 微軟新研究提出一個新的多任務深度神經網絡模型——MT-DNN
微軟新研究提出一個新的多任務深度神經網絡模型——MT-DNN

微軟新研究提出一個新的多任務深度神經網絡模型——MT-DNN。MT-DNN結合了BERT的優點,并在10大自然語言理解任務上超越了BERT,在多個流行的基準測試中創造了新的最先進的結果。
語言嵌入是將自然語言符號文本(如單詞、短語和句子)映射到語義向量表示的過程。這是自然語言理解(NLU)深度學習方法的基礎。學習對多個NLU任務通用的語言嵌入是非常必要的。
學習語言嵌入有兩種流行方法,分別是語言模型預訓練和多任務學習(MTL)。前者通過利用大量未標記的數據學習通用語言嵌入,但MTL可以有效地利用來自許多相關任務的有監督數據,并通過減輕對特定任務的過度擬合,從正則化效果中獲益,從而使學習的嵌入在任務之間具有通用性。
最近,微軟的研究人員發布了一個用于學習通用語言嵌入的多任務深度神經網絡模型——MT-DNN。MT-DNN結合了MTL和BERT的語言模型預訓練方法的優點,并在10個NLU任務上超越了BERT,在多個流行的NLU基準測試中創造了新的最先進的結果,包括通用語言理解評估(GLUE)、斯坦福自然語言推理(SNLI)和SciTail。
MT-DNN的架構
MT-DNN擴展了微軟在2015年提出的多任務DNN模型(Multi-Task DNN),引入了谷歌AI開發的預訓練雙向transformer語言模型BERT。
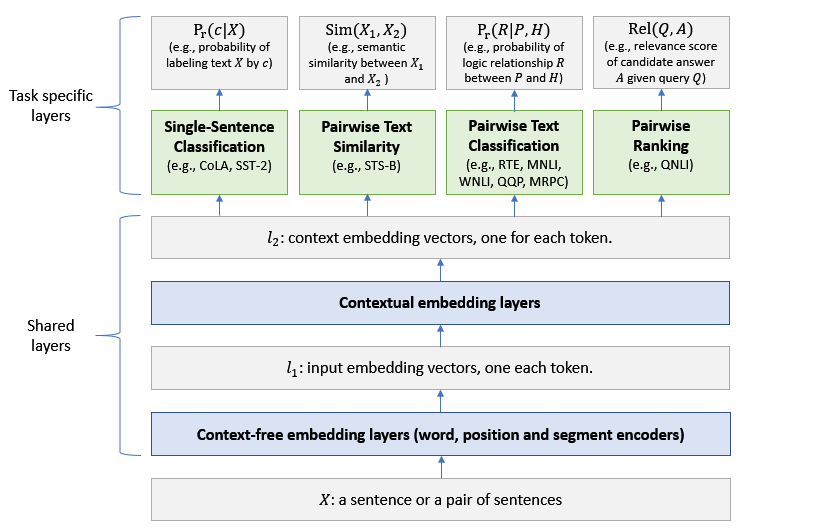
MT-DNN架構
MT-DNN模型的架構如上圖所示。低層在所有任務之間共享,而頂層是特定于任務的。輸入X可以是一個句子或一對句子,其中的每個單詞都先被表示為一個嵌入向量序列,表示為l_1。
然后,基于transformer的編碼器捕獲每個單詞的上下文信息,并在l_2中生成共享的上下文嵌入向量。
最后,對于每個任務,額外的 task-speci?c 的層生成特定于任務的表示,然后是分類、相似度評分或相關性排序所需的操作。MT-DNN使用BERT來初始化它的共享層,然后通過MTL改進它們。
領域自適應結果
評估語言嵌入的通用性的一種方法是測量嵌入適應新任務的速度,或者需要多少特定于任務的標簽才能在新任務上獲得不錯的結果。越通用的嵌入,它需要的特定于任務的標簽就越少。
MT-DNN論文的作者將MT-DNN與BERT在領域自適應(domain adaption)方面的表現進行了比較。
在域適應方面,兩種模型都通過逐步增加域內數據(in-domain data)的大小來適應新的任務。
SNLI和SciTail任務的結果如下表和圖所示。可以看到,在只有0.1%的域內數據(SNLI中為549個樣本,SciTail中為23個樣本)的條件下,MT-DNN的準確率超過80%,而BERT的準確率在50%左右,這說明MT-DNN學習的語言嵌入比BERT的更加通用。
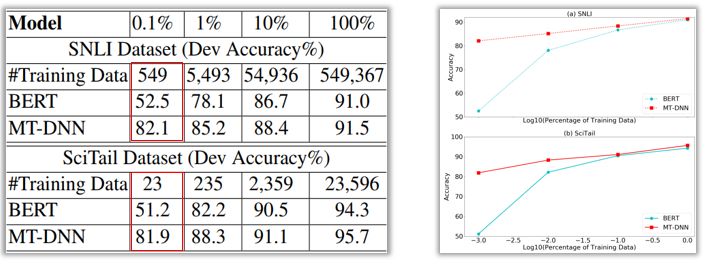
與BERT相比,MT-DNN在SNLI和SciTail數據集上的精度更高。
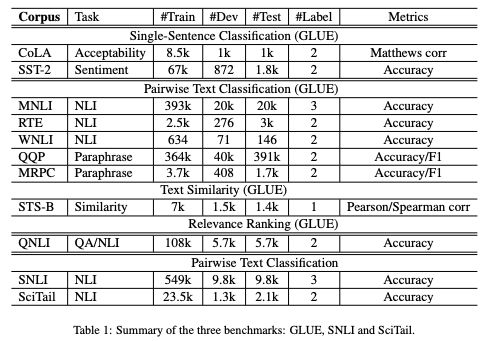
在GLUE、SNLI和SciTail 3個benchmarks上的結果
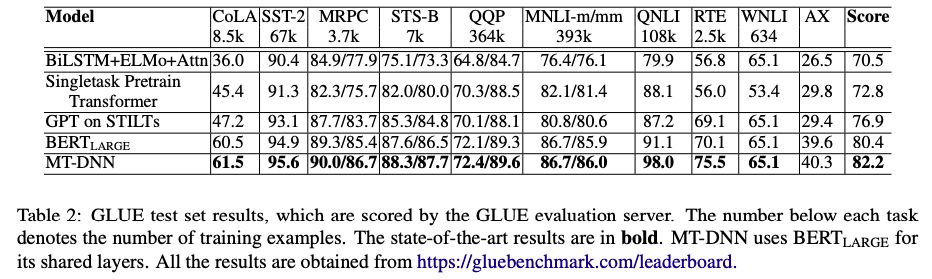
在GLUE測試集的結果,MT-DNN在10個任務上的結果均超越了BERT
模型開源
微軟已經在GitHub開源MT-DNN包,其中包含了預訓練的模型、源代碼,并描述了如何重現MT-DNN論文中報告的結果,以及如何通過domain adaptation使預訓練的MT-DNN模型適應任何新任務。
-
微軟
+關注
關注
4文章
6684瀏覽量
105659 -
神經網絡
+關注
關注
42文章
4813瀏覽量
103411 -
深度學習
+關注
關注
73文章
5560瀏覽量
122739
原文標題:10大任務超越BERT,微軟提出多任務深度神經網絡MT-DNN
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論