 電子發(fā)燒友App
電子發(fā)燒友App


?
NLP中的遷移學(xué)習(xí):利用預(yù)訓(xùn)練模型進(jìn)行文本分類(lèi)
- 轉(zhuǎn)換器(141068)
- 機(jī)器學(xué)習(xí)(130423)
- nlp(21784)


相關(guān)推薦
ChatGPT爆火背后,NLP呈爆發(fā)式增長(zhǎng)!
自然語(yǔ)言處理技術(shù),用于計(jì)算機(jī)中模擬人類(lèi)的對(duì)話(huà)和文本理解。主要源于AI大模型化的NLP技術(shù)突破是將深度學(xué)習(xí)技術(shù)與傳統(tǒng)的NLP方法結(jié)合在一起,從而更好地提高NLP技術(shù)的準(zhǔn)確性和效率。大模型化的NLP技術(shù)能夠更好地支持企業(yè)進(jìn)行大規(guī)模的語(yǔ)料內(nèi)容分析,并為企業(yè)更好地進(jìn)行文本分析提供幫助。 語(yǔ)言是人類(lèi)區(qū)
2023-02-13 09:47:00 2771
2771
2771一些解決文本分類(lèi)問(wèn)題的機(jī)器學(xué)習(xí)最佳實(shí)踐
文本分類(lèi)是一種應(yīng)用廣泛的算法,它是各種用于大規(guī)模處理文本數(shù)據(jù)的軟件系統(tǒng)的核心,常被用于幫助電子郵箱過(guò)濾垃圾郵件,幫助論壇機(jī)器人標(biāo)記不當(dāng)評(píng)論。
2018-07-31 09:28:416965
6965介紹用遷移學(xué)習(xí)處理NLP任務(wù)的大致思路
文本分類(lèi)是NLP領(lǐng)域重要的部分,它與現(xiàn)實(shí)生活中的場(chǎng)景密切相關(guān),例如機(jī)器人、語(yǔ)音助手、垃圾或詐騙信息監(jiān)測(cè)、文本分類(lèi)等等。這項(xiàng)技術(shù)的用途十分廣泛,幾乎可以用在任意語(yǔ)言模型上。本論文的作者進(jìn)行的是文本分類(lèi),直到現(xiàn)在,很多學(xué)術(shù)研究人員仍然用詞嵌入訓(xùn)練模型,例如word2vec和GloVe。
2018-08-02 09:18:155982
5982構(gòu)建中文網(wǎng)頁(yè)分類(lèi)器對(duì)網(wǎng)頁(yè)進(jìn)行文本分類(lèi)
特征提取就是提取出最能代表某篇文章或某類(lèi)的特征項(xiàng),以達(dá)到降維的效果從而減少文本分類(lèi)的計(jì)算量。典型特征提取方法:信息增益(Information Gain),互信息(MI)、文檔頻度(DF)。傳統(tǒng)的MI特征提取方法:
2018-09-13 08:06:003906
390650多種適合機(jī)器學(xué)習(xí)和預(yù)測(cè)應(yīng)用的API,你的選擇是?(2018年版本)
網(wǎng)絡(luò)服務(wù)上的簡(jiǎn)單JSON,被用于自然語(yǔ)言處理,能夠?qū)W(wǎng)絡(luò)新聞媒體進(jìn)行情感分析和文本分類(lèi)。9.Geneea:該API可以對(duì)提供的原始文本、從給定的URL中提取到的文本或直接提供的文檔進(jìn)行分析
2018-05-03 16:41:16
遷移學(xué)習(xí)
的基本原理和編程思想。理解在一個(gè)新的場(chǎng)景或數(shù)據(jù)集下,何時(shí)以及如何進(jìn)行遷移學(xué)習(xí)。利用PyTorch加載數(shù)據(jù)、搭建模型、訓(xùn)練網(wǎng)絡(luò)以及進(jìn)行網(wǎng)絡(luò)微調(diào)操作。給定遷移場(chǎng)景,利用daib庫(kù)和生成對(duì)抗技術(shù)獨(dú)立完成圖像分類(lèi)中
2022-04-21 15:15:11
Edge Impulse的分類(lèi)模型淺析
Edge Impulse是一個(gè)應(yīng)用于嵌入式領(lǐng)域的在線的機(jī)器學(xué)習(xí)網(wǎng)站,不僅為用戶(hù)提供了一些現(xiàn)成的神經(jīng)網(wǎng)絡(luò)模型以供訓(xùn)練,還能直接將訓(xùn)練好的模型轉(zhuǎn)換成能在單片機(jī)MCU上運(yùn)行的代碼,使用方便,容易上手。本文
2021-12-20 06:51:26
NLPIR平臺(tái)在文本分類(lèi)方面的技術(shù)解析
文本分類(lèi)問(wèn)題就是將一篇文檔歸入預(yù)先定義的幾個(gè)類(lèi)別中的一個(gè)或幾個(gè),而文本的自動(dòng)分類(lèi)則是使用計(jì)算機(jī)程序來(lái)實(shí)現(xiàn)這種文本分類(lèi),即根據(jù)事先指定的規(guī)則和示例樣本,自動(dòng)從海量文檔中識(shí)別并訓(xùn)練分類(lèi),文本為大家講解
2019-11-18 17:46:10
Pytorch模型訓(xùn)練實(shí)用PDF教程【中文】
本教程以實(shí)際應(yīng)用、工程開(kāi)發(fā)為目的,著重介紹模型訓(xùn)練過(guò)程中遇到的實(shí)際問(wèn)題和方法。在機(jī)器學(xué)習(xí)模型開(kāi)發(fā)中,主要涉及三大部分,分別是數(shù)據(jù)、模型和損失函數(shù)及優(yōu)化器。本文也按順序的依次介紹數(shù)據(jù)、模型和損失函數(shù)
2018-12-21 09:18:02
pyhanlp文本分類(lèi)與情感分析
關(guān)系如下:訓(xùn)練訓(xùn)練指的是,利用給定訓(xùn)練集尋找一個(gè)能描述這種語(yǔ)言現(xiàn)象的模型的過(guò)程。開(kāi)發(fā)者只需調(diào)用train接口即可,但在實(shí)現(xiàn)中,有許多細(xì)節(jié)。分詞目前,本系統(tǒng)中的分詞器接口一共有兩種實(shí)現(xiàn): 但文本分類(lèi)是否
2019-02-20 15:37:24
【KV260視覺(jué)入門(mén)套件試用體驗(yàn)】Vitis AI 通過(guò)遷移學(xué)習(xí)訓(xùn)練自定義模型
使用inspector檢查模型
六、Vitis AI 進(jìn)行模型校準(zhǔn)和來(lái)量化
七、Vitis AI 通過(guò)遷移學(xué)習(xí)訓(xùn)練自定義模型
八、Vitis AI 將自定義模型編譯并部署到KV260中
本文目的
使用遷移
2023-10-16 15:03:16
九眼公共安全語(yǔ)義智能分析平臺(tái),實(shí)現(xiàn)文本分析的公共安全應(yīng)用
社會(huì)和科技的進(jìn)步和現(xiàn)在行業(yè)對(duì)數(shù)據(jù)的利用率提高有很大關(guān)系,各行各業(yè)積累的數(shù)據(jù)量均在增加,公安領(lǐng)域也包括在內(nèi),有大量的案件信息數(shù)據(jù)需要進(jìn)行文本分析。 現(xiàn)在的公安部門(mén)均使用信息管理系統(tǒng)管理數(shù)據(jù),在實(shí)現(xiàn)
2019-10-08 15:56:16
使用KNN進(jìn)行分類(lèi)和回歸
奇數(shù)。與分類(lèi)任務(wù)不同,在回歸任務(wù)中,特征向量與實(shí)值標(biāo)量而不是標(biāo)簽相關(guān)聯(lián),KNN是通過(guò)對(duì)響應(yīng)變量均值或加權(quán)均值來(lái)進(jìn)行預(yù)測(cè)。惰性學(xué)習(xí)和非參數(shù)模型惰性學(xué)習(xí)是 KNN 的標(biāo)志。惰性學(xué)習(xí)器,也稱(chēng)為基于實(shí)例的學(xué)習(xí)器
2022-10-28 14:44:46
基于Keras利用訓(xùn)練好的hdf5模型進(jìn)行目標(biāo)檢測(cè)實(shí)現(xiàn)輸出模型中的表情或性別gradcam
CV:基于Keras利用訓(xùn)練好的hdf5模型進(jìn)行目標(biāo)檢測(cè)實(shí)現(xiàn)輸出模型中的臉部表情或性別的gradcam(可視化)
2018-12-27 16:48:28
基于稀疏編碼的遷移學(xué)習(xí)及其在行人檢測(cè)中的應(yīng)用
一定進(jìn)展,但大都需要大量的訓(xùn)練數(shù)據(jù).針對(duì)這一問(wèn)題,提出了一種基于遷移學(xué)習(xí)的半監(jiān)督行人分類(lèi)方法:首先基于稀疏編碼,從任意的未標(biāo)記樣本中,學(xué)習(xí)到一個(gè)緊湊、有效的特征表示;然后通過(guò)遷移學(xué)習(xí),將學(xué)習(xí)到的特征表示
2010-04-24 09:48:05
機(jī)器學(xué)習(xí)簡(jiǎn)介與經(jīng)典機(jī)器學(xué)習(xí)算法人才培養(yǎng)
思想。理解在一個(gè)新的場(chǎng)景或數(shù)據(jù)集下,何時(shí)以及如何進(jìn)行遷移學(xué)習(xí)。利用PyTorch加載數(shù)據(jù)、搭建模型、訓(xùn)練網(wǎng)絡(luò)以及進(jìn)行網(wǎng)絡(luò)微調(diào)操作。給定遷移場(chǎng)景,利用daib庫(kù)和生成對(duì)抗技術(shù)獨(dú)立完成圖像分類(lèi)中的領(lǐng)域適配
2022-04-28 18:56:07
深入挖掘通用句子編碼器的每個(gè)組成部分
檢測(cè)、聚類(lèi)、智能回復(fù)、文本分類(lèi)和許多其他NLP任務(wù)。結(jié)果需要注意的是,在USE論文中沒(méi)有一個(gè)章節(jié)是關(guān)于與其他的句子嵌入方法在標(biāo)準(zhǔn)基準(zhǔn)上的比較。這篇論文似乎是從工程學(xué)的角度出發(fā),從Gmail和谷歌Books的Inbox等產(chǎn)品中汲取了經(jīng)驗(yàn)。原作者:Amit Chaudhary
2022-11-02 15:23:25
基于文章標(biāo)題信息的漢語(yǔ)自動(dòng)文本分類(lèi)
文本分類(lèi)是文本挖掘的一個(gè)重要組成部分,是信息搜索領(lǐng)域的一項(xiàng)重要研究課題。該文提出一種基于文章標(biāo)題信息的漢語(yǔ)自動(dòng)文本分類(lèi)方法,在HNC理論的領(lǐng)域概念框架下,通過(guò)標(biāo)題
2009-04-13 08:31:16 10
10
10基于GA和信息熵的文本分類(lèi)規(guī)則抽取方法
文本分類(lèi)是文本數(shù)據(jù)挖掘中一個(gè)非常重要的技術(shù),已經(jīng)被廣泛地應(yīng)用于信息管理、搜索引擎、推薦系統(tǒng)等多個(gè)領(lǐng)域。現(xiàn)有的文本分類(lèi)方法,大多是基于向量空間模型的算法。這
2009-06-03 09:22:5026
26用于文本分類(lèi)和文本聚類(lèi)的特征抽取方法的研究
文本信息處理已成為一門(mén)日趨成熟、應(yīng)用面日趨廣泛的學(xué)科。文本分類(lèi)和聚類(lèi)技術(shù)是應(yīng)信息檢索和查詢(xún)需要而出現(xiàn)的自然語(yǔ)言處理領(lǐng)域的重要研究課題。面對(duì)急速膨脹的各種文本信
2009-12-22 14:19:463
3基于Rough集的web文本分類(lèi)研究
隨著Internet的飛速發(fā)展,網(wǎng)絡(luò)上的web信息資源迅速膨脹,如何在浩瀚的web文本信息資源中高效精確地挖掘出有用的知識(shí)已經(jīng)成為目前的研究熱點(diǎn)之一。本文首先介紹了web文本分類(lèi)
2010-01-27 13:39:414
4基于文本分類(lèi)計(jì)數(shù)識(shí)別平臺(tái)設(shè)計(jì)(JAVA實(shí)現(xiàn))
根據(jù)電力企業(yè)輿情管控工作的需要,設(shè)計(jì)了一種基于文本分類(lèi)技術(shù)的企業(yè)輿情主題識(shí)別實(shí)驗(yàn)平臺(tái),技術(shù)人員只需根據(jù)需要設(shè)定文本分類(lèi)中不同的基本參數(shù),即可針對(duì)相應(yīng)的輿情文本測(cè)試不同參數(shù)方案下主題文本的識(shí)別效果
2017-10-30 17:26:3611
11基于apiori算法改進(jìn)的knn文本分類(lèi)方法
的,通過(guò)實(shí)例去學(xué)習(xí)分類(lèi)在這方面就很有優(yōu)勢(shì)。 一般的文本分類(lèi)分為這幾個(gè)步驟,首先是建立文檔的表示模型,即通過(guò)若干特征去表示一個(gè)文本,因?yàn)橐话闱闆r下一篇文章都有著成百上千的特征向量,直接進(jìn)行分類(lèi)會(huì)有很大的時(shí)間和空
2017-11-09 10:25:029
9文本分類(lèi)中CTM模型的優(yōu)化和可視化應(yīng)用研究
如何從海量文本中自動(dòng)提取相關(guān)信息已成為巨大的技術(shù)挑戰(zhàn),文本分類(lèi)作為解決該問(wèn)題的重要方法已引起廣大關(guān)注,而其中文本表示是影響分類(lèi)效果的關(guān)鍵因素。為此采用相關(guān)主題模型進(jìn)行文本表示,以保證信息完整同時(shí)表現(xiàn)
2017-11-22 10:46:3010
10融合詞語(yǔ)類(lèi)別特征和語(yǔ)義的短文本分類(lèi)方法
LDA主題模型從背景知識(shí)中選擇最優(yōu)主題形成新的短文本特征,在此基礎(chǔ)上建立分類(lèi)器進(jìn)行分類(lèi)。采用支持向量機(jī)SVM與是近鄰法k-NN分類(lèi)器對(duì)搜狗語(yǔ)料庫(kù)數(shù)據(jù)集上的搜狐新聞標(biāo)題內(nèi)容進(jìn)行分類(lèi),實(shí)驗(yàn)結(jié)果表明該方法對(duì)提高短文本分類(lèi)的性能是
2017-11-22 16:29:580
0基于超像素融合的文本分割
超像素分割并融合;最后利用超像素融合的局部相似性對(duì)初始二值化圖像進(jìn)行文本校驗(yàn)。實(shí)驗(yàn)結(jié)果表明,與最大穩(wěn)定極值區(qū)域( MSER)及筆畫(huà)超像素聚合(SSG)方法相比,所提方法在KAIST數(shù)據(jù)集上的分割精度分別提高了8. 00個(gè)百分點(diǎn)和
2017-12-08 16:59:181
1基于KNN的煙草企業(yè)檔案文本分類(lèi)
通過(guò)對(duì)云南某卷煙廠歷史檔案文本數(shù)據(jù)的分析研究,結(jié)合實(shí)際情況,對(duì)檔案文本主題詞的獲取和自動(dòng)分類(lèi)算法進(jìn)行了詳細(xì)的設(shè)計(jì)。且在主題詞獲取算法中引入了TFIDF算法,解決了檔案文本缺少題名、文號(hào)及責(zé)任者
2017-12-12 18:04:470
0基于多模態(tài)特征數(shù)據(jù)的多標(biāo)記遷移學(xué)習(xí)方法的早期阿爾茨海默病診斷
特征選擇模塊和多模態(tài)多標(biāo)記分類(lèi)回歸學(xué)習(xí)器模塊。首先,通過(guò)稀疏多標(biāo)記學(xué)習(xí)模型對(duì)分類(lèi)和回歸學(xué)習(xí)任務(wù)進(jìn)行有效結(jié)合;然后,將該模型擴(kuò)展到來(lái)自多個(gè)學(xué)習(xí)領(lǐng)域的訓(xùn)練集,從而構(gòu)建出多標(biāo)記遷移學(xué)習(xí)特征選擇模型;接下來(lái),針對(duì)異
2017-12-14 11:22:373
3基于直推判別字典學(xué)習(xí)的零樣本分類(lèi)方法
零樣本分類(lèi)的目標(biāo)是對(duì)訓(xùn)練階段未出現(xiàn)過(guò)的類(lèi)別的樣本進(jìn)行識(shí)別和分類(lèi),其主要思路是,借助類(lèi)別語(yǔ)義信息,將可見(jiàn)類(lèi)別的知識(shí)轉(zhuǎn)移到未見(jiàn)類(lèi)別中.提出了一種直推式的字典學(xué)習(xí)方法,包含以下兩個(gè)步驟:首先,提出一個(gè)判別
2017-12-25 10:15:440
0詳細(xì)解析scikit-learn進(jìn)行文本分類(lèi)
而多類(lèi)別分類(lèi)指的是y的可能取值大于2,但是y所屬類(lèi)別是唯一的。它與多標(biāo)簽分類(lèi)問(wèn)題是有嚴(yán)格區(qū)別的。所有的scikit-learn分類(lèi)器都是默認(rèn)支持多類(lèi)別分類(lèi)的。但是,當(dāng)你需要自己修改算法的時(shí)候,也是可以使用scikit-learn實(shí)現(xiàn)多類(lèi)別分類(lèi)的前期數(shù)據(jù)準(zhǔn)備的。
2017-12-27 08:36:014385
4385
基于分布特征遷移加權(quán)算法
傳統(tǒng)機(jī)器學(xué)習(xí)面臨一個(gè)難題,即當(dāng)訓(xùn)練數(shù)據(jù)與測(cè)試數(shù)據(jù)不再服從相同分布時(shí),由訓(xùn)練集得到的分類(lèi)器無(wú)法對(duì)測(cè)試集文本準(zhǔn)確分類(lèi)。針對(duì)該問(wèn)題,根據(jù)遷移學(xué)習(xí)原理,在源領(lǐng)域和目標(biāo)領(lǐng)域的交集特征中,依據(jù)改進(jìn)的特征分布相似
2018-01-09 14:49:360
0一種新型樸素貝葉斯文本分類(lèi)算法
針對(duì)在文本分類(lèi)中先驗(yàn)概率的計(jì)算比較費(fèi)時(shí)而且對(duì)分類(lèi)效果影響不大、后驗(yàn)概率的精度損失影響分類(lèi)準(zhǔn)確率的現(xiàn)象,對(duì)經(jīng)典樸素貝葉斯分類(lèi)算法進(jìn)行了改進(jìn),提出了一種先抑后揚(yáng)(抑制先驗(yàn)概率的作用,擴(kuò)大后驗(yàn)概率
2018-03-05 11:19:590
0如何用更少的數(shù)據(jù)自動(dòng)將文本分類(lèi),同時(shí)精確度還比原來(lái)的方法高
計(jì)算機(jī)視覺(jué)領(lǐng)域遷移學(xué)習(xí)和預(yù)訓(xùn)練ImageNet模型的成功已經(jīng)轉(zhuǎn)移到了NLP領(lǐng)域。許多企業(yè)家、科學(xué)家和工程師目前都用調(diào)整過(guò)的ImageNet模型解決重要的視覺(jué)問(wèn)題,現(xiàn)在這款工具已經(jīng)能用于語(yǔ)言處理,我們希望看到這一領(lǐng)域會(huì)有更多相關(guān)應(yīng)用產(chǎn)生。
2018-05-21 15:53:056150
6150
NLP的介紹和如何利用機(jī)器學(xué)習(xí)進(jìn)行NLP以及三種NLP技術(shù)的詳細(xì)介紹
本文用簡(jiǎn)潔易懂的語(yǔ)言,講述了自然語(yǔ)言處理(NLP)的前世今生。從什么是NLP到為什么要學(xué)習(xí)NLP,再到如何利用機(jī)器學(xué)習(xí)進(jìn)行NLP,值得一讀。這是該系列的第一部分,介紹了三種NLP技術(shù):文本嵌入、機(jī)器翻譯、Dialogue 和 Conversations。
2018-06-10 10:26:1076462
76462
一個(gè)深度學(xué)習(xí)模型能完成幾項(xiàng)NLP任務(wù)?
對(duì)于機(jī)器翻譯、文本摘要、Q&A、文本分類(lèi)等自然語(yǔ)言處理任務(wù)來(lái)說(shuō),深度學(xué)習(xí)的出現(xiàn)一遍遍刷新了state-of-the-art的模型性能記錄,給研究帶來(lái)諸多驚喜。但這些任務(wù)一般都有各自的度量基準(zhǔn),性能也只在一組標(biāo)準(zhǔn)數(shù)據(jù)集上測(cè)試。
2018-06-26 15:19:094233
4233什么是遷移學(xué)習(xí)?NLP遷移學(xué)習(xí)的未來(lái)
只用了100個(gè)案例,他們就達(dá)到了和用2萬(wàn)個(gè)案例訓(xùn)練出的模型同樣的錯(cuò)誤率水平。除此之外,他們還提供了對(duì)模型進(jìn)行預(yù)訓(xùn)練的代碼,因?yàn)榫S基百科有多種語(yǔ)言,這使得我們能快速地進(jìn)行語(yǔ)言轉(zhuǎn)換。除英語(yǔ)之外,其他語(yǔ)種并沒(méi)有很多經(jīng)過(guò)標(biāo)記的公開(kāi)數(shù)據(jù)集,所以你可以在語(yǔ)言模型上對(duì)自己的數(shù)據(jù)進(jìn)行微調(diào)。
2018-08-17 09:18:183649
3649面向NLP任務(wù)的遷移學(xué)習(xí)新模型ULMFit
除了能夠更快地進(jìn)行訓(xùn)練之外,遷移學(xué)習(xí)也是特別有趣的,僅在最后一層進(jìn)行訓(xùn)練,讓我們可以?xún)H僅使用較少的標(biāo)記數(shù)據(jù),而對(duì)整個(gè)模型進(jìn)行端對(duì)端訓(xùn)練則需要龐大的數(shù)據(jù)集。標(biāo)記數(shù)據(jù)的成本很高,在無(wú)需大型數(shù)據(jù)集的情況下建立高質(zhì)量的模型是很可取的方法。
2018-08-22 08:11:545410
5410如何使用CNN和BiLSTM網(wǎng)絡(luò)特征融合進(jìn)行文本情感分析
卷積神經(jīng)網(wǎng)絡(luò)( CNN)和循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)在自然語(yǔ)言處理,上得到廣泛應(yīng)用,但由于自然語(yǔ)言在結(jié)構(gòu)上存在著前后依賴(lài)關(guān)系,僅依靠卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)文本分類(lèi)將忽略詞的上下文含義,且傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò)存在梯度消失或梯度爆炸問(wèn)題,限制了文本分類(lèi)的準(zhǔn)確率。
2018-11-22 16:01:459
9NVIDIA遷移學(xué)習(xí)工具包 :用于特定領(lǐng)域深度學(xué)習(xí)模型快速訓(xùn)練的高級(jí)SDK
,并在 TeslaGPU 上使用 DeepStream SDK 3.0 進(jìn)行部署。這些模型針對(duì) IVA 特定參考使用場(chǎng)景(如檢測(cè)和分類(lèi))進(jìn)行了全面地訓(xùn)練。
2018-12-07 14:45:472848
2848如何使用Spark計(jì)算框架進(jìn)行分布式文本分類(lèi)方法的研究
針對(duì)傳統(tǒng)文本分類(lèi)算法在面對(duì)日益增多的海量文本數(shù)據(jù)時(shí)效率低下的問(wèn)題,論文在Spark計(jì)算框架上設(shè)計(jì)并實(shí)現(xiàn)了一種并行化樸素貝葉斯文本分類(lèi)器,并著重介紹了基于Spark計(jì)算框架的文本分類(lèi)實(shí)現(xiàn)過(guò)程。實(shí)驗(yàn)階段
2018-12-18 14:19:573
3使用深度模型遷移進(jìn)行細(xì)粒度圖像分類(lèi)的方法說(shuō)明
針對(duì)細(xì)粒度圖像分類(lèi)方法中存在模型復(fù)雜度較高、難以利用較深模型等問(wèn)題,提出深度模型遷移( DMT)分類(lèi)方法。首先,在粗粒度圖像數(shù)據(jù)集上進(jìn)行深度模型預(yù)訓(xùn)練;然后,使用細(xì)粒度圖像數(shù)據(jù)集對(duì)預(yù)訓(xùn)練模型
2019-01-18 17:01:505
5SiATL——最新、最簡(jiǎn)易的遷移學(xué)習(xí)方法
許多傳統(tǒng)的遷移學(xué)習(xí)方法都是利用預(yù)先訓(xùn)練好的語(yǔ)言模型(LMs)來(lái)實(shí)現(xiàn)的,這些模型已經(jīng)非常流行,并且具有翻譯上下文信息的能力、高級(jí)建模語(yǔ)法和語(yǔ)義語(yǔ)言特性,能夠在對(duì)象識(shí)別、機(jī)器翻譯、文本分類(lèi)等許多任務(wù)中生成高質(zhì)量的結(jié)果。
2019-03-12 15:13:593319
3319
深度學(xué)習(xí)框架PaddlePaddle在百度內(nèi)部的戰(zhàn)略地位進(jìn)行了定調(diào)
服務(wù)平臺(tái)則主要由可定制化訓(xùn)練深度學(xué)習(xí)模型的EasyDL以及一站式開(kāi)發(fā)平臺(tái)AI Studio組成。EasyDL目前已經(jīng)支持圖像識(shí)別、文本分類(lèi)、聲音分類(lèi)等深度學(xué)習(xí)模型的訓(xùn)練,而AI Studio則集合了AI教程、代碼環(huán)境、算法算力、數(shù)據(jù)集和比賽,屬于百度大腦的深度學(xué)習(xí)實(shí)訓(xùn)平臺(tái)。
2019-04-29 10:58:194537
4537
如何結(jié)合改進(jìn)主動(dòng)學(xué)習(xí)的SVD-CNN進(jìn)行彈幕文本分類(lèi)算法資料說(shuō)明
采樣的主動(dòng)學(xué)習(xí)算法(DBC-AL)選擇對(duì)分類(lèi)模型貢獻(xiàn)率較高的樣本進(jìn)行標(biāo)注,以低標(biāo)注代價(jià)獲得高質(zhì)量模型訓(xùn)練集;然后,結(jié)合SVD算法建立SVD-CNN彈幕文本分類(lèi)模型,使用奇異值分解的方法代替?zhèn)鹘y(tǒng)CNN模型池化層進(jìn)行特征提取和降維,并在此基礎(chǔ)上完成彈幕文
2019-05-06 11:42:476
6訓(xùn)練一個(gè)機(jī)器學(xué)習(xí)模型,實(shí)現(xiàn)了根據(jù)基于文本分析預(yù)測(cè)葡萄酒質(zhì)量
我們可以把上述的其他信息也引入作為特征參數(shù),這樣就能構(gòu)建出一個(gè)更全面的模型來(lái)預(yù)測(cè)葡萄酒質(zhì)量。為了將文字描述與其他特征結(jié)合起來(lái)進(jìn)行預(yù)測(cè),我們可以創(chuàng)建一個(gè)集成學(xué)模型(文本分類(lèi)器就是集成在內(nèi)的一部分);也可以創(chuàng)建一個(gè)層級(jí)模型,在層級(jí)模型中,分類(lèi)器的輸出會(huì)作為一個(gè)預(yù)測(cè)變量。
2019-05-16 18:27:395662
56628個(gè)免費(fèi)學(xué)習(xí)NLP的在線資源
此在線課程涵蓋從基礎(chǔ)到高級(jí)NLP,它是Coursera上高級(jí)機(jī)器學(xué)習(xí)專(zhuān)業(yè)化的一部分。你可以免費(fèi)注冊(cè)本課程,你將學(xué)習(xí)情緒分析、總結(jié)、對(duì)話(huà)狀態(tài)跟蹤等。你將學(xué)習(xí)的主題包括文本分類(lèi)介紹、語(yǔ)言建模和序列標(biāo)記、語(yǔ)義向量空間模型、序列到序列任務(wù)等等。
2019-07-07 07:44:006408
6408遷移學(xué)習(xí)與模型預(yù)訓(xùn)練:何去何從
把我們當(dāng)前要處理的NLP任務(wù)叫做T(T稱(chēng)為目標(biāo)任務(wù)),遷移學(xué)習(xí)技術(shù)做的事是利用另一個(gè)任務(wù)S(S稱(chēng)為源任務(wù))來(lái)提升任務(wù)T的效果,也即把S的信息遷移到T中。至于怎么遷移信息就有很多方法了,可以直接利用S的數(shù)據(jù),也可以利用在S上訓(xùn)練好的模型,等等。
2019-07-18 11:29:477440
7440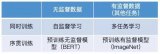
NLP遷移學(xué)習(xí)面臨的問(wèn)題和解決
自然語(yǔ)言處理(NLP)最近取得了巨大的進(jìn)步,每隔幾天就會(huì)發(fā)布最新的結(jié)果。排行榜瘋狂是指最常見(jiàn)的NLP基準(zhǔn),如GLUE和SUPERGLUE,它們的得分越來(lái)越接近人類(lèi)的水平。這些結(jié)果大多是通過(guò)超大(數(shù)十億個(gè)參數(shù))模型從大規(guī)模數(shù)據(jù)集中遷移學(xué)習(xí)得到的。
2020-05-04 12:03:002821
2821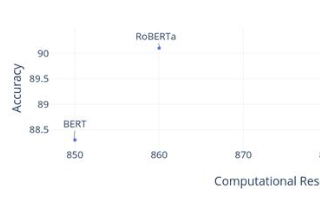
如何利用機(jī)器學(xué)習(xí)思想,更好地去解決NLP分類(lèi)任務(wù)
NLP分類(lèi)任務(wù)我們每個(gè)NLPer都異常熟悉了,其在整個(gè)NLP業(yè)務(wù)中占據(jù)著舉足輕重的地位,更多領(lǐng)域的子任務(wù)也常常轉(zhuǎn)化為一個(gè)分類(lèi)任務(wù),例如新聞分類(lèi)、情感識(shí)別、意圖識(shí)別、關(guān)系分類(lèi)、事件類(lèi)型判斷等等。
2020-08-28 10:02:211901
1901
NLP中文自然語(yǔ)言處理數(shù)據(jù)集、平臺(tái)和工具整理
資源整理了文本分類(lèi)、實(shí)體識(shí)別詞性標(biāo)注、搜索匹配、推薦系統(tǒng)、指代消歧、百科數(shù)據(jù)、預(yù)訓(xùn)練詞向量or模型、中文完形填空等大量數(shù)據(jù)集,中文數(shù)據(jù)集平臺(tái)和NLP工具等。 本文內(nèi)容整理自:https
2020-11-05 09:29:062443
2443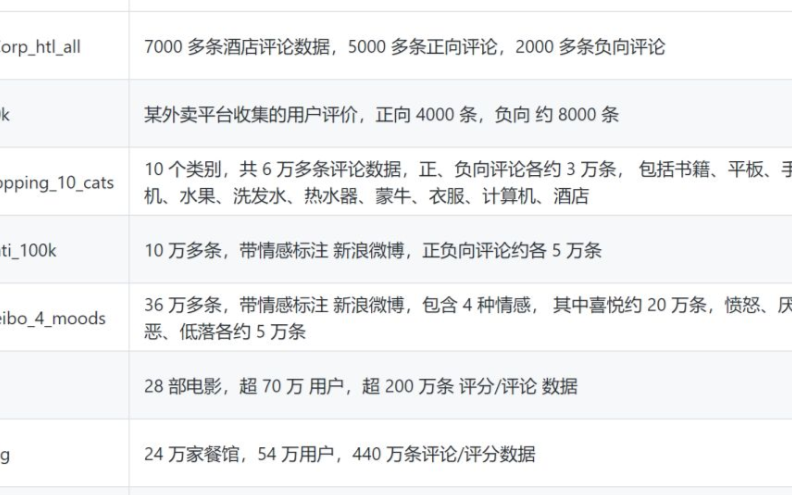
textCNN論文與原理——短文本分類(lèi)
包是處理圖片的torchvision,而處理文本的少有提及,快速處理文本數(shù)據(jù)的包也是有的,那就是torchtext[1]。下面還是結(jié)合上一個(gè)案例:【深度學(xué)習(xí)】textCNN論文與原理——短文本分類(lèi)(基于pytorch)[2],使用torchtext進(jìn)行文本數(shù)據(jù)預(yù)處理,然后再使用torchtext進(jìn)
2020-12-31 10:08:422217
2217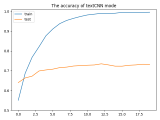
小米在預(yù)訓(xùn)練模型的探索與優(yōu)化
大家?guī)?lái)小米在預(yù)訓(xùn)練模型的探索與優(yōu)化。 01 預(yù)訓(xùn)練簡(jiǎn)介 預(yù)訓(xùn)練與詞向量的方法一脈相承。詞向量是從任務(wù)無(wú)關(guān)和大量的無(wú)監(jiān)督語(yǔ)料中學(xué)習(xí)到詞的分布式表達(dá),即文檔中詞的向量化表達(dá)。在得到詞向量之后,一般會(huì)輸入到下游任務(wù)中,進(jìn)行后續(xù)的計(jì)
2020-12-31 10:17:112217
2217
NLP:序列標(biāo)注
0 小系列初衷 自己接觸的項(xiàng)目大都是初創(chuàng),沒(méi)開(kāi)始多久的項(xiàng)目,從0到1的不少,2020年快結(jié)束,感覺(jué)這個(gè)具有一定個(gè)人特色的技術(shù)經(jīng)驗(yàn)可以在和大家分享一下。 計(jì)劃篇章: (已完成)文本分類(lèi)篇。針對(duì)NLP
2021-01-13 09:46:212243
2243深度學(xué)習(xí):基于語(yǔ)境的文本分類(lèi)弱監(jiān)督學(xué)習(xí)
高成本的人工標(biāo)簽使得弱監(jiān)督學(xué)習(xí)備受關(guān)注。seed-driven 是弱監(jiān)督學(xué)習(xí)中的一種常見(jiàn)模型。該模型要求用戶(hù)提供少量的seed words,根據(jù)seed words對(duì)未標(biāo)記的訓(xùn)練數(shù)據(jù)生成偽標(biāo)簽,增加訓(xùn)練
2021-01-18 16:04:272657
2657一種處理多標(biāo)簽文本分類(lèi)的新穎推理機(jī)制
研究動(dòng)機(jī) 多標(biāo)簽文本分類(lèi)(multi-label text classification, 簡(jiǎn)稱(chēng)MLTC)的目的是在給定文本后要求模型預(yù)測(cè)其多個(gè)非互斥的相關(guān)標(biāo)簽。該任務(wù)在許多自然語(yǔ)言處理任務(wù)上都有
2021-02-05 09:21:132593
2593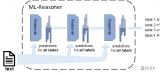
文本分類(lèi)的一個(gè)大型“真香現(xiàn)場(chǎng)”來(lái)了
任何標(biāo)注數(shù)據(jù)啦!哇,真香! 當(dāng)前的文本分類(lèi)任務(wù)需要利用眾多標(biāo)注數(shù)據(jù),標(biāo)注成本是昂貴的。而半監(jiān)督文本分類(lèi)雖然減少了對(duì)標(biāo)注數(shù)據(jù)的依賴(lài),但還是需要領(lǐng)域?qū)<沂謩?dòng)進(jìn)行標(biāo)注,特別是在類(lèi)別數(shù)目很大的情況下。 試想一下,我們?nèi)祟?lèi)是如何對(duì)新聞文本進(jìn)行分
2021-02-05 11:02:241596
1596
fastText有兩大用途——文本分類(lèi)和Word Embedding
N-gram 是一種基于統(tǒng)計(jì)語(yǔ)言模型的算法,常用于 NLP 領(lǐng)域。其思想在于將文本內(nèi)容按照字節(jié)順序進(jìn)行大小為 N 的滑動(dòng)窗口操作,從而形成了長(zhǎng)度為 N 的字節(jié)片段序列,其片段我們稱(chēng)為 gram。
2021-03-05 15:38:542910
2910
基于深度神經(jīng)網(wǎng)絡(luò)的文本分類(lèi)分析
隨著深度學(xué)習(xí)技術(shù)的快速發(fā)展,許多研究者嘗試利用深度學(xué)習(xí)來(lái)解決文本分類(lèi)問(wèn)題,特別是在卷積神經(jīng)網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)方面,出現(xiàn)了許多新穎且有效的分類(lèi)方法。對(duì)基于深度神經(jīng)網(wǎng)絡(luò)的文本分類(lèi)問(wèn)題進(jìn)行分析,介紹
2021-03-10 16:56:5636
36結(jié)合BERT模型的中文文本分類(lèi)算法
針對(duì)現(xiàn)有中文短文夲分類(lèi)算法通常存在特征稀疏、用詞不規(guī)范和數(shù)據(jù)海量等問(wèn)題,提出一種基于Transformer的雙向編碼器表示(BERT)的中文短文本分類(lèi)算法,使用BERT預(yù)訓(xùn)練語(yǔ)言模型對(duì)短文本進(jìn)行句子
2021-03-11 16:10:396
6一種基于神經(jīng)網(wǎng)絡(luò)的短文本分類(lèi)模型
、詞向量以及短文本的概念集作為模型的輸入,運(yùn)用編碼器-解碼器模型對(duì)短文本與概念集進(jìn)行編碼,利用注意力機(jī)制計(jì)算每個(gè)概念權(quán)重值,減小無(wú)關(guān)噪聲概念對(duì)短文本分類(lèi)的影響,在此基礎(chǔ)上通過(guò)雙向門(mén)控循環(huán)單元編碼短文本輸入序
2021-03-12 14:07:477
7集成WL-CNN和SL-Bi-LSTM的旅游問(wèn)句文本分類(lèi)算法
學(xué)習(xí)詞序列子空間向量和句序列深層語(yǔ)義信息,通過(guò)多頭注意力機(jī)制將兩種深度學(xué)習(xí)模型進(jìn)行集成以實(shí)現(xiàn)旅游問(wèn)句文本的語(yǔ)法和語(yǔ)義信息互補(bǔ),并通過(guò) Softmax分類(lèi)器得到最終的旅游問(wèn)句文本分類(lèi)結(jié)果。實(shí)驗(yàn)結(jié)果表明,與基于傳統(tǒng)深度學(xué)習(xí)模型的旅游問(wèn)句文本分類(lèi)算法相比,該算法在準(zhǔn)
2021-03-17 15:24:344
4一種側(cè)重于學(xué)習(xí)情感特征的預(yù)訓(xùn)練方法
transformers編碼表示)的基礎(chǔ)上,提岀了一種側(cè)重學(xué)習(xí)情感特征的預(yù)訓(xùn)練方法。在目標(biāo)領(lǐng)域的預(yù)練階段,利用情感詞典改進(jìn)了BERT的預(yù)訓(xùn)練任務(wù)。同時(shí),使用基于上下文的詞粒度情感預(yù)測(cè)任務(wù)對(duì)掩蓋詞情感極性進(jìn)行分類(lèi),獲取偏向情感特征的文本表
2021-04-13 11:40:514
4一種基于BERT模型的社交電商文本分類(lèi)算法
基于BERT模型的社交電商文本分類(lèi)算法。首先,該算法采用BERT( Bidirectional Encoder Representations from Transformers)預(yù)訓(xùn)練語(yǔ)言模型來(lái)完成社交電商文本的句子層面的特征向量表示,隨后有針對(duì)性地將獲得的特征向量輸入分類(lèi)器進(jìn)行分類(lèi),最后采
2021-04-13 15:14:218
8基于BERT+Bo-LSTM+Attention的病歷短文分類(lèi)模型
病歷文本的提取與自動(dòng)分類(lèi)的方法具有很大的臨床價(jià)值。文中嘗試提出一種基于BERT十 BI-LSTM+ Attention融合的病歷短文本分類(lèi)模型。使用BERT預(yù)處理獲取短文本向量作為模型輸入,對(duì)比BERT與 word2vec模型的預(yù)訓(xùn)練效果,對(duì)比Bⅰ-LSTM十 Atten
2021-04-26 14:30:2013
13融合文本分類(lèi)和摘要的多任務(wù)學(xué)習(xí)摘要模型
質(zhì)量,使用K- means聚類(lèi)算法構(gòu)建 Cluster-2、 Cluster-10和 Cluster-20文本分類(lèi)數(shù)據(jù)集訓(xùn)練分類(lèi)器,并研究不同分類(lèi)數(shù)據(jù)集參與訓(xùn)練對(duì)摘要模型的性能影響,同時(shí)利用基于統(tǒng)計(jì)分布的判別法全面評(píng)價(jià)摘要準(zhǔn)確性。在CNNDM測(cè)試集上的實(shí)驗(yàn)結(jié)果表明,
2021-04-27 16:18:5811
11基于BERT的中文科技NLP預(yù)訓(xùn)練模型
深度學(xué)習(xí)模型應(yīng)用于自然語(yǔ)言處理任務(wù)時(shí)依賴(lài)大型、高質(zhì)量的人工標(biāo)注數(shù)據(jù)集。為降低深度學(xué)習(xí)模型對(duì)大型數(shù)據(jù)集的依賴(lài),提出一種基于BERT的中文科技自然語(yǔ)言處理預(yù)訓(xùn)練模型 ALICE。通過(guò)對(duì)遮罩語(yǔ)言模型進(jìn)行
2021-05-07 10:08:1614
14基于主題相似度聚類(lèi)的文本分類(lèi)算法綜述
傳統(tǒng)的文本分類(lèi)方法僅使用一種模型進(jìn)行分類(lèi),容易忽略不同類(lèi)別特征詞出現(xiàn)交叉的情況,影響分類(lèi)性能。為提高文本分類(lèi)的準(zhǔn)確率,提岀基于主題相似性聚類(lèi)的文本分類(lèi)算法。通過(guò)CH和 Wordcount相結(jié)合的方法
2021-05-12 16:25:206
6基于協(xié)同訓(xùn)練的電商領(lǐng)域文本短語(yǔ)挖掘方法
電商領(lǐng)域的文本通常不遵循通用領(lǐng)域文本的表達(dá)方式,導(dǎo)致傳統(tǒng)短語(yǔ)挖掘方法在電商領(lǐng)域文本中的挖掘精度較低。為此,提出一種基于協(xié)同訓(xùn)練的電商領(lǐng)域短語(yǔ)挖掘方法。通過(guò)基于語(yǔ)義特征的短語(yǔ)分類(lèi)模型來(lái)有效檢測(cè)電商領(lǐng)域
2021-05-13 15:01:150
0基于不同神經(jīng)網(wǎng)絡(luò)的文本分類(lèi)方法研究對(duì)比
神經(jīng)網(wǎng)絡(luò)、時(shí)間遞歸神經(jīng)網(wǎng)絡(luò)、結(jié)構(gòu)遞歸神經(jīng)網(wǎng)絡(luò)和預(yù)訓(xùn)練模型等主流方法在文本分類(lèi)中應(yīng)用的發(fā)展歷程比較不同模型基于常用數(shù)據(jù)集的分類(lèi)效果,表明利用人工神經(jīng)網(wǎng)絡(luò)伂構(gòu)自動(dòng)獲取文本特征,可避免繁雜的人工特征工程,使文本分類(lèi)
2021-05-13 16:34:3448
48低頻詞詞向量?jī)?yōu)化在短文本分類(lèi)中的應(yīng)用
的下游任務(wù)時(shí),往往需要通過(guò)微調(diào)進(jìn)行一定的更新和調(diào)整,使其更適用于目標(biāo)任務(wù)。但是,目標(biāo)語(yǔ)料集中的低頻詞由于缺少訓(xùn)練樣夲,導(dǎo)致在微調(diào)過(guò)程中無(wú)法獲得穩(wěn)定的梯度信息,使得詞向量無(wú)法得到有效更新。而在短文本分類(lèi)任務(wù)中,這些低頻詞對(duì)分類(lèi)結(jié)果同樣有著重要的指示性。
2021-05-17 15:37:2413
13一種為小樣本文本分類(lèi)設(shè)計(jì)的結(jié)合數(shù)據(jù)增強(qiáng)的元學(xué)習(xí)框架
01 研究背景及動(dòng)機(jī) 近些年,元學(xué)習(xí)已經(jīng)成為解決小樣本問(wèn)題的主流技術(shù),并且取得不錯(cuò)的成果。然而,由于現(xiàn)有的元學(xué)習(xí)方法大多數(shù)集中在圖像分類(lèi)上,而對(duì)文本分類(lèi)上的關(guān)注比較少。與圖像不同,同一類(lèi)別中文本具有
2021-05-19 15:54:154012
4012
膠囊網(wǎng)絡(luò)在小樣本做文本分類(lèi)中的應(yīng)用(下)
論文提出Dynamic Memory Induction Networks (DMIN) 網(wǎng)絡(luò)處理小樣本文本分類(lèi)。 兩階段的(two-stage)few-shot模型: 在監(jiān)督學(xué)習(xí)階段(綠色的部分
2021-09-27 17:46:081833
1833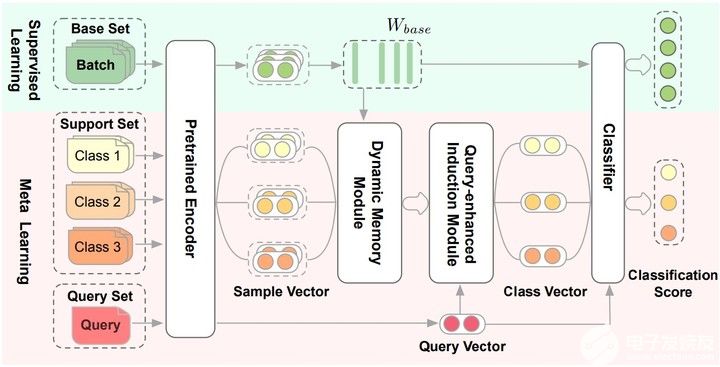
基于雙通道詞向量的卷積膠囊網(wǎng)絡(luò)文本分類(lèi)算法
的詞向量與基于特定文本分類(lèi)任務(wù)擴(kuò)展的語(yǔ)境詞向量作為神經(jīng)網(wǎng)絡(luò)的2個(gè)輸入通道,并采用具有動(dòng)態(tài)路由機(jī)制的卷積膠囊網(wǎng)絡(luò)模型進(jìn)行文本分類(lèi)。在多個(gè)英文數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明,雙通道的詞向量訓(xùn)練方式優(yōu)于單通道策略,與LSTM、RAE、 M
2021-05-24 15:07:296
6基于神經(jīng)網(wǎng)絡(luò)與隱含狄利克雷分配的文本分類(lèi)
主題概率分布,提出一種文本分類(lèi)算法NLDA。在 Thucnews語(yǔ)料庫(kù)和復(fù)旦大學(xué)語(yǔ)料庫(kù)上進(jìn)行實(shí)驗(yàn),結(jié)果表明,與傳統(tǒng)LDA模型相比,該算法的平均分類(lèi)準(zhǔn)確率分別提升5.53%和4.67%,平均訓(xùn)練時(shí)間分別減少8%和10%。
2021-05-25 15:20:590
0基于主題分布優(yōu)化的模糊文本分類(lèi)方法
在對(duì)類(lèi)別模糊的文本進(jìn)行分類(lèi)時(shí),主題模型只考慮文檔和主題級(jí)別信息,未考慮底層詞語(yǔ)間的隱含信息且多數(shù)主題信息復(fù)雜、中心不明確。為此,提出一種改進(jìn)的文本分類(lèi)方法。通過(guò)分位數(shù)選擇中心明確的主題,將其映射
2021-05-25 16:33:295
5一種特征假期樸素貝葉斯文本分類(lèi)算法
樸素貝葉斯(NB)算法應(yīng)用于文本分類(lèi)時(shí)具有簡(jiǎn)單性和高效性,但算法中屬性獨(dú)立性與重要性一致的假設(shè),使其在精確度方面存在瓶頸。針對(duì)該問(wèn)題,提出一種基于泊松分布的特征加權(quán)NB文本分類(lèi)算法。結(jié)合泊松分布模型
2021-05-28 11:30:244
4基于LSTM的表示學(xué)習(xí)-文本分類(lèi)模型
的關(guān)鍵。為了獲得妤的文本表示,提高文本分類(lèi)性能,構(gòu)建了基于LSTM的表示學(xué)習(xí)-文本分類(lèi)模型,其中表示學(xué)習(xí)模型利用語(yǔ)言模型為文本分類(lèi)模型提供初始化的文本表示和網(wǎng)絡(luò)參數(shù)。文中主要采用對(duì)抗訓(xùn)練方法訓(xùn)練語(yǔ)言模型,即在詞向量
2021-06-15 16:17:1718
18基于新型文本塊分割法的簡(jiǎn)歷解析器
近些年,基于神經(jīng)網(wǎng)絡(luò)的文本分類(lèi)器和詞嵌入在自然語(yǔ)言處理中被廣泛應(yīng)用。然而,傳統(tǒng)的簡(jiǎn)歷解析器采用基于關(guān)鍵字的模糊匹配或正則表達(dá)式來(lái)進(jìn)行文本塊分割。文中提岀了一種基于神經(jīng)網(wǎng)絡(luò)文本分類(lèi)器和詞向量
2021-06-16 11:47:2117
17文本分類(lèi)任務(wù)的Bert微調(diào)trick大全
1 前言 大家現(xiàn)在打比賽對(duì)預(yù)訓(xùn)練模型非常喜愛(ài),基本上作為NLP比賽基線首選(圖像分類(lèi)也有預(yù)訓(xùn)練模型)。預(yù)訓(xùn)練模型雖然很強(qiáng),可能通過(guò)簡(jiǎn)單的微調(diào)就能給我們帶來(lái)很大提升,但是大家會(huì)發(fā)現(xiàn)比賽做到后期
2021-07-18 09:49:322165
21652021 OPPO開(kāi)發(fā)者大會(huì):NLP預(yù)訓(xùn)練大模型
2021 OPPO開(kāi)發(fā)者大會(huì):NLP預(yù)訓(xùn)練大模型 2021 OPPO開(kāi)發(fā)者大會(huì)上介紹了融合知識(shí)的NLP預(yù)訓(xùn)練大模型。 責(zé)任編輯:haq
2021-10-27 14:18:411492
1492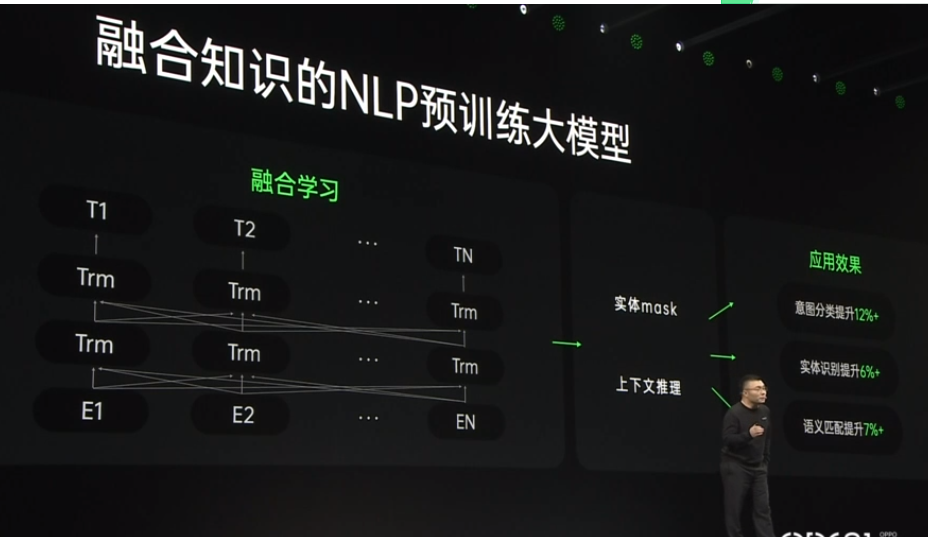
2021年OPPO開(kāi)發(fā)者大會(huì) 融合知識(shí)的NLP預(yù)訓(xùn)練大模型
2021年OPPO開(kāi)發(fā)者大會(huì)劉海鋒:融合知識(shí)的NLP預(yù)訓(xùn)練大模型,知識(shí)融合學(xué)習(xí)運(yùn)用在小布助手里面。
2021-10-27 14:48:162251
2251
如何實(shí)現(xiàn)更綠色、經(jīng)濟(jì)的NLP預(yù)訓(xùn)練模型遷移
NLP中,預(yù)訓(xùn)練大模型Finetune是一種非常常見(jiàn)的解決問(wèn)題的范式。利用在海量文本上預(yù)訓(xùn)練得到的Bert、GPT等模型,在下游不同任務(wù)上分別進(jìn)行finetune,得到下游任務(wù)的模型。然而,這種方式
2022-03-21 15:33:301843
1843帶你從頭構(gòu)建文本分類(lèi)器
文本分類(lèi)是 NLP 中最常見(jiàn)的任務(wù)之一, 它可用于廣泛的應(yīng)用或者開(kāi)發(fā)成程序,例如將用戶(hù)反饋文本標(biāo)記為某種類(lèi)別,或者根據(jù)客戶(hù)文本語(yǔ)言自動(dòng)歸類(lèi)。另外向我們平時(shí)見(jiàn)到的郵件垃圾過(guò)濾器也是文本分類(lèi)最熟悉的應(yīng)用場(chǎng)景之一。
2022-03-22 10:49:322904
2904一種基于標(biāo)簽比例信息的遷移學(xué)習(xí)算法
摘要: 標(biāo)簽比例學(xué)習(xí)問(wèn)題是一項(xiàng)僅使用樣本標(biāo)簽比例信息去構(gòu)建分類(lèi)模型的挖掘任務(wù),由于訓(xùn)練樣本不充分,現(xiàn)有方法將該問(wèn)題視為單一任務(wù),在文本分類(lèi)中的表現(xiàn)并不理想。考慮到遷移學(xué)習(xí)在一定程度上能解決訓(xùn)練數(shù)據(jù)
2022-03-30 15:46:31343
343遷移學(xué)習(xí)Finetune的四種類(lèi)型招式
遷移學(xué)習(xí)方法。例如NLP中的預(yù)訓(xùn)練Bert模型,通過(guò)在下游任務(wù)上Finetune即可取得比直接使用下游數(shù)據(jù)任務(wù)從零訓(xùn)練的效果要好得多。
2022-04-02 17:35:552509
2509用NVIDIA遷移學(xué)習(xí)工具箱如何訓(xùn)練二維姿態(tài)估計(jì)模型
本系列的第一篇文章介紹了在 NVIDIA 遷移學(xué)習(xí)工具箱中使用開(kāi)源 COCO 數(shù)據(jù)集和 BodyPoseNet 應(yīng)用程序的 如何訓(xùn)練二維姿態(tài)估計(jì)模型 。
2022-04-10 09:41:201445
1445
深度學(xué)習(xí)——如何用LSTM進(jìn)行文本分類(lèi)
簡(jiǎn)介 主要內(nèi)容包括 如何將文本處理為T(mén)ensorflow LSTM的輸入 如何定義LSTM 用訓(xùn)練好的LSTM進(jìn)行文本分類(lèi) 代碼 導(dǎo)入相關(guān)庫(kù) #coding=utf-8 import
2022-10-21 09:57:071018
1018PyTorch文本分類(lèi)任務(wù)的基本流程
文本分類(lèi)是NLP領(lǐng)域的較為容易的入門(mén)問(wèn)題,本文記錄文本分類(lèi)任務(wù)的基本流程,大部分操作使用了**torch**和**torchtext**兩個(gè)庫(kù)。
## 1. 文本數(shù)據(jù)預(yù)處理
2023-02-22 14:23:59729
729淺析4個(gè)計(jì)算機(jī)視覺(jué)領(lǐng)域常用遷移學(xué)習(xí)模型
使用SOTA的預(yù)訓(xùn)練模型來(lái)通過(guò)遷移學(xué)習(xí)解決現(xiàn)實(shí)的計(jì)算機(jī)視覺(jué)問(wèn)題。
2023-04-23 18:08:411023
1023
PyTorch教程4.3之基本分類(lèi)模型
電子發(fā)燒友網(wǎng)站提供《PyTorch教程4.3之基本分類(lèi)模型.pdf》資料免費(fèi)下載
2023-06-05 15:43:550
0基于預(yù)訓(xùn)練模型和語(yǔ)言增強(qiáng)的零樣本視覺(jué)學(xué)習(xí)
Stable Diffusion 多模態(tài)預(yù)訓(xùn)練模型 考慮多標(biāo)簽圖像分類(lèi)任務(wù)——每幅圖像大于一個(gè)類(lèi)別 如果已有圖文對(duì)齊模型——能否用文本特征代替圖像特征 訓(xùn)練的時(shí)候使用文本組成的句子 對(duì)齊總會(huì)有 gap,選 loss 的時(shí)候使用 rank loss,對(duì)模態(tài) gap 更穩(wěn)定 拿到文本后有幾種選擇,比如
2023-06-15 16:36:11277
277
一文詳解遷移學(xué)習(xí)
遷移學(xué)習(xí)需要將預(yù)訓(xùn)練好的模型適應(yīng)新的下游任務(wù)。然而,作者觀察到,當(dāng)前的遷移學(xué)習(xí)方法通常無(wú)法關(guān)注與任務(wù)相關(guān)的特征。在這項(xiàng)工作中,作者探索了重新聚焦模型注意力以進(jìn)行遷移學(xué)習(xí)。作者提出了自上而下的注意力
2023-08-11 16:56:173048
3048
視覺(jué)深度學(xué)習(xí)遷移學(xué)習(xí)訓(xùn)練框架Torchvision介紹
Torchvision是基于Pytorch的視覺(jué)深度學(xué)習(xí)遷移學(xué)習(xí)訓(xùn)練框架,當(dāng)前支持的圖像分類(lèi)、對(duì)象檢測(cè)、實(shí)例分割、語(yǔ)義分割、姿態(tài)評(píng)估模型的遷移學(xué)習(xí)訓(xùn)練與評(píng)估。支持對(duì)數(shù)據(jù)集的合成、變換、增強(qiáng)等,此外還支持預(yù)訓(xùn)練模型庫(kù)下載相關(guān)的模型,直接預(yù)測(cè)推理。
2023-09-22 09:49:51391
391
人工智能中文本分類(lèi)的基本原理和關(guān)鍵技術(shù)
在本文中,我們?nèi)嫣接懥?b class="flag-6" style="color: red">文本分類(lèi)技術(shù)的發(fā)展歷程、基本原理、關(guān)鍵技術(shù)、深度學(xué)習(xí)的應(yīng)用,以及從RNN到Transformer的技術(shù)演進(jìn)。文章詳細(xì)介紹了各種模型的原理和實(shí)戰(zhàn)應(yīng)用,旨在提供對(duì)文本分類(lèi)技術(shù)深入理解的全面視角。
2023-12-16 11:37:31435
435





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論