮大,可以通過激活函數(shù)來解決。
132.推導(dǎo)下反向傳播Backpropagation。
@我愛大泡泡,來源:
推導(dǎo)過程
http://blog.csdn.net/woaidapaopao/article/details/77806273
133.SVD和PCA。
PCA的理念是使得數(shù)據(jù)投影后的方差最大,找到這樣一個投影向量,滿足方差最大的條件即可。而經(jīng)過了去除均值的操作之后,就可以用SVD分解來求解這樣一個投影向量,選擇特征值最大的方向。
134.數(shù)據(jù)不平衡問題。
這主要是由于數(shù)據(jù)分布不平衡造成的。解決方法如下:
1)采樣,對小樣本加噪聲采樣,對大樣本進行下采樣
2)進行特殊的加權(quán),如在Adaboost中或者SVM中
3)采用對不平衡數(shù)據(jù)集不敏感的算法
4)改變評價標(biāo)準(zhǔn):用AUC/ROC來進行評價
5)采用Bagging/Boosting/Ensemble等方法
6)考慮數(shù)據(jù)的先驗分布
135.簡述神經(jīng)網(wǎng)絡(luò)的發(fā)展。
MP模型+sgn—->單層感知機(只能線性)+sgn— Minsky 低谷 —>多層感知機+BP+Sigmoid— (低谷) —>深度學(xué)習(xí)+Pretraining+ReLU/Sigmoid
136.深度學(xué)習(xí)常用方法。
@SmallisBig,來源:
機器學(xué)習(xí)崗位面試問題匯總 之 深度學(xué)習(xí)
http://blog.csdn.net/u010496169/article/details/73550487
137.神經(jīng)網(wǎng)絡(luò)模型(Neural Network)因受人類大腦的啟發(fā)而得名。神經(jīng)網(wǎng)絡(luò)由許多神經(jīng)元(Neuron)組成,每個神經(jīng)元接受一個輸入,對輸入進行處理后給出一個輸出。請問下列關(guān)于神經(jīng)元的描述中,哪一項是正確的?(E)
A.每個神經(jīng)元只有一個輸入和一個輸出
B.每個神經(jīng)元有多個輸入和一個輸出
C.每個神經(jīng)元有一個輸入和多個輸出
D.每個神經(jīng)元有多個輸入和多個輸出
E.上述都正確
答案:(E)
每個神經(jīng)元可以有一個或多個輸入,和一個或多個輸出
138.下圖是一個神經(jīng)元的數(shù)學(xué)表示,
139.在一個神經(jīng)網(wǎng)絡(luò)中,知道每一個神經(jīng)元的權(quán)重和偏差是最重要的一步。如果知道了神經(jīng)元準(zhǔn)確的權(quán)重和偏差,便可以近似任何函數(shù),但怎么獲知每個神經(jīng)的權(quán)重和偏移呢?(C)
A. 搜索每個可能的權(quán)重和偏差組合,直到得到最佳值
B. 賦予一個初始值,然后檢查跟最佳值的差值,不斷迭代調(diào)整權(quán)重
C. 隨機賦值,聽天由命
D. 以上都不正確的
答案:(C)
選項C是對梯度下降的描述。
140.梯度下降算法的正確步驟是什么?( D)
1.計算預(yù)測值和真實值之間的誤差
2.重復(fù)迭代,直至得到網(wǎng)絡(luò)權(quán)重的最佳值
3.把輸入傳入網(wǎng)絡(luò),得到輸出值
4.用隨機值初始化權(quán)重和偏差
5.對每一個產(chǎn)生誤差的神經(jīng)元,調(diào)整相應(yīng)的(權(quán)重)值以減小誤差
A. 1, 2, 3, 4, 5
B. 5, 4, 3, 2, 1
C. 3, 2, 1, 5, 4
D. 4, 3, 1, 5, 2
答案:(D)
141.已知:
- 大腦是有很多個叫做神經(jīng)元的東西構(gòu)成,神經(jīng)網(wǎng)絡(luò)是對大腦的簡單的數(shù)學(xué)表達。
- 每一個神經(jīng)元都有輸入、處理函數(shù)和輸出。
- 神經(jīng)元組合起來形成了網(wǎng)絡(luò),可以擬合任何函數(shù)。
- 為了得到最佳的神經(jīng)網(wǎng)絡(luò),我們用梯度下降方法不斷更新模型
給定上述關(guān)于神經(jīng)網(wǎng)絡(luò)的描述,什么情況下神經(jīng)網(wǎng)絡(luò)模型被稱為深度學(xué)習(xí)模型?
A. 加入更多層,使神經(jīng)網(wǎng)絡(luò)的深度增加
B. 有維度更高的數(shù)據(jù)
C. 當(dāng)這是一個圖形識別的問題時
D. 以上都不正確
答案:(A)
更多層意味著網(wǎng)絡(luò)更深。沒有嚴(yán)格的定義多少層的模型才叫深度模型,目前如果有超過2層的隱層,那么也可以及叫做深度模型。
142.卷積神經(jīng)網(wǎng)絡(luò)可以對一個輸入進行多種變換(旋轉(zhuǎn)、平移、縮放),這個表述正確嗎?
答案:錯誤
把數(shù)據(jù)傳入神經(jīng)網(wǎng)絡(luò)之前需要做一系列數(shù)據(jù)預(yù)處理(也就是旋轉(zhuǎn)、平移、縮放)工作,神經(jīng)網(wǎng)絡(luò)本身不能完成這些變換。
143.下面哪項操作能實現(xiàn)跟神經(jīng)網(wǎng)絡(luò)中Dropout的類似效果?(B)
A. Boosting
B. Bagging
C. Stacking
D. Mapping
答案:B
Dropout可以認為是一種極端的Bagging,每一個模型都在單獨的數(shù)據(jù)上訓(xùn)練,同時,通過和其他模型對應(yīng)參數(shù)的共享,從而實現(xiàn)模型參數(shù)的高度正則化。
144.下列哪一項在神經(jīng)網(wǎng)絡(luò)中引入了非線性?(B)
A. 隨機梯度下降
B. 修正線性單元(ReLU)
C. 卷積函數(shù)
D .以上都不正確
答案:(B)
修正線性單元是非線性的激活函數(shù)。
145.在訓(xùn)練神經(jīng)網(wǎng)絡(luò)時,損失函數(shù)(loss)在最初的幾個epochs時沒有下降,可能的原因是?(A)
A. 學(xué)習(xí)率(learning rate)太低
B. 正則參數(shù)太高
C. 陷入局部最小值
D. 以上都有可能
答案:(A)
146.下列哪項關(guān)于模型能力(model capacity)的描述是正確的?(指神經(jīng)網(wǎng)絡(luò)模型能擬合復(fù)雜函數(shù)的能力)(A)
A. 隱藏層層數(shù)增加,模型能力增加
B. Dropout的比例增加,模型能力增加
C. 學(xué)習(xí)率增加,模型能力增加
D. 都不正確
答案:(A)
147.如果增加多層感知機(Multilayer Perceptron)的隱藏層層數(shù),分類誤差便會減小。這種陳述正確還是錯誤?
答案:錯誤
并不總是正確。過擬合可能會導(dǎo)致錯誤增加。
148.構(gòu)建一個神經(jīng)網(wǎng)絡(luò),將前一層的輸出和它自身作為輸入。下列哪一種架構(gòu)有反饋連接?(A)
A. 循環(huán)神經(jīng)網(wǎng)絡(luò)
B. 卷積神經(jīng)網(wǎng)絡(luò)
C. 限制玻爾茲曼機
D. 都不是
答案:(A)
149.下列哪一項在神經(jīng)網(wǎng)絡(luò)中引入了非線性?在感知機中(Perceptron)的任務(wù)順序是什么?
1.隨機初始化感知機的權(quán)重
2.去到數(shù)據(jù)集的下一批(batch)
3.如果預(yù)測值和輸出不一致,則調(diào)整權(quán)重
4.對一個輸入樣本,計算輸出值
答案:1 - 4 - 3 - 2
150.假設(shè)你需要調(diào)整參數(shù)來最小化代價函數(shù)(cost function),可以使用下列哪項技術(shù)?(D)
A. 窮舉搜索
B. 隨機搜索
C. Bayesian優(yōu)化
D. 以上任意一種
答案:(D)
151.在下面哪種情況下,一階梯度下降不一定正確工作(可能會卡住)?(B)
答案:(B)
這是鞍點(Saddle Point)的梯度下降的經(jīng)典例子。另,本題來源于:題目來源
https://www.analyticsvidhya.com/blog/2017/01/must-know-questions-deep-learning/
152.下圖顯示了訓(xùn)練過的3層卷積神經(jīng)網(wǎng)絡(luò)準(zhǔn)確度,與參數(shù)數(shù)量(特征核的數(shù)量)的關(guān)系。
從圖中趨勢可見,如果增加神經(jīng)網(wǎng)絡(luò)的寬度,精確度會增加到一個特定閾值后,便開始降低。造成這一現(xiàn)象的可能原因是什么?(C)
A. 即使增加卷積核的數(shù)量,只有少部分的核會被用作預(yù)測
B. 當(dāng)卷積核數(shù)量增加時,神經(jīng)網(wǎng)絡(luò)的預(yù)測能力(Power)會降低
C. 當(dāng)卷積核數(shù)量增加時,它們之間的相關(guān)性增加(correlate),導(dǎo)致過擬合
D. 以上都不正確
答案:(C)
如C選項指出的那樣,可能的原因是核之間的相關(guān)性。
153.假設(shè)我們有一個如下圖所示的隱藏層。隱藏層在這個網(wǎng)絡(luò)中起到了一定的降維作用。假如現(xiàn)在我們用另一種維度下降的方法,比如說主成分分析法(PCA)來替代這個隱藏層。那么,這兩者的輸出效果是一樣的嗎?
答案:不同,因為PCA用于相關(guān)特征而隱層用于有預(yù)測能力的特征。
154.神經(jīng)網(wǎng)絡(luò)能組成函數(shù)(y=1xy=1x)嗎?
答案:可以,因為激活函數(shù)可以是互反函數(shù)。
155.下列哪個神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)會發(fā)生權(quán)重共享?(D)
A. 卷積神經(jīng)網(wǎng)絡(luò)
B. 循環(huán)神經(jīng)網(wǎng)絡(luò)
C. 全連接神經(jīng)網(wǎng)絡(luò)
D. 選項A和B
答案:(D)
156.批規(guī)范化(Batch Normalization)的好處都有啥?(A)
A. 在將所有的輸入傳遞到下一層之前對其進行歸一化(更改)
B. 它將權(quán)重的歸一化平均值和標(biāo)準(zhǔn)差
C. 它是一種非常有效的反向傳播(BP)方法
D. 這些均不是
答案:(A)
157.在一個神經(jīng)網(wǎng)絡(luò)中,下面哪種方法可以用來處理過擬合?(D)
A. Dropout
B. 分批歸一化(Batch Normalization)
C. 正則化(regularization)
D. 都可以
答案:(D)
158.如果我們用了一個過大的學(xué)習(xí)速率會發(fā)生什么?(D)
A. 神經(jīng)網(wǎng)絡(luò)會收斂
B. 不好說
C. 都不對
D. 神經(jīng)網(wǎng)絡(luò)不會收斂
答案:(D)
159.下圖所示的網(wǎng)絡(luò)用于訓(xùn)練識別字符H和T,如下所示:
網(wǎng)絡(luò)的輸出是什么?(D)
D.可能是A或B,取決于神經(jīng)網(wǎng)絡(luò)的權(quán)重設(shè)置
答案:(D)
不知道神經(jīng)網(wǎng)絡(luò)的權(quán)重和偏差是什么,則無法判定它將會給出什么樣的輸出。
160.假設(shè)我們已經(jīng)在ImageNet數(shù)據(jù)集(物體識別)上訓(xùn)練好了一個卷積神經(jīng)網(wǎng)絡(luò)。然后給這張卷積神經(jīng)網(wǎng)絡(luò)輸入一張全白的圖片。對于這個輸入的輸出結(jié)果為任何種類的物體的可能性都是一樣的,對嗎?(D)
A. 對的
B. 不知道
C. 看情況
D. 不對
答案:(D)各個神經(jīng)元的反應(yīng)是不一樣的
161.當(dāng)在卷積神經(jīng)網(wǎng)絡(luò)中加入池化層(pooling layer)時,變換的不變性會被保留,是嗎?(C)
A. 不知道
B. 看情況
C. 是
D. 否
答案:(C)使用池化時會導(dǎo)致出現(xiàn)不變性。
162.當(dāng)數(shù)據(jù)過大以至于無法在RAM中同時處理時,哪種梯度下降方法更加有效?(A)
A. 隨機梯度下降法(Stochastic Gradient Descent)
B. 不知道
C. 整批梯度下降法(Full Batch Gradient Descent)
D. 都不是
答案:(A)
163.下圖是一個利用sigmoid函數(shù)作為激活函數(shù)的含四個隱藏層的神經(jīng)網(wǎng)絡(luò)訓(xùn)練的梯度下降圖。這個神經(jīng)網(wǎng)絡(luò)遇到了梯度消失的問題。下面哪個敘述是正確的?(A)
A. 第一隱藏層對應(yīng)D,第二隱藏層對應(yīng)C,第三隱藏層對應(yīng)B,第四隱藏層對應(yīng)A
B. 第一隱藏層對應(yīng)A,第二隱藏層對應(yīng)C,第三隱藏層對應(yīng)B,第四隱藏層對應(yīng)D
C. 第一隱藏層對應(yīng)A,第二隱藏層對應(yīng)B,第三隱藏層對應(yīng)C,第四隱藏層對應(yīng)D
D. 第一隱藏層對應(yīng)B,第二隱藏層對應(yīng)D,第三隱藏層對應(yīng)C,第四隱藏層對應(yīng)A
答案:(A)由于反向傳播算法進入起始層,學(xué)習(xí)能力降低,這就是梯度消失。
164.對于一個分類任務(wù),如果開始時神經(jīng)網(wǎng)絡(luò)的權(quán)重不是隨機賦值的,二是都設(shè)成0,下面哪個敘述是正確的?(C)
A. 其他選項都不對
B. 沒啥問題,神經(jīng)網(wǎng)絡(luò)會正常開始訓(xùn)練
C. 神經(jīng)網(wǎng)絡(luò)可以訓(xùn)練,但是所有的神經(jīng)元最后都會變成識別同樣的東西
D. 神經(jīng)網(wǎng)絡(luò)不會開始訓(xùn)練,因為沒有梯度改變
答案:(C)
165.下圖顯示,當(dāng)開始訓(xùn)練時,誤差一直很高,這是因為神經(jīng)網(wǎng)絡(luò)在往全局最小值前進之前一直被卡在局部最小值里。為了避免這種情況,我們可以采取下面哪種策略?(A)
A. 改變學(xué)習(xí)速率,比如一開始的幾個訓(xùn)練周期不斷更改學(xué)習(xí)速率
B. 一開始將學(xué)習(xí)速率減小10倍,然后用動量項(momentum)
C. 增加參數(shù)數(shù)目,這樣神經(jīng)網(wǎng)絡(luò)就不會卡在局部最優(yōu)處
D. 其他都不對
答案:(A)
選項A可以將陷于局部最小值的神經(jīng)網(wǎng)絡(luò)提取出來。
166.對于一個圖像識別問題(在一張照片里找出一只貓),下面哪種神經(jīng)網(wǎng)絡(luò)可以更好地解決這個問題?(D)
A. 循環(huán)神經(jīng)網(wǎng)絡(luò)
B. 感知機
C. 多層感知機
D. 卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)將更好地適用于圖像相關(guān)問題,因為考慮到圖像附近位置變化的固有性質(zhì)。
答案:(D)
167.假設(shè)在訓(xùn)練中我們突然遇到了一個問題,在幾次循環(huán)之后,誤差瞬間降低。你認為數(shù)據(jù)有問題,于是你畫出了數(shù)據(jù)并且發(fā)現(xiàn)也許是數(shù)據(jù)的偏度過大造成了這個問題。
你打算怎么做來處理這個問題?(D)
A. 對數(shù)據(jù)作歸一化
B. 對數(shù)據(jù)取對數(shù)變化
C. 都不對
D. 對數(shù)據(jù)作主成分分析(PCA)和歸一化
答案:(D)
首先將相關(guān)的數(shù)據(jù)去掉,然后將其置零。
168.下面那個決策邊界是神經(jīng)網(wǎng)絡(luò)生成的?(E)
A. A
B. D
C. C
D. B
E. 以上都有
答案:(E)
169.在下圖中,我們可以觀察到誤差出現(xiàn)了許多小的”漲落”。 這種情況我們應(yīng)該擔(dān)心嗎?(B)
A. 需要,這也許意味著神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)速率存在問題
B. 不需要,只要在訓(xùn)練集和交叉驗證集上有累積的下降就可以了
C. 不知道
D. 不好說
答案:(B)
選項B是正確的,為了減少這些“起伏”,可以嘗試增加批尺寸(batch size)。
170.在選擇神經(jīng)網(wǎng)絡(luò)的深度時,下面那些參數(shù)需要考慮?(C)
1 神經(jīng)網(wǎng)絡(luò)的類型(如MLP,CNN)
2 輸入數(shù)據(jù)
3 計算能力(硬件和軟件能力決定)
4 學(xué)習(xí)速率
5 映射的輸出函數(shù)
A. 1,2,4,5
B. 2,3,4,5
C. 都需要考慮
D. 1,3,4,5
答案:(C)
所有上述因素對于選擇神經(jīng)網(wǎng)絡(luò)模型的深度都是重要的。
171.考慮某個具體問題時,你可能只有少量數(shù)據(jù)來解決這個問題。不過幸運的是你有一個類似問題已經(jīng)預(yù)先訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)。可以用下面哪種方法來利用這個預(yù)先訓(xùn)練好的網(wǎng)絡(luò)?(C)
A. 把除了最后一層外所有的層都凍住,重新訓(xùn)練最后一層
B. 對新數(shù)據(jù)重新訓(xùn)練整個模型
C. 只對最后幾層進行調(diào)參(fine tune)
D. 對每一層模型進行評估,選擇其中的少數(shù)來用
答案:(C)
172.增加卷積核的大小對于改進卷積神經(jīng)網(wǎng)絡(luò)的效果是必要的嗎?
答案:不是,增加核函數(shù)的大小不一定會提高性能。這個問題在很大程度上取決于數(shù)據(jù)集。
173.請簡述神經(jīng)網(wǎng)絡(luò)的發(fā)展史。
@SIY.Z。本題解析來源:
淺析 Hinton 最近提出的 Capsule 計劃
https://zhuanlan.zhihu.com/p/29435406
174.說說spark的性能調(diào)優(yōu)。
https://tech.meituan.com/spark-tuning-basic.html
https://tech.meituan.com/spark-tuning-pro.html
175.機器學(xué)習(xí)中,有哪些特征選擇的工程方法?
數(shù)據(jù)和特征決定了機器學(xué)習(xí)的上限,而模型和算法只是逼近這個上限而已
1.計算每一個特征與響應(yīng)變量的相關(guān)性:工程上常用的手段有計算皮爾遜系數(shù)和互信息系數(shù),皮爾遜系數(shù)只能衡量線性相關(guān)性而互信息系數(shù)能夠很好地度量各種相關(guān)性,但是計算相對復(fù)雜一些,好在很多toolkit里邊都包含了這個工具(如sklearn的MINE),得到相關(guān)性之后就可以排序選擇特征了;
2.構(gòu)建單個特征的模型,通過模型的準(zhǔn)確性為特征排序,借此來選擇特征;
3.通過L1正則項來選擇特征:L1正則方法具有稀疏解的特性,因此天然具備特征選擇的特性,但是要注意,L1沒有選到的特征不代表不重要,原因是兩個具有高相關(guān)性的特征可能只保留了一個,如果要確定哪個特征重要應(yīng)再通過L2正則方法交叉檢驗*;
4.訓(xùn)練能夠?qū)μ卣鞔蚍值念A(yù)選模型:RandomForest和Logistic Regression等都能對模型的特征打分,通過打分獲得相關(guān)性后再訓(xùn)練最終模型;
5.通過特征組合后再來選擇特征:如對用戶id和用戶特征最組合來獲得較大的特征集再來選擇特征,這種做法在推薦系統(tǒng)和廣告系統(tǒng)中比較常見,這也是所謂億級甚至十億級特征的主要來源,原因是用戶數(shù)據(jù)比較稀疏,組合特征能夠同時兼顧全局模型和個性化模型,這個問題有機會可以展開講。
6.通過深度學(xué)習(xí)來進行特征選擇:目前這種手段正在隨著深度學(xué)習(xí)的流行而成為一種手段,尤其是在計算機視覺領(lǐng)域,原因是深度學(xué)習(xí)具有自動學(xué)習(xí)特征的能力,這也是深度學(xué)習(xí)又叫unsupervised feature learning的原因。從深度學(xué)習(xí)模型中選擇某一神經(jīng)層的特征后就可以用來進行最終目標(biāo)模型的訓(xùn)練了。
176.常見的分類算法有哪些?
SVM、神經(jīng)網(wǎng)絡(luò)、隨機森林、邏輯回歸、KNN、貝葉斯
177.常見的監(jiān)督學(xué)習(xí)算法有哪些?
感知機、SVM、人工神經(jīng)網(wǎng)絡(luò)、決策樹、邏輯回歸
178.在其他條件不變的前提下,以下哪種做法容易引起機器學(xué)習(xí)中的過擬合問題(D)
A. 增加訓(xùn)練集量
B. 減少神經(jīng)網(wǎng)絡(luò)隱藏層節(jié)點數(shù)
C. 刪除稀疏的特征
D. SVM算法中使用高斯核/RBF核代替線性核
正確答案:(D)
@劉炫320
一般情況下,越復(fù)雜的系統(tǒng),過擬合的可能性就越高,一般模型相對簡單的話泛化能力會更好一點。
B.一般認為,增加隱層數(shù)可以降低網(wǎng)絡(luò)誤差(也有文獻認為不一定能有效降低),提高精度,但也使網(wǎng)絡(luò)復(fù)雜化,從而增加了網(wǎng)絡(luò)的訓(xùn)練時間和出現(xiàn)“過擬合”的傾向, svm高斯核函數(shù)比線性核函數(shù)模型更復(fù)雜,容易過擬合
D.徑向基(RBF)核函數(shù)/高斯核函數(shù)的說明,這個核函數(shù)可以將原始空間映射到無窮維空間。對于參數(shù) ,如果選的很大,高次特征上的權(quán)重實際上衰減得非常快,實際上(數(shù)值上近似一下)相當(dāng)于一個低維的子空間;反過來,如果選得很小,則可以將任意的數(shù)據(jù)映射為線性可分——當(dāng)然,這并不一定是好事,因為隨之而來的可能是非常嚴(yán)重的過擬合問題。不過,總的來說,通過調(diào)整參數(shù) ,高斯核實際上具有相當(dāng)高的靈活性,也是 使用最廣泛的核函數(shù)之一。
179.下列時間序列模型中,哪一個模型可以較好地擬合波動性的分析和預(yù)測?(D)
A. AR模型
B. MA模型
C. ARMA模型
D. GARCH模型
正確答案:(D)
@劉炫320
R模型是一種線性預(yù)測,即已知N個數(shù)據(jù),可由模型推出第N點前面或后面的數(shù)據(jù)(設(shè)推出P點),所以其本質(zhì)類似于插值。
MA模型(moving average model)滑動平均模型,其中使用趨勢移動平均法建立直線趨勢的預(yù)測模型。
ARMA模型(auto regressive moving average model)自回歸滑動平均模型,模型參量法高分辨率譜分析方法之一。這種方法是研究平穩(wěn)隨機過程有理譜的典型方法。它比AR模型法與MA模型法有較精確的譜估計及較優(yōu)良的譜分辨率性能,但其參數(shù)估算比較繁瑣。
GARCH模型稱為廣義ARCH模型,是ARCH模型的拓展,由Bollerslev(1986)發(fā)展起來的。它是ARCH模型的推廣。GARCH(p,0)模型,相當(dāng)于ARCH(p)模型。GARCH模型是一個專門針對金融數(shù)據(jù)所量體訂做的回歸模型,除去和普通回歸模型相同的之處,GARCH對誤差的方差進行了進一步的建模。特別適用于波動性的分析和預(yù)測,這樣的分析對投資者的決策能起到非常重要的指導(dǎo)性作用,其意義很多時候超過了對數(shù)值本身的分析和預(yù)測。
180.以下哪個屬于線性分類器最佳準(zhǔn)則?(ACD)
A. 感知準(zhǔn)則函數(shù)
B.貝葉斯分類
C.支持向量機
D.Fisher準(zhǔn)則
正確答案:(ACD)
@劉炫320
線性分類器有三大類:感知器準(zhǔn)則函數(shù)、SVM、Fisher準(zhǔn)則,而貝葉斯分類器不是線性分類器。
感知準(zhǔn)則函數(shù) :準(zhǔn)則函數(shù)以使錯分類樣本到分界面距離之和最小為原則。其優(yōu)點是通過錯分類樣本提供的信息對分類器函數(shù)進行修正,這種準(zhǔn)則是人工神經(jīng)元網(wǎng)絡(luò)多層感知器的基礎(chǔ)。
支持向量機 :基本思想是在兩類線性可分條件下,所設(shè)計的分類器界面使兩類之間的間隔為最大,它的基本出發(fā)點是使期望泛化風(fēng)險盡可能小。(使用核函數(shù)可解決非線性問題)
Fisher 準(zhǔn)則 :更廣泛的稱呼是線性判別分析(LDA),將所有樣本投影到一條遠點出發(fā)的直線,使得同類樣本距離盡可能小,不同類樣本距離盡可能大,具體為最大化“廣義瑞利商”。
根據(jù)兩類樣本一般類內(nèi)密集,類間分離的特點,尋找線性分類器最佳的法線向量方向,使兩類樣本在該方向上的投影滿足類內(nèi)盡可能密集,類間盡可能分開。這種度量通過類內(nèi)離散矩陣SwSw和類間離散矩陣SbSb實現(xiàn)。
181.基于二次準(zhǔn)則函數(shù)的H-K算法較之于感知器算法的優(yōu)點是(BD)?
A. 計算量小
B. 可以判別問題是否線性可分
C. 其解完全適用于非線性可分的情況
D. 其解的適應(yīng)性更好
正確答案:(BD)
@劉炫320
HK算法思想很樸實,就是在最小均方誤差準(zhǔn)則下求得權(quán)矢量。
他相對于感知器算法的優(yōu)點在于,他適用于線性可分和非線性可分得情況,對于線性可分的情況,給出最優(yōu)權(quán)矢量,對于非線性可分得情況,能夠判別出來,以退出迭代過程。
182.以下說法中正確的是(BD)?
A. SVM對噪聲(如來自其他分布的噪聲樣本)魯棒
B. 在AdaBoost算法中,所有被分錯的樣本的權(quán)重更新比例相同
C. Boosting和Bagging都是組合多個分類器投票的方法,二者都是根據(jù)單個分類器的正確率決定其權(quán)重
D. 給定n個數(shù)據(jù)點,如果其中一半用于訓(xùn)練,一般用于測試,則訓(xùn)練誤差和測試誤差之間的差別會隨著n的增加而減少
正確答案:(BD)
@劉炫320
A、SVM對噪聲(如來自其他分布的噪聲樣本)魯棒
SVM本身對噪聲具有一定的魯棒性,但實驗證明,是當(dāng)噪聲率低于一定水平的噪聲對SVM沒有太大影響,但隨著噪聲率的不斷增加,分類器的識別率會降低。
B、在AdaBoost算法中所有被分錯的樣本的權(quán)重更新比例相同
AdaBoost算法中不同的訓(xùn)練集是通過調(diào)整每個樣本對應(yīng)的權(quán)重來實現(xiàn)的。開始時,每個樣本對應(yīng)的權(quán)重是相同的,即其中n為樣本個數(shù),在此樣本分布下訓(xùn)練出一弱分類器。對于分類錯誤的樣本,加大其對應(yīng)的權(quán)重;而對于分類正確的樣本,降低其權(quán)重,這樣分錯的樣本就被凸顯出來,從而得到一個新的樣本分布。在新的樣本分布下,再次對樣本進行訓(xùn)練,得到弱分類器。以此類推,將所有的弱分類器重疊加起來,得到強分類器。
C、Boost和Bagging都是組合多個分類器投票的方法,二者均是根據(jù)單個分類器的正確率決定其權(quán)重。
Bagging與Boosting的區(qū)別:
取樣方式不同。
Bagging采用均勻取樣,而Boosting根據(jù)錯誤率取樣。
Bagging的各個預(yù)測函數(shù)沒有權(quán)重,而Boosting是有權(quán)重的。
Bagging的各個預(yù)測函數(shù)可以并行生成,而Boosing的各個預(yù)測函數(shù)只能順序生成。
183.輸入圖片大小為200×200,依次經(jīng)過一層卷積(kernel size 5×5,padding 1,stride 2),pooling(kernel size 3×3,padding 0,stride 1),又一層卷積(kernel size 3×3,padding 1,stride 1)之后,輸出特征圖大小為(C):
A. 95
B. 96
C. 97
D. 98
正確答案:(C)
@劉炫320
首先我們應(yīng)該知道卷積或者池化后大小的計算公式:
out_height=((input_height - filter_height + padding_top+padding_bottom)/stride_height )+1
out_width=((input_width - filter_width + padding_left+padding_right)/stride_width )+1
其中,padding指的是向外擴展的邊緣大小,而stride則是步長,即每次移動的長度。
這樣一來就容易多了,首先長寬一般大,所以我們只需要計算一個維度即可,這樣,經(jīng)過第一次卷積后的大小為: (200-5+2)/2+1,取99;經(jīng)過第一次池化后的大小為:(99-3)/1+1 為97;經(jīng)過第二次卷積后的大小為: (97-3+2)/1+1 為97。
184.在SPSS的基礎(chǔ)分析模塊中,作用是“以行列表的形式揭示數(shù)據(jù)之間的關(guān)系”的是(C)
A. 數(shù)據(jù)描述
B. 相關(guān)
C. 交叉表
D. 多重相應(yīng)
正確答案:(C )
185.一監(jiān)獄人臉識別準(zhǔn)入系統(tǒng)用來識別待進入人員的身份,此系統(tǒng)一共包括識別4種不同的人員:獄警,小偷,送餐員,其他。下面哪種學(xué)習(xí)方法最適合此種應(yīng)用需求:(B)。
A. 二分類問題
B. 多分類問題
C. 層次聚類問題
D. k-中心點聚類問題
E. 回歸問題
F. 結(jié)構(gòu)分析問題
正確答案:(B)
@劉炫320
二分類:每個分類器只能把樣本分為兩類。監(jiān)獄里的樣本分別為獄警、小偷、送餐員、其他。二分類肯 定行不通。瓦普尼克95年提出來基礎(chǔ)的支持向量機就是個二分類的分類器,這個分類器學(xué)習(xí)過 程就是解一個基于正負二分類推導(dǎo)而來的一個最優(yōu)規(guī)劃問題(對偶問題),要解決多分類問題 就要用決策樹把二分類的分類器級聯(lián),VC維的概念就是說的這事的復(fù)雜度。
層次聚類: 創(chuàng)建一個層次等級以分解給定的數(shù)據(jù)集。監(jiān)獄里的對象分別是獄警、小偷、送餐員、或者其 他,他們等級應(yīng)該是平等的,所以不行。此方法分為自上而下(分解)和自下而上(合并)兩種操作方式。
K-中心點聚類:挑選實際對象來代表簇,每個簇使用一個代表對象。它是圍繞中心點劃分的一種規(guī)則,所以這里并不合適。
回歸分析:處理變量之間具有相關(guān)性的一種統(tǒng)計方法,這里的獄警、小偷、送餐員、其他之間并沒有什 么直接關(guān)系。
結(jié)構(gòu)分析: 結(jié)構(gòu)分析法是在統(tǒng)計分組的基礎(chǔ)上,計算各組成部分所占比重,進而分析某一總體現(xiàn)象的內(nèi)部結(jié)構(gòu)特征、總體的性質(zhì)、總體內(nèi)部結(jié)構(gòu)依時間推移而表現(xiàn)出的變化規(guī)律性的統(tǒng)計方法。結(jié)構(gòu)分析法的基本表現(xiàn)形式,就是計算結(jié)構(gòu)指標(biāo)。這里也行不通。
多分類問題: 針對不同的屬性訓(xùn)練幾個不同的弱分類器,然后將它們集成為一個強分類器。這里獄警、 小偷、送餐員 以及他某某,分別根據(jù)他們的特點設(shè)定依據(jù),然后進行區(qū)分識別。
186.關(guān)于 Logit 回歸和 SVM 不正確的是(A)。
A. Logit回歸目標(biāo)函數(shù)是最小化后驗概率
B. Logit回歸可以用于預(yù)測事件發(fā)生概率的大小
C. SVM目標(biāo)是結(jié)構(gòu)風(fēng)險最小化
D. SVM可以有效避免模型過擬合
正確答案:(A)
@劉炫320
A. Logit回歸本質(zhì)上是一種根據(jù)樣本對權(quán)值進行極大似然估計的方法,而后驗概率正比于先驗概率和似然函數(shù)的乘積。logit僅僅是最大化似然函數(shù),并沒有最大化后驗概率,更談不上最小化后驗概率。而最小化后驗概率是樸素貝葉斯算法要做的。A錯誤
B. Logit回歸的輸出就是樣本屬于正類別的幾率,可以計算出概率,正確
C. SVM的目標(biāo)是找到使得訓(xùn)練數(shù)據(jù)盡可能分開且分類間隔最大的超平面,應(yīng)該屬于結(jié)構(gòu)風(fēng)險最小化。
D. SVM可以通過正則化系數(shù)控制模型的復(fù)雜度,避免過擬合。
187.有兩個樣本點,第一個點為正樣本,它的特征向量是(0,-1);第二個點為負樣本,它的特征向量是(2,3),從這兩個樣本點組成的訓(xùn)練集構(gòu)建一個線性SVM分類器的分類面方程是(C)
A. 2x+y=4
B. x+2y=5
C. x+2y=3
D. 2x-y=0
正確答案:(C)
解析:這道題簡化了,對于兩個點來說,最大間隔就是垂直平分線,因此求出垂直平分線即可。
188.下面有關(guān)分類算法的準(zhǔn)確率,召回率,F(xiàn)1 值的描述,錯誤的是?(C)
A. 準(zhǔn)確率是檢索出相關(guān)文檔數(shù)與檢索出的文檔總數(shù)的比率,衡量的是檢索系統(tǒng)的查準(zhǔn)率
B. 召回率是指檢索出的相關(guān)文檔數(shù)和文檔庫中所有的相關(guān)文檔數(shù)的比率,衡量的是檢索系統(tǒng)的查全率
C. 正確率、召回率和 F 值取值都在0和1之間,數(shù)值越接近0,查準(zhǔn)率或查全率就越高
D. 為了解決準(zhǔn)確率和召回率沖突問題,引入了F1分?jǐn)?shù)
正確答案:(C)
解析:對于二類分類問題常用的評價指標(biāo)是精準(zhǔn)度(precision)與召回率(recall)。通常以關(guān)注的類為正類,其他類為負類,分類器在測試數(shù)據(jù)集上的預(yù)測或正確或不正確,4種情況出現(xiàn)的總數(shù)分別記作:
TP——將正類預(yù)測為正類數(shù)
FN——將正類預(yù)測為負類數(shù)
FP——將負類預(yù)測為正類數(shù)
TN——將負類預(yù)測為負類數(shù)
由此:
精準(zhǔn)率定義為:P = TP / (TP + FP)
召回率定義為:R = TP / (TP + FN)
F1值定義為: F1 = 2 P R / (P + R)
精準(zhǔn)率和召回率和F1取值都在0和1之間,精準(zhǔn)率和召回率高,F(xiàn)1值也會高,不存在數(shù)值越接近0越高的說法,應(yīng)該是數(shù)值越接近1越高。
189.以下幾種模型方法屬于判別式模型(Discriminative Model)的有(A)
1)混合高斯模型 2)條件隨機場模型
3)區(qū)分度訓(xùn)練 4)隱馬爾科夫模型
A. 2,3
B. 3,4
C. 1,4
D. 1,2
正確答案:(A)
@劉炫320
常見的判別式模型有:Logistic Regression(Logistical 回歸)
Linear discriminant analysis(線性判別分析)
Supportvector machines(支持向量機)
Boosting(集成學(xué)習(xí))
Conditional random fields(條件隨機場)
Linear regression(線性回歸)
Neural networks(神經(jīng)網(wǎng)絡(luò))
常見的生成式模型有:Gaussian mixture model and othertypes of mixture model(高斯混合及其他類型混合模型)
Hidden Markov model(隱馬爾可夫)
NaiveBayes(樸素貝葉斯)
AODE(平均單依賴估計)
Latent Dirichlet allocation(LDA主題模型)
Restricted Boltzmann Machine(限制波茲曼機)
生成式模型是根據(jù)概率乘出結(jié)果,而判別式模型是給出輸入,計算出結(jié)果。
190.SPSS中,數(shù)據(jù)整理的功能主要集中在(AD )等菜單中。
A. 數(shù)據(jù)
B. 直銷
C. 分析
D. 轉(zhuǎn)換
正確答案:(AD )
@劉炫320
解析:對數(shù)據(jù)的整理主要在數(shù)據(jù)和轉(zhuǎn)換功能菜單中。
191.深度學(xué)習(xí)是當(dāng)前很熱門的機器學(xué)習(xí)算法,在深度學(xué)習(xí)中,涉及到大量的矩陣相乘,現(xiàn)在需要計算三個稠密矩陣A,B,C的乘積ABC,假設(shè)三個矩陣的尺寸分別為m?n,n?p,p?q,且m
A. (AB)C
B. AC(B)
C. A(BC)
D. 所以效率都相同
正確答案:(A)
@劉炫320
首先,根據(jù)簡單的矩陣知識,因為 A*B , A 的列數(shù)必須和 B 的行數(shù)相等。因此,可以排除 B 選項。
然后,再看 A 、 C 選項。在 A 選項中,m?n 的矩陣 A 和n?p的矩陣 B 的乘積,得到 m?p的矩陣 A*B ,而 A?B的每個元素需要 n 次乘法和 n-1 次加法,忽略加法,共需要 m?n?p次乘法運算。同樣情況分析 A*B 之后再乘以 C 時的情況,共需要 m?p?q次乘法運算。因此, A 選項 (AB)C 需要的乘法次數(shù)是 m?n?p+m?p?q 。同理分析, C 選項 A (BC) 需要的乘法次數(shù)是 n?p?q+m?n?q。
由于m?n?p
192.Nave Bayes是一種特殊的Bayes分類器,特征變量是X,類別標(biāo)簽是C,它的一個假定是:( C )
A. 各類別的先驗概率P(C)是相等的
B. 以0為均值,sqr(2)/2為標(biāo)準(zhǔn)差的正態(tài)分布
C. 特征變量X的各個維度是類別條件獨立隨機變量
D. P(X|C)是高斯分布
正確答案:( C )
@劉炫320
樸素貝葉斯的條件就是每個變量相互獨立。
193.關(guān)于支持向量機SVM,下列說法錯誤的是(C)
A. L2正則項,作用是最大化分類間隔,使得分類器擁有更強的泛化能力
B. Hinge 損失函數(shù),作用是最小化經(jīng)驗分類錯誤
C. 分類間隔為1||w||1||w||,||w||代表向量的模
D. 當(dāng)參數(shù)C越小時,分類間隔越大,分類錯誤越多,趨于欠學(xué)習(xí)
正確答案:(C)
@劉炫320
A正確。考慮加入正則化項的原因:想象一個完美的數(shù)據(jù)集,y>1是正類,y<-1是負類,決策面y=0,加入一個y=-30的正類噪聲樣本,那么決策面將會變“歪”很多,分類間隔變小,泛化能力減小。加入正則項之后,對噪聲樣本的容錯能力增強,前面提到的例子里面,決策面就會沒那么“歪”了,使得分類間隔變大,提高了泛化能力。
B正確。
C錯誤。間隔應(yīng)該是2||w||2||w||才對,后半句應(yīng)該沒錯,向量的模通常指的就是其二范數(shù)。
D正確。考慮軟間隔的時候,C對優(yōu)化問題的影響就在于把a的范圍從[0,+inf]限制到了[0,C]。C越小,那么a就會越小,目標(biāo)函數(shù)拉格朗日函數(shù)導(dǎo)數(shù)為0可以求出w=∑iai?yi?xiw=∑iai?yi?xi,a變小使得w變小,因此間隔2||w||2||w||變大。
194.在HMM中,如果已知觀察序列和產(chǎn)生觀察序列的狀態(tài)序列,那么可用以下哪種方法直接進行參數(shù)估計( D )
A. EM算法
B. 維特比算法
C. 前向后向算法
D. 極大似然估計
正確答案:( D )
@劉炫320
EM算法: 只有觀測序列,無狀態(tài)序列時來學(xué)習(xí)模型參數(shù),即Baum-Welch算法
維特比算法: 用動態(tài)規(guī)劃解決HMM的預(yù)測問題,不是參數(shù)估計
前向后向算法:用來算概率
極大似然估計:即觀測序列和相應(yīng)的狀態(tài)序列都存在時的監(jiān)督學(xué)習(xí)算法,用來估計參數(shù)
注意的是在給定觀測序列和對應(yīng)的狀態(tài)序列估計模型參數(shù),可以利用極大似然發(fā)估計。如果給定觀測序列,沒有對應(yīng)的狀態(tài)序列,才用EM,將狀態(tài)序列看不不可測的隱數(shù)據(jù)。
195.假定某同學(xué)使用Naive Bayesian(NB)分類模型時,不小心將訓(xùn)練數(shù)據(jù)的兩個維度搞重復(fù)了,那么關(guān)于NB的說法中正確的是:(BD)
A. 這個被重復(fù)的特征在模型中的決定作用會被加強
B. 模型效果相比無重復(fù)特征的情況下精確度會降低
C. 如果所有特征都被重復(fù)一遍,得到的模型預(yù)測結(jié)果相對于不重復(fù)的情況下的模型預(yù)測結(jié)果一樣。
D. 當(dāng)兩列特征高度相關(guān)時,無法用兩列特征相同時所得到的結(jié)論來分析問題
E. NB可以用來做最小二乘回歸
F. 以上說法都不正確
正確答案:(BD)
196.L1與L2范數(shù)在Logistic Regression 中,如果同時加入L1和L2范數(shù),會產(chǎn)生什么效果( A )。
A. 可以做特征選擇,并在一定程度上防止過擬合
B. 能解決維度災(zāi)難問題
C. 能加快計算速度
D. 可以獲得更準(zhǔn)確的結(jié)果
正確答案:( A )
@劉炫320
L1范數(shù)具有系數(shù)解的特性,但是要注意的是,L1沒有選到的特征不代表不重要,原因是兩個高相關(guān)性的特征可能只保留一個。如果需要確定哪個特征重要,再通過交叉驗證。
在代價函數(shù)后面加上正則項,L1即是Losso回歸,L2是嶺回歸。L1范數(shù)是指向量中各個元素絕對值之和,用于特征選擇。L2范數(shù) 是指向量各元素的平方和然后求平方根,用于 防止過擬合,提升模型的泛化能力。因此選擇A。
對于機器學(xué)習(xí)中的范數(shù)規(guī)則化,也就是L0,L1,L2范數(shù)的詳細解答,請參閱范數(shù)規(guī)則化。
197.機器學(xué)習(xí)中L1正則化和L2正則化的區(qū)別是?(AD)
A. 使用L1可以得到稀疏的權(quán)值
B. 使用L1可以得到平滑的權(quán)值
C. 使用L2可以得到稀疏的權(quán)值
D. 使用L2可以得到平滑的權(quán)值
正確答案:(AD)
@劉炫320
L1正則化偏向于稀疏,它會自動進行特征選擇,去掉一些沒用的特征,也就是將這些特征對應(yīng)的權(quán)重置為0。
L2主要功能是為了防止過擬合,當(dāng)要求參數(shù)越小時,說明模型越簡單,而模型越簡單則,越趨向于平滑,從而防止過擬合。
L1正則化/Lasso
L1正則化將系數(shù)w的L1范數(shù)作為懲罰項加到損失函數(shù)上,由于正則項非零,這就迫使那些弱的特征所對應(yīng)的系數(shù)變成0。因此L1正則化往往會使學(xué)到的模型很稀疏(系數(shù)w經(jīng)常為0),這個特性使得L1正則化成為一種很好的特征選擇方法。
L2正則化/Ridge regression
L2正則化將系數(shù)向量的L2范數(shù)添加到了損失函數(shù)中。由于L2懲罰項中系數(shù)是二次方的,這使得L2和L1有著諸多差異,最明顯的一點就是,L2正則化會讓系數(shù)的取值變得平均。對于關(guān)聯(lián)特征,這意味著他們能夠獲得更相近的對應(yīng)系數(shù)。還是以Y=X1+X2Y=X1+X2為例,假設(shè)X1X1和X1X1具有很強的關(guān)聯(lián),如果用L1正則化,不論學(xué)到的模型是Y=X1+X2Y=X1+X2還是Y=2X1Y=2X1,懲罰都是一樣的,都是2α2α。但是對于L2來說,第一個模型的懲罰項是2α2α,但第二個模型的是4α4α。可以看出,系數(shù)之和為常數(shù)時,各系數(shù)相等時懲罰是最小的,所以才有了L2會讓各個系數(shù)趨于相同的特點。
可以看出,L2正則化對于特征選擇來說一種穩(wěn)定的模型,不像L1正則化那樣,系數(shù)會因為細微的數(shù)據(jù)變化而波動。所以L2正則化和L1正則化提供的價值是不同的,L2正則化對于特征理解來說更加有用:表示能力強的特征對應(yīng)的系數(shù)是非零。
因此,一句話總結(jié)就是:L1會趨向于產(chǎn)生少量的特征,而其他的特征都是0,而L2會選擇更多的特征,這些特征都會接近于0。Lasso在特征選擇時候非常有用,而Ridge就只是一種規(guī)則化而已。
198.位勢函數(shù)法的積累勢函數(shù)K(x)的作用相當(dāng)于Bayes判決中的( AD )
A. 后驗概率
B. 先驗概率
C. 類概率密度
D. 類概率密度與先驗概率的乘積
正確答案: (AD)
@劉炫320
事實上,AD說的是一回事。
參考鏈接:勢函數(shù)主要用于確定分類面,其思想來源于物理。
199.隱馬爾可夫模型三個基本問題以及相應(yīng)的算法說法正確的是( ABC)
A. 評估—前向后向算法
B. 解碼—維特比算法
C. 學(xué)習(xí)—Baum-Welch算法
D. 學(xué)習(xí)—前向后向算法
正確答案: ( ABC)
解析:評估問題,可以使用前向算法、后向算法、前向后向算法。
200.特征比數(shù)據(jù)量還大時,選擇什么樣的分類器?
答案:線性分類器,因為維度高的時候,數(shù)據(jù)一般在維度空間里面會比較稀疏,很有可能線性可分。




-
函數(shù)
+關(guān)注
關(guān)注
3文章
4371瀏覽量
64279 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8493瀏覽量
134156 -
tensorflow
+關(guān)注
關(guān)注
13文章
330瀏覽量
61048
原文標(biāo)題:1000面試題,BAT機器學(xué)習(xí)面試刷題寶典
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【硬件方向】名企面試筆試真題:大疆創(chuàng)新校園招聘筆試題
BAT32G系列是中微半導(dǎo)推出的高性能超低功耗MCU
硬件工程師面試/筆試經(jīng)典 100 題

BP神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)的關(guān)系
【面試題】人工智能工程師高頻面試題匯總:概率論與統(tǒng)計篇(題目+答案)
傳統(tǒng)機器學(xué)習(xí)方法和應(yīng)用指導(dǎo)

【面試題】人工智能工程師高頻面試題匯總:機器學(xué)習(xí)深化篇(題目+答案)
【面試題】人工智能工程師高頻面試題匯總:Transformer篇(題目+答案)
人工智能工程師高頻面試題匯總——機器學(xué)習(xí)篇

NPU與機器學(xué)習(xí)算法的關(guān)系
賽盛在線平臺疑問解答系列(二)

AI引擎機器學(xué)習(xí)陣列指南






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論