") 研究人員開(kāi)發(fā)出一個(gè)端到端的機(jī)器學(xué)習(xí)系統(tǒng)Audio2Face
研究人員開(kāi)發(fā)出一個(gè)端到端的機(jī)器學(xué)習(xí)系統(tǒng)Audio2Face

浙江大學(xué)和網(wǎng)易伏羲AI實(shí)驗(yàn)室的研究人員開(kāi)發(fā)出一個(gè)端到端的機(jī)器學(xué)習(xí)系統(tǒng)Audio2Face,可以從音頻中單獨(dú)生成實(shí)時(shí)面部動(dòng)畫,同時(shí)考慮到音高和說(shuō)話風(fēng)格。
我們都知道動(dòng)畫里的人物說(shuō)話聲音都是由后期配音演員合成的。
但即使利用CrazyTalk這樣的軟件,也很難將電腦生成的嘴唇、嘴型等與配音演員進(jìn)行很好地匹配,尤其是當(dāng)對(duì)話時(shí)長(zhǎng)在數(shù)十甚至數(shù)百小時(shí)的情況下。
但不要?dú)怵H,動(dòng)畫師的福音來(lái)了——Audio2Face問(wèn)世!
Audio2Face是一款端到端的機(jī)器學(xué)習(xí)系統(tǒng),由浙江大學(xué)與網(wǎng)易伏羲AI實(shí)驗(yàn)室共同打造。
它可以從音頻中單獨(dú)生成實(shí)時(shí)的面部動(dòng)畫,更厲害的是,它還能調(diào)節(jié)音調(diào)和說(shuō)話風(fēng)格。該成果已經(jīng)發(fā)布至arXiv:
arXiv地址:
https://arxiv.org/pdf/1905.11142.pdf
團(tuán)隊(duì)試圖構(gòu)建一個(gè)系統(tǒng),既要逼真又要低延遲
“我們的方法完全是基于音軌設(shè)計(jì)的,沒(méi)有任何其他輔助輸入(例如圖像),這就使得當(dāng)我們?cè)噲D從聲音序列中回歸視覺(jué)空間的過(guò)程將會(huì)越來(lái)越具有挑戰(zhàn)。”論文共同作者解釋道,“另一個(gè)挑戰(zhàn)是面部活動(dòng)涉及臉部幾何表面上相關(guān)區(qū)域的多重激活,這使得很難產(chǎn)生逼真且一致的面部變形。”
該團(tuán)隊(duì)試圖構(gòu)建一個(gè)同時(shí)滿足“逼真”(生成的動(dòng)畫必須反映可見(jiàn)語(yǔ)音運(yùn)動(dòng)中的說(shuō)話模式)和低延遲(系統(tǒng)必須能夠進(jìn)行近乎實(shí)時(shí)的動(dòng)畫)要求的系統(tǒng)。他們還嘗試將其推廣,以便可以將生成的動(dòng)畫重新定位到其他3D角色。
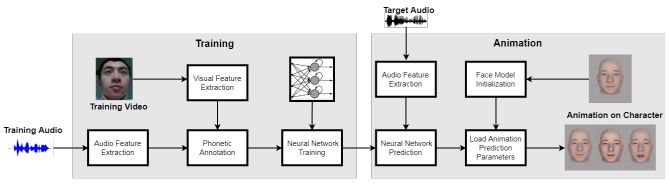
他們的方法包括從原始輸入音頻中提取手工制作的高級(jí)聲學(xué)特征,特別是梅爾頻率倒譜系數(shù)(MFC),或聲音的短期功率譜的表示。然后深度相機(jī)與mocap工具Faceshift一起,捕捉配音演員的面部動(dòng)作并編制訓(xùn)練集。

深度相機(jī)示意圖
之后研究人員構(gòu)建了帶有51個(gè)參數(shù)的3D卡通人臉模型,控制了臉部的不同部位(例如,眉毛,眼睛,嘴唇和下巴)。最后,他們利用上述AI系統(tǒng)將音頻上下文映射到參數(shù),產(chǎn)生唇部和面部動(dòng)作。
1470個(gè)音頻樣本加持,機(jī)器學(xué)習(xí)模型的輸出“相當(dāng)可以”
團(tuán)隊(duì)使用一個(gè)訓(xùn)練語(yǔ)料庫(kù),其中包含兩個(gè)60分鐘、每秒30幀的女性和男性演員逐行閱讀劇本中臺(tái)詞的視頻,以及每個(gè)相應(yīng)視頻幀的1470個(gè)音頻樣本(每幀總共2496個(gè)維度)。
團(tuán)隊(duì)報(bào)告說(shuō),與ground truth相比,機(jī)器學(xué)習(xí)模型的輸出“相當(dāng)可以”。它設(shè)法在測(cè)試音頻上重現(xiàn)準(zhǔn)確的面部形狀,并且它一直“很好地”重新定位到不同的角色。此外,AI系統(tǒng)平均只需0.68毫秒即可從給定的音頻窗口中提取特征。
該團(tuán)隊(duì)指出,AI無(wú)法跟隨演員的眨眼模式,主要是因?yàn)檎Q叟c言語(yǔ)的相關(guān)性非常弱。不過(guò)從廣義上講,該框架可能為適應(yīng)性強(qiáng)、可擴(kuò)展的音頻到面部動(dòng)畫技術(shù)奠定基礎(chǔ),這些技術(shù)幾乎適用于所有說(shuō)話人和語(yǔ)言。
“評(píng)估結(jié)果顯示,我們的方法不僅可以從音頻中產(chǎn)生準(zhǔn)確的唇部運(yùn)動(dòng),還可以成功地消除說(shuō)話人隨時(shí)間變化的面部動(dòng)作,”他們寫道。
-
3D
+關(guān)注
關(guān)注
9文章
2955瀏覽量
110421 -
音頻
+關(guān)注
關(guān)注
29文章
3030瀏覽量
83199 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8499瀏覽量
134295
原文標(biāo)題:浙大研發(fā)AudioFace:隨心錄語(yǔ)音就能實(shí)時(shí)生成3D面部動(dòng)畫
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
為何端到端成為各車企智駕布局的首要選擇?
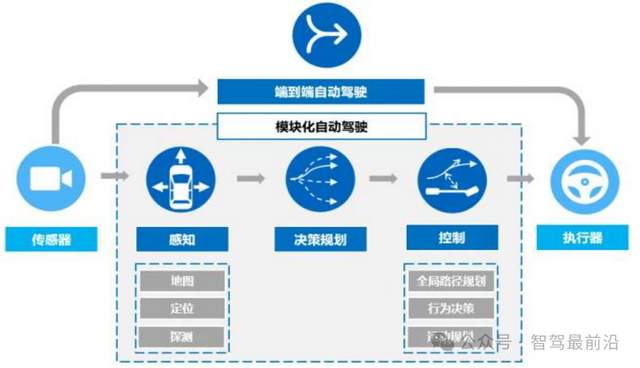
一文帶你厘清自動(dòng)駕駛端到端架構(gòu)差異
研究人員開(kāi)發(fā)出基于NVIDIA技術(shù)的AI模型用于檢測(cè)瘧疾
小米汽車端到端智駕技術(shù)介紹

【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】+初品的體驗(yàn)
端到端自動(dòng)駕駛技術(shù)研究與分析
端到端在自動(dòng)泊車的應(yīng)用
端到端已來(lái),智駕仿真測(cè)試該怎么做?

爆火的端到端如何加速智駕落地?
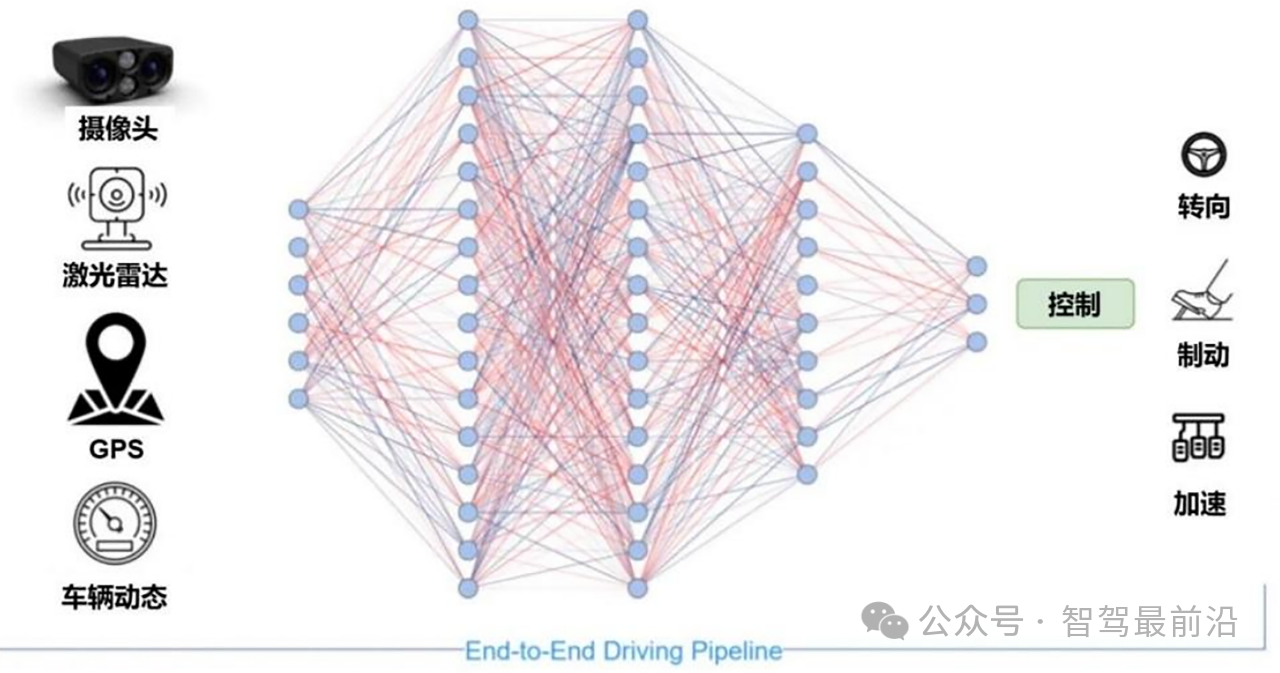
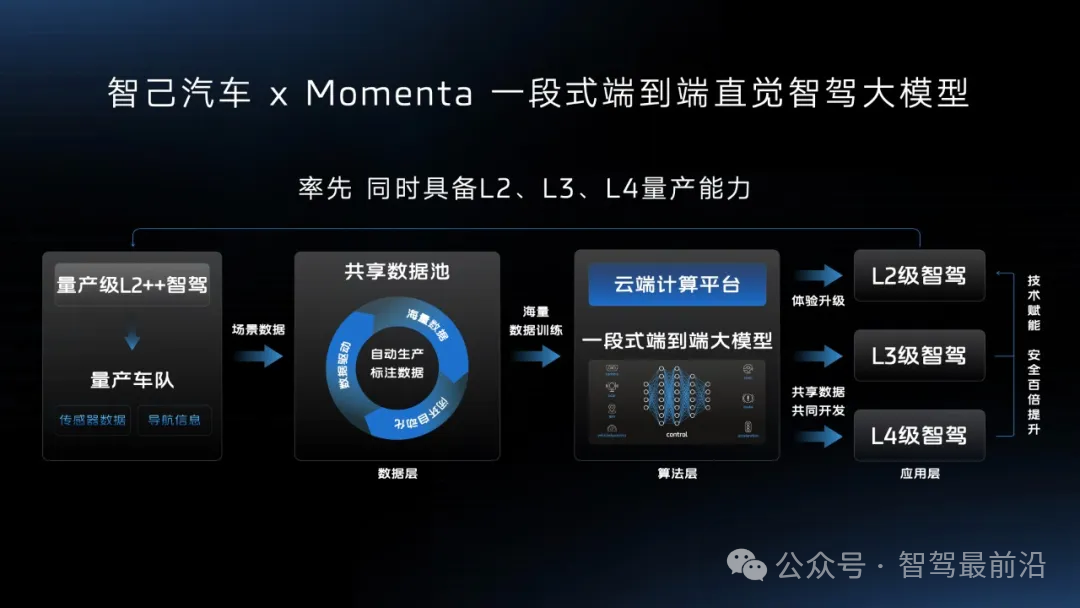
智己汽車“端到端”智駕方案推出,老司機(jī)真的會(huì)被取代嗎?
端到端讓智駕強(qiáng)者愈強(qiáng)時(shí)代來(lái)臨?
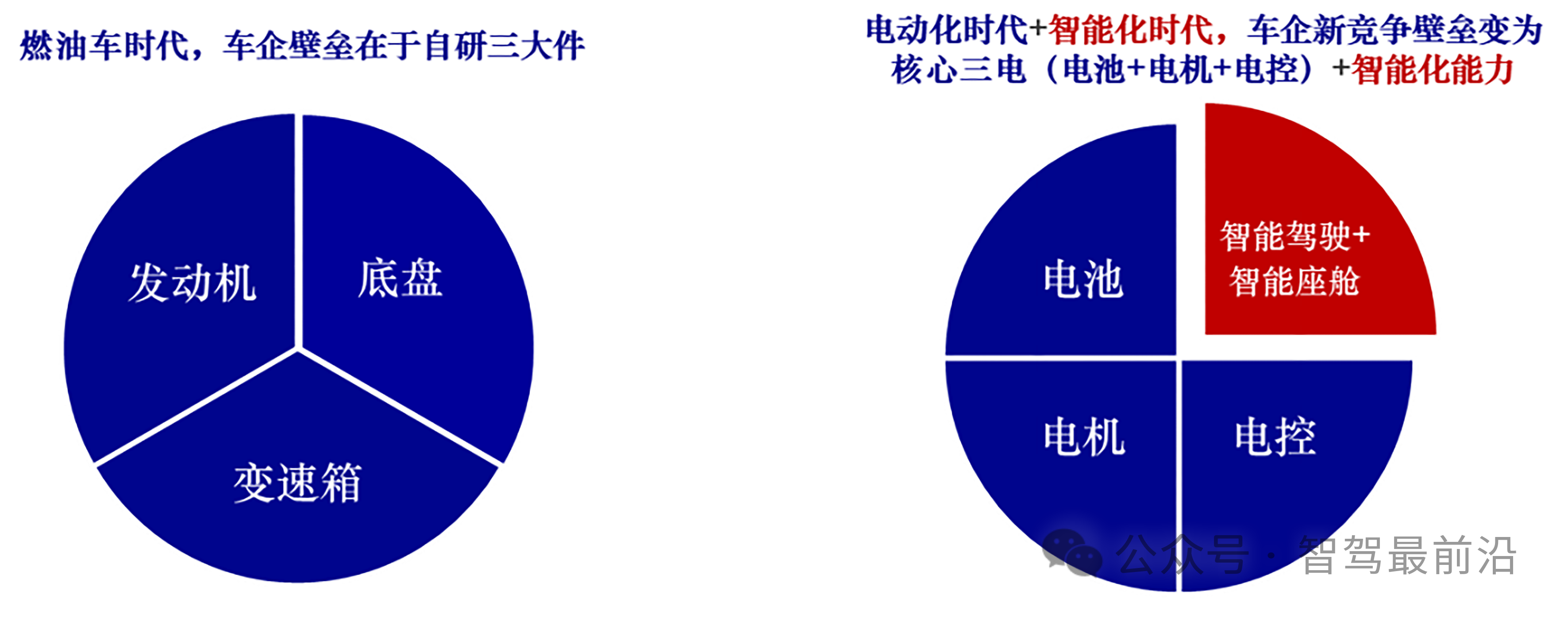
Mobileye端到端自動(dòng)駕駛解決方案的深度解析

端到端測(cè)試用例怎么寫
實(shí)現(xiàn)自動(dòng)駕駛,唯有端到端?

saas模式的一套智慧工地云平臺(tái)源碼,支持多端展示:PC端、大屏端、手機(jī)端、平板端





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論