 電子發燒友App
電子發燒友App


當你在機器上啟動某個程序時,它只是在自己的“bubble”里面運行,這個氣泡的作用就是用來將同一時刻運行的所有程序進行分離。這個“bubble”也可以稱之為進程,包含了管理該程序調用所需要的一切。
例如,這個所謂的進程環境包括該進程使用的內存頁,處理該進程打開的文件,用戶和組的訪問權限,以及它的整個命令行調用,包括給定的參數。
此信息保存在UNIX/Linux系統的流程文件系統中,該系統是一個虛擬文件系統,可通過/proc目錄進行訪問。條目都已經根據進程ID排過序了,該ID是每個進程的唯一標識符。示例1顯示了具有進程ID#177的任意選擇的進程。
示例1:可用于進程的信息
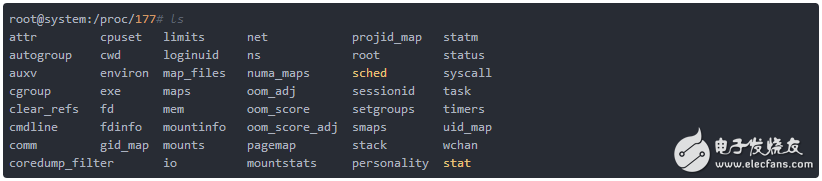
?
構建程序代碼以及數據
程序越復雜,就越有助于將其分成較小的模塊。不僅僅源代碼是這樣,在機器上執行的代碼也同樣適用于這條規則。該規則的典型范例就是使用子進程并行執行。這背后的想法就是:
單個進程包含了可以單獨運行的代碼段
某些代碼段可以同時運行,因此原則上允許并行
使用現代處理器和操作系統的特性,例如可以使用處理器的所有核心,這樣就可以減少程序的總執行時間
減少程序/代碼的復雜性,并將工作外包專門的代理
使用子進程需要重新考慮程序的執行方式,從線性到并行。它類似于將公司的工作視角從普通員工轉變為經理——你必須關注誰在做什么,某個步驟需要多長時間,以及中間結果之間的依賴關系。
這有利于將代碼分割成更小的部分,這些更小的部分可以由專門用于此任務的代理執行。如果還沒有想清楚,試想一下數據集的構造原理,它也是同樣的道理,這樣就可以由單個代理進行有效的處理。但是這也引出了一些問題:
為什么要將代碼并行化?落實到具體案例中或者在努力的過程中,思考這個問題有意義嗎?
程序是否打算只運行一次,還是會定期運行在類似的數據集上?
能把算法分成幾個單獨的執行步驟嗎?
數據是否允許并行化?如果不允許,那么數據組織將以何種方式進行調整?
計算的中間結果是否相互依賴?
需要對硬件進行調整嗎?
在硬件或算法中是否存在瓶頸,如何避免或者最小化這些因素的影響?
并行化的其他副作用有哪些?
可能的用例就是主進程,以及后臺運行的等待被激活的守護進程(主/從)。此外,這可能是啟動按需運行的工作進程的一個主要過程。在實踐中,主要的過程是一個饋線過程,它控制兩個或多個被饋送數據部分的代理,并在給定的部分進行計算。
請記住,由于操作系統所需要的子進程的開銷,并行操作既昂貴又耗時。與以線性方式運行兩個或多個任務相比,在并行的情況下,根據您的用例,可以在每個子過程中節省25%到30%的時間。例如,如果在系列中執行了兩項消耗5秒的任務,那么總共需要10秒的時間,并且在并行化的情況下,在多核機器上平均需要8秒。這8秒中的3秒可能會在頭頂上消失,限制你的速度提高。
運行與Python并行的函數
Python提供了四種可能的處理方式。首先可以使用multiprocessing模塊并行執行功能。第二,進程的替代方法是線程。從技術上講,這些都是輕量級的進程,不在本文的范圍之內。想了解更加詳細的內容,可以看看Python的線程模塊。第三,可以使用os模塊的system()方法或subprocess模塊提供的方法調用外部程序,然后收集結果。
multiprocessing模塊涵蓋了一系列方法來處理并行執行例程。這包括進程,代理池,隊列以及管道。
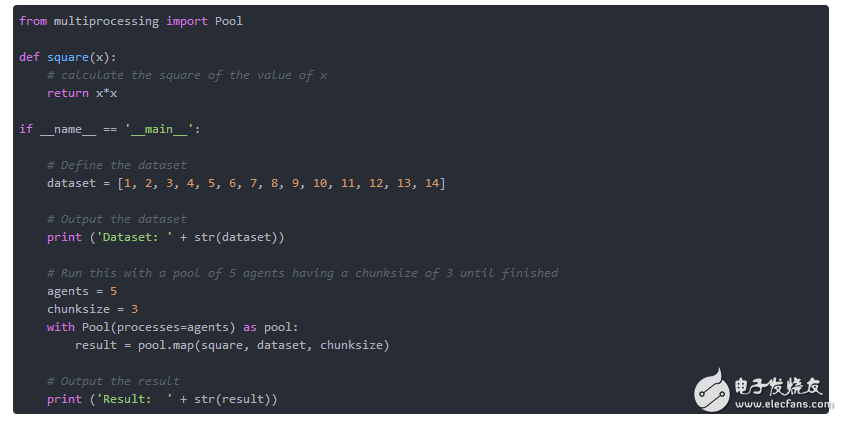
清單1使用了五個代理程序池,同時處理三個值的塊。對于代理的數量和對chunksize的值都是任意選擇的,用于演示目的。根據處理器中核心的數量來調整這些值。
Pool.map()方法需要三個參數 - 在數據集的每個元素上調用的函數,數據集本身和chunksize。在清單1中,我們使用square函數,并計算給定整數值的平方。此外,chunksize不是必須的。如果未明確設置,則默認chunksize為1。
請注意,代理商的執行訂單不能保證,但結果集的順序是正確的。它根據原始數據集的元素的順序包含平方值。
清單1:并行運行函數
?
運行此代碼應該產生以下輸出:
注意:我們將使用Python 3作為這些例子。
使用隊列運行多個函數
作為數據結構,隊列是非常普遍的,并且以多種方式存在。 它被組織為先進先出(FIFO)或先進先出(LIFO)/堆棧,以及有和沒有優先級(優先級隊列)。 數據結構被實現為具有固定數量條目的數組,或作為包含可變數量的單個元素的列表。
在列表2.1-2.7中,我們使用FIFO隊列。 它被實現為已經由來自multiprocessing模塊的相應類提供的列表。此外,time模塊被加載并用于模擬工作負載。
清單2.1:要使用的模塊
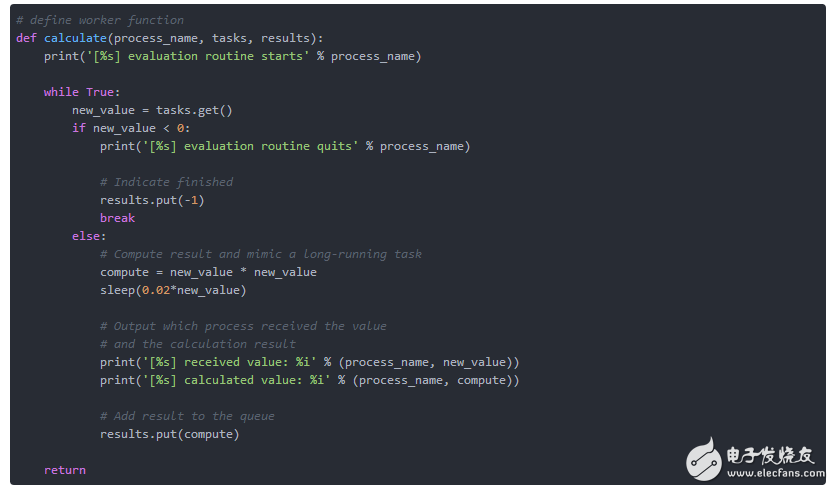
接下來,定義一個worker函數(清單2.2)。 該函數實際上代表代理,需要三個參數。進程名稱指示它是哪個進程,tasks和results都指向相應的隊列。
在工作函數里面是一個while循環。tasks和results都是在主程序中定義的隊列。tasks.get()從要處理的任務隊列中返回當前任務。小于0的任務值退出while循環,返回值為-1。任何其他任務值都將執行一個計算(平方),并返回此值。將值返回到主程序實現為result.put()。這將在results隊列的末尾添加計算值。
清單2.2:worker函數
下一步是主循環(參見清單2.3)。首先,定義了進程間通信(IPC)的經理。接下來,添加兩個隊列,一個保留任務,另一個用于結果。
?
清單2.3:IPC和隊列

完成此設置后,我們定義一個具有四個工作進程(代理)的進程池。我們使用類multiprocessing.Pool(),并創建一個它的實例。 接下來,我們定義一個空的進程列表(見清單2.4)。
?
清單2.4:定義一個進程池

?
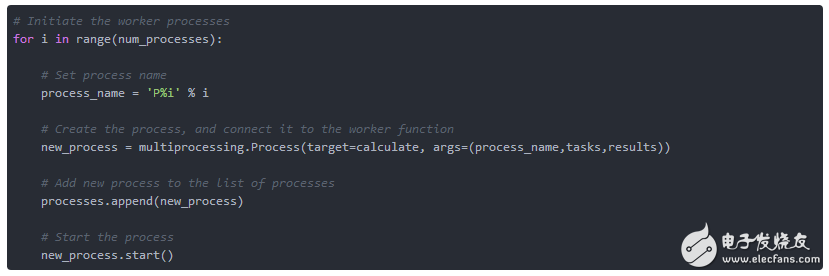
作為以下步驟,我們啟動了四個工作進程(代理)。 為了簡單起見,它們被命名為“P0”到“P3”。使用multiprocessing.Pool()完成創建四個工作進程。這將它們中的每一個連接到worker功能以及任務和結果隊列。 最后,我們在進程列表的末尾添加新初始化的進程,并使用new_process.start()啟動新進程(參見清單2.5)。
清單2.5:準備worker進程
?
我們的工作進程正在等待工作。我們定義一個任務列表,在我們的例子中是任意選擇的整數。這些值將使用tasks.put()添加到任務列表中。每個工作進程等待任務,并從任務列表中選擇下一個可用任務。 這由隊列本身處理(見清單2.6)。
清單2.6:準備任務隊列

?
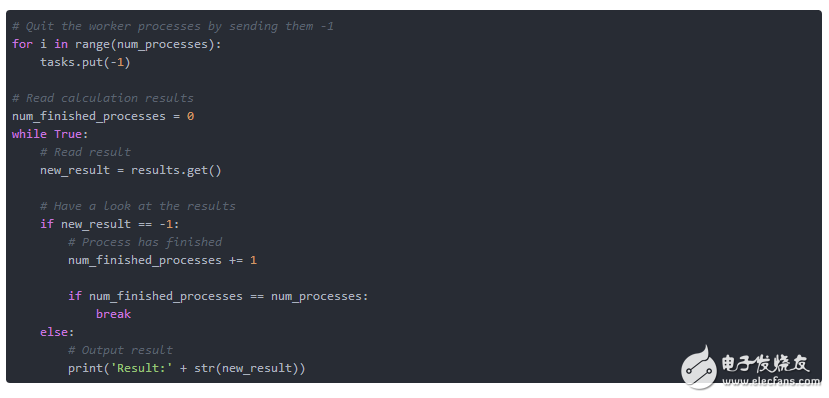
過了一會兒,我們希望我們的代理完成。 每個工作進程對值為-1的任務做出反應。 它將此值解釋為終止信號,此后死亡。 這就是為什么我們在任務隊列中放置盡可能多的-1,因為我們有進程運行。 在死機之前,終止的進程會在結果隊列中放置-1。 這意味著是代理正在終止的主循環的確認信號。
在主循環中,我們從該隊列讀取,并計數-1。 一旦我們計算了我們有過程的終止確認數量,主循環就會退出。 否則,我們從隊列中輸出計算結果。
清單2.7:結果的終止和輸出
?
示例2顯示了Python程序的輸出。 運行程序不止一次,您可能會注意到,工作進程啟動的順序與從隊列中選擇任務的進程本身不可預測。 但是,一旦完成結果隊列的元素的順序與任務隊列的元素的順序相匹配。
示例2
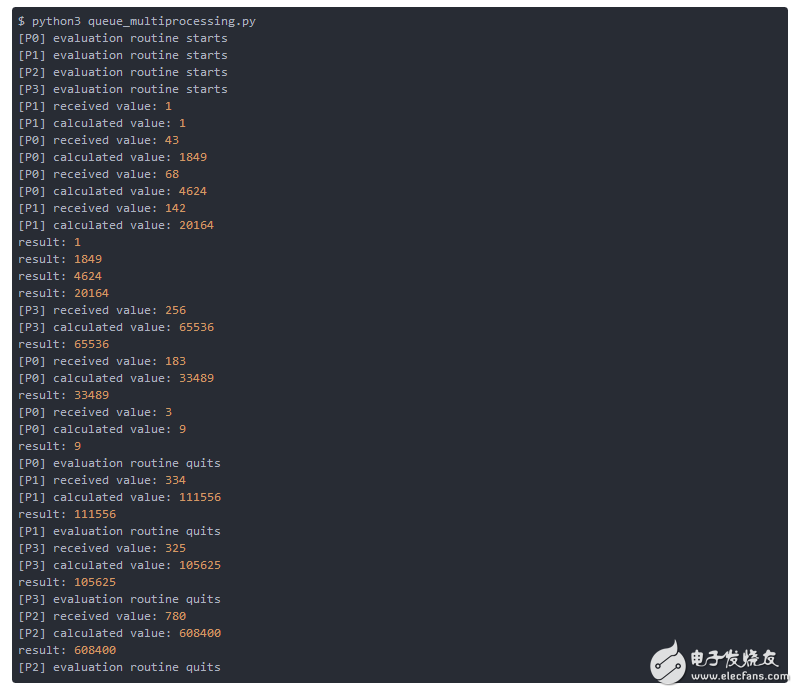
注意:如前所述,由于執行順序不可預測,您的輸出可能與上面顯示的輸出不一致。
?
使用os.system()方法
system()方法是os模塊的一部分,它允許在與Python程序的單獨進程中執行外部命令行程序。system()方法是一個阻塞調用,你必須等到調用完成并返回。 作為UNIX / Linux拜物教徒,您知道可以在后臺運行命令,并將計算結果寫入重定向到這樣的文件的輸出流(參見示例3):
示例3:帶有輸出重定向的命令
在Python程序中,您只需簡單地封裝此調用,如下所示:
清單3:使用os模塊進行簡單的系統調用
此系統調用創建一個與當前Python程序并行運行的進程。 獲取結果可能會變得有點棘手,因為這個調用可能會在你的Python程序結束后終止 - 你永遠都不會知道。
使用這種方法比我描述的先前方法要貴得多。 首先,開銷要大得多(進程切換),其次,它將數據寫入物理內存,比如一個需要更長時間的磁盤。 雖然這是一個更好的選擇,你的內存有限(像RAM),而是可以將大量輸出數據寫入固態磁盤。
使用子進程模塊
該模塊旨在替換os.system()和os.spawn()調用。子過程的想法是簡化產卵過程,通過管道和信號與他們進行通信,并收集他們生成的輸出包括錯誤消息。
從Python 3.5開始,子進程包含方法subprocess.run()來啟動一個外部命令,它是底層subprocess.Popen()類的包裝器。 作為示例,我們啟動UNIX/Linux命令df -h,以查找機器的/ home分區上仍然有多少磁盤空間。在Python程序中,您可以執行如下所示的調用(清單4)。
清單4:運行外部命令的基本示例

?
這是基本的調用,非常類似于在終端中執行的命令df -h / home。請注意,參數被分隔為列表而不是單個字符串。輸出將與示例4相似。與此模塊的官方Python文檔相比,除了調用的返回值之外,它將調用結果輸出到stdout。
示例4顯示了我們的呼叫的輸出。輸出的最后一行顯示命令的成功執行。調用subprocess.run()返回一個類CompletedProcess的實例,它有兩個名為args(命令行參數)的屬性和returncode(命令的返回值)。
示例4:運行清單4中的Python腳本

?
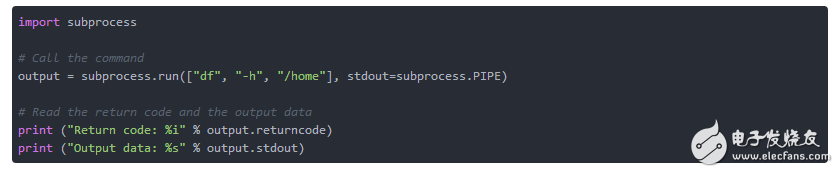
要抑制輸出到stdout,并捕獲輸出和返回值進行進一步的評估,subprocess.run()的調用必須稍作修改。沒有進一步修改,subprocess.run()將執行的命令的輸出發送到stdout,這是底層Python進程的輸出通道。 要獲取輸出,我們必須更改此值,并將輸出通道設置為預定義值subprocess.PIPE。清單5顯示了如何做到這一點。
清單5:抓取管道中的輸出
?
如前所述,subprocess.run()返回一個類CompletedProcess的實例。在清單5中,這個實例是一個簡單命名為output的變量。該命令的返回碼保存在屬性output.returncode中,打印到stdout的輸出可以在屬性output.stdout中找到。 請注意,這不包括處理錯誤消息,因為我們沒有更改輸出渠道。
結論
由于現在的硬件已經很厲害了,因此也給并行處理提供了絕佳的機會。Python也使得用戶即使在非常復雜的級別,也可以訪問這些方法。正如在multiprocessing和subprocess模塊之前看到的那樣,可以讓你很輕松的對該主題有很深入的了解。










 工商網監
工商網監
評論