") fastText有兩大用途——文本分類和Word Embedding
fastText有兩大用途——文本分類和Word Embedding

今天我們來看 Mikolov 大佬 2016 年的另一大巨作——fastText。2013 年大佬在 Google 開源了 Word2Vec,2016 年剛就職于 FaceBook 就開源了 fastText,全都掀起了軒然大波。
fastText 模型有兩篇相關(guān)論文:
《Bag of Tricks for Efficient Text Classification》
《Enriching Word Vectors with Subword Information》
截至目前為止,第一篇有 1500 多引用量,第二篇有 2700 多引用量。
從這兩篇文的標(biāo)題我們可以看出來 fastText 有兩大用途——文本分類和Word Embedding。
由于 fastText 模型比較簡單,所以我們可以把兩篇論文放在一起看。
1. Introduction
fastText 提供了簡單而高效的文本分類和 Word Embedding 方法,分類精度比肩深度學(xué)習(xí)而且速度快上幾個(gè)數(shù)量級(jí)。
舉個(gè)例子:使用標(biāo)準(zhǔn)的 CPU 可以在十分鐘的時(shí)間里訓(xùn)練超過 10 億個(gè)單詞,在不到一分鐘的時(shí)間里可以將 50 萬個(gè)句子分到 31 萬個(gè)類別中。
可以看到 fastText 的速度有多驚人。
2. fastText
fastText 之所以能做到速度快效果好主要是兩個(gè)原因:N-Gram 和 Hierarchical softmax。由于 Hierarchical softmax 在 Word2Vec 中已經(jīng)介紹過了,所以我們只介紹一下 N-gram。
2.1 N-gram
N-gram 是一種基于統(tǒng)計(jì)語言模型的算法,常用于 NLP 領(lǐng)域。其思想在于將文本內(nèi)容按照字節(jié)順序進(jìn)行大小為 N 的滑動(dòng)窗口操作,從而形成了長度為 N 的字節(jié)片段序列,其片段我們稱為 gram。
以“谷歌是家好公司” 為例子:
二元 Bi-gram 特征為:谷歌 歌是 是家 家好 好公 公司
三元 Tri-gram 特征為:谷歌是 歌是家 是家好 家好公 好公司
當(dāng)然,我們可以用字粒度也可以用詞粒度。
例如:谷歌 是 家 好 公司二元 Bi-gram 特征為:谷歌是 是家 家好 好公司三元 Tri-gram 特征為:谷歌是家 是家好 家好公司
N-gram 產(chǎn)生的特征只是作為文本特征的候選集,后面還可以通過信息熵、卡方統(tǒng)計(jì)、IDF 等文本特征選擇方式篩選出比較重要的特征。
2.2 Embedding Model
這邊值得注意的是,fastText 是一個(gè)庫,而不是一個(gè)算法。類似于 Word2Vec 也只是一個(gè)工具,Skip-Gram 和 CBOW 才是其中的算法。
?
fastText is a library for efficient learning of word representations and sentence classification.
”
fastText 在 Skip-Gram 的基礎(chǔ)上實(shí)現(xiàn) Word Embedding,具體來說:fastText 通過 Skip-Gram 訓(xùn)練了字符級(jí)別 N-gram 的 Embedding,然后通過將其相加得到詞向量。
舉個(gè)例子:對于 “where” 這個(gè)單詞來說,它的 Tri-gram 為:“
這樣做主要有兩個(gè)好處:
低頻詞生成的 Embedding 效果會(huì)更好,因?yàn)樗鼈兊?N-gram 可以和其它詞共享而不用擔(dān)心詞頻過低無法得到充分的訓(xùn)練;
對于訓(xùn)練詞庫之外的單詞(比如拼錯(cuò)了),仍然可以通過對它們字符級(jí)的 N-gram 向量求和來構(gòu)建它們的詞向量。
為了節(jié)省內(nèi)存空間,我們使用 HashMap 將 N-gram 映射到 1 到 K,所以單詞的除了存儲(chǔ)自己在單詞表的 Index 外,還存儲(chǔ)了其包含的 N-gram 的哈希索引。
2.3 Classification Model
一般來說,速度快的模型其結(jié)構(gòu)都會(huì)比較簡單,fastText 也不例外,其架構(gòu)圖如下圖所示:
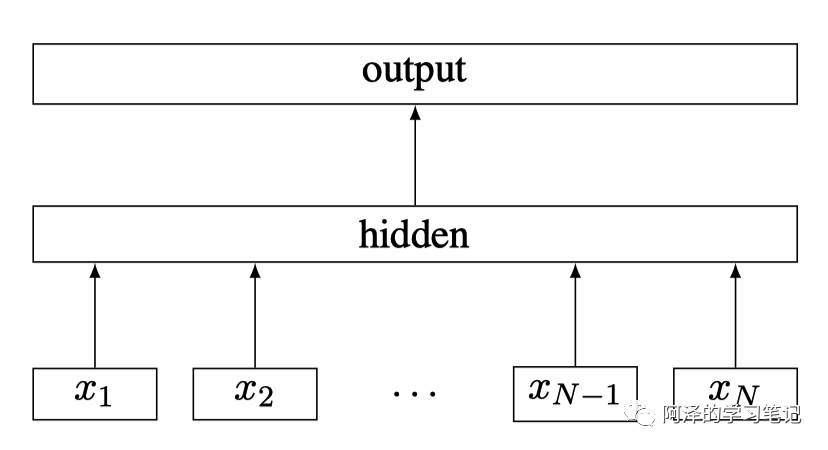
fastText Architecture
其中, 為一個(gè)句子的 N-gram 特征。
我們看到這個(gè)架構(gòu)是不是感覺似曾相似?
fastText 與 Word2Vec 的 CBOW 架構(gòu)是非常相似的,但與 CBOW 不同的是:fastText 輸入不僅是多個(gè)單詞 Embedding 向量,還將字符級(jí)別的 N-gram 向量作為額外的特征,其預(yù)測是也不是單詞,而是 Label(fastText 主要用于文本分類,所以預(yù)測的是分類標(biāo)簽)。
3. Experiment
我們簡單看下 fastText 的兩個(gè)實(shí)驗(yàn)——Embedding 和文本分類;
3.1 Embeddng
sisg 是 fastText 用于 Embedding 的模型,實(shí)驗(yàn)效果如下:
3.2 Classification
分類實(shí)驗(yàn)的精度 fastText 比 char-CNN、 char-RCNN 要好,但比 VDCNN 要差。(但這里注意:fastText 僅僅使用 10 個(gè)隱藏層節(jié)點(diǎn) ,訓(xùn)練了 5 次 epochs。)
在速度上 fastText 快了幾個(gè)數(shù)量級(jí)。(此處注意:CNN 和 VDCNN 用的都是 Tesla K40 的 GPU,而 fastText 用的是 CPU)
下面是標(biāo)簽預(yù)測的結(jié)果,兩個(gè)模型都使用 CPU 并開了 20 個(gè)線程:
4. Conclusion
一句話總結(jié):fastText 是一個(gè)用于文本分類和 Embedding 計(jì)算的工具庫,主要通過 N-gram 和 Hierarchical softmax 保證算法的速度和精度。
關(guān)于 Hierarchical softmax 為什么會(huì)使 fastText 速度那么快?而在 Word2Vec 中沒有看到類似的效果?
我覺得是因?yàn)?fastText 的標(biāo)簽數(shù)量相比 Word2Vec 來說要少很多,所以速度會(huì)變的非常快。其次 Hierarchical softmax 是必要的,如果不同的話速度會(huì)慢非常多。
另外,fastText 可能沒有什么創(chuàng)新,但他卻異常火爆,可能有多個(gè)原因,其中包括開源了高質(zhì)量的 fastText,類似 Work2Vec,當(dāng)然也會(huì)有 Mikolov 大佬和 Facebook 的背書。
總的來說,fastText 還是一個(gè)極具競爭力的一個(gè)工具包。
5. Reference
《Bag of Tricks for Efficient Text Classification》
《Enriching Word Vectors with Subword Information》
責(zé)任編輯:lq
-
算法
+關(guān)注
關(guān)注
23文章
4710瀏覽量
95380 -
文本分類
+關(guān)注
關(guān)注
0文章
18瀏覽量
7400 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122794
原文標(biāo)題:fastText:極快的文本分類工具
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
半導(dǎo)體激光器的常見分類
光纖纖芯直徑的兩大分類
電源盒的分類有哪些
Spire.Cloud.Word云端Word文檔處理SDK介紹

存儲(chǔ)器的分類及其區(qū)別
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+Embedding技術(shù)解讀
如何使用自然語言處理分析文本數(shù)據(jù)
生物芯片有哪些分類
RK3588 技術(shù)分享 | 在Android系統(tǒng)中使用NPU實(shí)現(xiàn)Yolov5分類檢測
直流電機(jī)有哪些型號(hào)?如何分類的?
emc有哪些測試方法和分類方法
放大電路的基本分析方法有哪兩種
普強(qiáng)成功榮登兩大榜單
動(dòng)圖展示兩大電機(jī)系統(tǒng)的運(yùn)行順序
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評論