 賽靈思INT8優化為嵌入式視覺應用提供性能和計算方法
賽靈思INT8優化為嵌入式視覺應用提供性能和計算方法
與其他 FPGA DSP 架構相比,賽靈思的集成 DSP 架構在 INT8 深度學習運算上能實現 1.75 倍的解決方案級性能。
概要
本白皮書探討將 INT8 運算用于實現在賽靈思 DSP48E2 片上、使用深度學習推斷和計算機視覺功能的嵌入式視覺應用,以及這種方案與其他 FPGA 的對比。與占用相同資源數量的其他 FPGA 相比,賽靈思的 DSP 架構對 INT8 乘法累加 (MACC) 運算能實現 1.75 倍的峰值解決方案級性能。由于嵌入式視覺應用可以在不犧牲準確性的情況下使用較低位精度,因此需要高效的 INT8 實現方案。
賽靈思的 DSP 架構和庫針對 INT8 運算進行了精心優化。本白皮書介紹如何使用賽靈思 16nm 和 20nm All Programmable 器件中的 DSP48E2 Slice,在共享相同內核權重的同時處理兩個并行的 INT8 MACC 運算。本白皮書還闡述了要運用賽靈思這一獨特技術,為何輸入的最小位寬為 24 位。此外本白皮書還詳細介紹了如何以 SIMD 模式使用 DSP48E2 Slice,供基本算術運算使用。另外還提供在深度學習領域或其他計算機視覺處理任務領域如何將這些功能用于嵌入式視覺的實例。
用于深度學習和計算機視覺的 INT8
嵌入式視覺是專業術語,指的是在嵌入式平臺上實現用于現實用途的計算機視覺算法。雖然計算機視覺算法近年來有明顯改進,要在降低功耗的條件下將這樣復雜且高計算強度的算法移植到嵌入式平臺上卻是一大挑戰。以更低功耗處理更多運算是一個亙古不變的需求,無論是對過濾、角點檢測等傳統計算機視覺算法還是對深度學習算法。
深度神經網絡憑借人類級 AI 功能已推動眾多應用不斷演進并重新對其定義。鑒于這類算法提供的超高精度,這些網絡是嵌入式設備中的主要工作負載。隨著更精確的深度學習模型被開發出來,它們的復雜性也帶來了高計算強度和高內存帶寬方面的難題。能效要求正推動深度學習推斷新模式開發方面的創新,這些模式需要的計算強度和內存帶寬較低,但絕不能以犧牲準確性和吞吐量為代價。降低這一開銷將最終提升能效,降低所需的總功耗。
除了節省計算過程中的耗電,較低位寬的計算還能降低內存帶寬所需的功耗,因為在內存事務數量不變的情況下傳輸的位數減少了。
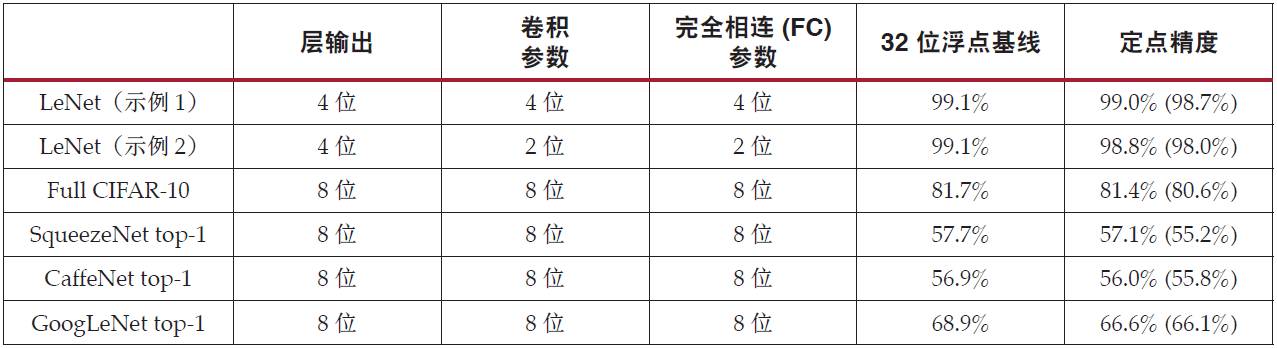
研究顯示要保持同樣的準確性[ 參考資料 1][ 參考資料 2][ 參考資料 3],深度學習推斷中無需浮點計算,而且圖像分類等許多應用只需要 INT8 或更低定點計算精度來保持可接受的推斷準確性[ 參考資料 2][ 參考資料 3]。表 1 列出了精調網絡以及卷積層和完全相連層的動態定點參數及輸出。括號內的數字代表未精調的準確性。
表 1 :帶定點精度的 CNN 模型
對用于深度學習的 INT8 運算的優化也直接地適用于大量傳統計算機視覺功能。這些算法一般工作在 8 位到 16 位整數表達式。OpenVX[ 參考資料 4]是一種近期提議的計算機視覺標準,規定了每個通道 INT8 表達式的用法。大多數計算機視覺應用需要某些程度的過濾,而過濾能夠分解為一套點積運算。賽靈思 DSP48E2 Slice 上的 SIMD 運算模式為實現視覺算法涉及的運算提供額外選擇。
賽靈思 DSP Slice 片上的 INT8 運算
UltraScale 和 UltraScale+ FPGA、Zynq UltraScale+ MPSoC(可編程邏輯)中的賽靈思 DSP48E2 Slice 設計用于完成一次乘法和加法運算,最大可在一個時鐘周期內高效地實現 18x27 位相乘和 48 位累加,如圖 1 所示。除了采用回送或鏈接多個 DSP48E2 Slice,乘法累加 (MACC) 也能使用賽靈思器件高效完成。
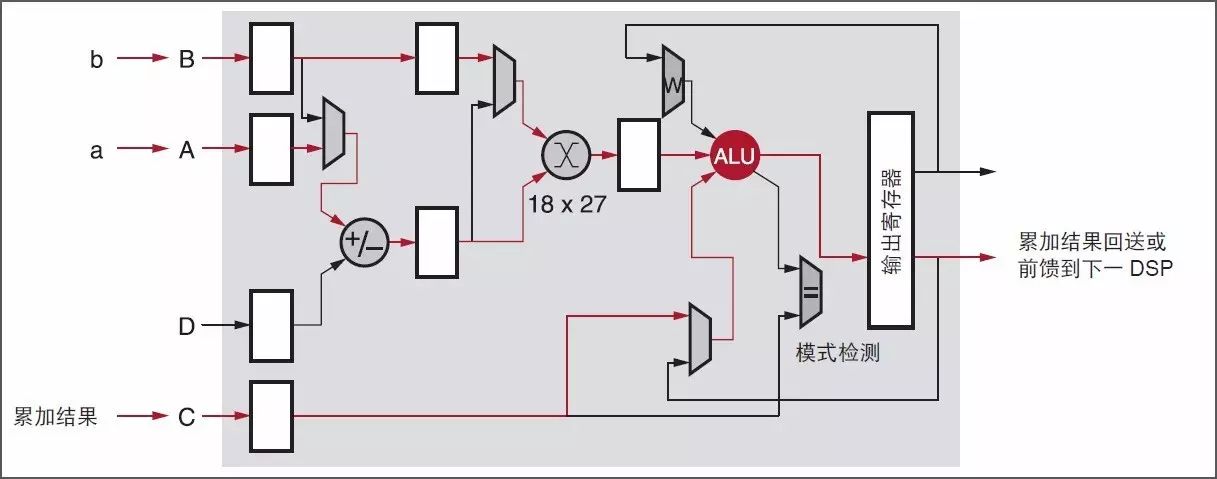
圖 1 :使用 MACC 模式的 DSP48E2 Slice
INT8 計算本身就能發揮寬 27 位帶寬的優勢。在傳統應用中,預加法器一般用于高效實現(A+B)xC 類型的運算,但這類型運算不常見于深度學習和計算機視覺應用中。將 (A+B)xC 的結果分解為 AxC 和 BxC,然后在獨立的數據流中進行累加,使之適用于典型深度學習和計算機視覺計算的要求。
對 INT8 MACC 運算來說,擁有 18x27 位乘法器很占優勢。乘法器的輸入中至少有一個必須為最小 24 位,同時進位累加器必須為 32 位寬,才能在一個 DSP48E2 Slice 上同時進行兩個 INT8 MACC 運算。27 位輸入可與 48 位累加器相結合,實現 1.75 倍的解決方案性能提升(DSP 乘法器與 INT8 MACC 之比為 1.75:1)。其他廠商提供的 FPGA 在單個 DSP 模塊中只提供 18x19 乘法器,DSP 乘法器與 INT8 MACC 之比僅為 1:1。
可擴展的 INT8 優化
目標是找到一種能夠對輸入 a 、b 和 c 進行高效編碼的方法,這樣 a 、b 和 c 之間的相乘結果可以輕松分解為 a x c 和 b x c。鑒于公共輸入 c,這種方法可以推斷為單個指令,擁有公共系數的 2 個數據。
在更低精度計算中,例如 INT8 乘法中,高位 10 位或 19 位輸入用 0 或 1 填充,僅攜帶 1 位信息。對最終的 45 位乘積的高位 29 位來說,情況一樣。這樣就可以使用高位 19 位來進行另一個運算,同時不影響低位 8 位和 16 位輸入。
總的來說,要把未使用的高位用于另一計算必須遵循兩條規則:
1. 高位不應影響低位的計算。
2. 低位計算對高位的任何影響必須可檢測、可恢復。
為滿足上述規則,高位乘積結果的最低有效位不得進入低位 16 位。因此高位的輸入應至少從第 17 位開始。對一個 8 位的高位輸入,總輸入寬位至少為 16+8=24 位。這種最小 24 位輸入大小只能保證用一個乘法器同時完成兩次相乘,但仍然足以實現總體 1.75 倍的 MACC 吞吐量。
接下來的步驟是在一個 DSP48E2 Slice 中并行計算 ac 和 bc 。DSP48E2 Slice 被用作一個帶有一個 27 位預加法器(輸入和輸出均為 27 位寬)和一個 27x18 乘法器的算術單元。見圖 2。
1. 通過預加法器在 DSP48E2 乘法器的 27 位端口 p 打包 8 位輸入 a 和 b,這樣 2 位向量能盡量分隔開。輸入 a 左移位僅 18 位,這樣從第一項得到的 27 位結果中的兩個符號位 a 以避免在 b<0 和 a=–128 時預加法器中發生溢值。a 的移位量為 18,恰好與 DSP48E2 乘法器端口 B 的寬度一樣。
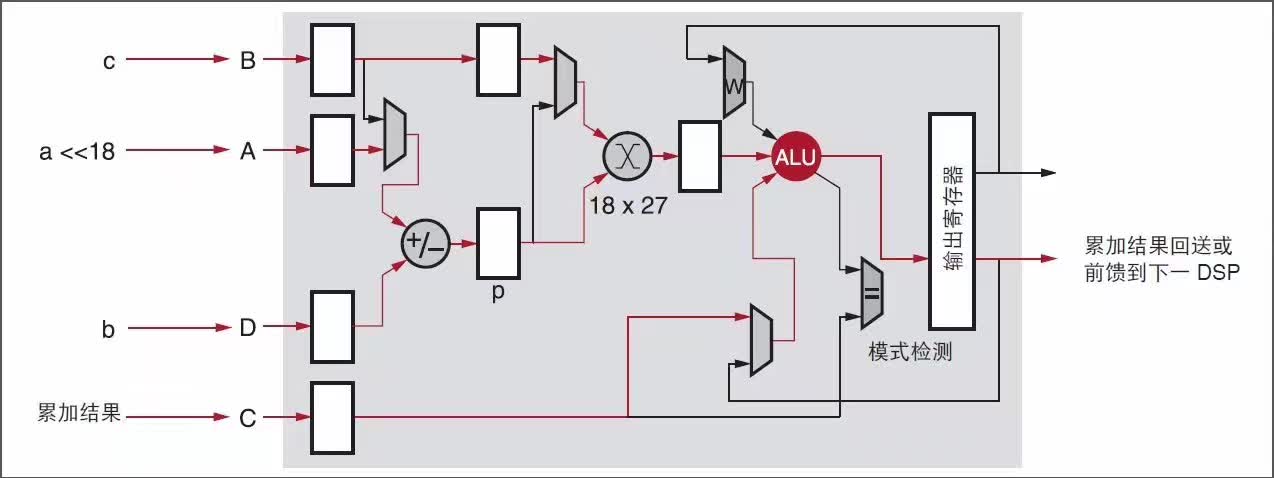
圖 2 :8 位優化
2. DSP48E2 27x18 乘法器用于計算打包的 27 位端口 p 和以二進制補碼格式表達在 18 位 c 中的 8 位系數的積。現在該 45 位乘積是二進制補碼格式的兩個 44 位項的和:ac 左移位 18 位以及 bc 。
后加法器可用于累加上述包含單獨的高位乘積項和低位乘積項的 45 位乘積。在累加單個 45 位積時,對高位項和低位項進行了校正累加。最終的累加結果如果沒有溢值,可以用簡單運算分開。
這種方法的局限在于每個 DSP48E2 Slice 能累加的乘積項的數量。由于高位項和低位項間始終保持兩位(圖 3),可以保證在低位不溢值的情況下累加多達 7 個項。在七個乘積項后,需要使用額外的 DSP48E2 Slice 來克服這一局限。執行 7x2 INT8 乘法- 加法運算,與擁有相同數量乘法器的競爭型器件相比 INT8 MACC 運算的效率提升 1.75 倍。
根據實際用例的要求,這種方法有多種變化形式。使用修正線性單元(ReLU)的卷積神經網絡產生非負激活,而無符號 INT8 格式產生額外一位精度和 1.78 倍峰值吞吐量提升。
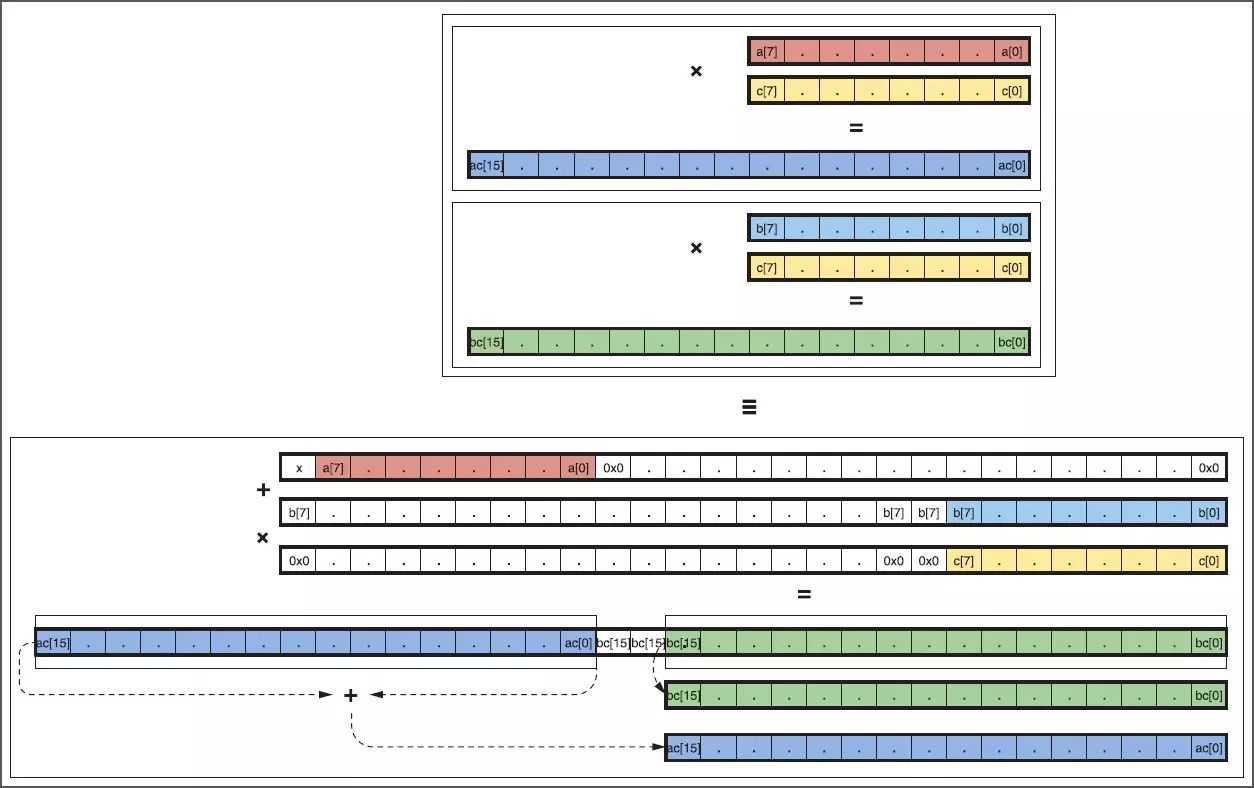
圖 3 :用單個 DSP48E2 Slice 打包兩個 INT8 乘運算
DSP48E2 SIMD 模式
DSP48E2 Slice 的后加法器分裂成四個 12 位或兩個 24 位 SIMA ALU(參見圖 4),以執行并行加法、減法、累加或逐位邏輯運算。在 SIMD 模式下,DSP48E2 Slice 的預加法器和乘法器不可用。在每個周期上,ALUMODE[3:0] 控制總線選擇運算,而 OPMODE[8:0] 控制總線則選擇操作數 W、X、Y 和 Z。如果考慮 24 位運算,DSP48E2 Slice 的 P 寄存器能存儲處理兩個輸入陣列的結果。對每一個陣列按順序求和,每個周期一個元。吞吐量由此變為每個周期產生兩個新結果。詳細說明,請參閱《UltraScale 架構 DSP Slice 用戶指南》(UG579)(關鍵字“SIMD”、“ALUMODE”和“OPMODE”)[ 參考資料 5 ]。
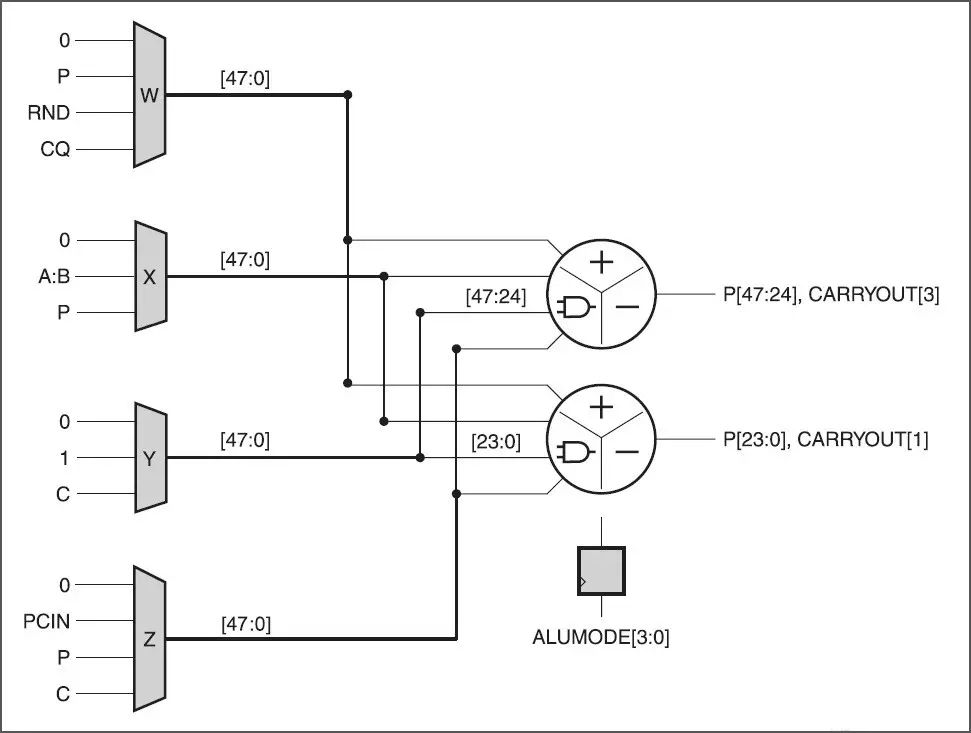
圖 4 :DSP48E2 雙 24 位 SIMD 模式
映射 INT8 優化到深度學習應用
新型神經網絡大部分是從這個初始概念模型[ 參考資料 6 ]衍生而來。見圖 5。
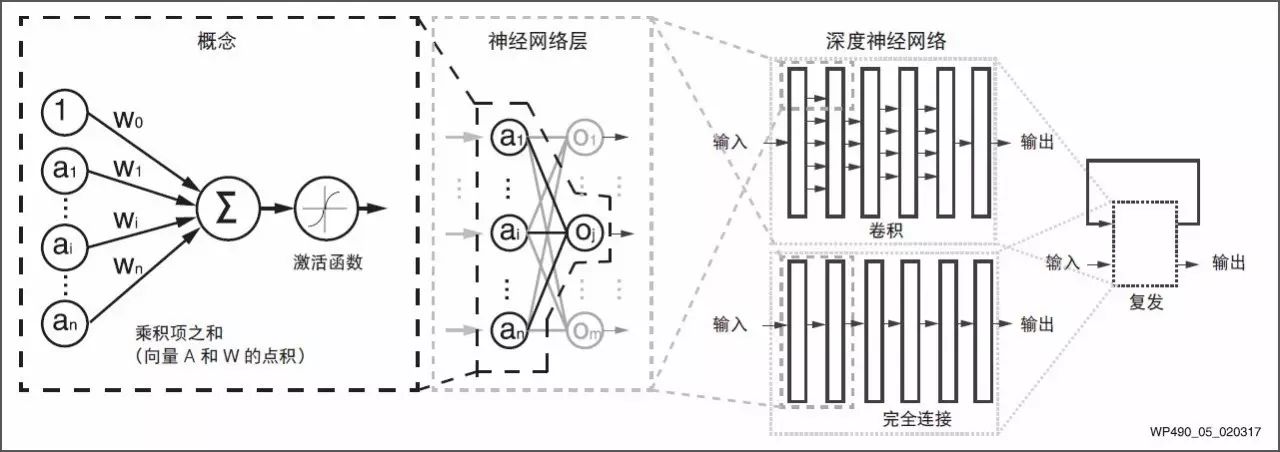
圖 5 :概念和深度神經網絡
雖然從標準感知器結構開始已有相當程度的演進,現代深度學習(也稱為深度神經網絡 (DNN))的基本運算仍然是類感知器的運算,只是有有更大的總體規模和更深的堆疊感知器結構。圖 5 顯示了感知器的基本運算。在每個典型的深度學習推斷中它穿過多個層,最終重復數百萬至數十億次。如圖 6 所示,在神經網絡層中,計算 m 個感知器/ 神經元輸出中的每一個輸出的主要計算運算包括:
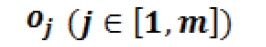
將全部的 n 個輸入樣本
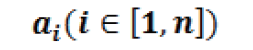
乘以對應的內核權重
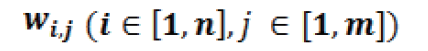
并累加結果
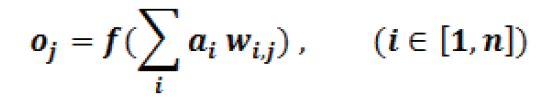
其中:f(x) 可以是任何選擇的激活函數。
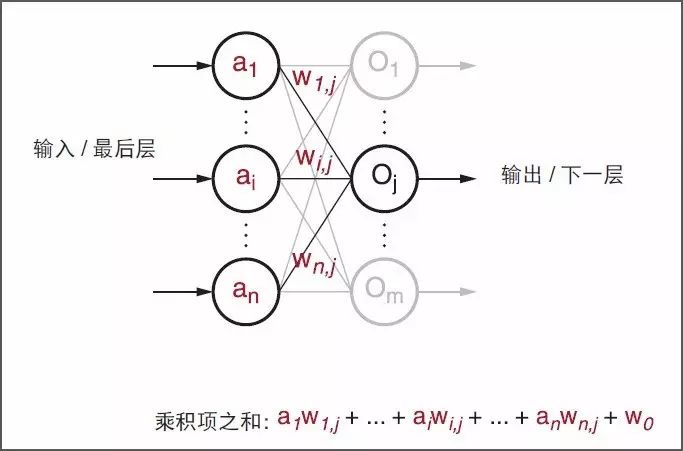
圖 6 :深度學習中的感知器
如果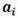 和
和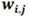 的精度限定為 INT8,該乘積之和是 INT8 優化方法中介紹的并行 MACC 中的第一個。第二個乘積和使用相同輸入
的精度限定為 INT8,該乘積之和是 INT8 優化方法中介紹的并行 MACC 中的第一個。第二個乘積和使用相同輸入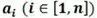 ,但內核權重
,但內核權重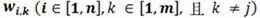 不同。第二個感知器/ 神經元輸出的結果是
不同。第二個感知器/ 神經元輸出的結果是
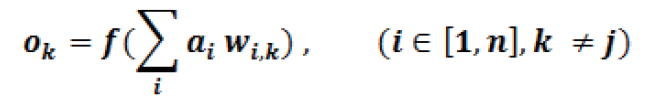
見圖 7。
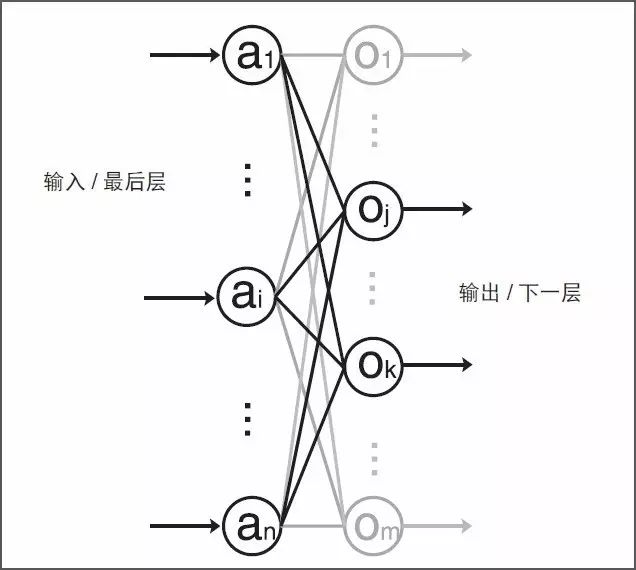
圖 7 :使用共享輸入并行得到兩個乘積項和
使用 INT8 優化方法將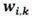 值向左移位 18 位,每個 DSP48E2 Slice 就得出最終輸出值的部分且獨立的一部分。用于每個 DSP48E2 Slice 的累加器有 48 位寬并鏈接到下一個 Slice。為避免移位飽和影響到計算,鏈接的模塊數量被限制為 7 個,即對總共 n 個輸入樣本使用 2n 個 MACC 和 n 個 DSP Slice。
值向左移位 18 位,每個 DSP48E2 Slice 就得出最終輸出值的部分且獨立的一部分。用于每個 DSP48E2 Slice 的累加器有 48 位寬并鏈接到下一個 Slice。為避免移位飽和影響到計算,鏈接的模塊數量被限制為 7 個,即對總共 n 個輸入樣本使用 2n 個 MACC 和 n 個 DSP Slice。
典型的 DNN 每層有數百到數千個輸入樣本。但是在完成 7 個項的累加后,48 位累加器的低位項可能飽和,因此每 7 個項之和就需要一個額外的 DSP48E2 Slice。這相當于每 7 個 DSP48E2 Slice 和 14 個 MACC,另加一個 DSP48E2 Slice 用于防止過飽和,從而帶來 7/4 或 1.75 倍的吞吐量提升。
在卷積神經網絡(CNN)中,卷積層一般主要使用同一組權重,從而形成 axw 和 bxw 類型的并行 MACC 運算。因此除輸入共享外,還可以使用權重共享(見圖 8)。
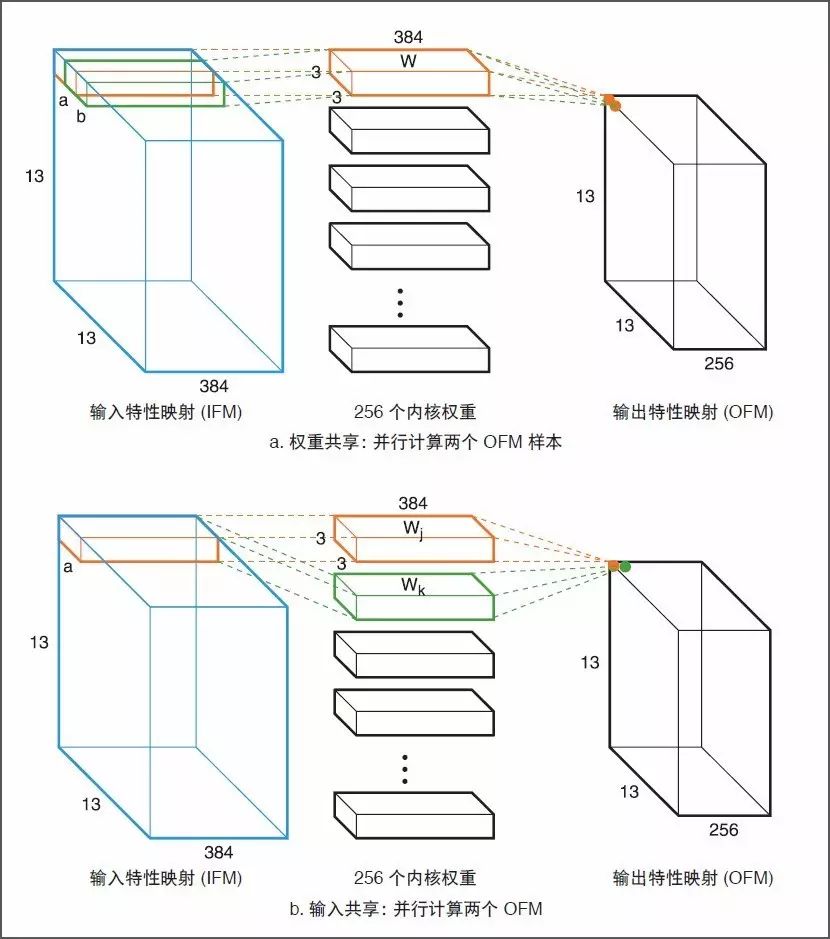
圖 8 :權重共享和輸入共享比較
創建 INT8 鏈接 MACC 的其他方法
還可以使用可編程邏輯中與 DSP48E2 Slice 工作頻率近似的可用 LUT(即未被設計其余部分使用的 LUT)來構建 INT8 鏈接 MACC。
使用可用 LUT 能顯著提高深度學習性能,一些情況下可提升達 3 倍之多。在許多情況下,對于其他非FPGA 架構而言,在計算可用深度學習運算時這些可用的計算資源并未考慮在內。
賽靈思 FPGA 和 MPSoC 中的編程邏輯是獨有的,因為它能并行且高效地處理不同工作負載。例如賽靈思 FPGA 和 MPSoC 能并行執行 CNN 圖像分類、網絡加密和數據壓縮。本深度學習性能比較分析未將MACC LUT 考慮在內,因為一般 LUT 用于執行其他并行功能比用于執行 MACC 功能時更有價值。
映射 INT8 優化到計算機視覺功能
Khronos OpenVX 標準定義了一套計算機視覺處理模塊,對下列用例尤為重要:面部、身體和手勢跟蹤;智能視頻監控;高級駕駛員輔助系統 (ADAS) ;對象和情景再現;增強現實;目測;機器人等。表 2 顯示了 INT8 優化適用的計算機視覺相關功能。
表 2 :適用于計算機視覺功能的 INT8 優化
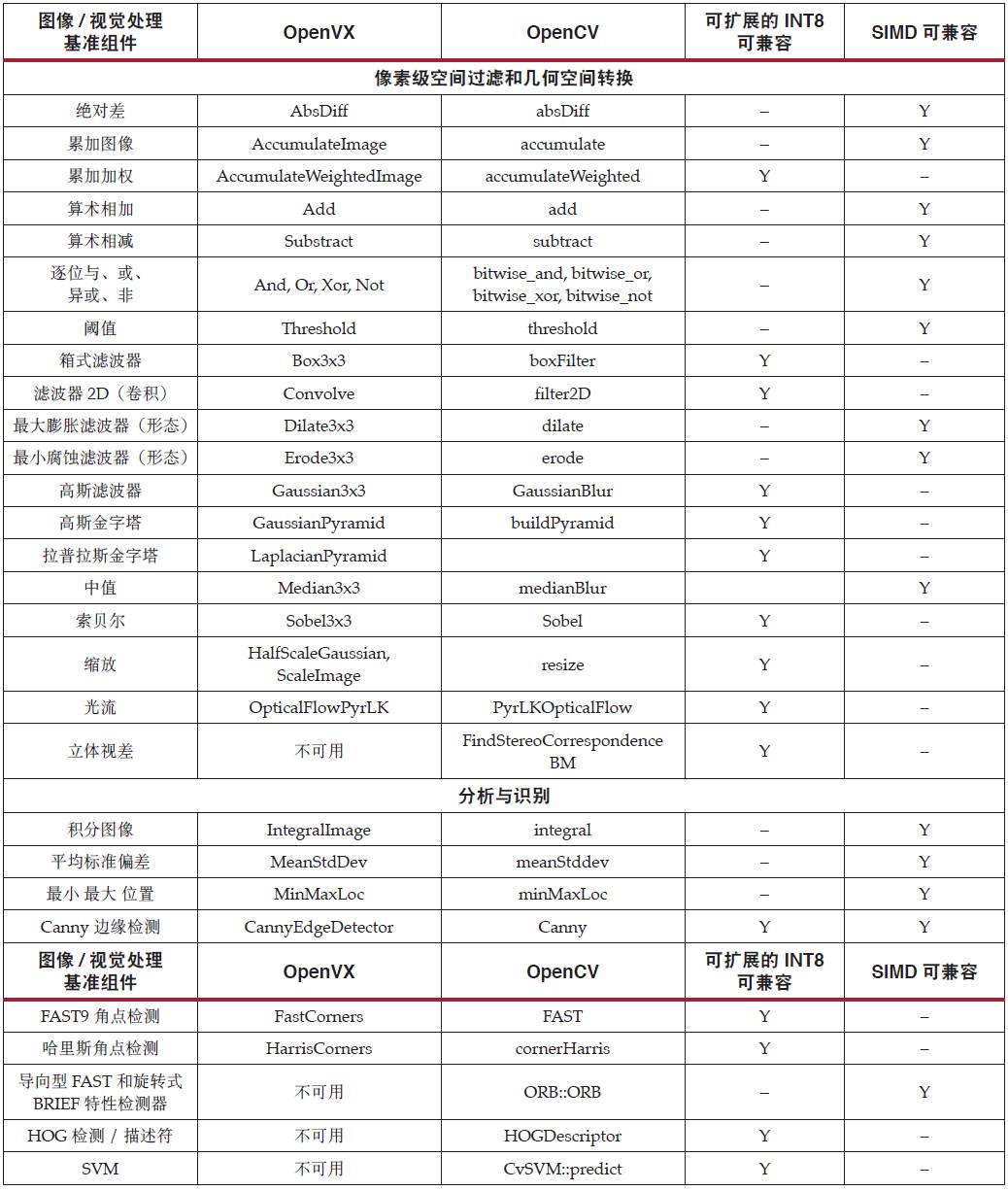
可擴展 INT8 優化可檢查同時處理兩個有共享系數的數據項的兼容性。SIMD 可檢查能從 DSP48E2 Slice 中的四個操作數和算子受益的模塊。數據和權重遵循 8 位限制的所有濾波器相關模塊都能從這種可擴展 INT8 方法獲益。大多數其他涉及基本圖像算術(例如加/ 減或比較等)的模塊能運用 DSP48E2 的 SIMD 運算。
使用可擴展 INT8 優化的定制 2D 卷積
在計算機視覺功能環境中,大部分預處理任務會涉及一定程度的過濾。因為圖像主要使用每個通道 8 位的方式表達,深度學習應用中對 INT8 運算的優化能應用到圖像處理中的二維過濾運算。唯一的局限是濾波器中的系數的精度必須能夠用 8 位表達。這對諸如索貝爾、Scharr、拉普拉斯或其他邊緣檢測濾波器等常見濾波器而言,一般來說是正確的。
使用下列方法之一即可發揮 DSP48E2 Slice 內的雙乘法器模式的作用:
對同一通道在多像素輸出上運算:在這種模式下可以并行計算出兩個輸出像素。因為在圖像中濾波器系數在像素間共享,因此能同時計算位置 (x,y) 和 (x,y+1) 的像素。按照濾波器計算順序,每個濾波器系數與兩個不同輸入像素相乘。這意味著在可編程邏輯中提供的資源不變的情況下,性能提高了 1.75 倍。
對不同通道或圖像的多像素輸出進行運算:如果正在處理的圖像有多個通道且濾波器在不同通道間共享,對處于相同位置 (x,y) 的像素,濾波器的系數可在多通道間共享。相同的方法可擴展用于同時運算多個圖像。
使用 SIMD 運算的中值濾波器
圖像處理中常用的中值濾波器也用于消噪。在圖像上使用中值濾波器涉及用預設大小的窗口掃描圖像,計算進入該窗口的像素的中值,使用中值替換中心像素。中值計算屬于高計算強度。它涉及為值排序,然后找到位于列表中間的值。排序流程是一個比較運算序列。
要使用可編程邏輯上的 DSP 實現中值濾波器,可以對算法做改動。每次比較運算可以分為減法運算及后續的符號位檢查。對減法運算,DSP48E2 Slice 能夠以四個 12 位或兩個 24 位模式進行運算。要充分利用 DSP48E2 Slice,可以并行運算多個像素。假定每個像素為單通道,深度小于 12 位,就可以同時處理四個輸出像素。對每個輸出像素存在多個排序運算,這些排序運算都可以使用 DSP48E2 Slice 中的減法運算。結果的符號位可以使用最小的邏輯在 DSP48E2 Slice 之外檢查。比較的總數量取決于用于排序值的算法。
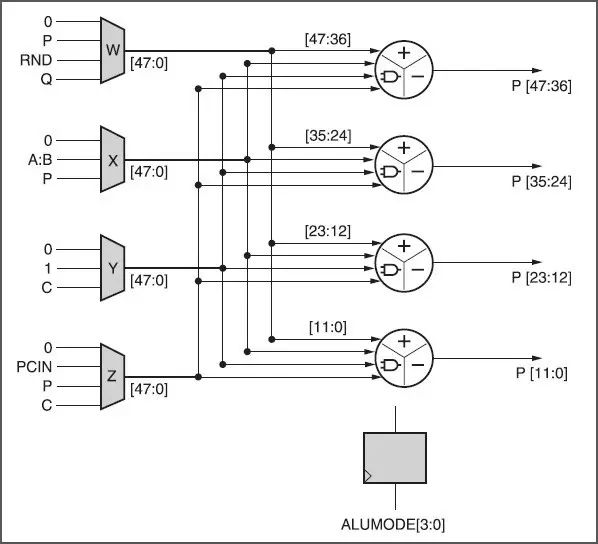
圖 9 :中值濾波器的 DSP48E2 運算模式
競爭分析
在競爭分析中使用英特爾(前 Altera)的 Arria 10 器件與賽靈思的 Zynq UltraScale+ MPSoC 對比。在進行嵌入式視覺應用計算效率比較時,選擇的器件有可比的 DSP 密度和器件功耗:
? Arria 10 SoC :SX220、SX270 和 SX480
? Zynq UltraScale+ MPSoC :ZU3、ZU7 和 ZU9 器件
重點比較能用于包括深度學習和計算機視覺在內的眾多應用的通用 MACC 性能。
英特爾的 MACC 性能基于運用預加法器的算子。但是這種實現方案產生的是乘積項的和,而非單獨的乘積項。因此英特爾的預加法器不適用高效深度學習或計算機視覺運算。
在本計算效率分析中,每個器件的功耗使用賽靈思的2016.4 版 Power Estimator 工具和英特爾的 16.0.1 版 EPE Power Estimate 工具進行估算,并根據下列假設得出:
1. 90% DSP 占用率
2. 英特爾器件 - 速度等級為:2L, 最大頻率下供電電壓為 0.9V
3. 賽靈思器件 - 速度等級為 1L, 最大頻率下供電電壓為 0.72V
4. 時鐘速率為 DSP Fmax 時邏輯利用率為 70%
5. 時鐘速率為 DSP 最大頻率的一半時,Block RAM 利用率為 90%
6. DSP 翻轉率為 12.5%
7. 功耗特征:“典型功耗”
圖 10 所示的即為深度學習和計算機視覺運算的能效對比。與英特爾的 Arria 10 SoC 器件相比,賽靈思器件能讓深度學習和計算機視覺運算的計算效率提高 3-7 倍。
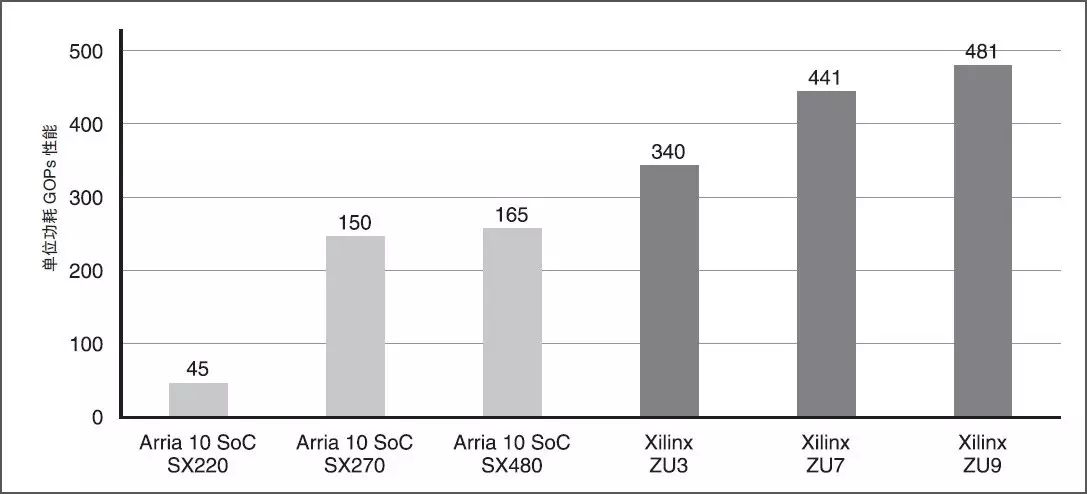
圖 10 :INT8 深度學習和計算機視覺能效對比:賽靈思對比英特爾
結 論
本白皮書探討了如何在賽靈思 DSP48E2 Slice 上優化 INT8 深度學習和計算機視覺運算,從而實現 1.75 倍的性能提升。賽靈思 DSP48E2 Slice 可用于在共享相同內核權重的同時處理兩個并行的 INT8 MACC 運算。為高效實現 INT8,需要 24 位輸入寬度,這一優勢只有賽靈思 DSP48E2 Slice 支持。同樣的優勢還能用于計算機視覺運算,例如過濾任務及其它圖像操作任務。賽靈思的 DSP48E2 Slice 的 SIMD 模式為開展四個 12 位或兩個 24 位 SIMD 運算提供了新的途徑。
總之,賽靈思的 Zynq UltraScale+ MPSoC 非常適用于 INT8 工作負載,使之成為為嵌入式視覺領域大量應用加速的理想選擇。賽靈思不斷創新新的基于軟/ 硬件的方法,以加速嵌入式視覺應用領域的深度學習和計算機視覺功能。
-
計算機視覺
+關注
關注
9文章
1706瀏覽量
46594 -
嵌入式視覺
+關注
關注
8文章
118瀏覽量
59498 -
深度學習
+關注
關注
73文章
5555瀏覽量
122536
發布評論請先 登錄
采用FPGA實現DisplayPort詳細教程【賽靈思內部資料】
用OpenCV和Vivado HLS加速基于Zynq SoC的嵌入式視覺應用開發
Xilinx賽靈思FPGA技術及應用線上公開課

賽靈思收購嵌入式Linux方案提供商PetaLogix
賽靈思收購嵌入式Linux方案提供商PetaLogix
賽靈思強化嵌入式視覺應用與工業物聯網產品系列
DSP48E2 Slice 上優化 INT8 深度學習運算分析
賽靈思擴大生態系統,重塑嵌入式視覺、工業物聯網系統設計的未來





 工商網監
工商網監
評論