") 訓(xùn)練一個(gè)機(jī)器學(xué)習(xí)模型,實(shí)現(xiàn)了根據(jù)基于文本分析預(yù)測(cè)葡萄酒質(zhì)量
訓(xùn)練一個(gè)機(jī)器學(xué)習(xí)模型,實(shí)現(xiàn)了根據(jù)基于文本分析預(yù)測(cè)葡萄酒質(zhì)量
愛酒人士應(yīng)該都知道,選紅酒是個(gè)需要大量知識(shí)儲(chǔ)備的技術(shù)活——產(chǎn)地、年份、包裝、飲用場(chǎng)合,每個(gè)元素的變化都會(huì)對(duì)口感產(chǎn)生一定的影響。
TowardsDataScience上一位作者(同時(shí)也是輕度葡萄酒飲用者)用一組Kaggle的數(shù)據(jù)集撰寫了一個(gè)可以幫忙在網(wǎng)上選紅酒的AI小程序。
該數(shù)據(jù)中包含對(duì)葡萄酒的評(píng)論,葡萄酒評(píng)級(jí)(以分?jǐn)?shù)衡量),以及從WineEnthusiasts網(wǎng)站提取的其他相關(guān)信息。他通過訓(xùn)練一個(gè)機(jī)器學(xué)習(xí)模型,實(shí)現(xiàn)了根據(jù)基于文本分析預(yù)測(cè)葡萄酒質(zhì)量。
數(shù)據(jù)集按照日期被劃分為兩組數(shù)據(jù)文件。一組作為訓(xùn)練集,把一組作為測(cè)試集。
以下是整個(gè)訓(xùn)練過程,一起看看。
目標(biāo):訓(xùn)練一個(gè)機(jī)器學(xué)習(xí)模型,實(shí)現(xiàn)基于文本分析的葡萄酒質(zhì)量預(yù)測(cè)
WineEnthusiast的用戶會(huì)對(duì)葡萄酒評(píng)分,1表示最差,100表示最好。不幸的是,傳到網(wǎng)站上的都是正面評(píng)論,所以數(shù)據(jù)集里分?jǐn)?shù)值只分布在80-100之間。
這意味著我們所用的這套數(shù)據(jù)并不能很好反應(yīng)我們?cè)谔剿鞯膯栴}。因此,基于這套數(shù)據(jù)所建立的模型只適用于評(píng)論較好的酒。在進(jìn)行分析之前,我們還是得先預(yù)習(xí)一些圈內(nèi)基本知識(shí)。通過從閱讀葡萄酒網(wǎng)站及一些相關(guān)資源,我找到一種自認(rèn)為不錯(cuò)的分級(jí)方案,按照評(píng)分進(jìn)行分級(jí)。如下所示。

對(duì)于一個(gè)最終用戶(白話說就是買葡萄酒的),評(píng)分就是他們想要傳達(dá)的信息。如果我們按照上述劃分形式,我們就能既減少了葡萄酒信息維度又能保留住質(zhì)量相關(guān)信息。
重要決定:我把這個(gè)問題定義為一個(gè)傾向性分析問題,基于用戶評(píng)價(jià)判斷葡萄酒屬于Classic(典藏酒)、Superb(豪華酒)、Excellent(酒中上品)、Very Good(優(yōu)質(zhì)酒)、Good(好酒)及Acceptable(湊合吧)中的哪個(gè)等級(jí)。
實(shí)現(xiàn):探索式分析
在這步中,我們會(huì)一點(diǎn)點(diǎn)深入理解數(shù)據(jù)。數(shù)據(jù)探索能夠給我們帶來更多解決問題的靈感。數(shù)據(jù)集中除了評(píng)論和評(píng)分,還有其他信息,如葡萄酒價(jià)格、品類(葡萄品種)及產(chǎn)地等。
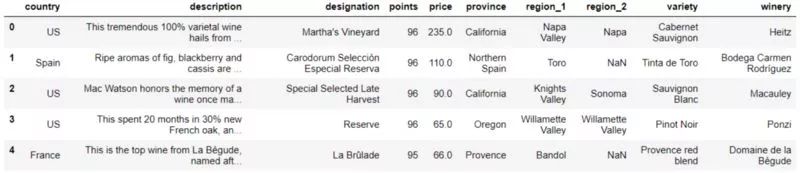
數(shù)據(jù)預(yù)覽
我們可以把上述的其他信息也引入作為特征參數(shù),這樣就能構(gòu)建出一個(gè)更全面的模型來預(yù)測(cè)葡萄酒質(zhì)量。為了將文字描述與其他特征結(jié)合起來進(jìn)行預(yù)測(cè),我們可以創(chuàng)建一個(gè)集成學(xué)模型(文本分類器就是集成在內(nèi)的一部分);也可以創(chuàng)建一個(gè)層級(jí)模型,在層級(jí)模型中,分類器的輸出會(huì)作為一個(gè)預(yù)測(cè)變量。
出于此目的,我們僅研究一下評(píng)論與葡萄酒評(píng)分之間的關(guān)系。
全面地查看數(shù)據(jù)完整性
評(píng)分和評(píng)論描述這兩列數(shù)據(jù)是完整的。前文提到過,葡萄酒的評(píng)分相對(duì)都比較高。所以,以我的經(jīng)驗(yàn)看來,價(jià)格也會(huì)比較高。
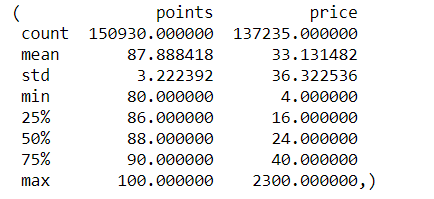
data.describe()的輸出結(jié)果
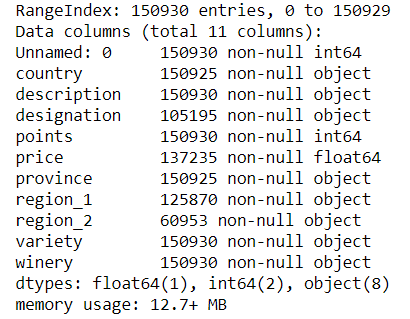
data.info()的輸出結(jié)果
查看文本數(shù)據(jù)
評(píng)論的內(nèi)容看似來都很清晰。沒有出現(xiàn)任何語法和拼寫錯(cuò)誤,而且評(píng)論的言語都比較簡潔。請(qǐng)看示例:
這款由純葡萄釀制的精品干紅來自奧克維爾酒莊,并在木桶中足足陳釀3年。當(dāng)如紅櫻桃汁般的果味遇上濃烈的焦糖味,再在精致柔和的單寧的作用下,并散發(fā)著微微薄荷香,真是令人垂涎。綜合從釀造開始至今的各項(xiàng)數(shù)據(jù),它還值得再存放幾年使其越陳越香,推薦品嘗時(shí)間2022年-2030年。
還是得有一定的葡萄酒知識(shí)才能完全讀懂一些評(píng)論。上述示例中,“單寧”是一種能使得葡萄酒口感很干的一種成分。
下圖中我能看到這些常用術(shù)語的出現(xiàn)頻率。
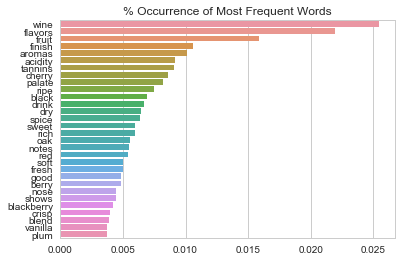
最常出現(xiàn)的詞就是“Wine”,出現(xiàn)頻率超過了0.025%
分類前的準(zhǔn)備工作
所以,我們可以通過評(píng)分,將評(píng)論和我們所分的等級(jí)關(guān)聯(lián)起來。但不巧的是,我們的數(shù)據(jù)并不是很平衡。
沒有落在第4級(jí)內(nèi)的評(píng)論,大部分評(píng)論都落在第1-3級(jí)中。數(shù)據(jù)分布不均雖然是個(gè)問題,但還是可以通過細(xì)分類別或者設(shè)置類別權(quán)重來處理。可是,某個(gè)類別完全沒數(shù)據(jù),這可得好好想想辦法了。
重要決定:我把第5級(jí)和第4級(jí)合成一級(jí),這里評(píng)分在94-100中的評(píng)論就都在這個(gè)級(jí)別里了。
有必要清洗文本數(shù)據(jù)嗎?
我們可以考慮一下要不要對(duì)葡萄酒的評(píng)論信息進(jìn)行清洗或者標(biāo)準(zhǔn)化。做不做這事主要取決于我們所使用的學(xué)習(xí)算法。如果我們想把每條評(píng)論轉(zhuǎn)化成一個(gè)向量并作為一對(duì)一分類器的輸入,那就得花大量的時(shí)間進(jìn)行文本的標(biāo)準(zhǔn)化處理。另一種方式,如果以多向量的形式順序處理文本內(nèi)容,就用不著過多的標(biāo)準(zhǔn)化了。
順序處理文本(通常每個(gè)單詞都有對(duì)應(yīng)的向量,且對(duì)應(yīng)關(guān)系都很明確)有利于詞義消歧(一個(gè)單詞有多種含義)和識(shí)別同義詞。因?yàn)樵u(píng)論都是關(guān)于葡萄酒的,其中所提到的專業(yè)術(shù)語語境基本一致,所以我不太在意詞義消歧和識(shí)別同義詞的問題。但是由于評(píng)論的內(nèi)容都比較正面,我當(dāng)心一對(duì)一分類器很難區(qū)分出相鄰兩個(gè)類別之間的微妙差異。
重要決定:我要使用遞歸神經(jīng)網(wǎng)絡(luò)模型,把每條評(píng)論轉(zhuǎn)化為向量序列傳到模型中進(jìn)行預(yù)測(cè)。這樣我也就保留了文本的原始形式。
相較于使用TF-IDF等方式將文本轉(zhuǎn)為詞向量傳到一對(duì)一分類器中,我所選的就會(huì)一定更優(yōu)嗎?這并不好說。不過,這可以留到以后試試再作比較。
文本向量化
基于神經(jīng)網(wǎng)絡(luò)的單詞向量化通常可以使用word2vec、GloVe和fastText。對(duì)此,我們可以選擇使用自己定義的詞向量映射模型或是預(yù)先訓(xùn)練好的模型。由于我們要處理的文本沒有異常語意,所以我們直接使用訓(xùn)練好的詞向量模型來理解文字即可。
重要決定:使用預(yù)先訓(xùn)練好的詞向量模型。
但是該使用哪種詞向量映射模型?首先排除掉fastText方案,因?yàn)樗峭ㄟ^對(duì)單詞的n-gram等級(jí)求和來構(gòu)建詞向量的。而我們處理的文本中不太可能包含標(biāo)準(zhǔn)單詞表以外的詞匯(沒有拼寫錯(cuò)誤、俚語、縮寫),所以fastText這種方案沒什么優(yōu)勢(shì)。
重要決定:使用訓(xùn)練好的GloVe詞向量。
我們可以下載一些已經(jīng)訓(xùn)練好的詞向量。我選用已經(jīng)標(biāo)記好的Common Crawl數(shù)據(jù)集,它包含大量詞匯且區(qū)分大小寫,名為300d的詞向量包含300個(gè)維度。
在加載預(yù)先訓(xùn)練好的嵌入之前,我們應(yīng)該定義一些固定的參數(shù),另外還需下載一些必備的庫文件以及將類別進(jìn)行one-hot化編碼。
分割訓(xùn)練集和驗(yàn)證集
即使我們已經(jīng)有了指定的測(cè)試集,我們也最好把訓(xùn)練數(shù)據(jù)分為訓(xùn)練集和驗(yàn)證集,因?yàn)檫@有助于調(diào)參。
我將使用Keras庫中的text_to_sequences函數(shù)來保留文本中的單詞序列。同時(shí),每個(gè)單詞會(huì)根據(jù)預(yù)先訓(xùn)練好的詞向量模型映射為詞向量。不足100(max_len)個(gè)單詞的序列會(huì)填充到100個(gè),超過100(max_len)個(gè)單詞的序列只截取100個(gè),這樣學(xué)習(xí)算法的輸入向量長度就一致了。
如果文本中出現(xiàn)了生僻的單詞(沒在訓(xùn)練好的詞向量模型中),它們會(huì)被設(shè)定為0向量。
注:如果有大量單詞不在模型的詞庫中,那我們得找個(gè)更智能的方式來初始化這些單詞。
訓(xùn)練分類器
由于文本的內(nèi)容通常比較短,我將選擇使用GRU網(wǎng)絡(luò),而不用LSTM。這樣,文本內(nèi)容越短,我們對(duì)內(nèi)存的開銷就越少,而且GRU還能使學(xué)習(xí)算法效率更高。
我還會(huì)使用到早停法,這種方式可以通過驗(yàn)證集的準(zhǔn)確率來判斷是否要繼續(xù)訓(xùn)練網(wǎng)絡(luò)。當(dāng)驗(yàn)證集的準(zhǔn)確率在幾次訓(xùn)練后呈現(xiàn)為持續(xù)下降,早停法就會(huì)生效以停止訓(xùn)練。該方法還會(huì)將最有權(quán)重保存為“checkpoint”(就是本例中的model.h5),當(dāng)準(zhǔn)確度提升后還會(huì)更新權(quán)重。使用早停法,我們大可對(duì)網(wǎng)絡(luò)進(jìn)行多次訓(xùn)練,而不必?fù)?dān)心出現(xiàn)過擬合。
patience這個(gè)參數(shù)可以理解為一個(gè)閾值,用來判斷是否要提前結(jié)束訓(xùn)練。patience=3,意味著如果對(duì)全樣本進(jìn)行3次訓(xùn)練后仍沒有減少損失函數(shù),則執(zhí)行早停。
遞歸神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)比較簡單。其結(jié)構(gòu)里依次包含著有50個(gè)神經(jīng)元的雙向GRU層、池化層、全連接層、dropout層。雙向則意味著網(wǎng)絡(luò)能按照單詞出現(xiàn)的正序和逆序都進(jìn)行學(xué)習(xí)。
分類器還需優(yōu)化一下對(duì)準(zhǔn)確率這個(gè)指標(biāo)的定義。因?yàn)闇?zhǔn)確率無法辨別出人類兩種誤判中的差別。對(duì)于人的判斷而言,把0級(jí)酒預(yù)測(cè)為4級(jí)酒可能比把0級(jí)酒預(yù)測(cè)為1級(jí)酒要糟糕得多。對(duì)神經(jīng)網(wǎng)絡(luò)的判斷而言,卻看不出差別。在未來的實(shí)踐中,可以設(shè)計(jì)一個(gè)指標(biāo)來反映兩者的關(guān)系。
是時(shí)候評(píng)估模型了——祭出我們的測(cè)試集
準(zhǔn)確率高達(dá)64%!
請(qǐng)看下圖中的混淆矩陣。從矩陣中,數(shù)值以百分比的形式反映出我們樣本數(shù)據(jù)中的數(shù)據(jù)不平衡。
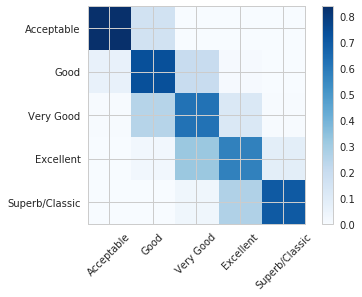
必須記住的是,由于數(shù)據(jù)樣本中關(guān)于葡萄酒的評(píng)論都比較正面,所以這個(gè)分類器僅適用于評(píng)價(jià)較好的葡萄酒。如果未來能拿到一些不一樣數(shù)據(jù)來嘗試,結(jié)果想必也會(huì)很有意思。
-
模型
+關(guān)注
關(guān)注
1文章
3500瀏覽量
50124 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8497瀏覽量
134222 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25317
原文標(biāo)題:如何在網(wǎng)上選到一瓶心儀的紅酒?通過文本分析預(yù)測(cè)葡萄酒的質(zhì)量
文章出處:【微信號(hào):BigDataDigest,微信公眾號(hào):大數(shù)據(jù)文摘】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
50多種適合機(jī)器學(xué)習(xí)和預(yù)測(cè)應(yīng)用的API,你的選擇是?(2018年版本)
pyhanlp文本分類與情感分析
50個(gè)機(jī)器學(xué)習(xí)實(shí)用API干貨
NLPIR平臺(tái)在文本分類方面的技術(shù)解析
自回歸滯后模型進(jìn)行多變量時(shí)間序列預(yù)測(cè)案例分享
50個(gè)機(jī)器學(xué)習(xí)實(shí)用API
改進(jìn)粒子群優(yōu)化神經(jīng)網(wǎng)絡(luò)的葡萄酒質(zhì)量識(shí)別
基于深度神經(jīng)網(wǎng)絡(luò)的文本分類分析

融合文本分類和摘要的多任務(wù)學(xué)習(xí)摘要模型

基于不同神經(jīng)網(wǎng)絡(luò)的文本分類方法研究對(duì)比
基于LSTM的表示學(xué)習(xí)-文本分類模型
NLP中的遷移學(xué)習(xí):利用預(yù)訓(xùn)練模型進(jìn)行文本分類
如何基于深度學(xué)習(xí)模型訓(xùn)練實(shí)現(xiàn)圓檢測(cè)與圓心位置預(yù)測(cè)

如何基于深度學(xué)習(xí)模型訓(xùn)練實(shí)現(xiàn)工件切割點(diǎn)位置預(yù)測(cè)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論