") 手把手教你使用Python實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法
手把手教你使用Python實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法
這是一篇手把手教你使用 Python 實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法,并在數(shù)值型數(shù)據(jù)和圖像數(shù)據(jù)集上運(yùn)行模型的入門(mén)教程,當(dāng)你看完本文后,你應(yīng)當(dāng)可以開(kāi)始你的機(jī)器學(xué)習(xí)之旅了!
本教程會(huì)采用下述兩個(gè)庫(kù)來(lái)實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法:
scikit-learn
Keras
此外,你還將學(xué)習(xí)到:
評(píng)估你的問(wèn)題
準(zhǔn)備數(shù)據(jù)(原始數(shù)據(jù)、特征提取、特征工程等等)
檢查各種機(jī)器學(xué)習(xí)算法
檢驗(yàn)實(shí)驗(yàn)結(jié)果
深入了解性能最好的算法
在本文會(huì)用到的機(jī)器學(xué)習(xí)算法包括:
KNN
樸素貝葉斯
邏輯回歸
SVM
決策樹(shù)
隨機(jī)森林
感知機(jī)
多層前向網(wǎng)絡(luò)
CNNs
安裝必備的 Python 機(jī)器學(xué)習(xí)庫(kù)
開(kāi)始本教程前,需要先確保安裝了一下的 Python 庫(kù):
Numpy:用于 Python 的數(shù)值處理
PIL:一個(gè)簡(jiǎn)單的圖像處理庫(kù)
scikit-learn:包含多種機(jī)器學(xué)習(xí)算法(注意需要采用 0.2+ 的版本,所以下方安裝命令需要加上--upgrade)
Kears 和 TensorFlow:用于深度學(xué)習(xí)。本教程可以?xún)H采用 CPU 版本的 TensorFlow
OpenCV:本教程并不會(huì)采用到 OpenCV,但imutils庫(kù)依賴(lài)它;
imutils:作者的圖像處理/計(jì)算機(jī)視覺(jué)庫(kù)
安裝命令如下,推薦采用虛擬環(huán)境(比如利用 anaconda 創(chuàng)建一個(gè)新的環(huán)境):
$pipinstallnumpy$pipinstallpillow$pipinstall--upgradescikit-learn$pipinstalltensorflow#ortensorflow-gpu$pipinstallkeras$pipinstallopencv-contrib-python$pipinstall--upgradeimutils
數(shù)據(jù)集
本教程會(huì)用到兩個(gè)數(shù)據(jù)集來(lái)幫助更好的了解每個(gè)機(jī)器學(xué)習(xí)算法的性能。
第一個(gè)數(shù)據(jù)集是 Iris(鳶尾花)數(shù)據(jù)集。這個(gè)數(shù)據(jù)集的地位,相當(dāng)于你剛開(kāi)始學(xué)習(xí)一門(mén)編程語(yǔ)言時(shí),敲下的 “Hello,World!”
這個(gè)數(shù)據(jù)集是一個(gè)數(shù)值型的數(shù)據(jù),如下圖所示,其實(shí)就是一個(gè)表格數(shù)據(jù),每一行代表一個(gè)樣本,然后每一列就是不同的屬性。這個(gè)數(shù)據(jù)集主要是收集了三種不同的鳶尾花的數(shù)據(jù),分別為:
Iris Setosa
Iris Versicolor
Iris Virginica
對(duì)應(yīng)圖中最后一列Class label,然后還有四種屬性,分別是:
Sepal length--萼片長(zhǎng)度
Sepal width--萼片寬度
Petal length--花瓣長(zhǎng)度
Petal width--花瓣寬度
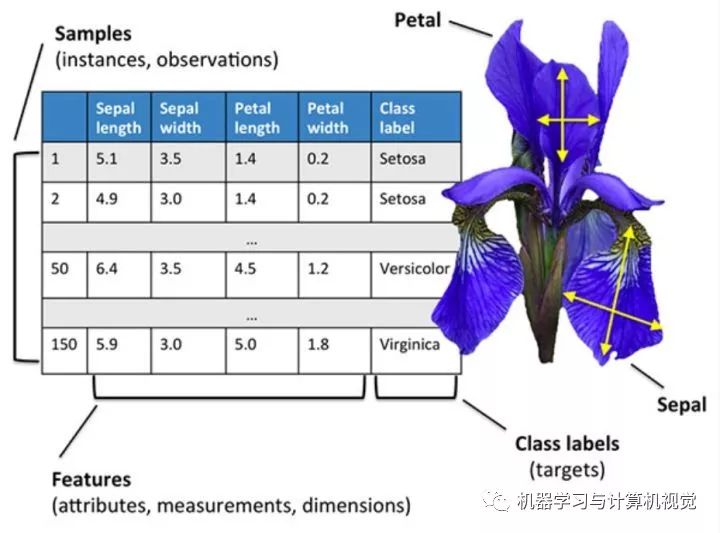
這個(gè)數(shù)據(jù)集可能是最簡(jiǎn)單的機(jī)器學(xué)習(xí)數(shù)據(jù)集之一了,通常是用于教導(dǎo)程序員和工程師的機(jī)器學(xué)習(xí)和模式識(shí)別基礎(chǔ)的數(shù)據(jù)集。
對(duì)于該數(shù)據(jù)集,我們的目標(biāo)就是根據(jù)給定的四個(gè)屬性,訓(xùn)練一個(gè)機(jī)器學(xué)習(xí)模型來(lái)正確分類(lèi)每個(gè)樣本的類(lèi)別。
需要注意的是,其中有一個(gè)類(lèi)別和另外兩個(gè)類(lèi)別是線(xiàn)性可分的,但這兩個(gè)類(lèi)別之間卻并非線(xiàn)性可分,所以我們需要采用一個(gè)非線(xiàn)性模型來(lái)對(duì)它們進(jìn)行分類(lèi)。當(dāng)然了,在現(xiàn)實(shí)生活中,采用非線(xiàn)性模型的機(jī)器學(xué)習(xí)算法是非常常見(jiàn)的。
第二個(gè)數(shù)據(jù)集是一個(gè)三場(chǎng)景的圖像數(shù)據(jù)集。這是幫助初學(xué)者學(xué)習(xí)如何處理圖像數(shù)據(jù),并且哪種算法在這兩種數(shù)據(jù)集上性能最優(yōu)。
下圖是這個(gè)三場(chǎng)景數(shù)據(jù)集的部分圖片例子,它包括森林、高速公路和海岸線(xiàn)三種場(chǎng)景,總共是 948 張圖片,每個(gè)類(lèi)別的具體圖片數(shù)量如下:
Coast: 360
Forest: 328
Highway: 260
這個(gè)三場(chǎng)景數(shù)據(jù)集是采樣于一個(gè)八場(chǎng)景數(shù)據(jù)集中,作者是 Oliva 和 Torralba 的 2001 年的一篇論文,Modeling the shape of the scene: a holistic representation of the spatial envelope
利用 Python 實(shí)現(xiàn)機(jī)器學(xué)習(xí)的步驟
無(wú)論什么時(shí)候?qū)崿F(xiàn)機(jī)器學(xué)習(xí)算法,推薦采用如下流程來(lái)開(kāi)始:
評(píng)估你的問(wèn)題
準(zhǔn)備數(shù)據(jù)(原始數(shù)據(jù)、特征提取、特征工程等等)
檢查各種機(jī)器學(xué)習(xí)算法
檢驗(yàn)實(shí)驗(yàn)結(jié)果
深入了解性能最好的算法
這個(gè)流程會(huì)隨著你機(jī)器學(xué)習(xí)方面的經(jīng)驗(yàn)的積累而改善和優(yōu)化,但對(duì)于初學(xué)者,這是我建議入門(mén)機(jī)器學(xué)習(xí)時(shí)采用的流程。
所以,現(xiàn)在開(kāi)始吧!第一步,就是評(píng)估我們的問(wèn)題,問(wèn)一下自己:
數(shù)據(jù)集是哪種類(lèi)型?數(shù)值型,類(lèi)別型還是圖像?
模型的最終目標(biāo)是什么?
如何定義和衡量“準(zhǔn)確率”呢?
以目前自身的機(jī)器學(xué)習(xí)知識(shí)來(lái)看,哪些算法在處理這類(lèi)問(wèn)題上效果很好?
最后一個(gè)問(wèn)題非常重要,隨著你使用 Python 實(shí)現(xiàn)機(jī)器學(xué)習(xí)的次數(shù)的增加,你也會(huì)隨之獲得更多的經(jīng)驗(yàn)。根據(jù)之前的經(jīng)驗(yàn),你可能知道有一種算法的性能還不錯(cuò)。
因此,接著就是準(zhǔn)備數(shù)據(jù),也就是數(shù)據(jù)預(yù)處理以及特征工程了。
一般來(lái)說(shuō),這一步,包括了從硬盤(pán)中載入數(shù)據(jù),檢查數(shù)據(jù),然后決定是否需要做特征提取或者特征工程。
特征提取就是應(yīng)用某種算法通過(guò)某種方式來(lái)量化數(shù)據(jù)的過(guò)程。比如,對(duì)于圖像數(shù)據(jù),我們可以采用計(jì)算直方圖的方法來(lái)統(tǒng)計(jì)圖像中像素強(qiáng)度的分布,通過(guò)這種方式,我們就得到描述圖像顏色的特征。
而特征工程則是將原始輸入數(shù)據(jù)轉(zhuǎn)換成一個(gè)更好描述潛在問(wèn)題的特征表示的過(guò)程。當(dāng)然特征工程是一項(xiàng)更先進(jìn)的技術(shù),這里建議在對(duì)機(jī)器學(xué)習(xí)有了一定經(jīng)驗(yàn)后再采用這種方法處理數(shù)據(jù)。
第三步,就是檢查各種機(jī)器學(xué)習(xí)算法,也就是實(shí)現(xiàn)一系列機(jī)器學(xué)習(xí)算法,并應(yīng)用在數(shù)據(jù)集上。
這里,你的工具箱應(yīng)當(dāng)包含以下幾種不同類(lèi)型的機(jī)器學(xué)習(xí)算法:
線(xiàn)性模型(比如,邏輯回歸,線(xiàn)性 SVM)
非線(xiàn)性模型(比如 RBF SVM,梯度下降分類(lèi)器)
樹(shù)和基于集成的模型(比如 決策樹(shù)和隨機(jī)森林)
神經(jīng)網(wǎng)絡(luò)(比如 多層感知機(jī),卷積神經(jīng)網(wǎng)絡(luò))
應(yīng)當(dāng)選擇比較魯棒(穩(wěn)定)的一系列機(jī)器學(xué)習(xí)模型來(lái)評(píng)估問(wèn)題,因?yàn)槲覀兊哪繕?biāo)就是判斷哪種算法在當(dāng)前問(wèn)題的性能很好,而哪些算法很糟糕。
決定好要采用的模型后,接下來(lái)就是訓(xùn)練模型并在數(shù)據(jù)集上測(cè)試,觀察每個(gè)模型在數(shù)據(jù)集上的性能結(jié)果。
在多次實(shí)驗(yàn)后,你可能就是有一種“第六感”,知道哪種算法更適用于哪種數(shù)據(jù)集。比如,你會(huì)發(fā)現(xiàn):
對(duì)于有很多特征的數(shù)據(jù)集,隨機(jī)森林算法的效果很不錯(cuò);
而邏輯回歸算法可以很好處理高維度的稀疏數(shù)據(jù);
對(duì)于圖像數(shù)據(jù),CNNs 的效果非常好。
而以上的經(jīng)驗(yàn)獲得,當(dāng)然就需要你多動(dòng)手,多進(jìn)行實(shí)戰(zhàn)來(lái)深入了解不同的機(jī)器學(xué)習(xí)算法了!
開(kāi)始動(dòng)手吧!
接下來(lái)就開(kāi)始敲代碼來(lái)實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法,并在上述兩個(gè)數(shù)據(jù)集上進(jìn)行測(cè)試。本教程的代碼文件目錄如下,包含四份代碼文件和一個(gè)3scenes文件夾,該文件夾就是三場(chǎng)景數(shù)據(jù)集,而Iris數(shù)據(jù)集直接采用scikit-learn庫(kù)載入即可。
├──3scenes│├──coast[360entries]│├──forest[328entries]│└──highway[260entries]├──classify_iris.py├──classify_images.py├──nn_iris.py└──basic_cnn.py
首先是實(shí)現(xiàn)classify_iris.py,這份代碼是采用機(jī)器學(xué)習(xí)算法來(lái)對(duì)Iris數(shù)據(jù)集進(jìn)行分類(lèi)。
首先導(dǎo)入需要的庫(kù):
fromsklearn.neighborsimportKNeighborsClassifierfromsklearn.naive_bayesimportGaussianNBfromsklearn.linear_modelimportLogisticRegressionfromsklearn.svmimportSVCfromsklearn.treeimportDecisionTreeClassifierfromsklearn.ensembleimportRandomForestClassifierfromsklearn.neural_networkimportMLPClassifierfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromsklearn.datasetsimportload_irisimportargparse#設(shè)置參數(shù)ap=argparse.ArgumentParser()ap.add_argument("-m","--model",type=str,default="knn",help="typeofpythonmachinelearningmodeltouse")args=vars(ap.parse_args())#定義一個(gè)保存模型的字典,根據(jù)key來(lái)選擇加載哪個(gè)模型models={"knn":KNeighborsClassifier(n_neighbors=1),"naive_bayes":GaussianNB(),"logit":LogisticRegression(solver="lbfgs",multi_class="auto"),"svm":SVC(kernel="rbf",gamma="auto"),"decision_tree":DecisionTreeClassifier(),"random_forest":RandomForestClassifier(n_estimators=100),"mlp":MLPClassifier()}
可以看到在sklearn庫(kù)中就集成了我們將要實(shí)現(xiàn)的幾種機(jī)器學(xué)習(xí)算法的代碼,包括:
KNN
樸素貝葉斯
邏輯回歸
SVM
決策樹(shù)
隨機(jī)森林
感知機(jī)
我們直接調(diào)用sklearn中相應(yīng)的函數(shù)來(lái)實(shí)現(xiàn)對(duì)應(yīng)的算法即可,比如對(duì)于knn算法,直接調(diào)用sklearn.neighbors中的KNeighborsClassifier()即可,只需要設(shè)置參數(shù)n_neighbors,即最近鄰的個(gè)數(shù)。
這里直接用一個(gè)models的字典來(lái)保存不同模型的初始化,然后根據(jù)參數(shù)--model來(lái)調(diào)用對(duì)應(yīng)的模型,比如命令輸入python classify_irs.py --model knn就是調(diào)用knn算法模型。
接著就是載入數(shù)據(jù)部分:
print("[INFO]loadingdata...")dataset=load_iris()(trainX,testX,trainY,testY)=train_test_split(dataset.data,dataset.target,random_state=3,test_size=0.25)
這里直接調(diào)用sklearn.datasets中的load_iris()載入數(shù)據(jù),然后采用train_test_split來(lái)劃分訓(xùn)練集和數(shù)據(jù)集,這里是 75% 數(shù)據(jù)作為訓(xùn)練集,25% 作為測(cè)試集。
最后就是訓(xùn)練模型和預(yù)測(cè)部分:
#訓(xùn)練模型print("[INFO]using'{}'model".format(args["model"]))model=models[args["model"]]model.fit(trainX,trainY)#預(yù)測(cè)并輸出一份分類(lèi)結(jié)果報(bào)告print("[INFO]evaluating")predictions=model.predict(testX)print(classification_report(testY,predictions,target_names=dataset.target_names))
完整版代碼代碼如下:
fromsklearn.neighborsimportKNeighborsClassifierfromsklearn.naive_bayesimportGaussianNBfromsklearn.linear_modelimportLogisticRegressionfromsklearn.svmimportSVCfromsklearn.treeimportDecisionTreeClassifierfromsklearn.ensembleimportRandomForestClassifierfromsklearn.neural_networkimportMLPClassifierfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromsklearn.datasetsimportload_irisimportargparse#設(shè)置參數(shù)ap=argparse.ArgumentParser()ap.add_argument("-m","--model",type=str,default="knn",help="typeofpythonmachinelearningmodeltouse")args=vars(ap.parse_args())#定義一個(gè)保存模型的字典,根據(jù)key來(lái)選擇加載哪個(gè)模型models={"knn":KNeighborsClassifier(n_neighbors=1),"naive_bayes":GaussianNB(),"logit":LogisticRegression(solver="lbfgs",multi_class="auto"),"svm":SVC(kernel="rbf",gamma="auto"),"decision_tree":DecisionTreeClassifier(),"random_forest":RandomForestClassifier(n_estimators=100),"mlp":MLPClassifier()}#載入Iris數(shù)據(jù)集,然后進(jìn)行訓(xùn)練集和測(cè)試集的劃分,75%數(shù)據(jù)作為訓(xùn)練集,其余25%作為測(cè)試集print("[INFO]loadingdata...")dataset=load_iris()(trainX,testX,trainY,testY)=train_test_split(dataset.data,dataset.target,random_state=3,test_size=0.25)#訓(xùn)練模型print("[INFO]using'{}'model".format(args["model"]))model=models[args["model"]]model.fit(trainX,trainY)#預(yù)測(cè)并輸出一份分類(lèi)結(jié)果報(bào)告print("[INFO]evaluating")predictions=model.predict(testX)print(classification_report(testY,predictions,target_names=dataset.target_names))
接著就是采用三場(chǎng)景圖像數(shù)據(jù)集的分類(lèi)預(yù)測(cè)代碼 classify_images.py ,跟 classify_iris.py 的代碼其實(shí)是比較相似的,首先導(dǎo)入庫(kù)部分,增加以下幾行代碼:
fromsklearn.preprocessingimportLabelEncoderfromPILimportImagefromimutilsimportpathsimportnumpyasnpimportos
其中LabelEncoder是為了將標(biāo)簽從字符串編碼為整型,然后其余幾項(xiàng)都是處理圖像相關(guān)。
對(duì)于圖像數(shù)據(jù),如果直接采用原始像素信息輸入模型中,大部分的機(jī)器學(xué)習(xí)算法效果都很不理想,所以這里采用特征提取方法,主要是統(tǒng)計(jì)圖像顏色通道的均值和標(biāo)準(zhǔn)差信息,總共是 RGB 3個(gè)通道,每個(gè)通道各計(jì)算均值和標(biāo)準(zhǔn)差,然后結(jié)合在一起,得到一個(gè)六維的特征,函數(shù)如下所示:
defextract_color_stats(image):'''將圖片分成RGB三通道,然后分別計(jì)算每個(gè)通道的均值和標(biāo)準(zhǔn)差,然后返回:paramimage::return:'''(R,G,B)=image.split()features=[np.mean(R),np.mean(G),np.mean(B),np.std(R),np.std(G),np.std(B)]returnfeatures
然后同樣會(huì)定義一個(gè)models字典,代碼一樣,這里就不貼出來(lái)了,然后圖像載入部分的代碼如下:
#加載數(shù)據(jù)并提取特征print("[INFO]extractingimagefeatures...")imagePaths=paths.list_images(args['dataset'])data=[]labels=[]#循環(huán)遍歷所有的圖片數(shù)據(jù)forimagePathinimagePaths:#加載圖片,然后計(jì)算圖片的顏色通道統(tǒng)計(jì)信息image=Image.open(imagePath)features=extract_color_stats(image)data.append(features)#保存圖片的標(biāo)簽信息label=imagePath.split(os.path.sep)[-2]labels.append(label)#對(duì)標(biāo)簽進(jìn)行編碼,從字符串變?yōu)檎麛?shù)類(lèi)型le=LabelEncoder()labels=le.fit_transform(labels)#進(jìn)行訓(xùn)練集和測(cè)試集的劃分,75%數(shù)據(jù)作為訓(xùn)練集,其余25%作為測(cè)試集(trainX,testX,trainY,testY)=train_test_split(data,labels,test_size=0.25)
上述代碼就完成從硬盤(pán)中加載圖片的路徑信息,然后依次遍歷,讀取圖片,提取特征,提取標(biāo)簽信息,保存特征和標(biāo)簽信息,接著編碼標(biāo)簽,然后就是劃分訓(xùn)練集和測(cè)試集。
接著是相同的訓(xùn)練模型和預(yù)測(cè)的代碼,同樣沒(méi)有任何改變,這里就不列舉出來(lái)了。
完整版如下:
fromsklearn.neighborsimportKNeighborsClassifierfromsklearn.naive_bayesimportGaussianNBfromsklearn.linear_modelimportLogisticRegressionfromsklearn.svmimportSVCfromsklearn.treeimportDecisionTreeClassifierfromsklearn.ensembleimportRandomForestClassifierfromsklearn.neural_networkimportMLPClassifierfromsklearn.preprocessingimportLabelEncoderfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromPILimportImagefromimutilsimportpathsimportnumpyasnpimportargparseimportosdefextract_color_stats(image):'''將圖片分成RGB三通道,然后分別計(jì)算每個(gè)通道的均值和標(biāo)準(zhǔn)差,然后返回:paramimage::return:'''(R,G,B)=image.split()features=[np.mean(R),np.mean(G),np.mean(B),np.std(R),np.std(G),np.std(B)]returnfeatures#設(shè)置參數(shù)ap=argparse.ArgumentParser()ap.add_argument("-d","--dataset",type=str,default="3scenes",help="pathtodirectorycontainingthe'3scenes'dataset")ap.add_argument("-m","--model",type=str,default="knn",help="typeofpythonmachinelearningmodeltouse")args=vars(ap.parse_args())#定義一個(gè)保存模型的字典,根據(jù)key來(lái)選擇加載哪個(gè)模型models={"knn":KNeighborsClassifier(n_neighbors=1),"naive_bayes":GaussianNB(),"logit":LogisticRegression(solver="lbfgs",multi_class="auto"),"svm":SVC(kernel="rbf",gamma="auto"),"decision_tree":DecisionTreeClassifier(),"random_forest":RandomForestClassifier(n_estimators=100),"mlp":MLPClassifier()}#加載數(shù)據(jù)并提取特征print("[INFO]extractingimagefeatures...")imagePaths=paths.list_images(args['dataset'])data=[]labels=[]#循環(huán)遍歷所有的圖片數(shù)據(jù)forimagePathinimagePaths:#加載圖片,然后計(jì)算圖片的顏色通道統(tǒng)計(jì)信息image=Image.open(imagePath)features=extract_color_stats(image)data.append(features)#保存圖片的標(biāo)簽信息label=imagePath.split(os.path.sep)[-2]labels.append(label)#對(duì)標(biāo)簽進(jìn)行編碼,從字符串變?yōu)檎麛?shù)類(lèi)型le=LabelEncoder()labels=le.fit_transform(labels)#進(jìn)行訓(xùn)練集和測(cè)試集的劃分,75%數(shù)據(jù)作為訓(xùn)練集,其余25%作為測(cè)試集(trainX,testX,trainY,testY)=train_test_split(data,labels,random_state=3,test_size=0.25)#print('trainXnumbers={},testXnumbers={}'.format(len(trainX),len(testX)))#訓(xùn)練模型print("[INFO]using'{}'model".format(args["model"]))model=models[args["model"]]model.fit(trainX,trainY)#預(yù)測(cè)并輸出分類(lèi)結(jié)果報(bào)告print("[INFO]evaluating...")predictions=model.predict(testX)print(classification_report(testY,predictions,target_names=le.classes_))
完成這兩份代碼后,我們就可以開(kāi)始運(yùn)行下代碼,對(duì)比不同算法在兩個(gè)數(shù)據(jù)集上的性能。
因?yàn)槠脑颍@里我會(huì)省略原文對(duì)每個(gè)算法的介紹,具體的可以查看之前我寫(xiě)的對(duì)機(jī)器學(xué)習(xí)算法的介紹:
常用機(jī)器學(xué)習(xí)算法匯總比較(上)
常用機(jī)器學(xué)習(xí)算法匯總比較(中)
常用機(jī)器學(xué)習(xí)算法匯總比較(完)
KNN
這里我們先運(yùn)行下classify_irs.py,調(diào)用默認(rèn)的模型knn,看下KNN在Iris數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果,如下所示:
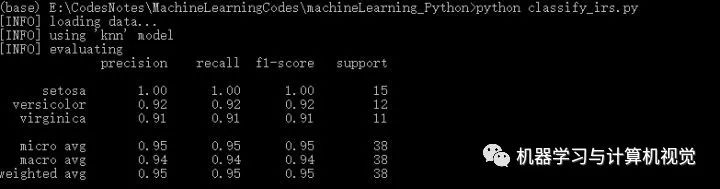
其中主要是給出了對(duì)每個(gè)類(lèi)別的精確率、召回率、F1 以及該類(lèi)別測(cè)試集數(shù)量,即分別對(duì)應(yīng)precision,recall,f1-score,support。根據(jù)最后一行第一列,可以看到KNN取得95%的準(zhǔn)確率。
接著是在三場(chǎng)景圖片數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果:
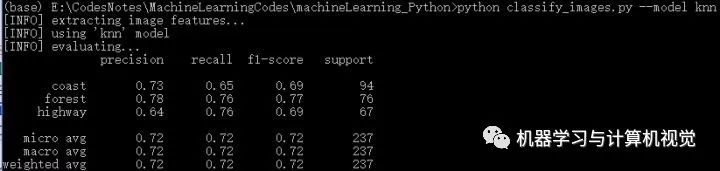
這里KNN取得72%的準(zhǔn)確率。
(ps:實(shí)際上,運(yùn)行這個(gè)算法,不同次數(shù)會(huì)有不同的結(jié)果,原文作者給出的是 75%,其主要原因是因?yàn)樵趧澐钟?xùn)練集和測(cè)試集的時(shí)候,代碼沒(méi)有設(shè)置參數(shù)random_state,這導(dǎo)致每次運(yùn)行劃分的訓(xùn)練集和測(cè)試集的圖片都是不同的,所以運(yùn)行結(jié)果也會(huì)不相同!)
樸素貝葉斯
接著是樸素貝葉斯算法,分別測(cè)試兩個(gè)數(shù)據(jù)集,結(jié)果如下:
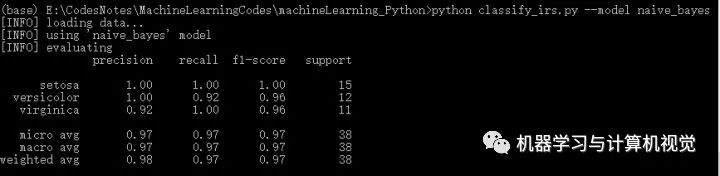
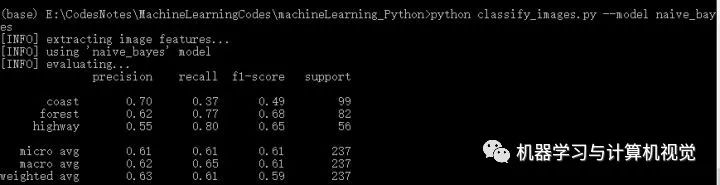
同樣,樸素貝葉斯在Iris上有98%的準(zhǔn)確率,但是在圖像數(shù)據(jù)集上僅有63%的準(zhǔn)確率。
那么,我們是否可以說(shuō)明KNN算法比樸素貝葉斯好呢?
當(dāng)然是不可以的,上述結(jié)果只能說(shuō)明在三場(chǎng)景圖像數(shù)據(jù)集上,KNN算法優(yōu)于樸素貝葉斯算法。
實(shí)際上,每種算法都有各自的優(yōu)缺點(diǎn)和適用場(chǎng)景,不能一概而論地說(shuō)某種算法任何時(shí)候都優(yōu)于另一種算法,這需要具體問(wèn)題具體分析。
邏輯回歸
接著是邏輯回歸算法,分別測(cè)試兩個(gè)數(shù)據(jù)集,結(jié)果如下:
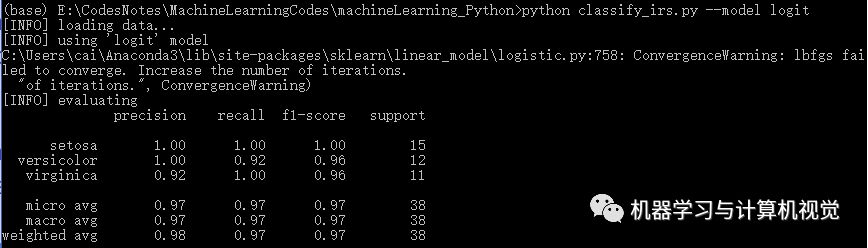
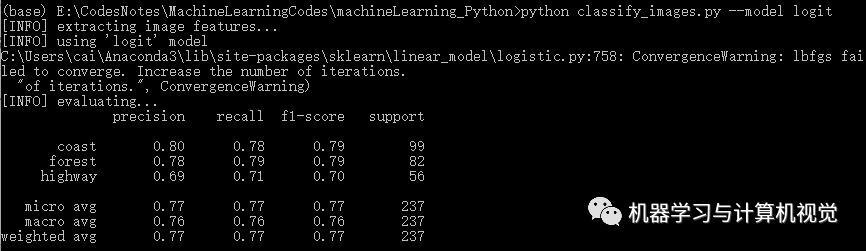
同樣,邏輯回歸在Iris上有98%的準(zhǔn)確率,但是在圖像數(shù)據(jù)集上僅有77%的準(zhǔn)確率(對(duì)比原文作者的邏輯回歸準(zhǔn)確率是 69%)
支持向量機(jī) SVM
接著是 SVM 算法,分別測(cè)試兩個(gè)數(shù)據(jù)集,結(jié)果如下:
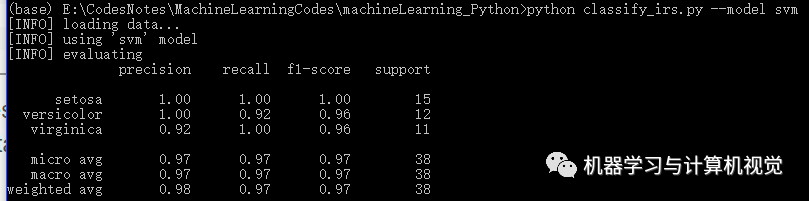
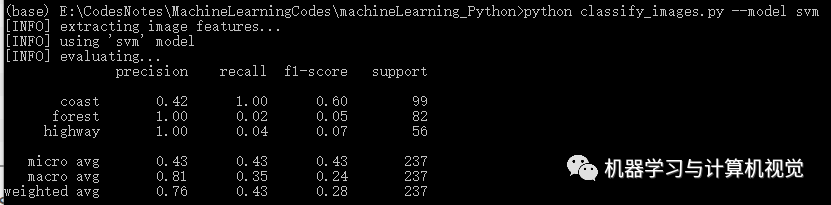
同樣,SVM 在Iris上有98%的準(zhǔn)確率,但是在圖像數(shù)據(jù)集上僅有76%的準(zhǔn)確率(對(duì)比原文作者的準(zhǔn)確率是 83%,主要是發(fā)現(xiàn)類(lèi)別coast差別有些大)
決策樹(shù)
接著是決策樹(shù)算法,分別測(cè)試兩個(gè)數(shù)據(jù)集,結(jié)果如下:
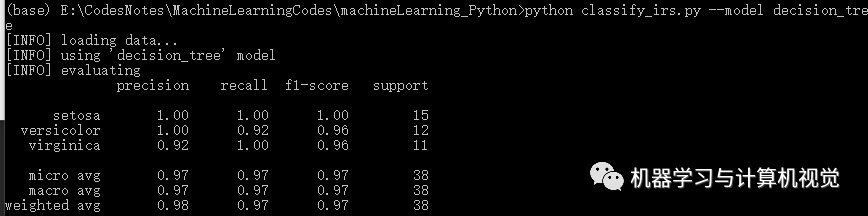
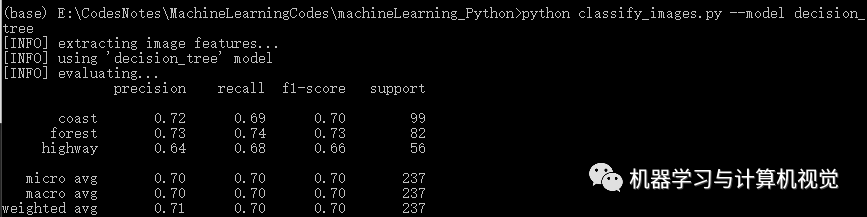
同樣,決策樹(shù)在Iris上有98%的準(zhǔn)確率,但是在圖像數(shù)據(jù)集上僅有71%的準(zhǔn)確率(對(duì)比原文作者的決策樹(shù)準(zhǔn)確率是 74%)
隨機(jī)森林
接著是隨機(jī)森林算法,分別測(cè)試兩個(gè)數(shù)據(jù)集,結(jié)果如下:

同樣,隨機(jī)森林在Iris上有96%的準(zhǔn)確率,但是在圖像數(shù)據(jù)集上僅有77%的準(zhǔn)確率(對(duì)比原文作者的決策樹(shù)準(zhǔn)確率是 84%)
注意了,一般如果決策樹(shù)算法的效果還不錯(cuò)的話(huà),隨機(jī)森林算法應(yīng)該也會(huì)取得不錯(cuò)甚至更好的結(jié)果,這是因?yàn)殡S機(jī)森林實(shí)際上就是多棵決策樹(shù)通過(guò)集成學(xué)習(xí)方法組合在一起進(jìn)行分類(lèi)預(yù)測(cè)。
多層感知機(jī)
最后是多層感知機(jī)算法,分別測(cè)試兩個(gè)數(shù)據(jù)集,結(jié)果如下:
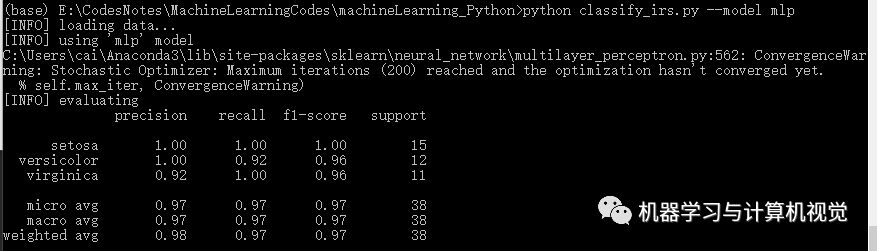
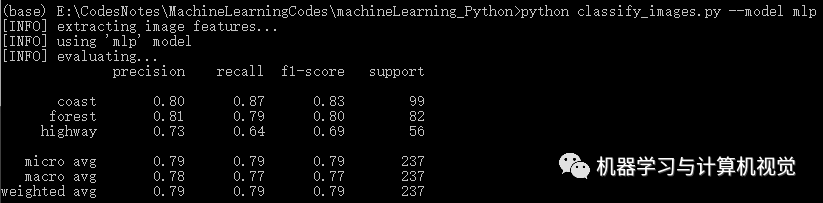
同樣,多層感知機(jī)在Iris上有98%的準(zhǔn)確率,但是在圖像數(shù)據(jù)集上僅有79%的準(zhǔn)確率(對(duì)比原文作者的決策樹(shù)準(zhǔn)確率是 81%).
深度學(xué)習(xí)以及深度神經(jīng)網(wǎng)絡(luò)
神經(jīng)網(wǎng)絡(luò)
最后是實(shí)現(xiàn)深度學(xué)習(xí)的算法,也就是nn_iris.py和basic_cnn.py這兩份代碼。
(這里需要注意TensorFlow和Keras的版本問(wèn)題,我采用的是TF=1.2和Keras=2.1.5)
首先是nn_iris.py的實(shí)現(xiàn),同樣首先是導(dǎo)入庫(kù)和數(shù)據(jù)的處理:
fromkeras.modelsimportSequentialfromkeras.layers.coreimportDensefromkeras.optimizersimportSGDfromsklearn.preprocessingimportLabelBinarizerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromsklearn.datasetsimportload_iris#載入Iris數(shù)據(jù)集,然后進(jìn)行訓(xùn)練集和測(cè)試集的劃分,75%數(shù)據(jù)作為訓(xùn)練集,其余25%作為測(cè)試集print("[INFO]loadingdata...")dataset=load_iris()(trainX,testX,trainY,testY)=train_test_split(dataset.data,dataset.target,test_size=0.25)#將標(biāo)簽進(jìn)行one-hot編碼lb=LabelBinarizer()trainY=lb.fit_transform(trainY)testY=lb.transform(testY)
這里我們將采用Keras來(lái)實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò),然后這里需要將標(biāo)簽進(jìn)行one-hot編碼,即獨(dú)熱編碼。
接著就是搭建網(wǎng)絡(luò)模型的結(jié)構(gòu)和訓(xùn)練、預(yù)測(cè)代碼:
#利用Keras定義網(wǎng)絡(luò)模型model=Sequential()model.add(Dense(3,input_shape=(4,),activation="sigmoid"))model.add(Dense(3,activation="sigmoid"))model.add(Dense(3,activation="softmax"))#采用梯度下降訓(xùn)練模型print('[INFO]trainingnetwork...')opt=SGD(lr=0.1,momentum=0.9,decay=0.1/250)model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=["accuracy"])H=model.fit(trainX,trainY,validation_data=(testX,testY),epochs=250,batch_size=16)#預(yù)測(cè)print('[INFO]evaluatingnetwork...')predictions=model.predict(testX,batch_size=16)print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),target_names=dataset.target_names))
這里是定義了 3 層全連接層的神經(jīng)網(wǎng)絡(luò),前兩層采用Sigmoid激活函數(shù),然后最后一層是輸出層,所以采用softmax將輸出變成概率值。接著就是定義了使用SGD的優(yōu)化算法,損失函數(shù)是categorical_crossentropy,迭代次數(shù)是 250 次,batch_size是 16。
完整版如下:
fromkeras.modelsimportSequentialfromkeras.layers.coreimportDensefromkeras.optimizersimportSGDfromsklearn.preprocessingimportLabelBinarizerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromsklearn.datasetsimportload_iris#載入Iris數(shù)據(jù)集,然后進(jìn)行訓(xùn)練集和測(cè)試集的劃分,75%數(shù)據(jù)作為訓(xùn)練集,其余25%作為測(cè)試集print("[INFO]loadingdata...")dataset=load_iris()(trainX,testX,trainY,testY)=train_test_split(dataset.data,dataset.target,test_size=0.25)#將標(biāo)簽進(jìn)行one-hot編碼lb=LabelBinarizer()trainY=lb.fit_transform(trainY)testY=lb.transform(testY)#利用Keras定義網(wǎng)絡(luò)模型model=Sequential()model.add(Dense(3,input_shape=(4,),activation="sigmoid"))model.add(Dense(3,activation="sigmoid"))model.add(Dense(3,activation="softmax"))#采用梯度下降訓(xùn)練模型print('[INFO]trainingnetwork...')opt=SGD(lr=0.1,momentum=0.9,decay=0.1/250)model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=["accuracy"])H=model.fit(trainX,trainY,validation_data=(testX,testY),epochs=250,batch_size=16)#預(yù)測(cè)print('[INFO]evaluatingnetwork...')predictions=model.predict(testX,batch_size=16)print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),target_names=dataset.target_names))
直接運(yùn)行命令python nn_iris.py, 輸出的結(jié)果如下:
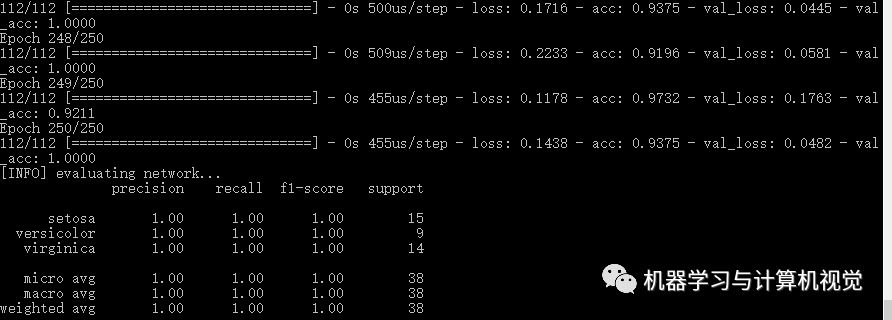
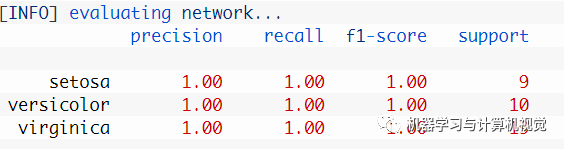
這里得到的是 100% 的準(zhǔn)確率,和原文的一樣。當(dāng)然實(shí)際上原文給出的結(jié)果如下圖所示,可以看到其實(shí)類(lèi)別數(shù)量上是不相同的。
CNN
最后就是實(shí)現(xiàn)basic_cnn.py這份代碼了。
同樣首先是導(dǎo)入必須的庫(kù)函數(shù):
fromkeras.modelsimportSequentialfromkeras.layers.convolutionalimportConv2Dfromkeras.layers.convolutionalimportMaxPooling2Dfromkeras.layers.coreimportActivationfromkeras.layers.coreimportFlattenfromkeras.layers.coreimportDensefromkeras.optimizersimportAdamfromsklearn.preprocessingimportLabelBinarizerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromPILimportImagefromimutilsimportpathsimportnumpyasnpimportargparseimportos#配置參數(shù)ap=argparse.ArgumentParser()ap.add_argument("-d","--dataset",type=str,default="3scenes",help="pathtodirectorycontainingthe'3scenes'dataset")args=vars(ap.parse_args())
同樣是要導(dǎo)入Keras來(lái)建立CNN的網(wǎng)絡(luò)模型,另外因?yàn)槭翘幚韴D像數(shù)據(jù),所以PIL、imutils也是要導(dǎo)入的。
然后是加載數(shù)據(jù)和劃分訓(xùn)練集和測(cè)試集,對(duì)于加載數(shù)據(jù),這里直接采用原始圖像像素?cái)?shù)據(jù),只需要對(duì)圖像數(shù)據(jù)做統(tǒng)一尺寸的調(diào)整,這里是統(tǒng)一調(diào)整為 32×32,并做歸一化到[0,1]的范圍。
#加載數(shù)據(jù)并提取特征print("[INFO]extractingimagefeatures...")imagePaths=paths.list_images(args['dataset'])data=[]labels=[]#循環(huán)遍歷所有的圖片數(shù)據(jù)forimagePathinimagePaths:#加載圖片,然后調(diào)整成32×32大小,并做歸一化到[0,1]image=Image.open(imagePath)image=np.array(image.resize((32,32)))/255.0data.append(image)#保存圖片的標(biāo)簽信息label=imagePath.split(os.path.sep)[-2]labels.append(label)#對(duì)標(biāo)簽編碼,從字符串變?yōu)檎蚻b=LabelBinarizer()labels=lb.fit_transform(labels)#劃分訓(xùn)練集和測(cè)試集(trainX,testX,trainY,testY)=train_test_split(np.array(data),np.array(labels),test_size=0.25)
接著定義了一個(gè) 4 層的CNN網(wǎng)絡(luò)結(jié)構(gòu),包含 3 層卷積層和最后一層輸出層,優(yōu)化算法采用的是Adam而不是SGD。代碼如下所示:
#定義CNN網(wǎng)絡(luò)模型結(jié)構(gòu)model=Sequential()model.add(Conv2D(8,(3,3),padding="same",input_shape=(32,32,3)))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Conv2D(16,(3,3),padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Conv2D(32,(3,3),padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Flatten())model.add(Dense(3))model.add(Activation("softmax"))#訓(xùn)練模型print("[INFO]trainingnetwork...")opt=Adam(lr=1e-3,decay=1e-3/50)model.compile(loss="categorical_crossentropy",optimizer=opt,metrics=["accuracy"])H=model.fit(trainX,trainY,validation_data=(testX,testY),epochs=50,batch_size=32)#預(yù)測(cè)print("[INFO]evaluatingnetwork...")predictions=model.predict(testX,batch_size=32)print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),target_names=lb.classes_))
完整版如下:
fromkeras.modelsimportSequentialfromkeras.layers.convolutionalimportConv2Dfromkeras.layers.convolutionalimportMaxPooling2Dfromkeras.layers.coreimportActivationfromkeras.layers.coreimportFlattenfromkeras.layers.coreimportDensefromkeras.optimizersimportAdamfromsklearn.preprocessingimportLabelBinarizerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromPILimportImagefromimutilsimportpathsimportnumpyasnpimportargparseimportos#配置參數(shù)ap=argparse.ArgumentParser()ap.add_argument("-d","--dataset",type=str,default="3scenes",help="pathtodirectorycontainingthe'3scenes'dataset")args=vars(ap.parse_args())#加載數(shù)據(jù)并提取特征print("[INFO]extractingimagefeatures...")imagePaths=paths.list_images(args['dataset'])data=[]labels=[]#循環(huán)遍歷所有的圖片數(shù)據(jù)forimagePathinimagePaths:#加載圖片,然后調(diào)整成32×32大小,并做歸一化到[0,1]image=Image.open(imagePath)image=np.array(image.resize((32,32)))/255.0data.append(image)#保存圖片的標(biāo)簽信息label=imagePath.split(os.path.sep)[-2]labels.append(label)#對(duì)標(biāo)簽編碼,從字符串變?yōu)檎蚻b=LabelBinarizer()labels=lb.fit_transform(labels)#劃分訓(xùn)練集和測(cè)試集(trainX,testX,trainY,testY)=train_test_split(np.array(data),np.array(labels),test_size=0.25)#定義CNN網(wǎng)絡(luò)模型結(jié)構(gòu)model=Sequential()model.add(Conv2D(8,(3,3),padding="same",input_shape=(32,32,3)))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Conv2D(16,(3,3),padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Conv2D(32,(3,3),padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Flatten())model.add(Dense(3))model.add(Activation("softmax"))#訓(xùn)練模型print("[INFO]trainingnetwork...")opt=Adam(lr=1e-3,decay=1e-3/50)model.compile(loss="categorical_crossentropy",optimizer=opt,metrics=["accuracy"])H=model.fit(trainX,trainY,validation_data=(testX,testY),epochs=50,batch_size=32)#預(yù)測(cè)print("[INFO]evaluatingnetwork...")predictions=model.predict(testX,batch_size=32)print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),target_names=lb.classes_))
運(yùn)行命令python basic_cnn.py, 輸出結(jié)果如下:
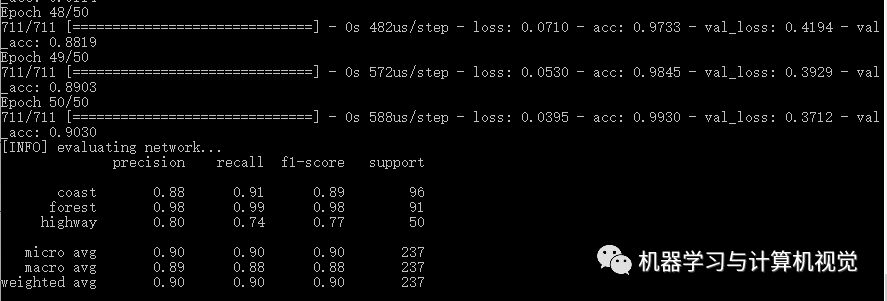
CNN的準(zhǔn)確率是達(dá)到90%,它是優(yōu)于之前的幾種機(jī)器學(xué)習(xí)算法的結(jié)果。
小結(jié)
最后,這僅僅是一份對(duì)機(jī)器學(xué)習(xí)完全是初學(xué)者的教程,其實(shí)就是簡(jiǎn)單調(diào)用現(xiàn)有的庫(kù)來(lái)實(shí)現(xiàn)對(duì)應(yīng)的機(jī)器學(xué)習(xí)算法,讓初學(xué)者簡(jiǎn)單感受下如何使用機(jī)器學(xué)習(xí)算法,正如同在學(xué)習(xí)編程語(yǔ)言的時(shí)候,對(duì)著書(shū)本的代碼例子敲起來(lái),然后運(yùn)行代碼,看看自己寫(xiě)出來(lái)的程序的運(yùn)行結(jié)果。
通過(guò)這份簡(jiǎn)單的入門(mén)教程,你應(yīng)該明白的是:
沒(méi)有任何一種算法是完美的,可以完全適用所有的場(chǎng)景,即便是目前很熱門(mén)的深度學(xué)習(xí)方法,也存在它的局限性,所以應(yīng)該具體問(wèn)題具體分析!
記住開(kāi)頭推薦的 5 步機(jī)器學(xué)習(xí)操作流程,這里再次復(fù)習(xí)一遍:
評(píng)估你的問(wèn)題
準(zhǔn)備數(shù)據(jù)(原始數(shù)據(jù)、特征提取、特征工程等等)
檢查各種機(jī)器學(xué)習(xí)算法
檢驗(yàn)實(shí)驗(yàn)結(jié)果
深入了解性能最好的算法
最后一點(diǎn),是我運(yùn)行算法結(jié)果,和原文作者的結(jié)果會(huì)不相同,這實(shí)際上就是每次采樣數(shù)據(jù),劃分訓(xùn)練集和測(cè)試集不相同的原因!這其實(shí)也說(shuō)明了數(shù)據(jù)非常重要,對(duì)于機(jī)器學(xué)習(xí)來(lái)說(shuō),好的數(shù)據(jù)很重要!
接著,根據(jù)這份教程,你可以繼續(xù)進(jìn)一步了解每種機(jī)器學(xué)習(xí)算法,了解每種算法的基本原理和實(shí)現(xiàn),嘗試自己手動(dòng)實(shí)現(xiàn),而不是簡(jiǎn)單調(diào)用現(xiàn)有的庫(kù),這樣更加能加深印象,這里推薦《機(jī)器學(xué)習(xí)實(shí)戰(zhàn)》,經(jīng)典的機(jī)器學(xué)習(xí)算法都有介紹,并且都會(huì)帶你一步步實(shí)現(xiàn)算法!
最后,極力推薦大家去閱讀下原文作者的博客,原文作者也是一個(gè)大神,他的博客地址如下:https://www.pyimagesearch.com/
他的博客包含了 Opencv、Python、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)方面的教程和文章,而且作者喜歡通過(guò)實(shí)戰(zhàn)學(xué)習(xí),所以很多文章都是通過(guò)一些實(shí)戰(zhàn)練習(xí)來(lái)學(xué)習(xí)某個(gè)知識(shí)點(diǎn)或者某個(gè)算法,正如同本文通過(guò)實(shí)現(xiàn)這幾種常見(jiàn)的機(jī)器學(xué)習(xí)算法在兩個(gè)不同類(lèi)型數(shù)據(jù)集上的實(shí)戰(zhàn)來(lái)帶領(lǐng)初學(xué)者入門(mén)機(jī)器學(xué)習(xí)。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8493瀏覽量
134162 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86268 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25295
原文標(biāo)題:初學(xué)者的機(jī)器學(xué)習(xí)入門(mén)實(shí)戰(zhàn)教程!
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
原創(chuàng)手把手教你學(xué)習(xí)FPGA視頻教程,不看后悔喲
美女手把手教你如何裝機(jī)(中)
手把手教你學(xué)習(xí)FPGA—LED篇
手把手教你安裝Quartus II
手把手教你學(xué)LabVIEW視覺(jué)設(shè)計(jì)
手把手教你開(kāi)關(guān)電源PCB排板






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論