") 最新加速深度強(qiáng)化學(xué)習(xí):谷歌創(chuàng)造
最新加速深度強(qiáng)化學(xué)習(xí):谷歌創(chuàng)造

深度強(qiáng)化學(xué)習(xí)技術(shù)可以通過視覺輸入來為復(fù)雜任務(wù)學(xué)習(xí)有效策略,這種方法在最近的研究中已經(jīng)被成功應(yīng)用經(jīng)典的雅達(dá)利2600系列游戲。最新的研究表明,即使在像Montezuma’s Revenge這樣復(fù)雜的游戲中基于深度強(qiáng)化學(xué)習(xí)依然可以達(dá)到超越人類的表現(xiàn)。然而深度強(qiáng)化學(xué)習(xí)最大的限制在于要達(dá)到高水平的效果,需要與環(huán)境進(jìn)行非常多次的交互,遠(yuǎn)遠(yuǎn)超過了人類學(xué)習(xí)游戲時與環(huán)境交互的次數(shù)。這也許是由于人類在游戲時可以有效預(yù)測其行為可以長生的結(jié)果,有效提升了學(xué)習(xí)的效率。可以通過行為序列和對應(yīng)的結(jié)果來進(jìn)行游戲建模。通過為游戲建模并學(xué)習(xí)選擇行為的策略,是基于模型強(qiáng)化學(xué)習(xí)(model-based reinforcement learning (MBRL))的主要假設(shè)。在先前研究的基礎(chǔ)上,谷歌研究人員在新論文中提出了模擬策略學(xué)習(xí)算法(Simulated Policy Learning (SimPLe) algorithm),這是一套大幅度提高雅達(dá)利游戲主體訓(xùn)練效率的MBRL框架,在僅僅100k次的交互訓(xùn)練后就可以達(dá)到較好的效果。100k次交互大概等效于人類兩個小時的游戲時間。這一算法通過觀測、建模、模擬學(xué)習(xí)的方式很好的處理了深度強(qiáng)化學(xué)習(xí)過程中的效率問題。
學(xué)習(xí)SimPle環(huán)境模型
從宏觀上來看,SimPle主要分為兩個交替進(jìn)行的學(xué)習(xí)過程,一個是學(xué)習(xí)游戲行為并建立環(huán)境模型的過程,另一個是在模擬游戲環(huán)境中利用這一模型優(yōu)化策略的過程。學(xué)習(xí)的流程如下圖所示循環(huán)進(jìn)行。
SimPle的主要流程,主體與環(huán)境交互并收集數(shù)據(jù)更新環(huán)境模型,隨后基于環(huán)境模型更新策略。
為了訓(xùn)練一個有效的雅達(dá)利游戲模型,后向需要在像素空間生成對未來的預(yù)測,換句話說我們需要根據(jù)先前的觀察和動作行為預(yù)測游戲的下一幀。選擇像素空間來預(yù)測的主要原因在于圖像觀測中包含了豐富且稠密的監(jiān)督信號。一旦完成未來幀預(yù)測模型的訓(xùn)練,算法就可以利用這一信息為游戲主體生成軌跡來訓(xùn)練好的策略,例如可以基于最大化長期回報來選擇行為。這意味著我們可以替代耗時和 消耗資源的真實(shí)游戲序列來訓(xùn)練策略,直接使用基于環(huán)境模型生成的圖像序列來進(jìn)行策略訓(xùn)練。
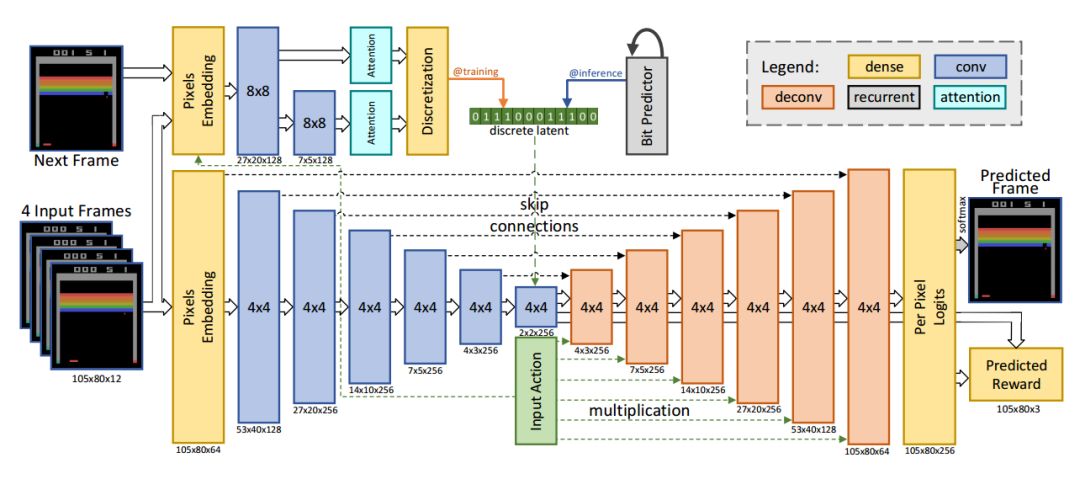
幀預(yù)測模型的架構(gòu)圖
基于前饋卷積網(wǎng)絡(luò)研究人員利用4幀輸入預(yù)測出下一幀的輸出以及對應(yīng)的反饋。輸入的像素和動作通過全連接層編碼,輸出則由逐像素的256色softmax構(gòu)成。模型有兩個主要的部分,下半部分是基于編碼器的卷積,解碼器的每一層與輸入動作都進(jìn)行了連接。另一部分是推理網(wǎng)絡(luò),在訓(xùn)練的時候從近似后驗(yàn)中約化采樣的隱空間編碼被離散成比特,為了保持模型可差分bp繞過了離散部分。在推理時利用網(wǎng)絡(luò)自回歸預(yù)測隱空間比特。

kufu在功夫大師游戲中,系統(tǒng)錯誤預(yù)測了對手的數(shù)量。其中左側(cè)是預(yù)測輸出、中間是基準(zhǔn)右邊是逐像素的差別。
這一模型雖然表現(xiàn)良好,但在某些特殊情況下依然會輸出錯誤的結(jié)果。例如在Pong游戲中,但球落到幀以外的時候系統(tǒng)就不能有效預(yù)測后續(xù)幀的結(jié)果。在先前工作的啟發(fā)下,研究人員利用新的視頻模型架構(gòu)來解決這類隨機(jī)問題。在模型訓(xùn)練后的每一個迭代中,研究人員利用Monique生成一系列包含動作、觀測和結(jié)果的序列,并利用PPO來改進(jìn)策略。其關(guān)鍵在于每一個生成序列都是從真實(shí)數(shù)據(jù)集開始的。考慮到長程序列的時間復(fù)雜度和誤差,SimPLe僅僅使用中程序列來進(jìn)行改進(jìn)。但PPO算法可以從內(nèi)部價值函數(shù)中學(xué)習(xí)到行為和結(jié)果間的長程作用,使得有限長度的序列在較為稀疏獎勵的游戲中也是足夠的。
高效的SimPLe
為了評測算法的效率,研究人員測評了主體在100k次環(huán)境交互后的輸出。研究人員在26個不同游戲中比較了Rainbow和PPO兩種流行的強(qiáng)化學(xué)習(xí)方法,在大多數(shù)情況下SimPLe算法都比其他算法塊兩倍以上。

20中不同游戲的測評,左側(cè)是Rainbow算法,右邊是PPO算法,展示了達(dá)到SimPLe100k訓(xùn)練分?jǐn)?shù)所需的交互次數(shù)。其中紅線是SimPLe的結(jié)果。
效果
SimPLe算法在Pong和Freeway中表現(xiàn)最精彩,在模擬環(huán)境中訓(xùn)練的主體可以達(dá)到最高分。同時在Pong,F(xiàn)reeway和Breakout中幾乎可以無誤差預(yù)測未來50步的像素幀。
兩種游戲中完美的像素預(yù)測結(jié)果,最又側(cè)是預(yù)測的誤差圖,可以看到幾乎與真實(shí)情況相同。
但這一算法也在某些情況下無法正確預(yù)測,它難以捕捉畫面中很多微小但十分重要的物體,例如游戲中的子彈。同時也無法使用迅速變化的游戲畫面,比如gameover時候的閃爍畫面。
但總的來說,新方法有助于學(xué)習(xí)模擬器更好的理解周遭的環(huán)境并提供了更新更好更快的訓(xùn)練方法來適應(yīng)多任務(wù)強(qiáng)化學(xué)習(xí)。雖然目前與最優(yōu)秀的無模型方法還有差距,但SimPLe具有很大的效率潛力,研究人員將在未來不斷深入改進(jìn)。
如果你想詳細(xì)了解其中的算法流程,可以參看下面的鏈接:
Paper:https://arxiv.org/pdf/1903.00374.pdf
這一部分代碼已經(jīng)集成到了tensor2tensor的強(qiáng)化學(xué)習(xí)代碼中:
Code:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/rl/README.md
研究人員還準(zhǔn)備了代碼和Colab幫助好學(xué)的你復(fù)現(xiàn)實(shí)驗(yàn):
Colab:https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t-rl.ipynb
ref:https://arxiv.org/abs/1509.06113http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.329.6065&rep=rep1&type=pdf
logo pic from:https://dribbble.com/shots/4166879-Controllers
-
谷歌
+關(guān)注
關(guān)注
27文章
6231瀏覽量
108069
原文標(biāo)題:谷歌新方法加速深度強(qiáng)化學(xué)習(xí)的訓(xùn)練過程
文章出處:【微信號:thejiangmen,微信公眾號:將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是深度強(qiáng)化學(xué)習(xí)?深度強(qiáng)化學(xué)習(xí)算法應(yīng)用分析

深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
將深度學(xué)習(xí)和強(qiáng)化學(xué)習(xí)相結(jié)合的深度強(qiáng)化學(xué)習(xí)DRL
薩頓科普了強(qiáng)化學(xué)習(xí)、深度強(qiáng)化學(xué)習(xí),并談到了這項(xiàng)技術(shù)的潛力和發(fā)展方向
如何深度強(qiáng)化學(xué)習(xí) 人工智能和深度學(xué)習(xí)的進(jìn)階
深度強(qiáng)化學(xué)習(xí)是否已經(jīng)到達(dá)盡頭?
深度強(qiáng)化學(xué)習(xí)的筆記資料免費(fèi)下載
深度強(qiáng)化學(xué)習(xí)到底是什么?它的工作原理是怎么樣的
DeepMind發(fā)布強(qiáng)化學(xué)習(xí)庫RLax
模型化深度強(qiáng)化學(xué)習(xí)應(yīng)用研究綜述

基于深度強(qiáng)化學(xué)習(xí)仿真集成的壓邊力控制模型
基于深度強(qiáng)化學(xué)習(xí)的無人機(jī)控制律設(shè)計方法
《自動化學(xué)報》—多Agent深度強(qiáng)化學(xué)習(xí)綜述

ESP32上的深度強(qiáng)化學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論